App Store: FineScanner: Сканер документов
ABBYY FineScanner AI – ваш умный карманный сканер для документов и книг от ведущего мирового разработчика решений в области интеллектуальной обработки информации.
FineScanner AI использует искусственный интеллект, создавая электронные копии документов и книг в форматах PDF и JPEG, и распознает текст на сканах (OCR) с сохранением форматирования.
*****Победитель конкурса Mobile Star Award в категории «Сканирование документов» с наградой SUPERSTAR*****
***** № 1 в категории Бизнес в 98 странах *****
Сканируйте с помощью вашего iPhone или iPad документы, книги, чеки, рецепты, заметки, статьи, изображения, диаграммы, таблицы, слайды, объявления и даже рекламные щиты на улице и получайте прекрасные электронные копии. FineScanner — идеальный инструмент оцифровки для бизнесменов, студентов, научных сотрудников, простых обывателей, который всегда с собой.
КЛЮЧЕВЫЕ ВОЗМОЖНОСТИ
• PDF И JPEG. Сканируйте любые печатные или рукописные бумаги и сохраняйте их в JPEG или PDF.
Сканируйте любые печатные или рукописные бумаги и сохраняйте их в JPEG или PDF.
• Нейросети ABBYY. Умная галерея автоматически распределит документы на 7 типов: A4, книги, визитки, удостоверения, рукописный текст, чеки, прочее.
• ИЩИТЕ ТЕКСТ НА ФОТО. Введите искомый текст в строку поиска на странице галереи. FineScanner найдёт и покажет фото, содержащие этот текст.
• AR ЛИНЕЙКА. Определяйте размер документа с помощью дополненной реальности (AR). Это пригодится для документов нестандартного размера и позволит сохранить правильные пропорции при печати документов.
• OFFLINE OCR. Распознавайте текст в формате TXT быстро и без интернета.
• ONLINE OCR. Распознавайте печатные тексты на сканах документов на 193 языках (включая латиницу, кириллицу и азиатские языки) с выгрузкой результатов в Word, Excel, PDF, TXT с сохранением форматирования документа (списки, таблицы, заголовки). Доступно для 100 страниц в документе.
• BOOKSCAN. Переключите камеру в режим Книга и обрабатывайте разворот книги одним кадром! BookScan разрежет разворот на две отдельные страницы, удалит геометрические искажения, дефекты света, выпрямит изгибы строк и страниц. Как если бы вы прижимали книгу крышкой обычного настольного сканера.
Как если бы вы прижимали книгу крышкой обычного настольного сканера.
• ГОЛОСОВЫЕ КОМАНДЫ SIRI. Открывайте сканы голосом и настраивайте цепочки действий для документов с помощью приложения «Команды»
• АННОТАЦИЯ СКАНОВ. Редактируйте PDF с помощью инструментов аннотации: добавляйте подписи или пишите текст ручкой, выделяйте маркером, скрывайте конфиденциальные данные или вставляйте печатный текст.
• 3D TOUCH И SPOTLIGHT SEARCH.
• ПАРОЛЬ НА PDF. Добавляет пароль на image-only PDF при экспорте и пересылке по email.
• МНОГОСТРАНИЧНЫЕ ДОКУМЕНТЫ. Создавайте электронные копии как небольших (1-2 страницы), так и объемных многостраничных документов без дополнительных переключений (не более 100 страниц в документе).
• АВТО-ЗАХВАТ И ФИЛЬТРЫ. Идеальный результат за счет автоматического определения границ листа, а также фильтров, которые позволяют сохранить изображение в черно-белом, сером или цветном режиме.
• УДОБНОЕ ХРАНИЛИЩЕ с тегами и поиском.
• ЭКСПОРТ. Делитесь результатами по e-mail, сохраняйте в облако — iCloud Drive, Box, Яндекс. Диск, Evernote, Dropbox, Facebook или Google.Drive, OneDrive для Бизнеса, переносите сканы напрямую на Маc или Windows с помощью iTunes sharing.
Диск, Evernote, Dropbox, Facebook или Google.Drive, OneDrive для Бизнеса, переносите сканы напрямую на Маc или Windows с помощью iTunes sharing.
• AIRPRINT. Печатайте сканы прямо с iPhone или iPad.
КОРПОРАТИВНОЕ ЛИЦЕНЗИРОВАНИЕ
Если вы хотите приобрести большое количество лицензий (от 100 лицензий) для вашей компании или хотите внести кастомизацию в приложение, пожалуйста, напишите [email protected].
Читайте нас:
Mobileblog.abbyy.com
@ABBYY_Mobile в Твиттере
Facebook.com/Abbyy.Lingvo
vk.com/abbyylingvo
Youtube.com/ABBYYMobile
Пожалуйста, оставьте отзыв, если вам понравилось приложение FineScanner. Спасибо!
Сканер + распознавание текста на айфоне: Обзор Adobe Scan для iOS
Перечисленные ниже сервисы для распознавания содержимого изображений и отсканированных документов помогут быстро и совершенно бесплатно перенести текст для его последующего редактирования.
♥ ПО ТЕМЕ: Как передать гостям пароль от Wi-Fi, при этом не называя его (QR-код).

Office Lens
Какие форматы распознает: изображения, снятые камерой.
В каких форматах сохраняет: DOCX, PPTX, PDF.
Данный сервис позволяет сканировать документы с помощью камеры телефона или компьютера. Office Lens поддерживает сохранение в популярных форматах. Получившиеся файлы можно редактировать в текстовых редакторах Microsoft, интегрированных с Office Lens, таких как Word и One Note.
Скачать Office Lens для ПК
Скачать Office Lens для iPhone и iPad
Скачать Office Lens для Android
♥ ПО ТЕМЕ: ПДФ → Ворд (текст), МП3 → Вав (аудио) конвертер онлайн: 5 лучших бесплатных онлайн-сервисов.
Adobe Scan
Какие форматы распознает: изображения, снятые камерой.
В каких форматах сохраняет: PDF.
Разработанный компанией Adobe продукт несколько уступает предыдущему сервису, так как позволяет сохранять распознанный текст только в формате PDF. Его сильной стороной является возможность экспорта документов в Adobe Acrobat, в котором можно удобно редактировать PDF-файлы.
Скачать Adobe Scan для iPhone и iPad
Скачать Adobe Scan для Android
♥ ПО ТЕМЕ: Как правильно фотографировать: 12 простых советов для тех, кто хочет улучшить качество своих фотографий.
Free OCR to Word
Какие форматы распознает: JPG, TIF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и пр.
В каких форматах сохраняет: DOC, DOCX, TXT.
Программа доступна для компьютера на базе Windows и Mac и позволяет распознавать текст на изображениях во множестве форматов. Присутствует поддержка экспорта в Word, сохранения не отформатированного текста в формате TXT и сохранения содержимого в буфере обмена.
Присутствует поддержка экспорта в Word, сохранения не отформатированного текста в формате TXT и сохранения содержимого в буфере обмена.
Скачать Free OCR to Word для Windows и Mac.
ПО ТЕМЕ: 20 полезных сервисов Google, о которых вы могли не знать.
FineReader Online
Какие форматы распознает: JPG, TIF, BMP, PNG, PCX, DCX, PDF.
В каких форматах сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A.
Сервис позволяет распознавать и редактировать тексты и таблицы в режиме online. Бесплатно можно распознать только 10 страниц, после чего каждый месяц можно будет без оплаты загрузить еще по 5 страниц.
Пользоваться FineReader Online.
♥ ПО ТЕМЕ: Обрезать видео онлайн: 3 быстрых бесплатных сервиса.
Online OCR
Какие форматы распознает: JPG, BMP, TIFF, GIF, PDF.
В каких форматах сохраняет: DOCX, XLSX, TXT.
Еще один online-сервис, позволяющий, в отличие от предыдущего, распознавать тексты и таблицы совершенно бесплатно и без регистрации. У зарегистрировавшихся пользователей есть возможность загружать больше одного файла за один раз.
Пользоваться Online OCR.
♥ ПО ТЕМЕ: Как сделать фотоколлаж онлайн: обзор лучших сервисов.
Soda PDF OCR
Какие форматы распознает: JPG, GIF, TIFF BMP, PNG, PDF.
В каких форматах сохраняет: TXT.
Один из простейших сервисов, предоставляющий на выходе чистый, не отформатированный текст. Не требует регистрации и поддерживает работу с документами на нескольких языках.
Пользоваться Soda PDF OCR.
♥ ПО ТЕМЕ: Бесплатный редактор ПДФ: лучшие программы для редактирования PDF-документов на компьютере.
Microsoft OneNote
Какие форматы распознает: большинство распространенных форматов изображений.
В каких форматах сохраняет: файлы OneNote.
Функция распознавания текста присутствует в версии OneNote для персональных компьютеров. Для того чтобы провести данную операцию, необходимо нажать на изображение текста правой кнопкой мыши и выбрать опцию «Копировать текст из рисунка» → «Текст». Распознанное содержимое будет перемещено в буфер обмена.
Скачать Microsoft OneNote для ПК
Скачать Microsoft OneNote для iPhone и iPad
Скачать Microsoft OneNote для Android
Смотрите также:
Как вставить отсканированный текст или изображения в Word
Если вы хотите вставить в документ Word печатный документ или рисунок, это можно сделать несколькими способами.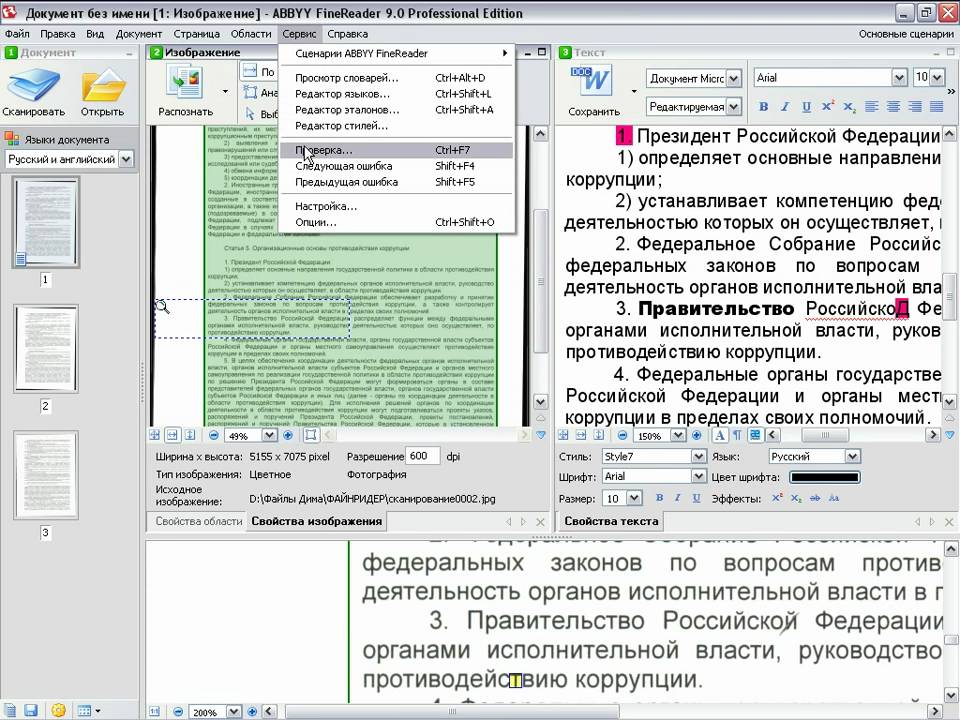
Примечание: Если вы ищете инструкции по подключению сканера или копировального аппарата в Microsoft Windows, посетите веб-сайт изготовителя устройства.
Сканирование изображения в Word
Чтобы отсканировать изображение в документ Word, можно воспользоваться сканером, принтером с несколькими функциями, копировальным аппаратом с возможностью сканирования или цифровой камерой.
-
Отсканируйте изображение или сделайте его снимок с помощью цифровой камеры или смартфона.
-
Сохраните изображение в стандартном формате, таком как JPG, PNG или GIF. Поместите его в папку на своем компьютере.
-
В Word поместите курсор в то место, куда вы хотите вставить отсканированное изображение, а затем на вкладке Вставка на ленте нажмите кнопку рисунки.
-
В диалоговом окне выберите отсканированное изображение и нажмите кнопку Вставить.

Вставка отсканированного текста в Word
Для сканирования документа в Microsoft Word проще всего использовать наше бесплатное приложение Office Lens на смартфоне или планшете. Оно получает снимок документа с помощью камеры устройства и сохраняет его в виде редактируемого документа непосредственно в Word. Она доступна бесплатно на iPad, iPhone, Windows Phone и Android.
Если вы не хотите использовать Office Lens, лучше просканировать документ в формате PDF с помощью собственного программного обеспечения сканера, а затем открыть этот PDF-файл в Word.
-
В Word выберите Файл > Открыть.
-
Перейдите в папку, в которой хранится PDF-файл, и откройте его.
-
Word откроет диалоговое окно, в котором нужно подтвердить импорт текста PDF-файла. Нажмите кнопку ОК , чтобы подтвердить действие, и Word импортирует текст. Word постарается сохранить форматирование текста.
Дополнительные сведения см. в статье Редактирование содержимого PDF-документа в Word.
Примечание: Точность распознавания текста зависит от качества сканирования и четкости отсканированного текста.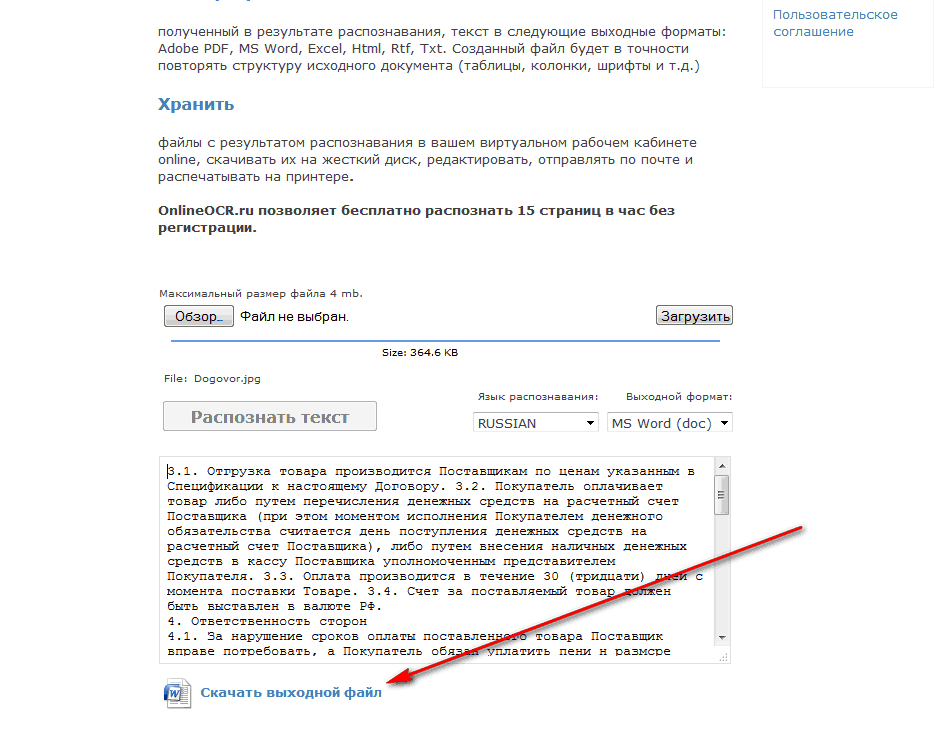 Рукописный текст редко распознается, поэтому для лучших результатов сканируйте печатные материалы. Всегда проверяйте текст после его открытия в Word, чтобы убедиться, что он правильно распознан.
Рукописный текст редко распознается, поэтому для лучших результатов сканируйте печатные материалы. Всегда проверяйте текст после его открытия в Word, чтобы убедиться, что он правильно распознан.
Кроме того, со сканером может поставляться приложение для распознавания текста (OCR). Обратитесь к документации своего устройства или к его производителю.
Остались вопросы о Word?
Задайте их на форуме сообщества Word Answers
Помогите нам улучшить Word
У вас есть предложения, как улучшить Word? Поделитесь ими на странице Word User Voice.
См. также
Как отредактировать текст в отсканированном PDF
Все мы так или иначе работаем с документами. Одни занимаются этим весь день в офисе, другие «от случая к случаю» или для учебы. Чаще всего обмен документацией осуществляется в формате PDF, так как он удобен в использовании и экономичен в потреблении трафика. Но зачастую присланный файл PDF оказывается собран из нескольких отсканированных изображений. Что же делать, если вам нужно внести туда свои корректировки? Без редактора PDF не обойтись.
Отредактировать PDF можно даже из отсканированного файла
Можно, конечно, перепечатать текст, однако этот способ актуален разве что для одной-двух страниц документа. Да и все равно он очень трудозатратный, не говоря о потере большого количества времени. А уж если мы имеем дело с файлом на 50-100 страниц, перепечатывать его придется целую вечность. На помощь приходят сторонние решения для Mac и Windows, которые позволяют отредактировать файл, даже если в вашем распоряжении оказался PDF в графическом формате.
Если интересующий вас файл содержит отсканированный текст, в который нужно внести правки, для начала этот текст необходимо распознать. Для этого можно загрузить приложение PDFelement 7 из Mac App Store или с сайта разработчика. Нас интересует функция OCR — оптическое распознавание символов.
Запустить оптическое распознавание можно в один клик
Вы открываете необходимый файл и в разделе «Инструменты» в боковом меню нажимаете на кнопку «Выполнить OCR». Кстати, распознавание в программе осуществляется в большом количестве языков, в том числе в русском. Стоит отметить, что нас приятно удивило качество то, как эта программа смогла распознать текст.
По времени процесс занимает около минуты — все зависит от размера файла
После выполнения распознавания текста документ сохранится в папке, в которой у вас по умолчанию хранятся документы. Чтобы продолжить работу с текстом, открываем сохраненный файл в PDFelement 7 и приступаем к правкам. С документом вы можете делать все, что угодно: править текст, добавлять пометки и примечания, вставлять рисунки, выделять некоторые участки, удалять страницы, вставлять колонтитулы и многое другое.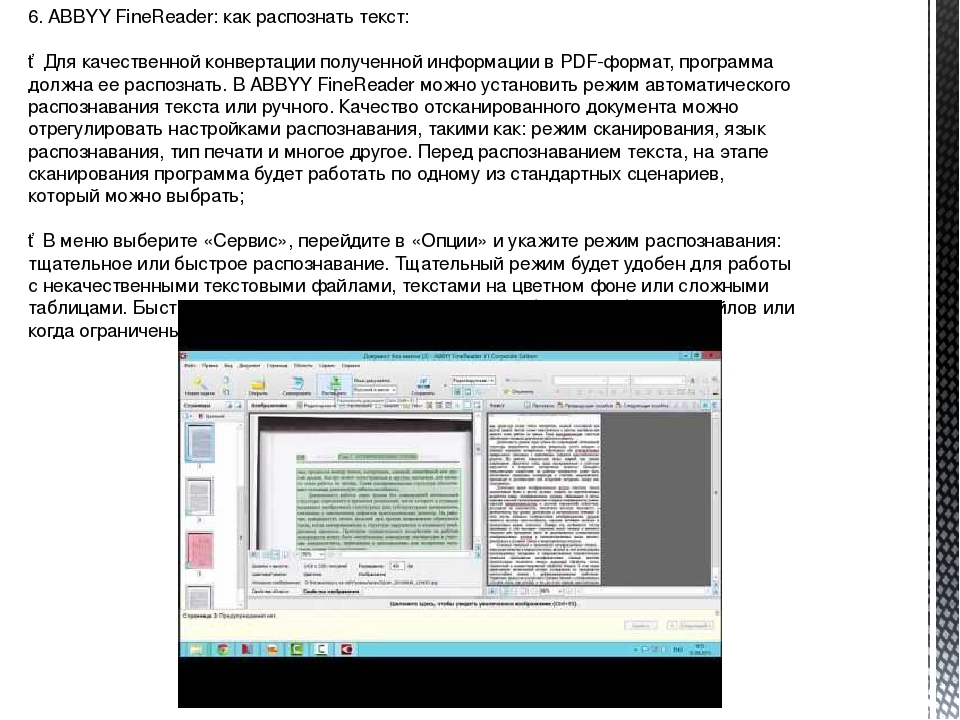
Документ успешно распознан, можно его редактировать
Есть множество возможностей продвинутого редактирования
Удобно, что полученный файл можно экспортировать в один из популярных форматов (не только PDF, но и MS Office, текстовые документы или графические файлы). Также прямо из программы можно отправить плоды своих трудов по электронной почте. Если вы хотите запретить редактировать получившийся PDF-файл, при желании можно установить на него защиту — например, паролем или с помощью вотермарки.
OCR — не единственная полезная функция данного приложения. PDFelement 7 также поддерживает автоматическое распознавание полей формы и извлечение больших объемов данных. Все это помогает повысить скорость обработки данных и работать с PDF, как профессионал.
Автоматическое распознавание полей форм пригодится во время работы с Excel
И это все помимо продвинутого создания PDF с нуля — от добавления аннотаций в виде геометрических фигур, линий или стрелок до подписей и объединения нескольких файлов в формате PDF в один.
Защитить документ можно несколькими способами
Чтобы ознакомиться с базовой функциональностью приложения PDFelement, пробную версию для Windows и Mac вы можете бесплатно загрузить по ссылкам ниже. Если вы поняли, что эта программа вам жизненно необходима, можно приобрести полную версию, в которой доступно оптическое распознавание текста и другие полезные функции. Кстати, в честь Черной пятницы разработчики устроили распродажу, в рамках которой можно сэкономить до 50 долларов на покупке полной версии приложения.
Название: PDFelement 7
Издатель/разработчик: Wondershare
Цена: Бесплатно / Подписка
Совместимость: Windows, Mac
Ссылка: Установить
Распознаватели текста (Text Recognition) — MrTranslate.ru
Если вам необходимо перевести ранее напечатанный текст в электронную форму, то сегодня вам не потребуется набирать его на клавиатуре.
Современные технологии существенно упрощают этот процесс.
Достаточно отсканировать его или сфотографировать, и обработать специальной программой — распознавателем текста.
Давно прошло то время, когда для получения электронной копии печатного текста, приходилось набирать его на клавиатуре, символ за символом, буква за буквой. Сегодня печатный текст достаточно положить на сканер, нажать одну кнопку, и уже через несколько секунд у вас будет его электронная копия, как будто кто-то уже набрал его для вас.
Как же это стало возможным? Как работает распознавание текста?
Системы распознавания текста или OCR-системы (Optical Character Recognition) предназначены для автоматического ввода документов в компьютер. Это может быть страница книги, журнала, словаря, какой-то документ — все, что угодно, что было уже напечатано, и должно быть преобразовано обратно в электронную форму.
OCR-системы распознают текст и различные его элементы (картинки, таблицы) с электронного изображения. Изображение получается обычно путем сканирования документа и реже — его фотографированием. Поступившее изображение обрабатывается алгоритмом OCR-программы, выделяются области текста, изображений, таблиц, отделяется мусор от нужных данных.
Поступившее изображение обрабатывается алгоритмом OCR-программы, выделяются области текста, изображений, таблиц, отделяется мусор от нужных данных.
На следующем этапе каждый символ сравнивается со специальным словарем символов, и если находится соответствие, то этот символ считается распознанным. В итоге вы получаете набор распознанных символов, то есть искомый текст.
Современные OCR-системы представляют собой достаточно сложные программные решения. Ведь текст может быть замусорен, искажен,
загрязнен, и программа должна это учитывать и уметь правильно обрабатывать такие ситуации. Кроме того, современные OCR-системы позволяют также получить копию печатного документа в электронном виде с сохранением форматирования, стилей, размеров текста и видов шрифтов и т.д.
ABBYY FineReader 9.0 Home Edition
| Разработчик: | ABBYY |
| Тип лицензии: | Trial, только для домашнего использования |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
Система распознавания текста ABBYY FineReader — это многофункциональная программа для перевода бумажных документов, pdf-файлов, фотографий в редактируемые форматы. Эта версия известной программы для распознавания текста специально
Эта версия известной программы для распознавания текста специально
предназначена для домашнего пользователя, простая и удобная в использовании. В ней отсутствуют лишние функции и сложные настройки, а интерфейс рассчитан даже на неподготовленного пользователя. Если вам нужно время от времени быстро получать электронные копии страниц каких-то учебников, книг, документов — эта версия OCR-программы для вас.
Подробнее о FineReader 9.0 Home Edition →
ABBYY FineReader 9.0 Professional Edition
| Разработчик: | ABBYY |
| Тип лицензии: | Trial |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
Эта версия программы ABBYY FineReader для распознавания текста подойдет для использования в офисе или в учебном заведении, а также для продвинутых пользователей, кто хотел бы иметь возможность задавать множество настроек и активно участвовать в процессе распознавания текста.
Возможности программы позволяют вам отсканировать и распознать документы, проверить результат распознавания на ошибки, исправить их автоматически или вручную, и сохранить документ в одном из множества форматов (txt, doc, pdf и др.). Программа умеет работать с сетью: пересылать документы по электронной почте,
размещать их в хранилища информации, использовать сетевое оборудование (сканеры и МФУ).
Подробнее о FineReader 9.0 Professional Edition →
ABBYY FineReader 9.0 Corporate Edition
| Разработчик: | ABBYY |
| Тип лицензии: | для корпоративного использования |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
Специальная версия программы ABBYY FineReader для распознавания текста, предназначенная для использования в крупных фирмах, для организации электронных архивов документов. Система позволяет организовать полноценную работу по распознаванию текста внутри большой компании, размещение результатов в электронных хранилищах, использование сетевого оборудования.
Система позволяет организовать полноценную работу по распознаванию текста внутри большой компании, размещение результатов в электронных хранилищах, использование сетевого оборудования.
Подробнее о FineReader 9.0 Corporate Edition →
ABBYY Business Card Reader
| Разработчик: | ABBYY |
| Тип лицензии: | Trial 1 день |
| Требования: | Nokia (модели N73, N78, N79, N82, N85, N86 8MP, N93, N93i, N95, N95-3 NAM, N95 8GB, N96, N96-3, E90 Communicator, 6210 Navigator, E71, E66, E63, E75, 6220 classic, 6720 classic, 5730 XpressMusic, 6710 Navigator, 5800 XpressMusic) |
Эта программа предназначена для мобильных устройств (смартфонов), позволяющая быстро вводить в записную книжку контактную информацию с визитных карточек. ABBYY Business Card Reader будет удобна для деловых людей, бизнесменов, менеджеров, всех, кто часто сталкивается с визитными карточками. Программа поддерживает 16 языков.
Программа поддерживает 16 языков.
Подробнее о ABBYY Business Card Reader →
Readiris 12 Pro
| Разработчик: | I.R.I.S. s.a. |
| Тип лицензии: | Trial |
| Требования: | Windows 200/XP/Vista или Mac, 256 Mb RAM, 150-250 Mb свободного места, сканер |
Readiris Pro — многофункциональная OCR-система, которая подойдет как домашним пользователям, так и профессионалам. При помощи этой программы вы можете быстро преобразовать любой документ, PDF-файл, изображение в редактируемый текст,
и затем сохранить его в один из множества популярных форматов.
Программа имеет простой и приятный интерфейс со множеством дополнительных возможностей и полезных инструментов: сжатие файлов, работа с изображениями, функции экспорта, и др.
Подробнее о Readiris 12 Pro →
Readiris 12 Corporate
| Разработчик: | I. R.I.S. s.a. R.I.S. s.a. |
| Тип лицензии: | Trial |
| Требования: | Windows 200/XP/Vista или Mac, 256 Mb RAM, 150-250 Mb свободного места, сканер |
Readiris Corporate — OCR-система, которая специально предназначена для использования в крупных компаниях, офисах, а также для создания электронных архивов.
Программа обладает теми же возможностями, что и версия Readiris Pro, плюс еще дополнительные инструменты и настройки для работы с сетью и сетевым оборудованием. Поддерка азиатских языков, иврита, фарси устанавливается отдельно.
Подробнее о Readiris 12 Corporate →
SimpleOCR
| Разработчик: | SimpleSoftware |
| Тип лицензии: | Freeware |
| Требования: | Windows 95/98/NT4/2000/XP/Vista, 50 Mb свободного места, сканер, TWAIN driver |
SimpleOCR — OCR-система, которая распространяется совершенно бесплатно.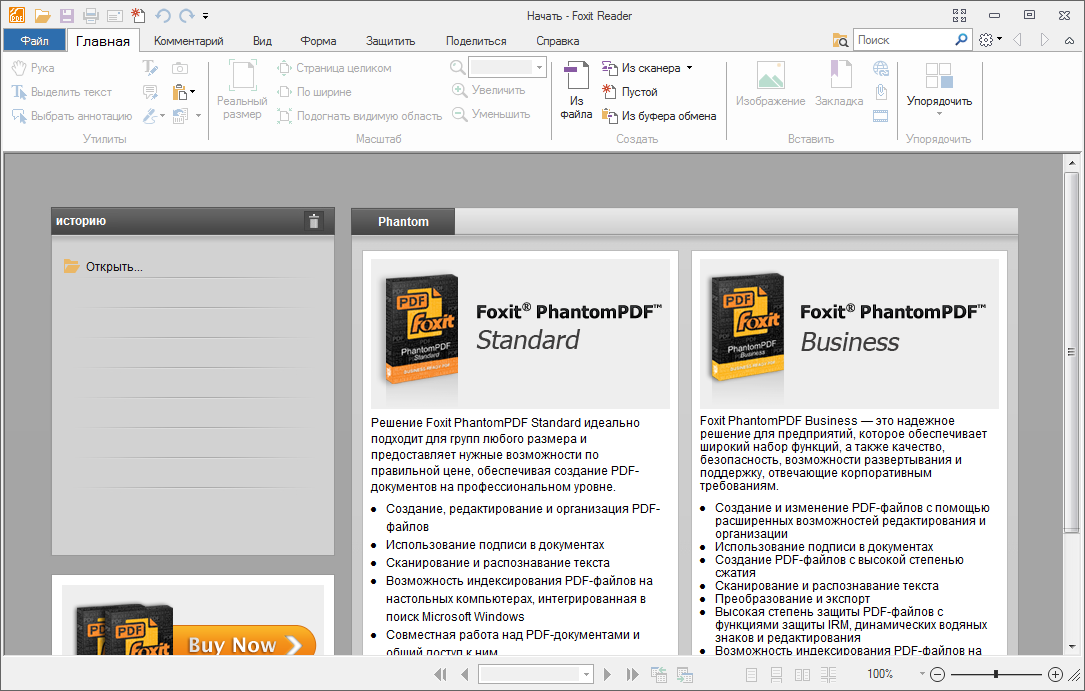 Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках.
Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках.
Подробнее о SimpleOCR →
Ввод китайских иероглифов при помощи мыши или планшета
| Разработчик: | NJStar Software Corp. |
| Тип лицензии: | trial на 30 дней |
NJStar Chinese Pen — полезная программа для тех, кто работает с китайским языком. NJStar Chinese Pen позволяет вводить китайские иероглифы простым рисования их при помощи мыши или планшета.
Это намного быстрее и удобнее, чем набирать иероглифы на клавиатуре по определенным правилам.
Программа поддерживает как китайский традиционный, так и китайский упрощенный. Набранный текст можно озвучивать (произносить) при помощи встроенного speech-движка. Все параметры программы полностью настраиваются.
NJStar Chinese Pen поддерживает все версии операционной системы Windows.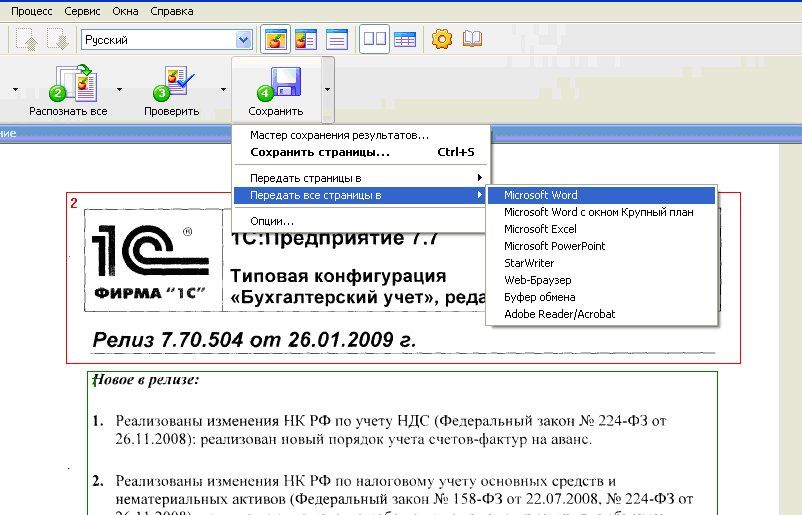 Для работы программы требуется примерно 50 Мб свободного места на жестком диске.
Для работы программы требуется примерно 50 Мб свободного места на жестком диске.
rite Pen
| Разработчик: | Evernote Corp. |
| Тип лицензии: | trial на 30 дней |
rite Pen — программа для ускорения ввода текста в текстовые редакторы, формы, для быстрого заполнения форм и сохранения заметок. Вы можете вводить текст, просто рисуя рукописные символы при помощи мыши или планшета в любом месте экрана.
Программа автоматически их распознает и введет в указанную программу или форму, или просто сохранит в своей базе данных. Вы также можете добавлять заметки прямо на экран, выделять области экрана, и сохранять их для дальнейшего использования.
Еще одна полезная возможность — создание меток. Запрограммируйте определенное слово или рисунок (метку) за вводом определенного текста, и как только вы нарисуете эту метку на экране, тут же будет вставлен нужный текст.
Подробнее о rite Pen →
ArioForm
| Разработчик: | Ariolis |
| Тип лицензии: | trial на 30 дней |
ArioForm — решение для обработки большого объема данных, оформленных по определенному шаблону (таких как результаты тестов и опросов, бланки, отчеты, различные формы).
Возможности программы позволяют вам создавать и распознавать формы практически любой сложности, содержащие печатный текст, поля ввода рукописного текста, поля выбора одного или нескольких параметров, графические элементы.
Программа также имеет набор уже созданных шаблонов.
Подробнее о ArioForm →
MyScript Studio
| Разработчик: | Vision Objects |
| Тип лицензии: | trial на 30 дней |
MyScript Studio — решение для оцифровки документов и заметок, созданных «от руки».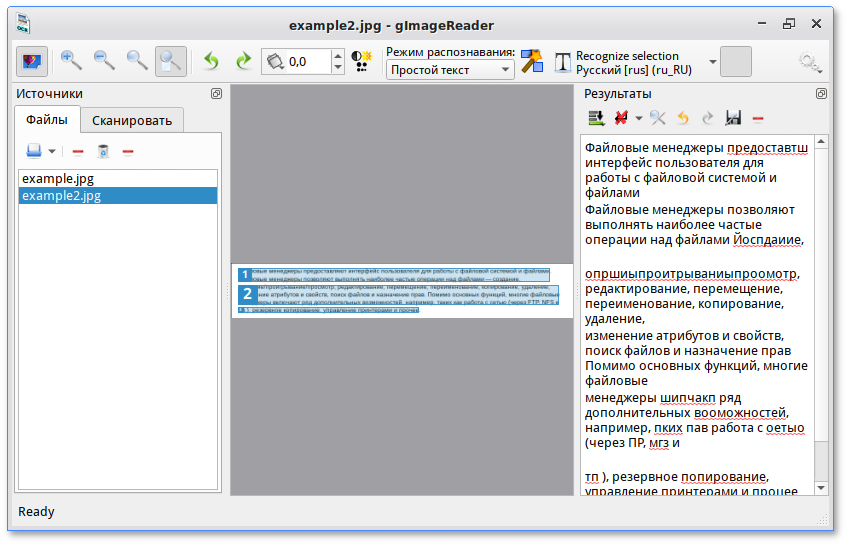 Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки.
Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки.
При помощи этой программы вы сможете быстро перевести в электронную форму все ваши заметки, записи и рукописные документы, распознать текст и организовать электронный архив.
Подробнее о MyScript Studio →
Распознавание рукописного текста MyScript Stylus
| Разработчик: | Vision Objects |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows, Mac или Linux, 400 Мб свободного места |
MyScript Stylus — программа для распознавания рукописного текста. Текст можно вводить при помощи мыши или планшета. Программа распознает текст по технологии, применяющейся в кпк, и может использоваться там, где нет возможности использовать стандартную клавиатуру или ее использование затруднено
(например, если компьютер используется как терминал для ввода/вывода информации, как платежный терминал).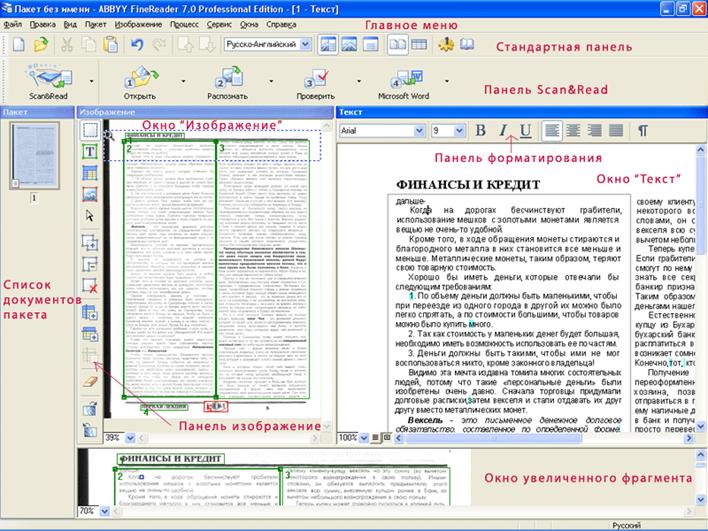 Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков.
Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков.
Подробнее о MyScript Stylus →
PenOffice
| Разработчик: | PhatWare Corporation |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows XP/Vista, 50 Мб свободного места |
PenOffice — программа для распознавания рукописного текста. PenOffice был специально создан для интеграции с программами пакетов Microsoft Office и OpenOffice, но позволяет вводить распознанный текст также и в другие программы. Программа позволяет распознавать 9 языков: английский, испанский, итальянский, голландский, французский, немецкий, норвежский, португальский и шведский.
Подробнее о PenOffice →
CalliGrapher
| Разработчик: | PhatWare Corporation |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows Mobile 4/5/6/6. 1, 3.8 Мб свободного места, ActiveSync 4.0 1, 3.8 Мб свободного места, ActiveSync 4.0 |
CalliGrapher — программа ввода рукописного текста для кпк и смартфонов под управлением Windows Mobile. Программа распознает рукописный текст и сразу же вводит его в текстовый редактор в выбранном стиле. Вы можете писать текст в любом месте экрана.
CalliGrapher имеет встроенную виртуальную клавиатуру, систему проверки правописания и многоязыковую поддержку.
Подробнее о CalliGrapher →
Отсканировать книгу и распознать текст за 5050 рублей
Цена договорная
Помощь фрилансеров
Требуется создать аватарку для сообщества в ВКонтакте (тематика : реклама товаров из известных интернет магазинов, стиль : минимализм
Владимир
Цена договорная
Выковать меч
Выковать сувенирный меч длинной 1м. Деревянная рукоять чёрного цвета Меч не должен быть острым, ничего не должен рубить и резать. Просто сувенирный предмет. Возможна будет надпись на клинке. Примерный…
Деревянная рукоять чёрного цвета Меч не должен быть острым, ничего не должен рубить и резать. Просто сувенирный предмет. Возможна будет надпись на клинке. Примерный…
Максим К.
Цена договорная
Цена разработки логотипа, варианты логотипов
Необходимо разработать логотип для службы доставки пиццы и роллов "El Pablo". Сама доставка пока еще находится в стадии планирования. На основе данного логотипа будет создаваться весь остальной…
Павел Л.
Цена договорная
Поменять морду енота на лицо человека)
Для принта на свитшоте нужно вместо самого енота поместить фото девушки. Примерный енот во вложении, фото человека, который будет владельцем тела енота — дам) Только выглядеть должно естественно, конечно…
Рубен
Цена договорная
Нанять художника в Челябинске
Надо нарисовать дом в объеме, сделать его в цвете-те показать этот объём, потом опираясь на рисунок сделать из бумаги макет этого дома
Марина А.
Как изменить отсканированный текст?
Получение высшего образования предусматривает постоянную работу с текстом. Вам придется посещать лекции, писать конспекты, разрабатывать презентации, оформлять многочисленные рефераты.
Для подготовки к экзамену приходится составлять конспекты. Свои записи рекомендуется дополнять сведениями из учебников. Следовательно, студенту приходится много времени тратить на подготовку к занятиям.
Иногда нужно отредактировать свой или чужой конспект. При переписывании текста вручную тратится очень много времени. Что делать? Студенты знают, что можно отсканировать любой документ, график или таблицу.
Если вы пропустили какую-либо лекцию, то можно сфотографировать чужой конспект. Вам потребуется смартфон, позволяющий переснять текст. В итоге у вас будет изображение чужих записей.
Однако, что делать, если полученную картинку нужно изменить? Вы хотите что-то вписать или дополнить текст? Современные программы позволяют изменять сканированные изображения.
Возможности работы с текстом для студентов
Вам известно, что любой текст можно сканировать. Данная функция удобна для того, чтобы не тратить время на переписывание конспектов. Вы сможете даже сделать шпаргалки при помощи сканера.
Однако, имеется также возможность распознавания текста. Такая функция позволяет превращать любое изображение в обычный документ, который вы сможете редактировать.
Сканирование текста
Вам просто нужно отсканировать текст или картинку, а затем приступить к редактированию. Специальная программа распознает информацию, превращая ее в обычный текст. Вы сможете работать с любым изображением, как с документом, созданным в Word.
Для того, чтобы программа смогла преобразовать сканированный текст в документ Word вам нужно правильно сохранить полученное изображение. Вам предлагаются форматы BMP, JPG, PNG, GIF.
Сохранив текст в одном из вышеуказанных форматов, вы получите привычный документ. Далее вы сможете работать в Wordе, удаляя или вставляя информацию. Вам доступны все инструменты привычной программы.
Вам доступны все инструменты привычной программы.
Сканирование и распознавание текста
Студенту приходится постоянно работать с текстом, поэтому нужно разобраться, какие технологии смогут облегчить процесс обучения в ВУЗе. Вам потребуются следующие вещи:
- Сканер. Данный аппарат должен быть совместим с вашим стационарным компьютером или ноутбуком. Однако, без специального аппарата можно обойтись, используя фотоаппарат смартфона. Собираетесь приобрести сканер? Обратите внимание на скорость сканирования одного листа. Если скорость небольшая, то придется тратить много времени на сканирование конспектов иди изображений.
- Вам нужна специальная программа, которая способна распознавать любой текст. Отлично зарекомендовала себя платная программа ABBYY FineReader, которая успешно справляется с текстами большого объема. Бесплатная версия Cunei Form работает в режиме онлайн, но она имеет ограниченные возможности.
- Поиск необходимой информации в Интернете. Если вам нужно отсканировать и отредактировать текст из какого-либо учебника, то перед началом работы следует поискать информацию в сети. Возможно, кто-то из студентов уже занимался подобной работой, поэтому в сети имеются сохраненные документы. В таком случае вы сможете сразу приступить к редактированию.
 Возможно, кто-то из студентов уже занимался подобной работой, поэтому в сети имеются сохраненные документы. В таком случае вы сможете сразу приступить к редактированию.
Возможно, кто-то из студентов уже занимался подобной работой, поэтому в сети имеются сохраненные документы. В таком случае вы сможете сразу приступить к редактированию.Распознавание текста
Вы подготовили сканер, установили специальную программу? Что делать дальше? Для облегчения работы рекомендуется установить на своем компьютере настройки, позволяющие сразу сканировать текст в нужном формате.
Так вы сэкономите время, необходимое для редактирования текста. Вы будете сохранять текст в том режиме, который является самым удобным для вас.
Как студенту сэкономить на распознавании текста
Если вам иногда нужно отсканировать чужие записи, то не стоит тратиться на приобретение специальной техники. Достаточно просто сфотографировать конспект при помощи собственного смартфона.
Далее вы сможете скопировать полученные изображения в компьютер. Размеры картинок несложно уменьшить или увеличить. Вам не потребуются специальные программы и устройства.
Вам нужно преобразовать свой конспект в шпаргалки? Вы сможете сфотографировать свои записи при помощи телефона, а далее необходимо уменьшить размеры полученных картинок.
При наличии сканера вы сможете просто переснять все записи. У вас получится прекрасный комплект шпаргалок, которые помогут успешно сдать экзамен.
Однако, если вы хотите работать со сканированными документами в режиме редактирования, то придется установить специальную программу. Так вы сможете создавать новые документы, полученные из стандартных изображений.
Хотите быстро редактировать сканированный текст? Имеет смысл приобрести специальную программу ABBYY FineReader, которая позволит вам полностью работать с любой картинкой.
Вы сможете изменять текст, исправлять ошибки, добавлять информацию. Не получается купить специализированную программу? Вы можете сложиться с однокурсниками, чтобы работать совместно.
Стоимость программы вы разделите на всех, получится небольшая сумма. Зато на протяжении всего периода обучения в ВУЗе у вас будет прекрасный помощник, позволяющий работать со сканированными документами.
При наличии Интернета вы сможете использовать программу Cunei Form, позволяющую бесплатно распознавать текст.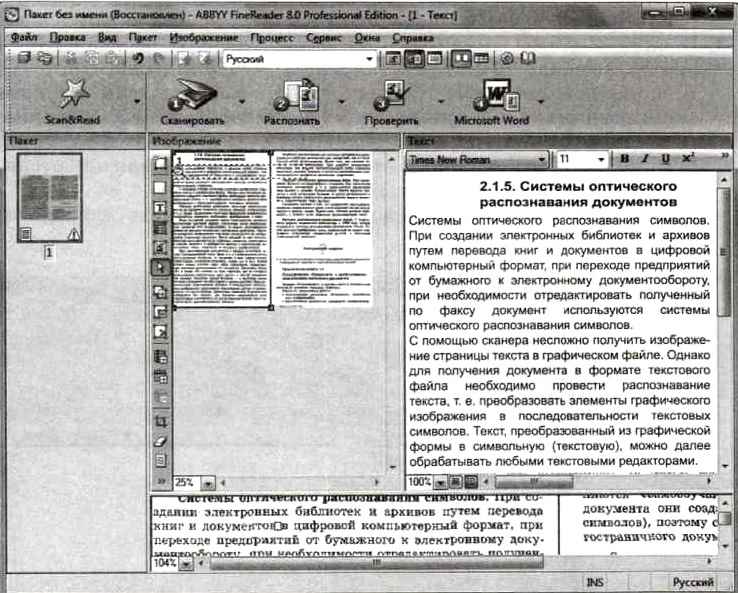 Перед вами откроются достаточно ограниченные возможности, но вы также сможете работать с картинками, таблицами и сканированным текстом.
Перед вами откроются достаточно ограниченные возможности, но вы также сможете работать с картинками, таблицами и сканированным текстом.
Современные возможности облегчают процесс обучения для студентов ВУЗов. Вам нужно установить специальные программы, позволяющие создавать документы различной сложности.
Проживая в общежитии, вы сможете использовать смартфон и ноутбук. Например, в библиотеке имеет смысл сфотографировать необходимые страницы журнала, книги или учебника.
В общежитии вы сможете скинуть полученные изображения на ноутбук, а затем распознать текст. Далее вам предстоит процесс редактирования текста, получение желаемого документа.
Оптическое распознавание символов и как это работает
Ручка и бумага могут быть устаревшими, но они не исчезли полностью. Если вы предпочитаете делать заметки вручную или работать с формами, которые заполняются вручную, бывают моменты, когда вам нужно перенести эту информацию в цифровую форму.
Набор рукописных данных любого типа — утомительный способ оцифровки. Вот где оптическое распознавание символов спасает положение.
Что такое оптическое распознавание символов (OCR)?
Технология оптического распознавания символов (OCR) означает оптическое распознавание символов.Это популярное программное обеспечение для распознавания текста внутри изображений, например отсканированных документов и фотографий. OCR используется для преобразования практически любых изображений, содержащих письменный текст (напечатанный, рукописный или напечатанный), в машиночитаемые данные.
Оцифровка документов с помощью OCR позволяет выполнять поиск по ключевым словам в тексте. Lumin PDF предлагает OCF как одну из многих полезных функций для работы с PDF.
Как работает OCR?
OCR преобразует отсканированную или рукописную страницу в машиночитаемую версию.Что касается PDF, это означает, что вы можете сканировать документы, загружать их в Lumin и вносить необходимые правки по своему усмотрению. Технология OCR экономит время; Кроме того, если вы потеряете первоначальную версию файла из-за сбоя и у вас есть бумажная копия, вам просто нужно отсканировать ее, и с этого момента больше не нужно набирать ее заново. Отсканировав документ, вы сможете вносить изменения прямо в сам файл и быстро искать нужные части документов.
Технология OCR экономит время; Кроме того, если вы потеряете первоначальную версию файла из-за сбоя и у вас есть бумажная копия, вам просто нужно отсканировать ее, и с этого момента больше не нужно набирать ее заново. Отсканировав документ, вы сможете вносить изменения прямо в сам файл и быстро искать нужные части документов.
Что такое Lumin PDF?
По своей сути Lumin PDF — это программа, призванная упростить работу с файлами PDF как для занятых профессионалов, так и для государственных служащих, студентов.Возможно, вы сталкивались с пересылкой по электронной почте, чтобы внести небольшие изменения в файл PDF, или повторным сканированием документа PDF для добавления подписи. Мы полагаем, что вы, возможно, расстроились из-за рутинной работы с PDF. Однако не волнуйтесь, эти дни давно в прошлом. Lumin PDF заменяет утомительные методы редактирования PDF эффективными цифровыми процессами.
Как работает Lumin PDF?
Lumin PDF позволяет пользователям загружать, редактировать и совместно работать над файлами PDF в облаке. Вы также можете подключить Lumin PDF к Google Диску, чтобы получить доступ к вашим сохраненным документам.Lumin PDF предоставляет вам надежный набор полезных функций, которые сделают повседневную работу с файлами PDF простой и интуитивно понятной.
Вы также можете подключить Lumin PDF к Google Диску, чтобы получить доступ к вашим сохраненным документам.Lumin PDF предоставляет вам надежный набор полезных функций, которые сделают повседневную работу с файлами PDF простой и интуитивно понятной.
Lumin предлагает все функции, необходимые для быстрой и простой работы с PDF:
Когда дело доходит до аннотирования файлов PDF, многие люди ограничены в возможностях эффективного аннотирования. Lumin PDF решает эту проблему с помощью надежного набора эффективных функций. Lumin PDF позволяет аннотировать документы PDF в Интернете, на Mac, Windows или с мобильного устройства. Вы также можете использовать Lumin PDF как расширение для Google Диска и комфортно работать с Google Docs, Google Sheets и вашими PDF-файлами.С помощью Lumin PDF вы можете:
- Добавить комментарии в файл PDF
- Добавить комментарии в файл PDF с помощью параметра «Свободный текст»
- Сделать комментарий к файлу PDF, нарисовав
- Добавить формы
- Выделить формы
- Вставить изображение
Страницы PDF часто требуют корректировки. Однако вы можете не знать, как это сделать, или не иметь надежных инструментов, чтобы выполнить это без каких-либо нежелательных проблем. Lumin PDF имеет множество полезных функций для эффективного выполнения различных манипуляций со страницами.Используя Lumin PDF, вы сможете:
Однако вы можете не знать, как это сделать, или не иметь надежных инструментов, чтобы выполнить это без каких-либо нежелательных проблем. Lumin PDF имеет множество полезных функций для эффективного выполнения различных манипуляций со страницами.Используя Lumin PDF, вы сможете:
- Поворачивать страницы
- Удалить страницы
- Изменить порядок страниц в PDF
- Вставить пустую страницу
- Обрезать страницы
Нет необходимости проходить через хлопоты загрузки и выгрузки для внесения небольших изменений в документ PDF. Используя Lumin PDF, вы можете общаться с членами вашей команды прямо в документе. Вместо того, чтобы тратить время на пересылку форм и документов между членами команды или клиентами, вы можете использовать Lumin PDF для мгновенного редактирования и совместной работы и более быстрых результатов для вашей организации.Lumin PDF предоставляет пользователям онлайн-инструменты для удобного редактирования. Оптическое распознавание символов — одно из них.
OCR PDF-файлов, отсканированных изображений и т. Д. И сохранение распознанного текста как PDF или текста с возможностью поиска с помощью программного обеспечения DocuFreezer OCR Converter
Почему у меня такое плохое распознавание текста? 7 шагов для повышения точности распознавания текста
Текст может быть неправильным или поврежденным после преобразования с помощью OCR. Краткий совет — убедитесь, что входные файлы имеют высокое качество — большой формат и высокое разрешение.Понимание ограничений процесса оптического распознавания символов может помочь вам помочь механизму оптического распознавания текста получать более точные результаты. Результаты распознавания считаются хорошими, если распознанный текст имеет точность 98-99% (неверно 1-2% распознавания).
Ниже приведены несколько советов, которые помогут вам добиться лучших результатов распознавания текста.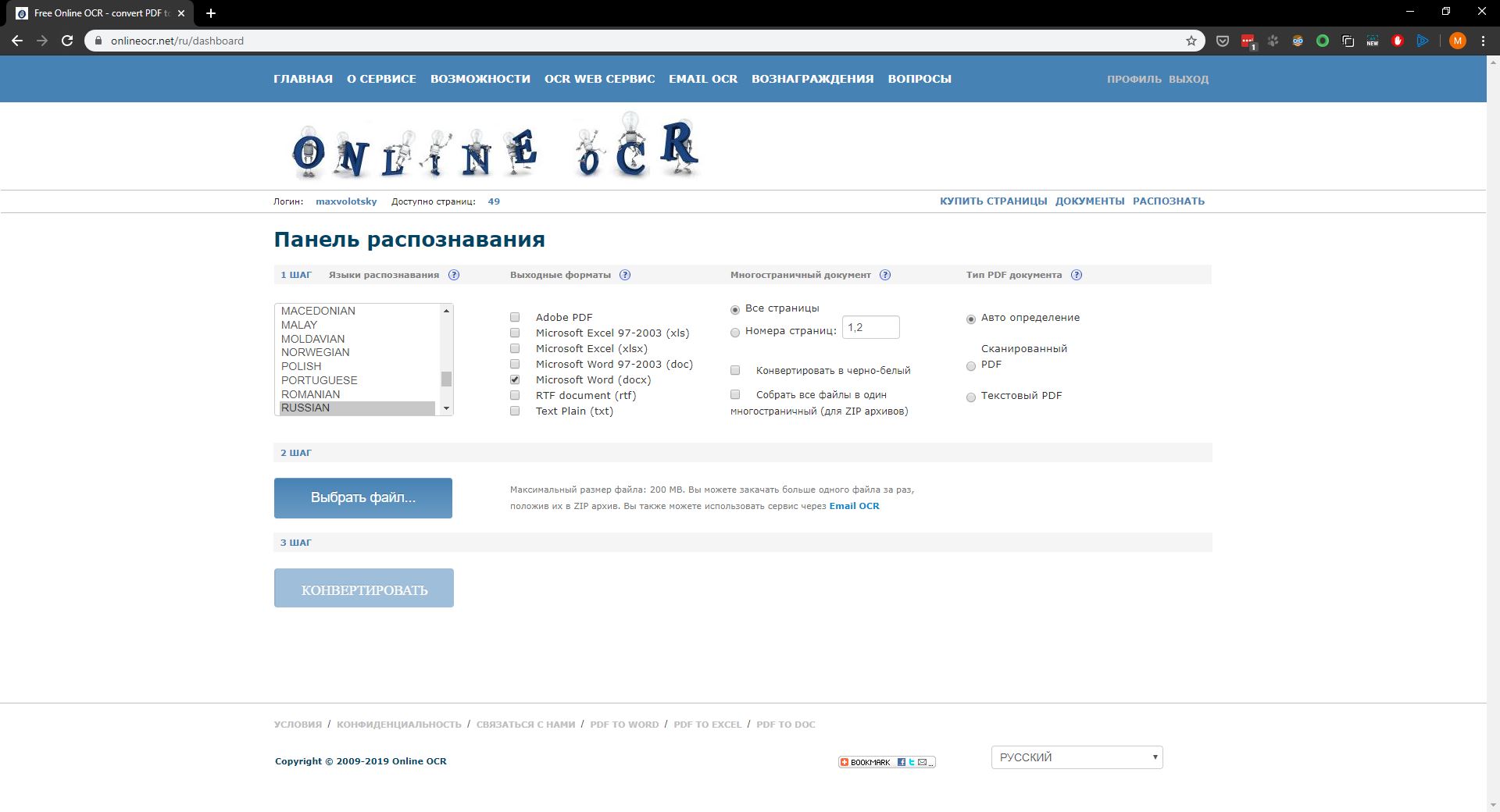
# 1 Улучшить качество исходных изображений
Одним из наиболее важных факторов является DPI (количество точек на дюйм). Сканируйте документы с разрешением 300 или выше точек на дюйм. Желательно сканировать с разрешением 600 точек на дюйм, чтобы получить как можно больше информации об изображении.При высоком разрешении изображения движок OCR должен уметь распознавать высокие контрасты, границы символов, пиксельный шум и выровненные символы.
# 2 Выберите выходной формат без потерь при сканировании
Для более точного извлечения текста программой OCR выберите формат файла без потерь, например TIFF. При сканировании в TIFF без сжатия никакая информация об изображении (грубо говоря, пиксели) не будет потеряна. Поэтому при сканировании исходного файла выбирайте формат файла без потерь, например TIFF или высококачественный PDF.
# 3 Повышение контрастности изображений
Контраст и плотность — важные факторы, которые необходимо учитывать перед распознаванием текста. При использовании сканера (или редактора изображений, если нет возможности отсканировать документ еще раз), вы можете настроить гамму и контраст, чтобы получить более четкие результаты. Настройте высокий контраст так, чтобы символы были различимы.
При использовании сканера (или редактора изображений, если нет возможности отсканировать документ еще раз), вы можете настроить гамму и контраст, чтобы получить более четкие результаты. Настройте высокий контраст так, чтобы символы были различимы.
# 4 Увеличить размер текста исходных изображений
Рекомендуемый размер текста в отсканированных документах — 10 пунктов или больше.Для достижения наилучших результатов постарайтесь, чтобы высота текста была не менее 20 пикселей.
Существует минимальный размер текста для разумной точности. Учитывайте разрешение, а также размер точки — точность распознавания падает ниже 10 пунктов, быстро ниже 8 пунктов (с разрешением 300 точек на дюйм). При 10pt и 300 DPI высота по оси x обычно составляет около 20 пикселей. Если высота x меньше 10 пикселей, у вас очень мало шансов на получение точных результатов, а буквы ниже 8 пикселей будут «удалены».
Быстрая проверка — подсчитать пиксели x-высоты ваших символов (x-height — высота нижнего регистра). Вы можете сделать это с помощью инструмента для сохранения снимков экрана (например, Lightshot) или редактора изображений, такого как Photoshop.
Вы можете сделать это с помощью инструмента для сохранения снимков экрана (например, Lightshot) или редактора изображений, такого как Photoshop.
# 5 Выбирайте только те языки, которые содержатся в ваших документах
Если в используемом вами программном обеспечении OCR есть возможность выбирать между языками (например, DocuFreezer), выбирайте только те, которые есть в исходных документах. Чем меньше языков выбрано — тем лучше. Это поможет избежать неправильного толкования персонажей.
# 6 Избегайте поворота или перекоса текста и делайте строки текста горизонтальными
Когда страница была отсканирована не прямо, текст может быть повернут.Если текст страницы слишком перекошен или повернут, это серьезно влияет на качество распознавания текста. Чтобы решить эту проблему, попробуйте снова отсканировать документ, чтобы линии слов были горизонтальными. Или слегка поверните цифровое изображение с помощью редактора изображений.
# 7 Убрать темные границы и другие объекты рядом с персонажами
Отсканированные страницы могут иметь темные края вокруг себя. Их можно обрабатывать как дополнительные символы, особенно если они различаются по форме и градации. Если слишком много шума или объектов, вы можете улучшить изображение с помощью GIMP.Увеличить изображение в 2,5 раза; затем выделите фон возле букв с помощью инструмента Magic Wand и удалите его; повысить резкость изображения с помощью фильтра «Нерезкость меток».
Их можно обрабатывать как дополнительные символы, особенно если они различаются по форме и градации. Если слишком много шума или объектов, вы можете улучшить изображение с помощью GIMP.Увеличить изображение в 2,5 раза; затем выделите фон возле букв с помощью инструмента Magic Wand и удалите его; повысить резкость изображения с помощью фильтра «Нерезкость меток».
Часто невозможно выполнить все эти условия, и может потребоваться вычитка. Вы можете использовать средство проверки грамматики / орфографии, например Grammarly. Всегда проверяйте и исправляйте любые ошибки, прежде чем публиковать текст, созданный с помощью OCR.
PDF7: выполнение оптического распознавания текста в отсканированном документе PDF для получения фактического текста
Цель этого метода — гарантировать, что визуально отображаемый текст
представлен таким образом, что может быть воспринят без его
визуальное представление, мешающее его читабельности.
Документ, состоящий из отсканированных изображений текста, изначально недоступен
потому что содержание документа — изображения, а не текст, доступный для поиска.
Вспомогательные технологии не могут читать или извлекать слова; пользователи не могут
выделять, редактировать, изменять размер или перекомпоновку текста, а также они не могут изменять текст и фон
цвета; и авторы не могут управлять PDF-файлом для обеспечения доступности.
По этим причинам авторам следует использовать фактический текст, а не изображения.
текста, используя инструмент разработки, такой как Microsoft Word или Oracle Open
Office для создания и преобразования содержимого в PDF.
Если авторы не имеют доступа к исходному файлу и инструменту разработки,
отсканированные изображения текста можно преобразовать в PDF с помощью оптических символов
распознавание (OCR). Затем Adobe Acrobat Pro можно использовать для создания доступных
текст.
Этот пример показан с Adobe Acrobat Pro. Существуют и другие программные инструменты, выполняющие аналогичные функции. См. Список других программных инструментов в PDF Authoring Tools, которые обеспечивают поддержку специальных возможностей.
В этом примере используется простое сканированное изображение текста на одной странице.Для обеспечения
что фактический текст хранится в документе, выполните следующие действия:
Отсканируйте документ с максимально возможным разрешением для улучшения
производительность OCR.Загрузите отсканированный документ в Acrobat Acrobat Pro. Выберите Документ> OCR.
Распознавание текста> Распознать текст с помощью OCR …В следующем диалоговом окне выберите переключатель Все страницы в разделе Страницы
(или Текущая страница, если вы конвертируете только одну страницу), а затем выберите
ОК.В списке «Настройки» выберите «Изменить». В следующем диалоговом окне выберите
Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF».
Это важно для обеспечения доступности.В зависимости от разрешения и четкости текста OCR преобразует
изображения слов и символов в фактический текст. Напишите что Acrobat
Pro не распознает, указан как «подозреваемый в распознавании текста» или
текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста с оптическим распознаванием текста»> «Найти».
Первый подозреваемый OCR. Acrobat Pro представляет каждого подозреваемого по одному,
которые можно исправить с помощью инструментов коррекции Acrobat Pro.Запустите Advanced> Accessibility> Add Tags to Document
Test for accessibility: Advanced> Accessibility> Full
Проверить …
 Напишите что Acrobat
Напишите что Acrobat Примечание: В качестве альтернативы вы можете использовать Document> OCR
Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR
в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat.
Pro.
На следующем изображении показано преобразованное содержимое после добавления тегов в
документ. Возможно, потребуется использовать TouchUp Reading
Инструмент заказа и панель тегов, чтобы правильно пометить контент для предполагаемого
итоговый документ. В этом примере изображение спирального переплета книги
был отмечен при преобразовании. Использовался инструмент TouchUp Reading Order.
, чтобы скрыть изображение как фоновое (декоративное) (см. PDF4: Скрытие декоративных изображений с помощью тега Artifact в документах PDF ).Рецепт
заголовки были помечены как заголовки первого уровня.
Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла.
через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
Ресурсы предназначены только для информационных целей, без какой-либо поддержки.
Процедура
Для каждой страницы, преобразованной в текст с помощью OCR, убедитесь, что результат
PDF-файл был преобразован правильно одним из следующих способов:Прочтите PDF-документ с помощью средства чтения с экрана или инструмента, который читает вслух, прислушиваясь к тому, что весь текст читается правильно
и в правильном порядке чтения.Сохраните документ как текст и убедитесь, что преобразованный текст
является полным и в правильном порядке чтения.Используйте инструмент, способный отображать преобразованный контент
чтобы открыть документ PDF и убедиться, что весь текст был преобразован
и находится в правильном порядке чтения.Используйте инструмент, который предоставляет доступ к документу через специальные возможности.
API и убедитесь, что весь текст преобразован и находится в правильном
порядок чтения.
Ожидаемые результаты
Если это достаточный метод для критерия успеха, неудача этой процедуры тестирования не обязательно означает, что критерий успеха не был удовлетворен каким-либо другим способом, только то, что этот метод не был успешным реализованы и не могут использоваться для подтверждения соответствия.
Преобразование изображений в текст на iPhone — приложение для iOS еженедельно
У вас есть сканер, когда у вас есть iPhone. Запустите приложение «Камера» на iPhone, сфотографируйте все, что вам нравится: визитные карточки, журналы, документы, книги, квитанции, доски, бумажные заметки, статьи, затем преобразуйте их в PDF и отправьте всем, с кем хотите поделиться.Все это можно очень легко сделать на iPhone с помощью приложения для сканирования. Ознакомьтесь с этим руководством по преобразованию фотографий и изображений в PDF на iPhone. Или, что еще проще, вы можете просто навести и снимать, тогда файлы будут сохранены в формате PDF напрямую без какого-либо процесса преобразования. См. Подробную информацию в этом руководстве по сканированию бумажных документов в PDF с помощью iPhone. Сегодня мы представим еще одну очень полезную функцию этого приложения для сканера — OCR (Optical Character Reader), которая извлекает текст из PDF-файлов сканера и файлов изображений. Например, если вы отсканировали визитную карточку с помощью мобильного телефона, вы можете использовать утилиту OCR для извлечения телефонных номеров, адреса электронной почты и другой информации из отсканированной визитной карточки. Звучит интересно? Ознакомьтесь с подробностями ниже.
Например, если вы отсканировали визитную карточку с помощью мобильного телефона, вы можете использовать утилиту OCR для извлечения телефонных номеров, адреса электронной почты и другой информации из отсканированной визитной карточки. Звучит интересно? Ознакомьтесь с подробностями ниже.
Преобразование PDF и изображений в текст на iPhone
Скачайте приложение для сканера здесь, если еще нет. Затем следуйте инструкциям ниже, чтобы сканировать бумажные документы в текстовые документы или преобразовывать изображения в текст на iPhone.
Запустите приложение сканера на iPhone, нажмите кнопку Добавить (+) в правом нижнем углу, чтобы открыть экран захвата.Вы можете напрямую сканировать документ на iPhone. В этой демонстрации мы покажем вам, как вместо этого преобразовать существующую фотографию в текст на iPhone. Поэтому коснитесь значка Изображение на нижней панели инструментов, чтобы выбрать и импортировать фотографию, изображение или любой файл изображения, сохраненный в папке «Фотопленка». После того, как файл изображения добавлен в приложение сканера, нажмите кнопку Меню (три точки) в правом верхнем углу, вы увидите всплывающее меню внизу экрана, подобное этому.
После того, как файл изображения добавлен в приложение сканера, нажмите кнопку Меню (три точки) в правом верхнем углу, вы увидите всплывающее меню внизу экрана, подобное этому.
Выберите Распознать текст (OCR) для выполнения OCR, тогда это приложение сканера для iPhone преобразует изображение в текст или мгновенно извлечет текст из изображения.После завершения преобразования на экране вашего iPhone отобразится вкладка с текстом . Нажмите кнопку Копировать все , чтобы скопировать текст, извлеченный из изображения, и вставить его куда угодно: в заметку, электронную почту, текстовые сообщения, разговоры через приложение чата и т. Д.
Связанные страницы
Image to Text: как извлечь текст из изображения
Представьте, что существует простой способ получить или извлечь текст из изображения, отсканированного документа или файла PDF и быстро вставить его в другой документ.
Хорошая новость заключается в том, что вам больше не нужно тратить время на ввод всего текста, потому что есть программы, использующие оптическое распознавание символов (OCR) для анализа букв и слов на изображении, а затем преобразования их в текст.
Существует ряд причин, по которым вы можете захотеть использовать функцию OCR для копирования текста с изображения или PDF.
- Вставьте текст с изображения или снимка экрана в Microsoft Office или другой документ.
- Сохранение текста в сообщении об ошибке, всплывающем окне или меню, где текст не может быть выделен.
- Захватить текст в каталоге файлов (имя файла, размер файла, дата изменения).
Независимо от вашей ситуации, этот тип функциональности может быть полезен, особенно когда вам нужно скопировать информацию из папки с файлами или снимка экрана веб-сайта, что обычно требует от вас значительного количества времени для повторного набора всего текста.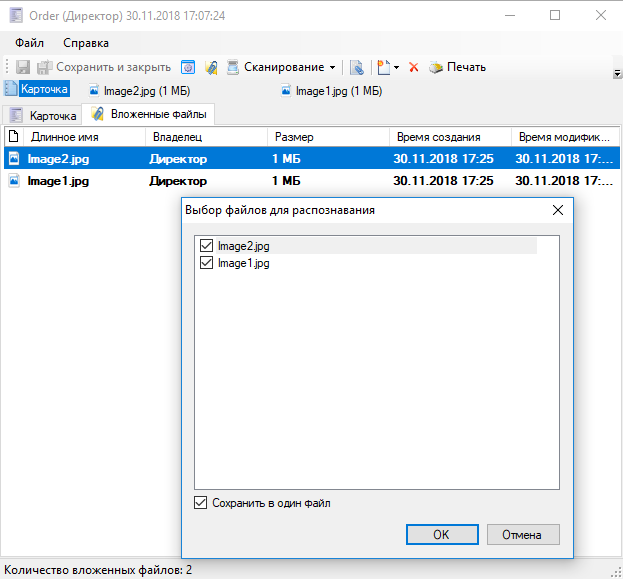
К счастью, есть чрезвычайно простой способ записать текст или преобразовать изображение текста в редактируемый текст.С Snagit достаточно всего нескольких шагов, чтобы быстро получить текст с изображения.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Вот все, что вам нужно знать о том, как снимать текст с экрана компьютера или извлекать текст из изображения.
Как записать текст в Windows или Mac
Шаг 1. Настройте параметры захвата
Чтобы захватить текст, откройте окно захвата, выберите вкладку «Изображение» и выберите «Захватить текст».
Вы также можете ускорить процесс с помощью предустановки «Захват текста».
Шаг 2. Сделайте снимок экрана
Начните захват, затем используйте перекрестие, чтобы выбрать область экрана с нужным текстом.
Snagit анализирует выбранный вами текст и отображает отформатированный текст.
Если указанный шрифт не установлен на вашем компьютере, Snagit заменит его системным шрифтом аналогичного стиля.
Выделите текст, который хотите скопировать, или нажмите «Копировать все…», чтобы скопировать весь текст в буфер обмена.
Шаг 3. Вставьте текст
Наконец, вы можете вставить текст в документ, презентацию или любое другое место назначения.
Изображение в текст: как извлечь текст из изображения с помощью OCR
Шаг 1. Найдите свое изображение
Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе.
Шаг 2. Откройте текст для захвата в Snagit
Откройте изображение в редакторе Snagit, перейдите в меню «Правка» и выберите «Захватить текст».
Или просто щелкните изображение правой кнопкой мыши или щелкните изображение и выберите «Захватить текст».
Шаг 3. Скопируйте текст
Затем скопируйте текст и вставьте его в другие программы и приложения.
И все. Извлечение текста из изображений, PDF-файлов или отсканированных документов не требует больших усилий.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Часто задаваемые вопросы
Как преобразовать изображение в текст?
Загрузите изображение в Snagit.Затем щелкните правой кнопкой мыши в любом месте изображения и выберите «Захватить текст». Это сканирует ваше изображение и преобразует его в текст.
Как извлечь текст из изображения в Windows?
Во-первых, используйте Snagit, чтобы сделать снимок экрана своего изображения или загрузить его в редактор.
Snagit использует программное обеспечение оптического распознавания символов, или OCR, для распознавания и извлечения текста из вашего изображения на вашем компьютере с Windows.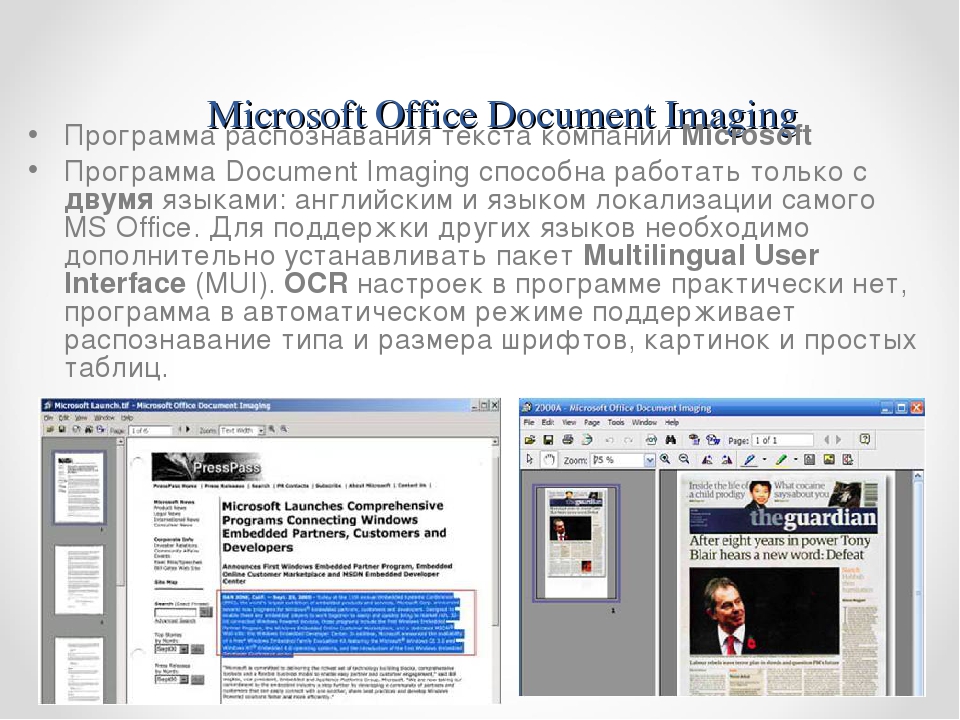
Как извлечь текст из отсканированного PDF-файла?
Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе.Затем просто щелкните изображение правой кнопкой мыши и выберите «Захватить текст».
Текст из отсканированного PDF-файла можно затем скопировать и вставить в другие программы и приложения.
Как скопировать текст с изображения?
Используйте окно захвата изображений Snagit. Затем в раскрывающемся списке выберите «Захватить текст». По завершении появится окно со всем текстом, готовым для копирования и вставки.
Примечание редактора. Этот пост был первоначально опубликован в 2017 году и был обновлен для обеспечения точности и полноты.
Сканировать документы как редактируемый текст (OCR) | UMass Amherst Information Technology
Вы можете использовать сканеры в компьютерных классах ИТ и в библиотеке Learning Commons и Adobe Acrobat Pro для сканирования документа с помощью оптического распознавания символов (OCR), которое экспортирует отсканированный документ в виде PDF-файла, который вы можете прочитать с помощью программа чтения с экрана или с помощью которой можно извлекать текст в текстовый процессор.
Примечание: Если вы используете оптическое распознавание символов по причинам доступности, Центр вспомогательных ИТ-технологий (ATC) может предоставить вам дополнительную помощь.Он расположен на нижнем уровне W.E.B. Библиотека Дюбуа. Для получения дополнительной информации см. Центр вспомогательных технологий (ATC).
- Положите книгу или документ на стекло сканера лицевой стороной вниз.
- На компьютере выберите Пуск> Программы Adobe> Adobe Acrobat 9 Pro . Adobe Acrobat Pro откроется.
Примечание: Не путайте эту программу с Adobe Reader, которая может просматривать файлы PDF, но не создавать их. - В Adobe Acrobat Pro перейдите в Файл> Создать PDF> Со сканера> и выберите соответствующий тип документа:
- Черно-белый документ для текста без изображений или с черно-белыми логотипами или графиками.
- Градации серого Документ для текста с цветными изображениями, которые вы хотите отобразить в оттенках серого.
- Цветной документ для текста с цветными изображениями, которые вы хотели бы иметь в цвете.
- Откроется окно сканирования с индикатором выполнения. Когда сканирование будет завершено, откроется окно Acrobat Scan , предлагающее вам несколько вариантов:
- Выберите Сканирование завершено , если сканирование завершено.
- Выберите Сканировать другие страницы (лист 2) , если следующей отсканированной страницей является , а не , обратная предыдущей странице.
- Выберите Сканировать обратные стороны (обратная сторона листа 1) , если следующая страница для сканирования является обратной предыдущей страницы.
- Нажмите ОК . Acrobat автоматически повернет и обработает отсканированный документ, «прочитает» текст, а затем создаст файл PDF. Сохраните этот файл перед внесением изменений! Затем вы можете:
- Скопируйте / вставьте текст из вашего PDF-файла в Word или любой другой текстовый редактор.
- Перейдите в Файл> Экспорт> Текст> Текст (доступно) , чтобы сохранить PDF-файл в виде простого текстового файла (рекомендуется).
- Перейдите в Файл> Сохранить как … и в раскрывающемся меню Тип файла: выберите MS Word Doc (.doc) , чтобы сохранить PDF-файл как документ Microsoft Word.
- Скопируйте / вставьте текст из вашего PDF-файла в Word или любой другой текстовый редактор.
- Не забудьте вынуть документ из сканера!


Примечание: Хотя процесс распознавания текста и экспорта файлов довольно точен, он не идеален.Возможно, вам придется «очистить» или исправить макет полученного текста и проверить орфографические ошибки.
После сканирования документа (ов)
- Сохраните отсканированные изображения на USB-накопитель или другой съемный носитель.
- Вы также можете сохранить отсканированные изображения в онлайн-хранилище. Чтобы войти в систему или узнать больше о вариантах онлайн-хранилища в UMass Amherst, перейдите на umass. edu/it/online-storage-collaboration.
- Чтобы распечатать отсканированные изображения в Learning Commons, вы можете использовать нашу услугу Pay-for-Print.Посетите нашу страницу с оплатой за печать для получения инструкций.
 edu/it/online-storage-collaboration.
edu/it/online-storage-collaboration.Как программное обеспечение OCR, как преобразовать PDF в текст, OCR PDF
Распознавание текста в отсканированных PDF-документах с помощью Acrobat X
Ян Кэмпбелл — , 12 октября 2010 г.
Привет.
Я Ян Кэмпбелл, и в этом видео мы покажем вам, как использовать новую панель «Распознать текст» в Acrobat X, чтобы сделать отсканированный текст доступным для поиска в вашем файле PDF, а также исправить любые ошибки распознавания.
Между прочим, технический термин для распознавания печатного текста на изображениях — OCR — это «оптическое распознавание символов». Вот документ, который был преобразован из набора файлов TIFF в PDF.
Посмотрите соответствующий видеоролик: «Преобразование отсканированных документов в файлы PDF», чтобы узнать, как преобразовать файлы изображений. На данный момент этот документ не доступен для поиска — он содержит только изображения отсканированных страниц.
На данный момент этот документ не доступен для поиска — он содержит только изображения отсканированных страниц.
Если я попытаюсь подобрать слово, Acrobat выдаст нам сообщение об ошибке.Однако если я открою новую область инструментов Acrobat X, я сразу же увижу функцию «Распознать текст», и щелкнув ее, вы увидите параметры панели.
Кстати, если по какой-то причине панель «Распознать текст» была отключена, вы можете щелкнуть здесь, чтобы открыть эту или любую другую панель. Я собираюсь выбрать опцию «Распознать текст в этом файле» и просто выбрать оптическое распознавание текста. текущая страница для скорости.
Поскольку я впервые использую функцию распознавания текста в Acrobat, я нажимаю «Правка», чтобы изменить некоторые настройки.
Основным языком, используемым в этом документе, является американский английский, поэтому я выберу «Английский (США)».
Для стиля вывода PDF мне обычно нравится выбирать ClearScan, так как это создает очень компактный, но доступный для поиска PDF-файл. Однако здесь мой оригинал был юридическим документом, поэтому я хочу убедиться, что доступный для поиска PDF-файл содержит отсканированное изображение из оригинала.
Однако здесь мой оригинал был юридическим документом, поэтому я хочу убедиться, что доступный для поиска PDF-файл содержит отсканированное изображение из оригинала.
Выбор «Изображение с возможностью поиска» в качестве стиля вывода сохраняет изображение страницы, но добавляет под ним слой текста с возможностью поиска.
Содержание изображения может быть субдискретизировано, чтобы сохранить размер файла на управляемом уровне.
Если бы этот документ был критически важным, я мог бы использовать опцию «Изображение с возможностью поиска (точное)» — в этом случае изображение сохраняется точно так же, как оно было отсканировано, чтобы сохранить полную аутентичность. Теперь я соглашусь с этим выбором и скажу ОК запустить процесс распознавания текста.
Параметр «Изображение с возможностью поиска» включает в себя некоторую очистку изображения, такую как выравнивание или выравнивание страницы, а также делает страницу доступной для поиска.Давайте попробуем найти слово — «вечеринка» — документ определенно доступен для поиска, но у нас все еще есть изображение отсканированной страницы, на которое можно ссылаться.
Еще одно преимущество использования опции OCR «Изображение с возможностью поиска» заключается в том, что мы можем попросить Acrobat X идентифицировать любые преобразования слов, в которых он не уверен, и позволить нам исправить их вручную.
Я мог бы выбрать показ всех подозрительных слов сразу, но для этой демонстрации мы выберем «Найти первого подозреваемого», поскольку это позволяет нам перемещаться по подозреваемым по одному.
Итак, первым обнаруженным подозреваемым является слово «длинный».
Если мы щелкнем по слову на странице, мы увидим, что Acrobat действительно распознал и написал слово правильно, поэтому мы можем выбрать Принять и Найти, чтобы перейти к следующему подозреваемому. Следующее слово, в котором он не совсем уверен, — это «отношения» ‘- но на самом деле, опять же, Acrobat правильно преобразовал отсканированное слово.
С другой стороны, теперь мы видим, где Acrobat допустил ошибку — со словом, которое мы почти можем разобрать как «предоставление».
Добавить комментарий