Многоязычный синтез речи с клонированием / Хабр
Хотя нейронные сети стали использоваться для синтеза речи не так давно (например), они уже успели обогнать классические подходы и с каждым годам испытывают на себе всё новые и новый задачи.
Например, пару месяцев назад появилась реализация синтеза речи с голосовым клонированием Real-Time-Voice-Cloning. Давайте попробуем разобраться из чего она состоит и реализуем свою многоязычную (русско-английскую) фонемную модель.
Строение
Наша модель будет состоять из четырёх нейронных сетей. Первая будет преобразовывать текст в фонемы (g2p), вторая — преобразовывать речь, которую мы хотим клонировать, в вектор признаков (чисел). Третья — будет на основе выходов первых двух синтезировать Mel спектрограммы. И, наконец, четвертая будет из спектрограмм получать звук.
Наборы данных
Для этой модели нужно много речи. Ниже базы, которые в этом помогут.
Обработка текста
Первой задачей будет обработка текста.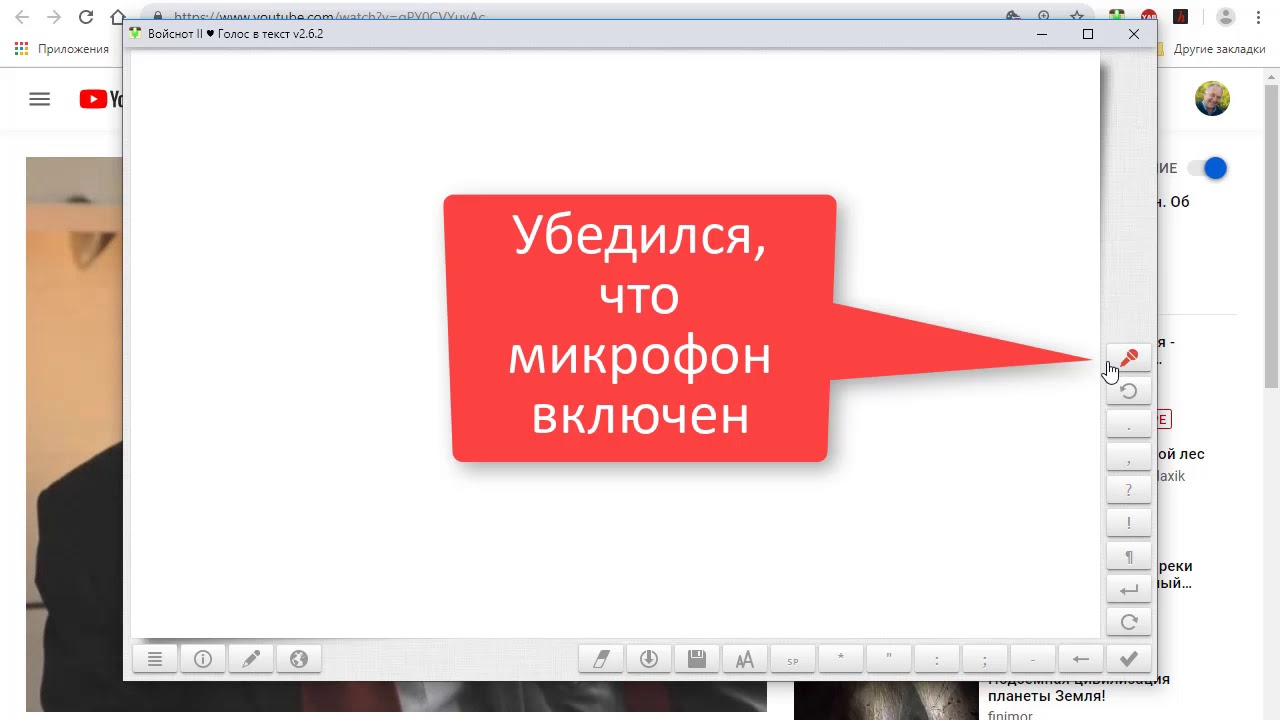 Представим текст в том виде, в котором он будет в дальнейшем озвучен. Числа представим прописью, а сокращения раскроем. Подробнее можно почитать в статье посвященной синтезу. Это тяжелая задача, поэтому предположим, что к нам поступает уже обработанный текст (в базах выше он обработан).
Представим текст в том виде, в котором он будет в дальнейшем озвучен. Числа представим прописью, а сокращения раскроем. Подробнее можно почитать в статье посвященной синтезу. Это тяжелая задача, поэтому предположим, что к нам поступает уже обработанный текст (в базах выше он обработан).
Следующим вопросом, которым следуют задаться, это использовать ли графемную, или фонемную запись. Для одноголосного и одноязычного голоса подойдет и буквенная модель. Если хотите работать с многоголосой многоязычной моделью, то советую использовать транскрипцию (Гугл тоже).
G2P
Для русского языка существует реализация под названием russian_g2p. Она построена на правилах русского языка и хорошо справляется с задачей, но имеет минусы. Не для всех слов расставляет ударения, а также не подходит для многоязычной модели. Поэтому возьмём созданный ей словарь, добавим словарь для английского языка и скормим нейронной сети (например этим 1, 2)
Прежде чем обучать сеть, стоит подумать, какие звуки из разных языков звучат похоже, и можно им выделить один символ, а для каких нельзя. Чем больше будет звуков, тем сложнее модели учиться, а если их будет слишком мало, то у модели появиться акцент. Не забудьте ударным гласным выделять отдельные символы. Для английского языка вторичное ударение играет малую роль, и я бы его не выделял.
Чем больше будет звуков, тем сложнее модели учиться, а если их будет слишком мало, то у модели появиться акцент. Не забудьте ударным гласным выделять отдельные символы. Для английского языка вторичное ударение играет малую роль, и я бы его не выделял.
Кодирование спикеров
Сеть схожа с задачей идентификации пользователя по голосу. На выходе у разных пользователей получаются разные вектора с числами. Предлагаю использовать реализацию самого CorentinJ, которая основана на статье. Модель представляет собой трехслойный LSTM с 768 узлами, за которыми следует полносвязный слой из 256 нейронов, дающие вектор из 256 чисел.
Опыт показал, что сеть, обученная на английской речи, хорошо справляется и с русской. Это сильно упрощает жизнь, так как для обучения требуется очень много данных. Рекомендую взять уже обученную модель и дообучить на английской речи из VoxCeleb и LibriSpeech, а также всей русской речи, что найдёте. Для кодера не нужна текстовая аннотация фрагментов речи.
Тренировка
- Запустите
python encoder_preprocess.py <datasets_root>для обработки данных - Запустите «visdom» в отдельном терминале.
- Запустите
python encoder_train.py my_run <datasets_root>для тренировки кодировщика
Синтез
Перейдём к синтезу. Известные мне модели не получают звук напрямую из текста, так как, это сложно (слишком много данных). Сначала из текста получается звук в спектральной форме, а уже потом четвертая сеть будет переводить в привычный голос. Поэтому сначала поймём, как спектральное вид связанна с голосом. Проще разобраться в обратной задаче, как из звука получить спектрограмму.
Звук разбивается на отрезки длинной 25 мс с шагом 10 мс (по умолчанию в большинстве моделей). Далее с помощью преобразования Фурье для каждого кусочка вычисляется спектр (гармонические колебания, сумма которых даёт исходный сигнал) и представляется в виде графика, где вертикальная полоса — это спектр одного отрезка (по частоте), а по горизонтальной — последовательность отрезков (по времени). Этот график называется спектрограммой. Если же частоту закодировать нелинейно (нижние частоты качественнее, чем верхние), то изменится масштаб по вертикали (нужно для уменьшения данных) то такой график называют Mel спектрограммой. Так устроен человеческий слух, что небольшое отклонение на нижних частотах мы слышим лучше, чем на верхних, поэтому качество звука не пострадает
Этот график называется спектрограммой. Если же частоту закодировать нелинейно (нижние частоты качественнее, чем верхние), то изменится масштаб по вертикали (нужно для уменьшения данных) то такой график называют Mel спектрограммой. Так устроен человеческий слух, что небольшое отклонение на нижних частотах мы слышим лучше, чем на верхних, поэтому качество звука не пострадает
Существует несколько хороших реализаций синтеза спектрограмм, такие как Tacotron 2 и Deepvoice 3. У каждой из этих моделей есть свои реализации, например 1, 2, 3, 4. Будем использовать(как и CorentinJ) модель Tacotron от Rayhane-mamah.
Tacotron основан на сети seq2seq с механизмом внимания. Ознакомитесь с подробностями в статье.
Тренировка
Не забудьте отредактировать utils/symbols.py, если будете синтезировать не только английскую речь, hparams.pу, а так же preprocess.py.
Для синтеза нужно много чистого, хорошо размеченного звука разных спикеров. Здесь чужой язык не поможет.
- Запустите
python synthesizer_preprocess_audio.py <datasets_root>для создания обработанного звука и спектрограмм - Запустите
python synthesizer_preprocess_embeds.py <datasets_root>для кодирования звука (получения признаков голоса) - Запустите
python synthesizer_train.py my_run <datasets_root>для тренировки синтезатора
Вокодер
Теперь осталось только преобразовать спектрограммы в звук. Для этого служит последняя сеть — вокодер. Возникает вопрос, если спектрограммы получаются из звука с помощью преобразования Фурье, нельзя ли с помощью обратного преобразования получить снова звук? Ответ и да, и нет. Гармонические колебания, из которых состоит исходный сигнал, содержат как амплитуду, так и фазу, а наши спектрограммы содержат информацию только об амплитуде (ради сокращения параметров и работаем со спекрограммами), поэтому если мы сделаем обратное преобразование Фурье, то получим плохой звук.
Для решения этой проблемы придумали быстрый алгоритм Гриффина-Лима. Он делает обратное преобразование Фурье спектрограммы, получая «плохой» звук. Далее делает прямое преобразования этого звука и получают спектр, в котором уже содержится немножко информации о фазе, причём амплитуда в процессе не меняется. Далее берётся еще раз обратное преобразование и получается уже более чистый звук. К сожалению, качество сгенерированной таким алгоритмом речи оставляет желать лучшего.
На его смену пришли нейронные вокодеры, такие как WaveNet, WaveRNN, WaveGlow и другие. CorentinJ использовал модель WaveRNN за авторством fatchord
Для предобработки данных используется два подхода. Либо получить спектрограммы из звука (с помощью преобразования Фурье), или из текста (с помощью модели синтеза). Google рекомендует второй подход.
Тренировка
- Запустите
python vocoder_preprocess.py <datasets_root>для синтеза спектрограмм - Запустите
python vocoder_train.для вокодера py <datasets_root>
py <datasets_root>
 py <datasets_root>
py <datasets_root>
Итого
Мы получили модель многоязычного синтеза речи, умеющей клонировать голос.
Запустите toolbox: python demo_toolbox.py -d <datasets_root>
Примеры можно послушать тут
Советы и выводы
- Нужно много данных (>1000 голосов, >1000 часов)
- Скорость работы сравнима с реальным временем только при синтезе минимум 4 предложений
- Для кодера используйте предобученную модель для английского языка, немножко дообучив. Она справляется хорошо
- Синтезатор, обученный на «чистых» данных, работает лучше, но хуже клонирует, чем тот, кто обучался на большем объёме, но грязных данных
- Модель хорошо работает только на данных, на которых училась
Можете синтезировать свой голос онлайн с помощью colab, или посмотреть мою реализацию на github и скачать мои веса.
Речевой синтезатор онлайн.
 Как это работает: синтез речи
Как это работает: синтез речи
Синтезаторы речи — это программы, на вход которых подаётся текст, а на выходе синтезируется человеческая речь. Эти программы имеют широкое применение — в телефонии, электронных ассистентах-помощниках, для телефонного доступа к веб-приложениям, в образовательных целях, в кол-центрах и т.п. Основные голосовые движки для воспроизведения русской речи — Realspeak, Digalo и Sakrament от компаний Nuance, Acapela и Sakrament соответственно.
Синтезаторы речи, работающие под Windows-системами:
Digalo (Acapela ELAN TTS)
Синтезаторы речи Acapela доступны на 23 языках, в том числе, и на русском и могут разговаривать более чем 50 голосами. Есть возможность использования в нескольких программах одновременно (многоканальность). Качественное русское произношение, большой словарь русских слов и ударений, всевозможные настройки и параметры воспроизведения. Наиболее качественный голосовой пакет — «Николай».
Nuance RealSpeak (ранее ScanSoft)
Поддерживает более 20 языков включая китайский, норвежский и корейский и 30 голосов.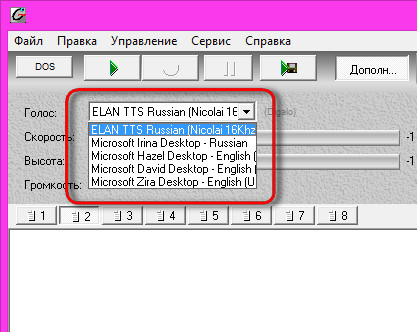 Голос, звучащий на русском языке — «Катерина». По многим параметрам это даже гораздо более удачное решение для русского языка, чем Digalo. Полностью поддерживает SAPI5. Программа распространяется только на коммерческой основе.
Голос, звучащий на русском языке — «Катерина». По многим параметрам это даже гораздо более удачное решение для русского языка, чем Digalo. Полностью поддерживает SAPI5. Программа распространяется только на коммерческой основе.
Sakrament TTS Engine
Программа умеет воспроизводить тексты на русском языке. На русском есть и версия сайта компании. Линейка продуктов Sakrament включает в себя приложение для коммуникаторов и КПК, программа для озвучивания электронных учебников и документов. В пакете для русского языка можно выбирать из трех голосов («Ольга», «Ирина», «Вячеслав»). Поддерживает входные форматы RTF и TXT, автоматически распознает кодировку текста, полностью поддерживает SAPI Speech Tags и дополнительные тэги семантической разметки текста для улучшения звучания синтезированной речи. Посредством тэгов можно задавать ударение, тип фрагмента текста (дата, время, адрес, URL, e-mail, телефон, аббревиатура и т.д.), параметры воспроизведения (громкость, скорость, интонация), а также другие параметры.
CoolReader
Программа для комфортного чтения книг с экрана, чтения вслух, форматирования и конвертирования текстов. Функция чтения вслух разработана с использованием движков MS SAPI 4.0 × 5.1. Работает в том числе и с текстами на русском языке. Распознает форматы HTML, RTF, DOC (MS Word), TXT, FB2 (FictionBook). Автоматически распознает русские кодировки dos, win, koi-8, а также latin, utf-8 и unicode. Можно сохранить аудиокнигу в формате MP3 для прослушивания на MP3 плеере. Отдельно подключаются словари произношений с настройками для каждого голосового движка. Поддерживаемые операционные системы: Win9x/ME/NT4.0/Win2K/XP.
ToM Reader
Приложение представляет собой просмотрщик текстов и речевой синтезатор одновременно. Работает в том числе и на русском языке. Позволяет создавать из текстов MP3-файлы, есть возможность подключения словарей произношения, умеет работать с zip архивами. Поддерживаемые форматы файлов: HTML, RTF, MS Word, TXT, кодировки: ANSI, KOI, OEM. Максимальный размер открываемого файла — 12 Мб.
Speak Aloud — программа для чтения и сохранения в файл с конвертированием текста форматов TXT, PDF, HTML, RTF в аудио MP3, WAV, WMA, OGG, VOX, AU, AIFF, MP4, FLAC, SWF. Можно настраивать интонации, тембр звучащего голоса и качество воспроизведения звука. Поддерживается пакетная обработка файлов. Работает под операционными системами: Windows 2000/XP/Vista
Govorilka
Воспроизводит текст на русском языке. Возможна запись читаемого текста в звуковой файл (*.WAV, *.MP3), а также регулирование скорости чтения и высоты озвучивающего голоса. Можно добавлять словари произношений, и таким образом довольно легко корректировать произношение отдельных слов и словосочетаний. Может работать с большими файлами, открывает тексты из файлов.doc, HTML. Также запоминает позицию курсора при выходе из программы (чтобы потом начать чтения с того же самого места).
Речевые синтезаторы, установленные на компьютеры или мобильные устройства, уже не кажутся такими необычными программами, как раньше. Благодаря современным технологиям обычный настольный ПК может воспроизводить человеческий голос.
Благодаря современным технологиям обычный настольный ПК может воспроизводить человеческий голос.
Каким образом работают синтезаторы речи? Где они применяются? Какой самый лучший речевой синтезатор? Ответы на эти и другие вопросы изложены в данной статье.
Общее понятие
Синтезаторы речи являются специальными программами, состоящими из некоторого количества модулей, которые предоставляют возможность перевести набранные тексты в озвученные человеческим голосом предложения. Не стоит думать, что вся база слов и фраз записана реальными людьми в профессиональных студиях. Выполнить подобную задачу физически невозможно. Библиотеку с таким большим количеством фраз нельзя установить ни на один современный компьютер, не говоря уже о мобильных телефонах. Для этого разработчики создали технологию Text-to-Speech.
Сфера применения
Синтезаторы речи используются при изучении иностранных языков, прослушивании текстов на страницах книг, создании вокальных партий, выдаче поисковых запросов в форме озвученных фраз и т. п.
п.
Какие разновидности программ существуют? В зависимости от сферы применения утилиты можно разделить на 2 вида: обычные, преобразующие набранный текст в речь, и специальные вокальные модули, используемые в музыкальных приложениях.
Преимущества и недостатки
На данный момент компьютер синтезирует человеческую речь только приблизительно. В простейших программах можно наблюдать проблемы со звуком и правильной постановкой ударений в различных словах. Синтезаторы речи, установленные на мобильные устройства, расходуют много энергии. Нередко можно отметить несанкционированную загрузку дополнительных модулей.
К преимуществам следует отнести удобство восприятия. Многим пользователям гораздо проще усваивать звуковую информацию, нежели какую-либо другую.
Лучшие речевые синтезаторы с русскими голосами
Программа RHVoice была создана Ольгой Яковлевой. Стандартный вариант приложения включает 3 голоса. Настройки очень просты. Программу можно использовать и как самостоятельное приложение, совместимое с SAPI5, и как дополнительный экранный модуль.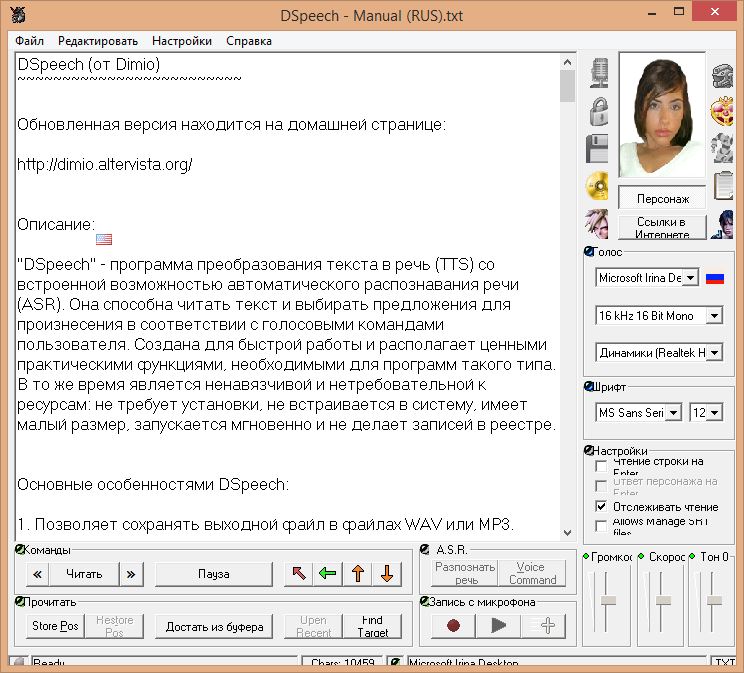
Речевой синтезатор Acapela отличается от аналогов идеальным озвучиванием текста. Приложение поддерживает более 30 языков мира. В бесплатной версии доступен лишь 1 женский голос.
Программа Vocalizer часто применяется в call-центрах. Пользователь может настроить постановку ударения, громкость и скорость чтения. При необходимости загружаются дополнительные словари. В приложении есть 1 женский голос. Речевой движок автоматически встраивается в программы для чтения книг в электронном формате.
Утилита eSpeak поддерживает свыше 50 языков. Недостатком программы можно считать сохранение звуковых файлов лишь в формате WAV, который требует много места на жестком диске.
Приложение Festival является мощнейшей утилитой синтеза речи, поддерживающей даже финский язык и хинди.
Установка программы
Как использовать приложения такого типа? Для начала нужно установить программу. В компьютерных ОС применяется стандартный инсталлятор, в котором пользователю остается выбрать лишь поддерживаемый утилитой языковой модуль. Установщик для мобильных устройств можно скачать с официального сайта, Google Play, а также App Store. Инсталляция приложения происходит в автоматическом режиме.
Установщик для мобильных устройств можно скачать с официального сайта, Google Play, а также App Store. Инсталляция приложения происходит в автоматическом режиме.
Первый запуск программы
На данном этапе пользователю достаточно установить язык по умолчанию. Иногда требуется отметить качество звучания. Стандартный вариант подразумевает частоту дискретизации 4410 Гц, глубину 16 бит и битрейт 128 кбит/с. В мобильных ОС показатели могут быть ниже. В качестве основы используется определенный голос.
Фильтры и эквалайзеры помогают достичь необходимого звучания. Пользователю доступны три варианта перевода текста. Он может набрать на клавиатуре предложения, включить озвучивание уже имеющегося файла или установить в браузере расширение, которое преобразует содержимое на веб-страницах в речь. Достаточно отметить необходимый вариант действий, тембр голоса и язык, на котором будет произноситься текст. Для включения процесса воспроизведения требуется кликнуть по кнопке «Старт».
Работа со сложными программами
В музыкальных приложениях настройки гораздо сложнее. В речевом модуле программы FL Studio пользователь может выбрать несколько видов голосов, а также указать тональность и скорость воспроизведения. Постановка ударений перед слогами осуществляется с помощью символа «_». С помощью подобного речевого синтезатора можно создать лишь роботизированный голос.
В речевом модуле программы FL Studio пользователь может выбрать несколько видов голосов, а также указать тональность и скорость воспроизведения. Постановка ударений перед слогами осуществляется с помощью символа «_». С помощью подобного речевого синтезатора можно создать лишь роботизированный голос.
Программа Vocaloid относится к приложениям профессионального типа. Помимо обычных параметров, пользователь может выбирать артикуляцию и глиссандо. В утилите есть база с вокалом профессионалов. При желании можно подгонять под ноты целые предложения. Одна только библиотека с вокалом занимает более 4 Гб в сжатом виде.
«Синтезатор речи Google»: что это за программа
В мае 2014 года компания предоставила пользователям возможность опробовать новый бесплатный продукт. Что такое «Синтезатор речи Google» на «Андроиде»? Это программа, озвучивающая текст на экране мобильного устройства или планшета. Теперь нет необходимости устанавливать сторонние утилиты, которые требуют наличия лицензии. «Синтезатор речи Google» используется при чтении электронных книг, прослушивании правильного произношения слов, запуске приложения TalkBack.
«Синтезатор речи Google» используется при чтении электронных книг, прослушивании правильного произношения слов, запуске приложения TalkBack.
Новая версия программы «Синтезатор речи Google 3.1» получила функцию поддержки английского, итальянского, испанского, корейского, немецкого, нидерландского, польского, португальского, русского и французского языков. Где найти голосовые пакеты? Они загружаются из самого приложения.
Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы. Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух. Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.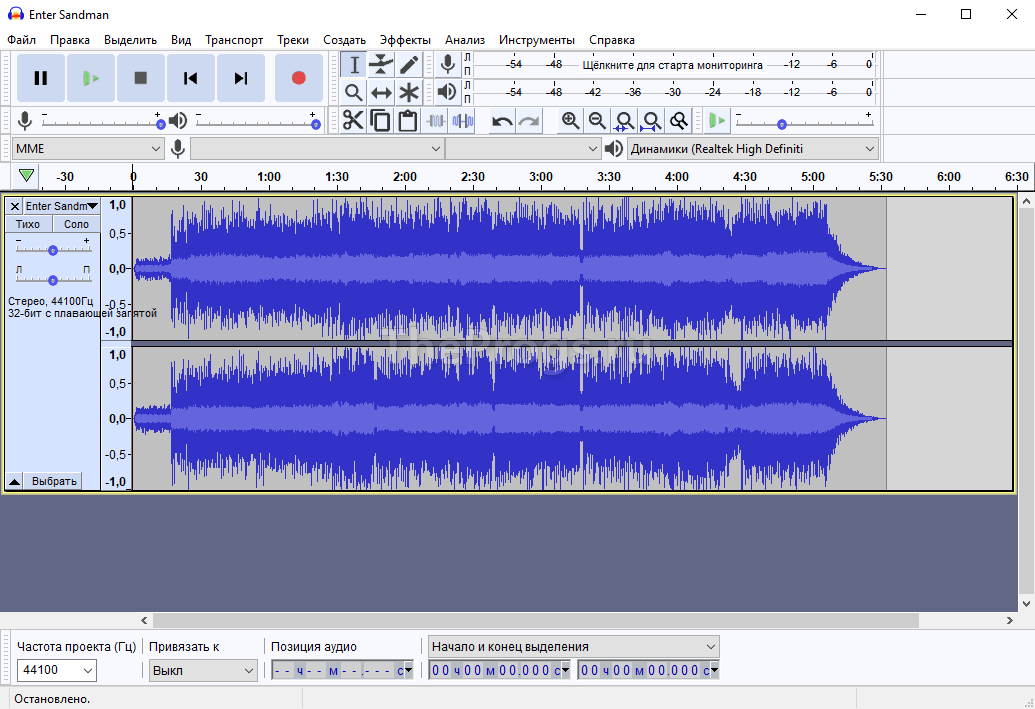
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.
«Синтезатор речи Google»: как пользоваться программой
Для того чтобы утилита заработала как надо, требуется обновить ее до последней версии. Чтобы активировать процесс озвучивания текста, нужно открыть настройки. В разделе «язык и ввод» необходимо поставить флажок на пункте «синтез речи». Тут же следует отметить строку «система по умолчанию». Не стоит забывать о том, что голосовые пакеты в самой программе также нуждаются в обновлении.
Проблемы при работе с утилитой
При необходимости пользователь может отключить приложение. В самых простых утилитах кнопка остановки находится в самой программе. Деактивация расширения, установленного в браузере, производится путем отключения дополнения или полного удаления плагина. При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
Данный процесс занимает много времени и существенно расходует трафик. Как отключить «Синтезатор речи Google» на мобильном устройстве и избавиться от этой проблемы? Для начала нужно открыть настройки приложения. Потом необходимо выбрать раздел «язык и голосовой ввод». Далее нужно отметить последнюю строку.
Выбрав голосовой поиск, следует кликнуть по крестику у пункта «распознавание речи офлайн». Затем рекомендуется удалить кэш приложений. Далее требуется перезагрузить мобильный телефон. Чтобы полностью отключить утилиту, необходимо открыть в настройках раздел «приложения», выбрать в списке синтезатор речи и кликнуть по кнопке «остановить».
Удаление программы
Бывает так, что пользователь вообще не использует «Синтезатор речи Google». Можно ли удалить утилиту с мобильного устройства? Для этого нужно открыть Google Play.![]() Затем следует выбрать в перечне установленных программ синтезатор речи и кликнуть по кнопке «удалить».
Затем следует выбрать в перечне установленных программ синтезатор речи и кликнуть по кнопке «удалить».
Итоги
Обычным пользователям и людям с ограниченными возможностями подойдут приложения с простым интерфейсом. Это может быть как RHVoice, так и «Синтезатор речи Google». Русский голос озвучит отображаемый на экране текст. Большего рядовому пользователю не требуется.
Музыкантам рекомендуется отдавать предпочтение профессиональной программе Vocaloid. В приложении есть дополнительные голосовые библиотеки и множество различных опций. Программа позволит получить естественное звучание голоса. Ведь музыкантам так важно, чтобы компьютерный синтез не ощущался на слух.
Сегодня синтезаторы речи, применяемые в стационарных компьютерных системах или мобильных устройствах, чем-то необычным уже не кажутся. Технологии шагнули далеко вперед и позволили воспроизвести человеческий голос. Как все это работает, где применяется, каков лучший речевой синтезатор и с какими потенциальными проблемами может столкнуться пользователь, смотрите ниже.
Что представляют собой речевые синтезаторы и где они применяются?
Синтезаторы речи представляют собой специальные программы, состоящие из нескольких модулей, которые позволяют переводить набранный на клавиатуре текст в обычную человеческую речь в виде звукового сопровождения.
Было бы наивно полагать, что сопутствующие библиотеки содержат абсолютно все слова или возможные фразы, записанные в студиях реальными людьми. Это просто физически невозможно. К тому же библиотеки фраз имели бы такой размер, что установить их даже на современные винчестеры большого объема, не говоря уже о мобильных девайсах, просто не представлялось бы возможным.
Для этого была разработана технология, получившая название Text-to-Speech (перевод текста в речь).
Наиболее широкое распространение синтезаторы речи получили в нескольких областях, к которым можно отнести самостоятельное изучение иностранных языков (программы нередко имеют поддержку в 50 языков и более), кода нужно услышать правильное произношение слова, прослушивание текстов книг вместо чтения, создание речевых и вокальных партий в музыке, использование их людьми с ограниченными возможностями, выдача поисковых запросов в виде озвученных слов и фраз и т. д.
д.
Разновидности программ
В зависимости от области применения, все программы можно разделить на два основных типа: стандартные, непосредственно преобразующие текст в речь, и речевые или вокальные модули, применяемые в музыкальных приложениях.
Для более полного понимания картины рассмотрим оба класса, но больший упор будет сделан все-таки на синтезаторы речи в их непосредственном назначении.
Плюсы и минусы простейших речевых приложений
Что же касается преимуществ и недостатков программ такого типа, сначала рассмотрим все-таки недостатки.
Прежде всего нужно четко понимать, что компьютер — он и есть компьютер, который на данном этапе развития человеческую речь может синтезировать весьма приблизительно. В простейших программах зачастую наблюдаются проблемы с постановкой ударений в словах, пониженное качество звука, а в мобильных устройствах — повышенное энергопотребление, а иногда и несанкционированная загрузка речевых модулей.
Но и преимуществ хватает, ведь очень многие звуковую информацию воспринимают гораздо лучше, нежели визуальную. Удобство восприятия налицо.
Удобство восприятия налицо.
Как пользоваться синтезатором речи?
Теперь несколько слов об основных принципах использования программ такого типа. Установить синтезатор речи любого типа можно без особых проблем. В стационарных системах используется стандартный инсталлятор, где основной задачей станет выбор поддерживаемых языковых модулей. Для мобильных девайсов установочный файл можно скачать из официального магазина или хранилища вроде Google Play или AppStore, после чего приложение инсталлируется в автоматическом режиме.
Как правило, при первом запуске никаких настроек, кроме установки языка по умолчанию, производить не нужно. Правда, иногда программа может предложить выбрать качество звучания (в стандартном варианте, применяемом повсеместно, частота дискретизации 4410 Гц, глубина 16 бит и битрейт 128 кбит/с). В мобильных устройствах эти показатели ниже. Тем не менее за основу берется определенный голос. С использованием стандартного шаблона произношения путем применения фильтров и эквалайзеров достигается звучание именно такого тембра.
В использовании можно выбрать несколько вариантов перевода текста: ввод текста вручную, озвучивание уже имеющего текста из файла, интеграция в другие приложения (например, веб-браузеры) с активацией выдачи поисковых результатов или прочтения текстового содержимого на страницах онлайн. Достаточно выбрать нужный вариант действий, язык и голос, которым все это будет произноситься. Многие программы имеют несколько разновидностей голосов: как мужских, так и женских. Для активации процесса воспроизведения обычно используется кнопка старта.
Если говорить о том, как отключить синтезатор речи, тут может быть несколько вариантов. В самом простом случае используется кнопка остановки воспроизведения в самой программе. В случае интеграции в браузер деактивация производится в настройках расширений или полным удалением плагина. А вот с мобильными устройствами, несмотря на непосредственное отключение, могут быть проблемы, о которых будет сказано отдельно.
В музыкальных программах настройки и ввод текста намного сложнее. Например, в приложении FL Studio есть свой речевой модуль, в котором можно выбрать несколько изменить настройки тональности, скорости воспроизведения и т. д. Для постановки ударений перед слогом используется символ «_». Но и такой синтезатор годится только для создания роботизированных голосов.
Например, в приложении FL Studio есть свой речевой модуль, в котором можно выбрать несколько изменить настройки тональности, скорости воспроизведения и т. д. Для постановки ударений перед слогом используется символ «_». Но и такой синтезатор годится только для создания роботизированных голосов.
Но вот пакет Vocaloid от Yamaha относится к программам профессионального типа. Технология Text-to-Speech здесь реализована в наиболее полном объеме. В настройках, помимо стандартных параметров, можно выставить артикуляцию, глиссандо, использовать библиотеки с вокалом профессиональных исполнителей, составлять слова и фразы, подгоняя их под ноты, и еще кучу всего. Неудивительно, что пакет только с одним вокалом занимает порядка 4 Гб и более в установочном дистрибутиве, а после распаковки — вдвое-втрое больше.
Синтезаторы речи с русскими голосами: краткий обзор самых популярных
Но вернемся к самым простым приложениям и рассмотрим самые популярные из них.
RHVoice — по мнению большинства экспертов, лучший синтезатор речи, являющийся российской разработкой авторства В стандартном варианте доступно три голоса (Александр, Ирина, Елена). Настройки просты. А само приложение может использоваться и как самостоятельная программа, совместимая с SAPI5, и как экранный модуль.
Настройки просты. А само приложение может использоваться и как самостоятельная программа, совместимая с SAPI5, и как экранный модуль.
Acapela — достаточно интересное приложение, главной особенностью которого является почти идеальная озвучка текста более чем на 30 языках мира. В обычной версии, правда, доступен только один голос (Алена).
Vocalizer — мощное приложение с женским голосом Milena. Очень часто эта программа применяется в call-центрах. Имеется множество настроек постановки ударения, громкости, скорости чтения и установки дополнительных словарей. Главное отличие состоит в том, что речевой движок может встраиваться в программы вроде Cool Reader, Moon+ Reader Pro или Full Screen Caller ID.
Festival — мощнейшая утилита синтеза и распознавания речи, созданная для систем Linux и Mac OS X. Приложение поставляется с открытым исходным кодом и, помимо стандартных языковых пакетов, имеет поддержку даже финского языка и хинди.
eSpeak — речевое приложение, поддерживающее более 50 языков. Главным недостатком считается сохранение файлов с синтезированной речью исключительно в формате WAV, который занимает уж очень много места. Зато программа является кроссплатформенной и может использоваться даже в мобильных системах.
Главным недостатком считается сохранение файлов с синтезированной речью исключительно в формате WAV, который занимает уж очень много места. Зато программа является кроссплатформенной и может использоваться даже в мобильных системах.
Проблемы с синтезатором речи в Google Android
При установке «родного» синтезатора речи от Google, пользователи постоянно жалуются на то, что он самопроизвольно включает загрузку дополнительных языковых модулей, что может не только занимать достаточно длительный промежуток времени, но еще и расходует трафик.
Избавиться от этого в Android-системах можно очень просто. Для этого используем меню настроек, далее переходим в раздел языка и голосового ввода, выбираем голосовой поиск и на параметре распознавания речи оффлайн нажимаем на крестик (отключение). Дополнительно рекомендуется почистить кэш приложений и перезагрузить устройство. Иногда может потребоваться в самом приложении отключить показ уведомлений.
Что в итоге?
Поводя некий итог, можно сказать, что в большинстве случаев рядовым пользователям подойдут самые простые программы.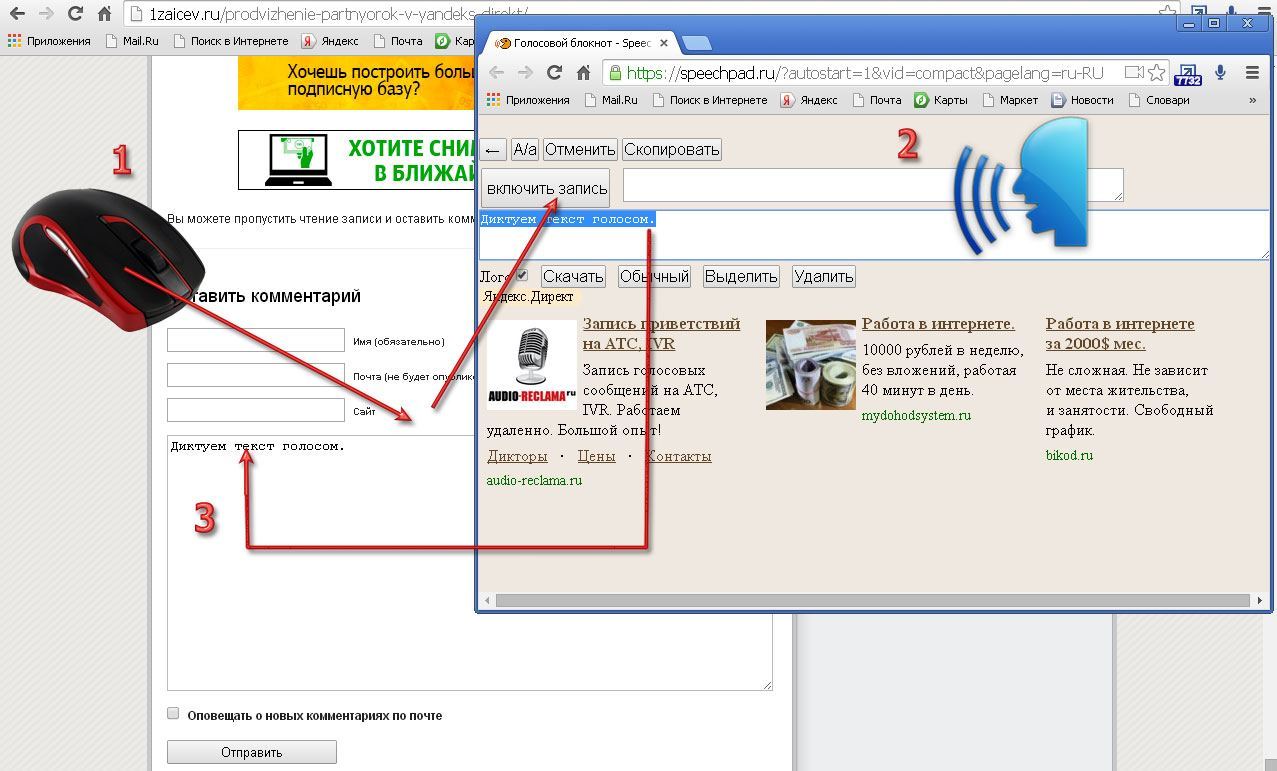 Во всех рейтингах лидирует RHVoice. Но для музыкантов, которые хотят добиться естественного звучания голоса, чтобы разница между живым вокалом и компьютерным синтезом не ощущалась на слух, лучше отдать предпочтение программам типа Vocaloid, тем более что для них выпускается множество дополнительных голосовых библиотек, а настройки имеют столько возможностей, что примитивные приложения, как говорится, и рядом не стояли.
Во всех рейтингах лидирует RHVoice. Но для музыкантов, которые хотят добиться естественного звучания голоса, чтобы разница между живым вокалом и компьютерным синтезом не ощущалась на слух, лучше отдать предпочтение программам типа Vocaloid, тем более что для них выпускается множество дополнительных голосовых библиотек, а настройки имеют столько возможностей, что примитивные приложения, как говорится, и рядом не стояли.
– процесс генерации речевого сигнала — технология, которая дает возможность прочитать текст (документ, письмо, смс) голосом, приближенном к естественному. Для того, чтобы синтезированная речь звучала натурально, необходимо решить целый комплекс задач, связанных как с обеспечением естественности голоса на уровне тембра, плавности звучания и интонации, так и с правильной расстановкой ударений, расшифровкой сокращений, чисел, аббревиатур и специальных знаков.
Технология синтеза может быть востребована как в узкой предметной области, так и в широкой, или неограниченной. Для узкой области качество звучания может быть сведено к максимально естественной, за счёт компиляции заранее записанных длительных речевых фрагментов, относящихся к данной области. Примером такого синтеза (называемого макросинтезом) могут служить системы оповещения о движении поездов, применяющиеся на вокзалах больших городов в России. Гораздо сложнее сделать синтезатор речи для неограниченного текста любой предметной области. В таком случае пользователь может задать системе синтеза на произношение любую фразу или предложение.
Для узкой области качество звучания может быть сведено к максимально естественной, за счёт компиляции заранее записанных длительных речевых фрагментов, относящихся к данной области. Примером такого синтеза (называемого макросинтезом) могут служить системы оповещения о движении поездов, применяющиеся на вокзалах больших городов в России. Гораздо сложнее сделать синтезатор речи для неограниченного текста любой предметной области. В таком случае пользователь может задать системе синтеза на произношение любую фразу или предложение.
Программы экранного доступа
Программа экранного доступа VIRGO 4
— это итог многолетней работы фирмы BAUM по развитию программы VIRGO, главная цель которой состоит в обеспечении комфортной работы слепых и слабовидящих пользователей с Windows. VIRGO 4 позволяет пользователю выбирать, какую информацию показывать на брайлевском дисплее, а какую произносить голосом. Слабовидящие пользователи могут также воспользоваться интегрированной в VIRGO 4 системой увеличения экрана ГАЛИЛЕО. Комплексный подход VIRGO 4, использующий брайль и речь, гибко сочетает силу обоих методов вывода информации для удобства пользователя.
Комплексный подход VIRGO 4, использующий брайль и речь, гибко сочетает силу обоих методов вывода информации для удобства пользователя.
Дополнительная информация
История
У синтеза речи долгая история, обросшая легендами. Ещё в Х веке Герберту Аврилакскому приписывали владение искусством изготовления терафима — говорящей мёртвой головы. Сделанная из бронзы , эта голова словами «да» и «нет» отвечала на вопросы любого к ней обращавшегося. В середине XIII века монах-доминиканец Альберт фон Больштедт и английский философ и естествоиспытатель Роджер Бэкон также пытались создавать первые образцы «говорящих голов».
В конце XVIII века датский учёный Христиан Кратценштейн , действительный член Российской Академии Наук , создал модель речевого тракта человека, способную произносить пять долгих гласных звуков (а
, э
, и
, о
, у
). Модель представляла собой систему акустических резонаторов различной формы, издававших гласные звуки при помощи вибрирующих язычков, возбуждаемых воздушным потоком. В австрийский учёный Вольфганг фон Кампелен дополнил модель Кратценштейна моделями языка и губ и представил акустическо-механическую говорящую машину , способную воспроизводить определённые звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным управлением. В учёный Чарльз Уитстоун (Charles Wheatstone
В австрийский учёный Вольфганг фон Кампелен дополнил модель Кратценштейна моделями языка и губ и представил акустическо-механическую говорящую машину , способную воспроизводить определённые звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным управлением. В учёный Чарльз Уитстоун (Charles Wheatstone
) представил улучшенный вариант машины, способный воспроизводить гласные и большинство согласных звуков. А в
Недавно передо мной встала проблема выбора голосового синтезатора речи. Основные требования — это поддержка русского языка и более-менее нормальное произношение.
Для тех, кто не в курсе того, что такое синтезатор речи, расскажу — это специальная программа, смысл работы которой заключается в преобразовании письменного текста в устную речь. Это и есть так называемый синтез.
Зачем это надо? Ну, например, когда надо записать голосовое сообщение чужим голосом. Иностранцам оно может быть полезно для того, чтобы услышать произношение того или иного слова.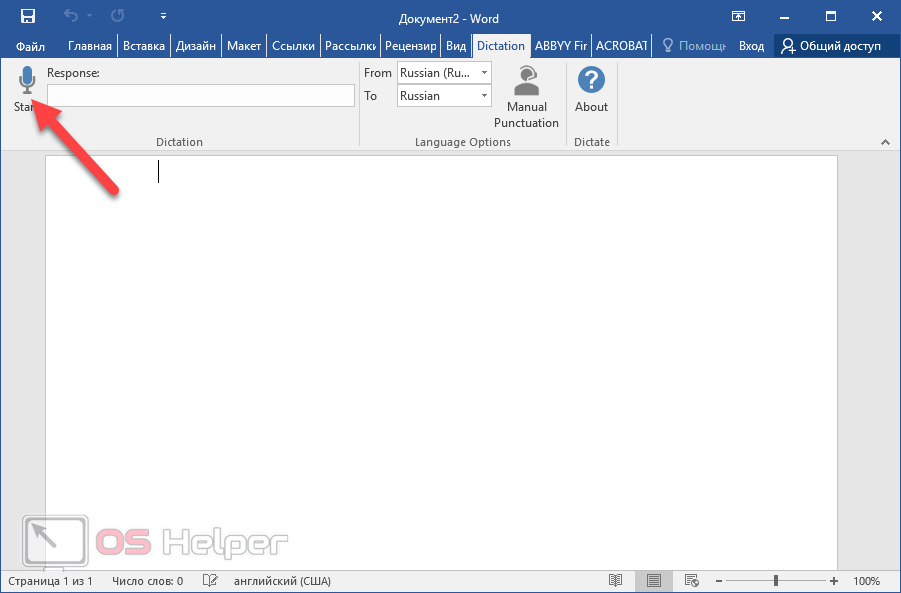 Синтезатор речи удобен для чтения, когда надо включить ребенку сказку, которой нет в аудиокнигах. Да и вообще, ситуации всякие бывают.
Синтезатор речи удобен для чтения, когда надо включить ребенку сказку, которой нет в аудиокнигах. Да и вообще, ситуации всякие бывают.
Так вот, в процессе выбора я нашел несколько очень полезных инструментов, среди которых работающих в режиме онлайн с поддержкой русского языка и сейчас я Вам о них и расскажу.
Переводчик Google
Вот поистине многоцелевой продукт, которых можно использовать совершенно по-разному. Главные преимущества:
— это совершенно бесплатный сервис;
— работа в режиме Онлайн без установки. Нужен только доступ в Интернет;
— на мой взгляд этот синтезатор речи имеет лучший голосовой модуль, самое близкое к натуральному;
— наверное самая лучшая команда разработчиков и техподдержка в мире;
— самое большое количество поддерживаемых языков.
К сожалению, вариант голоса только один — женский. Выбора я не нашел.
RHVoice
Отличный многоязычный синтезатор речи от российского разработчика — Ольги Яковлевой. Есть версии, как для операционных систем семейства Windows, так и для Linux. Разработчик синтезатора — Ольга Яковлева. Программа распространяется совершенно бесплатно и доступна на официальном сайте в двух вариантах: как SAPI5-совместимая самостоятельная версия и как модуль для бесплатной программы экранного доступа NVDA. Этот синтезатор голосовой речи умеет озвучивать русские тексты тремя голосами — Елена, Ирина и Александр.
Есть версии, как для операционных систем семейства Windows, так и для Linux. Разработчик синтезатора — Ольга Яковлева. Программа распространяется совершенно бесплатно и доступна на официальном сайте в двух вариантах: как SAPI5-совместимая самостоятельная версия и как модуль для бесплатной программы экранного доступа NVDA. Этот синтезатор голосовой речи умеет озвучивать русские тексты тремя голосами — Елена, Ирина и Александр.
Acapela
Acapela — это, пожалуй, один из самых популярных и распространенных голосовых синтезаторов в мире. Главная особенность — это озвучка текстов более чем на тридцати языках мира. Если рассматривать русский язык, то тут доступны два голоса — Николай и Алена. Причем последний более совершенен и естественен в плане произношения. В демонстрационном режиме на сайте доступен только голос Алена.
Программа доступна для скачивания на официальном сайте и поддерживает все популярные современные операционные системы — Windows, Linux, Mac. Есть даже версии для Android u iOS.
Vokalizer
Женских голос Milena — это ещё один очень популярный движок голосового синтезатора речи от компании Nuance — он очень высококачественный и естественно звучащий. Его Вы можете услышать в call-центрах и в различных сетевых речевых системах, а также в различных приложениях приложениях — таких как Moon+ Reader Pro, Full Screen Caller ID , Cool Reader, в навигационной программах TomTom, iGo Primo.
Среди плюсов можно отметить возможность установки различных словарей, регулировки громкости, ударения и скорости чтения.
Код программы открытый, скачать его бесплатно можно на официальном сайте, собственно как и инсталлятор самой программы.
Festival
Festival — это не просто очередной голосовой речевой синтезатор, а уже целая система распознавания и синтеза речи с различными API. Разработчик — Исследовательский Центр Речевых Технологий университета Эдинбурга.
Festival предназначен для поддержки нескольких языков. По умолчанию поддерживает английский, валлийский и испанский языки. Но есть возможность подключить голосовые пакеты других языков: чешский, финский, хинди, итальянский, маратхи, польский, русский и телугу.
Но есть возможность подключить голосовые пакеты других языков: чешский, финский, хинди, итальянский, маратхи, польский, русский и телугу.
Код программы открытый, сам голосовой синтезатор распространяется по лицензии open source и доступна только для операционных систем Linux. Правда есть портированная версия по Макинтош.
ESpeak
Последняя в моём обзоре система синтеза речи — программа ESpeak — разрабатывается уже около 8 лет. Последняя версия — 1.48.04 от 6 апреля 2014. Данный голосовой синтезатор речи кроссплатформенный — есть версии под Windows, Linux, Mac OS X, и даже под RISC OS, хотя последние две уже давно не поддерживаются.
Отдельно отмечу, что eSpeak используется в мобильных операционных системах Android, правда имеет при этом ряд существенных ошибок.
Программа поддерживает пятидесяти различных языков, поддержка которых указывается при установке программы.
Один из главных минусов это голосового синтезатора — генерирование голоса только в файл формата WAV. Скачать программу бесплатно можно на официальном сайте.
Скачать программу бесплатно можно на официальном сайте.
От себя добавлю лишь, что мне понравились RHVoice и Vokalizer, хотя тут во много дело индивидуальное и во многом зависит от того, что Вы хотите получить. Так что пробуйте, ставьте и смотрите. Я думаю, что один из представленных вариантов Вам обязательно должен подойти.
Как преобразовать аудиозапись в текст
Над созданием анализаторов речи лучшие умы человечества бьются не первое десятилетие, но до настоящего времени в мире пока не существует программы, безошибочно распознающей человеческую речь и автоматически преобразующей её в текст. В этой статье я расскажу о том, как делается преобразование речи в текст, и какие для этого есть программы.
Транскрипция аудиозаписей в стенограмму на сегодняшний день осуществляется профессиональными расшифровщиками вручную при многократном прослушивании исходного материала и одновременном наборе его в текстовых редакторах. Центральной задачей при этом становится восстановление текста, а также установление принадлежности реплик определенному лицу (при множестве лиц, участвовавших в разговоре) при помощи метода слухового исследования материала и проводится на базе аппаратуры и программных средств, предназначенных для воспроизведения фонограмм, усиления и коррекции акустических сигналов.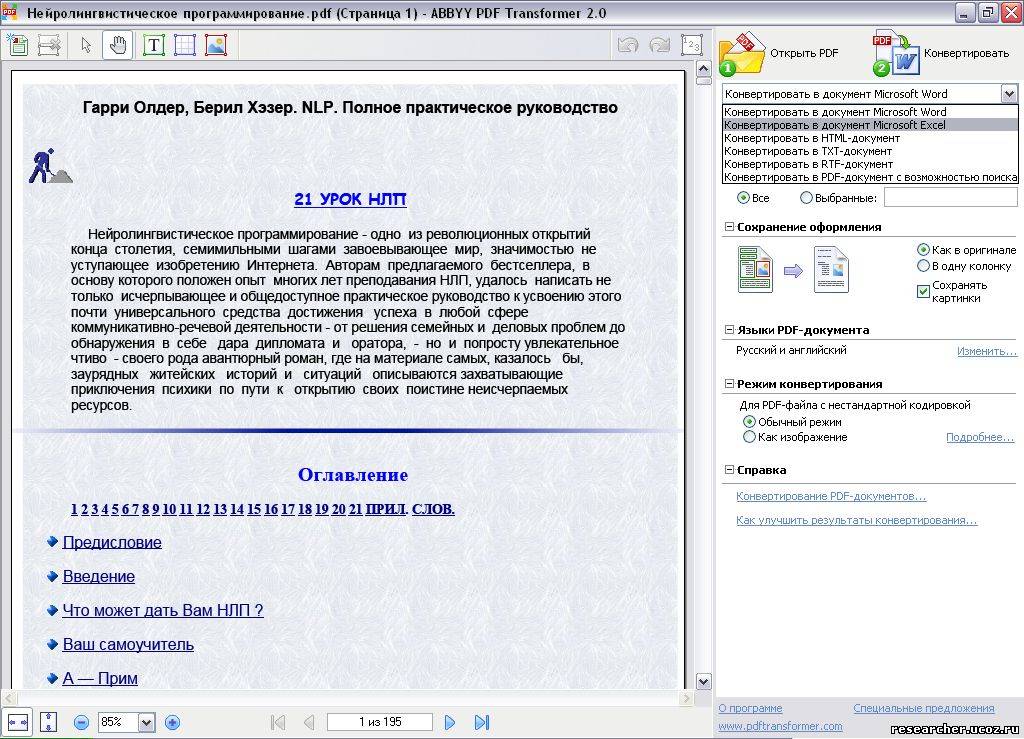
При этом не последнюю роль играет разборчивость речи, а именно, степень понимания речи слушателями. При низком качестве предоставленных аудиозаписей процесс усложняется в разы.
Как видно из всего вышеперечисленного, процесс по составлению стенограммы аудиозаписей достаточно трудоёмок и нередко требует усилий со стороны нескольких специалистов, как то: профессиональные расшифровщики, редакторы и корректоры.
В среднем у расшифровщика на транскрипцию десятиминутной фонограммы уходит примерно час.
Таким образом, за один день удаётся расшифровать приблизительно от 2-х до 4-х часов записи в зависимости от её качества. Распределяя полученный от заказчика материал между несколькими специалистами одного профиля, процесс расшифровки аудио в текст удаётся ускорить, а качество готовой стенограммы повысить.
Программы для преобразования голоса в текст
Незаменимыми помощниками в этом нелёгком деле выступают специальные программы, предназначенные для стенографирования аудиозаписей при их многократном прослушивании. Обычно данные программы снабжены текстовыми редакторами и аудиоплеерами с эквалайзерами. Они позволяют изменять скорость проигрывания записи, устанавливать временное кольцо повтора определённого фрагмента, а также зачастую обладают функциями шумоочистки.
Обычно данные программы снабжены текстовыми редакторами и аудиоплеерами с эквалайзерами. Они позволяют изменять скорость проигрывания записи, устанавливать временное кольцо повтора определённого фрагмента, а также зачастую обладают функциями шумоочистки.
Вот лишь несколько из множества программ для преобразования голоса в текст
Многие из этих программных средств можно скачать в интернете бесплатно. Только не будем забывать, что не одна программа не сможет заменить опытного специалиста. По крайней мере, пока.
лучше, дешевле, быстрее — Будущее на vc.ru
Человеческий голос – потрясающе мощный инструмент, способный передавать огромный спектр эмоций. Один тембр может заставить нас плакать от радости или печали, а другой – вогнать в сон от тоски и скуки. И все это определяется уникальными голосовыми связками и личностью говорящего, который точно доносит до нас информацию и эмоции. Именно поэтому талантливых актеров озвучки найти не так-то и просто, а сделать хороший аудио продукт стоит немалых денег и времени.
{«id»:124495,»url»:»https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree»,»title»:»\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435″,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree&title=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter. com\/intent\/tweet?url=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree&text=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree&text=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.
com\/intent\/tweet?url=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree&text=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree&text=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st. shareUrl=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435&body=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
shareUrl=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041e\u0437\u0432\u0443\u0447\u043a\u0430 \u0434\u043b\u044f \u043d\u043e\u0432\u043e\u0433\u043e \u043f\u043e\u043a\u043e\u043b\u0435\u043d\u0438\u044f: \u043b\u0443\u0447\u0448\u0435, \u0434\u0435\u0448\u0435\u0432\u043b\u0435, \u0431\u044b\u0441\u0442\u0440\u0435\u0435&body=https:\/\/vc.ru\/future\/124495-ozvuchka-dlya-novogo-pokoleniya-luchshe-deshevle-bystree»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
2019
просмотров
Давайте посмотрим на процесс поближе.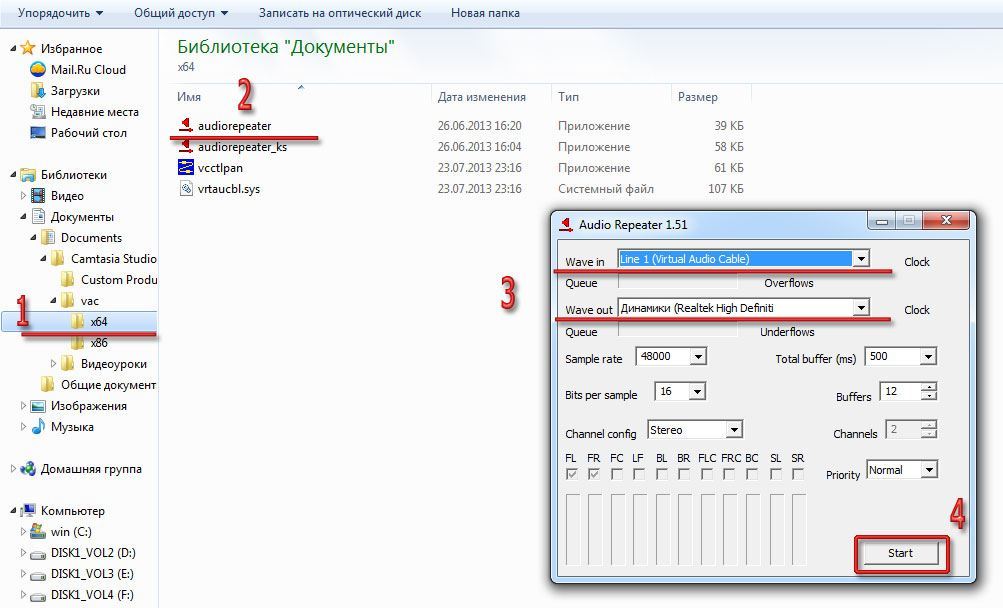 Для того, чтобы сделать качественную озвучку вам понадобится (как минимум) хорошая, профессиональная звукозаписывающая студия (а стоят они совсем недешево) и «окошко» в забитом расписании вашего любимого актера. В зависимости от объема будущего продукта это «окошко» может быть от пары часов до пары недель или даже месяцев – и за все это время вы будете платить арендную плату, зарплаты сотрудников, налоги, страховку и всякие прочие накладные расходы. Для того, чтобы записать книгу объемом примерно 350 страниц, вам придется выложить, по вполне скромным подсчетам, где-то в районе $1000-$5000. Добавим к этому монтаж, редактирование, повторную запись для исправления ошибок и прочее, и в результате получается вполне серьезное капиталовложение.
Для того, чтобы сделать качественную озвучку вам понадобится (как минимум) хорошая, профессиональная звукозаписывающая студия (а стоят они совсем недешево) и «окошко» в забитом расписании вашего любимого актера. В зависимости от объема будущего продукта это «окошко» может быть от пары часов до пары недель или даже месяцев – и за все это время вы будете платить арендную плату, зарплаты сотрудников, налоги, страховку и всякие прочие накладные расходы. Для того, чтобы записать книгу объемом примерно 350 страниц, вам придется выложить, по вполне скромным подсчетам, где-то в районе $1000-$5000. Добавим к этому монтаж, редактирование, повторную запись для исправления ошибок и прочее, и в результате получается вполне серьезное капиталовложение.
{«url»:»https:\/\/booster.osnova.io\/a\/relevant?site=vc»,»place»:»between_entry_blocks»,»site»:»vc»,»settings»:{«modes»:{«externalLink»:{«buttonLabels»:[«\u0423\u0437\u043d\u0430\u0442\u044c»,»\u0427\u0438\u0442\u0430\u0442\u044c»,»\u041d\u0430\u0447\u0430\u0442\u044c»,»\u0417\u0430\u043a\u0430\u0437\u0430\u0442\u044c»,»\u041a\u0443\u043f\u0438\u0442\u044c»,»\u041f\u043e\u043b\u0443\u0447\u0438\u0442\u044c»,»\u0421\u043a\u0430\u0447\u0430\u0442\u044c»,»\u041f\u0435\u0440\u0435\u0439\u0442\u0438″]}},»deviceList»:{«desktop»:»\u0414\u0435\u0441\u043a\u0442\u043e\u043f»,»smartphone»:»\u0421\u043c\u0430\u0440\u0442\u0444\u043e\u043d\u044b»,»tablet»:»\u041f\u043b\u0430\u043d\u0448\u0435\u0442\u044b»}},»isModerator»:false}
А что, если бы вам сказали, что этому процессу (и ценнику) существует прекрасная альтернатива, и что вы можете записать свою аудиокнигу всего за $100? Такое вообще возможно? А вот и да! Если в нашей повседневной жизни уже есть Алекса, Сири, Гугл-Ассистент и прочие виртуальные персонажи, помогающие нам выполнять различные бытовые задачи, то почему бы не взять примерно ту же самую идею и логически продолжить ее, в результате чего у вас под рукой окажется мощный, гибкий, но экономный инструментарий?
Несколько компаний-первопроходцев на сегодняшнем рынке уже делают именно это – они разрабатывают голосовых роботов, которые делают процесс быстрее, дешевле, и гораздо проще.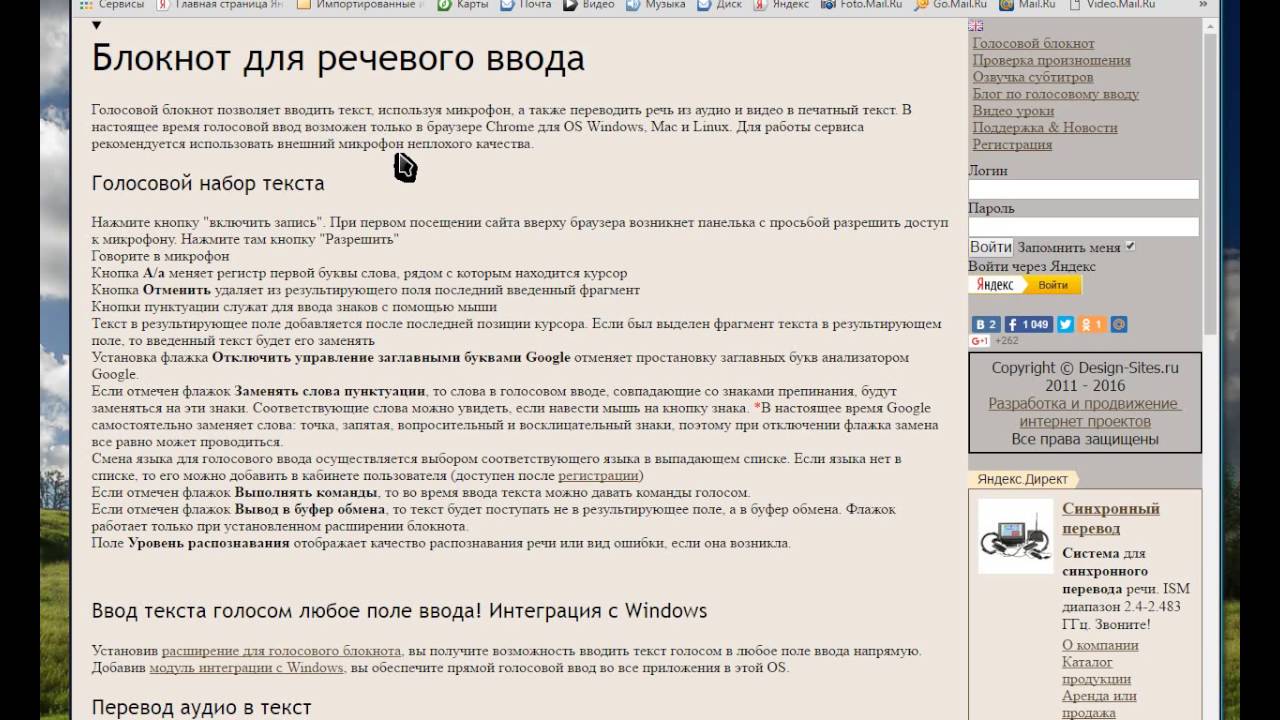 Независимо от того, какую конкретно технологию они используют – применяют ли они нейронные сети, искусственный интеллект или глубокое обучение; создают ли они голоса, звучащие как роботы из старого научно-фантастического фильма, или используют сэмплы человеческого голоса для создания более естественного, интуитивно приятного и понятного звука – их роботы, преобразующие текст в речь, могут использоваться в широком ряде ситуаций, от чтения новостей и работы операторов в колл-центрах до создания аудиокниг, предоставления моментального автоматического устного перевода и многого, многого другого.
Независимо от того, какую конкретно технологию они используют – применяют ли они нейронные сети, искусственный интеллект или глубокое обучение; создают ли они голоса, звучащие как роботы из старого научно-фантастического фильма, или используют сэмплы человеческого голоса для создания более естественного, интуитивно приятного и понятного звука – их роботы, преобразующие текст в речь, могут использоваться в широком ряде ситуаций, от чтения новостей и работы операторов в колл-центрах до создания аудиокниг, предоставления моментального автоматического устного перевода и многого, многого другого.
Среди компаний, занимающихся подобными разработками, есть такие гиганты как Амазон со своими проектом Polly и IBM, чьего робота зовут Watson – они создают недорогих высокопроизводительных роботов. Другие представители индустрии, как то, Acapela, ResponsiveVoice и ReadSpeaker, конкурируют в несколько другом сегменте рынка, в котором оплата базируется не на количестве преобразованных слов, а на годовой подписке. Каждый из таких продуктов имеет свои плюсы и минусы, использует разные подходы и в результате предоставляет пользователям разные уровни скорости, качества и цены, которые удовлетворяют потребности их соответствующей целевой клиентуры.
Каждый из таких продуктов имеет свои плюсы и минусы, использует разные подходы и в результате предоставляет пользователям разные уровни скорости, качества и цены, которые удовлетворяют потребности их соответствующей целевой клиентуры.
Тем временем, мы в компании Amai стараемся решить весь спектр этих задач. Большинство наших конкурентов предлагают роботы-голоса на частоте всего лишь 22 kHz, а мы сделали продукт, который работает на частоте 44 kHz. В результате получается кристально-чистый звук, без шума и искажений – и все это с естественными человеческими интонациями.
Для того, чтобы этого добиться, для начала мы берем файлы голосов профессиональных актеров и дикторов, записанные в самом высоком возможном качестве. Затем мы тренируем свои модели при помощи технологий искусственного интеллекта и понимания естественного языка. Получившиеся в результате роботы способны понимать пунктуацию – запятые, знаки вопроса, восклицательные знаки, – что позволяет им воспроизводить нюансы и интонации естественной человеческой речи. Мы также постоянно наращиваем скорость синтеза речи и совершенствуем качество нашего продукта.
Получившиеся в результате роботы способны понимать пунктуацию – запятые, знаки вопроса, восклицательные знаки, – что позволяет им воспроизводить нюансы и интонации естественной человеческой речи. Мы также постоянно наращиваем скорость синтеза речи и совершенствуем качество нашего продукта.
Пример голоса
Давайте теперь обратимся к приведенному выше примеру аудиокниги. В старой парадигме процесс записи аудиокниги объемом примерно 350 страниц (около 1 миллиона знаков) занял бы у вас и вашей команды примерно 2 недели и обошелся бы в $1000-$5000. При помощи роботов Amai вы сможете ее записать всего за день (а это уже гигантская экономия времени), сидя за своим собственным компьютером, заплатив за весь проект всего лишь $99. Что еще нужно для счастья?
И если все это вам кажется неправдоподобным, то это только потому, что вы еще слышали наших роботов. Послушайте, посмотрите, попробуйте поиграть с настройками нашего демо – и сравните их с голосами наших конкурентов.
Послушайте, посмотрите, попробуйте поиграть с настройками нашего демо – и сравните их с голосами наших конкурентов.
О способах перевода аудио и видео в текст
Автор: Николай Шмичков, агентство SEOQUICK
Знаете ли вы, что переписывая видео или аудио, можно значительно улучшить SEO-показатели? Для этого нужно транскрибировать материалы, которые вы регулярно публикуете на своем сайте или в блоге: различные семинары, обзоры и т.д. Если снабдить их соответствующими комментариями, можно получить некоторые преимущества перед конкурентами.
Аналитик Джон Мюллер подтвердил, что предоставление расшифровки улучшит индексирование аудиовизуального контента и сделает его более понятным.
Преимущества транскрибирования мультимедийного контента
Расшифровка записей увеличивает доступность восприятия контента. Это происходит от того, что у значительной части интернет-пользователей довольно плохая скорость воспроизведения аудио и видео, либо они лучше воспринимают информацию в виде текста. Кроме того, не нужно забывать о значимости текстовых факторов для поисковых систем. Несмотря на очевидную пользу транскрибирования, многие отказываются от него, ссылаясь на отсутствие средств и возможностей.
Это происходит от того, что у значительной части интернет-пользователей довольно плохая скорость воспроизведения аудио и видео, либо они лучше воспринимают информацию в виде текста. Кроме того, не нужно забывать о значимости текстовых факторов для поисковых систем. Несмотря на очевидную пользу транскрибирования, многие отказываются от него, ссылаясь на отсутствие средств и возможностей.
Прежде чем приступить к расшифровке записей, посмотрите полезную статью о том, как правильно подавать видео на ресурсе.
Как транскрибирование влияет на трафик?
Во-первых, трафик увеличивается. Многие радио- и телеканалы давно заметили, как интерес к их контенту возрос именно после создания текста ко всем материалам. Очень большая часть посетителей, нашедших сайт посредством поисковика, посещают именно страницы со стенограммами. Это способствует увеличению входящего трафика и увеличению входных ссылок.
Во-вторых, страницы с затранскрибированным текстом приносят в среднем на 16% больше просмотров, чем остальные. Транскрибирование не просто удобно для пользователя, оно является действенной тактикой в SEO-оптимизации.
Транскрибирование не просто удобно для пользователя, оно является действенной тактикой в SEO-оптимизации.
Способы транскрибирования материала
Для этого можно воспользоваться тремя способами:
- ручным;
- автоматическим;
- DIY
Автоматическая расшифровка
Автоматические средства по расшифровке записей включают в себя технологии по распознаванию речи или аудио в тексте, текстовое программное обеспечение и интерфейсы прикладных программ (API для транскрипции). С их помощью можно получить текст из звукового файла без усилий со стороны пользователя. Однако они не могут обеспечить абсолютную точность и будут требовать вмешательства и проверки. Чтобы понять, о чем речь, включите субтитры в видео из Youtube.
Оплошности при создании текстового материала возникают по ряду причин:
- специфический акцент;
- дефекты речи;
- помехи при записи;
- диалект;
- сленг.
При наличии подобных факторов, тому, кто транскрибирует текст, нужно будет снова его проработать на предмет несоответствий и ошибок.
К счастью, технологии совершенствуются, и с каждым днем инструменты становятся все лучше. С их помощью можно добиться точности в 80% или даже 90%, что, несомненно, экономит время на корректировку.
Ручная расшифровка
С одной стороны, ручная расшифровка предполагает выполнение работы самостоятельно без использования каких-либо вспомогательных программ. Единственное используемое программное обеспечение при этом способе транскрибирования – текстовый редактор.
Точность такого способа максимально высокая. Тем не менее, современные инструменты, которые используют машинное обучение, искусственный интеллект и методы сегментации, теперь могут производить тексты с примерно такой же точностью, что и люди.
DIY расшифровка
DIY (Do-It-Yourself – «сделай сам») метод используется, в основном, для быстрого выполнения поставленной задачи. Работу делят между несколькими людьми. Например, часовой подкаст можно разделить между четырьмя людьми. Уже в течение дня будет готов текст. Но важный нюанс такого метода состоит в индивидуальности каждого исполнителя. Это связано с особенностями подхода к выполнению работы, которые невозможно игнорировать.
Но важный нюанс такого метода состоит в индивидуальности каждого исполнителя. Это связано с особенностями подхода к выполнению работы, которые невозможно игнорировать.
Выбор любого из представленных методов зависит от ваших возможностей, ресурсов и особенностей текста.
Теперь рассмотрим собственно сами способы транскрибирования аудио и видеоконтента.
1. Бесплатные сервисы и инструменты для транскрибирования онлайн
Одним из способов расшифровки аудио- или видеозаписей является использование бесплатных онлайн-инструментов. Их легко найти, просто вбив запрос «бесплатные онлайн-инструменты транскрипции» в Google. Вы увидите огромное количество вариантов, среди которых и oTranscribe, Trint, Speechlogger.
GoogleDocs также предлагает воспользоваться своей бесплатной онлайн-системой транскрибирования под названием GoogleVoiceTyping. Чтобы получить к ней доступ, нужно зайти в GoogleDocs> Инструменты> Голосовой ввод или нажать Ctrl + Shift + S.
Такой полезный инструмент может дать почти 100% результат, если говорящий будет произносить текст максимально четко и медленно, чтобы система успевала уловить все особенности речи.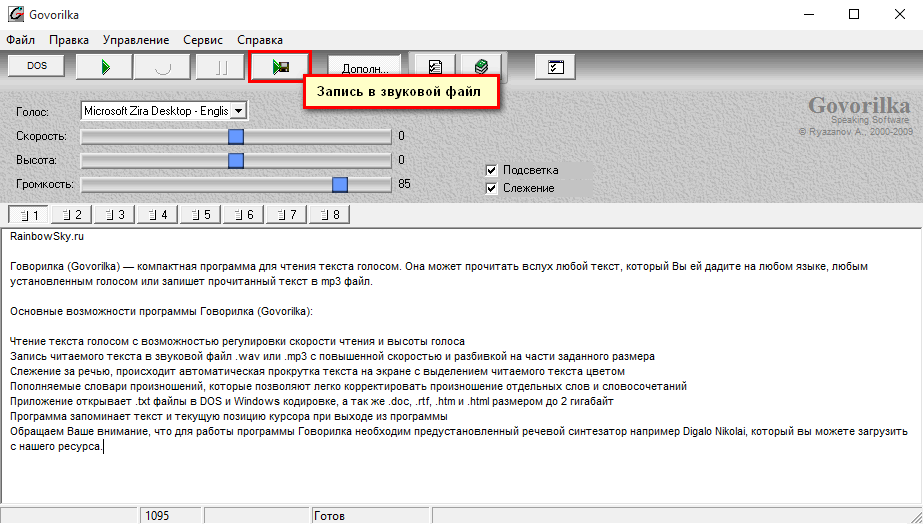 Но если нет возможности контролировать говорящего или динамику произношения, эти бесплатные ресурсы будут во многом ограничены. Отметим еще раз – запись одного голоса будет качественнее.
Но если нет возможности контролировать говорящего или динамику произношения, эти бесплатные ресурсы будут во многом ограничены. Отметим еще раз – запись одного голоса будет качественнее.
Не забудьте проверить и отредактировать получившийся текст!
Поисковая система Google установила строгие правила касаемо «автоматически сгенерированного текста». Неотредактированный текст может быть отнесен к спаму, что обязательно приведет к плохому месту в выдаче.
Еще одно замечание: инструменты онлайн-расшифровки требуют постоянного подключения к интернету. Поэтому если вы работаете в дороге без постоянного соединения, они вам не подойдут.
2. Бесплатное программное обеспечение
Принцип работы подобных инструментов в основном такой же, как и в первом способе. Основное различие заключается в том, что вы можете загрузить и установить их на свой компьютер, чтобы позволяет работать без подключения к сети. Примеры таких программ: Transcriber, ExpressScribe, MacSpeechScribe.
3. Автоматический ввод субтитров в Youtube
Субтитры на Youtube не всегда оправдывают ожидания, но такой способ имеет право на существование:
Ошибки, как в примере, возникают нечасто, но могут смутить и привести к неправильному пониманию. Если видеоролики будут с чистым и четким звуком, речь в них — медленной и без акцента, то можно получить вполне удовлетворительное качество.
Не исключайте того факта, что всегда контролировать звук и динамику не получится. Особенно это касается расшифровки переговоров, конференций или мероприятий, где много фоновых шумов и разговоры перекрывают друг друга. В остальных записях, если учитывать приведенные рекомендации и придерживаться правила строгой очередности, будет минимальное количество ошибок.
5. Мобильные приложения для расшифровки записей
В Android и AppleStore есть много приложений, которые помогут расшифровать записи при помощи телефона. Просто откройте свой магазин приложений и введите запрос «перевести голос в текст».
Приложения для мобильной транскрибации лучше всего подходят для журналистов и корреспондентов, которые всегда в движении и часто делают личные интервью или отчеты с места действия.
Кроме того, большинство современных смартфонов и компьютеров также оснащены собственной технологией распознавания речи. В самом обычном смартфоне можно открыть встроенное приложение блокнота и нажать значок микрофона или другую специальную кнопку, которая приведет в действие алгоритм для распознавания речи. После того, как вы начнете диктовать, система начнет переводить речь в текст и отображать ее в блокноте.
У Microsoft и Mac есть собственные программы для распознавания речи, известные как Windows Speech Recognition и Dictation.
Чтобы получить доступ к инструменту Microsoft, просто зайдите в панель поиска Windows и введите «Распознавание речи Windows». Когда он включен, вы можете открыть текстовый редактор и поместить курсор туда, где должен появиться продиктованный текст.

Недавно компания Microsoft объявила, что их система распознавания речи выдает только 5,1% ошибок. Такой процент есть и при ручной расшифровке.
Как видим, результаты не безупречные, но и не такие уж плохие.
Что касается надиктовки на Mac, то пользователи могут настроить его, перейдя к: Меню Apple> Системные настройки> Клавиатура> Диктовка.
Отсюда можно включить диктовку и заполнить всю необходимую информацию, такую как языковые настройки и сочетание клавиш.
Уникальность технологичного решения заключается в продуманном и удобном интерфейсе. Пользователь может настроить систему под особенности своей речи, чтобы восприятие звука было максимально четким и адекватным. Также к безусловным удобствам можно отнести расстановку знаков препинания. Для этого нужно просто произнести следующие слова, например:
- апостроф ‘
- открывающая скобка [
- закрывающая скобка ]
- открывающая фигурная скобка {
- и т. д.
 д.
д.Отметим, что инструмент от Windows может функционировать без подключения к интернету. В Mac, напротив, нужно будет выбирать опцию Enhanced Dictation, потому что программа распознавания речи по умолчанию нуждается в запуске сети.
6. Google Cloud Speech API
Это сервис для распознавания речи более чем с 110 языков, благодаря чему он стал одним из самых популярных. Считается, что инструмент значительно превосходит по качеству оцифровки звуковых записей другие софты и совершает наименьшее количество ошибок. Но как известно за качество нужно платить, поэтому после часа бесплатного транскрибирования аудио потребуется платная подписка.
7. Наемные работники или DIY
Как вы уже поняли, хорошие средства для транскрибирования обойдутся недешево. Цена на них варьируется от 50 до 150$. Специализированные компании без проблем могут позволить себе такие траты на профессиональное программное обеспечение. Но если нет цели оцифровывать аудио в огромных количествах, то ручной метод прекрасно подойдет. Расшифровка учебных материалов или интервью без специальных инструментов будет также недорогой.
Расшифровка учебных материалов или интервью без специальных инструментов будет также недорогой.
Нанять исполнителя задания можно на многих ресурсах, где фрилансеры предлагают свои услуги. Цену укажите фиксированную за знаки или минуты или устройте что-то вроде тендера, и посмотрите, кто предложит лучшие условия сотрудничества. Только помните известную поговорку: «Цена соответствует качеству».
Не стоит забывать, что могут попасться и недобросовестные исполнители. Проверка профиля, истории заказов, резюме и отзывов спасет от ряда неприятностей.
Конфиденциальную информацию для расшифровки лучше отдавать для выполнения специализированным компаниям. Они смогут гарантировать клиентам безопасность и защиту данных. Стоимость определяется непосредственно исполнителем в зависимости от ряда факторов.
Заключение
Расшифровка аудио- и видеозаписей приносит увеличение трафика и повышает привлекательность страницы. Выбор способа транскрибирования зависит от ваших возможностей, платежеспособности и качества звука.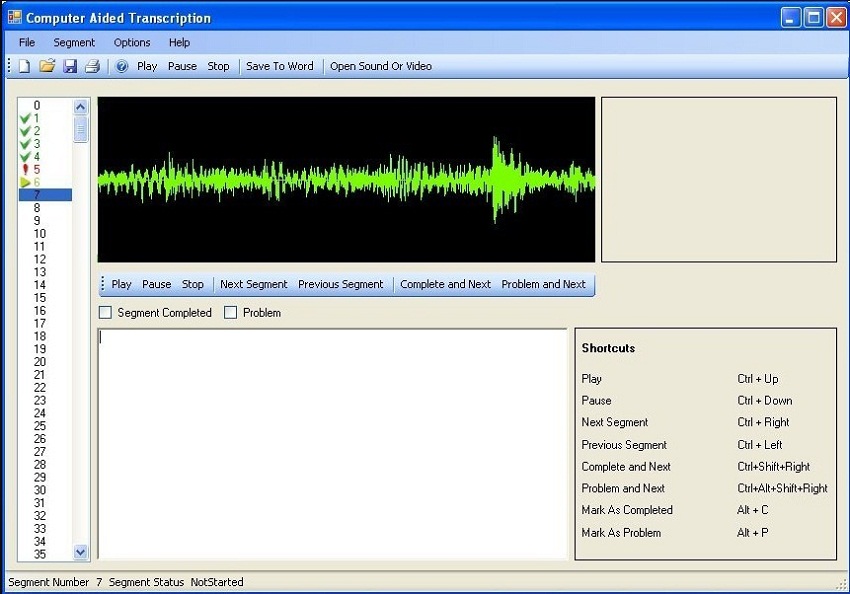
Качественное и профессиональное исполнение расшифровки стоит достаточно дорого, хотя можно прибегнуть к помощи наемного работника, который готов будет выполнить работу дешевле. Однако помните, что за хорошее качество лучше заплатить реальную цену.
Транскрибация: ещё один способ заработка в сети
Проще говоря, транскрибация — это расшифровка аудио и видеозаписей для дальнейшего перевода их в текст. На биржах фриланса подобный вид заработка довольно распространён, поскольку не требует особых навыков, кроме грамотного написания текста, слепой печати и большого количества свободного времени.
При переводе звука в текст следует учитывать множество факторов для совершения корректной транскрибации.
- Не переносить в текст слова-паразиты, обрывочные фразы, не несущие смысла, междометия и частицы, часто возникающие в речевых паузах;
- Заносить тайм-код (если требуется) тех слов, которые невозможно было разобрать на слух из-за плохого качества записи;
- Транскрибировать записи, учитывая специфику содержания в записи. Политические дебаты, многочасовые совещания депутатов и видео о том, как правильно что-то делать будут транскрибироваться по-разному;
- Перед транскрибацией следует ознакомиться с правилами транскрибирования определённых жанров;
Также не стоит забывать о том, что тайм-коды, которые иногда заказчик просит перенести на текст, должны внешне отличаться от тайм-кодов для нераспознанных слов. Например, обычное время можно указать в квадратных скобках, а время для нераспознанных слов — в круглых.
Транскрибация может быть не только ручной, но и автоматизированной. Конечно, второй способ кажется более предпочтительным, но всё же требует ручной доработки. В этом случае запись подаётся на вход программе, преобразующей речь в текст. На выходе получается неплохой черновой вариант записи. Почему черновой?
- Записи плохого качества плохо переводятся в текст;
- Могут не учитываться знаки препинания;
- При плохой работе Интернета возможен неккоректный перевод в текст, если запись проводится онлайн;
В любом случае, полученный вторым способом текст следует пересмотреть, повторно включив запись.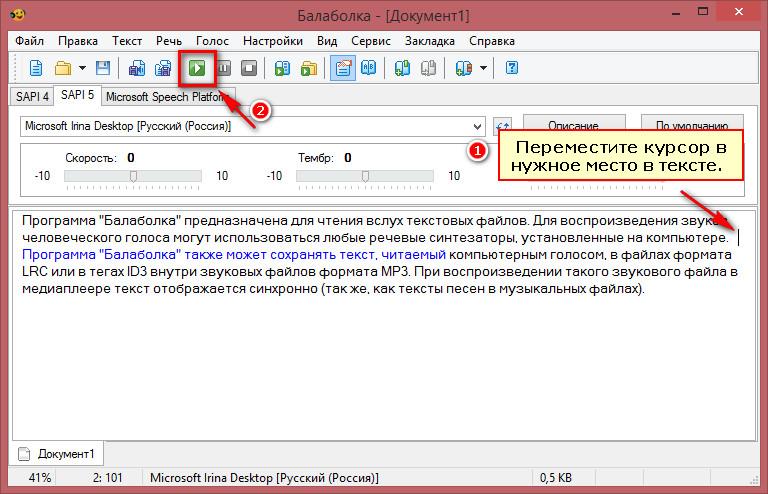 Использовать для машинной обработки записей можно огромное число утилит, например, голосовой блокнот Speechpad от Google.
Использовать для машинной обработки записей можно огромное число утилит, например, голосовой блокнот Speechpad от Google.
Следует помнить, что транскрибирование на открытых биржах фриланса, где много конкуренции, стоит довольно дёшево и на этом довольно проблематично хорошо заработать. Зато с этого можно начать путь фрилансера, чтобы прощупать почву и понять, стоит ли двигаться дальше в этом направлении или нет.
поделитесь с друзьями:
ВКонтакте
OK
Эта программа для транскрибации позволит упростить процесс в несколько раз
Перевод аудио в текст в модуле транскрибирования основывается на подаче звука с колонок на микрофон. Это можно достичь либо, положив микрофон к колонкам, либо посредством аудио кабеля, как физического, так и виртуального. Можно также использовать стерео микшер.
Транскрибирование звуковых файлов длинной более 15 минут относится к расширенным возможностям блокнота. За них взимается небольшая плата. Чтобы попробовать или оплатить ее, нужно зарегистрироваться на сайте и зайти в кабинет пользователя голосового блокнота (появится оранжевая ссылка).
За них взимается небольшая плата. Чтобы попробовать или оплатить ее, нужно зарегистрироваться на сайте и зайти в кабинет пользователя голосового блокнота (появится оранжевая ссылка).
Панель перевода аудио в текст открывается после нажатия на кнопку +Транскрибацию
на главной странице сайта.
На приведенной картинке я обвел красным то что относится к этому модулю и перечеркнул, то что использовать вместе с ним не надо. То есть не нужно включать флажки
вывод в буфер
и
интеграции
. Поле
Длина буфера фраз
не дает накапливаться тексту в поле предварительного просмотра (актуально при использовании виртуальных или физических кабелей).
Переключатель Защита от шумов
используется для борьбы с зависанием ввода в шумных видео. Хорошей альтернативой этому переключателю является установка переключателя
Пауза в речи
, например, в одну секунду. Переключатель
Пауза в речи
можно сделать видимым в настройках интерфейса кабинета пользователя.
Для загрузки видео с Youtube в модуль нужно ввести его ID.
Транскрибирование может вестись в двух режимах, зависящих от установки флажка Запускать синхронно с записью
. Когда этот флажок включен, то нажатие на кнопку
включить запись
одновременно включает проигрыватель, а
остановить запись
— останавливает его.
Весь алгоритм работы в этом случае заключается: 1) в загрузке ролика или файла в проигрыватель 2) обеспечению поступления звука с ролика на микрофон 3) Выставлению настроек, отметке флажка вставлять метки времени
3) нажатию на кнопку запуска.
Если флажок Запускать синхронно с записью
не установлен то появляется панель задания времен паузы и работы.
При таком режиме кнопка включить воспроизведение
запустит проигрыватель в прерывистом режиме, то есть после 5 секунд (как задано на нашем рисунке) воспроизведения он будет останавливаться на 5 секунд паузы. Кнопка же
включить запись
от нее не зависит. Если время паузы и время воспроизведения не установлены, то работает просто кнопка
Если время паузы и время воспроизведения не установлены, то работает просто кнопка
включить/отключить воспроизведение
.
Такой режим может быть использован для полуавтоматического транскрибирования. При этом режиме роль виртуального аудио кабеля играет человек — он прослушивает запись в течении времени воспроизведения и надиктовывает ее в течение времени паузы.
Системы распознавания речи и транскрибация
Проблема создания системы распознавания речи получила развитие в 1952 году, когда была продемонстрирована первая попытка в истории человечества распознать голосовую команду.
Система Audrey американской могла распознать только цифры, произнесенные мужским голосом с определенным интервалом, но это стало настоящим прорывом.
С тех пор утекло много воды, лучшие умы бились над задачей научить компьютер понимать речь. Впереди планеты всей в этом вопросе оказались Google с функцией распознавания речи в браузере Chrome и Apple со своей программой Siri – оба события пришлись на 2011 год.
Сегодня выбор программ, автоматически преобразующих устную речь в письменный текст, довольно внушительный и для компьютеров, и для смартфонов, они постоянно совершенствуются, но все же для полноценной транскрибации не подходят.
Проблема таких программ в их требованиях к качеству звука. К сожалению, четкая речь без мусора и отсутствие посторонних шумов – редкое явление в работе транскрибатора. А несколько спикеров превращают итоговый текст в малопонятную кашу, на редактуру может уйти слишком много времени.
Жмите на кнопку и получите Текстовый отчет:
Руководство по автоматической транскрипции
Руководство по автоматической транскрипции
Как автоматически транскрибировать любое аудио или видео (локальное или онлайн) с помощью наиболее точной автоматической транскрипции, работающей на механизмах преобразования речи в текст Google.
Перейдите на веб-страницу Speechnotes Files по адресу
https://speechnotes. co/files/
co/files/
Нажмите «ВОЙТИ» и войдите, используя свою учетную запись Google. Не нужно запоминать новые пароли. Speechnotes не получит ваш пароль — он останется приватным — он получит только ваш адрес электронной почты и подтверждение от Google, что вы действительно вошли в систему.Войдите, используя свою учетную запись gmail
После входа в систему вы увидите приветственное сообщение с вашим именем. Там вы увидите две основные кнопки действий, которые вам нужны. Первый — загрузить кредитные минуты для расшифровки. Нажмите кнопку «ДОБАВИТЬ КРЕДИТ», как показано на изображении ниже.
Нажмите «ДОБАВИТЬ КРЕДИТ», чтобы открыть диалоговое окно покупки.
Затем откроется диалоговое окно покупки, в котором вы можете выбрать, сколько минут вы хотите приобрести. Это метод предоплаты, при котором неиспользованные минуты остаются на вашем счете для будущих заданий по транскрипции.Диалог покупки. Выберите сколько минут.
После покупки вы увидите добавленные и обновленные кредитные минуты на главном экране.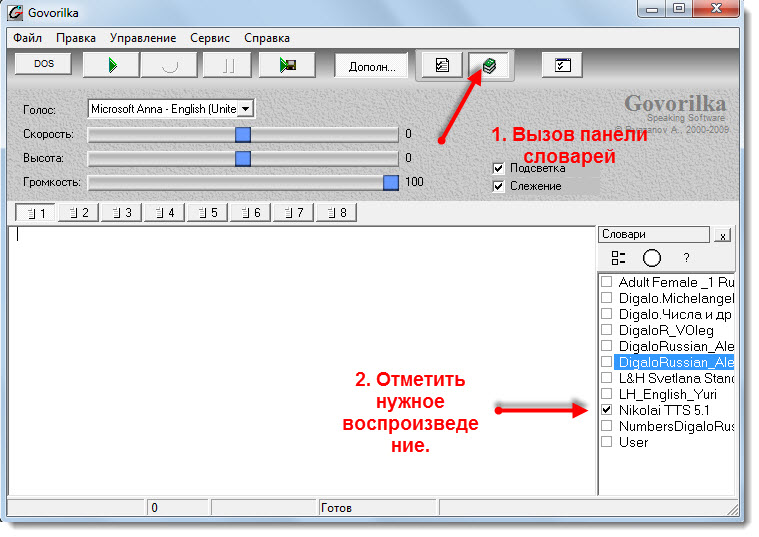 Выполнение платежа и обновления может занять несколько секунд.
Выполнение платежа и обновления может занять несколько секунд.
Обратите внимание: для вашего удобства мы принимаем платежи как с PayPal, так и с кредитных карт, что бы вы ни выбрали. Платежи защищены и обрабатываются PayPal.
Затем — последний шаг — просто загрузите файл. Speechnotes-Files принимает большинство типов аудио и видео файлов.Хотя для вашего удобства гораздо предпочтительнее загружать аудиофайлы, а не видео, так как видео намного больше по размеру. Это означает, что загрузка видеофайла может занять гораздо больше времени и данных (если вы используете мобильный телефон), чем загрузка только аудио части. Таким образом, если загрузка видеофайла происходит слишком медленно или вообще не выполняется из-за прерываний, рекомендуется извлечь аудио из видео и загрузить только аудио часть.
Кнопка загрузки
Затем откроется диалоговое окно загрузки, в котором вы можете выбрать свой файл, выбрать язык аудио в записи и, при необходимости, ввести. Диалог загрузки
Диалог загрузки
Для вашего удобства вы можете либо загрузить файл, хранящийся на вашем локальном диске, либо — вы можете просто вставить URL-адрес в файл в Интернете или даже обычную ссылку на YouTube. URL-адрес может быть прямым URL-адресом аудио- или видеофайла, YouTube или URL-адреса Google Диска. Если ваши файлы уже есть на Google Диске — то это предпочтительный вариант. Обратите внимание, что ссылки на Google Диск ограничены размером файла 100 МБ.
Обратите внимание: если вы выбрали передачу URL-адреса Google Диска, убедитесь, что размер файла меньше 100 МБ, и что он действительно общедоступен и доступен по этой ссылке, поскольку мы не запрашиваем конкретное разрешение для доступа к нему.Вот как получить общедоступный URL-адрес файла на Drive
Для вашего удобства вы даже можете загрузить несколько файлов одновременно или отправить несколько ссылок одновременно. Если вы отправляете несколько ссылок, разделите их запятыми.
Результаты расшифровки
Результаты появятся через несколько минут после завершения загрузки на вашей панели управления по адресу https://speechnotes. co/files/
co/files/
Для вашего удобства вы получите уведомление по электронной почте.
Свяжитесь с нами
По всем вопросам обращайтесь к нам по телефону admin @ speechlogger.com
Автоматически извлекать аудио из видео файлов
Автоматически извлекать аудио из видео файлов
Используется для больших видеофайлов, чтобы уменьшить размер и время загрузки
Выберите вашу операционную систему:
Win 64 бит
Win 32 бит
Mac
Если у вас 64-разрядная версия Windows, выполните следующие действия:
- Нажмите следующую кнопку, чтобы загрузить файл
.zipс именемspeechnotes_ffmpeg.zip - Копия
speechnotes_ffmpeg.zipна жесткий дискC - Распакуйте zip-файл.
- Убедитесь, что теперь у вас есть папка с именем
speechnotes_ffmpegпрямо на жестком дискеC. Если да — продолжай. - Нажмите следующую кнопку, чтобы загрузить файл
.batс именемspeechnotes_audio_extractor.bat - Скопируйте
speechnotes_audio_extractor.batв любой каталог, содержащий видеофайлы, из которых вы хотите извлечь звук. - Дважды щелкните скопированный файл
speechnotes_audio_extractor.bat, чтобы запустить его. Он должен автоматически открывать окно командной строки и запускаться там. - После завершения создается папка с именем
speechnotes-output-audio-only, в которой находится весь извлеченный звук только из видео. - Есть еще видео файлы в другом каталоге? Просто повторите ‘Скопируйте
speechnotes_audio_extractor.batв любой каталог… ‘ и далее с другим каталогом.
 Если да — продолжай.
Если да — продолжай.Расширенные примечания
Поддерживаемые видеофайлы
У вас нет жесткого диска C?
Вы можете использовать другой диск, но вам придется отредактировать файл . bat и заменить каждый «C: //» на выбранный вами диск.
bat и заменить каждый «C: //» на выбранный вами диск.
Если у вас 32-разрядная версия Windows, выполните следующие действия:
- Нажмите следующую кнопку, чтобы загрузить файл
.zipс именемspeechnotes_ffmpeg.zip - Копия
speechnotes_ffmpeg.zipна жесткий дискC - Распакуйте zip-файл.
- Убедитесь, что теперь у вас есть папка с именем
speechnotes_ffmpegпрямо на жестком дискеC. Если да — продолжай. - Нажмите следующую кнопку, чтобы загрузить файл
.batс именемspeechnotes_audio_extractor.bat - Скопируйте
speechnotes_audio_extractor.batв любой каталог, содержащий видеофайлы, из которых вы хотите извлечь звук. - Дважды щелкните скопированный файл
speechnotes_audio_extractor.bat, чтобы запустить его. Он должен автоматически открывать окно командной строки и запускаться там. - После завершения создается папка с именем
speechnotes-output-audio-only, в которой находится весь извлеченный звук только из видео. - Есть еще видео файлы в другом каталоге? Просто повторите ‘Скопируйте
speechnotes_audio_extractor.batв любой каталог… ‘ и далее с другим каталогом.

Расширенные примечания
Поддерживаемые видеофайлы
У вас нет жесткого диска C?
Вы можете использовать другой диск, но вам придется отредактировать файл .bat и заменить каждый «C: //» на выбранный вами диск.
Выполните следующие действия, если вы используете Mac
* Обратите внимание, что эти инструкции потребуют от вас работы с терминалом командной строки. Это очень просто — мы проведем вас через каждый шаг — так что, пожалуйста, с нами.*
Открытый терминал
На вашем Mac выполните одно из следующих действий:
- Щелкните значок Launchpad в Dock / или запустите «Поиск Spotlight», введите «Терминал» в поле поиска, затем щелкните «Терминал».
- В Finder откройте папку / Applications / Utilities, затем дважды щелкните «Терминал».

Установите ffmpeg. Если он у вас уже есть — переходите прямо к Got ffmpeg — позволяет извлечь часть аудио
Проверьте, установлен ли ffmpeg на вашем Mac:
В открывшемся Терминале введите
ffmpeg -version
и нажмите «Enter».
Если вы получили ответ: -bash: ffmpeg: command not found , значит, у вас НЕТ. В противном случае — оно у вас. Если он у вас уже есть — переходите прямо к Got ffmpeg — позволяет извлечь часть аудио.
— у меня нет ffmpeg. Установим.
Сначала еще одна проверка — давайте проверим, установлен ли у вас Homebrew на вашем Mac:
В открывшемся Терминале введите
brew -v
и нажмите «Enter».
Если вы получили ответ: -bash: brew: command not found , значит, у вас его НЕТ.В противном случае — оно у вас.
Если у вас его нет, просто установите его, скопировав следующее в свой терминал (нажмите «Enter» после вставки в терминал):
/ bin / bash -c "$ (curl -fsSL https://raw. githubusercontent.com/Homebrew/install/master/install.sh)"
githubusercontent.com/Homebrew/install/master/install.sh)"
После установки brew введите в Терминал следующее:
brew install ffmpeg
После установки — продолжить:
Получил ffmpeg — позволяет извлечь аудио
- Откройте терминал в той папке, где находятся ваши видео файлы.Один простой способ сделать это:
- Введите (без Enter)
cd & nbsp(обратите внимание на «пробел» после «cd»), а затем - Перетащите из Finder папку, содержащую видеофайлы, в Терминал
- Нажмите «Ввод»
- Теперь вы должны увидеть имя этого каталога в новой строке, в которой находится каретка Терминала.
- Введите (без Enter)
- В терминале скопируйте следующее и нажмите «Enter»:
echo "Создание каталога вывода-вывода-аудио для speechnotes"
mkdir -p speechnotes-output-audio-only
echo "Успешное создание каталога вывода-вывода-звука speechnotes"COUNTER = 0;
echo "Поиск видео файлов в каталоге"
для ввода в *. avi * .mp4 * .mpeg * .mov; do
# ffmpeg -i "$ input" -vn -acodec copy "speechnotes-output-audio-only / $ input"
if [-f "$ input"]; тогда
COUNTER = $ ((COUNTER + 1))
echo "Найдено и преобразовано $ input"
ffmpeg -i "$ input" -vn -acodec copy "speechnotes-output-audio-only / $ input" -nostdin -loglevel panic
fi
done
echo "Готово. Найдено всего $ COUNTER Видео файлы в каталоге" - Теперь вы должны были создать папку с именем «speechnotes-output-audio-only», в которой находятся только аудиофайлы.Поздравляю.
- Есть еще видеофайлы для преобразования в другом каталоге? Просто повторите Got ffmpeg — позволяет извлечь аудио в любой каталог, который вам нужен. Не нужно снова устанавливать brew или ffmpeg.
 avi * .mp4 * .mpeg * .mov; do
avi * .mp4 * .mpeg * .mov; do Свяжитесь с нами
По всем вопросам обращайтесь к нам по адресу [email protected]
15 лучших бесплатных программ преобразования речи в текст для Windows, Android, iOS и Mac
На рабочем месте эффективность имеет решающее значение для успеха. Чем быстрее вы добьетесь результатов, тем больше сможете сосредоточиться на улучшении более стратегических аспектов своей работы. Однако физическая расшифровка аудиозаписей, личных заметок, идей для вербального мозгового штурма и других документов — утомительная и трудоемкая задача, которая серьезно влияет на уровень умственных способностей, которые вы можете применить к другим видам деятельности. К счастью, существует технология преобразования речи в текст. Это позволяет вам печатать без рук и использовать свой голос для создания документов.В этой статье мы обсуждаем лучшее программное обеспечение для преобразования речи в текст, доступное сегодня в различных категориях решений для машинного обучения.
Чем быстрее вы добьетесь результатов, тем больше сможете сосредоточиться на улучшении более стратегических аспектов своей работы. Однако физическая расшифровка аудиозаписей, личных заметок, идей для вербального мозгового штурма и других документов — утомительная и трудоемкая задача, которая серьезно влияет на уровень умственных способностей, которые вы можете применить к другим видам деятельности. К счастью, существует технология преобразования речи в текст. Это позволяет вам печатать без рук и использовать свой голос для создания документов.В этой статье мы обсуждаем лучшее программное обеспечение для преобразования речи в текст, доступное сегодня в различных категориях решений для машинного обучения.
Список 5 лучших программ для свободного преобразования текста в текст
Вот список из пяти лучших программ для преобразования речи в текст, доступных в Интернете.
1) Converse Smartly
Мы включили Converse Smartly в этот список лучших программ для преобразования текста в текст благодаря своей мощной и надежной технологии. Он может быстро и точно преобразовать любой аудиопоток в текст, включая диалоги или беседы с командных встреч, конференций, интервью и семинаров.Это позволяет организациям и частным лицам работать быстрее, эффективнее и точнее.
Он может быстро и точно преобразовать любой аудиопоток в текст, включая диалоги или беседы с командных встреч, конференций, интервью и семинаров.Это позволяет организациям и частным лицам работать быстрее, эффективнее и точнее.
Созданный Folio3, основная цель Converse Smartly — повысить эффективность рабочего процесса любой организации. Приложение использует передовую технологию распознавания речи на основе IBM Watson Speech API и набора инструментов обработки естественного языка и является одним из лучших программ преобразования текста в речь с естественными голосами. Основные функции включают:
— Анализ речи
— Анализ текста
— Генерация сводки
— Выполнение анализа тональности
— Создание облака слов из вводимой речи и письма
— Определение ключевых сущностей и тем во время речи или разговора
— Транскрипция звука в реальном времени
— Обнаружение нескольких динамиков
— Ключевые слова
Совместимость: Любое устройство с подключением к Интернету, браузером и подключением к Интернету
Цена: Бесплатная пробная версия
Ссылка на демонстрацию: https: // www. folio3.ai/converse-smartly-try-now/
folio3.ai/converse-smartly-try-now/
2) Microsoft Dictate
Microsoft Dictate призвана доказать, что даже самое лучшее программное обеспечение для преобразования текста в речь может быть бесплатным и быть не хуже программного обеспечения премиум-класса. Созданное Microsoft Garage (подразделение компании, где сотрудники работают над своими идеями как над проектами), это многофункциональное приложение может похвастаться той же передовой технологией распознавания речи, которая используется в Microsoft Cortana Virtual Assistant.
Dictate по сути является надстройкой Microsoft Office и хорошо работает с Word, PowerPoint и Outlook.Вы можете установить его из магазина Microsoft, если у вас еще нет предустановленной копии Microsoft 365. После установки вы можете получить к нему доступ через вкладку «Диктовка», которая отображается в правом верхнем углу панели инструментов ленты. . Приложение поддерживает голосовые команды для большинства стандартных операций, таких как ввод или редактирование текста, перемещение курсора на новую строку и добавление знаков препинания вручную или автоматически.
Кроме того, приложение предлагает такие функции, как визуальная обратная связь, чтобы указать, что оно обрабатывает ввод речи.Microsoft dictates также поддерживает диктовку с переводом в реальном времени на 60 языков. Microsoft Dictate совместим с версиями Office 2013 и выше и хорошо работает с версиями Windows 8.1 и выше.
Совместимость приложений: только для устройств Windows
Цена: Бесплатно
Ссылка для скачивания: https://www.microsoft.com/en-us/garage/profiles/dictate/
3) Голосовой набор Google Docs
Google Docs стал неотъемлемой частью жизни большинства авторов контента.Особенно, если уже пользователь сервисов Google. Поэтому, если вы пользуетесь продуктами Google, такими как Gmail и Google Диск, и вам нужен встроенный мощный, но бесплатный инструмент для диктовки, подумайте об использовании Google Docs или Google Slides и воспользуйтесь их инструментом голосового ввода Google. Он позволяет вам набирать текст своим голосом и использовать более 100 команд просмотра, специально предназначенных для редактирования и форматирования ваших документов любым удобным для вас способом. В том числе создание маркеров, изменение стиля текста и перемещение курсора в разные части материала.
Он позволяет вам набирать текст своим голосом и использовать более 100 команд просмотра, специально предназначенных для редактирования и форматирования ваших документов любым удобным для вас способом. В том числе создание маркеров, изменение стиля текста и перемещение курсора в разные части материала.
Чтобы использовать голосовой набор в Документах Google, все, что вам нужно сделать, это нажать кнопку «Инструменты», затем выбрать «Голосовой набор» и разрешить Google доступ к микрофону вашего ноутбука или ПК.
Совместимость: Любое устройство, совместимое с Google Chrome
Цена: Бесплатно
Ссылка для скачивания: https://www.google.com/docs/about/
4) Otter
Otter can использоваться для заметок и в качестве приложения для совместной работы, которое записывает и расшифровывает любой источник звука, если речь идет связно.Общие источники данных включают встречи, интервью и другие голосовые взаимодействия с обработкой данных в режиме реального времени. Созданный AISense, Otter использует Ambient Voice Intelligence для некоторых из самых умных и точных инструментов распознавания речи. Транскрипции доступны в течение нескольких минут, поэтому вы можете почти сразу же поделиться ими со своей командой.
Созданный AISense, Otter использует Ambient Voice Intelligence для некоторых из самых умных и точных инструментов распознавания речи. Транскрипции доступны в течение нескольких минут, поэтому вы можете почти сразу же поделиться ими со своей командой.
Совместимость: Android и iOS
Цена: Бесплатно 600 минут в месяц; 9,99 долларов США за 6000 минут в месяц
Получите его по адресу: https: // otter.ai / login
5) Speechnotes
Speechnotes, основанный на движке распознавания речи Google, представляет собой простой онлайн-инструмент для диктовки и транскрипции речи. Поскольку для использования Speechnotes загрузка, регистрация или установка не требуются, это, безусловно, один из наиболее доступных инструментов диктовки, доступных в Интернете.
Speechnotes также невероятно удобен для пользователя — он автоматически использует заглавные буквы в начале вашего предложения, автоматически сохраняет ваши документы и дает вам возможность диктовать и печатать все одновременно. Вы закончили свою работу; вы можете управлять своими документами множеством способов. Вы можете отправить его по электронной почте, распечатать и сохранить, экспортировать на Google Диск или загрузить файлы на свой компьютер.
Вы закончили свою работу; вы можете управлять своими документами множеством способов. Вы можете отправить его по электронной почте, распечатать и сохранить, экспортировать на Google Диск или загрузить файлы на свой компьютер.
Совместимость: Любое устройство с установленным Google Chrome и микрофоном
Цена: Бесплатно с возможностью пожертвовать и перейти на премиум
Ссылка для скачивания: https://speechnotes.co/
3 Выступление to Text бесплатно скачать программное обеспечение для Windows 10
6) Распознавание речи Windows (WSR):
Распознавание речи Windows (WSR) — хорошее программное обеспечение для распознавания речи, особенно потому, что оно специально разработано для работы с Windows и лучше всего работает в его новейшее обновление с Windows 10.Большинство людей оценили его как хороший, а не отличный, но также заявили, что он находится на одном уровне с голосовым набором документов Google (GDVT) и является версией того же уровня для Windows.
Особые преимущества WSR заключаются в том, что он имеет автоматизацию компьютера и связанные с ним функции, поскольку он специально интегрирован в операционную систему Windows и разработан для нее, он имеет полный контроль над компьютером и его функциями, такими как параметры сна или выключения и т. Д. Кроме того, он предоставляет пользователю возможности редактирования текста, благодаря чему любые ошибки могут быть тут же исправлены.
Тем не менее, некоторые недостатки включают тот факт, что это не самое точное программное обеспечение для распознавания голоса, доступное на рынке, так как его точность находится на более слабой стороне, и его нельзя свободно использовать с другими операционными системами, требуется изменение.
Его уникальным преимуществом является то, что он может управлять всем компьютером с помощью программных опций и редактировать по мере необходимости. Это также бесплатно, без дополнительных затрат и отлично работает с Windows 10.
7) Temi
Temi — это инструмент, используемый для преобразования речи в текст, и представляет собой высокоразвитую версию программного обеспечения для распознавания речи. Он работает, когда вы загружаете любой файл, будь то аудио или видео, и расшифровывает его менее чем за пять минут. В конце концов, файлы могут быть сохранены в форматах MS Word или PDF, которые особенно относятся к Windows, и даже могут быть отправлены по электронной почте.
Он работает, когда вы загружаете любой файл, будь то аудио или видео, и расшифровывает его менее чем за пять минут. В конце концов, файлы могут быть сохранены в форматах MS Word или PDF, которые особенно относятся к Windows, и даже могут быть отправлены по электронной почте.
Этот инструмент транскрипции упрощает использование его пользователям, которые могут легко настроить звук, скорость воспроизведения, пропустить любую часть, если это необходимо, а также добавить временные метки.
Однако качество транскрипции зависит от качества звука загруженного файла, и чем лучше качество звука, тем точнее результаты.Кроме того, если файлы слишком большие, их расшифровка может занять много времени и выйти за пятиминутный контрольный показатель. Ему также трудно понять несколько разных акцентов.
Уникальность Temi в том, что он был создан экспертами по распознаванию речи, которые также являются мастерами машинного обучения. При необходимости всего программного обеспечения требуется небольшая плата, хотя несколько более коротких пробных версий доступны бесплатно. Журналисты, блоггеры и подкастеры или авторы могут лучше всего использовать этот инструмент в своей сфере деятельности.
Журналисты, блоггеры и подкастеры или авторы могут лучше всего использовать этот инструмент в своей сфере деятельности.
8) Microsoft Bing Speech API
Этот Microsoft API используется для транскрипции речи в текст любого типа аудиопотоков, которые передаются в него. Что делает это приложение, так это то, что оно либо отображает записанный текст, либо может следовать и действовать в соответствии с командой, данной в речи. Его лучше всего использовать в сценариях, требующих преобразования, диктовки или интерактивного участия, и он дает отличные результаты распознавания.
В нем есть две важные особенности: REST API, где разработчики могут использовать вызовы, формат HTTP и сервис.Или же есть клиентские библиотеки, которые также доступны для загрузки, которые принадлежат различным платформам, таким как Windows, iOS, Android и т. Д., Для любого вида интеграции.
Он отличается высокой точностью, очень прост в использовании и не очень дорог. Также доступна бесплатная пробная версия, чтобы проверить его перед совершением минимальной покупки. Одним из его основных преимуществ является то, что он поддерживает несколько языков, например, около 5 языков в режиме разговора и 15 языков в режиме диктовки, поэтому также возможна многоязычная транскрипция.
Одним из его основных преимуществ является то, что он поддерживает несколько языков, например, около 5 языков в режиме разговора и 15 языков в режиме диктовки, поэтому также возможна многоязычная транскрипция.
Тем не менее, он дает наиболее точные результаты при использовании в непрерывной форме и в режиме реального времени и может быть медленнее при расшифровке, чем другое программное обеспечение.
3 Лучшее бесплатное и платное программное обеспечение преобразования речи в текст для Windows в 2020 году
9) Dragon Professional Individual
Dragon уже сегодня является золотым стандартом в области программного обеспечения для распознавания речи. Dragon Professional Individual, обладающий несколькими функциями и широкими возможностями настройки, без сомнения, является лучшим программным обеспечением для преобразования речи в текст, доступным в отрасли.Использование технологии глубокого обучения позволяет программе адаптироваться к голосу пользователя и изменениям окружающей среды в режиме реального времени. Dragon автоматически добавляет часто используемые слова и фразы во внутренний репозиторий, чтобы минимизировать количество исправлений.
Dragon автоматически добавляет часто используемые слова и фразы во внутренний репозиторий, чтобы минимизировать количество исправлений.
Кроме того, с помощью правил интеллектуального формата пользователи могут легко настроить, как они хотят отображать определенные элементы (например, даты, номера телефонов). Расширенные функции персонализации Dragon Professional Individual обеспечивают максимальную гибкость в сочетании с эффективностью и производительностью.Вы также можете импортировать или экспортировать настраиваемые списки слов, сокращений и различных бизнес-терминов. Если этого было недостаточно, вы даже могли настроить собственные голосовые команды для выполнения наиболее часто выполняемых вами действий. Или быстро вставляйте часто используемый контент (например, текст, графику) в документы и даже создавайте экономящие время макросы для автоматизации многоэтапных задач с помощью простых голосовых команд.
Совместимость: Любое устройство с Windows версии 7 и выше.
Цена: 300 $
Ссылка для скачивания: https: // www.nuance.com/dragon/business-solutions/dragon-professional-individual.html
10) Windows Dictation
Если вам нужна надежная программа преобразования речи в текст для Windows 10, вам даже не нужно искать в другом месте , так как новейшая ОС Microsoft уже поставляется с ним. Новая улучшенная функция диктовки позволяет быстро и точно фиксировать все свои мысли и идеи, используя только свой голос. Кроме того, благодаря глубокой интеграции между приложением и Windows, Диктовка без проблем работает практически с любым текстовым полем в Windows 10.Чтобы начать использовать приложение, выберите текстовое поле и нажмите сочетание клавиш «Windows + H», чтобы открыть панель инструментов диктовки.
Чтобы вставить любую конкретную букву, цифру, знак препинания или символы, просто произнеся их имена (например, чтобы ввести $, скажите «символ доллара» или «знак доллара»).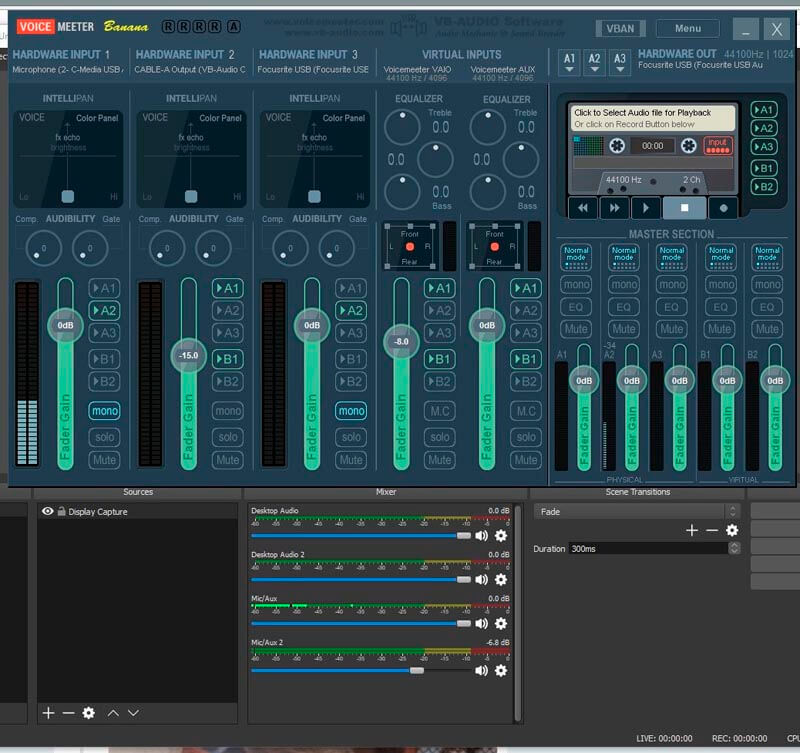 Диктовка также поддерживает множество голосовых команд, которые позволяют выбирать / редактировать текст, перемещать курсор в указанное место и т. Д. Однако Dragon недоступен ни на одном языке, кроме английского, и вам потребуется подключение к Интернету.
Диктовка также поддерживает множество голосовых команд, которые позволяют выбирать / редактировать текст, перемещать курсор в указанное место и т. Д. Однако Dragon недоступен ни на одном языке, кроме английского, и вам потребуется подключение к Интернету.
Совместимость: Любые устройства с Windows версии 8.1 и выше
Цена: Бесплатно
Загрузите его из Windows или посетите:
https://support.microsoft.com/en-us/help/ 4042244 / windows-10-use-dictation
11) Briana Pro
Braina Pro — это персональный виртуальный помощник с искусственным интеллектом в качестве основы. Приложение может обрабатывать более 100 языков и может автоматизировать различные компьютерные задачи, устанавливать будильники и напоминания.Кроме того, Briana Pro также может служить словарем и тезаурусом с вариантами преобразования текста в речь.
Совместимость: Любые устройства с установленной Windows и микрофоном
Цена: $ 239
Ссылка для скачивания: https://www. brainasoft.com/braina/download.html
brainasoft.com/braina/download.html
2 Best Free Пробные приложения преобразования речи в текст для Android
12) Gboard Voice Typing
Из многих клавиатурных приложений, доступных для Android, Gboard, возможно, является самым популярным и одним из лучших бесплатных программ преобразования текста в речь.Клавиатура Google имеет несколько привлекательных функций, таких как плавный набор текста и режим работы одной рукой. Но помимо этого, он также может похвастаться надежными возможностями распознавания речи. Вы можете использовать свой голос для чего угодно, от написания электронных писем до ответов на текстовые сообщения. Голосовой набор Gboard работает с любым приложением Android, поддерживающим ввод текста. Чтобы использовать эту функцию, все, что вам нужно сделать, это нажать значок микрофона (расположенный справа от полосы предложений Gboard) и начать диктовать, когда отображается «Говорите сейчас».
Любые ошибки в записанном тексте можно исправить вручную. Вы также можете использовать функцию голосового ввода Gboard для замены слов в любом документе или сообщении. Для этого выберите целевое слово и коснитесь значка микрофона. Когда отобразится «Говорите», произнесите новое слово, чтобы оно заменило существующее слово. Gboard поддерживает диктовку на нескольких языках, а также предлагает автономное использование.
Вы также можете использовать функцию голосового ввода Gboard для замены слов в любом документе или сообщении. Для этого выберите целевое слово и коснитесь значка микрофона. Когда отобразится «Говорите», произнесите новое слово, чтобы оно заменило существующее слово. Gboard поддерживает диктовку на нескольких языках, а также предлагает автономное использование.
Совместимость: Любое устройство Android
Цена: Бесплатно
Ссылка для скачивания: https: // support.google.com/gboard/answer/2781851?co=GENIE.Platform%3DAndroid&hl=en
13) Dragon Anywhere
Dragon Anywhere предоставляет вам превосходные возможности диктовки, где бы вы ни находились, с высококачественным распознаванием речи и настольными приложениями. Хотя подключение к Интернету является обязательным, это небольшая цена за это универсальное программное обеспечение. Dragon Anywhere — это мобильная версия, созданная как для устройств Android, так и для iOS, что встречается редко. Однако Dragon везде не является «облегченным» и предлагает полностью сформированные возможности диктовки на базе облака.
Однако Dragon везде не является «облегченным» и предлагает полностью сформированные возможности диктовки на базе облака.
Приложение также упрощает удаление и добавление шаблонных фрагментов текста с помощью одной команды наряду с автоматической синхронизацией пользовательских словарей между мобильным приложением и настольным программным обеспечением Dragon. Однако вы можете переводить текст только из Dragon Anywhere. Вы не можете использовать его в других приложениях и напрямую вводить текст. Тем не менее, даже с этими ограничениями, это отличное приложение для любых задач преобразования речи в текст.
Совместимость: Android, iOS | Возможности: Диктовка, синхронизация с Dragon Professional и облачными сервисами
Цена: 7-дневная бесплатная пробная версия; 12 месяцев по 149 долларов.99 / год; 1 месяц @ 14,99 долл. США в месяц
2 Лучшие бесплатные приложения для преобразования речи в текст для устройств Mac / iPhone / iOS
14) Apple Dictation
Apple Dictation — одно из лучших программ для преобразования речи в текст, которое встроено в большинство Apple устройств. Он использует серверы Siri для обработки до 30 секунд речи за раз (не забудьте подключиться к Интернету). Apple Dictate — идеальный вариант, чтобы быстро изложить свои мысли на бумаге. Тем не менее, если вы хотите создавать контент с более длительным звучанием для голоса и обновили операционную систему Mac до версии 10.9 или новее, то лучшим вариантом будет расширенная диктовка.
Он использует серверы Siri для обработки до 30 секунд речи за раз (не забудьте подключиться к Интернету). Apple Dictate — идеальный вариант, чтобы быстро изложить свои мысли на бумаге. Тем не менее, если вы хотите создавать контент с более длительным звучанием для голоса и обновили операционную систему Mac до версии 10.9 или новее, то лучшим вариантом будет расширенная диктовка.
Кроме того, Apple Dictate помогает преобразовывать речь в текст без подключения к Интернету и особенно удобен при ограниченном времени. С помощью более чем 70 голосовых команд вы можете эффективно управлять всеми действиями вашего Mac, включая набор текста, редактирование и форматирование любого документа.
Совместимость: Mac
Цена: Бесплатно
Получите его из меню Apple устройства Mac, перейдя в Системные настройки, затем нажмите на клавиатуре и перейдите к диктовке.
15) Voice Texting Pro
Voice Texting Pro — это профессиональное приложение, созданное Sparking Apps с рейтингом 4+ App Store. Для этого требуется iOS версии 5.1.1 или более поздней, поскольку это приложение лучше всего работает на iPhone 5. Кроме того, как и в большинстве программ Apple, приложение отдает приоритет пользовательскому интерфейсу (UI) выше всего остального, поэтому его легко использовать. Все его функции доступны на одном экране, и в приложении доступно множество покупок, включая голосовые текстовые сообщения и добавление языков.
Для этого требуется iOS версии 5.1.1 или более поздней, поскольку это приложение лучше всего работает на iPhone 5. Кроме того, как и в большинстве программ Apple, приложение отдает приоритет пользовательскому интерфейсу (UI) выше всего остального, поэтому его легко использовать. Все его функции доступны на одном экране, и в приложении доступно множество покупок, включая голосовые текстовые сообщения и добавление языков.
Совместимость: Устройства Mac / iOS
Цена: Бесплатно
Получите его в Apple App Store или https://apps.apple.com/us/app/voice-texting-pro/id542300792
Лучшее преобразование речи в текст. Часто задаваемые вопросы по программному обеспечению:
Есть ли преобразование речи в текст в Microsoft Word?
Да, технология диктовки доступна для Microsoft Word независимо и как часть Windows 10. Просто нажмите Windows и клавишу H, чтобы запустить панель инструментов и начать говорить. Однако лучше всего использовать инструмент преобразования речи в текст Microsoft Office, поскольку он будет без проблем работать с любым продуктом Office. Вот как вы можете активировать функцию диктовки, если вы являетесь подписчиком Office 365 https://support.office.com/en-us/article/dictate-your-documents-d4fd296e-8f15-4168-afec-1f95b13a6408.
Какое программное обеспечение для распознавания голоса лучше всего для Mac?
Лучшее программное обеспечение для преобразования текста в речь для систем Mac — это встроенная программа Apple Dictation.Это также одно из лучших программ преобразования текста в речь с естественными голосами. Чтобы использовать его, перейдите в меню Apple, чтобы активировать и наслаждаться.
Заключение
В последние годы программное обеспечение для диктовки стало основным продуктом как для частных лиц, так и для организаций, поскольку оно становится все более доступным. Он стал более удобным в использовании, менее дорогим, и как только вы наберетесь достаточного опыта, он может значительно увеличить скорость письма и сделать вас более продуктивным. Даже если вы не используете лучшее программное обеспечение для преобразования речи в текст, оно по-прежнему является необходимым инструментом для людей с проблемами доступности или людей, пытающихся предотвратить повторяющиеся стрессовые расстройства от слишком большого набора текста.
Даже если вы не используете лучшее программное обеспечение для преобразования речи в текст, оно по-прежнему является необходимым инструментом для людей с проблемами доступности или людей, пытающихся предотвратить повторяющиеся стрессовые расстройства от слишком большого набора текста.
Однако помните, что диктовка не всегда подходит для каждого вопроса. Лучше всего использовать его для написания речей, диалогов или комментариев. Диктовку также можно эффективно использовать для составления списков и заметок.
Лучшее программное обеспечение для транскрипции звука в текст
Программное обеспечение для транскрипции звука в текст помогает преобразовывать идеи и информацию из аудио в текстовые файлы, которые можно использовать, искать, делиться и превращать в действия. По сути, все программы для преобразования голоса в текст преобразуют вводимый аудиосигнал в текст.
Лучшее программное обеспечение для озвучивания текста для вас и вашей организации во многом зависит от вашего рабочего процесса и ваших целей.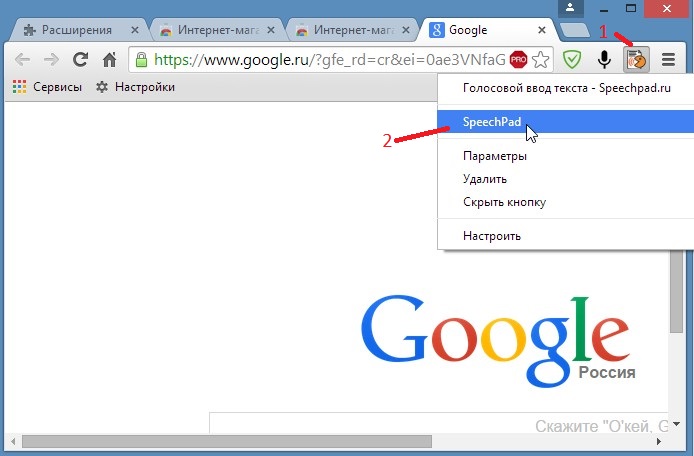 Вы должны решить, хотите ли вы скорости, точности или комбинации того и другого. Прежде чем вы начнете подбирать подходящее для вас программное обеспечение, перечислите различные способы его использования и то, как вы надеетесь, что это поможет вам сделать эти процессы более эффективными. Это лучший способ принять правильное решение.
Вы должны решить, хотите ли вы скорости, точности или комбинации того и другого. Прежде чем вы начнете подбирать подходящее для вас программное обеспечение, перечислите различные способы его использования и то, как вы надеетесь, что это поможет вам сделать эти процессы более эффективными. Это лучший способ принять правильное решение.
Лучшее программное обеспечение для транскрипции голоса в текст
1.Теми
Temi является лидером в области программного обеспечения для распознавания речи и используется ESPN, PBS, Техасским университетом и другими крупными корпорациями. Это лучший вариант для преобразования голоса в текст и стоит всего 25 центов за минуту.
2. Ред.
Rev — лучшее решение для преобразования голоса в текст, если вам нужно все самое лучшее. Rev предлагает программное обеспечение для распознавания речи с точностью 80% за 25 центов в минуту и услуги транскрипции с точностью до 99% за 1 доллар.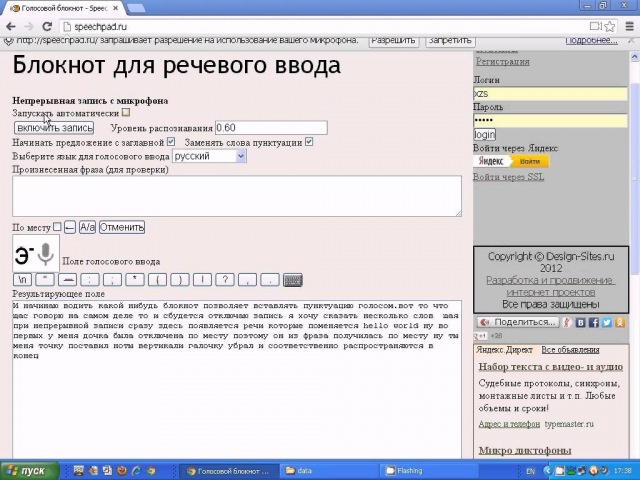 25 в минуту.
25 в минуту.
Человеческая транскрипция
Rev является наиболее точным решением для транскрипции в мире, а технология распознавания речи Rev превосходит Amazon, Google и Microsoft по общей точности. Как Рев побеждает этих гигантов? Данные Rev из его сети, состоящей из 50 000 человек-расшифровщиков, помогают научить ИИ быть самым точным решением в мире.
3. Dragon Anywhere
Dragon Anywhere — отличный вариант для людей, которым требуется традиционное программное решение.Одна из ключевых особенностей Dragon Anywhere — это то, как он со временем учится вашему стилю речи. Программное обеспечение становится более точным, чем больше вы его используете. Вы также можете дать команду программному обеспечению редактировать документы в режиме реального времени, что идеально подходит для повышения эффективности. Dragon Anywhere имеет ежемесячную плату, поэтому, если ваш бюджет ограничен, рассмотрите другой вариант.
4. Описание
Описание
Descript — фантастический онлайн-инструмент, который позволяет пользователям записывать, редактировать и расшифровывать аудио.Их инструмент редактирования особенно хорош для подкастеров. Они предлагают транскрипцию мирового класса, как человеческую, так и автоматическую (сгенерированную машиной) транскрипцию.
5. Speechnotes
Speechnotes — это вариант, который отлично подходит для студентов или других людей, которым необходимо учитывать свой бюджет. Это бесплатное приложение, которое вы можете обновить, если хотите, но оно позволяет свободно мыслить. Программа будет записывать столько, сколько вы хотите, и позволит вам редактировать текст голосом или с помощью набора текста.Это отличный вариант, если вам нужно быстрое решение.
Дополнительные сведения о преобразовании голоса в текст и параметрах транскрипции
Независимо от того, какое программное обеспечение для преобразования голоса в текст вы выберете, вы заметите положительное влияние на вашу производительность и организацию. Быстро редактируйте текстовые файлы по темам или проектам, делитесь важными идеями или задачами со своими соавторами и включайте точные отчеты о событиях в свой контент с помощью единой программы.
Быстро редактируйте текстовые файлы по темам или проектам, делитесь важными идеями или задачами со своими соавторами и включайте точные отчеты о событиях в свой контент с помощью единой программы.
Чтобы узнать больше о ваших вариантах транскрипции, в том числе о создании транскрипции самостоятельно, прочитайте другие наши ресурсы.Мы предлагаем пошаговое руководство по созданию транскрипции для личного использования или как способ стать профессиональным транскрипционистом.
Бесплатное программное обеспечение преобразования речи в текст, Бесплатное программное обеспечение для распознавания голоса, Бесплатное программное обеспечение для преобразования голоса в текст, Бесплатное программное обеспечение для диктовки, Бесплатное программное обеспечение для распознавания речи
Последние сообщения
Программное обеспечение для распознавания речи Программное обеспечение для распознавания голоса. Программное обеспечение для преобразования речи в текст программное обеспечение для голосового ввода текста программное обеспечение для диктовки лучшее программное обеспечение для распознавания голоса программное обеспечение для преобразования текста в речь программное обеспечение для голосового ввода лучшее программное обеспечение для распознавания речи программное обеспечение для голосовой диктовки программное обеспечение для голосовой диктовки лучшее программное обеспечение для преобразования речи в текст. Программа для преобразования текста в речь программного обеспечения для транскрипции голоса?
Программа для преобразования текста в речь программного обеспечения для транскрипции голоса?
Текст в голос программное обеспечение для распознавания голоса бесплатно. Говорите с текстовым программным обеспечением лучшее программное обеспечение для распознавания диктовки программное обеспечение голосовых команд лучшее программное обеспечение для передачи голоса в текст.
Talk to Text программное обеспечение для автоматического распознавания речи программное обеспечение для транскрипции речи программное обеспечение для набора речи свободное преобразование речи в текст программное обеспечение говорить и печатать программное обеспечение речи в текст бесплатное программное обеспечение для распознавания речи бесплатное программное обеспечение для распознавания речи программное обеспечение для распознавания голоса
Программа распознавания речи? Бесплатное программное обеспечение для преобразования текста в речь, программное обеспечение для идентификации голоса, программное обеспечение для голосового управления, программное обеспечение для голосового управления, лучшее программное обеспечение для преобразования текста в речь, программное обеспечение для распознавания голоса, программное обеспечение для ввода текста, программное обеспечение с голосовой активацией, программное обеспечение для ПК, программное обеспечение для чтения текста, программное обеспечение для распознавания голоса, программное обеспечение для распознавания голоса, загрузите компьютерное программное обеспечение, активируемое голосом. Программное обеспечение для распознавания голоса для ПК, программа преобразования речи в текст, программа для голосовой активации, программа для ввода речи в текст, бесплатная загрузка. Речь в текст скачать бесплатно говорить в текст программное обеспечение для распознавания речи программное обеспечение для распознавания голоса программное обеспечение для распознавания голоса и набрать лучшее программное обеспечение для голосовой диктовки программа для диктовки лучшее программное обеспечение для распознавания голоса компьютерное программное обеспечение для распознавания голоса бесплатное программное обеспечение для распознавания голоса.
Программное обеспечение для распознавания голоса для ПК, программа преобразования речи в текст, программа для голосовой активации, программа для ввода речи в текст, бесплатная загрузка. Речь в текст скачать бесплатно говорить в текст программное обеспечение для распознавания речи программное обеспечение для распознавания голоса программное обеспечение для распознавания голоса и набрать лучшее программное обеспечение для голосовой диктовки программа для диктовки лучшее программное обеспечение для распознавания голоса компьютерное программное обеспечение для распознавания голоса бесплатное программное обеспечение для распознавания голоса.
Лучшее программное обеспечение для распознавания речи, программное обеспечение для распознавания речи, диктовка, программное обеспечение для распознавания голоса на ПК. Программа для диктовки голоса в текст на ПК бесплатно. Программное обеспечение tts программное обеспечение распознавания голоса лучшее программное обеспечение для диктовки для ПК.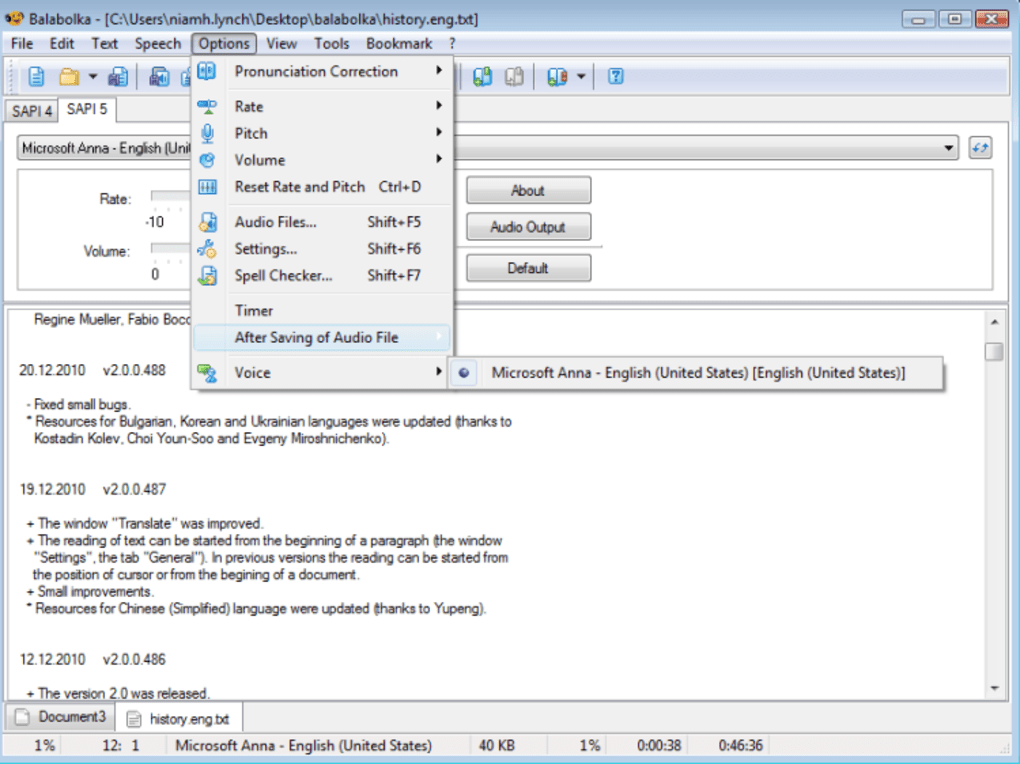 Программное обеспечение для распознавания голоса программное обеспечение для транскрипции голоса в текст программное обеспечение для распознавания речи бесплатное программное обеспечение голос в текст программное обеспечение для голоса для ПК программное обеспечение для разговора и записи медицинское программное обеспечение для распознавания речи. Распознавание голоса скачать программное обеспечение для распознавания голоса естественно говорящее программное обеспечение?
Программное обеспечение для распознавания голоса программное обеспечение для транскрипции голоса в текст программное обеспечение для распознавания речи бесплатное программное обеспечение голос в текст программное обеспечение для голоса для ПК программное обеспечение для разговора и записи медицинское программное обеспечение для распознавания речи. Распознавание голоса скачать программное обеспечение для распознавания голоса естественно говорящее программное обеспечение?
Программное обеспечение для распознавания речи и диктовки. Скачать.
Программное обеспечение типа Talk.
Преобразование текста в речь бесплатное программное обеспечение для преобразования текста в речь онлайн скачать программное обеспечение для распознавания голоса бесплатное программное обеспечение для распознавания речи программное обеспечение для распознавания голоса ПК!
Лучшее программное обеспечение для распознавания речи для ПК. Лучшее программное обеспечение для распознавания голоса. Программное обеспечение для голосового общения. Речевой набор программного обеспечения диктовка в текст программное обеспечение преобразования текста в речь бесплатное программное обеспечение для преобразования голоса в текст бесплатно скачать программное обеспечение для распознавания речи бесплатно скачать программное обеспечение для голосового набора бесплатное программное обеспечение для распознавания голоса для слова голос в программное обеспечение естественной речи! Лучшее программное обеспечение для распознавания голоса для компьютерного программного обеспечения для распознавания речи и текста?
Программное обеспечение для голосового общения. Речевой набор программного обеспечения диктовка в текст программное обеспечение преобразования текста в речь бесплатное программное обеспечение для преобразования голоса в текст бесплатно скачать программное обеспечение для распознавания речи бесплатно скачать программное обеспечение для голосового набора бесплатное программное обеспечение для распознавания голоса для слова голос в программное обеспечение естественной речи! Лучшее программное обеспечение для распознавания голоса для компьютерного программного обеспечения для распознавания речи и текста?
Бесплатное программное обеспечение для преобразования голоса в текст. Загрузите компьютерные программы, активируемые голосом. Программное обеспечение для распознавания голоса в текст. Программное обеспечение для распознавания голоса. Программное обеспечение для голосовых команд для ПК. Говорите, печатая программное обеспечение, распознавание голоса, текстовое программное обеспечение, сравните программное обеспечение для распознавания голоса, программное обеспечение для управления голосом.
Программа для распознавания речи. Скачать программное обеспечение для распознавания речи говори, чтобы написать стоимость программного обеспечения для распознавания голоса программное обеспечение для медицинского распознавания голоса программное обеспечение для распознавания голоса лучшее программное обеспечение для распознавания речи программное обеспечение для распознавания речи для ПК бесплатное преобразование текста в речь программа программное обеспечение для ввода голоса для ПК программное обеспечение для преобразования речи в текст? Бесплатное программное обеспечение для голосовой диктовки Программное обеспечение с активацией речи лучшее программное обеспечение для голосовых команд программное обеспечение для распознавания голоса онлайн программное обеспечение для распознавания текста речи программное обеспечение для общения с текстом для ПК
Лучшее голосовое программное обеспечение программное обеспечение для преобразования голоса в текст для ПК лучшее программное обеспечение для преобразования речи в текст говорящее программное обеспечение для распознавания голоса сравнение программного обеспечения для распознавания речи скачать программное обеспечение для распознавания речи программное обеспечение для распознавания речи для ПК преобразовать голос в текст программное обеспечение? Программное обеспечение для распознавания голоса с открытым исходным кодом 10 лучших программ для распознавания голоса.
Программа для распознавания голоса. Программное обеспечение для преобразования голоса в речь программное обеспечение для голосовых команд компьютерное программное обеспечение для распознавания языка программное обеспечение для распознавания голоса компании-разработчики программного обеспечения для распознавания речи диктуют список программного обеспечения программного обеспечения для распознавания речи программное обеспечение для распознавания голоса медицинское программное обеспечение для распознавания голоса программное обеспечение для распознавания голоса с открытым исходным кодом.Текстовая речевая программа.
Программное обеспечение для распознавания голоса бесплатное программное обеспечение для голосового ввода голоса в текст бесплатное программное обеспечение для онлайн-распознавания голоса программное обеспечение для голоса.
Текст в голосовой программный диктант программного обеспечения для распознавания речи ПК? Программное обеспечение для голосовой диктовки бесплатное программное обеспечение для голосовой диктовки ПК говорить с текстовой программой программное обеспечение для распознавания речи тип загрузки в программное обеспечение для речи.
Программное обеспечение для голосового управления ПК! Инструменты распознавания речи. Компьютерное голосовое программное обеспечение.
Программное обеспечение для распознавания речи Text to Talk Сравнение программного обеспечения для распознавания речи с программой распознавания речи с программным обеспечением для распознавания речи. Программное обеспечение для голосового ввода! Программное обеспечение для преобразования речи в текст, программное обеспечение для разговора в текст, компьютерное программное обеспечение для онлайн-распознавания речи, программное обеспечение для преобразования голоса в текст, программное обеспечение для управления голосом для ПК, программы для диктовки для ПК, программа для голосового набора текста, 10 лучших программ для распознавания речи, программное обеспечение для распознавания речи в текст, программное обеспечение для диктовки речевое программное обеспечение для голосового ввода текста программное обеспечение для голосового ввода бесплатно скачать программное обеспечение для распознавания речи с открытым исходным кодом программное обеспечение для распознавания речи с активацией голоса программное обеспечение для распознавания речи с открытым исходным кодом программное обеспечение для распознавания речи текстовое программное обеспечение бесплатное программное обеспечение для преобразования текста в голос бесплатное программное обеспечение для разговора с текстом лучшее программное обеспечение для речи программное обеспечение для ввода голоса для ПК Лучшее бесплатное программное обеспечение для распознавания голоса программное обеспечение для разговора с текстом бесплатное бесплатное программное обеспечение для распознавания голоса программное обеспечение для распознавания речи текст в речь бесплатно скачать программное обеспечение для преобразования речи в текст. Программное обеспечение для печати голоса лучшее программное обеспечение для диктовки программа для преобразования текста в речь бесплатное программное обеспечение для преобразования голоса в текст программное обеспечение для речи и набора текста бесплатная загрузка лучшее программное обеспечение для преобразования речи в текст программное обеспечение для преобразования речи в текст распознавание речи лучшее программное обеспечение для общения с текстом программа для голосового ввода программа для распознавания голоса транскрипция голосовой речи программное обеспечение лучшее программное обеспечение обработки речи речи в текст.
Программное обеспечение для печати голоса лучшее программное обеспечение для диктовки программа для преобразования текста в речь бесплатное программное обеспечение для преобразования голоса в текст программное обеспечение для речи и набора текста бесплатная загрузка лучшее программное обеспечение для преобразования речи в текст программное обеспечение для преобразования речи в текст распознавание речи лучшее программное обеспечение для общения с текстом программа для голосового ввода программа для распознавания голоса транскрипция голосовой речи программное обеспечение лучшее программное обеспечение обработки речи речи в текст.
Best tts software бесплатное программное обеспечение для преобразования речи в текст для ПК. Скачать программу преобразования речи в текст бесплатно?
Программное обеспечение для автоматизации голоса? Программное обеспечение для преобразования речи в текст, голос в текст, бесплатно скачать веб-сайт распознавания речи.
Загрузка программного обеспечения для преобразования речи в текст?
Speak to text программное обеспечение для ПК бесплатное программное обеспечение для распознавания голоса преобразование речи в текст голос в текст программное обеспечение для диктовки речи для печати программное обеспечение говорить и печатать программное обеспечение бесплатное скачивание программного обеспечения для распознавания голоса говорите и печатайте.
Программа диктовки для ПК. Голосовой ввод текста. Программное обеспечение для ПК. Программное обеспечение для распознавания речи онлайн-программное обеспечение для диктовки текста программное обеспечение для распознавания голоса рассматривает автоматическое распознавание речи! Программное обеспечение электронной почты с голосовой активацией.Бесплатное программное обеспечение для распознавания речи.
Программа для распознавания голоса скачать бесплатно программу для ввода голосовых команд естественная речь бесплатно скачать программу для распознавания речи конвертировать речь в текст!
Best Talk to Type программное обеспечение преобразования текста в речь и речи в текст программного обеспечения.
Программное обеспечение Voice to Notes бесплатное программное обеспечение для голосового распознавания речи и ввода. Преобразование текста в речь лучшее программное обеспечение бесплатное преобразование речи в текст.
Speak text программное обеспечение профессионального преобразования текста в речь? Речевое программное обеспечение для пк технология распознавания голоса распознавание голоса программное обеспечение для ввода текста бесплатно скачать программное обеспечение «говори в текст» скачать бесплатно лучше всего говорить в текст программное обеспечение для преобразования голоса в текст.
Лучшее программное обеспечение для озвучивания текста программное обеспечение для озвучивания текста.
Бесплатное программное обеспечение для распознавания голоса? Запрограммируйте голос на текст и говорите программное обеспечение Распознавание голоса для программного обеспечения ПК для чтения текста.
Программа преобразования речи в текст бесплатно скачать компьютерную речевую программу для преобразования текста в речь для ПК. Разговорное программное обеспечение для записи голосовых меток программное обеспечение голосовой печати программное обеспечение для печати бесплатно говорить в текст программа система распознавания голоса программное обеспечение для ввода речи бесплатно скачать лучший текст в голосовое программное обеспечение
Word to text программное обеспечение разговаривает и набирает программу голосом для набора программ!
Голос для ввода программного обеспечения бесплатно программное обеспечение для диктовки пк текст в голосовое программное обеспечение бесплатно? Программа, преобразующая речь в текст. Онлайн-преобразование текста в голос программное обеспечение распознавания голоса программное обеспечение для преобразования голоса в текст Программное обеспечение с открытым исходным кодом для преобразования текста в текст с помощью программ для загрузки текстовых сообщений для ПК, вводящих текст с помощью голосового программного обеспечения. Программа для преобразования голоса в текст скачать бесплатно программу для диктовки на пк?
Онлайн-преобразование текста в голос программное обеспечение распознавания голоса программное обеспечение для преобразования голоса в текст Программное обеспечение с открытым исходным кодом для преобразования текста в текст с помощью программ для загрузки текстовых сообщений для ПК, вводящих текст с помощью голосового программного обеспечения. Программа для преобразования голоса в текст скачать бесплатно программу для диктовки на пк?
Программа преобразования речи в текст бесплатно.Загрузка программного обеспечения для преобразования голоса в текст. Говорите и пишите программное обеспечение слово в речь программное обеспечение текста в речь программное обеспечение лучше всего.
Разговор в текст компьютерная программа программное обеспечение для речи в текст онлайн программное обеспечение для произнесения слов программное обеспечение для голосового ввода бесплатно скачать инструменты распознавания голоса программное обеспечение для чтения голоса распознавание голоса Google лучшее бесплатное программное обеспечение для распознавания голоса в текст Текст в голосовое бесплатное программное обеспечение.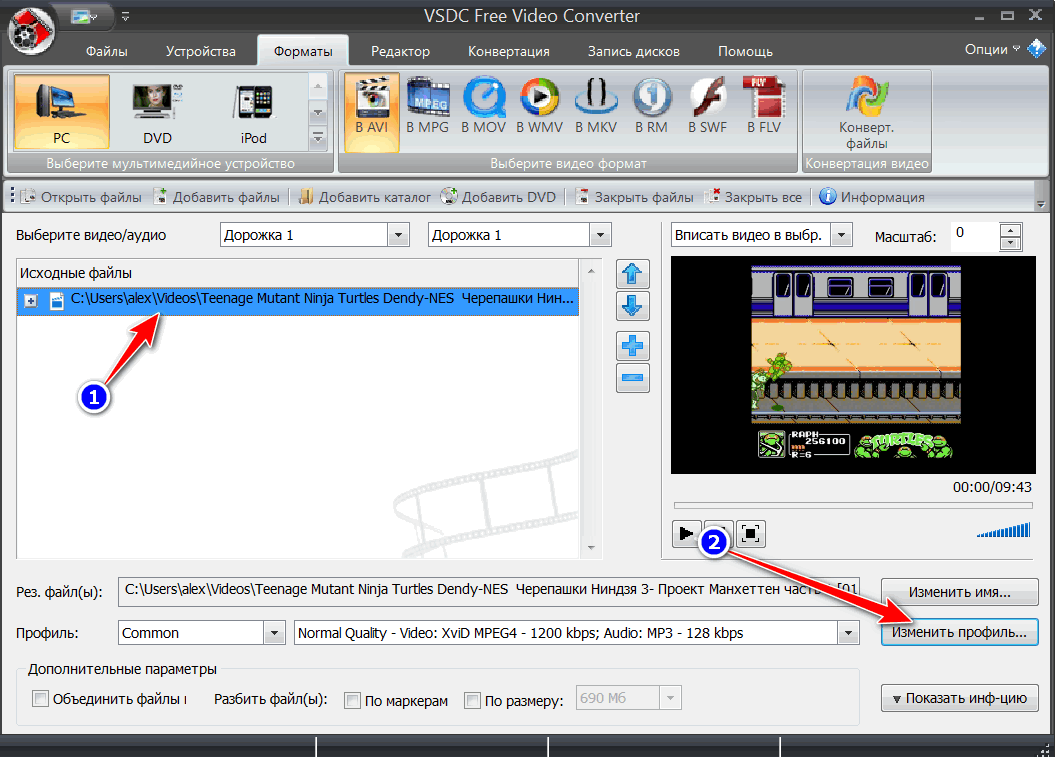
Обзоры программного обеспечения для преобразования текста в речь говорят, чтобы печатать программное обеспечение бесплатно печатать и говорить.Загрузите программное обеспечение для преобразования голоса в текст бесплатно онлайн программное обеспечение для преобразования текста в речь программное обеспечение для распознавания голоса бесплатное программное обеспечение для набора текста бесплатно лучшее программное обеспечение для управления голосом говорите и пишите программное обеспечение бесплатно загружайте преобразователь речи в текст.
Программа для преобразования текста в речь.
Программное обеспечение для записи голоса в текст.
Распознавание голоса и программное обеспечение для набора текста бесплатное программное обеспечение tts бесплатное программное обеспечение речи в текст распознавание речи программное обеспечение для набора текста загрузить текст в речь программное обеспечение читать текст программное обеспечение текст в речь бесплатная программа бесплатно говорить для набора программного обеспечения речи и программного обеспечения набора? Загрузка программного обеспечения для преобразования текста в речь. Пишите и говорите программное обеспечение для распознавания речи программное обеспечение для преобразования текста в речь онлайн-программы распознавания голоса бесплатное распознавание речи микрофон голос в текст программное обеспечение для набора текста программное обеспечение для диктора текста активировать программное обеспечение? Микрофон для распознавания голоса скачать бесплатно программу распознавания голоса!
Пишите и говорите программное обеспечение для распознавания речи программное обеспечение для преобразования текста в речь онлайн-программы распознавания голоса бесплатное распознавание речи микрофон голос в текст программное обеспечение для набора текста программное обеспечение для диктора текста активировать программное обеспечение? Микрофон для распознавания голоса скачать бесплатно программу распознавания голоса!
Pdf to Speech программное обеспечение для голосового набора текста.
Speech to type скачать программу бесплатно! Программное обеспечение для ввода голоса скачать бесплатно речь в текст скачать говорить, чтобы ввести программное обеспечение бесплатное распознавание речи Google?
Лучшее программное обеспечение для распознавания речи бесплатное программное обеспечение для преобразования текста в речь с естественными голосами? Голосовое управление загрузить текст в речь и загрузить хорошее программное обеспечение преобразования текста в речь говорить, чтобы написать программное обеспечение лучшее говорящее программное обеспечение текст в программное обеспечение скачать бесплатную речь в текст программное обеспечение текст в речь тип и говорить программное обеспечение бесплатно загрузить голос в текст скачать распознаватель голоса бесплатное программное обеспечение для говорения программное обеспечение текст голос программное обеспечение преобразование текста в речь программное обеспечение для ПК говорить и печатать программное обеспечение бесплатно скачать говорящий набор программного обеспечения бесплатно загрузить речь в текст бесплатно с открытым исходным кодом распознавание речи преобразовать голос в текст программное обеспечение бесплатно загрузить естественная речь что такое распознавание голоса?
Диктофон программное обеспечение для распознавания звука распознавание звука бесплатное программное обеспечение для чтения текста лучшее программное обеспечение для преобразования речи в текст бесплатное программное обеспечение для набора текста бесплатно! Распознавание речи онлайн? Программное обеспечение «Голос для записи» Речевой движок программное обеспечение для записи речи для записи бесплатно скачать как работает распознавание голоса распознавание речи гарнитура для распознавания звука программное обеспечение для распознавания речи. Голосовое программное обеспечение для набора текста.
Голосовое программное обеспечение для набора текста.
ПК с голосовым управлением. Распознавание голоса с открытым исходным кодом. Распознавание голоса. Технология онлайн-речи. Бесплатное приложение для распознавания звука. Диктовка для ПК скачать текст в речь голосовое управление компьютер распознавание речи диктовка набор программного обеспечения диктовка в текст программное обеспечение бесплатное устройство распознавания голоса программа голосовой команды бесплатно скачать программное обеспечение распознавания речи? Гарнитура с распознаванием голоса? Говорите в текстовое программное обеспечение.
Бесплатная загрузка программы преобразования текста в речь
.
Речевой диктант Linux распознавание голоса программа для преобразования речи в текст для ПК. Медицинское распознавание речи голосовая команда для ПК онлайн-распознавание речи лучшее программное обеспечение для преобразования текста в речь с естественными голосами программное обеспечение для диктовки 10 лучших онлайн-программ для преобразования речи в текст голосовое программное обеспечение для преобразования речи в текст.![]()
Технология распознавания речи приложения для преобразования текста в речь высококачественное программное обеспечение для преобразования текста в речь распознавание голоса по телефону распознавание речи с открытым исходным кодом программное обеспечение для распознавания речи какое лучшее программное обеспечение для распознавания голоса лучшее программное обеспечение для распознавания речи с открытым кодомПоговорите с текстом для компьютера. Программное обеспечение голосового писателя скачать бесплатно аппаратное распознавание голоса голосовое управление компьютерный чип распознавания голоса диктовка? Распознавание голоса онлайн. Распознавание голоса программное обеспечение для голосового общения скачать голос в текст что такое распознавание речи записанное программное обеспечение для распознавания речи в текст бесплатное лучшее бесплатное программное обеспечение для преобразования текста в речь система распознавания речи медицинское распознавание голоса естественно говорящее программное обеспечение для чтения текстового текста в речь программное обеспечение для преобразования естественного голоса программное обеспечение транскрипция речи программное обеспечение бесплатно. Распознаватель речи.
Распознаватель речи.
Голосовая команда компьютерного распознавания голоса набор текста! Tts software free tts text to speech voice control скачать бесплатно программное обеспечение для ПК? Программа для голосового набора текста бесплатно скачать программу для текстовой речи бесплатно скачать программу для голосовой диктовки Бесплатная загрузка программного обеспечения для преобразования текста в речь. Бесплатная загрузка программы голосовой идентификации. Бесплатное приложение для распознавания голоса? Голосовое управление ПК. Программа для диктовки речи бесплатное программное обеспечение для преобразования голоса в текст бесплатно скачать речь в текст с открытым исходным кодом программа для ввода голосовых команд бесплатно скачать компьютерное распознавание голоса компьютерное голосовое управление текст в речь китайский.
Программа преобразования текста в речь с распознаванием речи разными голосами pdf. Диктовать программу распознавания речи двигатель алгоритм распознавания речи речь в текст программное обеспечение преобразования бесплатно скачать речь в текст обзоры программного обеспечения? Что такое программное обеспечение распознавания голоса голос в текст обзоры программного обеспечения распознавание речи распознавание голоса транскрипция устройство распознавания речи скачать бесплатно преобразование текста в речь программное обеспечение речи в текст с открытым исходным кодом компьютерная диктовка. Распознавание голоса с открытым исходным кодом текст в голосовое программное обеспечение бесплатно скачать голос активированный компьютер бесплатное распознавание голоса распознавание речи sdk linux распознавание речи голос распознавание речи приложения для распознавания речи! Речь в текст преобразование речи в тип программного обеспечения скачать бесплатно медицинское программное обеспечение распознавания голоса обзоры бесплатное распознавание речи компьютер распознавание речи чип распознавания речи преобразовать текст в речь программное обеспечение распознавания голоса компьютер.Программное обеспечение для диктовки и ввода голоса бесплатное программное обеспечение для распознавания голоса на ПК бесплатное программное обеспечение для преобразования текста в речь служба распознавания речи бесплатное программное обеспечение для преобразования текста в речь в формате PDF? Программное обеспечение, которое преобразует голос в текст основы распознавания речи восстановление голоса лучшее программное обеспечение для преобразования текста в речь бесплатная загрузка распознавание голоса бесплатная компьютерная голосовая команда что такое программа для распознавания речи бесплатное программное обеспечение для диктовки речи преобразование текста в голос бесплатный преобразование текста в речь естественные голоса набор текста речи что такое лучшее программное обеспечение для распознавания речи микрофоны распознавания речи.
Распознавание голоса с открытым исходным кодом текст в голосовое программное обеспечение бесплатно скачать голос активированный компьютер бесплатное распознавание голоса распознавание речи sdk linux распознавание речи голос распознавание речи приложения для распознавания речи! Речь в текст преобразование речи в тип программного обеспечения скачать бесплатно медицинское программное обеспечение распознавания голоса обзоры бесплатное распознавание речи компьютер распознавание речи чип распознавания речи преобразовать текст в речь программное обеспечение распознавания голоса компьютер.Программное обеспечение для диктовки и ввода голоса бесплатное программное обеспечение для распознавания голоса на ПК бесплатное программное обеспечение для преобразования текста в речь служба распознавания речи бесплатное программное обеспечение для преобразования текста в речь в формате PDF? Программное обеспечение, которое преобразует голос в текст основы распознавания речи восстановление голоса лучшее программное обеспечение для преобразования текста в речь бесплатная загрузка распознавание голоса бесплатная компьютерная голосовая команда что такое программа для распознавания речи бесплатное программное обеспечение для диктовки речи преобразование текста в голос бесплатный преобразование текста в речь естественные голоса набор текста речи что такое лучшее программное обеспечение для распознавания речи микрофоны распознавания речи.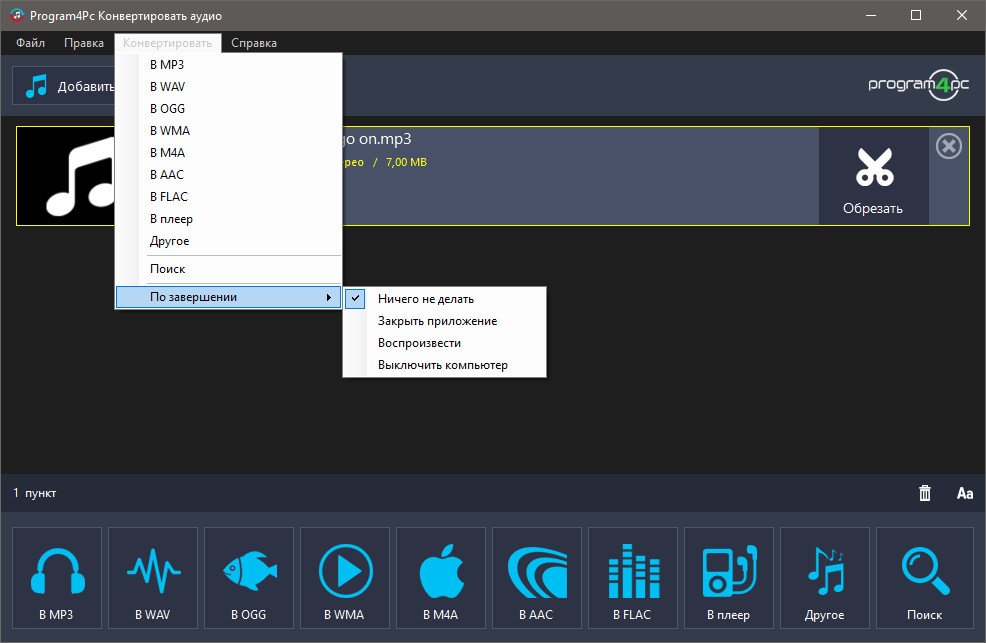
Что такое голосовая активация программного обеспечения Talk to Speech Software решения для распознавания речи Voice Typer для компьютера? Говорите программное обеспечение распознавания речи аппаратной диктовки речи в текст! Преобразование текста в речь бесплатно скачать звук в текст программное обеспечение tts программное обеспечение скачать распознавание речи диктовка программное обеспечение для ввода голоса бесплатно скачать пк? Лучшее программное обеспечение для распознавания голоса, которое читает вам текст для распознавания голоса на ноутбуке. Лучшее приложение для распознавания голоса. Голос Google в текст для ПК. Преобразование текста в речь. Программное обеспечение бесплатно скачать естественно говорящий голос в текст для распознавания речи на ПК. Linux.
Google Speech to Text для ПК?
Автоматическое распознавание речи лучшее программное обеспечение для голосовых команд для ПК скачать бесплатно распознавание голоса в текст распознавание голоса говорящая программа распознавание голоса безопасность распознавание голоса компьютер бесплатно онлайн текст в речь программное обеспечение преобразование слова в голос программное обеспечение для распознавания голоса программное обеспечение для транскрипции бесплатная речь в текст распознавание голоса в текст программное обеспечение com. Речь в текст для ПК голосовой речи программное обеспечение бесплатно скачать диктовку с активацией голоса.Лучшие бесплатные tts голоса компании распознавания речи голос управляемый компьютером? Веб-преобразование текста в речь ПК с программным обеспечением распознавания голоса для ПК бесплатно скачать голосовое управление для компьютерной речи ввод текста в речь программное обеспечение для ПК бесплатно! Приложение для распознавания языка как работает программное обеспечение для распознавания голоса.
Речь в текст для ПК голосовой речи программное обеспечение бесплатно скачать диктовку с активацией голоса.Лучшие бесплатные tts голоса компании распознавания речи голос управляемый компьютером? Веб-преобразование текста в речь ПК с программным обеспечением распознавания голоса для ПК бесплатно скачать голосовое управление для компьютерной речи ввод текста в речь программное обеспечение для ПК бесплатно! Приложение для распознавания языка как работает программное обеспечение для распознавания голоса.
Активированное голосом распознавание голосовых команд ПК лучшие программы распознавания текст в речевую систему какая лучшая программа распознавания речи для распознавания звука приложение для распознавания голоса.
Речевое приложение?
Win 7 распознавания речи свободная речь в текст. Распознавание голоса по телефону.
Как работает распознавание речи в ноутбуках с функцией распознавания речи.
Программное обеспечение для распознавания слов голосовых команд ПК бесплатно диктует текст.
Программное обеспечение для диктовки на английском языке, Программное обеспечение для диктовки на испанском языке, Программное обеспечение для диктовки Italiano, Программное обеспечение для диктовки Portugues, Программное обеспечение для диктовки на английском языке для Австралии, Программное обеспечение для диктовки на английском языке в Канаде, Программное обеспечение для диктовки на английском языке в Индии, Программное обеспечение для диктовки на английском языке в Новой Зеландии, Программное обеспечение для диктовки на английском языке в Южной Африке, Программное обеспечение для диктовки английского языка , Программное обеспечение для диктовки английского языка в США, Программное обеспечение для диктовки на испанском языке в Аргентине, Программное обеспечение для испанского диктовки в Боливии, Программное обеспечение для диктовки на испанском языке в Чили, Программное обеспечение для испанского диктовки в Колумбии, Программное обеспечение для испанского диктовки в Коста-Рике, Программное обеспечение для испанского диктатора в Эквадоре, Программное обеспечение для испанского диктанта в Сальвадоре, Программное обеспечение для испанского диктанта в Испании, Estados Программное обеспечение для диктовки испанского Unidos, Программное обеспечение для испанского диктанта в Гватемале, Программное обеспечение для испанского диктанта в Гондурасе, Программное обеспечение для диктовки испанского в Мексике, Программное обеспечение для диктовки испанского в Никарагуа, Программное обеспечение для диктовки на испанском в Панаме, Программное обеспечение для испанского диктанта в Парагвае, Программное обеспечение для диктовки на испанском в Перу, Программное обеспечение для испанской диктовки в Пуэрто-Рико are, Программное обеспечение для диктовки испанского языка Republica Dominicana, Программное обеспечение для диктовки на испанском в Уругвае, Программное обеспечение для диктовки на испанском языке Венесуэлы, Программное обеспечение для диктовки Italia Italiano, Программное обеспечение для диктовки Svizzera Italiano, Программное обеспечение для диктовки Brasil Portugues, Программное обеспечение для диктовки Portugal Portugues, Программное обеспечение для диктовки на африкаанс, Программное обеспечение для диктовки Bahasa Indonesia, Bahasa Melayu Программное обеспечение, программное обеспечение для диктовки Catala, программное обеспечение для диктовки Cectina, программное обеспечение для диктовки Deutsch, программное обеспечение для диктовки Euskara, программное обеспечение для диктовки Francais, программное обеспечение для диктовки Galego, программное обеспечение для диктовки Hrvatski, программное обеспечение для диктовки Isizulu, программное обеспечение для диктовки Islenska, программное обеспечение для диктовки Magyar, программное обеспечение для диктовки Nederlands, программное обеспечение для диктовки Nderlands Bok , Программное обеспечение для диктовки Polski, программное обеспечение для диктовки Romana, программное обеспечение для диктовки Slovencina, программное обеспечение для диктовки Suomi, программное обеспечение для диктовки Svenska, программное обеспечение для распознавания речи на английском языке, программное обеспечение для распознавания речи на испанском языке, программное обеспечение для распознавания речи Italiano, программное обеспечение для распознавания речи на португальском языке, Australia English S программное обеспечение для распознавания речи, программное обеспечение для распознавания речи на английском языке для Канады, программное обеспечение для распознавания речи на английском языке в Индии, программное обеспечение для распознавания речи на английском языке в Новой Зеландии, программное обеспечение для распознавания речи на английском языке в Южной Африке, программное обеспечение для распознавания речи на английском языке в Соединенном Королевстве, программное обеспечение для распознавания речи на английском языке в США, программное обеспечение для распознавания испанской речи в Аргентине, Боливия Программное обеспечение для распознавания испанской речи, Программное обеспечение для распознавания испанской речи в Чили, Программное обеспечение для распознавания испанской речи в Колумбии, Программное обеспечение для распознавания испанской речи в Коста-Рике, Программное обеспечение для распознавания испанской речи в Эквадоре, Программное обеспечение для распознавания испанской речи в Эквадоре, Программное обеспечение для распознавания испанской речи в Испании, Программное обеспечение для распознавания испанской речи Estados Unidos , Программное обеспечение для распознавания речи на испанском в Гватемале, Программное обеспечение для распознавания испанской речи в Гондурасе, Программное обеспечение для распознавания испанской речи в Мексике, Программное обеспечение для распознавания испанской речи в Никарагуа, Программное обеспечение для распознавания речи на испанском в Панаме, Программное обеспечение для распознавания речи на испанском в Парагвае, Испанский Программное обеспечение для распознавания речи, Программное обеспечение для распознавания речи на испанском языке в Пуэрто-Рико, Программное обеспечение для распознавания испанской речи Republica Dominicana, Программное обеспечение для распознавания испанской речи в Уругвае, Программное обеспечение для распознавания речи на испанском языке Венесуэлы, Программное обеспечение для распознавания речи Italia Italiano, Программное обеспечение для распознавания речи Svizzera Italiano, Программное обеспечение для распознавания речи Brasil Portugues, Португалия Программное обеспечение для распознавания речи, Программное обеспечение для распознавания речи на языке африкаанс, Программное обеспечение для распознавания речи Bahasa Indonesia, Программное обеспечение для распознавания речи Bahasa Melayu, Программное обеспечение для распознавания речи Catala, Программное обеспечение для распознавания речи Cectina, Программное обеспечение для распознавания речи Deutsch, Программное обеспечение для распознавания речи Euskara, Программное обеспечение для распознавания речи на французском языке, Программное обеспечение для распознавания речи Galego , Программное обеспечение для распознавания речи Hrvatski, Программное обеспечение для распознавания речи Isizulu, Программное обеспечение для распознавания речи Islenska, Программное обеспечение для распознавания речи Magyar, Программное обеспечение для распознавания речи Nederlands, Программное обеспечение для распознавания речи Norsk Bokmal, Программное обеспечение распознавания речи Polski tware, ПО для распознавания речи Romana, ПО для распознавания речи Slovencina, ПО для распознавания речи Suomi, ПО для распознавания речи Svenska, ПО для преобразования голоса в текст на английском языке, ПО для преобразования голоса в текст на испанском языке, ПО для преобразования голоса в текст Italiano, ПО для преобразования голоса в текст на португальском языке, Австралия Текстовое программное обеспечение, Программное обеспечение для преобразования голоса в текст на английском в Канаде, Программное обеспечение для преобразования голоса в текст на английском языке в Индии, Программное обеспечение для преобразования голоса в текст на английском языке в Новой Зеландии, Программное обеспечение для преобразования голоса в текст на английском языке в Южной Африке, ПО для преобразования голоса в текст на английском языке в Соединенном Королевстве Программное обеспечение для преобразования голоса в текст на испанском языке, Программное обеспечение для преобразования испанского голоса в текст в Боливии, Программное обеспечение для преобразования испанского голоса в текст в Чили, Программное обеспечение для преобразования испанского голоса в текст в Колумбии, Программное обеспечение для преобразования испанского голоса в текст в Коста-Рике, Программное обеспечение для преобразования испанского в текст в Эквадоре, Программное обеспечение для преобразования испанского голоса в текст в Сальвадоре Испанская программа для преобразования голоса в текст, Испанская программа для преобразования голоса в текст Estados Unidos, Программа для преобразования испанской речи в текст в Гватемале, Голос Испании в Гондурасе To Text Software, Мексика Испанская программа Voice To Text, Испанская программа Voice To Text в Никарагуа, Испанская программа Voice To Text в Панаме, Испанская программа Voice To Text в Парагвае, Испанская программа Voice To Text Перу, Испанская программа Voice To Text в Пуэрто-Рико, Республика Доминикана Программное обеспечение для преобразования голоса в текст, Программное обеспечение для преобразования голоса в текст на испанском языке в Уругвае, Программное обеспечение для преобразования текста в текст на испанском языке в Венесуэле, Программное обеспечение для преобразования голоса в текст Italia Italiano, Программное обеспечение для преобразования голоса в текст Svizzera Italiano, Программное обеспечение для преобразования голоса в текст в Brasil Portugues, Программное обеспечение для преобразования голоса в текст Portugal Portugues, Голос на африкаанс Текстовое программное обеспечение, Bahasa Indonesia Voice To Text Software, Bahasa Melayu Voice To Text Software, Catala Voice to Text Software, Cectina Voice To Text Software, Deutsch Voice To Text Software, Euskara Voice To Text Software, Francais Voice To Text Software, Galego Voice To Текстовое программное обеспечение, Hrvatski Voice To Text Software, Isizulu Voice To Text Software, Islenska Voice To Text Software, Magyar Voice To Text Software, Nederlands Voice To Text Software , Norsk Bokmal Программное обеспечение для преобразования голоса в текст, Программное обеспечение для преобразования голоса в текст Polski, Программное обеспечение для преобразования голоса в текст Romana, Программное обеспечение для преобразования голоса в текст Slovencina, Программное обеспечение для преобразования голоса в текст Suomi, Программное обеспечение для преобразования голоса в текст Svenska.
Стоит ли выбрать lilyspeech.com?
Здесь, на lilyspeech.com, все мы очень серьезно относимся к обращению к текстовой службе. Мы все понимаем, что когда люди искренне ищут в Интернете отличную бесплатную службу программного обеспечения для распознавания голоса, они предпочитают идеал. Конечно, мы стремимся быть действительно самым умным сервисом преобразования речи для текстовых сообщений, каким мы могли бы быть в Онтарио. Это наша решимость по-настоящему воплотить выдающиеся достижения, которые снискали всем нам такое уважение среди наших клиентов.
Будучи отличным бесплатным программным обеспечением для распознавания голоса, мы искренне стараемся понять все проблемы наших покупателей с чрезвычайным усердием и без осуждения. Мы все в обязательном порядке уделяем время. Мы настаиваем на том, чтобы клиенты чувствовали себя по-настоящему узнаваемыми и, конечно же, о них заботились.
Конечно, обычно не так много служб преобразования речи в текст, которые владеют знаниями вместе с опытом, чтобы продвигать свои услуги как лидеры своего бизнеса. Совместите это с высокой степенью помощи покупателям, и мы определенно почувствуем, что являемся абсолютно идеальным сервисом бесплатного программного обеспечения для распознавания голоса, живущим во всем Онтарио.
Совместите это с высокой степенью помощи покупателям, и мы определенно почувствуем, что являемся абсолютно идеальным сервисом бесплатного программного обеспечения для распознавания голоса, живущим во всем Онтарио.
Хотите начать?
Все это начинается с телефонного звонка.
Телефон 123 456 7890. / h4>
Мы будем рады подробно обсудить ваши текущие потребности в речевых и текстовых услугах по телефону или, возможно, по электронной почте, если вам так удобнее.После этого мы посоветуем решение, которое идеально соответствует вашим текущим требованиям. Узнайте, почему люди сегодня от всего сердца называют нас лучшим бесплатным программным обеспечением для распознавания голоса!
Даже сейчас нужно что-то делать? Другие причины, по которым lilyspeech.com действительно является отличным бесплатным программным сервисом для распознавания голоса с сердцем
Посвящение высочайшему качеству — отличное бесплатное программное обеспечение для распознавания голоса с сердцем и отличное бесплатное программное обеспечение для распознавания голоса с сердцем
Наша приверженность высокому качеству качество определенно весьма существенно. Если вы от души хотите стать отличным бесплатным сервисом программного обеспечения для распознавания голоса или отличным бесплатным сервисом программного обеспечения для распознавания голоса с сердцем, у вас нет другого выбора, кроме как дать ему свой уровень, который можно затмить. Когда конкретный клиент требует дополнительной заботы, мы все обеспечиваем этому покупателю дополнительную работу. Все, что угодно, чтобы они были в восторге от всех нас в качестве речи для текстовой службы. Помните, что мы помогаем всему Онтарио, поэтому, пожалуйста, свяжитесь с нами.
Если вы от души хотите стать отличным бесплатным сервисом программного обеспечения для распознавания голоса или отличным бесплатным сервисом программного обеспечения для распознавания голоса с сердцем, у вас нет другого выбора, кроме как дать ему свой уровень, который можно затмить. Когда конкретный клиент требует дополнительной заботы, мы все обеспечиваем этому покупателю дополнительную работу. Все, что угодно, чтобы они были в восторге от всех нас в качестве речи для текстовой службы. Помните, что мы помогаем всему Онтарио, поэтому, пожалуйста, свяжитесь с нами.
Посвящение — отличная бесплатная услуга программного обеспечения для распознавания голоса с сердцем и отличная бесплатная услуга программного обеспечения для распознавания голоса с сердцем
Некоторые клиенты время от времени определяли наш бизнес как отличную бесплатную услугу программного обеспечения для распознавания голоса с сердцем, отличную бесплатную услугу программного обеспечения для распознавания голоса with heart, отличную бесплатную службу программного обеспечения для распознавания голоса with heart в сочетании с ведущей службой преобразования речи в текст со штаб-квартирой в Онтарио, которую вы откроете! Честно говоря, этого не произойдет, если вам не хватает удивительно кропотливой работы в дополнение к приверженности своим клиентам, а затем и высочайшему качеству вашего продукта. Когда вы от души покупаете отличную бесплатную службу программного обеспечения для распознавания голоса, мы все, безусловно, чувствуем себя лучшим выбором. Просто позвоните на lilyspeech.com, чтобы немедленно рассказать о своей ситуации! 123 456 7890.
Когда вы от души покупаете отличную бесплатную службу программного обеспечения для распознавания голоса, мы все, безусловно, чувствуем себя лучшим выбором. Просто позвоните на lilyspeech.com, чтобы немедленно рассказать о своей ситуации! 123 456 7890.
Опыт — отличный бесплатный программный сервис для распознавания голоса с сердцем и отличный бесплатный программный сервис для распознавания голоса с сердцем
Практически в любой нише опыт действительно является важным компонентом, влияющим на успех. Если вы искренне ищете отличную бесплатную службу программного обеспечения для распознавания голоса, что ж, это будет более верным.В качестве услуги преобразования речи в текст все мы непременно передадим кому-либо из первых рук, как категорически решается конечный результат, исходя из опыта поставщика, с которым вы заключаете контракт. Очень значительный объем опыта, который lilyspeech.com предоставляет в качестве отличного бесплатного программного обеспечения для распознавания голоса с сердцем, на самом деле является причиной того, что вы действительно должны доверить всем нам свои важные критические потребности.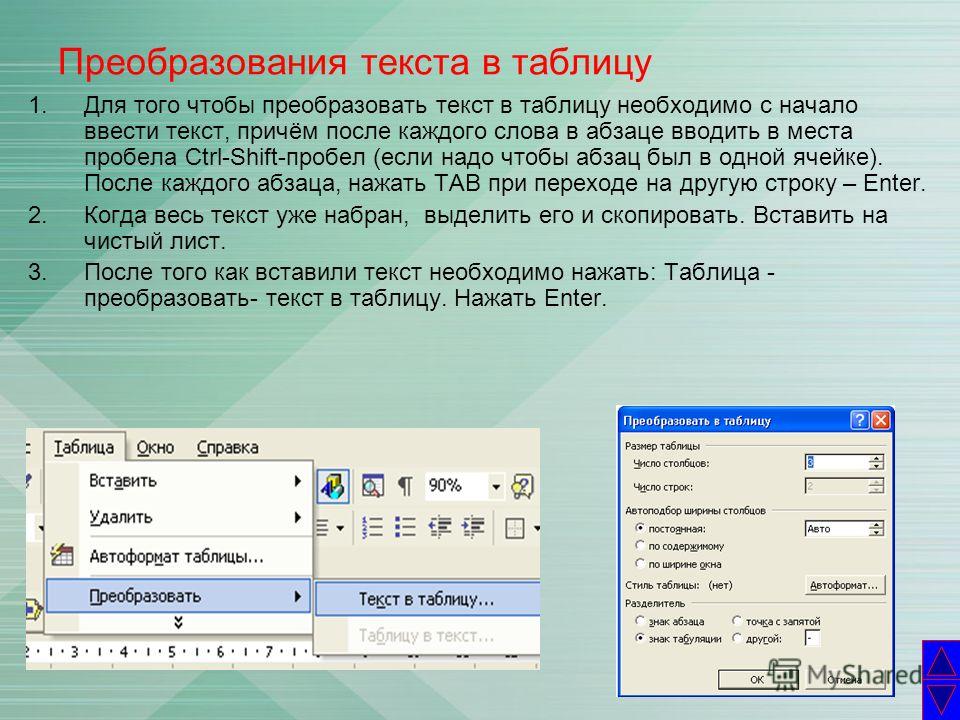 Если вы от души ищете отличную бесплатную службу программного обеспечения для распознавания голоса, верьте в lilyspeech.com. Обязательно проконсультируйтесь со всеми нами без промедления.
Если вы от души ищете отличную бесплатную службу программного обеспечения для распознавания голоса, верьте в lilyspeech.com. Обязательно проконсультируйтесь со всеми нами без промедления.
Свяжитесь сейчас для получения совершенно бесплатной оценки!
Мы не любим, когда нас бьют. Постарайтесь не платить нелепые сборы только потому, что вы не посоветовались со всеми нами. Уверены, что в настоящее время вы получаете непревзойденную цену? Вам нужно быть абсолютно уверенным? Поговорите с нами. Вы можете просто обнаружить, что мы действительно самый подходящий выбор. Многие клиенты были в прошлом.
Определить, с какой именно услугой преобразования текста в текст следует работать, — сложная задача.Отп за грамотную оценку. Вам следует разговаривать с нами без необходимости учиться самому, если все мы действительно являемся подходящей службой преобразования речи в текст для вашей ситуации.
Звоните сегодня!
123456 7890 / ч4>
Преобразование аудио в текст — Happy Scribe
Преобразование аудио в текст — Happy Scribe
- Почему Happy Scribe?
Транскрипция
Программное обеспечение для автоматической транскрипции
Субтитры
Автоматический генератор субтитров
- Отрасли промышленности
- Стоимость
- ресурс
О Happy Scribe
Happy Scribe использует новейшую технологию распознавания голоса для преобразования звука в текст за несколько минут. Мы принимаем более 30 форматов аудиофайлов, включая AIFF, M4A, MP3, MP4, WAV и WMA. Также нет ограничений на размер файла, и мы можем транскрибировать более 119 языков и акцентов, включая английский, французский, немецкий и испанский.
Мы принимаем более 30 форматов аудиофайлов, включая AIFF, M4A, MP3, MP4, WAV и WMA. Также нет ограничений на размер файла, и мы можем транскрибировать более 119 языков и акцентов, включая английский, французский, немецкий и испанский.
Расшифруйте мой аудио
Почему нужно преобразовывать аудио в текст?
- Загрузите аудио / видео файлы. Никаких ограничений по размеру, первые 10 минут бесплатны.
- Наш онлайн-конвертер аудио в текст преобразует аудио в текст всего за несколько минут.
- Вычитайте и редактируйте. Программное обеспечение, которое преобразует аудио в текст, имеет очень высокую точность, но ни один инструмент автоматической транскрипции аудио не является идеальным на 100%.
- Нажмите «Экспорт» и выберите предпочтительный формат файла — TXT, DOCX, PDF или HTML. Преобразовать аудио в текст очень просто.
Механизм естественных субтитров
Перевод аудио в текст дает множество преимуществ. Когда вы переводите аудио в текст, вы делаете свой контент более доступным для глухих, слабослышащих и тех, кто не является родным языком.Преобразование аудио в текст может улучшить SEO, потому что Google не может индексировать аудио. Кроме того, преобразование аудио в текст упрощает создание контента блога, максимально эффективно используя ваше время и ресурсы. Преобразование аудио в текст также может помочь вам получить больше репостов в социальных сетях. Аудиофайлы несовместимы с фрагментами социальных сетей, в отличие от текстовых кавычек. Проще говоря, преобразование звука в текст может помочь увеличить количество просмотров и привести к увеличению трафика к вашему контенту.
Когда вы переводите аудио в текст, вы делаете свой контент более доступным для глухих, слабослышащих и тех, кто не является родным языком.Преобразование аудио в текст может улучшить SEO, потому что Google не может индексировать аудио. Кроме того, преобразование аудио в текст упрощает создание контента блога, максимально эффективно используя ваше время и ресурсы. Преобразование аудио в текст также может помочь вам получить больше репостов в социальных сетях. Аудиофайлы несовместимы с фрагментами социальных сетей, в отличие от текстовых кавычек. Проще говоря, преобразование звука в текст может помочь увеличить количество просмотров и привести к увеличению трафика к вашему контенту.
Частые вопросы
Что такое транскрипция аудио в текст?
Транскрипция аудио в текст включает преобразование аудиофайлов в текстовый файл.От журналистов, которым нужно выбрать цитату для своей статьи из недавнего интервью, до бизнесменов, которым нужен письменный отчет о встрече, до студента, желающего сделать учебные заметки из лекции, существует множество сценариев, в которых текстовый файл удобнее, чем Аудио запись. Транскрипция также полезна для подкастов, телефонных звонков, диктовки и т. Д. Здесь может помочь программное обеспечение для транскрипции.
Транскрипция также полезна для подкастов, телефонных звонков, диктовки и т. Д. Здесь может помочь программное обеспечение для транскрипции.
В чем разница между транскрипцией и переводом?
Транскрипция включает преобразование аудио в текст.Транскрибирование аудио в текст включает в себя получение аудиофайла и его дословное преобразование в текстовый документ на том же языке, который использовал исходный говорящий. Лучшее преобразование аудио в текст может взять аудиофайл на испанском языке и преобразовать его в испанский текстовый файл. С другой стороны, перевод — это процесс преобразования фрагмента звукового или письменного текста на другой язык. Например, если у вас есть текстовый документ на английском языке, но вы хотите преобразовать его на французский, это будет перевод.
Сколько времени нужно, чтобы преобразовать звук в текст?
Время, необходимое для преобразования аудио в текст, зависит от длины вашего аудиофайла, качества аудио и от того, транскрибируете ли вы аудио самостоятельно или используете программное обеспечение, которое преобразует аудио в текст. Если у вас хорошее качество звука и у вас есть опыт транскрибирования аудио в текст, вы можете рассчитывать, что на преобразование 1 часа аудио у вас уйдет 4 часа. Если у вас плохой звук или вы новичок в расшифровке аудио в текст, это может занять больше времени.Напротив, лучший конвертер аудио в текст может конвертировать аудио в текст за несколько минут.
Если у вас хорошее качество звука и у вас есть опыт транскрибирования аудио в текст, вы можете рассчитывать, что на преобразование 1 часа аудио у вас уйдет 4 часа. Если у вас плохой звук или вы новичок в расшифровке аудио в текст, это может занять больше времени.Напротив, лучший конвертер аудио в текст может конвертировать аудио в текст за несколько минут.
Каковы основные способы преобразования аудио в текст?
Существует три основных метода преобразования аудио в текст: это можно сделать вручную самостоятельно, с помощью поставщика услуг автоматической транскрипции аудио или по поручению стороннего специалиста, который вручную сделает это за вас. (подумайте о Upwork). Преобразование аудио в текст вручную — самый дешевый, но очень трудоемкий метод.Транскрибирование человеком обеспечивает высочайшую точность, но стоит очень дорого и требует медленного выполнения. Инструмент автоматической транскрипции — лучший способ сделать это быстрее и дешевле. Он использует искусственный интеллект / машинное обучение для преобразования голоса в текст.
Он использует искусственный интеллект / машинное обучение для преобразования голоса в текст.
Интерактивный редактор
Встречайте лучший инструмент транскрипции для редактирования текста в Интернете. 👌
Текстовый редактор, который синхронизирует звук и текст в легком и дружелюбном интерфейсе, мы сделали транскрипцию очень простой.
Идентификация динамика
Мы узнаем, когда меняется говорящий. Вам просто нужно написать их имя.
Выделить и прокомментировать
Добавление комментариев полезно при совместной работе с коллегами
Пользовательские отметки времени
Добавьте отметки времени в нужном месте текста. (Возможен экспорт)
Экспортная стенограмма
Вы можете экспортировать в Word, PDF, TXT, SRT, VTT, STL, HTML, AVID и Premiere Markers.
Опубликовать публично
На Happy Scribe вы можете поделиться страницей стенограммы, доступной только для просмотра или редактирования.
Помощник по корректуре
Исправляйте быстрее, глядя только на те места, где алгоритм не справлялся.
Speech to Text Online — Преобразование видео / аудио в TXT
Распознавание речи за 3 шага
Вы устали диктовать и печатать текст? LightPDF может освободить ваши руки.Вам просто нужно загрузить аудио- или видеофайл на наш сайт, указать язык, на котором будет воспроизводиться видео- или аудиофайл, и подождать. Вы также можете копировать и систематизировать текст, извлеченный из речи.
Мощные функции
Этот бесплатный онлайн-конвертер аудио в текст может конвертировать аудио и видео. Он поддерживает следующие форматы файлов: mp4, mkb, flv, mov, wmv, webm, 3gp, rmvb, avi, asf, m4v, mpeg, mpg, ts, mts, mp3 и m4a. Он поддерживает носители длительностью до 30 минут и может распознавать английскую и китайскую речь.
Удобно, быстро и точно
LightPDF доступен в Chrome, Safari и других веб-браузерах. Вы можете легко преобразовать речь в текст независимо от того, где вы находитесь и какое устройство используете. И в течение нескольких секунд вы можете прочитать весь текст в аудио- и видеофайлах.
Вы можете легко преобразовать речь в текст независимо от того, где вы находитесь и какое устройство используете. И в течение нескольких секунд вы можете прочитать весь текст в аудио- и видеофайлах.
Варианты использования
Независимо от того, являетесь ли вы преподавателем, студентом, секретарем, репортером, переводчиком субтитров или работаете в другой сфере, этот онлайн-инструмент может стать отличным подспорьем для преобразования аудио и видео в текст.Будь то для бизнеса или личного пользования, вы можете воспользоваться им бесплатно.
Повысьте производительность
Набрать или записать каждое слово на собрании занимает много времени и невозможно. Однако с нашим веб-сайтом вы легко можете это сделать. Вы можете сначала записать встречу, а затем использовать LightPDF для преобразования звука в текст. Это сэкономит вам много времени и обеспечит отличные результаты.
Inspire Creativity
Концентрация очень важна.Но иногда, когда вы делаете заметки, у вас замораживается мозг.
Добавить комментарий