Модуль программа распознавания капчти Xevil. Сервис распознавания Google ReCaptcha, Yandex-Captcha, Solve Media.
Здравствуйте Друзья!
Январь 2017 года, стал ярким событием в многолетнем развитие программного комплекса Xrumer.
Вышедший модуль XEvil, не имеет аналогов в мире, по скорости и точности распознавания каптч (защитных изображений), только подумайте, скорость распознавания составляет 100 изображений в секунду, что никогда не смогут предоставить сервисы ручного распознавания (антикаптча, antigate и др.), тем более они берут за это деньги, а приобретая программу распознавания каптчи Xevil, Вы не будете далее тратить свои деньги на данные нужды.
А ГЛАВНОЕ!, Вы сможете применять его абсолютно к различным программам, работающим на одной машине, с установленном программным комплексом Хрумер.
Сложно поверить, но Xevil это софт который способен распознавать всем надоевшую уже Google ReCaptcha, Yandex-Captcha, Solve Media, там где приходится выбирать дорожные знаки, искать витрины и порой это ставит в тупик и приходится нервничать и терять время на работу(
Программа / модуль распознавания капчи Xevil, с радостью возьмет под свой контроль все процессы рутинного распознавания абсолютно любых видов каптч.
Стоит отметить, что модуль Xevil не продается отдельно, а идет в комплексе лицензий Стандарт и Бизнес, при покупке программного комплекса Хрумер, условия покупки можно изучить по данной ссылке.
Официальный сайт Xevil, представлен по ссылке – http://xevil.net/ru/
Вы сможете ознакомиться с демо версией, проверить принципы работы и принять решение о покупке программного комплекса Хрумер.
По всем вопросам покупки Xevil, просим Вас обращаться к Нашим специалистам.
С уважением к Вам, SaleSeo Xrumer Branch!
Новости
17. 05.20 Нововведения и улучшения в XRumer 19.0.5 + XEvil 4.0Длительный период закрытого бета-теста XEvil 4.0 завершился, и он доступен абсолютно всем владельцам лицензии «Стандарт» и «Бизнес» без каких-либо дополнительных оплат. добавлен модуль распознавания РеКапчи-2 «до галочки», с браузерной обработкой на основе Google Chromium , функционал которого включает:
05.20 Нововведения и улучшения в XRumer 19.0.5 + XEvil 4.0Длительный период закрытого бета-теста XEvil 4.0 завершился, и он доступен абсолютно всем владельцам лицензии «Стандарт» и «Бизнес» без каких-либо дополнительных оплат. добавлен модуль распознавания РеКапчи-2 «до галочки», с браузерной обработкой на основе Google Chromium , функционал которого включает:
Безлимитную многопоточность: вы можете устанавливать любое количество потоков, которые способна обработать система
Антибан-систему (прокси, получившие статус BANNED, программа вносит во внутренний блэк-лист, и старается не использовать в течение 2х часов)
Поддержку HTTP-прокси, SOCKS4 и SOCK5, Tor-Proxy, в том числе прокси с авторизацией
Назначение Cookie потокам через файл (как одиночный Cookie, так и набор)
Назначение Cookie, Proxy и User-Agent каждому из потоков через API
Детальную статистикуЧитать >>
11.01.20 Копия Нововведения и улучшения в XRumer 19.0.2 — 19.0.3База тексткапч дополнительно увеличена на +5000 новых тексткапч
обновлены прилагаемые базы
модернизированы инструменты «Анализатор баз», «Фильтр баз» и «Перемешать базу»:
теперь данные инструменты работают через внешние модули (DBProcessor32.exe и DBProcessor64.exe — в зависимости от разрядности ОС)
благодаря этому, значительно разгружается нагрузка на ресурсы XRumer-а
никаких специальных действий не требуется, механизм использование инструментов остаётся прежним — внешние модули подгружаются автоматически
благодаря поддержке 64 бит, теперь возможна обработка данными инструментами сколь угодно больших баз, на любом количестве потоков (в пределах возможностей CPU и RAM)
также, в «Анализаторе» и «Фильтре баз» реализована полноценная поддержка юникода (UTF-8)Читать >>
21.08.19 Нововведения и улучшения в XRumer 19.0 — 19.0.1Изменения и улучшения в XRumer 19.0
улучшена система защиты от взлома
значительно повышена детализация отладочных логов (папка Debug), для режима однопоточной отладки; это расширяет возможности по созданию и отладке Модификаций для разработчиков
значительно улучшена работа в режиме «Масс-ПМ»:
улучшена логика работы с платформами Ucoz, XenForo, Discuz, IPB, DLE
улучшено отладочное логирование действий программы
устранена ошибка «Range check error», которая могла возникать в тестовом режиме
добавлена поддержка vBulletin 4. 2.5, vBulletin 5.2.4, Yet Another Forum
2.5, vBulletin 5.2.4, Yet Another Forum
скорректирована логика формирования мульти-сообщений
улучшена логика получения списка пользователей
снижена вероятность работы «вхолостую»
улучшена логика заполнения имён получателей ЛСЧитать >>
28.01.19 Нововведения и улучшения в XRumer 19.0 — 19.0.1Изменения и улучшения в XRumer 19.0
улучшена система защиты от взлома
значительно повышена детализация отладочных логов (папка Debug), для режима однопоточной отладки; это расширяет возможности по созданию и отладке Модификаций для разработчиков
значительно улучшена работа в режиме «Масс-ПМ»:
улучшена логика работы с платформами Ucoz, XenForo, Discuz, IPB, DLE
улучшено отладочное логирование действий программы
устранена ошибка «Range check error», которая могла возникать в тестовом режиме
добавлена поддержка vBulletin 4.2.5, vBulletin 5.2.4, Yet Another Forum
скорректирована логика формирования мульти-сообщений
улучшена логика получения списка пользователей
снижена вероятность работы «вхолостую»
улучшена логика заполнения имён получателей ЛС
значительно улучшена работа в режиме «Антиспам»:….Читать >>
26.01.19 Нововведения и улучшения в XRumer 18.0 — 18.0.1Данное обновление существенно повышает эффективность работы в режиме Mass-PM, а также включает в себя ряд важных исправлений и улучшений.
обновлены прилагаемые базы:
All_Profiles_09_2018.txt — база всех профилей, более 319.000 ссылок
NotRus_Profiles_09_2018.txt — база иностранных профилей, более 264.000 ссылок
Rus_Profiles_09_2018.txt — русскоязычная база профилей, более 56.000 ссылок
RusNoUcoz_Profiles_09_2018.txt — русскоязычная база профилей без мусора (Ucoz и проч.), более 53.000 ссылок
Posting_09_2018.txt — проверенная база (гарантированное размещение поста), более 73.400 ссылок
Posting_09_2018_Big_Mixed. txt — «сырая» смешанная база, более 7.132.000 ссылок; база была значительно очищена от старых мёртвых ресурсов + было добавлено более миллиона новых
txt — «сырая» смешанная база, более 7.132.000 ссылок; база была значительно очищена от старых мёртвых ресурсов + было добавлено более миллиона новых
TrustedLinksFull.txt — «сырая» база трастовых форумов, более 72.000 ссылок
TrustedLinksChecked.txt — проверенная база трастовых форумов, более 17.600 ссылок
Читать >>
Как сервис распознавания капчи запустил бота для слепых
По данным ВОЗ, в мире сегодня около 217 млн людей со средними и серьезными нарушениями зрения, причем примерно 36 млн из них – слепые. Современные технологии постоянно открывают им новые возможности для интеграции в IT-среду. Для работы в интернете большинство слабовидящих пользуется программами экранного доступа, которые считывают происходящее на экране, а также речевыми синтезаторами, преобразующими цифровую информацию в устную речь.
Препятствие для ботов и слепых
Тем не менее, в интернете все больше графики, а одной из главных проблем для слепых и слабовидящих стали капчи – компьютерные тесты, призванные определять настоящих пользователей и не давать доступ к сайту программам, собирающим информацию. Чтобы подтвердить, что ты человек, надо ввести случайно генерируемый набор символов или распознать образы и ответить на вопрос – такая задача неподвластна существующим программам для слепых. Конечно, есть случаи, когда компания защищает сайт капчей с возможностью аудиораспознавания – это шаг навстречу людям с ограниченными возможностями. Если бы такой тип капчи использовало большее количество компаний, это частично решало бы проблему.
Однако сегодня участники рынка нередко забывают о нуждах слабовидящих и слепых людей, и с проблемой приходится справляться дргуими способами. Чтобы обойти это препятствие, чаще всего используют платные расширения для браузеров. Типичная проблема в таких случаях – поиск нового решения при смене браузера. Кроме того, расширения работают с английским языком, которым владеют не все. Решение этих проблем недавно предложил сервис RuСaptcha. Компания запустила в Telegram бота @BlindCaptchaBot, который помогает слабовидящим и слепым людям распознавать капчи.
Решение этих проблем недавно предложил сервис RuСaptcha. Компания запустила в Telegram бота @BlindCaptchaBot, который помогает слабовидящим и слепым людям распознавать капчи.
Как работает сервис RuСaptcha
RuСaptcha специализируется на автоматическом распознавании изображений, но обычно предоставляет эту услугу бизнесу. Например, сервисом пользуются компании, которым надо проверить позиции в поисковой системе. Также сервис необходим бизнесу для сбора и анализа больших объемов данных. Принцип работы прост: клиент загружает капчу и в течение считанных секунд получает ответ. Непосредственно распознаванием занимаются сотрудники на фрилансе, то есть сервису доступны все изображения, которые может распознать человек. Чтобы настроить процесс отправки капчи, компании-клиенты получают программный интерфейс (API), который позволяет интегрировать с сервисом их программное обеспечение. Стоимость услуги зависит от сложности капчи и загруженности сервиса.
Как работает бот
Запустить Telegram-бота в компании решили после того как о проблеме слепых людей с капчами им сообщил разработчик продуктов для слабовидящих. В боте функционал сервиса RuCaptcha приспособили для нужд слепых. Механика работы здесь тоже очень проста: пользователь высылает боту скриншот страницы и получает в ответ текст капчи, который уже можно озвучить или скопировать. При запуске бот обещает вернуть ответ в течение минуты. При этом само распознание в зависимости от сложности может занимать от 3-5 до 9-20 секунд. Бот платный, но сначала пользователь может его протестировать – для этого у него десять бесплатных распознаваний. По результатам компания собирает обратную связь, чтобы дорабатывать сервис. Несмотря на то, что услуга предоставляется на русском языке, именно в России развитие сервиса в нынешнем виде ограничено блокировкой Telegram.
Для развития проекта есть несколько вариантов, в том числе перевод на другие языки и добавление поддержки разных мессенджеров. Один из наиболее перспективных путей – разработка мобильного приложения, которое бы воспроизводило функционал Telegram-бота. Это не только избавит продукт от привязки к мессенджерам с их ограничениями, но и создаст альтернативу существующим расширениям, которые привязаны к браузерам. Кроме того, в приложении можно реализовать перевод сервиса на другие языки. В будущем такое приложение могло бы стать универсальным инструментом, помогающим незрячим людям работать в интернете.
Это не только избавит продукт от привязки к мессенджерам с их ограничениями, но и создаст альтернативу существующим расширениям, которые привязаны к браузерам. Кроме того, в приложении можно реализовать перевод сервиса на другие языки. В будущем такое приложение могло бы стать универсальным инструментом, помогающим незрячим людям работать в интернете.
ru:addons:capmonster:recognition [ZennoLab]
Чтобы начать распознавать капчи, вы должны включить эмуляцию капча-сервисов в настройках программы и запустить сервис распознавания, нажав кнопку Старт. После этого программа начнет перехватывать капчи. отправленные с ваших SEO-программ на эти сервисы, и будет распознавать их.
Работа и статистика
После того как сервис CapMonster по распознаванию капч запущен, вы можете проверять статистику и мониторить работу программы.
В первом блоке отображается статистика:
Статус сервера — запущен/остановлен.
Кол-во потоков — количество потоков обработки капч.
Обработанные капчи — кол-во капч, обработанных программой.
Распознанных капч — кол-во капч, распознанных программой.
Сэкономленные деньги — кол-во сэкономленных денег (которые вы бы потратили на распознавание через сервисы).
Среднее время ответа — среднее время ответа на одну капчу.
Во втором блоке на графике показывается процесс обработки капч, загрузка потоков и модулей.
В третьем вы можете наблюдать активность программы. Здесь отображается капчи, которые приходят на распознавание, время ответа на капчу, ответ на капчу и модуль, используемый для распознавания капчи.
База модулей
В этой вкладке будут отображаться все используемые модули CapMonster 2. Часть модулей будет добавляться с нашей стороны по мере их создания, часть модулей вы можете добавить вручную, если создадите их сами, или купите у кого-то. Для добавления просто кликаете на соответствующую иконку в меню и выбираете сохраненный модуль с жесткого диска. Для удаления — аналогично. Для каждого модуля будут отображаться его характеристики: тип капчи, номер версии модуля, процент распознавания, сложность капчи.
Часть модулей будет добавляться с нашей стороны по мере их создания, часть модулей вы можете добавить вручную, если создадите их сами, или купите у кого-то. Для добавления просто кликаете на соответствующую иконку в меню и выбираете сохраненный модуль с жесткого диска. Для удаления — аналогично. Для каждого модуля будут отображаться его характеристики: тип капчи, номер версии модуля, процент распознавания, сложность капчи.
Операции над модулями доступны в контекстном меню.
Можно включить или отключить нужный модуль, использовать один модуль для распознавания всех капч (в случае если нужный модуль не определяется автоматически), установить размеры капч (необходимо в случае если есть подходящий для капчи модуль, но не совпадают размеры присылаемых капч).
Универсальный модуль
Капчи, для которых нет специального модуля, будут отправляться на универсальный модуль. Данный модуль способен разгадывать более 10000 различных капч. Он является удаленным и не требует дополнительных ресурсов компьютера.
Для включения/отключения универсального модуля есть специальная настройка:
Пример распознавания капч через данный модуль:
Для
Что такое «Простая» и «Сложная» каптча?
Многие известные сервисы следят за взломом своих каптч и меняют алгоритмы при обнаружении факта взлома. Самый простой способ определить, что каптча взломана — посмотреть статистику и обнаружить каптчи, которые были правильно распознаны со скоростью, значительно превышающей человеческие возможности.
Чтобы не рубить сук, на котором мы все с вами сидим и не бороться с ветряными мельницами, мы решили ввести ограничение на время распознавания сложных каптч. Это значит, что ответ после распознавания некоторых видов каптч будет выдаваться программой с задержкой, зависящей от количества символов в каптче. Процессор в это время будет простаивать, поэтому такие задержки никак не отразятся на потреблении ресурсов компьютера.
ru/addons/capmonster/recognition.txt · Последние изменения: 2020/11/28 13:33 — zymlex
Пример взлома простой капчи за 15 минут с помощью машинного обучения | by NeuroHive Ru
У меня нет времени разрезать каждую из 10,000 картинок в фотошопе. Это бы заняло несколько дней, а у меня осталось всего 10 минут. И нельзя просто автоматически разделить все картинки на 4 одинаковых куска. Потому что алгоритм задает символам случайное горизонтальное положение:
Символы сдвинуты случайным образом, чтобы изображение было сложнее разделить.
К счастью, это всё же можно автоматизировать. При обработке изображений часто приходится находить связные области из пикселей одного цвета. Границы таких областей называют контурами. В OpenCV есть встроенная функция findContours(), которую мы используем, чтобы найти связные области.
Итак, начнем с изображения капчи:
Преобразуем изображение в бинарное (это называется thresholding), чтобы было легче найти связные области:
Далее, используем функцию findContours(), чтобы выделить связные группы пикселей, состоящие из одного цвета:
Теперь, нужно просто сохранить каждый прямоугольник как отдельное изображение. И, так как мы знаем последовательность символов в каждом изображении, можно подписать каждый прямоугольник своим символом при сохранении.
Погодите-ка! Тут есть проблемка! Буквы в капче иногда накладываются друг на друга:
И наш алгоритм отмечает их как одну:
Если проблему не решить, то у нас будут плохие обучающие данные. Это нужно исправить, потому что с такими данными мы обучим модель распознавать эти две слившиеся буквы как одну.
Простой выход из этой ситуации сказать, что если какой-то прямоугольник в ширину сильно больше, чем в высоту, то это нужно считать двумя буквами. В этом случае, прямоугольник можно просто разрезать посередине и считать, что этот два прямоугольника:
Мы разделим пополам все прямоугольники, ширина которых сильно превышает высоту, и будем считать их за две буквы. Способ слегка “химический”, но с этими капчами работает.
Способ слегка “химический”, но с этими капчами работает.
Теперь, когда у нас есть способ извлекать из капчи отдельные буквы, давайте прогоним наш алгоритм через весь датасет. Цель — получить много вариантов написания для каждой буквы. Каждую букву можно сохранять в отдельную папку.
Вот так выглядит моя папка с буквой “W” после того, как я запустил свой алгоритм:
Капчу обманули распознаванием речи
University of Maryland
Американские разработчики представили unCAPTCHA — алгоритм, который может обмануть аудио-капчу, используемую для слабовидящих пользователей. Алгоритм основан на различных системах распознавания речи и может расшифровать состоящую из цифр аудио-капчу с точностью 85,15 процента за 5,42 секунды. Описание работы unCAPTCHA представлено на сайте Мэрилендского университета.
Капча используется для того, чтобы выяснить, кто пытается воспользоваться каким-либо сервисом: человек или какая-нибудь программа для автоматизации действий в интернете. Самые распространенные капчи содержат текст и изображения, но также часто сопровождаются аудио для слабовидящих пользователей, которым необходимо под диктовку набрать несколько цифр. Среди сервисов, поддерживающих аудио-капчи, к примеру, — reCAPTCHA компании Google, который используется большинством современных веб-сайтов.
Разработчики из Мэрилендского университета под руководством Кевина Бока (Kevin Bock) решили создать алгоритм, который может взломать такую капчу.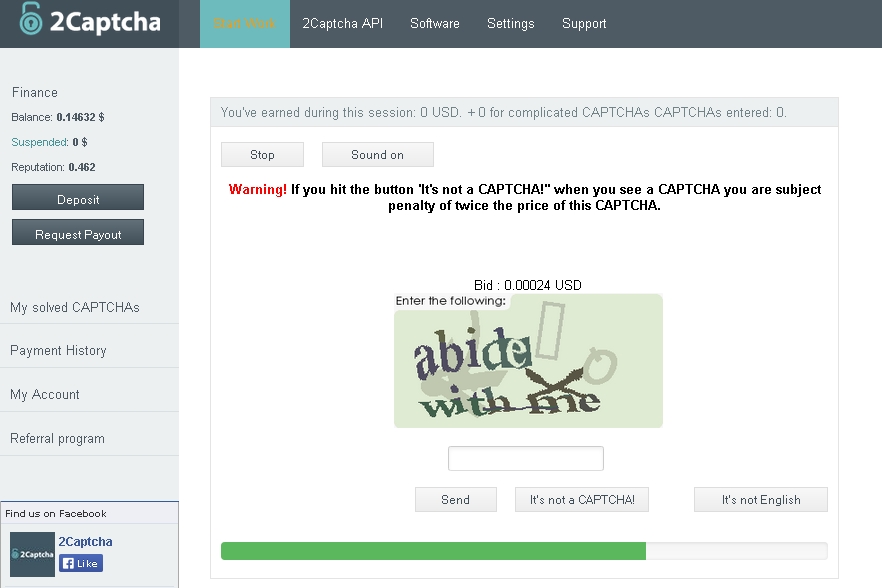 Алгоритм устроен следующим образом. Получив аудио-капчу, он делит ее на определенные сегменты по паузам, далее анализируя каждый из них с помощью нескольких алгоритмов распознавания речи. В случае, если один из алгоритмов сразу же предлагает определенную цифру, она записывается; если же системе кажется, что перед ней слово, то затем оно сопоставляется с цифрами, среди которых выбирается наиболее схожая фонетически.
Алгоритм устроен следующим образом. Получив аудио-капчу, он делит ее на определенные сегменты по паузам, далее анализируя каждый из них с помощью нескольких алгоритмов распознавания речи. В случае, если один из алгоритмов сразу же предлагает определенную цифру, она записывается; если же системе кажется, что перед ней слово, то затем оно сопоставляется с цифрами, среди которых выбирается наиболее схожая фонетически.
С помощью такого алгоритма разработчикам удалось добиться точности распознавания капчи в 85,15 процента. На сайте проекта сообщается, что после того, как авторы проекта уведомили Google о работе своей системы, в аудио-капчи reCAPTCHA добавили фразы вместо перечисления цифр. Тем не менее, новая версия unCAPTCHA справляется и с ними — причем с точностью свыше 90 процентов.
Взламывать капчи можно и с помощью распознавания изображений. В 2017 году такой алгоритм представили американские исследователи: он смог расшифровать примеры reCAPTCHA с точностью в 66,6 процента.
Елизавета Ивтушок
Antigate – сервис, который упрощает работу софта и позволяет заработать
Antigate.com используется для автоматического распознавания капч-картинок при регистрациях, отправлении сообщений, поиске и т.д. Все капчи в Antigate разгадываются вручную реальными пользователями. На линии работают постоянно 500-1000 человек, которые вводят текст с картинок. Это позволяет сервису разгадывать сколько угодно капч разной степени сложности.
На сегодняшний день Antigate является самым популярным в рейтинге подобных сервисов. За ручное распознавание текста с изображений в среднем платят 0,7 доллара за 1000 распознанных изображений или 2 копейки на 1 капчу:
Разработчикам SEO-софта Антигейт пригодится для повышения удобства своих программ для пользователей.
Минимальное пополнение в системе составляет 30 копеек. Плата взимается только за каждую загруженную картинку. Абонентская плата отсутствует. Пользоваться системой можно сразу после пополнения счета. Среднее время ожидания ответа – 15 секунд.
Количество одновременных загрузок неограниченно. Кроме того Antigate предоставляет точную статистику загрузок, поддерживает API протоколы Captchabot и De-Captcher.
Вебмастера и оптимизаторы используют сервис для автоматизации процесса распознавания капчи в используемых программах.
Отдельные пользователи используют Antigate для заработка. При этом за 1-2 часа пользователь может получить 1-2 бакса. В некоторых странах этого вполне достаточно для дополнительного и даже для основного дохода.
Партнерская программа предусматривает выплату 10%. Вывод заработанных средств производится на WMZ кошелек. При этом минимальная сумма вывода составляет 1 доллар:
Для начала следует зайти на http://antigate.com/ и регистрироваться:
На ваш почтовый ящик поступит уникальный ключ. Его можно использовать в разных программах, ознакомиться с которыми можно, заглянув в раздел «App Center» (новая версия) или «каталог софта» (старая версия). Панель управления приложениями находится по адресу http://anti-captcha.com/panel.
Далее нужно пополнить счет и вставить ваш персональный ключ Antigate в настройку программы, которая будет использовать данный сервис:
Рекомендуется устанавливать максимальную ставку (2 доллара). Несмотря на то, что средняя цена на 1000 капч составляет 0,7 доллара, для гарантированной работы потребуется немного больше. Чем выше вы установите цену, быстрее будет выполнено задание. Поняв как начать работать с сервисом, вы можете поставить 1 доллар, а затем повысить стоимость до 2 долларов и сравнить результаты.
При необходимости можно установить в настройках параметр «только русскоязычные работники». Данная опция пригодится, если вы работаете преимущественно с Рунетом.
Проверить баланс ключа можно, используя программу Antigate checker. Скачать ее можно здесь. Кроме того данный сервис проверяет привязанность к IP-адресу. Далее необходимо ввести свой ключ и нажать кнопку проверить.
Скачать ее можно здесь. Кроме того данный сервис проверяет привязанность к IP-адресу. Далее необходимо ввести свой ключ и нажать кнопку проверить.
Как проверить баланс ключа Antigate без скачивания программы? Нужно перейдите по ссылке:
http://antigate.com/res.php?key=%D0%9A%D0%9B%D0%AE%D0%A7&action=getbalance.
Далее необходимо вставить ключ в адресную строку вместо слова «КЛЮЧ», после чего должен появиться баланс счета.
Если вместо цифр возникло сообщение ERROR_WRONG_USER_KEY или BAD, возможно вы ввели информацию с пробелом либо ключ оказался неактивным:
Чтобы получить доход от ввода капчи с картинок сервис Антигейт предлагает перейти на страницу http://kolotibablo.com/ Приложение загружает в системе изображение и через несколько секунд получает набранный текст:
Каждая правильно введенная картинка стоит приблизительно 0,01 доллара. Интервал между возникновением картинок составляет 5-10 секунд. В минуту пользователи вводят 5-8 картинок. Соответственно в час можно заработать приблизительно 2 доллара. Для новичков этой суммы вполне достаточно. При этом от пользователя не требуется каких-либо специфических знаний. Начать работу можно с нуля.
Преимущества работы с Antigate.com очевидны. Данный сервис обеспечивает:
- Упрощенную работу разнообразного SEO-софта;
- Возможность получить стабильный доход без вложений;
- Легкий вывод заработанных денег через систему Webmoney, возможность перевода на другой аккаунт;
- Гарантию безопасности ваших денег в системе, предусматривающую ограничение доступа к IP. При покупке в магазинах вывод средств производится только с подтверждением по электронной почте;
- Партнерскую программу на основе инвайтов, позволяющую получить до 10% с каждого привлеченного клиента;
- Внушительный каталог программ, использующих данный сервис.
Безусловно, заработок на вводе капчи не способен обеспечить стойкое финансовое благополучие, но начать путь к успеху можно и с него.
unCaptcha 2 — сервис для обхода reCaptcha от Google с помощью сервиса Google — Сервисы на vc.ru
Работает в 90% случаев.
Проект unCaptcha 2 работает таким образом: он запрашивает проверку с помощью аудио, скачивает файл, который reCaptcha «произносит», с помощью Speech-to-Text от Google переводит его в текст и вставляет его в поле ввода ответа.
This projet defeat ReCaptcha with 91% accuracy 🤩. How? You might ask. They ask for the audio challenge, dl the mp3, forward it to Google Speech3Text API and submit the answer back… and it works 🤦🏻♂ https://buff.ly/2CO6s7V https://t.co/2wbksku9OK
946
1425
Разработчики указывают, что проект создан исключительно в образовательных целях. По их словам, разработчики reCaptcha из Google знают об этом методе и все равно разрешили опубликовать код проекта в открытом доступе.
22 202
просмотров
{
«author_name»: «Андрей Фролов»,
«author_type»: «editor»,
«tags»: [«recaptcha»],
«comments»: 62,
«likes»: 79,
«favorites»: 45,
«is_advertisement»: false,
«subsite_label»: «services»,
«id»: 54846,
«is_wide»: true,
«is_ugc»: false,
«date»: «Fri, 04 Jan 2019 19:56:01 +0300»,
«is_special»: false }
{«id»:14066,»url»:»https:\/\/vc. ru\/u\/14066-andrey-frolov»,»name»:»\u0410\u043d\u0434\u0440\u0435\u0439 \u0424\u0440\u043e\u043b\u043e\u0432″,»avatar»:»08df3230-e7c6-dc7f-e428-4885f4055663″,»karma»:122330,»description»:»\u0433\u043b\u0430\u0432\u043d\u044b\u0439 \u0440\u0435\u0434\u0430\u043a\u0442\u043e\u0440 vc.ru»,»isMe»:false,»isPlus»:true,»isVerified»:false,»isSubscribed»:false,»isNotificationsEnabled»:false,»isShowMessengerButton»:false}
ru\/u\/14066-andrey-frolov»,»name»:»\u0410\u043d\u0434\u0440\u0435\u0439 \u0424\u0440\u043e\u043b\u043e\u0432″,»avatar»:»08df3230-e7c6-dc7f-e428-4885f4055663″,»karma»:122330,»description»:»\u0433\u043b\u0430\u0432\u043d\u044b\u0439 \u0440\u0435\u0434\u0430\u043a\u0442\u043e\u0440 vc.ru»,»isMe»:false,»isPlus»:true,»isVerified»:false,»isSubscribed»:false,»isNotificationsEnabled»:false,»isShowMessengerButton»:false}
{«url»:»https:\/\/booster.osnova.io\/a\/relevant?site=vc»,»place»:»entry»,»site»:»vc»,»settings»:{«modes»:{«externalLink»:{«buttonLabels»:[«\u0423\u0437\u043d\u0430\u0442\u044c»,»\u0427\u0438\u0442\u0430\u0442\u044c»,»\u041d\u0430\u0447\u0430\u0442\u044c»,»\u0417\u0430\u043a\u0430\u0437\u0430\u0442\u044c»,»\u041a\u0443\u043f\u0438\u0442\u044c»,»\u041f\u043e\u043b\u0443\u0447\u0438\u0442\u044c»,»\u0421\u043a\u0430\u0447\u0430\u0442\u044c»,»\u041f\u0435\u0440\u0435\u0439\u0442\u0438″]}},»deviceList»:{«desktop»:»\u0414\u0435\u0441\u043a\u0442\u043e\u043f»,»smartphone»:»\u0421\u043c\u0430\u0440\u0442\u0444\u043e\u043d\u044b»,»tablet»:»\u041f\u043b\u0430\u043d\u0448\u0435\u0442\u044b»}},»isModerator»:false}
Обход капчи с помощью нашего API с разных языков
Документация по API для обхода капчи
Чтобы использовать наш сервис для решения капчи и рекапчи, нужно использовать API.
Чтобы использовать API, у вас должна быть учетная запись на bestcaptchasolver.com, немного кредита и строка токена доступа . Токен доступа можно получить на странице / account.
Аутентификация конечных точек API выполняется с использованием токена доступа.
Чтобы упростить задачу, мы разработали библиотеки API, так что вам не нужно беспокоиться о реализации нашего API. Для тех, кто хочет реализовать свои собственные библиотеки API или не может найти библиотеку для определенного языка программирования, этот документ призван помочь вам в этом.
Запросы и ответы в JSON.
Библиотеки
Автоматизация
Мы создали для вас несколько примеров автоматизации с браузером и с чистыми запросами, чтобы лучше понять, как интегрировать наш сервис с программным обеспечением для автоматизации, которое можно найти на нашем / bypass-captcha-solver -страница автоматизации
Баланс
GET https: // bcsapi. xyz / api / user / balance? access_token = YOUR_ACCESS_TOKEN
xyz / api / user / balance? access_token = YOUR_ACCESS_TOKEN
Параметры запроса :
Возвращает баланс пользователя. Баланс указан в долларах США.
Возврат
{
"status": "успех",
"balance": "5.2164"
} Image captcha
Процесс завершения изображения captcha состоит из двух частей:
- submission — отправить изображение captcha как строку в кодировке B64, которая возвращает ID
- search — используйте ID полученный в заявке, для проверки завершения капчи
Отправить
POST https: // bcsapi.xyz / api / captcha / image
Параметры тела :
{
"b64image": "/ 9j / 4AAQSkZJRgAB ... iiigD // 2Q ==",
"access_token": "your_access_token"
} - b64image — изображение, закодированное как строка B64
- access_token — маркер доступа пользователя
- is_case ( опционально ) — установить значение
trueили1, если ввод текста чувствителен к регистру - is_phrase ( необязательно ) — если текст captcha является фразой (содержит хотя бы один пробел), установить значение
true - is_math ( optional ) — указывает работнику, что необходимо вычислить математическую captcha, установить
true - буквенно-цифровой ( необязательно ) — установить
1, если текст captcha содержит только цифры, установитетолько 2букв - minlength ( необязательно ) — минимальная длина текст капчи, т.е.e
5, по умолчанию:любой - maxlength ( необязательно ) — максимальная длина текста captcha, т.
 е.
е. 8, по умолчанию:любая - affiliate_id ( необязательно ) — идентификатор
аффилированное лицочек / страница партнера
 е.
е. Возврат
{
"id": 25,
"статус": "отправлено"
} ID в этом случае будет 25. Используйте его для получения фактического текста изображения.
Лимит пост-данных 10 Мб. Другими словами, размер изображения не может превышать 10 Мб.
Получить
GET https://bcsapi.xyz/api/captcha/CAPTCHA_ID?access_token=ACCESS_TOKEN
Параметры запроса :
- t
- получено из представления
- access_token — токен доступа, с помощью которого была отправлена информация о капче
Returns
{
"id": 25,
"текст": "полум",
"статус": "завершено"
} Как только вы получили идентификатор для своего изображения captcha, используйте эту конечную точку для получения текста, он уже завершен на этом этапе
reCAPTCHA
- UPDATE 15.01.2021 — Добавлена поддержка reCAPTCHA Enterprise (v2 & v3)
- ОБНОВЛЕНИЕ 27.07.2018 — Добавлена поддержка reCaptcha V3
Чтобы обойти recaptcha, есть (как минимум) две вещи, которые вам нужно знать:
- url страницы — URL, на который вы включили капчу
- ключ сайта — recaptcha (общедоступный) sitekey, который можно найти в исходном коде веб-сайта
То же, что и с изображением капчи, процесс решения reCAPTCHA состоит из двух частей:
- отправить детали капчи
- получить g-response ( g-ответ будет использоваться для обхода капчи на странице )
Обход рекапчи занимает больше времени, чем решение обычная графическая капча.
После того, как вы отправите информацию о капче (URL-адрес страницы и ключ сайта ), время выполнения составит ~ 30 секунд.
Отправить
POST https://bcsapi.xyz/api/captcha/recaptcha
Параметры тела :
{
"page_url": "http://website.com",
"site_key": "6fd45trQJsd ... br",
"access_token": "your_access_token"
} - access_token — токен доступа пользователя
- page_url — URL страницы recaptcha
- site_key — sitekey (открытый ключ) recaptcha
- Тип ( необязательно ) — значение по умолчанию 1 ( то есть v2) если не указано
-
1— v2 -
2— невидимо -
3— v3 -
4— enterprise v2 -
5— enterprise v3
-
- v3_action ( необязательно ) — значение действия, используемое при решении рекапчи v3, оставьте пустым, если нет действий
- v3_min_score ( необязательно ) — таргетинг на минимальную оценку при решении v3,
float, i.e0,4 - data_s ( опционально ) — значение данных recaptcha, используемое при загрузке reCAPTCHA
- cookie_input ( опционально ) — используется при загрузке reCAPTCHA
- user_agent ( опционально ) User-Agent, используемый для решения reCAPTCHA
- прокси ( опционально ) — прокси в формате
12.34.56.78:8080илипользователь: [email protected]: 8080, если требуется аутентификация - proxy_type ( опционально ) — идет с
прокси-параметром, и на данный момент это может быть толькоHTTP, потому что в настоящее время мы поддерживаем только этот тип прокси - affiliate_id ( опционально ) — ID
аффилированного лицастраница чека / партнера
Возврат
{
"id": 26,
"статус": "отправлено"
} Получить
То же , что и при получении изображения captcha, запрос выполняется таким же образом. Единственное, что отличается, — это ответ. Отличие заключается в том, что вместо параметра text взамен вы получаете параметр gresponse .
Единственное, что отличается, — это ответ. Отличие заключается в том, что вместо параметра text взамен вы получаете параметр gresponse .
GET https://bcsapi.xyz/api/captcha/RECAPTCHA_ID?access_token=ACCESS_TOKEN
Параметры запроса :
- recaptcha_ID — идентификатор доступа к 50 получен из — идентификатор доступа к Информация о капче была отправлена
Возврат
{
"id": 25,
"gresponse": "03AJpayVFactgTmHlV... ",
// оценка v3 (нашей тестовой капчи), если тип отправки - v3
"v3_score": "0,3",
// возвращается в некоторых случаях, если вы хотите убедиться, что cookie_output также возвращается
// отправляем капчу с помощью cookie_input
"cookie_output": "NID: 22 = AvGseFW ... SDwfg4",
"статус": "завершено",
"proxy_status": "статус прокси (если используется)"
} gresponse используется для обхода капчи на веб-сайте. Все очень по-разному, в зависимости от сайта. Обычно, в случае автоматизации браузера, вы устанавливаете ответ, полученный от нашего сервиса, в DOM страницы с помощью JavaScript.
Если это автоматизация, основанная на чистых запросах, обычно gresponse отправляется с самим запросом, будь то логин, регистрация и т. Д.
GeeTest
Необходимые параметры для решения через службу bestcaptchasolver:
- домен
- gt
- вызов (уникальный)
ВАЖНО!
Geetest Challenge работает только один раз! Если вы отправите капчу с вызовом, вы больше не сможете повторно использовать ту же задачу, капча не будет решена
Отправить
POST https: // bcsapi.xyz / api / captcha / geetest
Параметры тела :
{
"домен": "http://website. com",
"gt": "8a7610 ... fd7f58bb",
"вызов": "dd44ab5 ... c056f7d5",
"access_token": "your_access_token"
}  com",
"gt": "8a7610 ... fd7f58bb",
"вызов": "dd44ab5 ... c056f7d5",
"access_token": "your_access_token"
}
com",
"gt": "8a7610 ... fd7f58bb",
"вызов": "dd44ab5 ... c056f7d5",
"access_token": "your_access_token"
} - access_token — токен доступа пользователя
- домен — страница / домен, на котором вы встретили капчу
- gt — параметр gt (geetest)
- вызов — уникальный вызов GeeTest, необходимый для решение капчи (становится недействительным после 1-го использования)
- прокси ( опционально ) — прокси в формате
12.34.56.78: 8080илипользователь: [email protected]: 8080, если требуется аутентификация - proxy_type ( необязательно ) — идет с параметром прокси , а пока это может быть только
HTTPпотому что в настоящее время мы поддерживаем только этот тип прокси. - affiliate_id ( необязательно ) — ID
аффилированного лицастраница проверки / партнера
Возврат
{
"id": 30,
"статус": "отправлено"
} Получить
GET https: // bcsapi.xyz / api / captcha / GEETEST_ID? access_token = ACCESS_TOKEN
Параметры запроса :
- geetest_id — идентификатор получен из отправки
- access_token — токен доступа
0
0ur 950755 был отправлен
{ "id": 30, "решение": { "вызов": "8ab8af73c1 ... ffc63f5f", "проверить": "d628bb2 ... fb097e6546", "seccode": "d628bb213 ... dfb097e6546 | Иордания" }, "статус": "завершено" }Используйте данные внутри объекта решения, чтобы обойти страницу ввода кода GeeTest.
Capy
Требуемые параметры для решения через службу bestcaptchasolver:
Отправить
POST https://bcsapi. xyz/api/captcha/capy Body paramaters :
{ "page_url": "http://website.com", "site_key": "Cme4hZL ... 2D3uNms5w", "access_token": "your_access_token" }- access_token — токен доступа пользователя
- page_url — страница / домен, на котором вы встретили captcha
- site_key — sitekey для капчи, можно получить из источника / DOM страницы
- прокси ( опционально ) — прокси в формате
12.34.56.78: 8080илипользователь: [email protected]: 8080, если требуется аутентификация - proxy_type ( необязательно ) — идет с параметром прокси , а пока это может быть только
HTTPпотому что в настоящее время мы поддерживаем только этот тип прокси. - affiliate_id ( необязательно ) — ID
аффилированного лицастраница проверки / партнера
Возврат
{ "id": 30, "статус": "отправлено" }Получить
GET https: // bcsapi.xyz / api / captcha / CAPY_ID? access_token = ACCESS_TOKENПараметры запроса :
- capy_id — id, полученный из отправки
- access_token — токен доступа, с которым была отправлена информация о captcha 95070004
{ "id": 30, "решение": "0x0x8ex0xax84x0 ... x1ix0x76x18x", "статус": "завершено" }hCaptcha
Обязательные параметры для решения через службу bestcaptchasolver:
Отправить
POST https: // bcsapi.xyz / api / captcha / hcaptchaПараметры тела :
{ "page_url": "http://website.com", "site_key": "Cme4hZL ... 2D3uNms5w", "access_token": "your_access_token" }- access_token — токен доступа пользователя
- page_url — страница / домен, на котором вы встретили captcha
- site_key — sitekey для капчи, можно получить из источника / DOM страницы
- прокси ( опционально ) — прокси в формате
12.или 34.56.78: 8080 пользователь: [email protected]: 8080, если требуется аутентификация - proxy_type ( необязательно ) — идет с параметром прокси , а пока это может быть только
HTTPпотому что в настоящее время мы поддерживаем только этот тип прокси. - affiliate_id ( необязательно ) — ID
аффилированного лицастраница проверки / партнера
Возврат
{ "id": 31, "статус": "отправлено" }Получить
GET https: // bcsapi.xyz / api / captcha / HCAPTCHA_ID? access_token = ACCESS_TOKENПараметры запроса :
- hcaptcha_id — идентификатор, полученный из отправки
- access_token
0 captcha55 — информация о токене доступа
была отправлена с которого был отправлен
{ "id": 31, "решение": "PmL43f64f1zc ... z3fpclM", "статус": "завершено" }Используйте данные внутри объекта решения для обхода страницы с hCaptcha
FunCaptcha (Arkose Labs)
Обязательные параметры для решения через службу bestcaptchasolver:
Отправить
POST https: // bcsapi.xyz / api / captcha / funcaptchaПараметры тела :
{ "page_url": "http://website.com", "s_url": "https://api.arkoselabs.com", "site_key": "11111-11 ..- 11-11111", "access_token": "your_access_token" }- access_token — токен доступа пользователя
- page_url — страница / домен, на котором вы встретили captcha
- s_url — API / исходный URL для funcaptcha
- site_key — sitekey для captcha, can быть собраны из источника / DOM страницы
- данных ( необязательно ) — дополнительные данные в формате JSON, используемые при загрузке прокси FunCaptcha
- ( необязательно ) — прокси в формате
12.или 34.56.78: 8080 пользователь: [email protected]: 8080, если требуется аутентификация - proxy_type ( необязательно ) — идет с параметром прокси , а пока это может быть только
HTTPпотому что в настоящее время мы поддерживаем только этот тип прокси. - affiliate_id ( необязательно ) — ID
аффилированного лицастраница проверки / партнера
Возврат
{ "id": 31, "статус": "отправлено" }Получить
GET https: // bcsapi.xyz / api / captcha / FUNCAPTCHA_ID? access_token = ACCESS_TOKENПараметры запроса :
- funcaptcha_id — идентификатор, полученный из представления
- отправленный токен доступа
0
— токен доступа , с которым был отправлен токен доступа{ "id": 31, "решение": "56460421add ... | surl = https: //api.arkoselabs.com", "статус": "завершено" }Установить неверную капчу
Используйте ее, если наш сервис решил капчу, но она была неправильной
POST https: // bcsapi.xyz / api / captcha / bad / CAPTCHA_IDПараметры запроса :
- captcha_id — это идентификатор капчи, которая была введена неправильно
Параметры тела
900_token «access : «FFB0BF8905CA4AD992C8BE256F35682F»}
- access_token — access_token, с которым была отправлена капча
Возвращает
{ "id": 53, "статус": "обновлено" }или
{ "id": 53, "status": "уже установлено плохое" }Ошибки
- Неверный или отсутствующий ключ доступа
{ "статус": "ошибка", "message": "токен доступа недействителен или отсутствует" } - неправильный / несуществующий ключ доступа
{ "статус": "ошибка", "message": "ошибка аутентификации" } - решение тайм-аута капчи
{ "статус": "ошибка", "сообщение": "истекло время ожидания" } - без капчи с заданным ID
{ "статус": "ошибка", "message": "нет captcha с данным ID" }
Поддержка 2captcha, DBC и antiicaptcha API
Мы разработали шлюз captcha, который позволяет перенаправлять трафик от других сервисов captcha через bestcaptchasolver.
В настоящее время мы интегрировали следующие службы:- 2captcha.com
- deathbycaptcha.com
- anti-captcha.com
Redirection
Gates перенаправляет следующие действия в нашу службу:
- get баланс
- отправить изображение captcha
- получить изображение captcha
- отправить recaptcha
- получить ответ recaptcha
Другими словами, если у вас есть программное обеспечение, которое работает с любой из вышеуказанных служб, используйте шлюз позволит вам использовать наш сервис с тем же программным обеспечением для обхода всех ваших капч.
Это достигается запуском программы batch , которая записывает информацию о конфигурации в файл hosts, операционной системы Windows. Все это происходит автоматически, все, что вам нужно сделать, это запустить его. Для Linux у нас есть скрипт python, который позволяет вам переключать (включать / отключать) пару IP-ДОМЕНОВ
Последний шаг — использовать для замены токена доступа ИЛИ имени пользователя и пароля учетными данными из / account . Таким образом, программы будут работать, даже если они были созданы для одной из вышеперечисленных служб, но на самом деле наша служба будет использоваться для завершения.
Если вы больше не хотите использовать шлюз, вы можете отредактировать файл hosts, который находится здесь:
% SystemRoot% \ System32 \ drivers \ etc \ hostsВ Linux вы найдете хосты файл в
/ etc / hostsОбе операционные системы требуют доступа администратора / root для изменения файлов
Для получения дополнительной информации о файле hosts проверьте эту ссылку
Установка
Клонировать репозиторий github
git clone https: // github. com / bestcaptchasolver / gates После того, как вы его получите, перейдите в папку scripts / windows и запустите файл bat для службы, которую вы хотите перенаправить
Он запросит у вас права администратора, потому что он пишет на системный файл, разрешите его, и шлюз должен быть включен в течение нескольких секунд
Для Linux, здесь используется сценарий:
./linux_hosts.py 127.0.0.1 site.com, который можно найти в скриптах / linuxПосмотреть на github>
Загрузить>
Автоматический решатель CAPTCHA на основе глубокого обучения — Навстречу AI — Лучшее из технологий, науки и техники
Автор (ы): Сергей Исаев
Компьютерное зрение, кибербезопасность, глубокое обучение
Использование сложной 10-символьной CAPTCHA (с кодом)
Фото Маркуса Списке на Unsplash.
Заявление об ограничении ответственности : Следующая работа была создана как академический проект. Работа не использовалась и не предназначалась для использования во вредных или злонамеренных целях. Наслаждаться!
Введение
CAPTCHA (полностью автоматизированный общедоступный тест Тьюринга для различения компьютеров и людей) — это то, с чем сталкивался почти каждый пользователь Интернета. В процессе входа в систему или создания учетной записи, совершения онлайн-покупки или даже публикации комментария многие люди сталкиваются со странно выглядящими, растянутыми, размытыми, цветными и искаженными изображениями, больше напоминающими картину Дали, чем английский текст. .
Долгое время при развертывании использовалась 10-символьная CAPTCHA с размытым текстом, потому что современные методы компьютерного зрения затрудняли распознавание букв на неоднородном фоне, в то время как люди не испытывают проблем с этим. Это остается важной проблемой в области распознавания символов и по сей день.
Таким образом, чтобы разработать программу, способную считывать символы в этой сложной задаче оптического распознавания символов, мы разработаем индивидуальное решение для конкретной проблемы.В этой статье мы перейдем к началу и завершим конвейер разработки решателя CAPTCHA для определенного класса CAPTCHA.
Данные
10000 изображений CAPTCHA были предоставлены из набора данных kaggle (скопировано Aadhav Vignesh, https://www.kaggle.com/aadhavvignesh/captcha-images). У каждого изображения имя NAME.jpg, где NAME — решение головоломки. Другими словами, ИМЯ содержит правильные буквы в правильной последовательности изображения, например 5OfaXDfpue.
Заставить компьютерную программу читать символы внутри изображения представляет собой серьезную проблему.Программное обеспечение OCR с открытым исходным кодом, такое как PyTesseract, терпело неудачу при тестировании на CAPTCHA, часто даже не выделяя ни одного символа из всего изображения. Обучение нейронной сети с необработанными изображениями в качестве входных данных и решениями в качестве выходных данных может быть успешным для набора данных из десятков миллионов, но вряд ли будет успешным с набором данных из 10 000 изображений. Необходимо разработать новый метод.
Проблему можно значительно упростить, анализируя по одному символу, а не все изображение сразу.Если можно получить набор данных из буквенно-цифровых символов и соответствующих им меток, простую нейронную сеть, подобную MNIST, можно обучить распознавать символы. Таким образом, наш пайплайн выглядит так:
- Инвертируйте CAPTCHA, сегментируйте символы и сохраняйте каждый буквенно-цифровой символ отдельно на диск (с его меткой).
- Обучите нейронную сеть распознавать персонажей каждого класса.
- Чтобы использовать нашу модель, введите любую CAPTCHA, инвертируйте изображение и сегментируйте символы.Примените модель машинного обучения к каждому персонажу, получите прогнозы и объедините их в строку. Вуаля.
Предварительная обработка
Для тех из вас, кто следит за моим кодом на Kaggle (https://github.com/sergeiissaev/kaggle_notebooks), следующий раздел относится к записной книжке под названием captchas_eda.ipynb. Мы начинаем с загрузки случайного изображения из набора данных, а затем его построения.
Это случайно выбранная CAPTCHA из нашего набора данных.
Затем с помощью OpenCV (очень полезная библиотека компьютерного зрения, доступная на Python и C ++) изображение преобразуется в оттенки серого, а затем применяется бинарный порог.Это помогает преобразовать сложное разноцветное изображение в гораздо более простое черно-белое изображение. Это очень важный шаг — современная технология распознавания текста часто дает сбой, когда текст находится на неоднородном фоне. Этот шаг устраняет эту проблему. Однако мы еще не готовы к OCR.
Изображение CAPTCHA с пороговым значением и инвертированным цветом.
Следующим шагом является определение контуров изображения. Вместо того, чтобы иметь дело с CAPTCHA в целом, мы хотим разделить CAPTCHA на 10 отдельных изображений, каждое из которых содержит одно буквенно-цифровое значение.Поэтому мы используем функцию OpenCV findContours для определения контуров букв.
Изображение с выделенными контурами. Обратите внимание на маленькие зеленые точки вокруг верхнего и нижнего краев изображения, которые добавляются к нашему списку контуров.
К сожалению, большинство изображений имеют более 20 контуров, несмотря на то, что мы знаем, что каждая CAPTCHA содержит ровно 10 буквенно-цифровых символов. Так какие же оставшиеся контуры можно подобрать?
Ответ в том, что это в основном фрагменты клетчатого фона.Согласно документам, «контуры можно объяснить просто как кривую, соединяющую все непрерывные точки (вдоль границы), имеющие одинаковый цвет или интенсивность». Некоторые пятна на заднем плане соответствуют этому определению. Чтобы проанализировать контуры и сохранить только те символы, которые нам нужны, нам нужно проявить творческий подход.
Поскольку фоновые точки намного меньше буквенно-цифровых, я определил 10 самых больших контуров (опять же, каждая капча имеет ровно 10 буквенно-цифровых символов на изображении), а остальные отбросил.
Индивидуально подобранные буквенно-цифровые символы. Были выбраны 10 самых больших контуров, чтобы удалить мелкие контуры фона. Обратите внимание на неправильный порядок букв и цифр.
Однако возникает новая проблема. У меня есть 10 контуров, отсортированных по размеру. Конечно, при решении CAPTCHA порядок имеет значение. Мне нужно было организовать контуры слева направо. Поэтому я отсортировал словарь, содержащий правый нижний угол каждого из контуров, связанных с номером контура, что позволило мне построить контуры слева направо как один график.
Буквенно-цифровые символы, каждая со своим изображением и в правильном порядке. Правильный порядок позволяет отображать метку (истинный класс) над каждым изображением, а также процент изображения, занимаемого белыми пикселями.
Однако я заметил, что многие из выводов были бессмысленными — изображения не соответствовали этикетке. Хуже того, из-за того, что одно изображение не соответствовало его метке, это часто нарушало порядок всех последующих букв, а это означало, что не только одна, но и многие отображаемые буквы имели неправильные метки.Это может иметь катастрофические последствия для обучения нейронной сети, поскольку неверно помеченные данные могут сделать обучение гораздо более подверженным ошибкам. Представьте, что вы показываете буквы 4-летнего ребенка, но иногда произносите неправильный звук для этой буквы — это будет серьезной проблемой для ребенка.
Я выполнил две проверки ошибок. Первый был для контуров, которые являются полной ерундой, которые, как я заметил, обычно имели очень разные отношения белого к черному пикселям, чем обычные буквы. Вот пример:
Третий контур в верхнем ряду — это пример изображения, которое будет пропущено моим первым алгоритмом проверки ошибок.
Третий контур в верхнем ряду на самом деле является внутренним кругом предыдущей буквы «О».
Обратите внимание, что все последующие письма теперь также неправильно помечены. Мы не можем позволить себе добавлять эти неправильно помеченные изображения к нашим обучающим данным. Поэтому я написал правило, согласно которому любые буквы и цифры с соотношением белого к черному выше 63% или ниже 29% будут пропущены.Вот пример моей второй проверки ошибок:
Крайнее правое изображение в верхнем ряду, а также среднее изображение в нижнем ряду иллюстрируют тип ошибки №2.
Иногда отдельные буквенно-цифровые символы слегка соприкасаются друг с другом и воспринимаются как одна буквенно-цифровая. Это большая проблема, потому что, как и при проверке ошибок №1, затрагиваются все последующие буквенно-цифровые символы. Чтобы решить эту проблему, я проверил, было ли каждое изображение значительно шире, чем длиннее. Большинство буквенно-цифровых символов выше или по крайней мере квадратные, и очень немногие из них намного шире, чем выше, если они не содержат ошибки типа № 2, то есть содержат более одной буквенно-цифровой цифры.
Это та же самая CAPTCHA, что и выше, за исключением того, что на этот раз использовалась проверка ошибок.
Кажется, проверка ошибок работает отлично! Даже очень сложные изображения CAPTCHA успешно маркируются. Однако теперь возник новый выпуск:
.
Пример ложного срабатывания при проверке ошибок №2.Здесь буква «w» в верхней строке соответствует критерию проверки ошибок №2 — она была очень широкой, поэтому программа разбила изображение. Я долго пробовал разные настройки гиперпараметров, при которых широкие изображения с буквами «w» и «m» не разделялись, а в реальных случаях двух буквенно-цифровых символов в одном изображении было бы.Однако я обнаружил, что это невыполнимая задача. Некоторые буквы «w» очень широкие, а некоторые контуры изображения, содержащие две буквенно-цифровые символы, могут быть очень узкими.
Очень узкий случай ошибки №2 можно увидеть на среднем изображении в нижнем ряду.
Не было секретной формулы, чтобы получить то, что я хотел сделать, поэтому мне (стыдно) пришлось сделать то, чем я не особо горжусь, — позаботиться обо всем вручную.
Получение обучающих данных
Для тех, кто подписан на Kaggle, теперь это второй файл с именем captchas_save.ipynb. Я перенес данные из Kaggle на свой локальный компьютер, настроил цикл, чтобы пройти все этапы предварительной обработки от начала до конца. В конце каждого цикла оценщику предлагалось выполнить проверку безопасности данных и меток («y» — сохранить их, «n» — отбросить). Обычно автор предпочитает делать что-то не так, но после того, как он потратил достаточно много часов на попытки автоматизировать процесс, шкала эффективности начала сдвигаться в сторону баланса между автоматизацией и балансировкой вручную.
Я провел оценку 1000 CAPTCHA (таким образом, создав набор данных примерно из 10 000 буквенно-цифровых символов) в период просмотра социальной сети, переключаясь между мной и своим другом, которому я заплатил зарплату в размере одной кружки пива за его помощь.
Пример запроса пользователя на подтверждение набора данных.
Все файлы, получившие проходную оценку, были добавлены в список. Конвейер предварительной обработки перебрал все файлы в списке, сохранив все буквенно-цифровые символы в соответствующие папки, и, таким образом, был создан обучающий набор. Вот итоговая организация каталогов, которую я загрузил и опубликовал как набор данных на kaggle по адресу https://www.kaggle.com/sergei416/captchas-segmented.
Каждому буквенно-цифровому значению был присвоен суффикс «верхний» или «нижний».Все числа получили суффикс «ниже».
В конечном итоге у меня осталось 62 каталога, а в моем наборе обучающих данных всего 5 854 изображения (это означает, что 10 000–5854 = 4146 буквенно-цифровых символов были отброшены).
Наконец, давайте приступим к разделу конвейера машинного обучения! Давайте вернемся к Kaggle, где мы будем обучать программное обеспечение для распознавания рукописных цифр на основе сегментированных буквенно-цифровых символов, полученных в обучающем наборе. Опять же, существующие библиотеки OCR с открытым исходным кодом не справляются с изображениями, которые мы получили до сих пор.
Обучение модели
Для создания системы машинного обучения мы используем обычную нейронную сеть PyTorch. Полный код доступен на Kaggle по адресу https://www.kaggle.com/sergei416/captcha-ml. Для краткости я буду обсуждать только интересные / сложные разделы кода машинного обучения в этой статье.
Благодаря функции PyTorch ImageFolder данные легко загружались в блокнот автора. Существует 62 возможных класса, что означает, что базовая точность для предсказания полностью случайных меток составляет 1/62 или 1.61% точность. Автор установил тестовый и валидный размер 200 изображений. Формы всех изображений были изменены до 128 x 128 пикселей, а затем была применена нормализация каналов. Специально для обучающих данных RandomCrop, ColorJitter, RandomRotation и RandomHorizontalFlip случайным образом применялись для увеличения набора обучающих данных. Вот визуализация пакета обучающих данных:
Один пакет обучающих данных.
Использовалось трансферное обучение от wide_resnet101, а обучение проводилось с использованием бесплатного графического процессора Kaggle.Поиск гиперпараметров был использован для определения лучших гиперпараметров, что дало точность проверки 99,61%. Модель сохранена, результаты визуализированы:
Потери в зависимости от количества эпох. Точность в зависимости от количества эпох. Визуализация планировщика скорости обучения.
Окончательные результаты демонстрируют точность проверки 99,6% и точность испытаний 98,8%. Это, честно говоря, превзошло мои ожидания, так как многие двоичные пиксельные изображения было трудно правильно расшифровать даже человеку.Быстрый просмотр пакета обучающих изображений выше покажет по крайней мере несколько сомнительных изображений.
Оценка нашей модели
Последним этапом этого конвейера была проверка точности нашей готовой модели машинного обучения. Ранее мы экспортировали веса модели для нашего классификатора, и теперь модель может быть применена к любой новой, невидимой CAPTCHA (того же типа, что и CAPTCHA в нашем исходном наборе данных).
Для полноты картины автор установил код для оценки точности модели.Если даже один символ неверен при решении CAPTCHA, вся CAPTCHA будет неудачной. Другими словами, все 10 предсказанных буквенно-цифровых символов должны точно соответствовать решению, чтобы CAPTCHA считалась решенной. Простой цикл сравнения равенства решения с прогнозом был настроен для 500 изображений, случайно взятых из набора данных, и проверялся, были ли прогнозы эквивалентны решениям. Код для этого находится в четвертой (и последней) записной книжке, которую можно найти по адресу https: // www.kaggle.com/sergei416/captchas-test/.
Эта эквивалентность верна для 125/500 протестированных изображений CAPTCHA, или 25% тестового набора *. Хотя это число кажется небольшим, важно помнить, что, в отличие от многих других задач машинного обучения, если одно дело терпит неудачу, сразу становится доступен другой случай. Наша программа должна быть успешной только один раз, но может терпеть неудачу бесконечно. Поскольку наша программа имеет вероятность неудачи 1–0,25 = 0,75 для любой данной попытки, то при n количестве попыток мы пройдем CAPTCHA до тех пор, пока не потерпим неудачу все n попыток.Так какова вероятность успешного прохождения через n попыток? Это
Следовательно, вероятность n попыток следующая:
* EDIT: точность ссылки kaggle составляет 0,3 или 30% для любой отдельной CAPTCHA (97,1% при n = 10).
Заключение
В целом, попытка построить модель машинного обучения, способную решать 10-символьные CAPTCHA, увенчалась успехом. Окончательная модель может решить головоломки с точностью 30%, то есть вероятность того, что изображение CAPTCHA будет решено в течение первых 10 попыток, составляет 97,1%.
Спасибо всем, кто добрался до конца этого урока! Этот проект показал, что 10-символьная CAPTCHA не подходит для дифференциации людей от других пользователей и что другие классы CAPTCHA должны использоваться в производстве.
Ссылки:
Linkedin: https://www.
linkedin.com/in/sergei-issaev/Twitter: https://twitter.com/realSergAI
Github: https://github.com/sergeiissaev
Kaggle: https://www.kaggle.com/sergei416
Jovian: https: // jovian.мл / сергейиссаев /
Средний: https://medium.com/@sergei740
Автоматический решатель капчи на основе глубокого обучения был первоначально опубликован в журнале Towards AI — Multidisciplinary Science Journal on Medium, где люди продолжают разговор, выделяя эту историю и отвечая на нее.
Опубликовано через Towards AI
Скачать CAPTCHA Solver 1.1 Beta
Комплексное приложение с удобным интерфейсом, позволяющее вводить коды капчи всего несколькими щелчками мыши.
Что нового в CAPTCHA Solver 1.1 бета:
- Добавлено: Отчет о выходе пользователю в отчете по окончании решения.
- Добавлено: Progressbar
- Добавлено: Возможность более эффективного решения больших изображений
.
Прочитать полный журнал изменений
кодов Captcha или «Полностью автоматизированный общедоступный тест Тьюринга для различения компьютеров и людей» — это специальный код, который используется для того, чтобы сделать текст неразборчивым для компьютеров. Эти коды могут успешно использоваться для предотвращения создания ботами бесплатных учетных записей, отправки спам-сообщений и сбора личной информации.
Captcha, по сути, предназначены для использования на компьютерах, но в некоторых случаях их трудно прочитать даже вам. CAPTCHA Solver — это легкое приложение, специально созданное для того, чтобы помочь вам расшифровать эти коды. Чтобы иметь возможность идентифицировать и отображать коды, приложение использует технику, аналогичную OCR, оптическому распознаванию символов.
Решение капчи с помощью этого приложения — очень простая задача. Сначала вам нужно загрузить код на свой компьютер в формате изображения, который вы можете загрузить в приложение.
Это не проблема, поскольку большинство кодов добавляются на веб-сайты в формате JPG. После загрузки изображения вы устанавливаете пороговый уровень, нажимаете «Решить капчу», а приложение сделает все остальное.Настройка порога позволяет определить сходство между буквами и цифрами, которые присутствуют в изображении капчи, с буквами в обученных изображениях. Это значительно поможет вам повысить скорость, с которой приложение может решать код. Но вы должны знать, что низкий порог может привести к совпадению некоторых букв, таких как «m» и «n».
CAPTCHA Solver также оснащен тем, что вы можете назвать механизмом обучения. Вы можете научить его распознавать символы. Для этого любой символ или число, не идентифицированные во время первоначального сканирования, экспортируются в «несоответствующий» каталог, откуда вы можете переместить их в папку, соответствующую букве. С этого момента, когда первоначально неопознанный символ снова появляется, приложение может правильно его сканировать.
CAPTCHA Solver разработан для обработки простых кодов капчи, которые, скорее всего, вы сможете расшифровать самостоятельно.С другой стороны, если вы потратите время на «обучение» более сложным кодам, тогда это станет практическим приложением.
Подано под
Расшифровать изображение Расшифровать случайную строку Обнаружение кода Программа определения капчи Решить обнаружение
8 лучших решателей CAPTCHA — веб-парсинг и интеллектуальный анализ данных
В этом посте мы хотим рассказать о программном обеспечении декапчи и услугах , с которыми мы столкнулись в процессе парсинга веб-страниц.
Все методы решения CAPTCHA и, следовательно, услуги и программное обеспечение, реализующие их, можно разделить на две основные категории:- Решения для оптического распознавания символов (OCR)
- Службы решения человеческих капчи
Оптическое распознавание символов (OCR)
1.
GSA Captcha BreakerGSA Captcha Breaker — это программное обеспечение для распознавания CAPTCHA для Windows, которое заменяет службы распознавания CAPTCHA, экономя ваши деньги. Он распознает более 600 различных типов CAPTCHA и даже позволяет вам редактировать или добавлять собственный алгоритм регистрации или делиться некоторыми с другими пользователями. В зависимости от уровня сложности капч, вполне вероятно, что программное обеспечение автоматически решит все ваши капчи на месте. По мере необходимости программное обеспечение пересылает случаи жесткого CAPTCHA в платные службы CAPTCHA.Вы можете прочитать или оставить отзыв здесь
2. DeCaptcher
DeCaptcher — это онлайн-сервис для распознавания капчи, который использует технологии OCR для распознавания капчи (в отличие от человеческого труда). Он предоставляет API-интерфейсы для более чем восьми языков программирования и предназначен для использования в другом коммерческом программном обеспечении.
Вы можете узнать больше о DeCaptcher здесь.
3. Captcha Sniper
Captcha Sniper — интересное приложение для Windows, которое перехватывает запросы к обычным службам распознавания капчи (например, Decaptcha, Death By Captcha, AntiCaptcha и Bypass Captcha) и автоматически решает их вместо них.Это позволяет вам значительно сократить расходы на распознавание капчи, поскольку вы платите только один раз, покупая программу, вместо того, чтобы платить за каждое распознавание!
Как наш читатель, вы имеете право на скидку 10% на Captcha Sniper !
Услуги по решению CAPTCHA, основанные на человеке
4. DeathByCaptcha
DeathByCaptcha — это гибрид системы распознавания текста и человеческих решателей CAPTCHA. Вы можете подключиться к сервису через API, доступный для C, PHP, Python,.NET C # и VB, Java, Perl, AutoIt3, iMacros и некоторые другие языки (обратите внимание, что документация доступна только для зарегистрированных пользователей).
Задержка распознавания капчи около 10 секунд. Здесь вы можете увидеть пример использования этой службы на C #.5. BypassCaptcha
Обход CAPTCHA — это сервис для решения капчи, основанный на людях. Отличительной особенностью этого сервиса является то, что он ориентирован на легкую интеграцию с любым сторонним программным обеспечением, чтобы расширить его функциональность декодирования captcha с помощью автоматического распознавания captca.Он предоставляет API для многих языков, таких как PHP, Python, Perl, Ruby, Java, JavaScript, C / C ++, C #, Delphi, VB.NET и других.
6. Image Typerz
Image Typerz — еще одна услуга обхода капчи, использующая дешевый человеческий труд. Отличие этого сервиса от других аналогичных в том, что он не обрабатывает плохие (с трудом распознаваемые) CAPTCHA. VIP Priority может решить ваши капчи менее чем за 10 секунд за дополнительную плату.
Сервис позволяет легко подключить его через многочисленные API для.Net, PHP, Java, C / C ++, Perl, пример iMacros, программа командной строки и публикация C # HTML (с примером проекта).
7. ExpertDecoders
ExpertDecoders — это автоматизированная программа для решения капчи, основанная на человеке. Я был впечатлен хорошими отзывами и качественным обслуживанием. Для конечных пользователей это позволяет работать с BypassCaptcha.com API или De-Capcher API. Для поставщиков программного обеспечения или разработчиков программного обеспечения сервис предоставляет примеры PHP, C # и iMacros.
8. www.9kw.eu Служба решения капчи
9кВт.Сервис eu предназначен для тех, кто хочет заниматься решением CAPTCHA. Вы создаете учетную запись, входите в систему и зарабатываете бонусные баллы или кредиты за решение уже представленных CAPTCHA. Также сервис работает наоборот. Вы можете отправить свои собственные CAPTCHA для решения для бонусных баллов (также можно приобрести кредиты). Оба способа применимы через API.
Также вам доступно расширение Google Chrome для удаленного решения CAPTCHA. API и плагины доступны здесь.Используйте это программное обеспечение, если вас не беспокоит невысокая скорость решения: «Почти каждая капча менее чем за 30 секунд».Среднее время решения CAPTCHA за это время составляет 15 секунд.
Заключение
Сервисы де-капчи делятся на две категории: OCR и с использованием человеческого труда. Последние обычно имеют процент успеха от 95% до 100%, но время декодирования составляет более 10 секунд на одну CAPTCHA.
Взлом текстовых CAPTCHA с помощью машинного обучения
Мы все бывали там раньше. Вы смотрите на простую CAPTCHA и думаете: Я могу взломать этот . Может быть, это очень простое изображение наклонного текста, возможно, в нем есть пара строк или, может быть, некоторые слова немного шатаются.У вас нет времени тратить время на то, чтобы возиться с OCR, но вы твердо уверены, что эту CAPTCHA легко обойти с помощью современных технологий.
В следующих примерах показаны CAPTCHA, которые можно тривиально решить с использованием минимальных методов предварительной обработки и стандартной предварительно обученной модели OCR:
CAPTCHA (полностью автоматизированный общедоступный тест Тьюринга, позволяющий отличить компьютеры и людей друг от друга) является проблемой. проблема реагирования, которая при правильной реализации может быть решена только человеком.С момента первоначальной разработки в 2003 году использование CAPTCHA неуклонно росло. Они в основном используются в местах, где требуется или раскрывается конфиденциальная информация, например, в процессах аутентификации или регистрации. Основная цель CAPTCHA — предотвратить автоматические атаки, такие как спам, перечисление имен пользователей и перебор паролей. Если только человек может решить эту проблему, становится невозможным создание автоматизированных сценариев для взлома механизма или перечисления из него конфиденциальной информации.
CAPTCHA бывают разных форм, от сторонних решений, в частности reCAPTCHA от Google, до индивидуальных реализаций. Основное внимание в этом посте уделялось оценке текстовых CAPTCHA, которые требуют от пользователя ввода текста для данного изображения. Поскольку существующие решения часто имеют высокую стоимость, часто встречаются текстовые CAPTCHA, разработанные внутри компании. Как и в случае с большинством средств обеспечения безопасности, изобретение колеса связано с набором проблем.
У вас может быть самая сильная и сложная CAPTCHA, но это ничего не значит, если она не реализована правильно.Распространенные ошибки, которые мы видим в этой области, — это жестко запрограммированные обходы разработчика, раскрытие ответа CAPTCHA в ответах сервера и даже полный отказ от проверки CAPTCHA (то есть отказ от открытия).
Но если вы сможете избежать этих ошибок и использовать достаточно сложные текстовые изображения, вы можете быть уверены, что это заблокирует автоматические атаки.
Однако с ростом технологий машинного обучения и вычислительной мощности даже хорошо реализованные текстовые CAPTCHA следует считать уязвимыми.Мощная технология распознавания символов больше не ограничивается академиками и Google. Ниже мы демонстрируем, как шесть специально реализованных тестовых CAPTCHA были взломаны с помощью свободно доступного программного обеспечения с открытым исходным кодом.
Попытка взломать CAPTCHA — это задача, которая является частью общих методологий тестирования безопасности веб-приложений. Традиционный подход к этому заключался в том, чтобы очистить CAPTCHA с помощью методов предварительной обработки изображений, а затем попытаться решить эту проблему с помощью существующей модели OCR.Но для этого может потребоваться большая ручная настройка, а поскольку оценки обычно имеют жесткие временные ограничения, а приложения, как правило, имеют более важные функции для тестирования, чем их CAPTCHA, разработка эффективного взломщика CAPTCHA обычно нецелесообразна.
Мы попытались применить традиционный подход к тому, что казалось довольно упрощенным CAPTCHA. Изображения в этой CAPTCHA имели минимальный шум, а набор символов был довольно ограничен. Хотя персонажи были трехмерными, этот эффект можно было отфильтровать, поскольку цвет эффекта отличался от основного контура персонажа.Чувствуя себя уверенно, мы вытащили 500 CAPTCHA и решили проверить нашу теорию.
Мы пробовали различные методы предварительной обработки для очистки изображений для модели Tesseract-OCR. К нашему ужасу, каждый раз он терпел неудачу. Если бы нам повезло, OCR правильно угадало бы два символа из пяти. Независимо от того, какие методы фильтрации мы пробовали, ничто не приближало нас к уровню точности, который представлял бы реальную угрозу.
Потратив на это пару часов, мы решили, что, возможно, мы смотрим на эту проблему под неправильным углом.Почему мы пытаемся очистить CAPTCHA, чтобы она соответствовала уже обученной модели распознавания текста? Почему мы не можем обучить индивидуальную модель для этой конкретной CAPTCHA?
Быстрый поиск в Google предоставил идеальную модель Tensorflow, которую можно обучить OCR: OCR на основе внимания (AOCR). Для обучения модели требуются данные как для обучения, так и для проверки. Мы потратили два часа на то, чтобы вручную пометить все 500 CAPTCHA. Мы передали модели 450 CAPTCHA для обучения, оставив 50 на проверку. Обучение работе с процессором ноутбука заняло около часа.Все еще не очень оптимистично, после трудоемкого процесса маркировки данных и целого дня проб и ошибок мы решили прекратить обучение и запустить проверку данных.
Нам пришлось запустить его трижды — мы действительно не поверили результатам. 100% точность. Не было допущено ни одной ошибки.
По мере обучения модель измеряла точность и вероятность уверенности в решении. Интересно, что анализ этого показателя показал, что мы допустили ошибки маркировки в исходном наборе данных.В четырех случаях мы пометили букву «M» как «N», и это было обнаружено обученной моделью.
Сомневаясь в статистической значимости наших результатов, мы знали, что нам нужен больший размер выборки. Итак, после празднования мы увеличили модель до 1500 CAPTCHA: 1000 для обучения и 500 для проверки. Опять же, нам удалось добиться 100% точности.
Подробное руководство по процессу и сценариям, которые помогут в создании вашей собственной машины для взлома CAPTCHA, можно найти в этом репозитории Github.
Для обучения модели обучения необходимо получить значительный набор выборок CAPTCHA. Процесс сбора набора данных можно автоматизировать, чтобы получить большой набор образцов за относительно короткое время, например путем преднамеренной отправки неправильных имен пользователей и сохранения сгенерированной CAPTCHA.
Для некоторых более простых CAPTCHA мы обнаружили, что 500 помеченных точек данных было достаточно для получения положительных результатов, в то время как для более сложных требовалось более 1000. В тех случаях, когда мы боролись с процессом ручной классификации, требовалось больше образцов для получения точных результатов. полученные результаты.
На втором этапе необходимо было вручную пометить набор данных. В зависимости от сложности CAPTCHA простота этого шага может варьироваться. Однообразия этого шага нет.
Процесс маркировки был максимально упрощен с помощью сценария. CAPTCHA отображались по одной для маркировки с использованием OpenCV, после чего изображение было сохранено с меткой в качестве имени файла. Чтобы увидеть требуемые человеческие усилия, маркировка занимает в среднем один час на 1000 CAPTCHA.
Для классификации использовалась модель OCR на основе внимания (AOCR). Эта модель Tensorflow OCR, разработанная Qi Guo и Yuntian Deng, использует для классификации скользящую сверточную нейронную сеть (CNN), укомплектованную модулями Long Short-Term Memory (LSTM). Это все большие и сложные термины ИИ, которые мы не будем здесь обсуждать. Мы хотим показать, как с помощью быстрого поиска в Google и перехода на страницу README на Github практически любой человек с базовыми навыками разработки может начать взламывать CAPTCHA.
Чтобы еще раз доказать эту точку зрения, начальное обучение проводилось на ноутбуке с рабочей станцией Core i7 с запущенным на ЦП Tensorflow. При использовании этого метода каждый шаг тренировки занимал в среднем 2,5 секунды. Для большинства примеров требовалось от 1000 до 2000 шагов. Самые большие модели тренировались менее чем за два часа.
В качестве эксперимента сборка Tensorflow с графическим процессором была протестирована на Nvidia GTX 960. Среднее время шага обучения упало до 0,2 секунды. Как упоминалось ранее, обучение модели более сложным CAPTCHA требует большего количества шагов и времени.Если сложность и количество шагов существенно увеличатся, переход на обучение на графическом процессоре может обеспечить значительное повышение производительности.
В целях экономии места описание каждой CAPTCHA и различные факторы ее сложности включены в таблицу ниже.
CAPTCHA # Фоновый шум Шум переднего плана Рандомизация цвета символов Искажение символов
Набор символов
К-1 Нет Тени на буквах Один из двух монохромных цветов Минимальный размер символа и искажение вращения A – Z, 0–9, исключая легко сбиваемый с толку символ К-2 Случайный монохромный цвет Линии и точки поверх знаков Случайные монохромные цвета Значительный размер символа и искажение вращения А-Я, А-Я С-3 Постоянный градиент от белого к красному Нет Случайные монохромные цвета Минимальный размер символа и искажение вращения A – Z, 0–9, исключая символы, которые легко спутать С-4 Монохромный фоновый персонаж Перемещение букв Случайный монохромный цвет, соответствующий фону Минимальный размер символа и искажение вращения, значительное перекрытие букв А-Я, 0-9 К-5 Значительный гауссов шум Значительный гауссов шум Одноцветный монохромный Минимальное искажение размера символа, значительное искажение вращения а-я С-6 Умеренный гауссов шум и оттенки серого Случайные линии и минимальный гауссов шум Оттенки серого Минимальный размер символа и искажение вращения, периодическая обрезка букв а-я, 0-9 Результаты точности для каждой из моделей CAPTCHA показаны ниже:
CAPTCHA # Правильно 1 неправильный символ 2 неправильных символа Более 2 неправильных символов К-1 100% 0% 0% 0% C-2 35% 40% 15% 9% C-3 79% 14% 6% 1% C-4 15% 29% 35% 21% C-5 8% 27% 31% 33% C-6 53% 36% 9% 3% Хотя на первый взгляд результаты для всех CAPTCHA могут показаться не очень впечатляющими, следующая таблица доказывает обратное.
Как уже упоминалось, модель будет выводить прогнозы CAPTCHA, а также измерения уверенности в том, что прогноз правильный. Правильные предположения обычно имеют большую достоверность, чем неправильные. Таким образом, можно указать минимальное значение достоверности или порог. Если достоверность полученного прогноза CAPTCHA не превышает этого порога, будет запрошена новая CAPTCHA. Такой подход ограничит отправку потенциально неверных значений CAPTCHA, но за счет отказа от некоторых CAPTCHA. Чем выше порог, тем больше CAPTCHA будет отброшено.Компромисс между порогами достоверности и отброшенными CAPTCHA показан в таблице ниже. Значения для каждой CAPTCHA показывают, сколько CAPTCHA будет в среднем отброшено для отправки одной CAPTCHA, если мы хотим достичь указанной скорости приема.
Рассмотрим C-2: если мы хотим отправлять CAPTCHA на сервер, зная, что почти 100% всех представлений будут правильными, наш фильтр будет разрешать отправку только 1 из каждых 250 CAPTCHA. Если бы мы снизили уровень принятия, допуская, что примерно 10% всех представлений будут неправильными, одна из каждых восьми CAPTCHA будет разрешена фильтром.Напротив, для C-1, поскольку в прогнозировании не было ошибок, не нужно было отбрасывать CAPTCHA для достижения какой-либо степени принятия.
Как видно из результатов выше, очевидным решением этой проблемы является усложнение текстовых CAPTCHA, например добавить больше шума, кластерного текста и увеличить длину и доступный набор символов. Следующий пример можно рассматривать как более безопасную реализацию текстовой CAPTCHA:
Естественно, в решениях есть компромисс между удобством использования и удобством для человека.Если обученная модель достигает 50% точности на CAPTCHA, но люди в среднем имитируют те же результаты, действительно ли модель ошибочна? Целью успешного автоматизированного решения не обязательно является достижение 100% успеха, а скорее достижение степени точности, подобной человеческой. Если модель может достичь точности человеческого уровня, шум, возникающий из-за неправильных представлений CAPTCHA, будет замаскирован как обычная человеческая ошибка.
Как упоминалось ранее, обученная модель AOCR обеспечивает не только классификацию для CAPTCHA, но также вероятность того, что прогноз верен.Это значение можно использовать в сложных случаях, чтобы гарантировать высокий уровень точности прогнозирования, отбрасывая классификации, которые ниже определенной вероятности прогнозирования, а затем запрашивая другую CAPTCHA.
Это не новая проблема. В 2014 году уже было показано, что доступны методы взлома текстовых CAPTCHA с помощью автоматических средств. Мы только показали, как четыре года прогресса значительно сократили усилия, необходимые для взлома этих систем.
Хотя этот пост был направлен на то, чтобы подчеркнуть небезопасный характер текстовых CAPTCHA, существуют различные типы сторонних решений CAPTCHA, которые могут быть более сложными для компьютеров, но все же могут использоваться людьми.Популярная реализация CAPTCHA — это Google reCAPTCHA. reCAPTCHA — это CAPTCHA на основе изображений, которая требует, чтобы пользователи щелкнули все изображения, соответствующие предоставленному описанию. Хотя сама задача проверки изображения считается более безопасной, было доказано, что эту проблему можно обойти, запросив и автоматически решив вместо этого звуковую задачу. Вдобавок, как и в случае с текстовыми решениями, это лишь вопрос времени, когда вычислительные мощности сделают этот подход тривиальным.
Еще одно такое решение, которое набирает обороты, — это построение модели угроз, основанной на поведении пользователя. Например, люди будут перемещать мышь по нелинейным путям, будут иметь непостоянную частоту кликов и будут прокручивать, чтобы прочитать контент. Одним из таких примеров является reCAPTCHA v3 от Google. В настоящее время это все еще повлечет за собой интеграцию сторонних компонентов, но, похоже, это лучшее решение.
Использование сторонних решений имеет ограничения, поскольку компании не всегда могут быть готовы внедрять стороннее программное обеспечение в чувствительные приложения.
В настоящее время разработчики в организациях, не желающих присоединиться к революции Google, могут только попытаться сделать CAPTCHA достаточно сложными, пока мы ждем лучшего решения.Цель CAPTCHA — блокировать спам и автоматизацию, требуя взаимодействия со стороны пользователя-человека. По мере того, как возможности ИИ становятся все более сложными, это становится все более сложной задачей. Это подчеркивает важность глубокоэшелонированной защиты. Если линия защиты, обеспечиваемая CAPTCHA в рамках функции входа в систему, выйдет из строя, учетные записи могут быть дополнительно защищены от попыток автоматического входа в систему с помощью таких функций, как политика блокировки учетной записи, политика надежных паролей и двухфакторная аутентификация.По мере того, как усилия, необходимые для взлома решений CAPTCHA, уменьшаются, автоматическое перечисление и другие атаки методом перебора станут более жизнеспособными, и это следует учитывать в стратегиях смягчения последствий.
— решатель CAPTCHA на основе глубокого обучения для оценки уязвимости
изображений с использованием глубоких сверточных нейронных сетей ». Препринт arXiv
arXiv: 1312.6082 (2013).
[15] Ван, Е и Ми Лу. «Оптимизированная система для решения текстовых кодов
CAPTCHA». Препринт arXiv arXiv: 1806.07202 (2018).
[16] Осадчий, Маргарита, Хулио Эрнандес-Кастро, Стюарт Гибсон, Орр Дункель-
человек и Даниэль Пре-Кабо. «Ни один бот не ожидает DeepCAPTCHA! Введение —
, дающее неизменные состязательные примеры, с приложениями для поколения CAPTCHA
». IEEE Transactions по информационной криминалистике и безопасности
12, no. 11 (2017): 2640-2653.
[17] Бурштейн, Эли, Джонатан Эйгрейн, Анжелика Москицки и Джон К.
Митчелл. «Конец близок: общее решение текстовых капч.”В
8-м семинаре USENIX по наступательным технологиям (WOOT 14). 2014.
[18] Чжао, Натан, И Лю и Ицзюнь Цзян. «Преодоление CAPTCHA с глубоким обучением
».
(2017).[19] Чэнь, Цзюнь, Сянъян Ло, Яньцин Го, И Чжан и Даофу Гун.
«Обзор техники взлома текстовой CAPTCHA». Безопасность
и Сети связи 2017 (2017).
[20] Ю, Нинг и Кайл Дарлинг. ”Недорогой подход к взлому Python
CAPTCHA с использованием атаки с использованием выбранного открытого текста на основе искусственного интеллекта.”Прикладные науки —
энсес 9, вып. 10 (2019): 2010.
[21] Алгвил, Абдальнасер, Дэн Чиресан, Бейбей Лю и Джефф Ян. «Анализ безопасности
автоматических китайских тестов Тьюринга». В материалах 32-й ежегодной конференции
по приложениям компьютерной безопасности, стр. 520-532.
2016.
[22] Сивакорн, Супханни, Джейсон Полакис и Ангелос Д. Керомитис. «Im
не человек: нарушение Google reCAPTCHA». Черная шляпа (2016).
[23] Резаи, Махди и Рейнхард Клетте, «Одновременный анализ поведения водителя
и состояния дороги для обнаружения отвлечения внимания водителя.”, Интер-
национальный журнал слияния изображений и данных, (2011).
[24] Квон, Хён, Хёнсу Юн и Пак Ки-Ун. ”CAPTCHA Image
Поколение
с использованием обучения с передачей стилей в глубокой нейронной сети”. В
International Workshop on Information Security Applications, pp. 234–
246. Springer, Cham, 2019.
[25] Квон, Хён, Ёнчул Ким, Хёнсу Юн и Дэсон Чой.
”Системы генерации изображений Captcha с использованием генеративной состязательной сети —
работает.«IEICE ОПЕРАЦИИ по информации и системам 101, вып.
2 (2018): 543–546.
[26] Джордж, Дилип, Вольфганг Лехрах, Кен Кански, Мигель Лзаро-Гредилья,
Кристофер Лаан, Бхаскара Марти, Синхуа Лу и др. «Генеративная модель технического зрения
, которая обучается с высокой эффективностью обработки данных и разбивает текстовые CAPTCHA
». Наука 358, вып. 6368 (2017): eaag2612.
[27] Резаи М., Саршар М. и Санаатян М.М. / «К следующему поколению —
систем помощи водителю: мультимодальная платформа на основе датчиков.
”Computer and Atomation Eengineering, (2010), стр. 62–67.
[28] Янь, Сюэху, Фэн Лю, Вэй Ци Янь и Юйлян Лу. «Применение криптографии Visual
для улучшения текстовых кодов». Математика 8, вып. 3 (2020):
332.
[29] Ван, Цзин, Цзяо Хуа Цинь, Сюй Юй Сян, Юнь Тан и Нан Пан.
«Распознавание CAPTCHA на основе глубокой сверточной нейронной сети».
Math. Biosci. Англ. 16, нет. 5 (2019): стр. 5851–5861.
[30] Резаи, Махди и Рейнхард Клетте.«Обнаружение объектов, классификация,
и отслеживание». Springer International Publishing, 2017.
[31] Старк, Фабиан, Канер Хазрбас, Рудольф Трибель и Дэниел Кремерс.
«Распознавание Captcha с активным глубоким обучением». В семинаре новые задачи
в нейронных вычислениях, т. 2015, стр. 94. Citeseer, 2015.
[32] Хуанг, Гао, Чжуан Лю, Лоренс Ван Дер Маатен и Килиан К. Вайн —
berger. «Плотно связанные сверточные сети». В материалах
конференции IEEE по компьютерному зрению и распознаванию образов, стр.
4700–4708. 2017.
[33] Цзя, Ян, Ван Фань, Чэнь Чжао и Чжунган Хан. «Подход
для распознавания китайских символов Captcha с использованием CNN». В журнале
Physics: Conference Series, vol. 1087, нет. 2, стр. 022015. IOP Publishing,
2018.
[34] Banday MT, Shah NA, «Image Flip Captcha». Международный журнал ISC
по информационной безопасности (ISeCure), том 1, вып. 2, стр. 105–123
[35] Резаи М., Шахиди М., «Обучение с нулевым выстрелом и его приложения от
автономных транспортных средств до диагностики COVID-19: обзор».В arXiv
препринт arXiv: 2004.14143 (2020).
[36] Вэй, Ли, Сян Ли, Тин Жун Цао, Цюань Чжан, Лян Ци Чжоу и
Вэньли Ван. «Исследование оптимизации алгоритма распознавания CAPTCHA
на основе SVM». В материалах 11-й Международной конференции по машинному обучению и вычислениям 2019 г., стр. 236-240.
2019.
[37] Ду, Фэн-Линь, Цзя-Син Ли, Чжи Ян, Пэн Чен, Бинг Ван и Цзюнь
Чжан. »Распознавание CAPTCHA на основе более быстрого R-CNN.”In Inter-
national Conference on Intelligent Computing, pp. 597-605. Springer,
Cham, 2017.
[38] Python Image Captch Librady https://github.com/lepture/captcha, последний
Доступ
: 15 июня 2020 г.
Поговорим об отношении к GAN-do … Программные боты AI могут видеть сквозь ваши текстовые CAPTCHA • The Register
Если вы один из тех, кто ненавидит выделять автомобили, уличные знаки и другие объекты в сетках изображений CAPTCHA, тогда привыкните к этому, потому что дни текстовых альтернатив сочтены.
CAPTCHA означает «полностью автоматизированный общедоступный тест Тьюринга, позволяющий отличить компьютеры от людей». Тесты CAPTCHA используются для отделения ботов от людей, как это видели многие интернет-пользователи.
Они не работают безупречно, поэтому такие компании, как Facebook, постоянно удаляют поддельные аккаунты. А постоянные исследования в области машинного обучения и методов распознавания изображений еще больше затрудняют создание головоломок, которые беспокоят программы, но не людей.
Боффинс из Ланкастерского университета в Великобритании, Северо-Западного университета в США и Пекинского университета в Китае разработали подход к созданию текстовых решателей CAPTCHA, который упрощает автоматическое дешифрование зашифрованных изображений текста.
Исследователи Guixin Ye, Zhanyong Tang, Dingyi Fang, Zhanxing Zhu, Yansong Feng, Pengfei Xu, Xiaojiang Chen и Zheng Wang описывают свою систему взлома CAPTCHA в документе, который был представлен на 25-й конференции ACM по компьютерной и коммуникационной безопасности в октябре 2000 года. теперь выпущен для публики.
Как можно догадаться из названия, «Еще одна программа для решения текстовых кодов капчи: подход на основе генеративной состязательной сети», компьютерщики использовали GAN (Generative Adversarial Network) для обучения своего генератора CAPTCHA, который используется для обучения их модели распознавания текста. .
Впервые описанная в 2014 году, GAN состоит из двух моделей нейронных сетей, противостоящих друг другу в качестве противников: одна моделирует что-то, а другая выявляет проблемы с моделированием до тех пор, пока какие-либо различия не могут быть идентифицированы.
По совпадению, в том же году исследователи из Google и Стэнфорда опубликовали статью под названием «Конец близок: общее решение текстовых CAPTCHA». Четыре года спустя были проложены «лежачие полицейские», ограничивающие общие атаки.
Можем ли мы его сломать? Да мы ГАН!
Оказалось, что GAN хорошо подходит для эффективного обучения моделей данных. Это позволило исследователям научить свою программу генерации CAPTCHA быстро создавать множество синтетических текстовых головоломок для обучения их базовой модели решения головоломок.Затем они настроили его с помощью трансферного обучения, чтобы избавиться от реальных текстовых беспорядков, используя только небольшой набор (~ 500 вместо миллионов) реальных образцов.
По словам исследователей, за прошедшие годы было разработано множество атак на текстовые CAPTCHA, но необходимость обучить механизмы атаки для обработки определенных методов преобразования текста ограничила скорость реакции злоумышленников на изменения CAPTCHA.
«Настройка атакующих эвристик или моделей требует серьезного участия экспертов и следует за трудоемким и длительным процессом сбора и маркировки данных», — поясняют они в статье.
Работа по обнаружению объектов с открытым исходным кодом Facebook: Осторожно, Google CAPTCHA
ПОДРОБНЕЕ
Хотя было предложено несколько общих атак, они работали только с относительно простыми функциями безопасности, такими как шумный фон и отдельные шрифты.
Исследователи утверждают, что за счет сокращения участия человека и усилий по созданию целевого решателя CAPTCHA их атака представляет собой «особенно серьезную угрозу для текстовых CAPTCHA».
 xyz/api/captcha/capy
xyz/api/captcha/capy  34.56.78: 8080
34.56.78: 8080  34.56.78: 8080
34.56.78: 8080 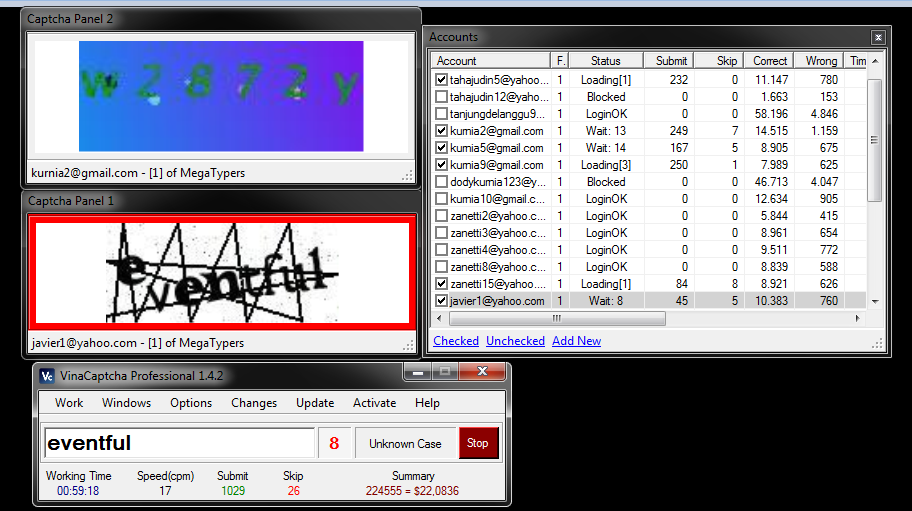 В настоящее время мы интегрировали следующие службы:
В настоящее время мы интегрировали следующие службы: com / bestcaptchasolver / gates
com / bestcaptchasolver / gates 
 Вуаля.
Вуаля.
 Обратите внимание, что все последующие письма теперь также неправильно помечены. Мы не можем позволить себе добавлять эти неправильно помеченные изображения к нашим обучающим данным. Поэтому я написал правило, согласно которому любые буквы и цифры с соотношением белого к черному выше 63% или ниже 29% будут пропущены.
Обратите внимание, что все последующие письма теперь также неправильно помечены. Мы не можем позволить себе добавлять эти неправильно помеченные изображения к нашим обучающим данным. Поэтому я написал правило, согласно которому любые буквы и цифры с соотношением белого к черному выше 63% или ниже 29% будут пропущены.
 Для полноты картины автор установил код для оценки точности модели.
Для полноты картины автор установил код для оценки точности модели. linkedin.com/in/sergei-issaev/
linkedin.com/in/sergei-issaev/ Это не проблема, поскольку большинство кодов добавляются на веб-сайты в формате JPG. После загрузки изображения вы устанавливаете пороговый уровень, нажимаете «Решить капчу», а приложение сделает все остальное.
Это не проблема, поскольку большинство кодов добавляются на веб-сайты в формате JPG. После загрузки изображения вы устанавливаете пороговый уровень, нажимаете «Решить капчу», а приложение сделает все остальное. GSA Captcha Breaker
GSA Captcha Breaker Также вам доступно расширение Google Chrome для удаленного решения CAPTCHA. API и плагины доступны здесь.
Также вам доступно расширение Google Chrome для удаленного решения CAPTCHA. API и плагины доступны здесь.



 Как уже упоминалось, модель будет выводить прогнозы CAPTCHA, а также измерения уверенности в том, что прогноз правильный. Правильные предположения обычно имеют большую достоверность, чем неправильные. Таким образом, можно указать минимальное значение достоверности или порог. Если достоверность полученного прогноза CAPTCHA не превышает этого порога, будет запрошена новая CAPTCHA. Такой подход ограничит отправку потенциально неверных значений CAPTCHA, но за счет отказа от некоторых CAPTCHA. Чем выше порог, тем больше CAPTCHA будет отброшено.
Как уже упоминалось, модель будет выводить прогнозы CAPTCHA, а также измерения уверенности в том, что прогноз правильный. Правильные предположения обычно имеют большую достоверность, чем неправильные. Таким образом, можно указать минимальное значение достоверности или порог. Если достоверность полученного прогноза CAPTCHA не превышает этого порога, будет запрошена новая CAPTCHA. Такой подход ограничит отправку потенциально неверных значений CAPTCHA, но за счет отказа от некоторых CAPTCHA. Чем выше порог, тем больше CAPTCHA будет отброшено.
 В настоящее время разработчики в организациях, не желающих присоединиться к революции Google, могут только попытаться сделать CAPTCHA достаточно сложными, пока мы ждем лучшего решения.
В настоящее время разработчики в организациях, не желающих присоединиться к революции Google, могут только попытаться сделать CAPTCHA достаточно сложными, пока мы ждем лучшего решения. (2017).
(2017). ”
”
Добавить комментарий