Как настроить robots.txt? Проверить файл robots.txt, закрыть от индексации страницы на сайте
Файл robots.txt управляет индексацией сайта. В нем содержатся команды, которые разрешают или запрещают поисковым системам добавлять в свою базу определенные страницы или разделы на сайте. Например, на Вашем сайте имеется раздел с конфиденциальной информацией или служебные страницы. Вы не хотите, чтобы они находились в индексе поисковых систем, и настраиваете запрет на их индексацию в файле robots.txt.
В данной статье мы рассмотрим, как настроить robots.txt и проверить правильность указанных в нем команд. Как закрыть от индексации сайт целиком или отдельные страницы или разделы.
Чтобы поисковые системы нашли файл, он должен располагаться в корневой папке сайта и быть доступным по адресу ваш_сайт.ru/robots.txt. Если файла на сайте нет, поисковые системы будут считать, что можно индексировать все документы на сайте. Это может привести к серьезным проблемам, в частности, попаданию в базы страниц-дублей, документов с конфиденциальной информацией.
Структура файла robots.txt
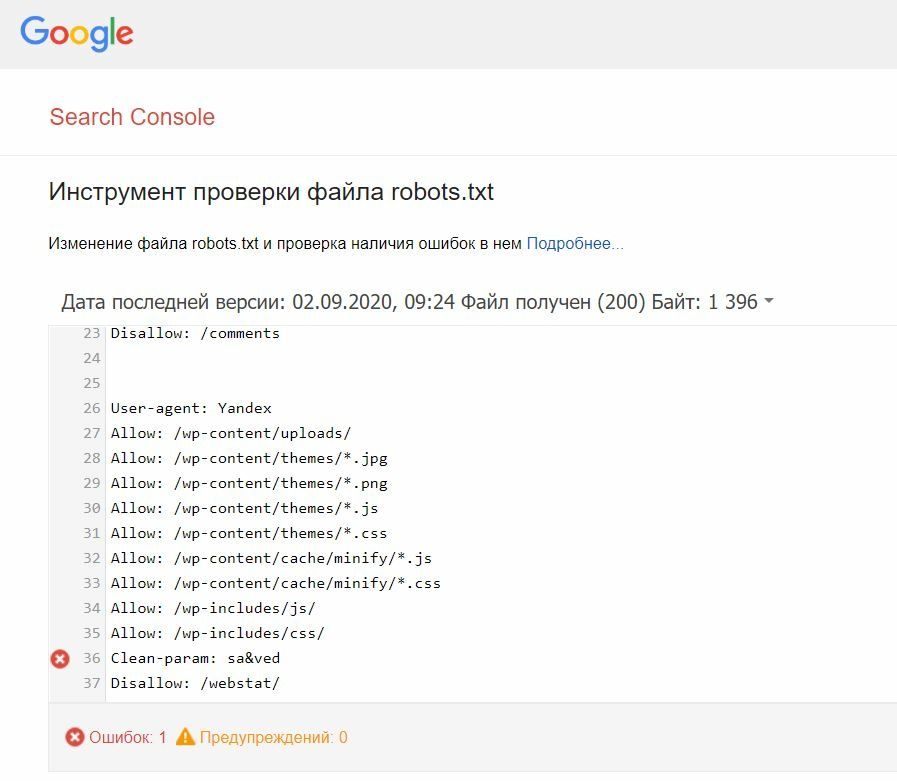
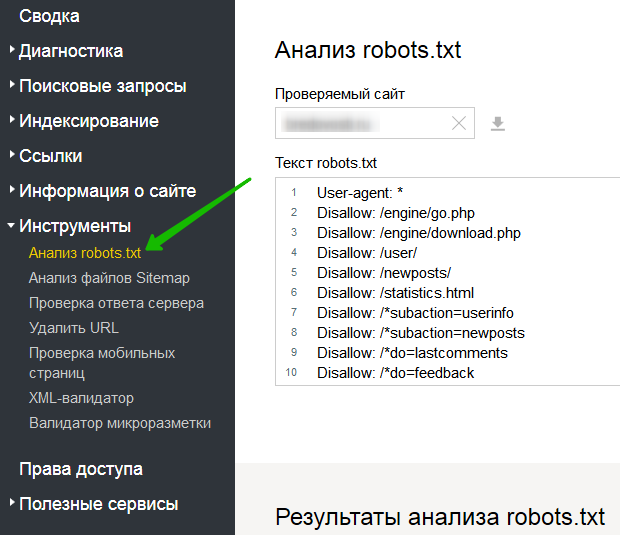
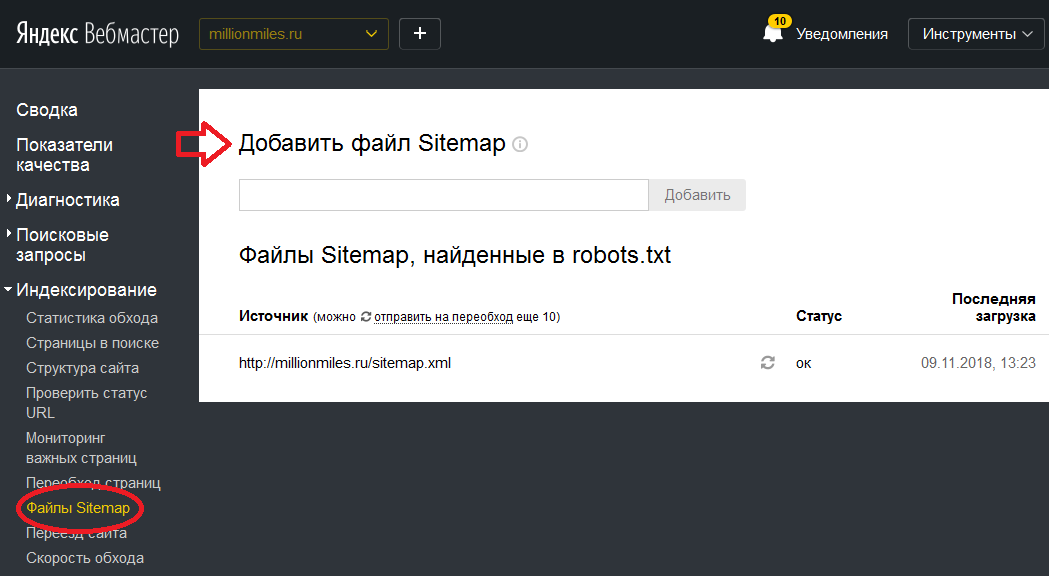
В файле robots.txt для каждой поисковой системы можно прописать свои команды. Например, на скриншоте ниже Вы можете увидеть команды для робота Яндекса, Google и для всех остальных поисковых систем:
Каждая команда начинается с новой строки. Между блоками команд для разных поисковых систем оставляют пустую строку.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
Директива
Назначение
User-agent:
Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы.
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots. txt
Разберем некоторые команды, которые потребуются Вам в работе:
Команда
Что обозначает
User-agent: Yandex
Начало блока команд для основного робота поисковой системы Яндекс.
User-agent: Googlebot
Начало блока команд для основного робота поисковой системы Google.
User-agent: *
Disallow: /
Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами.
User-agent: *
Disallow: /
Allow: /test.html
Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html
Disallow: /*.doc
Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации.
Disallow: /*.pdf
Данная команда в robots. txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах.
Disallow: /basket/
Команда запрещает индексировать все документы в разделе /basket/.
Host: www.yandex.ru
Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www.
Host: yandex.ru
Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www).
Использование спецсимволов в командах robots.txt
В командах robots.txt может использоваться два спецсимвола: * и $:
Звездочка * заменяет собой любую последовательность символов.
По умолчанию в конце каждой команды добавляется *. Чтобы отменить это, в конце строки необходимо поставить символ $.
Допустим, у нас имеется сайт с адресом site.com, и мы хотим настроить файл robots.txt для нашего проекта. Разберем действие спецсимволов на примерах:
Команда
Что обозначает
Disallow: /basket/
Запрещает индексацию всех документов в разделе /basket/, например:
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд
Метатег robots | Закрыть страницу от индексации
Метатег robots | Закрыть страницу от индексации
Статья для тех, кому лень читать справку по GoogleWebmaster и ЯндексВебмастер
Закрывание ненужных страниц веб-ресурса от поисковой индексации очень важно для его SEO-оптимизации, особенно на начальном этапе становления сайта или блога «на ноги». Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п.
Метатег robots
Почему метатег robots лучше файла robots.txt
Метатег robots
Для управления поведением поисковых роботов на веб-странице, в HTML существует метатег robots и его атрибут content. закрытия веб-страницы от поисковой индексации,
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») Это значение предназначено для поисковых систем. Оно устанавливает запрет на переход по ссылке и последующее её индексирование.
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>. В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow» на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow» на поисковых роботов Google и Яндекса несколько разное:
Google
Увидев атрибут rel=»nofollow» у отдельно стоящей ссылки, поисковые роботы Google не переходят по такой ссылке и не индексируют её видимую часть (анкор). Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»: <a href=»http://example.ru» rel=»nofollow»>Анкор</a> А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу, достаточно добавить в её заголовок строку с метатегом: <meta name=»robots» content=»nofollow»/>
Яндекс
Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют. Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют. Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
noindex – не индексировать текст (тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка. Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Учитывая не валидность своего бедного и непризнанного тега, Яндекс соглашается на оба варианта для его написания: Не валидный вариант – <noindex></noindex>, и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
Ссылка индексируется полностью
<a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content – в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/> Текст страницы, с таким метатегом в заголовке – Яндекс совершенно не индексирует, но при этом он – проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы. Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/> Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире. Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
не индексировать текст страницы
<meta name=»robots» content=»noindex»/>
не переходить по ссылкам на странице
<meta name=»robots» content=»nofollow»/>
не индексировать текст страницы и не переходить по ссылкам на странице
<meta name=»robots» content=»noindex, nofollow»/>
что, аналогично следующему:
запрещено индексировать текст и переходить по ссылкам на странице для роботов Яндекса
<meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега, закрывающего полностью всю страницу от поисковой индексации, выглядит так:
<meta name=»robots» content=»noindex, nofollow»/>
– запрещено индексировать текст и переходить по ссылкам на странице для всех поисковых роботов Яндекса и Google
Почему метатег robots лучше файла robots.txt
Самый простой и популярный способ закрыть веб-страницу от индексации – это указать для неё соответствующую директиву в файле robots.txt. Для этого, собственно файл robots.txt и существует. Однако, закрывать через метатег robots – гораздо надёжнее.
И, вот почему. Алгоритмы обработки роботами метатега robots и файла robots – совершенно различные. Работу этих алгоритмов можно сравнить с действием в известном анекдоте, где бьют не «по паспорту», а – «по морде». Пусть этот пример весьма груб и примитивен, но он, как нельзя лучше – отображает поведение поискового робота на странице:
В случае использования метатега robots, поисковик просто и прямо заходит на веб-страницу и читает её заголовок («смотрит в её морду». Если робот там находит метатег robots – он разворачивается и уходит восвояси. Вуаля! Всё предельно просто. Робот увидел запись, что здесь ловить нечего, и сразу же – «свалил». Ему проблемы не нужны. Это есть работа по факту записи прямо в заголовке страницы («по морде»).
В случае использования файла robots.txt, поисковик, перед заходом на страницу – сверяется с этим файлом (читает «паспорт»). Это есть работа по факту записи в постороннем файле («по паспорту»). Если в файле robots.txt («паспорте») прописана соответствующая директива – робот её выполняет. Если нет, то он – сканирует страницу в общем порядке, поскольку по-умолчанию – к сканированию разрешены все страницы.
Казалось-бы, какая разница.
Тем более, что сам Яндекс рассказывает следующее:
При сканировании сайта, на основании его файла robots.txt – составляется специальный список (пул), в котором ясно и чётко указываются и излагаются директории и страницы, разрешённые к поисковому индексированию сайта.
Ну, чего ещё проще – составил списочек,
прошёлся списочком по сайту,
и всё – можно «баиньки»…
Простота развеется, как майский дым, если мы вспомним, что роботов много, что все они разные, и самое главное – что все роботы ходят по ссылкам. А сей час, представим себе стандартную ситуацию, которая случается в интернете миллионы раз на дню – поисковый робот пришёл на страницу по ссылке из другого сайта. Вот он, трудяга Сети – уже стоит у ворот (у заголовка) странички. Ну, и где теперь файл robots.txt?
У робота, пришедшего на сайт по внешней ссылке, выбор не большой. Робот может, либо лично «протопать» к файлу robots.txt и свериться с ним, либо просто скачать страницу себе в кэш и уже потом разбираться – индексировать её или нет.
Как поступит наш герой, мы не знает. Это коммерческая тайна каждой поисковой системы. Несомненно, одно. Если в заголовке страницы будет указан метатег robots – поисковик выполнит его немедля. И, если этот метатег запрещает индексирование страницы – робот уйдёт немедля и без раздумий.
Вот теперь, совершенно ясно, что прямой заход на страницу, к метатегу robots – всегда короче и надёжнее, нежели долгий путь через закоулки файла robots.txt
Метатег robots | Закрыть страницу от индексации на tehnopost.info
Метатег robots
Почему метатег robots лучше файла robots.txt
Интернетчик: интернет, сайт, HTML
Закрываем бесполезные страницы от индексации директивой в robots. txt
Эта статья об использовании файла robots.txt на практике применительно к удалению ненужных страниц из индекса поисковых систем. Какие страницы удалять, как их искать, как убедиться, что не заблокирован полезный контент. По сути статья — об использовании одной лишь директивы — Disallow. Всесторонняя инструкция по использованию файла роботс и других директив в Помощи Яндекса.
В большинстве случаев закрываем ненужные страницы для всех поисковых роботов, то есть правила Disallow указываем для User-agent: *.
User-agent: * Disallow: /cgi-bin
Что нужно закрывать от индексации?
При помощи директивы Disallow в файле robots.txt нужно закрывать от индексации поисковыми ботами:
Как искать страницы, которые необходимо закрыть от индексации?
ComparseR
Просканировать сайт Компарсером и справа во вкладке «Структура» построить дерево сайта:
Просмотреть все вложенные «ветви» дерева.
Получить во вкладках «Яндекс» и «Google» страницы в индексе поисковых систем. Затем в статистике сканирования просмотреть адреса страниц в «Найдено в Яндекс, не обнаружено на сайте» и «Найдено в Google не обнаружено на сайте».
Яндекс.Вебмастер
В разделе «Индексирование» — «Структура сайта» просмотреть все «ветви» структуры.
Проверить, что случайно не был заблокирован полезный контент
Перечисленные далее методы дополняют друг друга.
robots.txt
Просмотреть содержимое файла robots.txt.
Comparser (проверка на закрытие мета-тегом роботс)
В настройках Компарсера перед сканированием снять галочку:
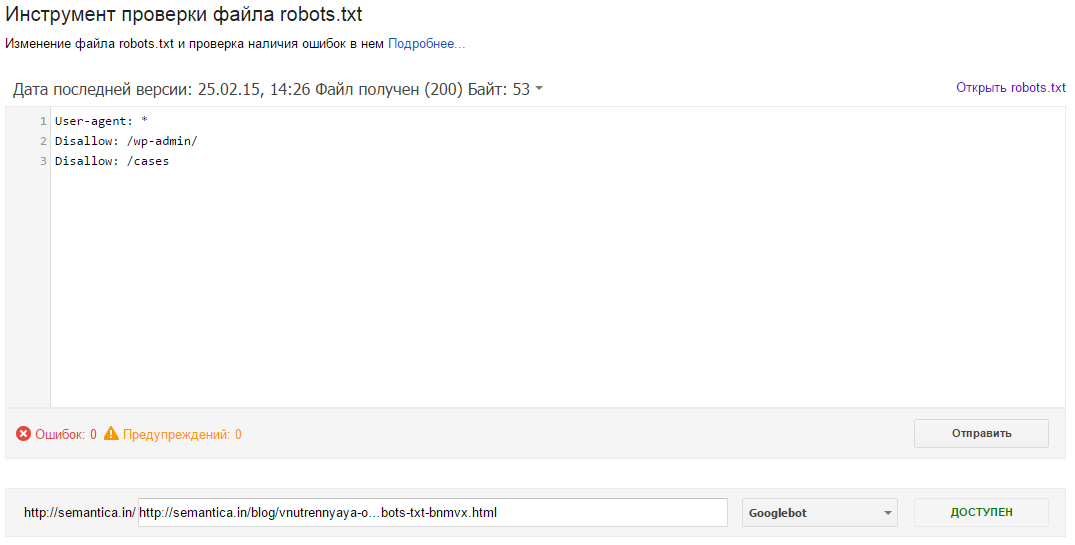
Важно убедиться, что робот Google имеет доступ к файлам стилей и изображениям, используемым при отображении страниц. Для этого нужно выборочно просканировать страницы инструментом «Посмотреть, как Googlebot», нажав на кнопку «Получить и отобразить». Полученные в результате два изображения «Так увидел эту страницу робот Googlebot» и «Так увидит эту страницу посетитель сайта» должны выглядеть практически одинаково. Пример страницы с проблемами:
Увидеть заблокированные части страницы можно в таблице ниже:
Подробнее о результатах сканирования в справке консоли. Все заблокированные ресурсы нужно разблокировать в файле robots.txt при помощи директивы Allow (не получится разблокировать только внешние ресурсы). При этом нужно точечно разблокировать только нужные ресурсы. В приведённом примере боту Гугла запрещён доступ к папке /templates/, но открыт некоторым типам файлов внутри этой папки:
Как закрыть сайт от индексации в robots. txt, через htaccess и мета-теги
Привет уважаемые читатели seoslim.ru! Некоторые пользователи интернета удивляются, какими же быстродействующими должны быть компьютеры Яндекса, чтобы в несколько секунд просмотреть все сайты в глобальной сети и найти ответ на вопрос?
Но на самом деле за пару секунд изучить все данные WWW не способна ни одна современная, даже самая мощная вычислительная машина.
Давайте сегодня пополним наши знания о всемирной сети и разберемся, как поисковые машины ищут и находят ответы на вопросы пользователей и каким образом можно им запретить это делать.
Что такое индексация сайта
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
Это полезно знать: Какую роль в работе сайта играют DNS-сервера
В плане индексации Google работает несколько быстрее нашего Яндекса.
Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в б
Как закрыть от индексации сайт, ссылку, страницу, в robots ?
Далеко не всегда нужно, чтобы поисковые системы индексировали всю информацию на сайте.
Иногда, вебмастерам даже нужно полностью закрыть сайт от индексации, но новички не знают, как это сделать. При желании, можно скрыть от поисковиков любой контент, ресурс или его отдельные страницы.
Как закрыть от индексации сайт, ссылку, страницу? Есть несколько простых функций, которые вы сможете использовать, для закрытия любой информации от Яндекса и Гугла. В этой статье мы подскажем, как закрыть сайт от индексации через robots, и покажем, какой код нужно добавить в этот файл.
Закрываем от индексации поисковиков
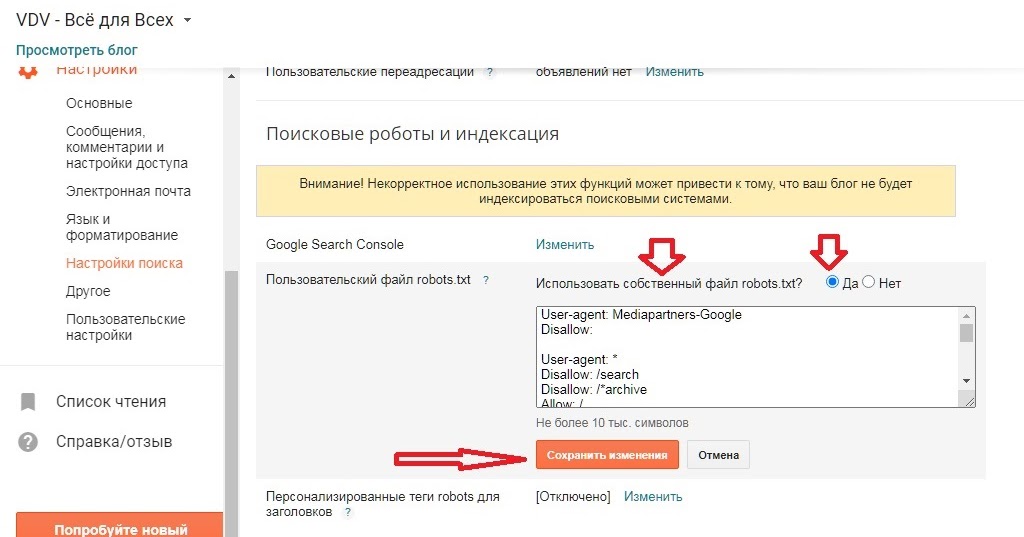
Перед тем как рассказать о способе с применением robots.txt, мы покажем, как на WordPress закрыть от индексации сайт через админку. В настройках (раздел чтение), есть удобная функция:
Можно убрать видимость сайта, но обратите внимание на подсказку. В ней говорится, что поисковые системы всё же могут индексировать ресурс, поэтому лучше воспользоваться проверенным способом и добавить нужный код в robots.txt.
Текстовый файл robots находится в корне сайта, а если его там нет, создайте его через блокнот.
Закрыть сайт от индексации поможет следующий код:
User-agent: *
Disallow: /
Просто добавьте его на первую строчку (замените уже имеющиеся строчки). Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.
Если не можете использовать этот способ, просто добавьте в код сайта строчку <meta name=»robots» content=»noindex,follow» />.
Когда проделаете эти действия, сайт больше не будет индексироваться, это самый лучший способ для закрытия ресурса от поисковых роботов.
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.
К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно: — Скорость сайта – важный фактор — Почему Яндекс не индексирует сайт? — Оригинальные тексты для защиты от Yandex
Как закрыть сайт от индексации в Robots. txt на время разработки?
Прячем в роботс.тхт всё, кроме главной
Нередко возникает необходимость скрыть в файле Robots.txt разделы или отдельные страницы сайта от «глаз» поисковых роботов. Это дело известное и причины для него могут быть разные: удаление дублей контента из индекса, выкидывание «застрявших» в индексе несуществующих страниц и т.д.
Однако при создании нового сайта бывает полезным закрыть от индексации всё, кроме главной страницы.
Например, вы создаёте интернет-магазин и дальше главной роботу лучше не ходить — чтобы не индексировать пока ещё «кривые» страницы (иначе в дальнейшем могут быть торможения при продвижении..).
Почему лучше оставить главную? В этом случае ПС узнает о существовании нового сайта и начнётся т.н. увеличение траста вашего ресурса (а иначе бы поисковик узнал о вашем проекте только при его полном запуске).
Так что если вам нужно оставить сайт открытым для пользователей, но закрыть всё «нутро» от поисковых систем и в то же время — заявить о себе поисковикам, то можно применить файл Robots. txt для этих целей. Как это делается — написано дальше.
Как закрыть сайт от индексации в Robots.txt, оставив поисковикам главную страницу?
Недавно у меня возникла такая задача, пришлось немного подумать. Как оказалось, всё очень просто — составляем такой Robots.txt:
User-agent: * Disallow: / Allow: /$
Вот и всё. Эффект от этого можно проверить инструментом Яндекса для анализа robots.txt.
Как закрыть сайт от индексации с помощью Robots.txt полностью:
Если вообще весь ресурс нужно спрятать от поисковиков, то это совсем просто:
User-agent: * Disallow: /
Таким образом, если на период разработки сайта вы не желаете «отдавать» ПС внутренние недоделанные страницы, но хотите уже пустить туда пользователей — закрывайте в robots.txt от индексации всё, кроме главной. И не забудьте отредактировать данный файл, когда решите пустить и роботов
Meta Robots Tag и Robots. txt Руководство для Google, Bing и других поисковых систем
Как создавать файлы Robots.txt
Используйте наш генератор Robots.txt для создания файла robots.txt.
Анализируйте файл Robots.txt
Воспользуйтесь нашим анализатором Robots.txt, чтобы проанализировать свой файл robots.txt уже сегодня.
Google также предлагает аналогичный инструмент в Центре веб-мастеров Google и показывает ошибки сканирования вашего сайта Google.
Примеры роботов.txt в формате
Разрешить индексацию всего
Пользовательский агент: * Disallow:
или
Пользовательский агент: * Разрешить: /
Запретить индексацию всего
Пользовательский агент: * Disallow: /
Запретить индексирование определенной папки
Пользовательский агент: * Запретить: / folder /
Запретить роботу Googlebot индексировать папку, за исключением разрешения индексирования одного файла в этой папке
Файлы Robots.txt информируют «пауков» поисковых систем о том, как взаимодействовать с индексированием вашего контента.
По умолчанию поисковые системы жадные. Они хотят проиндексировать как можно больше высококачественной информации и будут считать, что могут сканировать все, если вы не укажете им иное.
Если вы укажете данные для всех ботов (*) и данные для конкретного бота (например, GoogleBot), тогда будут выполняться определенные команды бота, в то время как этот движок игнорирует глобальные / стандартные команды бота .
Если вы создаете глобальную команду, которую хотите применить к определенному боту, и у вас есть другие особые правила для этого бота, вам необходимо поместить эти глобальные команды в раздел для этого бота, как указано в этой статье Энн Умный.
Когда вы блокируете индексирование URL-адресов в Google с помощью robots. txt, они могут по-прежнему отображать эти страницы как списки только URL-адресов в своих результатах поиска.Лучшее решение для полной блокировки индекса конкретной страницы — использовать метатег robots noindex для каждой страницы. Вы можете сказать им не индексировать страницу или не индексировать страницы и , чтобы не переходить по исходящим ссылкам, вставив один из следующих битов кода в заголовок HTML вашего документа, который вы не хотите индексировать.
<- страница не проиндексирована, но по ссылкам можно переходить
<- страница не индексируется и по ссылкам не переходят
Обратите внимание, что если вы сделаете и то, и другое: заблокируйте поисковые системы в robots.txt и через метатеги, тогда команда robots.txt является основным драйвером, поскольку они могут не сканировать страницу для просмотра метатегов, поэтому URL-адрес может по-прежнему отображаться в результатах поиска, перечисленных только для URL-адресов.
Если у вас нет файла robots.txt, журналы вашего сервера будут возвращать ошибку 404 всякий раз, когда бот пытается получить доступ к вашему файлу robots.txt. Вы можете загрузить пустой текстовый файл с именем robots.txt в корне вашего сайта (например, seobook.com/robots.txt), если вы не хотите получать ошибки 404, но не хотите предлагать какие-либо конкретные команды для ботов.
Некоторые поисковые системы позволяют вам указывать адрес XML-карты сайта в файле robots.txt, но если ваш сайт небольшой и хорошо структурирован с чистой структурой ссылок, вам не нужно создавать XML-карту сайта. Для крупных сайтов с несколькими подразделениями, сайтов, которые генерируют огромное количество контента каждый день, и / или сайтов с быстро меняющимся запасом, карты сайта XML могут быть полезным инструментом, помогающим индексировать важный контент и отслеживать относительную производительность глубины индексации по типу страницы.
Задержка сканирования
Поисковые системы позволяют устанавливать приоритеты сканирования.
Google не поддерживает команду задержки сканирования напрямую, но вы можете снизить приоритет сканирования в Центре веб-мастеров Google.
Google занимает наибольшую долю рынка поиска на большинстве рынков и имеет один из самых эффективных приоритетов сканирования, поэтому вам не нужно менять приоритет сканирования Google.
Yahoo! Задержки сканирования Slurp в вашем файле robots.txt. (Примечание : на большинстве основных рынков за пределами Японии Yahoo! Search поддерживается Bing, а Google поддерживает поиск в Yahoo! Японии).
Их код задержки сканирования robots.txt выглядит как Пользовательский агент: Slurp Задержка сканирования: 5 где 5 в секундах.
Информация Microsoft для Bing находится здесь.
Их код задержки сканирования robots.txt выглядит как User-agent: bingbot Задержка сканирования: 10 где 10 в секундах.
Robots.txt Соответствие подстановочных знаков
Google и Microsoft Bing разрешают использование подстановочных знаков в роботах.txt файлы.
Чтобы заблокировать доступ ко всем URL-адресам, содержащим вопросительный знак (?), Вы можете использовать следующую запись:
Пользовательский агент: * Disallow: / *?
Вы можете использовать символ $, чтобы указать совпадение конца URL-адреса. Например, чтобы заблокировать URL-адреса, заканчивающиеся на .asp, вы можете использовать следующую запись:
Агент пользователя: Googlebot Disallow: /*. asp$
Дополнительные сведения о подстановочных знаках доступны в Google и Yahoo! Поиск.
Советы по URL
Частью создания чистого и эффективного файла robots.txt является обеспечение того, чтобы структура вашего сайта и имена файлов были созданы на основе разумной стратегии. Какие из моих любимых советов?
Избегайте дат в URL-адресах: Если в какой-то момент вы хотите отфильтровать архивы, основанные на дате, тогда вам не нужны даты в ваших путях к файлам на ваших обычных страницах с контентом, или вы можете легко отфильтровать ваши обычные URL-адреса.Есть множество других причин избегать дат в URL-адресах.
Конечные URL-адреса с обратной косой чертой: Если вы хотите заблокировать короткое имя файла без обратной косой черты в конце, то вы можете случайно заблокировать другие важные страницы.
Рассмотрите связанные URL-адреса, если вы используете подстановочные знаки Robots. txt: Я случайно потерял более 10 000 долларов прибыли из-за одной ошибки robots.txt!
Динамическая перезапись URL: Yahoo! Поиск предлагает динамическое переопределение URL-адресов, но, поскольку большинство других поисковых систем не используют его, вам, вероятно, лучше переписать свои URL-адреса в вашем.htaccess вместо создания дополнительных перезаписей только для Yahoo! Поиск. Google предлагает варианты обработки параметров & rel = canonical, но, как правило, лучше всего исправить общедоступные URL-адреса таким образом, чтобы они оставались как можно более согласованными, например,
Если вы когда-либо переходите с одной платформы на другую, у вас не будет много случайных ссылок, указывающих на страницы, которые больше не существуют
вы не создадите сложный лабиринт ловушек, когда вы меняете платформу за годы
Сайты на разных рынках и на разных языках: Поисковые системы обычно стараются повысить рейтинг известных локальных результатов, хотя в некоторых случаях бывает сложно встроить ссылки на многие локальные версии сайта. Google предлагает hreflang, чтобы помочь им узнать, какие URL-адреса являются эквивалентами для разных языков и рынков.
Дополнительные советы по URL-адресам в разделе именования файлов нашей обучающей программы по SEO.
Примеры странностей роботов
Google создает страницы поиска на вашем сайте?
Google начал вводить поисковые фразы в формы поиска, что может привести к потере рейтинга PageRank и вызвать проблемы с дублированием контента.Если у вас нет большого авторитета домена, вы можете подумать о том, чтобы заблокировать Google от индексации URL вашей страницы поиска. Если вы не знаете URL-адрес своей страницы поиска, вы можете выполнить поиск на своем сайте и посмотреть, какой URL-адрес появляется. Например,
URL-адрес поиска WordPress по умолчанию обычно ? S =
Добавление Пользовательский агент: * Disallow: /? S = в ваш файл robots. txt не позволит Google создавать такие страницы
Drupal поддерживает сайт SEO Book, а наш поисковый URL-адрес Drupal по умолчанию — / search / node /
Noindex вместо Disallow в роботах.текст?
Обычно директива noindex включается в метатег robots. Однако Google в течение многих лет поддерживает использование noindex в файле Robots.txt, подобно тому, как веб-мастер использовал бы disallow.
Загвоздка, как заметил Sugarrae, заключается в том, что URL-адреса, которые уже проиндексированы, но затем установлены на noindex в robots.txt, будут вызывать ошибки в консоли поиска Google (ранее известной как Google Webmaster Tools).Джон Мейллер из Google также не рекомендовал использовать noindex в robots.txt.
Защищенная версия вашего сайта индексируется?
В этом гостевом посте Тони Спенсера о переадресации 301 и . htaccess он предлагает советы о том, как предотвратить индексирование вашей SSL-версии https вашего сайта. За годы, прошедшие с момента его первоначальной публикации, Google указывал, что предпочитает ранжировать HTTPS-версию сайта над HTTP-версией сайта. Есть способы выстрелить себе в ногу, если он не будет перенаправлен или канонизирован должным образом.
Возникли проблемы с канонизацией или захватом?
На протяжении многих лет некоторые люди пытались захватить другие сайты, используя гнусные методы с помощью веб-прокси. Google, Yahoo! Поиск, Microsoft Live Search и Спросить позволяют владельцам сайтов аутентифицировать своих ботов.
Хотя я считаю, что Google уже исправил перехват прокси прямо сейчас, хороший совет по минимизации рисков перехвата — использование абсолютных ссылок (например, ), а не относительные ссылки ().
Если индексируются и WWW, и не WWW версии вашего сайта, вам следует 301 перенаправить менее авторитетную версию на более важную версию.
Версия, которую следует перенаправить, — это версия, которая не так хорошо ранжируется по большинству поисковых запросов и имеет меньше входящих ссылок.
Сделайте резервную копию старого файла .htaccess перед его изменением!
Хотите разрешить индексирование определенных файлов в папке, которые заблокированы с помощью сопоставления с образцом?
Разве мы не хитрые!
Изначально роботы.txt поддерживает только директиву disallow, но некоторые поисковые системы также поддерживают директиву allow. Директива allow плохо документирована и может по-разному обрабатываться разными поисковыми системами. Семетрическая общая информация о том, как Google обрабатывает директиву allow. Их исследование показало:
Количество символов, которые вы используете в пути к директиве, имеет решающее значение при оценке разрешения против запрета. Правило их всех таково:
Соответствующая директива Allow превосходит соответствующую директиву Disallow, только если она содержит большее или равное количество символов в пути
Сравнение роботов.txt в …
ссылка rel = nofollow & Meta Robots Теги Noindex / Nofollow
Просканировано роботом Googlebot?
появляется в индексе?
Потребляет PageRank
Риски? Трата?
Формат
robots.txt
нет
Если на документ есть ссылка, он может отображаться только по URL-адресу или с данными из ссылок или доверенных сторонних источников данных, таких как ODP
да
Люди могут смотреть на ваших роботов. txt, чтобы увидеть, какой контент вы не хотите индексировать. Многие новые запуски обнаруживаются людьми, которые следят за изменениями в файле robots.txt.
Неправильное использование подстановочных знаков может быть дорогостоящим!
Пользовательский агент: * Запретить: / folder /
ИЛИ
Пользовательский агент: * Запрещено: /file.html
Также можно использовать сложные подстановочные знаки.
мета тег noindex роботов
да
нет
да, но может передать большую часть своего PageRank, ссылаясь на другие страницы
Ссылки на странице noindex по-прежнему сканируются поисковыми пауками, даже если страница не отображается в результатах поиска (если они не используются вместе с nofollow).
Страница, использующая мета nofollow роботов (1 строка ниже) в сочетании с noindex, может накапливать PageRank, но не передавать его другим страницам.
ИЛИ можно использовать с nofollow likeo
мета-тег nofollow для роботов
целевая страница сканируется только в том случае, если на нее есть ссылки из других документов
Целевая страница
отображается, только если на нее есть ссылка из других документов
нет, PageRank не передан по назначению
Если вы увеличиваете значительный PageRank на странице и не позволяете PageRank исходить с этой страницы, вы можете потерять значительную долю ссылочного рейтинга.
ИЛИ можно использовать с noindex likeo
ссылка rel = nofollow
целевая страница сканируется только в том случае, если на нее есть ссылки из других документов
Целевая страница
отображается, только если на нее есть ссылка из других документов
Использование этого может привести к потере некоторого PageRank. Рекомендуется использовать в областях контента, создаваемых пользователями.
Если вы делаете что-то на грани спама и используете nofollow для внутренних ссылок для увеличения PageRank, тогда вы больше похожи на оптимизатора поисковых систем и, скорее всего, будете наказаны инженером Google за «поисковый спам»
да.может сканироваться несколько версий страницы, и они могут появиться в индексе
В индексе все еще отображается
страниц. это воспринимается скорее как подсказка, чем как директива.
PageRank должен накапливаться на целевой цели
При использовании таких инструментов, как переадресация 301 и rel = canonical, может возникнуть небольшая потеря PageRank, особенно с rel = canonical, поскольку обе версии страницы остаются в поисковом индексе.
Ссылка на Javascript
в целом да, если целевой URL легко доступен в частях ссылки a href или onclick
Целевая страница
отображается, только если на нее есть ссылка из других документов
в целом да, PageRank обычно передается получателю
Хотя многие из них отслеживаются Google, они могут не отслеживаться другими поисковыми системами.
Bingbot, найдя для себя конкретный набор инструкций, проигнорирует директивы, перечисленные в общем разделе, поэтому вам нужно будет повторить все общие директивы в дополнение к конкретным директивам, которые вы создали для них, в их собственном разделе файла. .
Используйте текстовый редактор, чтобы создать файл robots.txt и добавить директивы REP, чтобы блокировать доступ к содержимому ботами. Текстовый файл должен быть сохранен в кодировке ASCII или UTF-8 .
Боты упоминаются как пользовательские агенты в файле robots.txt. В начале файла запустите первый раздел директив, применимых ко всем ботам, добавив эту строку: User-agent: *
Создайте список директив Disallow с указанием содержимого, которое вы хотите заблокировать. Пример Учитывая наши ранее использованные примеры каталогов, такой набор директив будет выглядеть так:
Пользовательский агент: *
Disallow: / cgi-bin /
Запретить: / scripts /
Disallow: / tmp /
Примечание
Вы не можете перечислить несколько ссылок на контент в одной строке, поэтому вам потребуется создать новую директиву Disallow: для каждого блокируемого шаблона. Однако вы можете использовать подстановочные знаки. Обратите внимание, что каждый шаблон URL-адреса начинается с косой черты, представляющей корень текущего сайта.
Вы также можете использовать директиву Allow: для файлов, хранящихся в каталоге, содержимое которого в противном случае будет заблокировано.
Дополнительные сведения об использовании подстановочных знаков и создании директив Disallow и Allow см. В статье блога Центра веб-мастеров «Предотвращение« потери бота в космосе »».
Если вы хотите добавить настраиваемые директивы для определенных ботов, которые не подходят для всех ботов, например crawl-delay :, добавьте их в настраиваемый раздел после первого общего раздела, изменив ссылку User-agent на конкретного бота.Список применимых имен ботов см. В базе данных роботов.
Примечание
Добавление наборов директив, настроенных для отдельных ботов, не рекомендуется. Типичная необходимость повторения директив из общего раздела усложняет задачи обслуживания файлов. Кроме того, упущения в надлежащем обслуживании этих настраиваемых разделов часто являются источником проблем сканирования с помощью роботов поисковых систем.
Необязательно: добавьте ссылку на файл карты сайта (если он у вас есть)
Если вы создали файл Sitemap, в котором перечислены наиболее важные страницы вашего сайта, вы можете указать на него боту, указав его в отдельной строке в конце файла.
Пример Файл Sitemap обычно сохраняется в корневом каталоге сайта. Такая строка директивы Sitemap будет выглядеть так:
Карта сайта: http://www.your-url.com/sitemap.xml
Проверьте наличие ошибок, проверив файл robots.txt
Загрузите файл robots.txt в корневой каталог вашего сайта
Примечание
Вам не нужно отправлять свои новые robots. txt в поисковые системы. Боты поисковых систем автоматически ищут файл с именем robots.txt в корневом каталоге вашего сайта и, если он найден, сначала прочитают этот файл, чтобы увидеть, какие директивы к ним относятся. Обратите внимание, что поисковые системы хранят копию вашего robots.txt как минимум в течение нескольких часов в своем кеше, поэтому изменения могут отразиться на их поведении сканирования в течение нескольких часов.
Помогите правильно настроить Robots.txt, чтобы очистить 164 Ошибка индексации консоли поиска Google
Я попытался опубликовать все это на форумах поддержки Google Search Console, однако они удалили мою ветку из-за слова «каннабис» в ней.Так что мне кажется, что я вообще не смогу от них получить помощь. Надеюсь, кто-то здесь может помочь мне разобраться в этом, это полный беспорядок.
Даже моя главная домашняя страница все это время не индексировалась, что, по мнению Google, означает, что она никогда не отображается ни при каких поисковых запросах — что, очевидно, является серьезной проблемой, поскольку на моей домашней странице имеется много соответствующей информации.
Во-первых, я не понимаю, почему у robots.txt вообще есть проблема, которая, похоже, возникла с тех пор, как я изначально установил wordpress и X Theme Pro.
Почему этот файл не установился автоматически при установке?
В настоящее время это мой новый файл robots.txt, который я создал с помощью Yoast SEO:
Кажется, все мои проблемы со сканированием по большей части связаны с изображениями:
Что меня действительно сбивает с толку, так как с момента установки ухудшилась возможность сканирования / добавления / добавления изображений на моем сайте WordPress?
И даже с добавлением этого нового Allow: / wp-content / uploads
Роботы. txt все еще заблокирован:
Не следует ли разрешить: / wp-content / uploads / устранить все эти проблемы со сканированием изображений теперь, когда я добавил это конкретное разрешение в файл robots.txt?
Кроме того, необходимы ли оба файла Sitemap? Действительно ли нужен файл news-sitemap.xml? Он был автоматически сгенерирован Yoast SEO, когда я попросил его создать файл robots.txt.
Я надеюсь, что кто-нибудь уже поможет мне исправить это, меня уже больше года разрушает эта ужасная индексация.Я даже получаю сообщения о том, что моя домашняя страница не проиндексирована!
Наконец, когда дело доходит до «Свойства» в Google Search Console, мне изначально было сказано кем-то добавить следующие 4 свойства:
Я пришел к выводу, что только у него была реальная статистика, по другим 3 свойствам буквально было 4 сканирования.
Я также заметил, что мой новый файл robots.txt Yoast SEO обновлялся только по URL-адресу, по какой-то причине остальные 3 сохранили старый / стандартный файл robots. txt
Я просто удалил остальные 3, так как не думал, что они что-то делают, основываясь на своей статистике и явно отрицательно влияли на индексирование со старыми / стандартными роботами.txt файл
Должен ли я добавить их обратно?
Извините, это так долго, но у меня действительно плохое положение с поисковой оптимизацией и индексированием, и в прошлом году мой бизнес сильно пострадал из-за очень низкого трафика.
Я не уверен, влияет ли этот robots.txts на тест для мобильных устройств, возвращающийся с кучей ошибок ресурсов, или нет, или это все еще отдельная проблема?
Страница, на которой мне нужна помощь: [войдите, чтобы увидеть ссылку]
Что такое robots.txt и как его создать?
Что такое robots.txt?
Рисунок: Robots.txt — Автор: Seobility — Лицензия: CC BY-SA 4.0
Robots.txt — это текстовый файл с инструкциями для поисковых роботов. Он определяет, в каких областях поисковые роботы веб-сайта могут выполнять поиск. Однако в файле robots.txt они явно не указаны. Скорее, в определенных областях запрещен обыск. Используя этот простой текстовый файл, вы можете легко исключить целые домены, полные каталоги, один или несколько подкаталогов или отдельные файлы из сканирования поисковой системой.Однако этот файл не защищает от несанкционированного доступа.
Robots.txt хранится в корневом каталоге домена. Таким образом, это первый документ, который сканеры открывают при посещении вашего сайта. Однако файл управляет не только сканированием. Вы также можете интегрировать ссылку в свою карту сайта, которая дает сканерам поисковых систем обзор всех существующих URL-адресов вашего домена.
Проверка Robots.txt
Проверьте файл robots.txt на своем веб-сайте
Как роботы.txt работает
В 1994 году был опубликован протокол под названием REP (Стандартный протокол исключения роботов). Этот протокол предусматривает, что все сканеры поисковых систем (пользовательские агенты) должны сначала найти файл robots. txt в корневом каталоге вашего сайта и прочитать содержащиеся в нем инструкции. Только после этого роботы могут начать индексировать вашу веб-страницу. Файл должен находиться непосредственно в корневом каталоге вашего домена и должен быть написан в нижнем регистре, поскольку роботы читают файл robots.txt и его инструкции с учетом регистра.К сожалению, не все роботы поисковых систем соблюдают эти правила. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.
На практике robots.txt можно использовать для файлов разных типов. Если вы используете его для файлов изображений, он предотвращает появление этих файлов в результатах поиска Google. Неважные файлы ресурсов, такие как файлы сценариев, стилей и изображений, также можно легко заблокировать с помощью роботов.текст. Кроме того, вы можете исключить динамически генерируемые веб-страницы из сканирования с помощью соответствующих команд. Например, могут быть заблокированы страницы результатов функции внутреннего поиска, страницы с идентификаторами сеанса или действия пользователя, такие как тележки для покупок. Вы также можете управлять доступом поискового робота к другим файлам без изображений (веб-страницам) с помощью текстового файла. Таким образом, вы можете избежать следующих сценариев:
поисковые роботы сканируют множество похожих или неважных веб-страниц
ваш краулинговый бюджет потрачен напрасно
ваш сервер перегружен поисковыми роботами
В этом контексте, однако, обратите внимание, что robots.txt не гарантирует, что ваш сайт или отдельные подстраницы не проиндексированы. Он контролирует только сканирование вашего сайта, но не индексирование. Если веб-страницы не должны индексироваться поисковыми системами, вы должны установить следующий метатег в заголовке своей веб-страницы:
Однако не следует блокировать файлы, которые имеют большое значение для поисковых роботов. Обратите внимание, что файлы CSS и JavaScript также должны быть разблокированы, поскольку они используются для сканирования, особенно мобильными роботами.
Какие инструкции используются в robots.txt?
Ваш robots.txt должен быть сохранен как текстовый файл UTF-8 или ASCII в корневом каталоге вашей веб-страницы. Должен быть только один файл с таким именем. Он содержит один или несколько наборов правил, структурированных в легко читаемом формате. Правила (инструкции) обрабатываются сверху вниз, при этом различаются буквы верхнего и нижнего регистра.
В файле robots.txt используются следующие термины:
user-agent: обозначает имя краулера (имена можно найти в базе данных роботов)
запретить: запрещает сканирование определенных файлов, каталогов или веб-страниц
разрешить: перезаписывает запрет и разрешает сканирование файлов, веб-страниц и каталогов.
карта сайта (необязательно): показывает расположение карты сайта
*: обозначает любое количество символов
$: обозначает конец строки
Инструкции (записи) в robots. txt всегда состоит из двух частей. В первой части вы определяете, для каких роботов (пользовательских агентов) применяется следующая инструкция. Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: / clients /» означают, что бот Google не может выполнять поиск в каталоге / clients /. Если поисковый бот не должен сканировать весь веб-сайт, введите следующую запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$» для блокировки веб-страниц с определенным расширением.Оператор «disallow: / * .doc $» блокирует все URL-адреса с расширением .doc. Таким же образом вы можете заблокировать определенные форматы файлов в файле robots.txt: «disallow: /*.jpg$».
Например, файл robots.txt для веб-сайта https://www.example.com/ может выглядеть так:
Какую роль играет robots.txt в поисковой оптимизации?
Инструкции в файле robots.txt имеет сильное влияние на SEO (поисковую оптимизацию), так как файл позволяет вам управлять поисковыми роботами. Однако, если пользовательские агенты слишком сильно ограничены инструкциями по запрещению, это отрицательно повлияет на рейтинг вашего сайта. Вы также должны учитывать, что вы не попадете в рейтинг веб-страниц, которые вы исключили или запретили в robots.txt. Если, с другой стороны, нет или почти нет запретительных ограничений, может случиться так, что страницы с дублированным контентом будут проиндексированы, что также отрицательно скажется на рейтинге этих страниц.
Перед тем, как сохранить файл в корневом каталоге вашего веб-сайта, вы должны проверить синтаксис. Даже незначительные ошибки могут привести к тому, что поисковые роботы будут игнорировать правила запрета и сканировать сайты, которые не должны индексироваться. Такие ошибки также могут привести к тому, что страницы больше не будут доступны для поисковых роботов, а целые URL-адреса не будут индексироваться из-за запрета. Вы можете проверить правильность своего файла robots.txt с помощью Google Search Console. В разделах «Текущий статус» и «Ошибки сканирования» вы найдете все страницы, заблокированные инструкциями по запрету.
Правильно используя robots.txt, вы можете гарантировать, что все важные части вашего сайта будут сканироваться поисковыми роботами. Следовательно, все содержимое вашей страницы индексируется Google и другими поисковыми системами.


 txt
txt txt
txt txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах.
txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. Чтобы отменить это, в конце строки необходимо поставить символ $.
Чтобы отменить это, в конце строки необходимо поставить символ $. Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п.
Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п.
 Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
 Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части. ru»><noindex>Анкор</noindex></a>
ru»><noindex>Анкор</noindex></a>
 В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера: После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.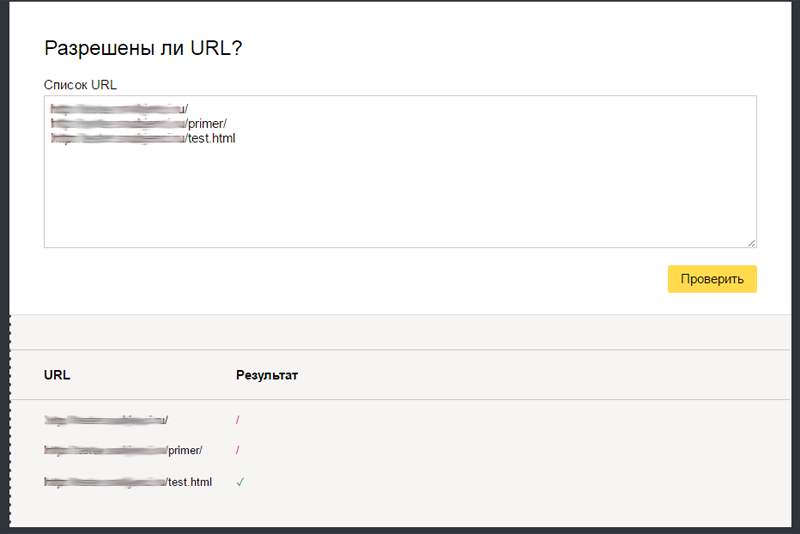
 Если в файле robots.txt («паспорте») прописана соответствующая директива – робот её выполняет. Если нет, то он – сканирует страницу в общем порядке, поскольку по-умолчанию – к сканированию разрешены все страницы.
Если в файле robots.txt («паспорте») прописана соответствующая директива – робот её выполняет. Если нет, то он – сканирует страницу в общем порядке, поскольку по-умолчанию – к сканированию разрешены все страницы.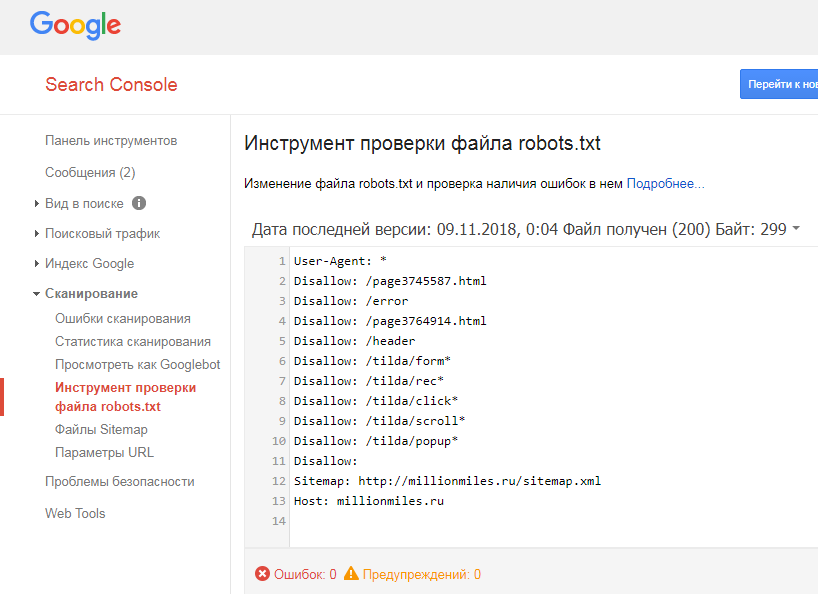 Ну, и где теперь файл robots.txt?
Ну, и где теперь файл robots.txt?
 Полученные в результате два изображения «Так увидел эту страницу робот Googlebot» и «Так увидит эту страницу посетитель сайта» должны выглядеть практически одинаково. Пример страницы с проблемами:
Полученные в результате два изображения «Так увидел эту страницу робот Googlebot» и «Так увидит эту страницу посетитель сайта» должны выглядеть практически одинаково. Пример страницы с проблемами: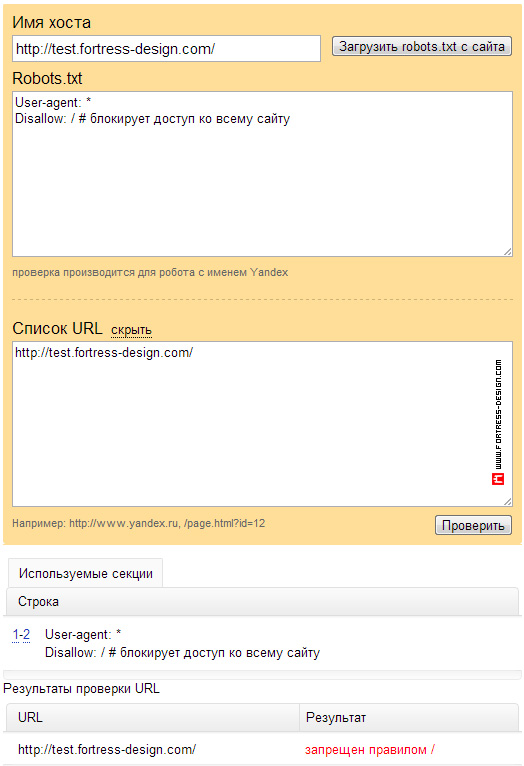 txt, через htaccess и мета-теги
txt, через htaccess и мета-теги Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
 При желании, можно скрыть от поисковиков любой контент, ресурс или его отдельные страницы.
При желании, можно скрыть от поисковиков любой контент, ресурс или его отдельные страницы.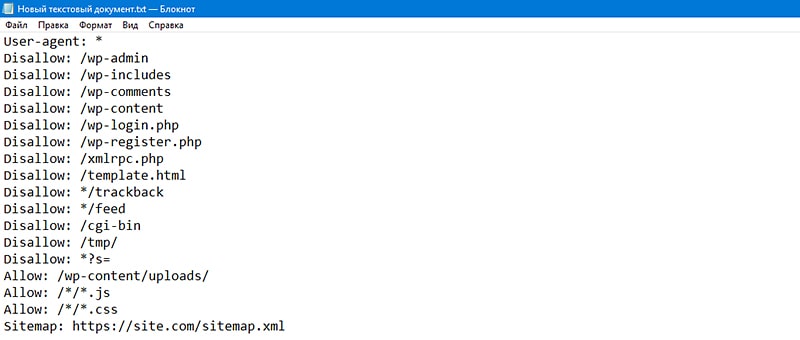 Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.
Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.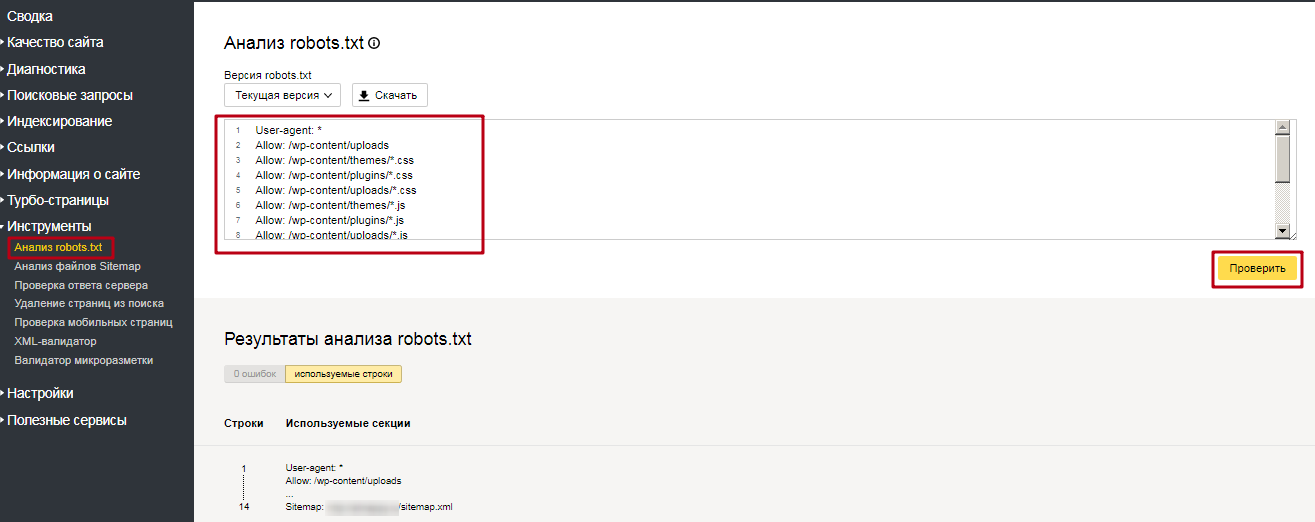
 txt на время разработки?
txt на время разработки? txt для этих целей. Как это делается — написано дальше.
txt для этих целей. Как это делается — написано дальше.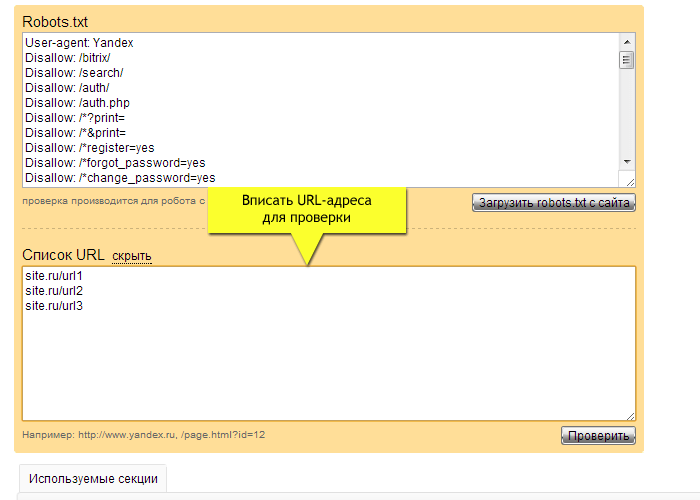 Рекомендуется использовать в областях контента, создаваемых пользователями.
Рекомендуется использовать в областях контента, создаваемых пользователями.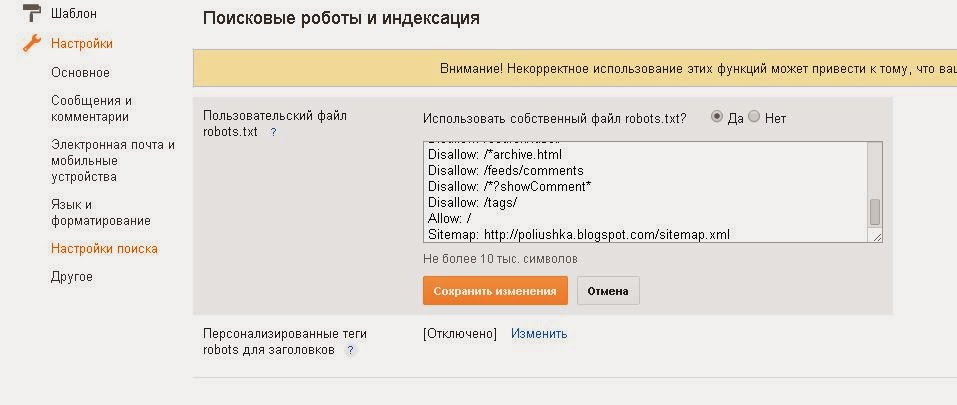
 txt Руководство для Google, Bing и других поисковых систем
txt Руководство для Google, Bing и других поисковых систем  txt, они могут по-прежнему отображать эти страницы как списки только URL-адресов в своих результатах поиска.Лучшее решение для полной блокировки индекса конкретной страницы — использовать метатег robots noindex для каждой страницы. Вы можете сказать им не индексировать страницу или не индексировать страницы и , чтобы не переходить по исходящим ссылкам, вставив один из следующих битов кода в заголовок HTML вашего документа, который вы не хотите индексировать.
txt, они могут по-прежнему отображать эти страницы как списки только URL-адресов в своих результатах поиска.Лучшее решение для полной блокировки индекса конкретной страницы — использовать метатег robots noindex для каждой страницы. Вы можете сказать им не индексировать страницу или не индексировать страницы и , чтобы не переходить по исходящим ссылкам, вставив один из следующих битов кода в заголовок HTML вашего документа, который вы не хотите индексировать.

 asp$
asp$ txt: Я случайно потерял более 10 000 долларов прибыли из-за одной ошибки robots.txt!
txt: Я случайно потерял более 10 000 долларов прибыли из-за одной ошибки robots.txt!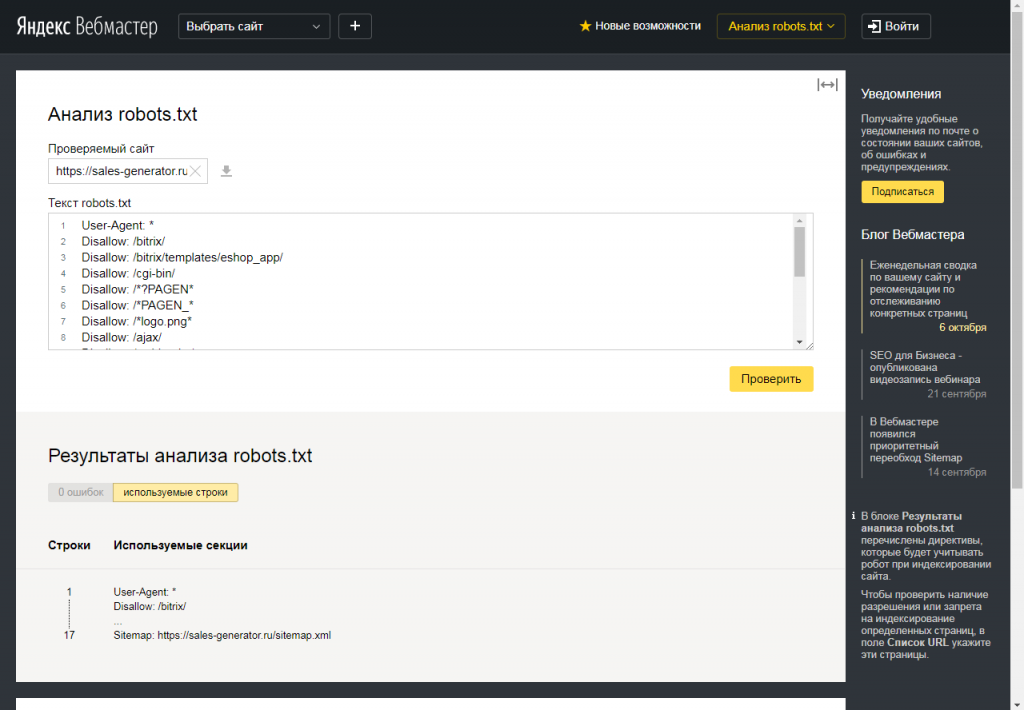 Google предлагает hreflang, чтобы помочь им узнать, какие URL-адреса являются эквивалентами для разных языков и рынков.
Google предлагает hreflang, чтобы помочь им узнать, какие URL-адреса являются эквивалентами для разных языков и рынков.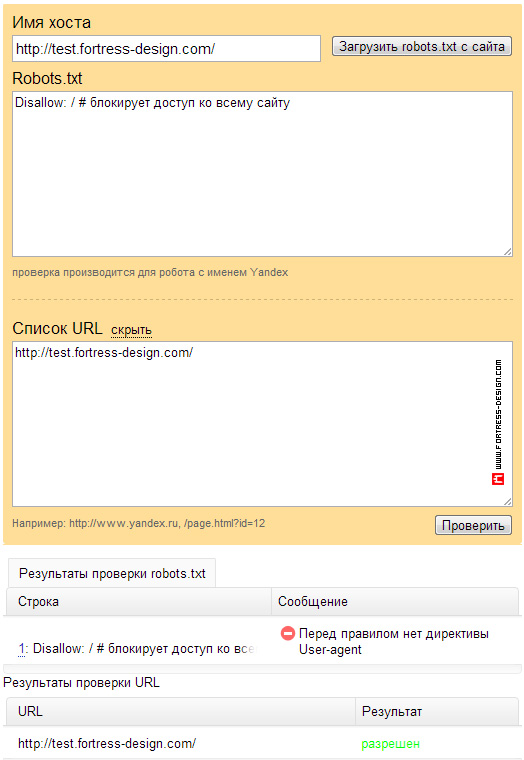 txt не позволит Google создавать такие страницы
txt не позволит Google создавать такие страницы htaccess он предлагает советы о том, как предотвратить индексирование вашей SSL-версии https вашего сайта. За годы, прошедшие с момента его первоначальной публикации, Google указывал, что предпочитает ранжировать HTTPS-версию сайта над HTTP-версией сайта. Есть способы выстрелить себе в ногу, если он не будет перенаправлен или канонизирован должным образом.
htaccess он предлагает советы о том, как предотвратить индексирование вашей SSL-версии https вашего сайта. За годы, прошедшие с момента его первоначальной публикации, Google указывал, что предпочитает ранжировать HTTPS-версию сайта над HTTP-версией сайта. Есть способы выстрелить себе в ногу, если он не будет перенаправлен или канонизирован должным образом.
 Правило их всех таково:
Правило их всех таково: txt, чтобы увидеть, какой контент вы не хотите индексировать. Многие новые запуски обнаруживаются людьми, которые следят за изменениями в файле robots.txt.
txt, чтобы увидеть, какой контент вы не хотите индексировать. Многие новые запуски обнаруживаются людьми, которые следят за изменениями в файле robots.txt.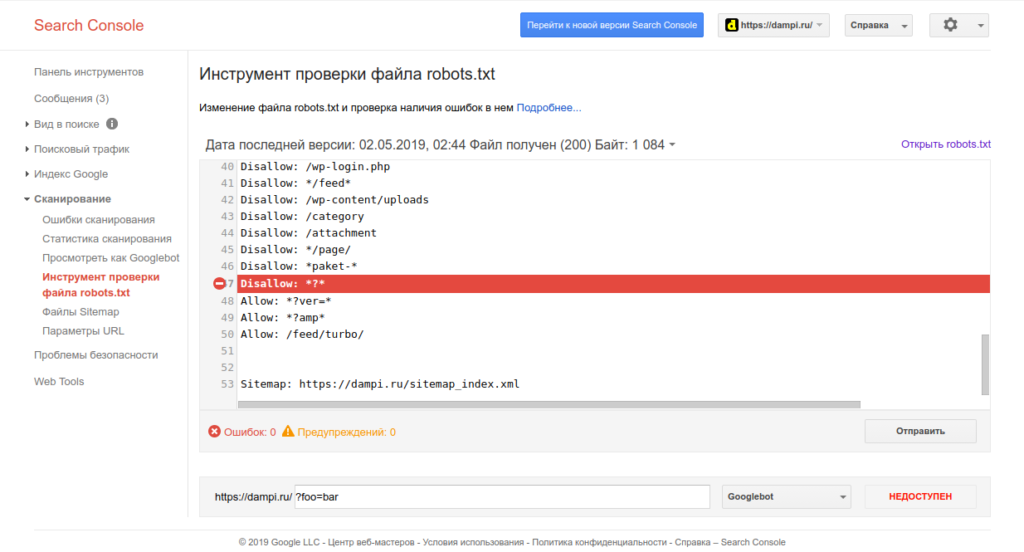
 txt и Sitemap
txt и Sitemap 
 Например, страницы входа или страницы ресурсов не должны даже запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Например, страницы входа или страницы ресурсов не должны даже запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.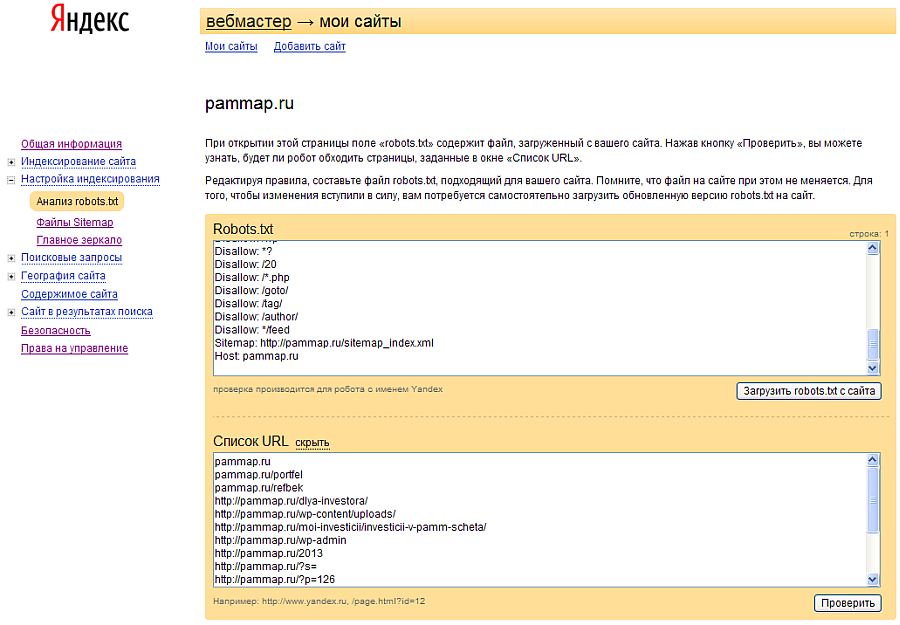 Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
 txt . В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
txt . В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
 Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»: Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом: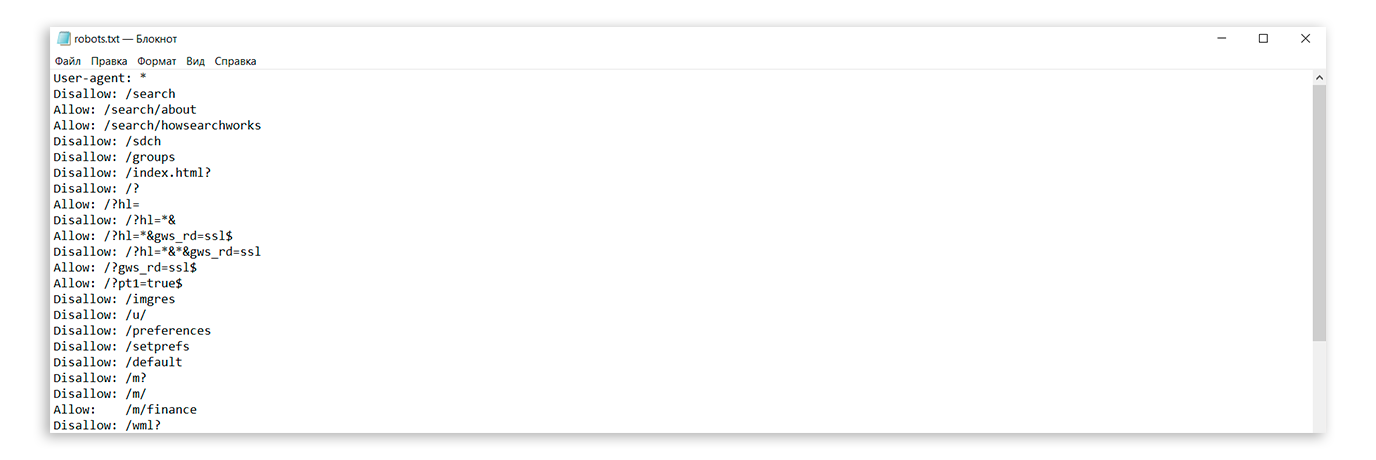 txt и карты сайта, прежде чем поисковые системы начнут их использовать.
txt и карты сайта, прежде чем поисковые системы начнут их использовать. txt
txt
 Однако вы можете использовать подстановочные знаки. Обратите внимание, что каждый шаблон URL-адреса начинается с косой черты, представляющей корень текущего сайта.
Однако вы можете использовать подстановочные знаки. Обратите внимание, что каждый шаблон URL-адреса начинается с косой черты, представляющей корень текущего сайта. Типичная необходимость повторения директив из общего раздела усложняет задачи обслуживания файлов. Кроме того, упущения в надлежащем обслуживании этих настраиваемых разделов часто являются источником проблем сканирования с помощью роботов поисковых систем.
Типичная необходимость повторения директив из общего раздела усложняет задачи обслуживания файлов. Кроме того, упущения в надлежащем обслуживании этих настраиваемых разделов часто являются источником проблем сканирования с помощью роботов поисковых систем. txt в поисковые системы. Боты поисковых систем автоматически ищут файл с именем robots.txt в корневом каталоге вашего сайта и, если он найден, сначала прочитают этот файл, чтобы увидеть, какие директивы к ним относятся. Обратите внимание, что поисковые системы хранят копию вашего robots.txt как минимум в течение нескольких часов в своем кеше, поэтому изменения могут отразиться на их поведении сканирования в течение нескольких часов.
txt в поисковые системы. Боты поисковых систем автоматически ищут файл с именем robots.txt в корневом каталоге вашего сайта и, если он найден, сначала прочитают этот файл, чтобы увидеть, какие директивы к ним относятся. Обратите внимание, что поисковые системы хранят копию вашего robots.txt как минимум в течение нескольких часов в своем кеше, поэтому изменения могут отразиться на их поведении сканирования в течение нескольких часов.
 txt все еще заблокирован:
txt все еще заблокирован: txt
txt Однако в файле robots.txt они явно не указаны. Скорее, в определенных областях запрещен обыск. Используя этот простой текстовый файл, вы можете легко исключить целые домены, полные каталоги, один или несколько подкаталогов или отдельные файлы из сканирования поисковой системой.Однако этот файл не защищает от несанкционированного доступа.
Однако в файле robots.txt они явно не указаны. Скорее, в определенных областях запрещен обыск. Используя этот простой текстовый файл, вы можете легко исключить целые домены, полные каталоги, один или несколько подкаталогов или отдельные файлы из сканирования поисковой системой.Однако этот файл не защищает от несанкционированного доступа. txt в корневом каталоге вашего сайта и прочитать содержащиеся в нем инструкции. Только после этого роботы могут начать индексировать вашу веб-страницу. Файл должен находиться непосредственно в корневом каталоге вашего домена и должен быть написан в нижнем регистре, поскольку роботы читают файл robots.txt и его инструкции с учетом регистра.К сожалению, не все роботы поисковых систем соблюдают эти правила. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.
txt в корневом каталоге вашего сайта и прочитать содержащиеся в нем инструкции. Только после этого роботы могут начать индексировать вашу веб-страницу. Файл должен находиться непосредственно в корневом каталоге вашего домена и должен быть написан в нижнем регистре, поскольку роботы читают файл robots.txt и его инструкции с учетом регистра.К сожалению, не все роботы поисковых систем соблюдают эти правила. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.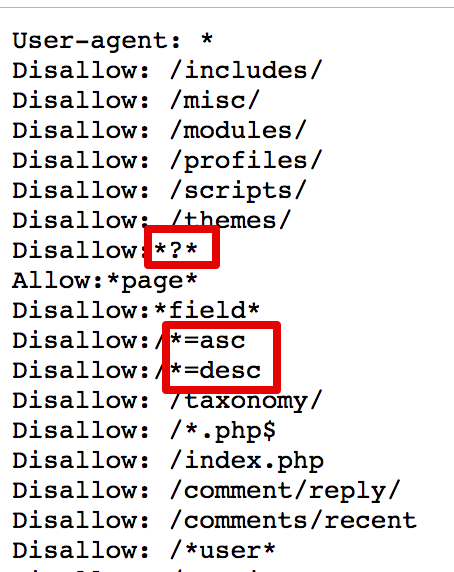 Например, могут быть заблокированы страницы результатов функции внутреннего поиска, страницы с идентификаторами сеанса или действия пользователя, такие как тележки для покупок. Вы также можете управлять доступом поискового робота к другим файлам без изображений (веб-страницам) с помощью текстового файла. Таким образом, вы можете избежать следующих сценариев:
Например, могут быть заблокированы страницы результатов функции внутреннего поиска, страницы с идентификаторами сеанса или действия пользователя, такие как тележки для покупок. Вы также можете управлять доступом поискового робота к другим файлам без изображений (веб-страницам) с помощью текстового файла. Таким образом, вы можете избежать следующих сценариев: Обратите внимание, что файлы CSS и JavaScript также должны быть разблокированы, поскольку они используются для сканирования, особенно мобильными роботами.
Обратите внимание, что файлы CSS и JavaScript также должны быть разблокированы, поскольку они используются для сканирования, особенно мобильными роботами. txt всегда состоит из двух частей. В первой части вы определяете, для каких роботов (пользовательских агентов) применяется следующая инструкция. Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: / clients /» означают, что бот Google не может выполнять поиск в каталоге / clients /. Если поисковый бот не должен сканировать весь веб-сайт, введите следующую запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$» для блокировки веб-страниц с определенным расширением.Оператор «disallow: / * .doc $» блокирует все URL-адреса с расширением .doc. Таким же образом вы можете заблокировать определенные форматы файлов в файле robots.txt: «disallow: /*.jpg$».
txt всегда состоит из двух частей. В первой части вы определяете, для каких роботов (пользовательских агентов) применяется следующая инструкция. Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: / clients /» означают, что бот Google не может выполнять поиск в каталоге / clients /. Если поисковый бот не должен сканировать весь веб-сайт, введите следующую запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$» для блокировки веб-страниц с определенным расширением.Оператор «disallow: / * .doc $» блокирует все URL-адреса с расширением .doc. Таким же образом вы можете заблокировать определенные форматы файлов в файле robots.txt: «disallow: /*.jpg$». example.com/sitemap.xml
example.com/sitemap.xml  Вы можете проверить правильность своего файла robots.txt с помощью Google Search Console. В разделах «Текущий статус» и «Ошибки сканирования» вы найдете все страницы, заблокированные инструкциями по запрету.
Вы можете проверить правильность своего файла robots.txt с помощью Google Search Console. В разделах «Текущий статус» и «Ошибки сканирования» вы найдете все страницы, заблокированные инструкциями по запрету.
Добавить комментарий