|
|
Если вы не нашли ответ на свой вопрос — свяжитесь с нами. |
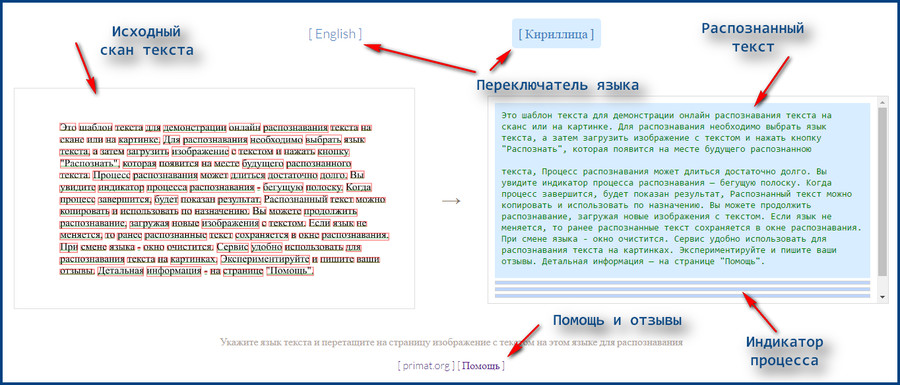 doc)
doc)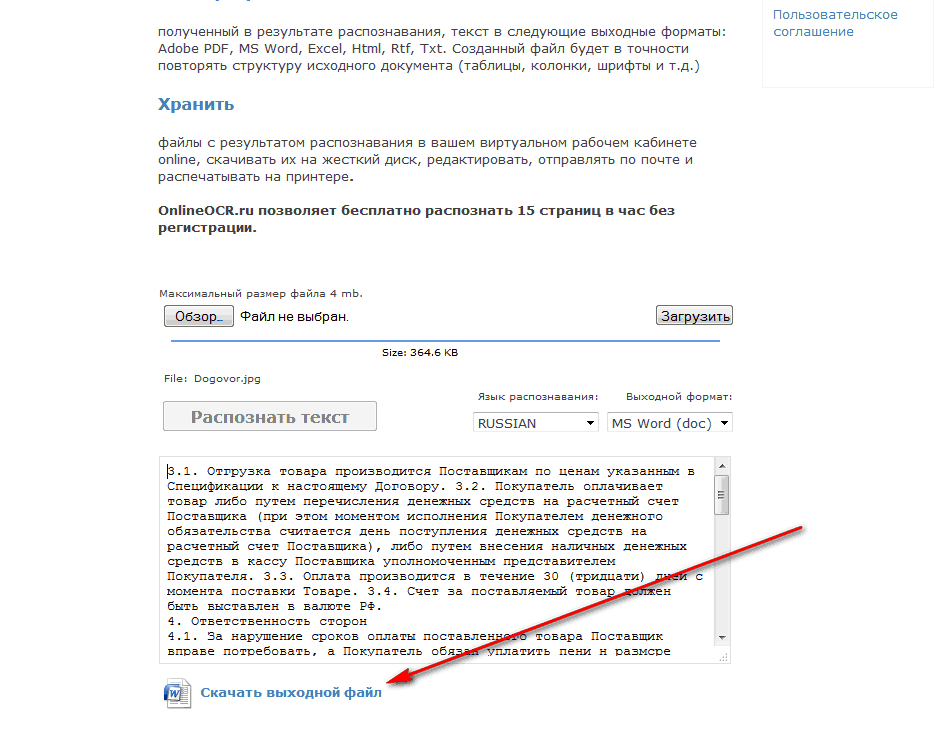 Чтобы получать письма, настройте отправку уведомлений в вашем профиле.
Чтобы получать письма, настройте отправку уведомлений в вашем профиле.
 Однако плохое качество фотографии может стать причиной множества ошибок.
Однако плохое качество фотографии может стать причиной множества ошибок.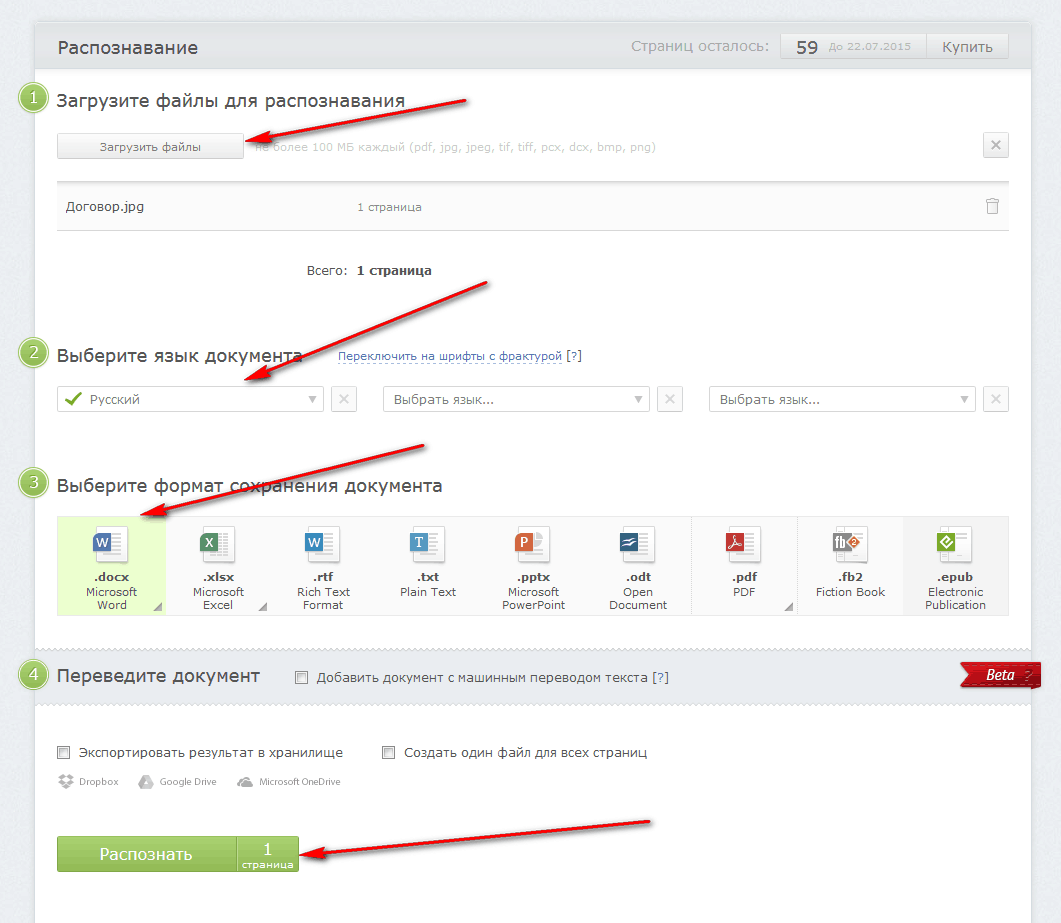 Документ, отсканированный под наклоном, или фотография с большим количеством
Документ, отсканированный под наклоном, или фотография с большим количеством

 FineReader
FineReader

Как Определить Шрифт по Картинке Онлайн
Определяем шрифт по картинке
Если вы дизайнер или просто любитель, использующий какой-либо графический редактор, возможно, вы сталкивались с проблемой определения шрифтов.
Например, когда приглянувшийся шрифт, которым написан текст, находится на изображении.
Вы могли увидеть его на сайте или сделать снимок экрана при просмотре видео ̶ это неважно.
О том, как определить шрифт по картинке, расскажем в статье.
Содержание этой статьи:
Сервисы для определения шрифтов
Читайте также: ТОП-10 Сервисов и программ для бесплатного онлайн распознавания текста
Определяем шрифт в интернете
Наиболее популярными на просторах Интернета являются следующие сервисы, которые позволяют определить по картинке онлайн:
- What The Font
- What Font Is
- Bowfin Printworks
- Identifont
- Type Navigator
- Flickr Typeface Identification
Различий между ними довольно много. Рассмотрим каждый из приведенных выше сайтов подробнее.
Рассмотрим каждый из приведенных выше сайтов подробнее.
back to menu ↑ back to menu ↑
What The Font
Читайте также: ТОП-10 Онлайн-сервисов чтобы сделать красивый текст +Отзывы
Сервис What The Font
Первый в списке поисковиков ресурс What The Font получил это место неслучайно. По своей сути, это раздел популярного сайта, содержащего широкую базу шрифтов.
Удобство пользования и быстрота поиска ̶ это также немаловажные критерии высокой оценки.
От вас требуется только ряд простых действий.
Порядок выполнения указан прямо на странице поиска.
Чтобы найти шрифт по картинке вам необходимо:
- Загрузить нужное изображение, нажав клавишу «Выберите файл». Сделать это можно с файлом, который уже хранится на вашем устройстве.
- Пройдите в папку, где хранится картинка и нажмите «Открыть».
- Чтобы перейти к следующему шагу используйте кнопку «Continue»;
Размер загружаемого снимка не должен превышать 2 Мб.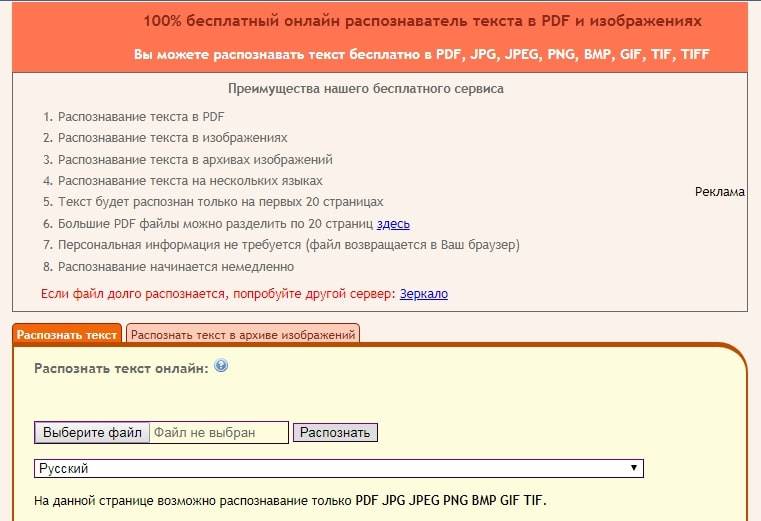 Сам файл может быть PNG, JPEG и GIF формата.
Сам файл может быть PNG, JPEG и GIF формата.
- На этом этапе ресурс разделяет имеющийся на изображении текст на отдельные буквы. Если ему это не удалось, то вам нужно ему немного помочь и вставить соответствующие буквы под теми, что находятся на снимке. После завершения идентификации нажмите «Continue»;
Нажимаем Continue
- Заключительный шаг представляет собой отчет о найденных шрифтах. Если их было несколько, сайт укажет это. Результат поиска, то есть название шрифта, отображается синим тестом.
Результаты поиска
Если нужный шрифт не был найден, вы можете пройти на Font Forum. Разместите имеющуюся картинку и спустя некоторое время получите комментарий от эксперта, который подскажет стиль указанного теста.
Для корректного результата убедитесь в том, что:
- Соседние буквы в тексте не касаются друг друга;
- Используемые в шрифте символы имеют отчетливую форму;
- Текст должен быть горизонтально ровным настолько, насколько это возможно;
- Если это возможно, высота символом не должна быть около 100 пикселей.

На сайт back to menu ↑ back to menu ↑
What Font Is
Читайте также: 10 интересных онлайн-сервисов для создания гифок (GIF-анимации)
Поиск шрифтов
What Font Is ̶ это еще один приятный и удобный в навигации и точности определения шрифта сервис.
Принцип поиска здесь почти полностью идентичен предыдущему сайту: вы также загружаете фото или вставляете на него URL-ссылку, прописываете каждую букву из текста для повышения корректности результата и на выходе получаете название интересующего вас стиля.
Однако есть и одно существенное отличие, выделяющее этот поисковик.
В процессе заполнения нужных полей вам будет предложен один из трех вариантов поиска на выбор:
- Показать бесплатные шрифты или их аналоги;
- Показать только платные (коммерческие) шрифты или их аналоги;
- Показывать все виды шрифтов.
Такой выбор альтернативных вариантов поможет сразу найти бесплатные стили, не утруждая вас самостоятельным поиском в сети Интернет.
На сайт back to menu ↑ back to menu ↑
Bowfin Printworks
Читайте также: Создать коллаж из фотографий онлайн — ТОП-15 сервисов
Сервис подбора шрифтов
Сайт Bowfin Printworks представляет собой площадку, обладающую огромными информационными ресурсами в сфере шрифтов.
Метод поиска основан на наводящих вопросах о форме символов используемого стиля.
Кроме инструментов поиска сервис содержит руководства по таким шрифтам, как Serif, Sans Serif, Script и множеству других.
На сайт back to menu ↑ back to menu ↑
Identifont
Читайте также: Как в Ворде перевернуть текст: Самые простые способы
Сервис Identifont
Принцип работы, как и у Bowfin Printworks, заключается в ответах на вопросы о ключевых особенностях шрифта.
Если вы допустили ошибку, то можете вернуться к нужному вопросу, используя список.
Сервис поможет определить результат, даже если у вас в распоряжении находится только небольшой кусочек текста.
По схожему способу идентификации стоит выделить сайт Type Navigator.
На сайт back to menu ↑ back to menu ↑
Flickr Typeface Identification
Читайте также: ТОП-10 Бесплатных программа для работы с PDF файлами +Отзывы
Flickr Typeface Identification
Flickr ̶ это крупный популярный фотохостинг.
На его просторах находятся разнообразные группы. Вам нужны Flickr Typeface Identification и Fonts in Use.
Они содержат сотни шрифтов, используемых на различных картинках, логотипах и постерах. Поэтому подобрать нужный не составит большого труда.
На сайт back to menu ↑ back to menu ↑
Как определить шрифт на кириллице
Определяем кириллический текст
Поиск шрифтов, основанных на латинице, уже набрал достаточные обороты и это неудивительно, так как латинский алфавит является основой письменности современного английского языка и других языков германской группы.
Определить шрифт, который основан на кириллице, по картинке онлайн с помощью вышеописанных сервисов не получится.
В этом случае придется проявить креативность и, например, поискать в базах с соответствующими стилями или использовать крупные поисковики типа Google и Яндекс, если вы ищите вид написания, использованный на каком-нибудь постере.
Также можно воспользоваться помощью дизайнеров на специализированных ресурсах. Например, сайте ФонтМассив.
На сайт back to menu ↑ back to menu ↑
Выводы
Для того, чтобы определить шрифт по картинке онлайн, Интернет предлагает огромный перечень вариантов. Какой из них выбрать ̶ решать вам.
Даже если все способы, которые были описаны в статье, вам не помогли, не отчаивайтесь.
Всегда можно написать создателям сайта, на котором был использован тот или иной тип оформления текста.
Также можно обратиться к дизайнерам на специализированных форумах, где вам, скорее всего, бескорыстно помогут найти понравившийся стиль написания текста, даже если потребуется определить русский шрифт по картинке.
back to menu ↑
ВИДЕО: Как мгновенно распознать и скопировать текст с фото, изображения или картинки? Как распознать текст?
back to menu ↑
Наш Рейтинг
7. 7 Total Score
7 Total Score
Для нас очень важна обратная связь с нашими читателями. Если Вы не согласны с данными оценками, оставьте свой рейтинг в комментариях с аргументацией Вашего выбора. Ваше мнение будет полезно другим пользователям.
Flickr Typeface Identification
7
Как определить шрифт на кириллице
8
Добавить свой отзыв | Отзывы и комментарии
Как распознать текст с фото и картинки онлайн Блог Ивана Кунпана
Как распознать текст с фото, этот вопрос задают многие пользователи. Причины разные, одна из причин — копирование текста с картинки, чтобы не переписывать его вручную. Иногда нам нужно перевести текст с картинки с иностранного языка. Для чтения текста с картинок существуют специальные сервисы и программы в Интернете, которые способны сделать просмотр фото с текстом. Именно их, мы и будем применять для этого дела в этой статье.
к оглавлению ↑
Распознать текст онлайн с картинки в Гугл Диск
Здравствуйте друзья! Распознать текст онлайн с картинки, можно в Гугл Диске.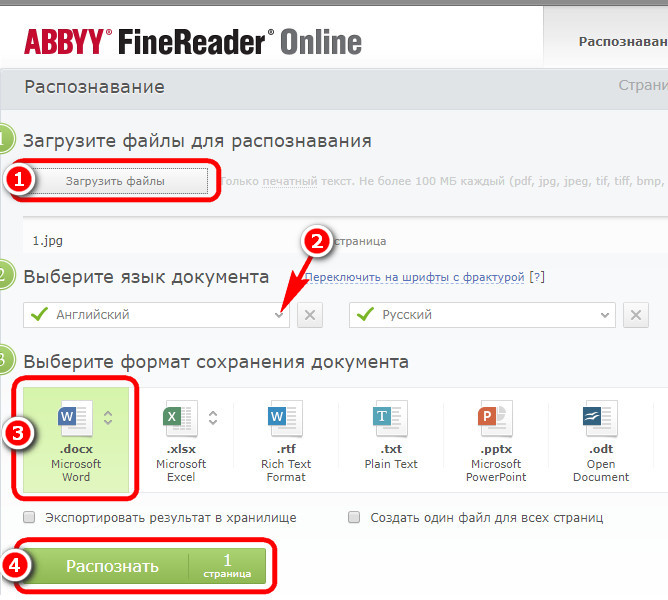 Гугл диск, это сервис по хранению файлов в Интернете, но он так, же имеет много преимуществ. И одно преимущество – это распознавание текста онлайн. Как это делается? Открывайте любой браузер и пишите в нём — Googl Диск. Заходите на этот сайт. Переходите туда, и нажмите на функцию создать, чтобы загрузить файл для точного просмотра.
Гугл диск, это сервис по хранению файлов в Интернете, но он так, же имеет много преимуществ. И одно преимущество – это распознавание текста онлайн. Как это делается? Открывайте любой браузер и пишите в нём — Googl Диск. Заходите на этот сайт. Переходите туда, и нажмите на функцию создать, чтобы загрузить файл для точного просмотра.
Далее, Вы перемещаете на данный ресурс изображение с компьютера, по которому нужно распознать текстс картинки. Открывайте его для просмотра с помощью гугл документов. Если всё получилось, то у Вас должен появиться нормальный текст на самом изображении и внизу после загруженного фото. Загрузка файла занимает некоторое время поэтому, немного подождите, прежде чем всё отобразиться. (Рисунок 1)
А вот как распознать текст с фото, в Яндексе читайте далее.
к оглавлению ↑
Как распознать текст с фото в Яндексе
Поисковик Яндекс, имеет сервис под названием Яндекс-переводчик. Он помогает не только переводить англоязычные слова, но и может распознать текст онлайн с картинки. Данный инструмент, находится на главной странице браузера Яндекс. Перейдите в него, чтобы загрузить картинку. Затем, откройте данное фото в переводчике, для полного просмотра. (Рисунок 2).
Данный инструмент, находится на главной странице браузера Яндекс. Перейдите в него, чтобы загрузить картинку. Затем, откройте данное фото в переводчике, для полного просмотра. (Рисунок 2).
После чего у Вас должен появиться текст, как на русском языке, так и английском. Данные сервисы, помогают разобраться с вопросом, как распознать текст с фото. Теперь, перейдём к программам, если сервисы Вам не помогли.
к оглавлению ↑
Программы для распознавания текста с картинки
Программа для распознавания текста с картинки, тоже ничем не хуже указанных выше сервисов. Они выполняют свою работу, эффективно и качественно, делая любые картинки с текстами годными для чтения. Как их использовать? Рассмотрим две программы, которые Вам помогут сделать картинку читаемой:
- Fine Reader. Данная программа, была специально создана для того чтобы распознавать текст с картинки. Работает она аналогичным образом, как и сервисы. Но, с помощью неё, можно сохранять тексты с картинок, в различные виды документов. Например, ПДФ, Ворд и так далее. Она имеет платная, и поэтому не весь функционал у Вас будет доступен.
- Scan Adobe. Это программное средство умеет определять не только обычные картинки, но и целый снимок камеры. Она сохраняет все переделанные изображения только в формат PDF.
 Например, ПДФ, Ворд и так далее. Она имеет платная, и поэтому не весь функционал у Вас будет доступен.
Например, ПДФ, Ворд и так далее. Она имеет платная, и поэтому не весь функционал у Вас будет доступен.В Интернете есть много подобных программ, но эти пользуются большим спросом и им доверяют уже много лет.
к оглавлению ↑
Заключение
В этой статье, была дана информация о том, как распознать текст с фото. Данный материал пригодиться и тем, кто зарабатывает через Интернет. Ведь, с приходом опыта, приходиться использовать много инструментов, которые иногда упрощают работу в сети. Удачного Вам распознавания текста!
С Уважением, Иван Кунпан.
P.S.
Для более удобного использования сервисов по распознаванию картинок, рекомендую прочитать статьи (Как пользоваться Яндекс диском, Облако Гугл диск).
Просмотров: 658
сервисы для онлайн-сканирования, программы и правила работы с ними
С учётом переезда большинства информации, в том числе художественной и специальной литературы, в интернет, появилась необходимо в распознавании текста: скачать книгу не всегда возможно, а копировать фрагмент приходится через цитирования.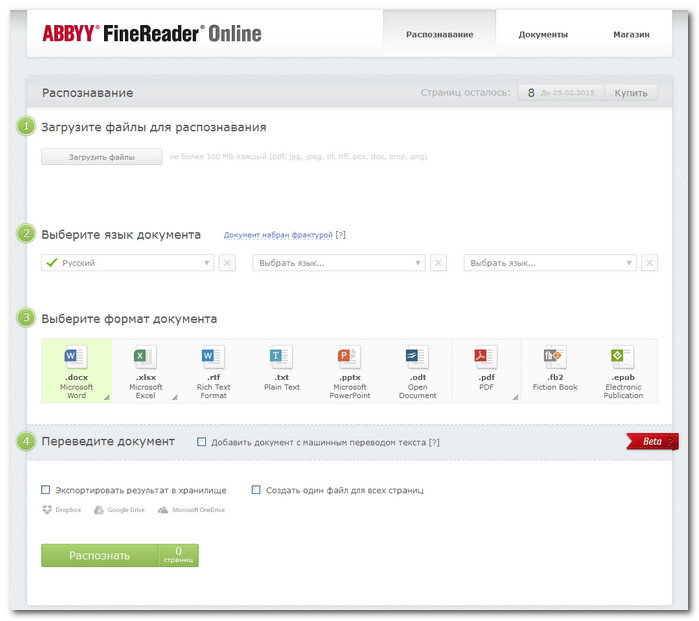 Современные люди фотографируют нужные фрагменты, и чтобы не переписывать все от руки, были созданы специальные программы для распознавания текста.
Современные люди фотографируют нужные фрагменты, и чтобы не переписывать все от руки, были созданы специальные программы для распознавания текста.
Хорошие сервисы на бесплатной основе
Первый сервис — это Диск Гугл. Необходимо зарегистрироваться в браузере. Если пользователь имеет отношение к ведению блока на этом сервисе, ведению ютуб канала, то у него уже есть аккаунт.
Сервис позволяет распознавать изображения разных форматов, текстовые варианты. Главное условие — размер файла не может превышать 2 МБ.
Если для распознавания берётся текст в PDF, то система обработает только первые десять. Сохраняется работа в вордовском документе, блокноте, пдф-формате.
Второй сервис — i 2 OCR. Пользователю также придётся пройти регистрацию. Программа распознает следующие форматы:
Сервис позволяет загружать документы до 10 МБ. Результат преобразовывается в текстовый файл формата DOC.
Результат преобразовывается в текстовый файл формата DOC.
Третий сервис — OCR CONVERT. Пользователю предоставляются услуги по распознаванию файлов на бесплатной основе и без регистрации. Поддерживаются различные форматы изображения. Результат сохраняется в виде интернет-ссылки, которая имеет расширение TXT. Пользователь может скопировать результат и вставить в любой файл. На сервисе можно загружать одновременно пять документов, которые не превышают 5 МБ.
Четвёртый сервис — ONLINE OCR. Пользователю не нужно регистрироваться и платить деньги за работу программы. На сервисе можно распознать 15 изображений за час. Файлы принимаются разных форматов. Результат сохраняется в вордовском, текстовом формате, а также в таблице. Минус сервиса — постоянная капча во время работы. Для распознавания доступно 32 языка
Пятый сервис — OcrOnline. Разработчики рекомендуют, чтобы изображения были в высоком качестве, формата JPG. Также можно использовать и другие форматы. Минус сервиса — за одну неделю распознаётся только 5 страниц.
Минус сервиса — за одну неделю распознаётся только 5 страниц.
Для расширения возможностей необходимо пройти регистрацию на сайте и заплатить символическую сумму. Результат работы сохраняется в различных текстовых форматах.
Программа FineReader
Файн ридер — это программа по оцифровке документов, разработанная компанией ABBYY. Какие услуги предоставляет компания:
- Распознавание в онлайн-режиме. При помощи официальной страницы пользователям доступны преобразования сканов и PDF -форматов в текстовые варианты.
- Сканер текста при помощи мобильного приложения. Компания предоставляет программу и для мобильных устройств, с помощью которой можно преобразовать файл в текстовый документ.
- Компьютерная программа. С её помощью пользователь может просматривать, редактировать, комментировать документы.

Быстрым способом является оптическое распознавание текста онлайн. Это первый вариант, который предоставляется на сайте. Как это работает:
- На первом этапе нужно загрузить файл. Система принимает отсканированные форматы, фотодокументы в формате PDF. Необходимо отметить те страницы, которые будут обработаны.
- На втором этапе выбирается язык распознавания текста.
- На третьем этапе выбирается формат сохранения результата. На сайте можно выбрать любой текстовый формат.
- На четвёртом этапе необходимо сделать распознавание. Можно объединить страницы документа в один файл.
- На пятом этапе система предоставит файл для скачивания. Есть возможность отправить документы на различные интернет-диски.
Система может распознавать текст не более 100 МБ. Можно загружать несколько файлов одновременно.
Основные возможности:
- Преобразование бумажных документов в текстовые форматы.
- Обработка сканов и фотографий на более чем 190 языках.
- Отправка документов на интернет-диск для хранения в течение 14 дней.
- Возможность скачивания программ для мобильных устройств и компьютера.
Сайт Convertio
Ещё одним способом распознавания текстов онлайн является сервис Convertio. Пользователь может бесплатно и без регистрации распознать 10 страниц, для увеличения количества придётся пройти регистрацию на сайте. Процедура распознавания текста:
- Выбрать файл. При помощи красной кнопки необходимо выбрать способ загрузки файла: с компьютера, ссылка интернета, Диск Гугл, из Dropbox.
- Выбрать язык. Есть четыре строки: для главного языка и три строки для дополнительного.
- Выбрать формат. Система предоставляет более пяти форматов.
- Ввести капчу.
- Выбрать вариант для сохранения результата.
- Преобразовать.

После чего можно скачать файл на компьютер или на интернет-диск.
Оцифровка текста с изображения
Первый сервис для сканирования текста с изображения — это IMG Online. Программа занимается опознаванием изображения в разных форматах — BMP, GIF, JPEG, PNG, TIFF.
Порядок действий:
- Выбрать файл для загрузки.
- Настроить язык для обработки. Выбирается основной язык из списка. Если на изображении есть не только русские слова, то следует выбирать дополнительный язык для обработки. Если указаны только символы основного языка, нет надобности устанавливать дополнительные языки.
- Сделать дополнительные настройки. Необходимо выбрать предварительную оптимизацию фото и улучшение скана документа. Если отсканированный формат качественный, то галочку на втором пункте можно и не ставить.
- Выбрать программу для распознавания текста.
- Нажать на ок.
Обработка данных длится около 20−60 секунд, после чего программа выдаст результат работы, который можно сохранить в удобном месте.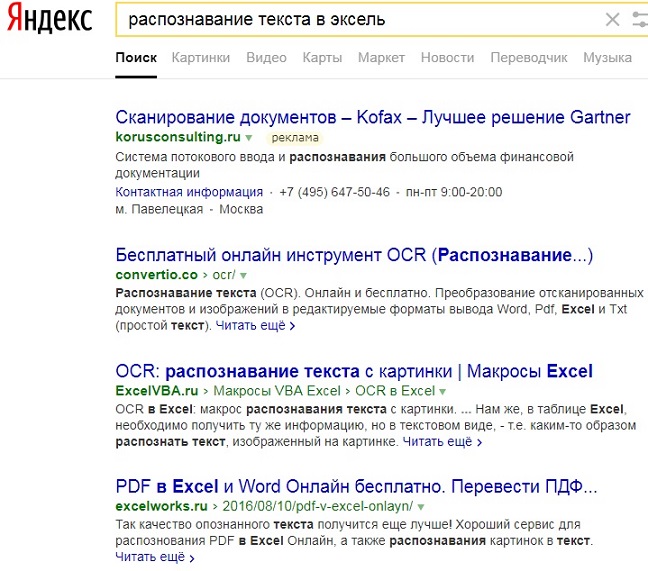
Ещё одним сервисом, который распознает текст с изображения, является Free online Ocr. На русский язык интернет-страница переводится автоматически. Распознаватель предоставляется бесплатно, также не нужна регистрация от пользователя. Порядок работы идентичный: необходимо загрузить файл с компьютера или ввести адрес сайта, выбрать язык и нажать на «Старт». После этого пользователю будет доступен файл для скачивания.
Можно воспользоваться сервисом NewOCR. Пользователю не нужно проходить регистрацию, предоставляется неограниченное количество загрузок. Обратить внимание необходимо и на cuneiform. Её нужно скачать напрямую или через торрент. Программа производит считывание текста со скриншотов.
Сервисов для распознавания текста достаточно. Работа с ними примерно одинаковая — загрузить файл, выбрать язык и формат полученного текста, скачать результат. С этой целью и нужны такие программы.
Originally posted 2018-04-07 11:51:15.
Приложения для распознавания по фото и изображениям
Сейчас уже существует довольно много мобильных приложений, которые распознают фотографии для получения некоторой полезной информации о людях или объёктах на нём. Одно из таких приложений – Facer, показывает на кого из знаменитостей вы похожи, используя алгоритмы на основе нейронных сетей.
Одно из таких приложений – Facer, показывает на кого из знаменитостей вы похожи, используя алгоритмы на основе нейронных сетей.
Платформа: Android
Цена: Бесплатно
Платформа: iOS
Цена: Бесплатно
Загружаете фото лица крупным планом и через пару секунд вы видите трёх знаменитостей, на которых вы похожи, с указанием процента сходства. Среди похожих на себя звёзд можно встретить российских и зарубежных музыкантов, актёров, блогеров или спортсменов. Приложение Facer можно скачать по ссылкам: на Android и iOS.
Приложение Facer можно скачать по ссылкам: на Android и iOS.
У компании Яндекс тоже есть функции распознавания изображений, они встроены в их голосового помощника. Алиса научилась искать информацию по фотографиям с камеры или любым другим картинкам, которые вы ей отправите. На основе загруженного изображения помощник может сделать некоторые полезные действия. Эти новыми функциями можно воспользоваться в приложении Яндекс и Яндекс.Браузер.
Где скачать Алису с поиском по картинкам
Голосовой ассистент Алиса встроен в приложение под названием «Яндекс». Скачать приложение для Android и iOS можно по этим ссылкам:
Платформа: Android
Цена: Бесплатно
Платформа: iOS
Цена: Бесплатно
Как включить поиск по картинкам в Алисе
- Чтобы открыть Алису нажимаем на красный значок приложения «Яндекс».
- Первый способ открыть функцию распознавания изображений: нажимаем на серый значок фотоаппарата с лупой в поисковой строке и переходим к шагу 4. Второй способ: нажимаем на фиолетовый значок Алисы или говорим «Привет, Алиса!» если у вас включена голосовая активация.
- Откроется диалог (чат) с Алисой. Нужно дать команду Алисе «Распознай изображение» или «Сделай фото». Также вы можете нажать на серый значок фотоаппарата с лупой.
- Приложение попросит доступ к камере вашего мобильного устройства. Нажимаем «Разрешить».
- Откроется режим съёмки. Здесь вы можете загрузить изображение из вашей галлереи или сделать новый снимок прямо сейчас. Нажмите на фиолетовый круг, чтобы сделать снимок.
- Алиса распознает объект на изображении.
- Давайте попробуем загрузить фотографию из памяти, т.е. галереи вашего iPhone или Android. Нажимаем на иконку с фотографией.
- Алиса попросит доступ к вашим фотографиям. Нажимаем «Разрешить».
- Выбираем фотографию.
- Через некоторое время фотография загрузится на сервера Яндекса и Алиса вам скажет, на что похоже загруженное изображение. В нашем случае мы загрузили фотографию умной колонки Amazon Echo Dot, и Алиса её успешно распознала.

Возможности Алисы по распознаванию изображений и список команд
Помимо общей команды «сделай фото», Алисе можно дать более точную команду по распознаванию объекта. Алиса умеет делать следующие операции с изображениями по соответствующим командам:
Узнать знаменитость по фото
- Кто на фотографии?
- Что за знаменитость на фотографии?
Алиса распознаёт фото знаменитых людей. Мы загрузили изображение актёра Константина Хабенского и Алиса успешно распознала его.
Распознать надпись или текст и перевести его
- Распознай текст
- Распознай и переведи надпись
Вы можете загрузить фотографию с текстом и Алиса распознает его и даже поможет его перевести. Для того, чтобы распознать и перевести текст с помощью Алисы необходимо:
Для того, чтобы распознать и перевести текст с помощью Алисы необходимо:
— Загрузить фото с текстом.
— Прокрутить вниз.
— Нажать «Найти и перевести текст».
— Откроется распознанный текст. Нажимаем «Перевести».
— Откроется Яндекс.Переводчик с переведённым текстом.
Узнать марку и модель автомобиля
- Определи марку автомобиля
- Распознай модель автомобиля
Алиса умеет определять марки автомобилей. Например, она без труда распознаёт новый автомобиль Nissan X-Trail, в который встроена мультимедийная система Яндекс.Авто с Алисой и Яндекс.Навигатором.
Узнать породу животного
- Распознай животное
- Определи породу собаки
Алиса умеет распознавать животных. Например, Алиса распознала не только, что на фото собака, но и точно определила породу Лабрадор по фото.
Узнать вид растения
- Определи вид растения
- Распознай растение
Если вы встретили экзотическое растение, Алиса поможет вам узнать его название.
Узнать автора и название картины
- Распознай картину
- Определи что за картина
Если вы увидели картину и хотите узнать её название, автора и описание, просто попросите Алису вам помочь. Картину «Утро в сосновом лесу» художника Ивана Ивановича Шишкина Алиса определяет моментально.
Найти предмет в Яндекс.Маркет
- Определи товар
- Найди товар
Если вы увидите интересный предмет, который вы не прочь были бы приобрести – вы можете попросить Алису найти похожие на него товары. Найденный товар вы можете открыть на Яндекс Маркете и там прочитать его характеристики, или сразу заказать.
Распознать QR-код
- Определи Кью Эр код
- Распознай Кью Эр код
Алиса пока не так быстро и качественно распознаёт QR коды, нам потребовалось несколько попыток, чтобы успешно распознать QR код.
Попробуйте распознать с помощью Алисы какое-нибудь изображение и напишите о своём опыте и впечатлениях в комментариях.
Яндекс постоянно добавляет новые команды для Алисы. Мы сделали приложение со справкой по командам, которое регулярно обновляем. Установив это приложение, у вас всегда будет под рукой самый актуальный список команд:
Платформа: Android
Цена: Бесплатно
Платформа: iOS
Цена: Бесплатно
Задавайте вопросы в комментариях, подписывайтесь на YouTube канал и Яндекс Дзен Канал, чтобы не пропустить статьи и видео об Алисе.
Поделиться в соц. сетях
Подписывайтесь на наши соц.сети, чтобы не пропустить новые видео, новости и статьи.
Похожие статьи
Как распознать текст онлайн с картинки?
Довольно часто на прошлой работе мне приходилось показывать пользователям как распознать текст онлайн с картинки. Документы, договора, счета, справки, свидетельства и многое другое… Как минимум раз десять в месяц, этим занимались.
Покупать специальное ПО для распознавания текста никто конечно не собирался. Но и брать на себя работу по набору текста я тоже не имел желания (а именно мне это и поручали, так как печатал быстрее всех). Одно время пользовался пиратской версией FineReader, но боялся что могут обнаружить при проверке, вся ответственность все таки на мне.Поэтому, было принято решение искать онлайн распознаватели и обучить пользователей распознавать текст с картинок своими силами. Благо есть такие сервисы. как платные так и бесплатные.
И так приступим, первым я вам покажу сайт onlineocr.ru с помощью которого можно распознать текст абсолютно бесплатно. Переходим на сайт, жмем “Обзор“, выбираем нужное изображение и жмем “Загрузить“. После этого вы увидите загруженный файл (обведен красным)
Теперь вам нужно выбрать язык распознавания документа и ввести цифры с картинки. После чего нажать на кнопку “Распознать текст“.
После успешного распознания изображения, в поле текста вы увидите распознанный текст, а так же можете сохранить документ в формате Word
Открыв распознанный документ в Word, вы можете его проверить и при необходимости отредактировать
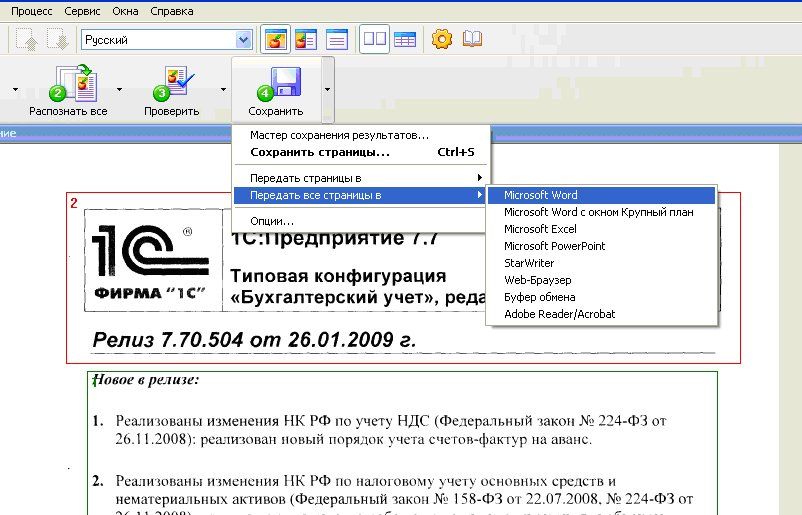
Второй сайт на котором можно распознать текст с изображения – FineReader Online. Всем хорош этот сайт, и дизайн отличный, и скорость распознавания на уровне, но без минусов не обошлось. Единственный минус – сервис платный!
Но с другой стороны, за удобство и качество нужно платить. В бесплатном режиме можно распознать 60 листов, Если вы не пользуетесь подобными инструментами часто, тогда этот вариант для вас будет самым лучшим.
Перейдя на сайт, вам в первую очередь нужно зарегистрироваться. После переходите на страницу распознавания и выбирайте изображение для загрузки. Принцип работы такой же, как и в вышеописанном сервисе (загружаете, выбираете язык распознавания, формат на выходе и жмете “Распознать”).
После распознания, вас перекинет на страницу с документами, которые были распознаны ранее (если таковы были). Для загрузки документа, просто нажмите на нем. Качество распознавания с помощью этого ресурса, на уровень выше, оно понятно, ведь FineReader является флагманом в этой сфере
Интересные статьи по теме:
[Обновлено] 10 лучших инструментов распознавания изображений
Получите бесплатную демонстрацию распознавания изображений!
Для брендов это означает доступ к большему количеству данных, чем когда-либо прежде, особенно данных на основе изображений. Пользователи социальных сетей полностью приняли концепцию обмена фотографиями вместо текста или сопроводительного текста.
Свидетельство того факта, что «картинка стоит тысячи слов» в реальной жизни, можно увидеть в растущей популярности платформ социальных сетей, основанных на фотографиях, таких как Snapchat.Во втором квартале 2020 года у Snapchat было 238 миллионов активных пользователей по всему миру. По сравнению с 203 миллионами DAU во всем мире в том же квартале 2019 года.
Очень важна способность выявлять, анализировать и использовать эту растущую тенденцию. Поскольку в будущем цифрового маркетинга будут доминировать визуальные данные, технология распознавания изображений должна существовать. Без него бренды упускают массу ценных данных.
В этом посте я собираюсь перечислить несколько замечательных инструментов распознавания изображений . У них разные функции, возможности и цены.Я включил проприетарную технологию распознавания изображений Talkwalker — подробности позже — потому что ИМХО она лучшая. Уровни точности и простота использования гарантируют, что он выделится из толпы.
За 30 дней логотип DHL был обнаружен почти 10 000 раз.
На изображении выше показано огромное количество логотипов DHL, которые публикуются или просматриваются в Интернете. От маркетинговых кампаний DHL до рекламных баннеров на гоночных трассах.
В этом случае фильтр использовался только для поиска изображений, содержащих ссылку на F1 / Формулу 1 в тексте.Почти 18% — 1800 упоминаний — включали ссылку на F1 / Формулу 1. Из этих изображений только 8 ссылались на DHL.
Значение?
Логотип DHL тесно связан с F1. Эти впечатления — 1800 упоминаний — были бы упущены, если бы отслеживался только текст.
Какая трата!
Скачать сравнительную таблицу средств распознавания изображений!
Что такое распознавание изображений?
Хорошо, распознавание изображений . Компьютер, использующий свои «глаза», как вы бы использовали свои.
Ознакомьтесь с разделом «Что такое анализ изображений?», Если вам нужна более подробная информация.
Распознавание изображений — это создание нейронной сети, которая обрабатывает все пиксели, составляющие изображение. Эти сети представлены кучей изображений уже идентифицированных объектов, чтобы сеть могла изучать и распознавать похожие объекты.
Например, AI будет показан тысячи изображений обуви. ИИ узнает, какие изображения обуви должны содержать.Покажите изображение слона, и искусственный интеллект сравнит все пиксели на изображении слона со всеми изображениями обуви, которые он видел. Не найдя совпадений или их мало, ИИ распознал бы в объекте слона.
Вот примеры инструментов, о которых вы, возможно, слышали, но не осознавали, используемую технологию распознавания изображений …
- Сравнение цен — сделайте снимок продукта, который вы хотите купить, и используйте такое приложение, как Google Shopper, чтобы узнать, какие магазины поблизости взимают плату за
- Беспилотные автомобили — использование компьютерного зрения и распознавания изображений для идентификации пешеходов, дорожных знаков и других транспортных средств
- Поиск изображений — укажите в Google изображение или URL-адрес, и поисковая система покажет вам, где изображение было использовано в Интернете, одновременно найдя похожие
- Какой сериал? — такое приложение, как израильское TVTak — Shazam of TV — определяет шоу, которое вы смотрите, с помощью технологии распознавания видео или изображений в вашем iPhone
- Это собака или нет? — Not Hotdog, приложение для распознавания изображений, без которого не обойтись… если вам абсолютно необходимо идентифицировать … хот-дог
Почему мне следует использовать распознавание изображений?
Данные, полученные с помощью инструментов распознавания изображений , можно использовать по-разному. От понимания ваших клиентов и их интересов до создания целевой рекламы для определенных групп. Представьте себе возможность размещать рекламу в Facebook на основе индивидуальных предпочтений и увлечений людей.
Просто, ВАУ!
Любители собак могут увидеть рекламу самых модных новых угощений для собак, а любители кошек могут получить рекомендации по выбору лучших кормов для кошек.
Инструменты распознавания изображений помогут вам лучше понять свою клиентскую базу. Оцените, что поможет вам выйти на новый рынок, убедитесь, что никто не злоупотребляет вашим логотипом, и проанализируйте истинный охват вашего маркетинга. Он может дать вам представление о потребителях в цифровом формате, в котором вы отчаянно нуждаетесь, и откроет вам глаза на новые возможности, которые вы могли так легко упустить. Технология распознавания изображений — это, по сути, компас, необходимый каждому бизнесу для навигации в сложной местности современного цифрового мира.
Этот пост даст вам некоторое представление о различных доступных инструментах распознавания изображений и поможет вам решить, какой из них лучше всего подходит для вашего бизнеса и вашего бренда.
Что умеют инструменты распознавания изображений?
Инструменты распознавания изображений могут распознавать, анализировать и интерпретировать изображения. Намного эффективнее, чем вы и ваша команда. Они сэкономят вам время и деньги. Инструменты распознавания изображений могут сортировать бесчисленное количество изображений и быстро возвращать данные, уникальные для вашего бизнеса.
Я составил список из 10 лучших инструментов для распознавания изображений и того, что их отличает. Взглянем!
Talkwalker | Запатентованная технология распознавания изображений
Технология распознавания изображений Talkwalker позволяет выполнять поиск в базе данных, содержащей более 30 000 логотипов, а также сцен и объектов. Это означает, что у вас есть доступ практически к любой информации о компании, которая может вам понадобиться. Помимо огромного объема изображений, которые он может распознать, он также использует адаптируемую запатентованную технологию для одновременного анализа текста и изображений.
Получите мою бесплатную демонстрацию распознавания изображений!
От максимального увеличения охвата вашей рекламы до получения уведомлений каждый раз, когда кто-то публикует о вашем бренде, запатентованная технология распознавания изображений Talkwalker — это инструмент, который дополнит ваши существующие знания о вашем бренде и поможет вам использовать эти знания в процессе работы. продолжайте развивать свой бизнес.
Роооооней !!!
Распознавание изображений обнаружит логотипы Martini, Texaco, Michelin, несмотря на отсутствие упоминания.
Это означает, что рентабельность инвестиций от спонсорства может быть точно измерена.
Вы нашли идеальное изображение, но оно не того размера. Вам нужно изображение, похожее на то, что у вас есть.
Вам нужен поиск обратного изображения Google!
Как следует из названия, этот инструмент распознавания изображений позволяет загружать изображение и выполнять поиск по нему.
Вы ищете изображение, а не слова. Круто!
Самое замечательное в этом инструменте то, что он так же интуитивно понятен, как и типичный текстовый поиск Google, и сохраняет возможности Google.
Примеры того, как вы могли бы использовать этот инструмент, включают …
- Вам нужно найти источник изображения, чтобы вы могли правильно указать его
- Поиск случаев ненадлежащего использования принадлежащего вам изображения — нарушение прав на товарный знак
Если изображение существует в Интернете, поиск обратного изображения Google поможет вам найти то, что вы ищете.
Вставьте URL-адрес или загрузите изображение.
Загрузка приведенного выше снимка экрана с F1 приносит кучу данных распознавания изображений.
Google API Cloud Vision позволяет анализировать изображения разными способами. От распознавания откровенного содержания до обнаружения эмоциональных сигналов на лицах. Обладая таким широким набором функций, это универсальный инструмент, который можно адаптировать к вашим конкретным потребностям.
Помимо своей гибкости, этот инструмент распознавания изображений несет в себе мощь Google и все, что следует из названия. Это означает, что это один из самых мощных инструментов, который вы найдете.
Инструмент распознавания изображений с мощью Google!
Еще одно громкое имя в веб-мире, Amazon предлагает инструмент для распознавания изображений с уникальными предложениями.
Amazon Rekognition не только анализирует неподвижные изображения, но и может анализировать видео.
Это высокотехнологичная программа, способная …
- Обнаружение объектов, сцен и действий — игра в футбол, велосипед, пляж, город и т. Д.
- Распознавание лиц — идентифицировать человека на фото или видео
- Анализ лица — улыбка, глаза открыты, очки, борода, пол
- Путь — e.грамм. движение спортсменов во время игры для анализа после игры
- Обнаружение небезопасного содержимого — определение небезопасного или неприемлемого содержимого в изображениях и видео
- Распознавание знаменитостей — определите звезд из своей библиотеки видео и изображений
- Текст в изображениях — обнаружение и распознавание текста, такого как названия улиц, подписи, названия продуктов, номера автомобилей
Amazon заверяет пользователей, что постоянно обучающийся инструмент распознавания изображений интуитивно понятен для интеграции и использования.
Преимущество Amazon Rekognition в том, что вы платите только за данные, которые используете. Это означает, что минимальных сборов нет. Это позволяет вам использовать программу так, как вы считаете нужным, и получать доступ ко всем преимуществам мощной системы, не нарушая при этом денег.
Обнаружение небезопасного контента и распознавание знаменитостей.
Объекты и сцены, распознавание лиц и анализ, отслеживание людей.
Clarifai | Поиск похожих изображений
Этот инструмент распознавания изображений позволяет искать изображения, используя другие изображения.Представьте себе потенциальное использование?
Например, вы можете захотеть найти изображения на основе сходства, а слова могут увести вас далеко.
Я повторю еще раз — картинка стоит тысячи слов, если не больше.
Как бы вы ни пытались описать изображение для поисковой машины, вы, скорее всего, никогда не поймете, что именно в изображении вы хотите, чтобы эта машина нашла. Инструмент распознавания изображений Clarifai сделает всю работу за вас. Это поможет вам найти похожие изображения, просто выбрав фотографии и указав инструменту, что делать.
Инструмент анализирует фото и распознает млекопитающих, диких животных, улицу, траву, животных, стадо, слоновую кость … слона!
Визуальный поиск, рекомендации и обнаружение, аналитика клиентов.
LogoGrab | Распознавание логотипа и знака
Имя, которое одновременно броское и информативное, служит мостом для компаний, желающих перейти в следующую эру маркетинга и взаимодействия с потребителями. LogoGrab знает свою нишу и хорошо ее заполняет, начиная с запатентованного механизма адаптивного обучения и кончая эталоном самого быстрого и точного инструмента на рынке.
Разработанный для технологических компаний, рекламных агентств и брендов, LogoGrab ориентирован на монетизацию и взаимодействие на мобильных платформах. Это делает его идеальным инструментом для тех, кто хочет получить максимальную отдачу от своего присутствия в социальных сетях.
LogoGrab может похвастаться тем, что их инструмент легко интегрируется в большинство существующих платформ. Это означает, что переход к LogoGrab и ценной информации, которую он может предоставить, будет плавным и безболезненным — еще одна особенность уже отличного инструмента.
Встраивайте обнаружение логотипа и SKU для изображений и видео в любой проект.
Получите бесплатную демонстрацию распознавания изображений!
IBM — гигант в мире технологий — находится в авангарде разработки передовых технологий, которые не только делают современный мир лучше, но и подталкивают его к новым возможностям.
Его инструменты распознавания изображений — одни из лучших. Одним из основных преимуществ IBM Image Detection является его обучаемость. Другими словами, IBM предоставляет платформу с широкими возможностями настройки, которую можно настроить для выполнения практически любой задачи, которая вам нужна.
Как это круто? !!
Анализируйте изображения сцен, объектов, лиц, цветов, продуктов и другого содержимого.
Инструмент распознавания изображений идентифицирует бренды на картинке.
Imagga | Catorgorize images
Инструмент распознавания изображений Imagga предоставляет несколько автоматических опций для сортировки, организации и отображения ваших изображений на основе категории, цвета, тега, которые также можно автоматизировать, или пользовательского ввода.Это означает, что у вас есть несколько встроенных опций, но вы также можете развиваться для удовлетворения ваших конкретных потребностей. Двойственность Imagga позволяет ему соответствовать любым обстоятельствам и уровню квалификации.
Если вам нужен способ упорядочить вещи, не тратя драгоценное время компании, или вам нужно убедиться, что на вашей странице не отображается явный контент, у Imagga есть инструмент для вас, а если нет, вы можете его создать!
Универсальные решения для распознавания изображений для разработчиков и предприятий.
CloudSight | распознать, классифицировать, понять
В то время как некоторые инструменты ориентированы на узкоспециализированное выполнение и приложение, другие стараются максимально повысить удобство, сохраняя при этом впечатляющую функциональность.CloudSight идеально подходит для тех, кто ищет простой в использовании и самоописанный «легкий» инструмент.
Этот инструмент распознавания изображений упрощает процесс распознавания, категоризации и понимания. Это позволяет вам практически полностью отказаться от использования визуальных элементов.
Это может означать …
- Разрешение программе писать естественно звучащую подпись
- Простая интеграция изображений в ваше торговое онлайн-пространство
- Раскрытие ключевого материала в вашем видеоконтенте
CloudSight интуитивно понятен, без ущерба для функциональности, которую можно ожидать от первоклассного инструмента распознавания изображений.
Отлично!
Дважды круто!
EyeEm | Оцените эстетический рейтинг фото
Для тех из вас, кто любит фотографию, осознавая ее потенциал в мире, основанном на изображениях, распознавание изображений EyeEm является идеальным инструментом. Специально для тех, кто использует социальные сети.
Благодаря автоматическим тегам и подписям это замечательно, если вы хотите использовать теги, которые не только лучше всего подходят для ваших изображений, но и способствуют увеличению экспозиции.EyeEm выходит за рамки этого, используя распознавание изображений для оценки эстетического рейтинга фотографии.
Звучит круто, не так ли?
Это полезно для тех, кто основывает свой успех на фотографии и взаимодействии с публикациями. Оценка фотографий на основе их эстетической привлекательности может помочь вам выбрать наилучшее изображение, которое максимально привлечет внимание.
Инструмент можно обучить распознавать ваш уникальный стиль, чтобы ваши сообщения сохраняли целостную эстетику, которую вы ищете при создании страницы на основе изображений.
Инструмент распознавания изображений, который оценивает фотографии на основе их эстетической привлекательности.
Ваш вывод из этого списка заключается в том, что независимо от того, что вы хотите от инструмента распознавания изображений, есть идеальный инструмент для вас и вашего бренда.
Технология распознавания изображений принесет пользу любому бизнесу, независимо от размера, продукта или рынка. От мегакорпораций, стремящихся к максимальной узнаваемости бренда, до независимых фотографов, желающих расширить свой рынок с помощью платформ социальных сетей.Распознавание изображений — ключ к навигации в нашем информационном мире.
Что выделит вас из массы данных? Что делает ваш бренд лучше, чем у конкурентов? Как лучше всего определить идеальный рынок для того, что вы предлагаете, а затем целенаправленно и эффективно выйти на него? Как вы можете гарантировать, что идентичность вашего бренда не используется и не злоупотребляется?
Ответ — распознавание изображений.
Предварительно разработанный инструмент, который сделает за вас охоту. позволяя вам тратить больше времени на развитие вашего бизнеса.Индивидуальная программа, дающая представление о потребителях вашего рынка в цифровом формате — есть вариант для вас. В мире бесконечного количества информации инструменты распознавания изображений разбирают все это и открывают двери безграничным возможностям. Нажмите ниже и найдите свой логотип в Интернете!
Франсуа является членом команды Talkwalker Marketing.
Франсуа — творческий человек, который любит делиться тем, что узнает. Его любимые темы — SEO, SEA и SMA. Он любит посмеяться и пошутить, и он не может начать день без чашки крепкого кофе.
3 шага к использованию распознавания текста изображения
2020-09-09 18:00:50 • Отправлено по адресу: OCR Solution • Проверенные решения
Распознавание изображений — одна из лучших технологий, которая может быть использована для извлечения данных из изображений.Распознавание текста изображения гарантирует получение наилучшего результата, и пользователь легко извлекает данные. Использование онлайн-технологий распознавания изображений не рекомендуется, поскольку это не дает необходимого результата и может также привести к проблемам с безопасностью. PDFelement — одна из лучших программ для распознавания китайских символов с изображения. Он не только прост в использовании, но и обеспечивает самые современные результаты.
Распознавание текста изображения с помощью PDFelement
В этом отношении вам необходимо выполнить следующие действия.
Шаг 1. Откройте изображение
Перетащите файл изображения в программу. Вы можете использовать 5 различных способов, чтобы убедиться, что изображение открыто. Это самый простой способ открыть файл изображения.
Шаг 2. Включите OCR для распознавания текста изображения
Нажмите кнопку «Редактировать»> «OCR», чтобы выбрать режим OCR, и нажмите кнопку «Изменить язык», чтобы выбрать язык содержимого изображения для его выполнения.OCR распознает текстовое содержимое вашего изображения, чтобы сделать его редактируемым.
Шаг 3. Редактировать текст
Новый созданный файл можно полностью редактировать после выполнения OCR. Нажмите кнопку «Изменить» в верхнем левом углу, чтобы отредактировать текст напрямую. Узнайте, как редактировать PDF-файлы здесь.
Лучшее программное обеспечение для распознавания изображений
PDFelement — одна из программ, которые настоятельно рекомендуются для управления PDF-файлами.Для распознавания символов с изображения настоятельно рекомендуется эта программа. Он имеет лучший интерфейс, а также позволяет пользователям преодолевать проблемы, связанные с распознаванием текста изображения. В программе также есть соответствующие технологии, связанные с оптическим распознаванием изображений, которое лучше всего подходит для OCR. PDFelement — одна из самых простых в использовании программ для распознавания изображений OCR. PDFelement — одна из лучших и наиболее эффективных программ, которая настоятельно рекомендуется для всех задач, связанных с PDF.
PDFelement — одна из немногих программ, которые позволяют пользователям решить эту проблему. Это позволит пользователям преодолеть проблемы, которые представляют другие программы. От OCR до других функций программы есть много преимуществ программы. Это также позволяет пользователям читать и управлять файлами PDF, которые соответствуют требованиям. Есть много мощных функций программы, таких как преобразование и подпись файлов PDF. Вы также можете добавлять аннотации к файлам PDF, что упрощает их разделение.Он также доступен для Mac, что еще больше увеличивает его охват, и больше пользователей используют эту программу.
Вы можете приобрести программу для одного, и это окажется очень экономичным способом для ваших файлов PDF. Есть много ресурсов, которые вы можете использовать для понимания программы. Это также один из способов полностью понять функциональность PDF. Для начинающих пользователей эта программа является благом, поскольку позволяет им работать с ней так легко, как никто другой.
- Для большинства распространенных задач, связанных с PDF, вы можете использовать PDFelement.Это значит, что для открытия, сохранения и разметки PDF вы можете использовать эту программу.
- Графические элементы PDF также могут быть изменены с помощью этой программы. Такие элементы можно добавлять, изменять, вращать и изменять размер с помощью этой программы.
- PDF-документы также можно изменять с помощью этой программы, что также означает защиту PDF-файлов паролем.
- В программе также есть мощный конвертер, который может преобразовывать формат PDF в HTML, текстовые и графические файлы.
- Программа очень старательная и гарантирует, что документы PDF одобрены и подписаны в цифровом виде.
Советы: знания о распознавании изображений
Это одна из лучших идей, которые можно встроить в программу. Это тот контекст, который позволяет машинам и связанным с ними программам идентифицировать текст или любой другой формат изображения.Такие боты также используются для распознавания текста из онлайн-сервисов изображений, что означает, что вы также можете использовать OCR с онлайн-сервисом. Это своего рода искусственный интеллект, который означает получение точных результатов. С помощью распознавания изображений можно изменить формат редактируемого текста. С такими программами можно полностью сэкономить время.
Это один из лучших способов убедиться, что изображения в наборе данных распознаются. Это один из лучших способов упростить распознавание слова по изображению.Распознаватель текста изображения также экономит время пользователей и позволяет им преодолевать проблемы, которые возникают в обычных программах. Существует полный процесс, который поддерживает глубокое обучение распознаванию изображений. Есть много программ, разработанных исключительно для этой цели. Для изображений оптического распознавания символов глубокое обучение выполняет одну из лучших функций на сегодняшний день. Для систем Брайля разрабатываются методы распознавания букв изображений. Это гарантирует, что слепые получат возможность распознавания данных, а общее управление такими программами станет простым.Механизм глубокого обучения изображений очень прост, и связанная с ним технология также очень проста для понимания.
Есть много применений технологии распознавания изображений. Он используется для создания беспилотных автомобилей и программ, которые могут работать сами по себе. Другая основная терминология, связанная с этой идеей, — это распознавание лиц. Также важно отметить, что технология распознавания изображений находится в стадии дальнейшего развития, так что она может давать рекомендации, основанные на содержании.Специалистов по нейросетям нанимают компании со всего мира. Эти люди будут следить за тем, чтобы общее управление распознаванием изображений осуществлялось таким образом, чтобы программное обеспечение работало безупречно. Эти профессионалы также следят за тем, чтобы сверточная нейронная технология была добавлена в основную систему любой программы, связанной с технологией распознавания изображений.
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Распознавание текста
- Продукты
АВТОМАТИЗАЦИЯ ДЛЯ ВСЕЙ КОРПОРАТИВНОСТИ
Лента новостей
Process Intelligence для точного обзора процессов.Vantage
Платформа, предоставляющая навыки Content IQ, чтобы сделать цифровой персонал умнее.
FlexiCapture
Собирайте полезные данные из любых документов, от структурированных форм и опросов до неструктурированных документов с большим объемом текста.FineReader Server
Разверните серверное решение OCR большого объема для преобразования документов.
Capture2Text
Capture2Text
Содержание
Что такое Capture2Text?
Capture2Text позволяет пользователям быстро распознавать текст на части экрана с помощью
Сочетание клавиш.Полученный текст по умолчанию будет сохранен в буфер обмена.
Концептуальная иллюстрация:
Capture2Text распространяется бесплатно и под лицензией GNU General Public License.
Скачать
Последнюю версию можно найти на странице загрузки Capture2Text, размещенной на SourceForge.
Системные требования
Поддерживаемые операционные системы:
- Windows 7
- Windows 8/8.1
- Windows 10
Примечание. Поддержка Windows XP была прекращена в Capture2Text v4.0.
Как запустить Capture2Text (установка не требуется)
- Распакуйте содержимое ZIP-файла.
- Дважды щелкните файл Capture2Text.exe. Вы должны увидеть значок Capture2Text на
в правом нижнем углу экрана (хотя он может быть скрыт, и в этом случае вы
придется нажать на стрелку «Показать скрытые значки»).
Установка дополнительных языков OCR
По умолчанию Capture2Text поставляется со следующими языками: английский, французский, немецкий, японский, корейский, русский и испанский.
Выполните следующие действия, если вы хотите установить дополнительные языки OCR:
- Загрузите словарь соответствующего языка OCR.
- Откройте файл .zip, который вы только что загрузили, с помощью 7-Zip или аналогичной программы для распаковки.
- Перетащите все файлы, содержащиеся в zip-файле, в папку tessdata:
- Перезапустите Capture2Text.
Поддерживаются следующие языки OCR:
| африкаанс (африкаанс) | греческий (эл. | Гаитянский (шляпа) | Персидский (fas) | ||
| Древнегреческий (grc) | Иврит (heb) | Польский (pol) | |||
| Арабский (ara) | Хинди (хин португальский) | por) | |||
| Ассамский (asm) | Венгерский (hun) | Пушту (pus) | |||
| Азербайджанский (aze) | Исландский (isl) | Румынский (ron) | |||
| Баскский (eus) | Индийский (inc) | Русский (rus) | |||
| Белорусский (bel) | Индонезийский (ind) | Санскрит (san) | |||
| Бенгальский (ben) | сербский (srp) | ||||
| боснийский (bos) | ирландский (gle) | сингальский (sin) | |||
| болгарский (bul) | итальянский (ita) | sl | |||
| Бирманский (mya) | Японский (jpn) | Словенский (slv) | |||
| Каталонский (cat) | Яванский (jav) | Испанский (спа) | |||
| Кебуано (ceb) | Каннада (кан) | Суахили (swa) | |||
| Центральный кхмерский (khm) | Казахский (kaz) | Шведский (swe) | |||
| Чероки | |||||
| Чероки | Сирийский (syr) | ||||
| Китайский — упрощенный (chi_sim) | Корейский (kor) | Тагальский (tgl) | |||
| Китайский — традиционный (chi_tra) | kruukh) tgk) | ||||
| Хорватский (hrv) | Лаосский (lao) | Тамильский (tam) | |||
| Чешский (ces) | Latin (lat) | Telugu (tel) | Danis 9048 h (dan) | латышский (lav) | тайский (tha) |
| голландский (nld) | литовский (lit) | тибетский (bod) | |||
| дзонгха (dzo) | македонский | Тигринья (tir) | |||
| Английский (eng) | Малайский (msa) | Турецкий (tur) | |||
| Эсперанто (epo) | Малаялам (mal) | ||||
| Эстонский (est) | Мальтийский (mlt) | Украинский (ukr) | |||
| Финский (fin) | Marathi (mar) | Urdu (urd) | |||
| Frankish (frk) | Математика / уравнения (equ) | Узбекский (uzb) | |||
| Французский (fra) | Среднеанглийский (1100-1500) (enm) | Вьетнамский (vie) | |||
| Галисийский (glg) | Среднефранцузский (1400-1600) (frm) | Валлийский (cym) | |||
| Грузинский (kat) | Непальский (nep) | Идиш (yid) | |||
| Немецкий (deu) | Норвежский (норвежский) |
Как выполнить стандартное распознавание текста
Выполните следующие действия, чтобы выполнить стандартный захват OCR с помощью окна захвата:
- Поместите указатель мыши в верхний левый угол текста, который нужно распознать.
- Нажмите горячую клавишу OCR (Windows Key + Q), чтобы начать захват OCR.
- Переместите указатель мыши, чтобы изменить размер синего поля захвата над текстом, который нужно OCR. Вы можете удерживать правую кнопку мыши и перетаскивать, чтобы переместить весь блок захвата.
- Снова нажмите горячую клавишу OCR (или щелкните левой кнопкой мыши или нажмите ENTER), чтобы завершить захват OCR.
Текст OCR будет помещен в буфер обмена, и появится всплывающее окно, показывающее захваченный текст (всплывающее окно может быть отключено в настройках).
Как и для всех снимков OCR, вы должны вручную выбрать язык, который вы хотите OCR, в настройках.
Чтобы изменить язык оптического распознавания текста, щелкните правой кнопкой мыши значок Capture2Text на панели задач, выберите параметр «Язык оптического распознавания текста», а затем выберите нужный язык.
Для быстрого переключения между 3 языками используйте клавиши быстрого доступа к языку OCR: Клавиша Windows + 1, Клавиша Windows + 2 и Клавиша Windows + 3. Языки быстрого доступа можно указать в настройках.
Если выбран китайский или японский язык, необходимо указать текст
направление (вертикальное / горизонтальное / авто) с использованием направления текста
горячая клавиша: Windows Key + O. Если выбрано авто, то при
ширина захвата более чем в два раза превышает высоту, в противном случае будет вертикальное
используемый. Направление текста также влияет на то, как фуригана удаляется из японского текста.
(для японского) Capture2Text попытается автоматически удалить фуригану.
Как выполнить оптическое распознавание текста строки
Capture2Text может автоматически захватывать строку текста, ближайшую к указателю мыши.
Выполните следующие действия, чтобы выполнить оптическое распознавание текста строки:
- Наведите указатель мыши на строку текста, которую нужно захватить, или рядом с ней.
- Нажмите горячую клавишу Text Line OCR Capture (Windows Key + E).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR прямой текстовой строки
Capture2Text может автоматически захватывать строку текста, начиная с символа, ближайшего к указателю мыши, и продвигаясь вперед.
Выполните следующие действия для выполнения прямого распознавания текста строки:
- Наведите указатель мыши на символ, с которого нужно начать, или рядом с ним.
- Нажмите горячую клавишу «Прямой текст» OCR Capture (Клавиша Windows + W).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR пузырьков
Capture2Text может автоматически захватывать текст, содержащийся в пузыре речи / мысли комиксов, если пузырек полностью закрыт.
Выполните следующие действия, чтобы выполнить захват OCR в виде пузырьков:
- Поместите указатель мыши в пустую часть пузыря (не на текст).
- Нажмите горячую клавишу «Захват OCR» (Клавиша Windows + S).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как указать активный язык OCR
Чтобы указать активный язык OCR, щелкните правой кнопкой мыши значок в области уведомлений, выберите Язык OCR и выберите языки OCR из списка:
Перевод
Чтобы включить функцию перевода, сначала откройте диалоговое окно настроек (щелкните правой кнопкой мыши значок в области уведомлений и выберите «Настройки… «) и щелкнув вкладку» Перевести «.
Установите флажок «Добавить перевод в буфер обмена», чтобы добавить переведенный текст в буфер обмена с помощью предоставленного разделителя.
Установите флажок «Показать перевод во всплывающем окне», чтобы отображать переведенный текст рядом с текстом OCR во всплывающем окне. Например:.
Каждый установленный язык OCR может быть переведен на другой язык.
Примечание 1. Некоторые языки OCR не поддерживают перевод.Неподдерживаемые языки отображаться не будут.
Примечание 2: Для перевода требуется доступ в Интернет.
Настройки
Щелкните правой кнопкой мыши значок Capture2Text на панели задач в правом нижнем углу экрана, а затем выберите параметр «Настройки …», чтобы открыть диалоговое окно «Настройки». Вы можете навести указатель мыши на многие метки параметров, чтобы отобразить полезную подсказку, объясняющую этот параметр.
На вкладке «Горячие клавиши» можно указать, какие клавиши и модификаторы использовать для каждой горячей клавиши.Чтобы отключить горячую клавишу, выберите «
Текущий язык OCR: укажите используемый активный язык OCR. Вы также можете указать активный язык OCR в меню значка на панели задач.
Quick-Access Languages: языки, используемые для каждой из горячих клавиш быстрого доступа.
Белый список. Сообщите механизму распознавания текста, что захваченный текст будет содержать только указанные символы.
Черный список: Сообщите механизму OCR, что захваченный текст никогда не будет содержать указанные символы.
Ориентация текста: ориентация текста, который будет захвачен. Этот параметр используется только в том случае, если в качестве активного языка распознавания выбран китайский или японский. Если выбран параметр «Авто», будет использоваться горизонтальное положение, если ширина захвата более чем в два раза превышает высоту, в противном случае будет использоваться вертикальное. Направление текста также влияет на то, как фуригана удаляется из японского текста. Вы также можете указать ориентацию текста в меню значка на панели задач или с помощью горячей клавиши «Ориентация текста».
Файл конфигурации Tesseract: расширенная функция, позволяющая указать файл конфигурации Tesseract.
Trim Capture: во время предварительной обработки OCR обрезайте захваченное изображение до пикселей переднего плана и добавьте тонкую границу. Точность распознавания текста будет более стабильной и даже может быть улучшена.
Deskew Capture: во время предварительной обработки OCR попытайтесь компенсировать наклон текста, обнаруженный при захвате OCR.
Содержит параметры для настройки автоматических захватов. Чтобы получить дополнительную информацию, наведите указатель мыши на метки параметров.
Позволяет указать цвета окна захвата OCR.Прозрачность можно изменить, настроив значение «Альфа-канал» в диалоговом окне выбора цвета.
Позволяет указать положение, цвет и шрифт предварительного просмотра. Вы можете отключить предварительный просмотр, сняв флажок «Показать окно предварительного просмотра».
Сохранить в буфер обмена: сохранить захваченный текст OCR в буфер обмена.
Показать всплывающее окно: показать захваченный текст OCR во всплывающем окне:
Сохранять разрывы строк: установите этот флажок, если вы не хотите, чтобы символы возврата каретки и перевода строки удалялись из захваченного текста.
Logging: позволяет сохранять все записи в указанный файл в указанном формате. В формате могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}, $ {linebreak}, $ {tab}. Формат по умолчанию: «$ {capture} $ {linebreak}».
Вызов исполняемого файла: расширенная функция, позволяющая вызывать исполняемый файл после завершения распознавания текста. Могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}. Пример:
C: \ Anaconda3 \ python.exe "C: \ Scripts \ test.py" "$ {capture}" "$ {translation}"
Позволяет выполнять замену текста. Поддерживает регулярные выражения. Текст слева будет заменен текстом справа. Для каждого языка OCR могут быть указаны разные замены.
См. Раздел перевода.
Эта страница позволяет вам включить функцию преобразования текста в речь, установить громкость и выбрать параметры (голос, скорость, высота тона) для использования для каждого языка OCR.
Включить преобразование текста в речь: включить преобразование текста в речь при захвате текста.
Когда этот параметр отмечен и голос не установлен на «
Громкость: основная громкость функции преобразования текста в речь. Применимо ко всем языкам.
Язык OCR: укажите параметры речи для выбранного языка OCR.
- Скорость: скорость преобразования текста в речь.
- Высота: высота голоса для преобразования текста в речь.
- Голос: голос, используемый для преобразования текста в речь. Установите значение «
», чтобы отключить функцию преобразования текста в речь только для выбранного языка OCR.
Предварительный просмотр: предварительный просмотр текущей скорости, высоты тона и голоса.
Параметры командной строки
Использование: Capture2Text_CLI.exe [параметры]
Capture2Text может использоваться для распознавания файлов изображений или части экрана.Примеры:
Capture2Text_CLI.exe --screen-rect "400 200 600 300"
Capture2Text_CLI.exe --vertical -l "Китайский - упрощенный" -i img1.png
Capture2Text_CLI.exe -i img1.png -i img2.jpg -o result.txt
Capture2Text_CLI.exe -l японский -f "C: \ Temp \ image_files.txt"
Capture2Text_CLI.exe --show-languages
Параметры:
- ?, -h, --help Отображает эту справку.
-v, --version Отображает информацию о версии.
-b, --line-breaks Не удалять разрывы строк из текста OCR.-d, --debug Выводить захваченное изображение и предварительно обработанное
изображение для отладки.
--debug-timestamp Добавить метку времени для отладки изображений, когда
используя опцию -d.
-f, --images-file <файл> Файл, содержащий пути файлов изображений к
OCR. Один путь на строку.
-i, --image <файл> Файл изображения для OCR.Вы можете OCR несколько
файлы изображений, например: "-i -i
-i "
-l, --language <язык> используемый язык распознавания текста. Деликатный случай.
По умолчанию "английский". Использовать
--show-languages для вывода списка установленных
Языки OCR.
-o, --output-file <файл> Выводить текст OCR в этот файл.Если не
указано, будет использоваться стандартный вывод.
--output-file-append Добавить в файл при использовании опции -o.
-s, --screen-rect <"x1 y1 x2 y2"> Координаты прямоугольника, определяющего область
экрана в OCR.
-t, --vertical OCR вертикальный текст. Если не указано,
предполагается горизонтальный текст.
-w, --show-languages Показать установленные языки, которые можно использовать
с опцией "--language".--output-format Формат для использования при выводе текста OCR.
Вы можете использовать эти токены:
$ {capture}: текст OCR.
$ {linebreak}: разрыв строки (\ r \ n).
$ {tab}: символ табуляции.
$ {timestamp}: время этого экрана или каждого
файл был обработан.$ {file}: файл, который был обработан или
экран прямоугольник.
Формат по умолчанию - "$ {capture} $ {linebreak}".
--whitelist <символы> Распознавать только указанные символы.
Пример: «0123456789».
--blacklist <символы> Не распознавать указанные символы.
Пример: «0123456789».--clipboard Выводить текст OCR в буфер обмена.
--trim-capture Во время предварительной обработки OCR выполняется обрезка
изображение в пиксели переднего плана и добавьте тонкий
граница.
--deskew Во время предварительной обработки OCR попытаться
компенсировать наклон текста.
--scale-factor Коэффициент масштабирования для использования во время предварительной обработки.Диапазон: [0,71, 5,0]. По умолчанию - 3,5.
--tess-config-file <файл> (Дополнительно) Путь к конфигурации Tesseract
файл.
------
Для Capture2Text.exe (в отличие от Capture2Text_CLI.exe) вы можете указать дополнительную опцию:
--portable Хранить файл настроек .ini в том же каталоге
как.EXE файл.
Устранение неполадок и часто задаваемые вопросы
- Я получаю сообщение об отсутствии файла DLL, когда дважды щелкаю Capture2Text.exe.
Решение: установите распространяемый пакет Visual Studio 2015.
- Capture2Text вообще не работает. Что я могу сделать?
Возможные решения:
Убедитесь, что вы разархивировали Capture2Text.Поищите в Google, если не знаете, как
разархивировать файл.Убедитесь, что ваше антивирусное программное обеспечение не блокирует Capture2Text.
См. Документацию, прилагаемую к вашему антивирусному программному обеспечению.Убедитесь, что вы скачали последнюю версию с
SourceForge.Перезагрузите компьютер.
Попросите внука вам помочь 🙂
- Я нашел ошибку!
Отлично! Создайте заявку и опишите ошибку.
- Я хочу сделать предложение.
Отлично! Создайте заявку и опишите свое предложение.
- Capture2Text выводит символы мусора.
Решение: укажите правильный язык OCR.
- Интересующий меня язык не отображается в меню языка распознавания текста.
Прочтите Установка дополнительных языков распознавания текста.
- Я не вижу значок Capture2Text на панели задач.персонаж).
- Я щелкнул значок Capture2Text в трее, но он ничего не сделал.
Вместо этого щелкните его правой кнопкой мыши.
- Capture2Text не работает на моем Mac.
Capture2Text — это программное обеспечение только для Windows. Если у вас есть технический опыт,
не стесняйтесь портировать его (но не просите меня помочь). - Где деинсталлятор?
Нет ни одного. Capture2Text также не имеет установщика.Удалять
Capture2Text со своего компьютера, просто удалите каталог Capture2Text. - Где находится файл настроек .ini?
Введите «% appdata% \ Capture2Text» в проводнике Windows.
Вы можете удалить его, чтобы восстановить настройки по умолчанию.
- Как сделать Capture2Text портативным?
Вызовите Capture2Text.exe с параметром —portable. Вы можете создать для этого ярлык.Установка этого параметра заставит Capture2Text сохранить файл настроек .ini в том же каталоге, что и Capture2Text.exe (в отличие от «% appdata% \ Capture2Text», которое является обычным местом).
- Где находится исходный код?
Исходный код находится на SourceForge.
Сопутствующие инструменты для изучающих японский язык
- JGlossator (Windows)
Автоматический поиск японских слов, распознаваемых вами с помощью Capture2Text.Поддерживает искаженные выражения, чтения, звуковое произношение, примеры предложений,
ударный тон, частота слов, информация о кандзи и грамматический анализ. Поддерживает словари EDICT и EPWING. - OCR Manga Reader (Android)
Бесплатное приложение для чтения манги для Android с открытым исходным кодом, которое позволяет быстро распознавать текст и выполнять поиск
Японские слова в реальном времени. Нет никакой рекламы и никаких загадочных сетевых разрешений.
Поддерживает словари EDICT и EPWING.
OCR на основе глубокого обучения для текста в дикой природе
Мы живем во времена, когда любая организация или компания, стремящаяся к масштабированию и сохранению актуальности, должна изменить свой взгляд на технологии и быстро адаптироваться к меняющимся условиям. Мы уже знаем, как Google оцифровал книги. Или как Google Earth использует NLP для идентификации адресов. Или как можно читать текст в цифровых документах, таких как счета-фактуры, юридические документы и т. Д.
Но как именно это работает?
Этот пост посвящен оптическому распознаванию символов (OCR) для распознавания текста в естественных изображениях сцены.Мы узнаем о том, почему это сложная проблема, о подходах, используемых для ее решения, и о соответствующем коде.
Имеете в виду проблему распознавания текста? Хотите извлечь данные из документов? Зайдите в Nanonets и создавайте модели OCR бесплатно!
Но почему на самом деле?
В нашу эпоху оцифровки хранить, редактировать, индексировать и находить информацию в цифровом документе намного проще, чем тратить часы, просматривая печатные / рукописные / печатные документы.
Более того, поиск чего-либо в большом нецифровом документе занимает не только много времени, но и может упустить информацию при прокрутке документа вручную. К счастью для нас, компьютеры с каждым днем становятся все лучше и лучше, выполняя те задачи, которые люди думали только о них, и зачастую работают лучше нас.
Извлечение текста из изображений нашло множество применений.
Некоторые из приложений: распознавание паспортов, автоматическое распознавание номерных знаков, преобразование рукописных текстов в цифровой текст, преобразование печатного текста в цифровой и т. Д.
Проблемы
Источник изображения: https://pixabay.com
Прежде чем мы расскажем, как нам нужно понять проблемы, с которыми мы сталкиваемся при распознавании текста.
Многие реализации OCR были доступны еще до бума глубокого обучения в 2012 году. Хотя обычно считалось, что OCR — это решенная проблема, OCR по-прежнему остается сложной проблемой, особенно когда текстовые изображения создаются в неограниченной среде.
Я говорю о сложном фоне, шуме, молниях, различном шрифте и геометрических искажениях изображения.
Именно в таких ситуациях блестят инструменты машинного обучения OCR.
Проблемы с распознаванием текста возникают в основном из-за свойств выполняемых задач распознавания текста. Обычно мы можем разделить эти задачи на две категории:
Структурированный текст — Текст в печатном документе. Стандартный фон, правильный ряд, стандартный шрифт и в основном плотный.
Структурированный текст: плотные, удобочитаемые стандартные шрифты; Источник изображения: https://pixabay.com
Неструктурированный текст — Текст в произвольных местах на естественной сцене.Редкий текст, отсутствие правильной структуры строк, сложный фон, случайное место на изображении и отсутствие стандартного шрифта.
Неструктурированные тексты: рукописные, несколько шрифтов и разреженные; Источник изображения: https://pixabay.com
Многие более ранние методы решали проблему распознавания текста для структурированного текста.
Но эти методы не работали должным образом для естественной сцены, которая является разреженной и имеет другие атрибуты, чем структурированные данные.
В этом блоге мы сосредоточимся больше на неструктурированном тексте, который представляет собой более сложную проблему для решения .
Как мы знаем в мире глубокого обучения, не существует единого решения, подходящего для всех. Мы увидим несколько подходов к решению поставленной задачи и проработаем один из них.
Наборы данных для неструктурированных задач OCR
Существует множество наборов данных на английском языке, но труднее найти наборы данных для других языков. Различные наборы данных представляют разные задачи, которые необходимо решить. Вот несколько примеров наборов данных, обычно используемых для задач распознавания текста машинным обучением.
Набор данных SVHN
Набор данных Street View House Numbers содержит 73257 цифр для обучения, 26032 цифры для тестирования и 531131 дополнительных в качестве дополнительных обучающих данных. Набор данных включает 10 меток, которые представляют собой цифры от 0 до 9. Набор данных отличается от MNIST, поскольку SVHN имеет изображения номеров домов с номерами домов на разном фоне. В наборе данных есть ограничивающие прямоугольники вокруг каждой цифры вместо нескольких изображений цифр, как в MNIST.
Набор данных Scene Text
Этот набор данных состоит из 3000 изображений в различных настройках (в помещении и на улице) и условиях освещения (тень, свет и ночь) с текстом на корейском и английском языках.Некоторые изображения также содержат цифры.
Набор данных Devanagri Character
Этот набор данных предоставляет нам 1800 образцов из 36 классов символов, полученных 25 различными авторами в сценарии devanagri.
И есть много других, таких как этот для китайских иероглифов, этот для CAPTCHA или этот для рукописных слов.
Любой Типичный конвейер OCR машинного обучения включает следующие шаги:
Поток OCR
Предварительная обработка
- Удаление шума из изображения
- Удаление сложного фона из изображения
- Обработка различных условий освещения на изображении
Удаление шума из изображения .Source
Это стандартные способы предварительной обработки изображения в задаче компьютерного зрения. В этом блоге мы не будем сосредотачиваться на этапе предварительной обработки.
Обнаружение текста
источник
Методы обнаружения текста, необходимые для обнаружения текста в изображении и создания ограничивающей рамки вокруг части изображения, содержащей текст. Здесь также будут работать стандартные методы обнаружения возражений.
Техника скользящего окна
Ограничивающая рамка может быть создана вокруг текста с помощью техники скользящего окна.Однако это дорогостоящая задача в вычислительном отношении. В этом методе скользящее окно проходит через изображение, чтобы обнаружить текст в этом окне, как сверточная нейронная сеть. Мы стараемся с другим размером окна, чтобы не пропустить текстовую часть другого размера. Существует сверточная реализация скользящего окна, которая может сократить время вычислений.
Детекторы одиночного снимка и детектора области
Существуют методы одноразового обнаружения, такие как YOLO (вы смотрите только один раз) и методы определения текста на основе области для обнаружения текста на изображении.
Архитектура YOLO: исходный код
YOLO — это однократная техника, когда вы передаете изображение только один раз, чтобы обнаружить текст в этой области, в отличие от скользящего окна.
Региональный подход работает в два этапа.
Во-первых, сеть предлагает область, в которой, возможно, будет проходить тест, а затем классифицирует область, есть ли в ней текст или нет. Вы можете обратиться к одной из моих предыдущих статей, чтобы понять методы обнаружения объектов, в нашем случае обнаружения текста.
EAST (Эффективный точный детектор текста сцены)
Это очень надежный метод глубокого обучения для обнаружения текста, основанный на этой статье.Стоит упомянуть, что это всего лишь метод обнаружения текста. Он может находить горизонтальные и повернутые ограничивающие рамки. Его можно использовать в сочетании с любым методом распознавания текста.
Конвейер обнаружения текста в этой статье исключил избыточные и промежуточные этапы и состоит только из двух этапов.
One использует полностью сверточную сеть для непосредственного прогнозирования на уровне слов или текстовых строк. Полученные прогнозы, которые могут быть повернутыми прямоугольниками или четырехугольниками, далее обрабатываются на этапе подавления без максимального значения, чтобы получить окончательный результат.
Изображение взято с https://arxiv.org/pdf/1704.03155v2.pdf
EAST может обнаруживать текст как на изображениях, так и на видео. Как упоминалось в документе, он работает почти в реальном времени со скоростью 13 кадров в секунду на изображениях 720p с высокой точностью распознавания текста. Еще одним преимуществом этого метода является то, что его реализация доступна в OpenCV 3.4.2 и OpenCV 4. Мы увидим эту модель EAST в действии вместе с распознаванием текста.
Распознавание текста
После того, как мы обнаружили ограничивающие прямоугольники с текстом, следующим шагом будет распознавание текста.Есть несколько техник распознавания текста. В следующем разделе мы обсудим некоторые из лучших техник.
CRNN
Сверточная рекуррентная нейронная сеть (CRNN) представляет собой комбинацию потерь CNN, RNN и CTC (Connectionist Temporal Classification) для задач распознавания последовательности на основе изображений, таких как распознавание текста сцены и OCR. Сетевая архитектура была взята из этой статьи, опубликованной в 2015 году.
Изображение взято с https: // arxiv.org / pdf / 1507.05717.pdf
Эта архитектура нейронной сети объединяет извлечение признаков, моделирование последовательностей и транскрипцию в единую структуру. Эта модель не требует сегментации символов. Сверточная нейронная сеть извлекает признаки из входного изображения (область обнаружения текста). Глубокая двунаправленная рекуррентная нейронная сеть предсказывает последовательность меток с некоторой связью между символами. Слой транскрипции преобразует каждый кадр, созданный RNN, в последовательность меток.Существует два режима транскрипции, а именно транскрипция без лексикона и транскрипция на основе лексики. В подходе, основанном на лексике, будет предсказана наиболее вероятная последовательность меток.
Машинное обучение OCR с Tesseract
Tesseract был первоначально разработан в Hewlett-Packard Laboratories в период с 1985 по 1994 год. В 2005 году он был открыт в HP. Согласно wikipedia —
В 2006 году Tesseract считался одним из наиболее точных на тот момент движков OCR с открытым исходным кодом.
Возможности Tesseract в основном ограничивались структурированными текстовыми данными. Он будет плохо работать с неструктурированным текстом со значительным шумом. Дальнейшая разработка tesseract спонсируется Google с 2006 года.
Метод на основе глубокого обучения лучше работает с неструктурированными данными. В Tesseract 4 добавлены возможности на основе глубокого обучения с движком OCR на основе сети LSTM (разновидность рекуррентной нейронной сети), который ориентирован на распознавание строк, но также поддерживает устаревший движок Tesseract OCR Tesseract 3, который работает путем распознавания шаблонов символов.Последняя стабильная версия 4.1.0 выпущена 7 июля 2019 года. Эта версия также значительно более точна в отношении неструктурированного текста.
Мы будем использовать некоторые изображения, чтобы показать как обнаружение текста с помощью метода EAST, так и распознавание текста с помощью Tesseract 4. Давайте посмотрим на обнаружение и распознавание текста в действии в следующем коде. Данная статья оказалась полезным ресурсом при написании кода для этого проекта.
## Загрузка необходимых пакетов
импортировать numpy как np
импорт cv2
от imutils.object_detection импорт non_max_suppression
импортировать pytesseract
from matplotlib import pyplot as plt Загрузка пакетов
# Создание словаря аргументов для аргументов по умолчанию, необходимых в коде.
args = {"image": "../ input / text-detection / example-images / Example-images / ex24.jpg", "east": "../ input / text-detection / east_text_detection.pb", " min_confidence ": 0,5," ширина ": 320," высота ": 320}
Создание словаря аргументов с некоторыми значениями по умолчанию
Здесь я работаю с основными пакетами.Пакет OpenCV использует модель EAST для обнаружения текста. Пакет tesseract предназначен для распознавания текста в ограничивающей рамке, обнаруженной для текста. Убедитесь, что у вас версия tesseract> = 4. В Интернете доступно несколько источников для руководства по установке tesseract.
Создан словарь для аргументов по умолчанию, необходимых в коде. Посмотрим, что означают эти аргументы.
- изображение: расположение входного изображения для обнаружения и распознавания текста.
- восток: расположение файла с предварительно обученной моделью детектора EAST.
- минимальная достоверность: минимальная оценка вероятности достоверности геометрической формы, предсказанной в местоположении.
- width: Для правильной работы модели EAST ширина изображения должна быть кратна 32.
- высота: для правильной работы модели EAST высота изображения должна быть кратна 32.
# Укажите местоположение изображения для чтения.
# Здесь загружается изображение "Example-images / ex24.jpg".
args ['image'] = "../ input / text-detection / example-images / Example-images / ex24.jpg "
image = cv2.imread (args ['изображение'])
# Сохранение исходного изображения и формы
orig = image.copy ()
(origH, origW) = image.shape [: 2]
# установить новую высоту и ширину по умолчанию 320 с помощью args #dictionary.
(newW, newH) = (args ["ширина"], args ["высота"])
# Рассчитайте соотношение между исходным и новым изображением как для роста, так и для веса.
# Это соотношение будет использоваться для перевода положения ограничивающей рамки на исходном изображении.
rW = origW / float (newW)
rH = origH / float (newH)
# изменить размер исходного изображения до новых размеров
изображение = cv2.resize (изображение; (newW, newH))
(H, W) = image.shape [: 2]
# конструируем blob из изображения, чтобы передать его модели EAST
blob = cv2.dnn.blobFromImage (изображение, 1.0, (Ш, В),
(123.68, 116.78, 103.94), swapRB = True, crop = False) Обработка изображений
# загрузить предварительно обученную модель EAST для обнаружения текста
net = cv2.dnn.readNet (args ["восток"])
# Мы хотели бы получить два вывода от модели EAST.
№1. Оценки вероятности для региона, содержит он текст или нет.
№2. Геометрия текста - Координаты ограничивающей рамки, определяющей текст
# Следующие два слоя необходимо извлечь из модели EAST для этого.layerNames = [
"feature_fusion / Conv_7 / Sigmoid",
"feature_fusion / concat_3"] Загрузка предварительно обученной модели EAST и определение выходных слоев
# Вперед передать blob из изображения, чтобы получить желаемые выходные слои
net.setInput (большой двоичный объект)
(scores, geometry) = net.forward (layerNames) Вперед передать изображение через модель EAST
## Возвращает ограничивающую рамку и оценку вероятности, если она превышает минимальную достоверность
прогнозы def (prob_score, geo):
(numR, numC) = prob_score.форма [2: 4]
коробки = []
доверие_val = []
# перебрать строки
для y в диапазоне (0, numR):
scoresData = prob_score [0, 0, y]
x0 = geo [0, 0, y]
x1 = geo [0, 1, y]
x2 = geo [0, 2, y]
x3 = geo [0, 3, y]
anglesData = geo [0, 4, y]
# перебрать количество столбцов
для i в диапазоне (0, numC):
если scoresData [i] Функция декодирования ограничивающего прямоугольника из прогноза модели EAST
В этом упражнении мы декодируем только горизонтальные ограничивающие прямоугольники.Расшифровка вращающихся ограничивающих рамок из партитур и геометрии более сложна.
# Найдите прогнозы и примените подавление не максимальных значений
(коробки, доверительное_значение) = прогнозы (баллы, геометрия)
boxs = non_max_suppression (np.array (box), probs = trust_val) Получение окончательных ограничивающих рамок после подавления без максимума
Теперь, когда мы вывели ограничивающие прямоугольники после применения подавления без максимума. Мы хотели бы видеть ограничивающие рамки на изображении и то, как мы можем извлечь текст из обнаруженных ограничивающих рамок.Мы делаем это с помощью тессеракта.
## Обнаружение и распознавание текста
# инициализировать список результатов
результаты = []
# перебираем ограничивающие прямоугольники, чтобы найти координаты ограничивающих прямоугольников
для (startX, startY, endX, endY) в полях:
# масштабируйте координаты на основе соответствующих соотношений, чтобы отразить ограничивающую рамку на исходном изображении
startX = int (startX * rW)
startY = int (startY * rH)
конецX = число (конецX * rW)
конец Y = int (конец Y * rH)
# извлечь интересующую область
r = orig [начало: конецY, началоX: конецX]
#configuration параметр для преобразования изображения в строку.configuration = ("-l eng --oem 1 --psm 8")
## Это распознает текст на изображении ограничивающей рамки
text = pytesseract.image_to_string (r, config = конфигурация)
# добавить координату bbox и связанный текст в список результатов
results.append (((startX, startY, endX, endY), text)) Создание списка с координатами ограничивающего прямоугольника и распознанным текстом в полях
В приведенной выше части кода сохранены координаты ограничивающего прямоугольника и связанный текст в списке. Посмотрим, как это выглядит на изображении.
В нашем случае мы использовали определенную конфигурацию тессеракта. Для настройки тессеракта доступно несколько опций.
l: язык , выбран английский в приведенном выше коде.
oem (режимы OCR Engine):
0 Только старый двигатель.
1 Только движок нейронных сетей LSTM.
2 двигателя Legacy + LSTM.
3 По умолчанию, в зависимости от того, что доступно.
psm (режимы сегментации страниц):
0 Только ориентация и обнаружение скриптов (OSD).
1 Автоматическая сегментация страниц с экранным меню.
2 Автоматическая сегментация страниц, но без OSD или OCR. (не реализовано)
3 Полностью автоматическая сегментация страниц, без экранного меню. (По умолчанию)
4 Предположим, что один столбец текста переменного размера.
5 Предположим, что это один однородный блок вертикально выровненного текста.
6 Предположим, что это один однородный блок текста.
7 Считайте изображение одной текстовой строкой.
8 Обращайтесь с изображением как с одним словом.
9 Рассматривайте изображение как отдельное слово в круге.
10 Считайте изображение одним символом.
11 Редкий текст. Найдите как можно больше текста в произвольном порядке.
12 Разреженный текст в экранном меню.
13 Необработанная линия. Относитесь к изображению как к одной текстовой строке, минуя хаки, специфичные для Tesseract.
Мы можем выбрать конкретную конфигурацию Tesseract на основе наших данных изображения.
# Показать изображение с ограничивающей рамкой и распознанным текстом
orig_image = orig.copy ()
# Перемещение результатов и отображение на изображении
for ((start_X, start_Y, end_X, end_Y), text) в результатах:
# отображаем текст, обнаруженный Tesseract
печать ("{} \ n".формат (текст))
# Отображение текста
text = "" .join ([x if ord (x) <128 else "" для x в тексте]). strip ()
cv2.rectangle (orig_image, (start_X, start_Y), (end_X, end_Y),
(0, 0, 255), 2)
cv2.putText (orig_image, текст, (start_X, start_Y - 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0, 255), 2)
plt.imshow (orig_image)
plt.title ('Вывод')
plt.show () Показать изображение с ограничивающей рамкой и распознанным текстом
Результаты
Приведенный выше код использует модель OpenCV EAST для обнаружения текста и тессеракт для распознавания текста.PSM для Tesseract настроен в соответствии с изображением. Важно отметить, что для нормальной работы Tesseract обычно требуется четкое изображение.
В нашей текущей реализации мы не рассматривали вращающиеся ограничивающие прямоугольники из-за сложности реализации. Но в реальном сценарии, когда текст повернут, приведенный выше код не будет работать. Кроме того, если изображение не очень четкое, tesseract будет трудно правильно распознать текст.
Вот некоторые из выходных данных, сгенерированных приведенным выше кодом:
Источник необработанного изображения: https: // madison.citymomsblog.com Источник сырого изображения: http://lrv.fri.uni-lj.si/andreji/CVLOCRDB/ Источник сырого изображения: https://www.tripadvisor.in/
Код может обеспечить отличные результаты для всех трех вышеперечисленных изображений. Текст на этих изображениях четкий, а фон за текстом также одинаков.
Источник необработанного изображения: https://www.magic.co.nz
Модель показала себя здесь довольно хорошо. Но некоторые алфавиты распознаются неправильно. Вы можете видеть, что ограничивающие рамки в основном правильные, какими они должны быть.Возможно, поможет небольшое вращение. Но наша текущая реализация не предоставляет вращающихся ограничивающих рамок. Кажется, из-за четкости изображения tesseract не смог его точно распознать.
Источник необработанного изображения: https://www.ktoo.org
Модель здесь показала неплохие результаты. Но некоторые тексты в ограничивающих рамках распознаются неправильно. Цифра 1 вообще не может быть обнаружена. Здесь неоднородный фон, возможно, создание однородного фона помогло бы в этом случае. Кроме того, 24 неправильно ограничены в рамке.В таком случае может помочь заполнение ограничивающей рамки.
Источник необработанного изображения: https://www.mirror.co.uk/
Похоже, что стилизованный шрифт с тенью на заднем фоне повлиял на результат в приведенном выше случае.
Нельзя ожидать, что модель OCR будет точной на 100%. Тем не менее, мы добились хороших результатов с моделью EAST и Tesseract. Добавление дополнительных фильтров для обработки изображения поможет улучшить производительность модели.
Вы также можете найти этот код для этого проекта в ядре Kaggle, чтобы попробовать его самостоятельно.
OCR с Nanonets
API Nanonets OCR позволяет легко создавать модели OCR. Вы можете загрузить свои данные, аннотировать их, настроить модель для обучения и ждать получения прогнозов через пользовательский интерфейс на основе браузера.
1. Использование графического интерфейса: https://app.nanonets.com/
Вы также можете использовать Nanonets-OCR- API, выполнив следующие действия:
2. Использование NanoNets API: https: // github. com / NanoNets / nanonets-ocr-sample-python
Ниже мы дадим вам пошаговое руководство по обучению вашей собственной модели с использованием API Nanonets в 9 простых шагов.
Шаг 1. Клонируйте репо
git clone https://github.com/NanoNets/nanonets-ocr-sample-python
CD наносети-ОКР-образец-Python
запросы на установку sudo pip
sudo pip install tqdm Шаг 2: Получите бесплатный ключ API
Получите бесплатный ключ API с https://app.nanonets.com/#/keys
Шаг 3. Установите ключ API в качестве переменной среды
экспорт NANONETS_API_KEY = YOUR_API_KEY_GOES_HERE
Шаг 4: Создайте новую модель
python./code/create-model.py
Примечание. При этом генерируется MODEL_ID, необходимый для следующего шага.
Шаг 5: Добавить идентификатор модели в качестве переменной среды
экспорт NANONETS_MODEL_ID = YOUR_MODEL_ID
Шаг 6. Загрузите обучающие данные
Соберите изображения объекта, который вы хотите обнаружить. Когда у вас есть готовый набор данных в папке изображения (файлы изображений), начните загрузку набора данных.
python ./code/upload-training.ру
Шаг 7. Обучение модели
После загрузки изображений начните обучение модели
python ./code/train-model.py
Шаг 8: Получение состояния модели
Обучение модели занимает около 30 минут. После обучения модели вы получите электронное письмо. А пока вы проверяете состояние модели
watch -n 100 python ./code/model-state.py
Шаг 9: Сделайте прогноз
После обучения модели.
Добавить комментарий