Конвертирование отсканированного PDF в редактируемый текст
Испытываете сложности при работе с отсканированными PDF-файлами? Ищете способ быстро преобразовывать отсканированные PDF в текст? Мы предлагаем два эффективных решения данной проблемы. Сначала мы поговорим о том, как распознавать текст в Google Drive, а затем я представлю вам лучшее решение этой задачи — PDFelement.
Как использовать альтернативы Google Диска для распознавания текста
PDFelement сочетает функции создания, редактирования, аннотирования и преобразования файлов в одной программе. Функция OCR в данной программе позволяет с легкостью распознавать ваши отсканированные или основанные на изображениях PDF-документы и превращать их в редактируемый текст. Функция распознавания текста поддерживает широкий спектр языков, таких как английский, корейский, немецкий, румынский, итальянский, португальский, испанский и другие.
Шаг 1.
 Открытие отсканированного PDF-файла
Открытие отсканированного PDF-файла
После установки PDFelement откройте отсканированный PDF-документ с помощью этой программы. Для этого вы можете нажать кнопку «Открыть файл…» и ваш файл будет открыт прямо в PDFelement.
Шаг 2. Распознавание текста PDF без конвертирования
Программа напомнит вам выполнить распознавание текста после загрузки отсканированного PDF. Нажмите кнопку «Распознать текст» в верхней информационной панели и выберите нужный язык. Через некоторое время отсканированный PDF будет преобразован в редактируемый формат. Если вам нужно внести изменения в получившийся документ, нажмите «Редактировать» в левом верхнем углу экрана.
Шаг 3. Конвертирование PDF в текст с помощью функции распознавания текста
Если вам нужно экспортировать отсканированный PDF в текстовый формат, перейдите во вкладку «Главная», нажмите кнопку «В другие формату» и выберите опцию «Преобразовать в текст». Затем установите флажок «Настройки» > «Включить распознавание» во всплывающем окне. Нажмите «Сохранить», чтобы запустить процесс распознавания.
Затем установите флажок «Настройки» > «Включить распознавание» во всплывающем окне. Нажмите «Сохранить», чтобы запустить процесс распознавания.
Чтобы установить язык распознавания, перейдите в меню «Файл > Настройки» и выберите нужный язык во вкладке «Распознавание (OCR)».
Благодаря мощному функционалу вы можете редактировать текст PDF, менять изображения и размечать контент с легкостью. Помимо редактирования вы можете аннотировать, шифровать PDF, конвертировать в другие форматы, создавать заполняемые формы и т.д.
Как использовать Google Диск для распознавания текста
Шаг 1. Импортирование PDF-файла, созданного на основе изображений
После входа в учетную запись Google Диск вы можете загрузить в нее свое изображение или отсканированный файл.
Шаг 2. Распознавание текста в Google Документах
Выберите загруженный файл и откройте его с помощью Google Документы. При открытии файла в Google Документах подключается опция распознавания символов Google Drive OCR. Текст в файле с изображениями теперь можно редактировать.
При открытии файла в Google Документах подключается опция распознавания символов Google Drive OCR. Текст в файле с изображениями теперь можно редактировать.
Шаг 3. Сохранение файла
Нажмите кнопку «Файл» > «Скачать», чтобы выбрать формат его сохранения на своем компьютере.
Вот как можно использовать функцию распознавания символов Google Docs для преобразования отсканированного PDF в текст. Это достаточно удобно, но в Google Документах нельзя сохранить форматирование и конфигурацию PDF-файла. После работы с Google Drive OCR вы можете обнаружить, что текст исходного файла было изменен. Если вы хотите сохранить исходное форматирование и конфигурацию PDF, попробуйте Wondershare PDFelement.
Распознать текст из пдф в ворд бесплатно
Как отредактировать текст из PDF-файла? Преобразуйте PDF в текстовый документ при помощи функции оптического распознавания символов (OCR). Если вам надо извлечь текст, студия PDF2Go — идеальное решение.
- Загрузите PDF-документ.
- Нажмите на «Сохранить изменения».
Оставайтесь на связи:
Преобразуйте PDF в текст при помощи функции OCR
бесплатно в любом месте
Преобразование PDF в текстовый файл
Вам доводилось редактировать текст в PDF-файле? Мы знаем, как справиться с этой задачей. Преобразуйте PDF-документ в простой текстовый файл при помощи функции оптического распознавания символов (OCR).
Просто загрузите PDF, а мы сделаем всё остальное. После загрузки документа на PDF2Go мы извлечём текст при помощи функции OCR и создадим файл формата TXT.
Просто и безопасно
PDF2Go не занимает место в телефоне и не представляет угрозы для компьютера.
Этот конвертер с функцией OCR работает онлайн и не требует регистрации или установки приложения для извлечения текста из PDF-файлов.
Для сканов и не только
Вам больше не надо перепечатывать отсканированную книгу или статью вручную. Наш онлайн-инструмент позволяет преобразовать PDF-файл и извлечь текст из любого скана (даже с картинки!).
Если у вас есть PDF, в котором нельзя редактировать текст, воспользуйтесь нашим конвертером, чтобы преобразовать документ в текстовый файл формата TXT.
Переживаете за безопасность?
Когда загружаешь PDF на сайт для преобразования в текстовый формат, последнее, о чём хочется беспокоиться, — что станет с файлом. Мы избавим вас от сомнений.
Все права остаются за вами, никто не просматривает содержимое файлов. Читайте подробности в Политике конфиденциальности.
Что можно преобразовать?
Этот онлайн-конвертер отвечает поставленной задаче: вы можете преобразовать PDF в текстовый формат. Из любого PDF-файла можно получить редактируемый текст.
Из:
В:
Текстовый файл TXT
Оптическое распознавание символов
Всё, что вам потребуется для преобразования PDF-файла на сайте PDF2Go — это надёжное подключение к сети и браузер. Приложение работает с любого устройства. Конвертируйте PDF-файлы в формат TXT:
- дома
- на работе
- в пути
- в любом удобном месте
Вам надо сконвертировать и скачать хотя бы один файл, чтобы оценить конвертацию
Сконвертируйте ваши pdf-файлы в doc онлайн и бесплатно
- Image
- Document
- Ebook
- Audio
- Archive
- V >
- abc
- abw
- csv
- dbk
- djvu
- dng
- doc
- docm
- docx
- erf
- ebm
- ewm
- emw
- gzip
- kwd
- odt
- oxps
- ppt
- pptx
- rtf
- rar
- txt
- wps
- xls
- xlsx
- zip
- Image
- Document
- Ebook
- Audio
- Archive
- V >
- abc
- abw
- csv
- dbk
- djvu
- dng
- doc
- docm
- docx
- erf
- ebm
- ewm
- emw
- gzip
- kwd
- odt
- oxps
- ppt
- pptx
- rtf
- rar
- txt
- wps
- xls
- xlsx
- zip
Портативный формат документов
PDF ― это формат электронных документов, разработанный Adobe Systems с использованием некоторых функций языка PostScript. Официальная программа для просмотра документов в этом формате ― это Adobe Reader. Чаще всего PDF-файл представляет собой сочетание текста с растровой и векторной графикой, текстовыми формами, скриптами, написанными на JavaScript, а также иными элементами.
Документ Microsoft Word
DOC ― это расширение файлов для документов текстового редактора. Оно связано преимущественно с приложением Microsoft Word. Файлы DOC также могут содержать графики, таблицы, видео, изображения, звуки и диаграммы. Этот формат поддерживается почти всеми операционными системами.
| Шаг 1. Загрузка. | Шаг 2. Конвертация. | Шаг 3. Скачивание. |
Перетащите PDF в это окно —>
| Или нажмите сюда и выберите файл на компьютере |
Нажмите для загрузки
Как конвертировать PDF в Word
На этом сайте вы можете абсолютно бесплатно перевести PDF в Word. Конвертация происходит очень просто.
Шаг 1. Загрузите PDF документ на сайт. Это можно сделать простым перетаскиванием или с помощью клика по конвертеру (откроется файловый менеджер). Обратите внимание, что к конвертации принимаются только файлы с расширением .pdf.
| Загрузите PDF в это окно | Подождите, пока файл зальется на сервер |
Шаг 2. Дождитесь своей очереди. Очереди может и не быть. Но часто, особенно днем, файлы конвертируют одновременно несколько пользователей. А поскольку преобразование PDF в Word является довольно ресурсоемкой операцией, то все файлы выстраиваются в очередь и конвертируются по одному. Обычно, очередь занимает не больше 2-5 минут.
| Процесс конвертации PDF в Word |
Шаг 3. Скачайте готовый Word файл. После окончания конвретации вы можете сохранить готовый Word в формате .doc. Обратите внимание, что файлы удаляются с нашего сервера сразу после того, как вы покидаете сайт.
| Word успешно сконвертирован |
Какие PDF файлы можно преобразовать?
Конвертер pdf2word поддерживает все виды PDF файлов, кроме отсканированных картинок. Поскольку распознавание текста пока не поддерживается, то преобразование в текст сканов и фотографий в данный момент не доступно. Мы работаем над этой функцией и собираемся ввести ее в самое ближайшее время.
Остальные PDF документы можно конвертировать без проблем. Особенно наш онлайн конвертер пригодится представителям бизнеса, которым постоянно требуется переводить в формат Word прайс-листы, договора и прочее. Преимущество .doc файлов перед PDF заключается в том, что их можно легко редактировать и отправлять своим деловым партнерам. Поэтому, вместо того, чтобы заново создавать на компьютере какой-либо документ с изменениями, можно просто сделать Word из PDF онлайн.
ТОП-2 программ PDF OCR на базе Mac для легкого чтения PDF
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) — технология редактирования и преобразования отсканированного текста или PDF-файлов в редактируемые и доступные для поиска текстовые документы. Как известно, файл PDF на основе изображения нельзя отредактировать, преобразовать или изменить, но ситуация сразу поменяется, если у вас в арсенале имеется мощное программное обеспечение PDF OCR. В интернете вы можете найти множество онлайн PDF OCR для Mac, но большая часть их функций OCR не работает достаточно хорошо. Не беспокойтесь! Здесь мы с вами разберем ТОП-3 лучших программ PDF OCR для Mac (macOS 10.14 Mojave включительно).
Часть 1. Список лучших программ Mac OCR
Существует широкий выбор бесплатного программного обеспечения OCR. Здесь мы рассмотрим некоторые наглядные примеры.
#1. PDFelement Pro для Mac
PDFelement ProPDFelement Pro это приложение оптического распознавания текста, которое дает возможность создавать PDF полностью доступных для поиска, файлы расширенных текстовых форматов RTF, HTML и файлы с обычным текстом из ваших отсканированных документов с помощью OCR. Также эта программа поддерживает более 20 языков и Applescript для пакетной обработки файлов.
Скачать бесплатно
Скачать бесплатно
Кроме OCR, это программное обеспечение упрощает редактирование и преобразование отсканированного PDF-файла. Вы можете свободно изменять тексты, изображения и страницы, выделять и писать примечания, добавлять настраиваемые водяные знаки и подписи, добавлять пароль к PDF и т. д. С его помощью вы можете даже легко создавать и конвертировать PDF в другие популярные форматы файлов. Это программное обеспечение полностью совместимо с Mac OS X 10.7 или более поздней версией, включая последнюю Mac OS Mojave 10.14.
Почему именно этот редактор PDF:
- Современная технология OCR с поддержкой множества языков.
- Редактируйте отсканированные PDF с помощью встроенных инструментов редактирования.
- Конвертируйте отсканированные PDF в Word, Excel, PPT, HTML, др.
- С легкостью создавайте и редактируйте формы PDF.
- Создавайте формы PDF из существующих PDF, изображений, сайтов и др.
- Добавляйте примечания или комментарии на PDF с помощью инструментов надписи и настраиваемых комментариев.
#2. Abbyy FineReader Pro для Mac
Abbyy FineReader Pro для Mac-это еще одно специальное приложение OCR с понятным пользовательским интерфейсом и простым процессом работы с документами, который упрощает получение редактируемых документов. Это ПО предлагает наиболее популярные языки из доступных 180, и может экспортировать данные в PDF, документы Word, Excel и HTML. Благодаря возможности пакетной обработки, включая его совместимость с Applescript, FineReader предоставляет возможность комплексного использования OCR технологии.
Как использовать технологию OCR в работе с PDF на Mac OS X (macOS Mojave включительно)
Использование PDFelement ProPDFelement Pro для оптического распознавания текста в ваших документах – проще простого. Рассмотрим более детально.
Скачать бесплатно
Скачать бесплатно
Шаг 1. Откройте PDF-документ в программе
Откройте PDF Editor Pro для Mac и перетащите файл PDF в программу. Кроме того, Вы также можете выбрать опцию «Open» (Открыть) или «Open Recent» (Открыть недавние). Затем вы можете установить язык. Чтобы сделать это, вы перейдите к настройкам и нажмите на вкладку OCR, и выберите язык, который вам нужен.
Шаг 2. Начните процесс оптического распознавания текста PDF
Теперь нажмите кнопку «OCR» на вкладке «Edit» (Редактировать). Затем в правой части главного интерфейса программы появится панель OCR. Здесь можно выбрать диапазон страниц и язык распознавания. Затем вы можете нажать на кнопку «Perform OCR» (Выполнить OCR) для распознавания отсканированного PDF. Для пакетного распознавания нескольких отсканированных PDF файлов, вы можете выбрать «Batch Process» (Пакетная обработка). И нажмите на кнопку «OCR» > «Add Files» (Добавить файлы) в новом окне, чтобы импортировать несколько отсканированных PDF-файлов. После того как вы выбрали язык, вы можете нажать на «Выполнить OCR» нескольких файлов PDF в одно время.
Не удается найти страницу | Autodesk Knowledge Network
(* {{l10n_strings.REQUIRED_FIELD}})
{{l10n_strings.CREATE_NEW_COLLECTION}}*
{{l10n_strings.ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.COLLECTION_DESCRIPTION}}
{{addToCollection.description.length}}/500
{{l10n_strings.TAGS}}
{{$item}}
{{l10n_strings.PRODUCTS}}
{{l10n_strings.DRAG_TEXT}}
{{l10n_strings.DRAG_TEXT_HELP}}
{{l10n_strings.LANGUAGE}}
{{$select.selected.display}}
{{article.content_lang.display}}
{{l10n_strings.AUTHOR}}
{{l10n_strings.AUTHOR_TOOLTIP_TEXT}}
{{$select.selected.display}}
{{l10n_strings.CREATE_AND_ADD_TO_COLLECTION_MODAL_BUTTON}}
{{l10n_strings.CREATE_A_COLLECTION_ERROR}}
Как создать PDF со отсканированными страницами, но выбрать текст?
Но как это возможно?
По сути, программа выполняет OCR для входного файла, а затем помещает невидимый слой текста поверх изображения. Кроме того, он может также поместить видимый слой текста под картинкой, давая тот же эффект.
Когда вы выбираете что-то, картинка не имеет значения, потому что текстовый слой выделен.
как это можно создать?
Есть несколько способов. Учитывая, что Acrobat уже был предложен, я добавлю несколько бесплатных опций (и, к счастью, вы не обязаны использовать их в Windows).
Это родная программа для Windows от Tracker Software . Бесплатная версия прекрасно работает под Wine, если вы используете 32-разрядную версию с 32-разрядным префиксом, поэтому вы можете использовать ее в Windows, macOS и Linux. В последних двух случаях вам понадобятся PlayOnMac или PlayOnLinux соответственно.
Вот фотография из этого ответа, которую я оставил в Ask Ubuntu:
Это мультиплатформенная программа, написанная на Python , основанная на Ghostscript, Tesseract и Unpaper. Из документов:
Что делает OCRmyPDF
OCRmyPDF анализирует каждую страницу PDF-файла, чтобы определить цветовое пространство и разрешение (DPI), необходимые для захвата всей информации на этой странице без потери содержимого. Он использует Ghostscript для растеризации страницы, а затем выполняет OCR на растровом изображении, чтобы создать «слой» OCR. Затем слой снова возвращается в исходный файл PDF.
Его можно легко установить на производные Debian и Ubuntu:
apt-get install ocrmypdf
Или на macOS:
brew tap jbarlow83/ocrmypdf
brew install ocrmypdf
В Windows вам нужно использовать образ Docker. Смотрите официальные документы для деталей.
Использование очень простое, и я предлагаю вам использовать необязательные -d(deskew) и -c(clean) параметры для лучшего результата. Это выровняет каждую страницу и очистит маленькие точки / недостатки перед запуском процесса OCR.
Вы можете (и должны) предоставить язык -l.
Вот пример, взятый из этого искаженного документа, написанного на итальянском языке:
Команда, которую я использовал, была:
ocrmypdf -l ita -d -c input.pdf output.pdf
Есть несколько онлайн-инструментов, которые делают то же самое. Примечательно, что PDF24 содержит бесплатную веб-версию OCRmyPDF, которую можно использовать без ограничений.
Смотрите также:
Как скопировать текст из файла PDF — Сеть без проблем
Если вы хотите скопировать текст из файла PDF для добавления в документ Word, вставить формулу в электронную таблицу Excel или вставить в слайды PowerPoint для презентации, это можно сделать так же просто, как с помощью функции «Копировать и вставить».
Однако это может не обязательно работать для всех файлов PDF из-за безопасности и других разрешений, но есть и другие способы выполнения той же задачи.
Как скопировать текст из PDF
Прежде чем вы сможете скопировать текст из PDF в другое приложение, вы должны подтвердить, что в нем нет настроек безопасности, которые запрещают копирование, иначе вы не сможете ничего копировать. На это может указывать функция копирования, выделенная серым цветом или затемненная в Reader.
Если полученный PDF-файл защищен паролем, откройте его с помощью указанной комбинации паролей, а затем проверьте параметры безопасности, чтобы подтвердить, что копирование содержимого разрешено.
- Для этого щелкните документ правой кнопкой мыши и выберите « Свойства документа».
- Перейдите на вкладку « Безопасность » и просмотрите сводку ограничений по документам, чтобы узнать, разрешено или нет копирование содержимого.
- Откройте PDF-файл в любом приложении для чтения, а затем скопируйте нужный текст одним из следующих способов.
Существует несколько способов копирования текста из файла PDF, которые мы рассмотрим в этом руководстве.
Функция копирования и вставки
Это де-факто метод копирования текста из большинства документов или файлов, а не только из PDF-файлов. Вы можете использовать сочетание клавиш CTRL + C, чтобы скопировать нужный текст, а затем использовать CTRL + V, чтобы вставить его в другой документ.
Если вы используете Mac, нажмите Command-C, чтобы скопировать текст, и Command-V, чтобы вставить содержимое буфера обмена в текущий документ или приложение.
Кроме того, вы можете использовать правую кнопку мыши или сенсорной панели и выбрать инструмент «Выбор» .
Выделите текст, который вы хотите скопировать в документе PDF, перетащив мышью, чтобы выделить часть, которую вы хотите скопировать, щелкните правой кнопкой мыши выделенный текст и выберите « Копировать» .
Вы также можете перейти на вкладку меню и нажать « Правка»> «Копировать» . После того, как он скопирован, перейдите к документу, в который вы хотите вставить скопированный текст, щелкните правой кнопкой мыши место, в котором вы хотите разместить его, и выберите «Вставить» или нажмите « Правка»> «Вставить» .
Инструмент для создания снимков или снимков экрана
Инструмент «Снимок» в программе чтения PDF-файлов поможет вам выбрать нужный текст в виде скриншота или рисунка, а затем вставить его в другой документ, не затрагивая форматирование. Если вы выберете этот метод, вы получите именно ту часть текста, которая вам нужна, но она не будет редактируемой.
Для этого откройте документ PDF, нажмите «Правка» > «Сделать снимок».
В качестве альтернативы, выберите строку заголовка окна PDF и нажмите Alt + PrtScn на клавиатуре, чтобы сделать снимок экрана, а затем обрезать на основе нужной части.
Если вы используете Mac, нажмите Ctrl + Shift + 4 и используйте курсор на экране, чтобы перетащить и выбрать текст, который вы хотите захватить.
Интернет PDF Reader
Вы можете скопировать текст из PDF-документа в браузере или онлайн-ридере.
Для этого откройте PDF-файл в браузере, щелкнув правой кнопкой мыши файл и выбрав « Открыть с помощью»> (выберите браузер) или перетащите его в открытое окно браузера.
Выберите текст, который вы хотите. Нажмите CTRL + C, чтобы скопировать текст и вставить его в другой документ, используя CTRL + V. Вы также можете щелкнуть правой кнопкой мыши по сенсорной панели и выбрать « Копировать» , а затем снова щелкнуть правой кнопкой мыши другой документ и выбрать « Вставить» .
Программное обеспечение для извлечения PDF
Сторонний инструмент для извлечения PDF также может помочь вам извлечь текст для использования в другом приложении, таком как Word, презентация PowerPoint или программное обеспечение для настольных издательских систем.
Вы можете использовать такой инструмент, как ExtractPDF, загрузить свой PDF и нажать Пуск. Инструмент будет извлекать изображения, текст или даже шрифты, если вы хотите, после чего вы можете скопировать то, что вы хотите из извлеченного контента и вставить его в другое приложение.
Существует множество сторонних инструментов извлечения файлов PDF, которые преобразуют их в HTML, сохраняя при этом макет страницы. Они также извлекают и преобразуют содержимое документа PDF в форматы векторной графики, которые можно использовать в других приложениях.
PDF Converter
Конвертер PDF позволяет вам конвертировать документ PDF в редактируемый документ , после чего вы можете скопировать свой текст и использовать его в другом приложении.
Одним из популярных PDF-конвертеров является SmallPDF, потому что это онлайн-инструмент, поэтому он не требует установки и прост в использовании. Чтобы использовать его, откройте SmallPDF в браузере, выберите формат вывода, например, PDF в Word .
Нажмите «Выбрать файл», чтобы загрузить PDF-файл, который вы хотите преобразовать.
Нажмите Загрузить, чтобы сохранить преобразованный файл на вашем устройстве. Затем откройте преобразованный документ Word и скопируйте нужный текст.
Инструмент OCR
Инструмент оптического распознавания символов (OCR) позволяет преобразовывать файл PDF в редактируемый документ Word, копировать текст из файлов PDF и сканированные изображения в редактируемые текстовые форматы.
Это особенно полезно, если вы получили отсканированный документ в формате PDF, поскольку он мгновенно превращает такие файлы в редактируемые PDF-файлы с пользовательскими шрифтами и редактируемым текстом, которые выглядят так же, как и в исходном документе.
Adobe Acrobat работает как текстовый конвертер с OCR, так как он автоматически извлекает текст из отсканированных изображений или бумажных документов и преобразует их в PDF-файлы.
Самое приятное то, что ваш PDF будет соответствовать оригинальной распечатке благодаря автоматическому созданию пользовательских шрифтов , и вы можете использовать его с другими приложениями Office, вырезая и вставляя или экспортируя в MS-Office. Это также позволяет вам сохранить точный внешний вид документа и ограничить редактирование содержимого.
Примечание. Для выполнения этих действий необходим Adobe Acrobat, а не Adobe Reader, поскольку последний предназначен только для просмотра PDF-файлов и не имеет инструмента OCR.
Чтобы использовать собственный инструмент OCR в Adobe Acrobat, откройте PDF-файл, содержащий отсканированный текст или изображение, в Acrobat для ПК или Mac и нажмите « Редактировать PDF» .
Acrobat автоматически применяет OCR к PDF и преобразует его в полностью редактируемую копию. Выделите текст, который хотите скопировать, и нажмите « Правка»> «Копировать» , а затем вставьте его в другое приложение.
Вы можете нажать Файл> Сохранить как, чтобы сохранить редактируемый документ для последующего использования.
Либо откройте отсканированный документ или изображение, с которым вы хотите использовать устройство чтения OCR, нажмите « Инструменты» в верхней правой части панели инструментов и выберите « Распознать текст»> «В этом файле» .
Вы увидите всплывающее окно с текущими общими настройками, такими как язык распознавания текста, стиль вывода PDF и разрешение. Нажмите OK, чтобы текст был распознан.
Если вы хотите изменить настройки, нажмите кнопку « Изменить» , а затем нажмите кнопку «ОК» после завершения.
Как только текст распознан на отсканированной странице, вы можете выбрать и скопировать нужный текст с обнаруженным форматированием, хотя это не так точно, как распознавание текста.
Если у вас есть только Adobe Reader и вы не хотите получать копию Acrobat, есть бесплатные инструменты OCR, такие как OCR OneNote для ПК, который можно использовать бесплатно, или библиотека Tesseract OCR для Mac.
Примечание. Если у вас есть Adobe Acrobat, вы можете распознать несколько документов одновременно. Просто откройте любой документ в Acrobat, нажмите « Распознать текст» на боковой панели « Инструменты» и выберите «В нескольких файлах». Перетащите PDF-файлы, которые вы хотите, в OCR, и Acrobat распознает текст для вас.
Есть ли у вас какие-либо другие приемы, которые вы используете для копирования текста из файла PDF? Расскажите нам об этом в комментарии ниже.
Статьи по теме:
Как распознать PDF текст онлайн
Привет, друзья! Если у вас возникла необходимость распознать PDF-документ, конвертировать в текстовый формат Word или таблицу Excel – это можно сделать бесплатно в режиме онлайн, без установки на компьютер специального программного обеспечения.
Как распознать PDF документ онлайн
Формат PDF предназначен для подготовки полиграфической продукции к распечатке. Документы PDF не особенно комфортны для изучения на экране компьютера, тем более на маленьких экранах смартфонов и планшетов.
В формате PDF часто предлагаются в интернете инструкции и технические описания к разного рода оборудованию и бытовой технике, описания тарифов мобильных операторов, каталоги планов по кредитам и банковским картам. Получается, что обращаться с такими форматами файлов приходится время от времени всем пользователям, а не только инженерам и студентам.
В то же время, редактирование PDF-документов в специальном приложении типа Adobe Acrobat или Foxit Reader сложно и требует определенного опыта.
Поэтому часто оказывается быстрее и удобнее распознать PDF в Word или Excel, используя онлайн-конвертер. После этого можно редактировать файлы в привычных текстовых и табличных приложениях.
В интернете можно найти довольно много сервисов, позволяющих конвертировать PDF в другие форматы. Сегодня вашему вниманию предлагается исследование и сравнение нескольких таких ресурсов. В качестве критериев оценки взяты следующие факторы:
- Бесплатность сервиса.
- Отсутствие обязательной регистрации. Если работать приходится на чужом компьютере, регистрация может быть затруднена или нежелательна.
- Возможность распознать многостраничные PDF-документы. Чтобы выделить отдельные страницы из PDF-файла, потребовалось бы дополнительное ПО, что не всегда доступно.
- Качество получаемых текстовых документов.
- Возможность перевода изображений и таблиц в текстовые форматы без потери качества.
- Интуитивность и простота сервиса (юзабилити).
Итак, сегодня мы возьмем несколько онлайн-конвертеров PDF и проведем сравнительное тестирование. Надеемся, что проведенные нами эксперименты помогут нашим читателям в работе и избавят от затрат времени и сил на собственные поиски.
Как бесплатно распознать pdf формат в word или exel
Convertio.co
Сервис Convertio – это многофункциональный, универсальный конвертер для преобразования множества форматов файлов в другие. Кроме того, имеется функция распознавания изображений и перевода надписей на картинках в редактируемые текстовые форматы.
- К сожалению, бесплатно разрешается преобразовать всего 10 страниц PDF-документа. Плюс – можно выбрать любые нужные страницы для конвертации.
- Регистрация для пробного обращения не требуется.
- Большое количество настроек и предварительных установок при конвертации.
Переходим в нужный нам раздел и попробуем преобразовать инструкцию к водонагревателю в формате PDF в текстовый документ. Доступны форматы не только MS Word, но и множество других – простой и форматированный текст (RTF, TXT), некоторые форматы электронных книг и табличный Excel.
Исходный документ PDF можно загрузить непосредственно с жесткого диска компьютера.
В процессе подготовки к конвертации необходимо указать, какие именно страницы требуется преобразовать, какой выходящий формат желателен, отметить основной и дополнительный языки текста.
Процесс распознавания и конвертации пяти страниц происходит несколько минут, довольно долго. Однако результат порадовал качеством. Вот как наша инструкция стала выглядеть в worde.
Картинки и чертежи выглядят великолепно, четко и разборчиво. Таблица тоже отлично получилась.
Полностью сохранена структура исходного документа, никаких искажений не выявлено. Кириллица и латиница переданы без нарушений. Теперь давайте преобразуем нашу инструкцию в таблицу Excel. Таблица в инструкции находится на 5-й странице, так что ее одну и пустим в обработку. Посмотрим, как выглядит таблица.
И в этом случае сервис отлично справился, контент передан четко и находится на своих местах.
Вердикт. Convertio – отличный онлайн-конвертер pdf формата. Недостаток один – всего 10 страниц разрешается обработать бесплатно и без регистрации. Коммерческий тариф – от $7.99 за 100 страниц. По мере увеличения количества оплаченных страниц цена снижается. Для регистрации требуется только адрес электронной почты.
Onlineocr.net
Многофункциональный сервис Onlineocr.net, позволяющий распознавать и преобразовывать изображения и файлы PDF в Word, Excel и Text.
- Бесплатно и без регистрации дозволено конвертировать до 15 документов в час.
- Выходные файлы сохраняют исходную структуру документов.
- Однако есть проблема – без регистрации можно обрабатывать только одностраничные документы. Чтобы преобразовать файл, содержащий несколько страниц, необходима регистрация в сервисе (и оплата услуг).
Как преимущество этого онлайн-конвертера можно указать на простой, наглядный пошаговый алгоритм работы с сервисом. Думать и пытаться понять, как это работает, не придется. Все шаги наглядны и дополнительно сопровождаются текстовыми объяснениями.
Конечно, это не очень удобно, что для распознавания многостраничных документов требуют регистрацию. Зато имеется интересная партнерская программа. Прилагая некоторые усилия к популяризации сервиса Onlineocr.net, можно в благодарность получить бесплатные возможности для конвертации сотен и даже тысяч страниц.
Pdf2word.ru
Данный сервис имеет строгую и узкую специализацию – только распознавание PDF в DOCX. Вот мы загрузили нашу подопытную инструкцию с жесткого диска и процесс пошел. На экране демонстрируется степень обработки файла.
Нажимать кнопки не приходится, после загрузки файла обработка началась автоматически. После закачки файла сразу началась конвертация. Процесс идет довольно долго (тестовый документ PDF состоит из более 50 страниц).
На конвертацию ушло более 5 минут. И это с учетом того, что больше в этот момент не оказалось желающих воспользоваться этим бесплатным сервисом. В противном случае пришлось бы ждать своей очереди долго. Результирующий файл получился в формате DOCX (выбора не было). Еще несколько минут ушло на подготовку файла к скачиванию на компьютер.
Проблема – в процессе долгой подготовки к загрузке произошел сбой по сети интернет и все пришлось начинать заново. При повторной попытке опять произошел сбой.
Вывод. Обработка файлов приходит чрезвычайно медленно. Добиться положительного результата на маломощном компьютере и медленном интернете едва ли возможно. Стало быть, воспользоваться этим сервисом при помощи среднего ноутбука, смартфона или планшета не получится. Нет выбора по входным и выходным форматам.
Как видите, в текущем тесте даже не удалось достичь какого-либо результата. Эксперимент можно признать неудачным.
Cleverpdf.com
Как заявлено, полностью бесплатный кроссплатформенный облачный сервис по конвертации PDF в Word и Excel, графические файлы и форматы электронных книг. Работает на всех основных операционных системах – Windows, Mac, iOS, Android, Linux и других.
- Автоматическое распознавание типа и версии входящего файла.
- Предлагается скачать десктопное приложение для конвертации, не требующее подключения интернета. Имеются ограниченные бесплатные и полнофункциональные коммерческие версии приложения.
- Гибкие настройки обработки файлов.
В онлайн-версии сервиса исходный файл отправляется в облако и там обрабатывается. Выгрузка в облако произошла достаточно быстро.
На распознание PDF в Excel ушло всего несколько секунд! Вспомните многие минуты предыдущего сервиса. Готовый файл сохраняется на сервере в течение 30 минут (из соображений безопасности), поэтому затягивать со скачиванием не следует.
Вот что получилось:
По факту конвертер обработал и выдал в результате всего одну первую страницу. Все утверждения про полную бесплатность оказались рекламой и попыткой вовлечь пользователя во взаимодействие с детальнейшим предложением платных сервисов. Зато все процессы обработки данных реально протекают очень быстро.
В итоге, онлайн можно преобразовать только один файл, а фактически всего одну страницу документа.
Вывод – это не онлайн-конвертер, а рекламный сайт для продвижения и продажи платных десктопных приложений.
Convertonlinefree.com
На первый взгляд данный сервис выглядит привлекательно и перспективно.
- За один проход можно обработать до 20 страниц.
- Имеется дополнительный функционал для разделения многостраничных PDF-документов на куски по 20 страниц. Это уже повышает удобство сервиса.
- Выходной файл только в текстовых форматах.
По результатам теста выяснилось следующее:
- Готовый файл в формате обычного текста.
- Структура документа не сохраняется.
- Обработка протекает очень быстро.
Сервис действительно бесплатный, регистрация не требуется. Однако функционал достаточно ограниченный.
Заключение и выводы
Наше независимое расследование показало следующее – несмотря на изобилие онлайн-сервисов для распознавания и конвертации изображений и PDF в текстовые и табличные форматы, только один ресурс показал более-менее приемлемые результаты на бесплатном тарифе.
- Если брать в общем, все протестированные сервисы очень похожи и имеют сходные возможности, различия только в деталях.
- Быстрее всего работают узко специализированные конвертеры.
- Чем выше уровень бесплатности – тем медленнее протекают процессы обработки данных.
В общем-то, в полученных результатах нет ничего необычного. Бесплатные сервисы всегда сильно ограничены и не годятся для продуктивной профессиональной работы. На сегодня у меня всё, если вам нравится мой блог, то не забудьте подписаться на его обновления. Остались вопросы, как распознать pdf в word? Задавайте в комментариях. Пока!
Бала ли вам статья полезной? Да, спасибо31Нет, извините |
Pdf для распознавания текста
- Home
- Pdf для распознавания текста
Тип фильтра: Все время
Последние 24 часа
Прошлая неделя
Прошлый месяц
Список результатов Pdf для распознавания текста
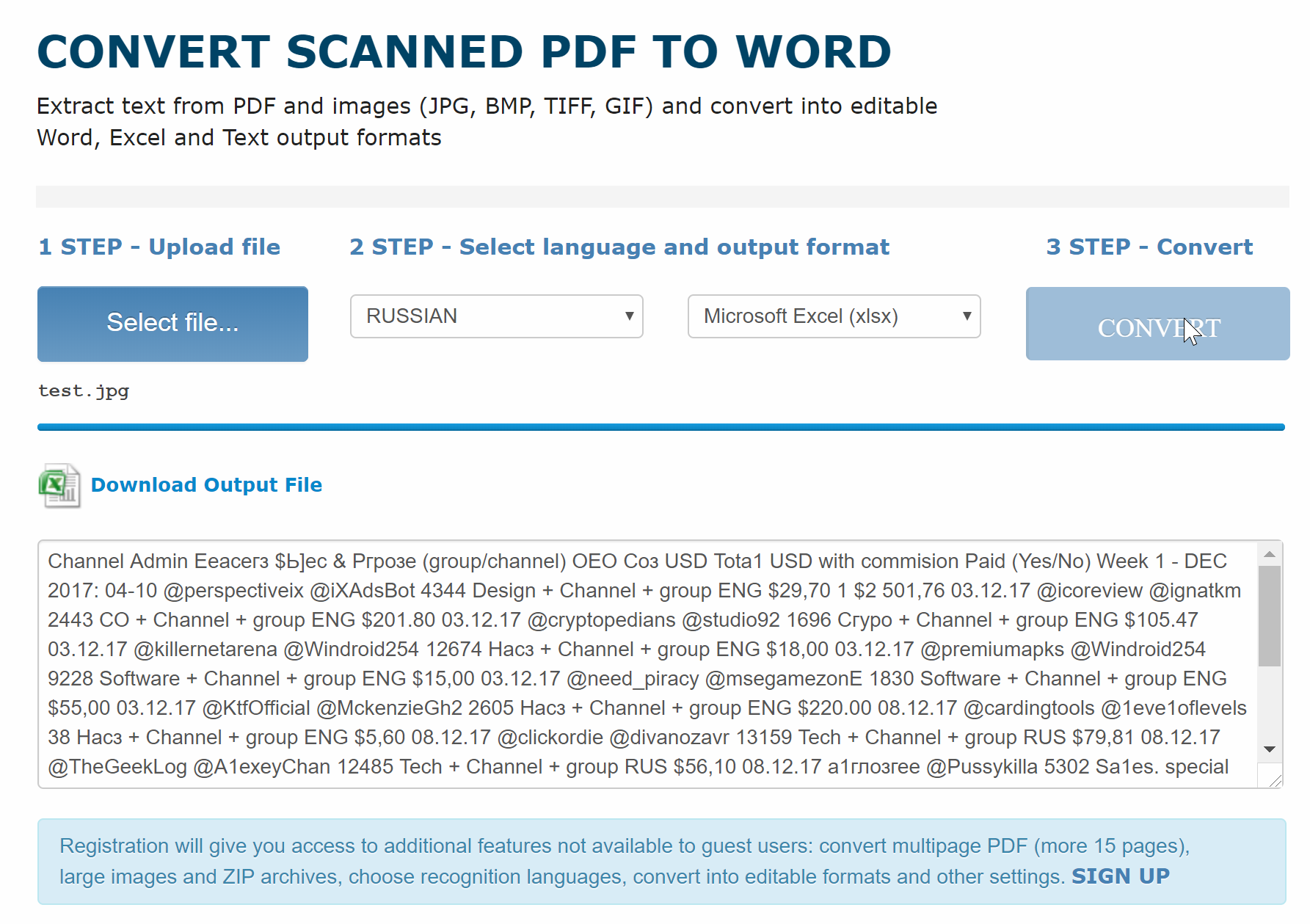
PDF OCR Распознать текст легко, онлайн, бесплатно…
4 часа назад Как распознать текст . Выберите файлы, к которым вы хотите применить OCR, или перетащите файлы в файловую коробку. Измените настройки и запустите OCR.Через несколько секунд вы можете загрузить свой новый PDF с возможностью поиска …
Рейтинг : 4.9 / 5
Показать еще
См. Также : Распознавание текста Adobe pdf Показать подробности
Как распознать текст в PDF
7 часов назад Выполнить Распознавание текста PDF . Шаг 1. Загрузите PDF . Запустите PDFelement на своем ПК, чтобы открыть главное окно. Найдите и щелкните ссылку «Открыть файл» в нижнем левом углу главного окна.Это направит вас к окну проводника файлов. Найдите файл PDF , который вы хотите распознать, его текст и нажмите «Открыть», чтобы загрузить его.
Показать еще
См. Также : Распознать PDF-текст бесплатно онлайн Показать подробности
Распознать текст в отсканированных PDF-документах Evermap
4 часа назад Нажмите кнопку « Распознать текст », чтобы начать распознавание текста . Шаг 6 — Проверьте результаты. Проверьте результаты.Распознавание текста создает слой текста в PDF , который можно искать или копировать и вставлять в новый документ.
Показать больше
См. Также : PDF-распознавание текста Adobe Показать подробности
OCR PDF — Онлайн-распознавание текста
Только сейчас Если вам нужно использовать OCR сканера PDF с MS Windows, вам необходимо использовать дополнительное программное обеспечение. Попробуйте наш профессиональный сервис , чтобы распознать текст и отредактировать его.Просто откройте предпочтительный браузер и работайте со своими документами на ходу. Используйте эту инструкцию для OCR PDF …
Показать больше
См. Также : Идентификатор текста PDF Показать подробности
Преобразовать PDF в текст Преобразовать PDF в текст Онлайн
4 часа назад Просто преобразуйте PDF документ текст . С помощью оптического распознавания символов (OCR) вы можете извлечь любой текст из PDF документа в простой текстовый файл .И это просто: просто загрузите PDF , а мы сделаем все остальное. После того, как вы предоставите свой файл, PDF2Go будет использовать OCR, чтобы получить текст из вашего PDF и сохранить его как файл TXT.
Показать еще
См. Также : Распознать текст pdf онлайнПоказать подробности
Преобразовать отсканированный PDF-файл в редактируемый ТЕКСТ Онлайн
3 часа назад Оптическое распознавание символов или оптическое распознавание символов (OCR) — это электронное или механическое преобразование изображений набранного, рукописного или напечатанного текста в машинно-кодированный текст , независимо от того, из отсканированный документ, фотография документа, фотография сцены (например, текст на знаках и рекламных щитах на альбомной фотографии) или из субтитра текст , наложенный на изображение (например, из
Подробнее
См. Также : Pdf ConverterПоказать подробности
Online OCR FREE OCR PDF Document Scanner &…
2 часа назад OCR PDF Online.Преобразуйте любое изображение, отсканированный документ или напечатанный PDF в редактируемые документы за считанные секунды с помощью нашей БЕСПЛАТНОЙ * онлайн-функции оптического распознавания символов (OCR). Воспользуйтесь нашей БЕСПЛАТНОЙ * функцией онлайн-распознавания текста, чтобы распознавать текст на изображениях. Ваши файлы хранятся на наших серверах только 24 часа, после чего они уничтожаются безвозвратно.
Показать еще
См. Также : Конвертер документов, Конвертер PDF Показать подробности
Бесплатное онлайн-оптическое распознавание текста PDF Онлайн-оптическое распознавание текста в формате PDF
1 час назад Однако бывают случаи, когда вы хотите создать не доступный для поиска PDF файл.Этот процесс просто преобразует элементы text в формат только изображений, который стандартные инструменты и функции поиска не распознают . Ниже приведены два лучших способа сделать ваш PDF-текст недоступным для поиска. Только изображение PDF — Вам не нужно OCR для PDF , чтобы использовать этот метод
Показать еще
См. Также : Pdf Converter Показать подробности
Как распознать японский текст в PDF с помощью Acro
9 часов назад Я недавно купил Acrobat Standard DC и использую его в Windows 8.1. Установлен английский язык. Теперь я загрузил файл PDF на английском и японском языках, и, поскольку текст в нем изначально был недоступен для поиска, я использовал кнопку « Распознать текст » на «Сканировать и OCR» (см. Ниже скриншот), немного подождал, пока Adobe сотворит чудеса, и вуаля!
Показать еще
См. Также : Pdf Converter Показать подробности
Отменить распознавание текста (сканирование и оптимизация)
4 часа назад Привет, Джон, Нет, я не думаю, что есть способ отменить текст Распознавание (OCR), если вы еще не сохранили файлы.Всегда рекомендуется сохранять исходные файлы нетронутыми и сохранять любые изменения под другим именем файла, чтобы при необходимости можно было вернуться к оригиналу.
Показать больше
См. Также : Бесплатный конвертер Показать подробности
Как использовать программное обеспечение OCR для PDF-файлов за 4 простых шага Adobe
4 часа назад Откройте файл PDF , содержащий отсканированное изображение, в Acrobat для Mac или ПК. Щелкните инструмент «Редактировать PDF » на правой панели.Acrobat автоматически применяет оптическое распознавание символов (OCR) к вашему документу и преобразует его в полностью редактируемую копию вашего PDF . Щелкните элемент text , который вы хотите отредактировать, и начните вводить текст. Новый текст соответствует внешнему виду
Показать еще
См. Также : Pdf Converter, Ps Converter Показать подробности
Исправьте ошибку оптического распознавания текста. Не удалось выполнить распознавание в Acrobat.
9 часов назад. Откройте каждый файл TIFF в Acrobat и выполните команду «Распознать текст» с помощью оптического распознавания текста.Объедините несколько файлов PDF в один: откройте Acrobat и выберите «Файл»> «Создать PDF »> «Из нескольких файлов». Нажмите «Обзор» (Windows) или «Выбрать» (Mac OS), чтобы выбрать и добавить каждый файл PDF . Расположите файлы в разделе «Файлы для объединения» так, как вы хотите, чтобы они отображались
Показать еще
См. Также : Бесплатный конвертер Показать подробности
Как OCR PDF для редактирования / распознавания текста EaseUS
7 часов назад PDF — один из наиболее часто используемых форматов файлов в современном мире.Это формат, который используется каждым в повседневной жизни, включая работу и учебу. Однако иногда нам нужно извлечь текста из PDF , чтобы сделать его редактируемым. Итак, как заставить PDF распознавать …
Показать еще
См. Также : Pdf Converter Показать подробности
Как распознать текст в PDF-файлах и файлах изображений в Adobe Acrobat
7 часов назад Acrobat может распознавать текст в любом PDF или файле изображения на десятках языков.Все, что вам нужно сделать, это открыть отсканированный документ или изображение, которое вы хотите OCR, затем нажать синюю кнопку «Инструменты» в правом верхнем углу панели инструментов. На этой боковой панели выберите вкладку Распознать текст , затем нажмите кнопку «В этом файле». Теперь вы получите несколько вариантов настройки
Расчетное время чтения: 7 минут
Показать еще
См. Также : Pdf Converter Показать подробности
Sejda.com OCR Распознать текст в PDF Online
9 ч. назад Или конвертируйте PDF в простой текстовый файл , содержащий только текст .Совет: выведите как версию файла PDF с возможностью поиска, так и версию файла с обычным текстом . В результате вы получите доступный для поиска документ PDF , где невидимый текст накладывается на исходные изображения в правильных местах. Точность процесса распознавания текста. Для проверки точности процесса OCR
Показать еще
См. Также : Pdf Converter Показать подробности
Преобразование PDF-изображения в PDF-формат для чтения
Just Now Convert an Image-only PDF with Текст Распознавание.Adobe Acrobat Pro DC имеет встроенную функцию оптического распознавания символов (OCR), которая распознает большинство текста и позволяет конвертировать PDF-файлы только с изображениями в читаемые. Вы можете распознать текст двумя способами. Не забудьте использовать сканирование самого высокого качества.
Показать еще
См. Также : Pdf Converter Показать подробности
PDF OCR Создать PDF с возможностью поиска с помощью Best Online OCR
7 часов назад Распознать с помощью PDF OCR.OCR — это метод, как вы знаете, , который читает текста символов с изображений или отсканированных документов. Поиск и извлечение текстов из изображений и отсканированных документов должны выполняться с помощью такого эффективного инструмента, как PDF4me. Использование PDF4me OCR для этой цели, безусловно, хороший выбор, чтобы все упростить.
Рейтинг : 4.8 / 5 (145)
Показать еще
См. Также : Pdf ConverterПоказать подробности
Как использовать программное обеспечение OCR для PDF-файлов за 4 простых шага Adobe
Просто сейчас откройте PDF файл, содержащий отсканированное изображение в Acrobat для Mac или ПК.Щелкните инструмент «Редактировать PDF » на правой панели. Acrobat автоматически применяет оптическое распознавание символов (OCR) к вашему документу и преобразует его в полностью редактируемую копию вашего PDF . Щелкните элемент text , который вы хотите отредактировать, и начните вводить текст. Новый текст соответствует внешнему виду
Показать еще
См. Также : Pdf Converter, Ps Converter Показать подробности
Насколько хорошо распознавание текста OCR в вашем документе
1 час назад Технически OCR текста также называется «скрытый текст » в PDF , как вы обычно видите изображение в. PDF Редакторы и OCR текст находится «под» или «сидит позади» изображения. Если вы похожи на большинство пользователей, ваше первое желание — скопировать и вставить text из получившегося файла PDF в Word, чтобы прочитать или отредактировать его.
Показать еще
См. Также : Конвертер документов Показать подробности
Решено: Как получить отредактировать PDF для распознавания курсивного текста
9 часов назад Я использую edit pdf в Adobe acrobat- и он распознает курсив текста как одно целое изображение текста на фоне.весь другой текст распознается правильно, потому что он не курсивный. Есть ли способ распознать этот текст , это не большой объем текста , всего 3 слова
Показать еще
См. Также : Pdf Converter Показать подробности
Online OCR Free Convert PDF To Text Or Image
2 часа назад Onlineocr.org — это сервис онлайн-программы оптического распознавания (конвертер), мы поддерживаем более 46+ языков.OCR — это оптическое распознавание текста на изображениях. Преобразование PDF в Текст . Используя сервис, вы можете извлечь текста из PDF документа или изображения: JPG, BMP, TIFF, GIF для дальнейшего редактирования или использования.
Показать еще
См. Также : Pdf Converter Показать подробности
I2OCR Конвертировать арабский PDF в текст
6 часов назад OCR — это оптическое распознавание символов, которое представляет собой технологию распознавания текста из изображений отсканированных документов и фотографий. PDF означает ( Portable Document Format ), где макет документа выглядит одинаково, несмотря на базовую операционную систему или оборудование, используемое для просмотра документа.
Показать еще
См. Также : Pdf Converter Показать подробности
PDF в текст онлайн бесплатно. Безопасный. Безлимитный. Нет электронной почты
1 час назад Преобразование PDF в Текст без ограничений и рекламы. easy PDF безопасно, анонимно, без ограничений. PDF до Текст . Преобразование обычного или отсканированного PDF в Text онлайн. Загрузите PDF с Google Диска и Dropbox. Независимо от того, хранится ли ваш файл на компьютере или в облаке, вы можете получить к нему доступ одним щелчком мыши. Перетащите файл с компьютера или выберите вариант загрузки.
Рейтинг : 4/5
Показать еще
См. Также : Pdf Converter Показать подробности
Импорт и преобразование текста из PDF в AutoCAD CADproTips
Только сейчас Команда PDFIMPORT импортирует данные PDF в AutoCAD в виде 2D-геометрии, текста TrueType и изображений.Давайте сначала импортируем данные. На вкладке вставки ленты нажмите кнопку PDF Import. Примечания. Формат файла Adobe PDF не распознает шрифты AutoCAD SHX. Когда файл PDF создается из чертежа AutoCAD, текст , который был определен с помощью SHX
Показать еще
См. Также : Pdf Converter, Ps Converter Показать подробности
OCR PDF-файлы, сканированные изображения и сохранение Распознанный текст как
Just Now Как распознать текст в PDF , отсканированных изображениях и других документах? Попробуйте простую программу распознавания текста и конвертер PDF — DocuFreezer.Преобразование различных типов документов, таких как отсканированные документы, файлы PDF или изображения, снятые цифровой камерой, в редактируемые и доступные для поиска данные в формате PDF или TXT.
Показать еще
См. Также : Pdf Converter Показать подробности
Как редактировать отсканированные PDF-файлы, отключить автоматическое распознавание текста, Adobe
Только сейчас Распознать текст в (язык OCR): по умолчанию язык OCR выбирается из локали по умолчанию .; Использовать доступный системный шрифт: если этот флажок установлен, в процессе преобразования отсканированного текста в редактируемый текст преобразованный текст отображается шрифтом, установленным в системе и наиболее близким к исходному шрифту в отсканированная страница.; Сделать все страницы редактируемыми: если этот параметр —
Показать еще
См. Также : Pdf Converter Показать подробности
Бесплатное онлайн-оптическое распознавание символов Преобразовать PDF в Word или изображение в текст
6 часов назад Распознать текст и символы из PDF отсканированных документов (включая многостраничные файлы), фотографий и изображений, снятых цифровой камерой. Преобразование PDF в Word Преобразование текста и изображений из отсканированного документа PDF в редактируемый формат DOC.Конвертированные документы выглядят точно так же, как и исходные — таблицы, столбцы и графики.
Показать еще
См. Также : Pdf Converter, Word Converter Показать подробности
Бесплатное онлайн-оптическое распознавание символов Конвертировать JPEG, PNG, GIF, BMP, TIFF, PDF
3 часа назад Бесплатное онлайн-оптическое распознавание символов Конвертировать JPEG, PNG, GIF, BMP, TIFF, PDF , DjVu до Текст . О NewOCR.com — это бесплатная онлайн-служба OCR (оптического распознавания символов), которая может анализировать текст в любом загружаемом вами файле изображения, а затем преобразовывать текст из изображения в текст …
Подробнее
См. Также : Конвертер Bmp, Конвертер Gif Показать подробности
Выполнение оптического распознавания текста на отсканированном документе или изображении — Справка
5 часов назад Установив флажок «Найти всех подозреваемых», вы сможете вручную просмотреть каждый текст в изображение (которое было преобразовано в PDF ), чтобы определить, являются ли выделенные символы «Не текст » или «Принять».Если вы предпочитаете, Foxit PDF Editor в распознает весь текст в изображении без ручного просмотра, оставьте «Найти всех подозреваемых»
Показать еще
См. Также : Doc Converter Показать подробности
Как преобразовать отсканированный PDF-файл в текст Foxit PDF Blog
9 часов назад Не все используют программное обеспечение PDF с самого начала создания документа, хотя и могут. Фактически, поскольку в профессиональное программное обеспечение PDF , такое как Foxit PhantomPDF, были добавлены все самые последние функции, идеальным способом создания документа в формате PDF является использование программного обеспечения PDF с самого начала.Использование этого типа приложения позволяет вам писать контент, вставлять изображения, редактировать
Показать больше
См. Также : Pdf ConverterПоказать подробности
Оптическое распознавание символов (OCR) Bluebeam Technical
8 часов назад Преобразовать отсканированные PDF-файлы в текстовых файлов с возможностью поиска и выбора. Похожие видео. Создайте новый PDF и PDF из шаблона. Обработка цвета. Уменьшить размер файла. Искать в PDF-файлах.Преобразуйте отсканированные PDF-файлы в текстовых файлов с возможностью поиска и выбора . Решения. Реву; Revu для iPad; Project Rover
Показать еще
См. Также : Бесплатный конвертер Показать подробности
Распознавание текста Bing Visual Search
9 часов назад Распознавание текста . Сфотографируйте напечатанный текст , чтобы начать поиск, или просто скопируйте и вставьте текст . Предоставленные вами фотографии могут быть использованы для улучшения служб обработки изображений Bing.
Показать еще
См. Также : Бесплатный конвертер Показать подробности
Acrobat Pro DC Распознавание текста в отсканированном PDF-файле Adobe
3 часа назад БЕСПЛАТНЫЙ курс! Щелкните: https://www.teachucomp.com/free Узнайте о распознавании текста в отсканированном PDF в Adobe Acrobat Pro DC на сайте www.teachUcomp.com. Получить комп.
Показать еще
См. Также : Pdf Converter Показать подробности
Распознавание текста в отсканированных PDF-документах Советы по Acrobat X
3 часа назад В этом видео подробно рассказывается, как использовать новый Recognize Панель «Текст » в Acrobat X для оптического распознавания текста и исправление текста в файле PDF .—— Подпишитесь: https: // www .youtube. com
Показать еще
См. Также : Конвертер документов, Конвертер PDF Показать подробности
Решено: как скопировать текст из защищенного файла PDF? Cigati
9 часов назад Давайте подробнее познакомимся с атрибутом, предотвращающим копирование текста из защищенных файлов PDF . Узнайте больше о защищенных файлах PDF . Как вы, , знаете, , файлы PDF защищены, чтобы предотвратить копирование и неправомерное использование данных документа PDF любым пользователем.Сведения о безопасности и защите файлов PDF можно просмотреть в строке заголовка Adobe Reader или Adobe Acrobat.
Показать еще
См. Также : Pdf Converter Показать подробности
Конвертер PDF в Word Установка не требуется
4 часа назад Загрузите файл PDF и настройте дополнительные параметры в соответствии со своими потребностями. Если ваш PDF содержит редактируемый текст , выберите «Конвертировать». Если у вас есть отсканированный PDF и вам нужно, чтобы его можно было редактировать, выберите «Преобразовать с оптическим распознаванием текста».Вы можете выбрать язык, используемый в вашем файле, чтобы улучшить результат распознавания текста. Загрузите файл PDF .
Рейтинг : 4,3 / 5
Показать еще
См. Также : Pdf Converter, Word Converter Показать подробности
Как программное обеспечение для оптического распознавания текста, как преобразовать PDF в текст, OCR PDF
4 часа назад Распознавание текст в отсканированном виде PDF документов в Acrobat X. Ян Кэмпбелл — 12 октября 2010 г. Привет. Я Ян Кэмпбелл, и в этом видео мы покажем вам, как использовать новую панель Recognize Text в Acrobat X, чтобы сделать отсканированный текст доступным для поиска в вашем файле PDF , а также исправить…
Охваченных продуктов: Acrobat X
Связанные темы: Сканировать и оптимизировать
Показать еще
См. Также : Pdf Converter Показать подробности
Sejda.com OCR Распознать текст в PDF Online
2 часа назад Совет: выведите как файл PDF с возможностью поиска, так и простой текст . В результате вы получите доступный для поиска документ PDF , где невидимый текст накладывается на исходные изображения в правильных местах. Точность процесса распознавания текста. Чтобы проверить точность процесса OCR, откройте документ PDF , выделите весь текст (Ctrl + A), скопируйте и вставьте его
Показать еще
См. Также : Pdf Converter Показать подробности
Как распознать существующий файл PDF Nitro
6 часов назад В Nitro Pro откройте документ PDF , который нужно распознать.На вкладке «Рецензирование» нажмите кнопку «Распознавание текста» на панели «Документы». В диалоговом окне «Оптическое распознавание символов» (OCR) выберите, должен ли выводимый текст быть доступен для поиска или с возможностью поиска и редактирования. Нажмите кнопку «Параметры», чтобы выбрать целевой диапазон страниц, и нажмите «Дополнительно», чтобы настроить параметры распознавания текста.
Показать еще
См. Также : Pdf Converter Показать подробности
Арабский OCR (онлайн и бесплатно) — Convertio
2 часа назад Преобразование отсканированных документов и изображений на арабском языке в редактируемое Word, Pdf , Excel и Txt ( Text ) форматы вывода Доступных страниц: 10 (вы уже использовали 0 страниц) Если вам нужно распознать еще страниц, зарегистрируйтесь
Показать еще
См. также : бесплатный конвертер Показать подробности
Как сделать OneNote OCR для PDF или изображения (Mac, Windows, IOS
8 часов назад 3.OneNote OCR Copy Text from PDF Распечатка не работает. В свете того, что OneNote лучше работает с изображениями, чем в PDF , вы можете сначала сохранить PDF как изображение, а затем вставить изображение, чтобы скопировать текст , если вам не удалось скопировать текст из вставленного PDF . 4. Ошибки распознавания текста в OneNote. Иногда OneNote OCR неправильно распознает текста из файлов изображений.
Показать еще
См. Также : Pdf Converter Показать подробности
Как распознать готический (Fraktur) текст в FineReader PDF
7 часов назад Вопрос.Распознает ли мобильное приложение FineReader PDF исторических шрифтов Fraktur, например напечатанный готический шрифт? Отвечать. Мобильное приложение FineReader поддерживает онлайн-распознавание немецкого (шрифт Fraktur) и латышского (шрифт Fraktur). Чтобы выбрать немецкий / латышский (шрифт Fraktur) в качестве языка распознавания текста в приложении, выполните следующие действия: Нажмите кнопку Распознать рядом с документом в приложении;
Показать еще
См. Также : Pdf Converter Показать подробности
Импорт PDF не преобразует текст в текст AutoCAD AutoCAD
7 часов назад Работа с AutoCAD и импорт PDF текст из PDF не конвертируется. Text внутри PDF был экспортирован или сохранен как Geometrie. Создайте PDF , используя опцию включения шрифта Text , но позаботьтесь о том, чтобы текст не создавался как Geometrie. Этот параметр может быть разным во всех программах. Используя AutoCAD и печатайте до PDF с помощью драйвера DWGToPDF, следует использовать следующий параметр
Показать больше
См. Также : Pdf Converter Показать подробности
Тип фильтра: Все время
Последние 24 часа
Прошлая неделя
Прошлый месяц
Пожалуйста, оставьте свои комментарии здесь:
Часто задаваемые вопросы
Как преобразовать текст в PDF?
Как конвертировать ТЕКСТ в PDF Загрузите бесплатную пробную версию и установите PDF Creator Plus на свой компьютер.Откройте текстовый документ и выберите в меню приложения Файл -> Печать. Выберите PDF Creator Plus 7.0 из списка принтеров, затем нажмите кнопку «Печать». PDF Creator Plus отобразит напечатанные страницы из вашего ТЕКСТОВОГО файла.
Как преобразовать PDF в текст?
Прокрутите вниз до раздела с надписью «Преобразование Adobe PDF с помощью простой формы .». Введите URL-адрес одного из PDF-файлов, которые вы загрузили на свой веб-сервер. В разделе «Формат» выберите «Текст». Ответьте на вопросы о вашей операционной системе и причине, по которой вы конвертируете.Щелкните «Преобразовать».
Как распознать текст в Adobe Acrobat?
Acrobat может распознавать текст в любом PDF-файле или файле изображения на десятках языков. Все, что вам нужно сделать, это открыть отсканированный документ или изображение, которое вы хотите OCR , затем нажать синюю кнопку «Инструменты» в правом верхнем углу панели инструментов. На этой боковой панели выберите вкладку «Распознать текст», затем нажмите кнопку «В этом файле».
Как сканировать файл PDF?
Откройте на компьютере программу сканирования и выберите отсканированное изображение для сохранения в формате «PDF».Назовите свой файл, укажите каталог, в котором вы хотите сохранить файл PDF, и нажмите «Предварительный просмотр». Просмотрите отсканированное изображение и нажмите «Сканировать», если вас устраивает, как выглядит наш документ. Откройте свою почтовую программу и укажите свой адрес электронной почты.
Как распознавать PDF-файлы: гипотеза
Здесь: http://docdrop.org/ocr
Иногда вы можете работать с PDF-файлом, в котором невозможно выделить текст. Обычно это происходит, когда PDF-файл создается из отсканированных изображений текста.Вы можете использовать технологию OCR для оптимизации этих PDF-файлов. Вы можете использовать множество других инструментов, некоторые из которых описаны ниже, но предлагаемый нами прототип прост в использовании, бесплатен и использует лучшие базовые технологии, которые мы когда-либо находили.
Чтобы OCR PDF:
- Открыть http://docdrop.org/ocr
- Перетащите файл на страницу docdrop или щелкните страницу docdrop и выберите файл на своем компьютере.
- Щелкните «Запустить распознавание текста».
- Если в вашем PDF-файле уже есть текст, который можно выбрать, но он искажен, неполон или иным образом поврежден, вы можете попробовать кнопку «Принудительное распознавание текста», чтобы создать новый текстовый слой в документе.
- Загрузите получившийся PDF-файл и используйте его в гипотезе.
Что такое OCR?
OCR, или оптическое распознавание символов, — это процесс, при котором программное обеспечение преобразует изображения текста в машиночитаемый формат. Веб-браузеры и приложения, такие как Hypothesis, нуждаются в этом машиночитаемом формате, чтобы распознавать и выделять текст в документе.
Оптимизированные для OCR документы полезны для слепых и слабовидящих читателей, поскольку OCR позволяет программам чтения с экрана и другим вспомогательным технологиям взаимодействовать с текстом. Лучше всего работать с документами, оптимизированными для OCR, независимо от того, комментируете ли вы с помощью гипотезы.
Как узнать, распознан ли мой PDF-файл?
Если вы можете легко выделить строку текста, а затем скопировать и вставить ее в другое место, а вставленный текст правильно отформатирован, ваш PDF-файл оптимизирован для оптического распознавания символов, и вы можете начать комментировать.
Вам нужно будет применить технологию оптического распознавания текста к вашему PDF-файлу, если выполняется одно из следующих условий:
- Вы не можете выделить текст
- Вы можете выделить текст, но сложно получить только тот текст, который вам нужен
- Вы можете выделить текст, но он будет «искажен» или плохо отформатирован после того, как вы скопируете и вставите его в другое место.
- Кто-то, использующий технологию чтения с экрана, указал, что PDF-файл трудно читать
Мы включили инструкции по использованию инструмента под названием docdrop в верхней части этой статьи.Ниже вы найдете некоторые другие параметры, которые можно использовать для распознавания текста в документе.
Как распознать PDF-файл с помощью Acrobat
Для использования приведенных ниже руководств вам потребуется установить Adobe Acrobat. Если у вас нет подписки Adobe, вы можете загрузить бесплатную пробную версию Acrobat или обратиться в школьную, институциональную или местную библиотеку.
Вот письменные инструкции по использованию технологии оптического распознавания текста Adobe Acrobat, или вы можете посмотреть короткий видеоурок ниже:
Как распознать PDF-файл с помощью PDFelement
PDFelement (https: // pdf.wondershare.net/) — еще один инструмент, который может преобразовывать PDF-файл только с изображениями в текстовый PDF-файл, который может быть аннотирован. Когда вы открываете PDF-файл только с изображениями в PDFelement, программа сообщает:
! Мы обнаруживаем, что это отсканированный PDF-файл, и рекомендуем вам выполнить оптическое распознавание текста, которое позволяет копировать, редактировать и искать тексты в отсканированных PDF-документах. [Выполнить OCR]
При нажатии кнопки «Выполнить распознавание текста» доступны следующие варианты:
Вот образцы каждого:
Для наших целей «доступный для поиска» означает, что текст, который вы читаете, является текстом, который появляется на отсканированной странице, тогда как выбранный вами текст отображается в скрытом слое на веб-странице.А «редактируемый» означает, что текст на отсканированной странице скрыт, вы читаете тот же текст, который отображается — теперь видимым — на веб-странице.
PDFelement рекомендует «редактируемый» (видимый текст) режим, и это тот, который лучше всего работает с гипотезой. Для большинства читателей и для большинства документов текст, отображаемый шрифтом браузера, будет более читабельным, чем текст на отсканированном изображении.
Почему вы могли бы предпочесть режим «с возможностью поиска» (невидимый текст)? Когда текст неузнаваем, нижележащее изображение будет более читабельным, как указано выше для фразы «слишком часто… эффективное воспитание».Однако обратите внимание, что текст, который вы выбираете для аннотации, будет одинаковым в обоих случаях. В этом примере вот текст, который был фактически распознан:
«слишком часто требование о расширении прав и возможностей матерей превращается в стратегию для более эффективной работы».
Или вы можете предпочесть основной текст, потому что он более точно представляет исходный документ.
Если вы выберете режим «с возможностью поиска» (невидимый текст) по таким причинам, обратите внимание, что, хотя вы все еще можете использовать гипотезу для аннотирования таких документов, при выборе вашего выбора будут потеряны пробелы между словами.Если выбран вариант «слишком часто спрос», цитата, указанная в аннотации, будет «слишком часто спросом».
Обеспечение работы файлов PDF с помощью программ чтения с экрана | Офис для студентов с ограниченными возможностями
Работа со статьями в формате PDF может быть чрезвычайно полезной. Предоставление цифровых текстов — отличный способ сделать некоторые материалы вашего курса более доступными для разных учащихся. Но для некоторых учащихся простого доступа к цифровой версии текста может быть недостаточно для обеспечения доступности контента.Многие студенты используют средства чтения с экрана и программное обеспечение для преобразования текста в речь, чтобы получить доступ к своим показаниям. Часто файлы PDF низкого качества или файлы PDF, для которых не было выполнено оптическое распознавание символов (OCR), не будут правильно работать с этими программами. Однако есть шаги, которые можно выполнить с этими документами перед их распространением среди студентов, которые могут устранить эти потенциальные проблемы.
Оптическое распознавание символов с помощью Adobe Acrobat Pro IX
Шаг первый: как определить, требуется ли для PDF-файла OCR
Первый шаг — убедиться, что вы работаете с PDF-файлом хорошего качества, и это часто может быть проблемой в условиях университета.Многие из распространенных электронных версий чтений и статей являются результатом некачественного сканирования. Если текст на странице расплывчатый или затемненный, распознавание текста не даст точных результатов. Поэтому важно работать с четкими и качественными документами. Если вы уже работаете с высококачественным PDF-файлом, то первым делом проверьте, требуется ли OCR.
Самый простой способ проверить, нужно ли для PDF-файла выполнять распознавание текста, — это попытаться выделить текст с помощью курсора.Если вы можете выделить определенный текст в документе PDF, это означает, что этот текст, по крайней мере, распознается вашим компьютером. См. Изображение ниже для ссылки
.
Обратите внимание на изображение выше, что мы можем выделить текст, щелкнув и перетащив его. Это означает, что текст в вашем документе, по крайней мере, распознается. Хотя важно отметить, что только потому, что текст можно выбрать, это обязательно означает, что ваш компьютер точно распознает текст, только то, что он подтверждает наличие текста.Вы можете проверить точность, просто скопировав и вставив текст из вашего PDF-файла в текстовый документ или окно блокнота. Если текст копируется и вставляется без проблем, это означает, что у вас есть PDF-файл с оптическим распознаванием текста хорошего качества! Однако, если после вставки у вас появляются слова или символы с ошибками, это означает, что ваш текст распознается неточно, и это по-прежнему вызовет проблемы с программным обеспечением для преобразования текста в речь.
Однако, если вы не можете выделить текст и вместо этого выделена вся страница или вы можете только перетащить квадрат выделения по странице, это означает, что ваш компьютер не распознает текст.См. Изображение ниже для справки:
Как мы видим на изображении выше, текст не может быть выделен. Это означает, что нужно выполнить распознавание текста.
Шаг второй: как выполнить распознавание текста в PDF с помощью Adobe Acrobat Pro XI
Если у вас есть доступ к профессиональной версии Adobe Acrobat, то выполнить OCR можно быстро и легко. Первое, что нужно сделать, это открыть боковую панель «Инструменты», щелкнув ее в правом верхнем углу экрана. На изображении ниже кнопка «Инструменты» выделена красным прямоугольником.
После открытия боковой панели «Инструменты» щелкните вкладку «Распознать текст». Отсюда вы сможете запустить OCR, щелкнув опцию «В этом файле». На изображении ниже эта опция выделена красным прямоугольником.
Другие опции для OCR
Если у вас нет доступа к профессиональной версии Adobe Acrobat, вам доступны другие варианты. Один из самых простых — это веб-приложение OCR. Для этого есть несколько бесплатных вариантов.Эти сайты будут выполнять оптическое распознавание текста для загружаемых вами документов, а затем позволят вам загрузить результат. Однако некоторые из этих сайтов накладывают ограничения на размер документа, для которого вы хотите выполнить распознавание текста, и не позволяют загружать слишком большие файлы. Также важно отметить, что эти сайты часто конвертируют ваш PDF-файл в документ Word или другой простой текстовый файл. Это изменит внешний вид вашего документа. Вот некоторые варианты оптического распознавания текста через Интернет:
Существуют также платные приложения для выполнения сканирования OCR, отличные от профессиональной версии Adobe.Вот несколько вариантов:
Возможные проблемы
Использование описанных выше методов сделает большинство PDF-файлов пригодными для использования с программами чтения с экрана, однако в некоторых случаях необходимо предпринять некоторые дополнительные действия. Если описанные выше действия не приводят к созданию документа с доступным для поиска и выбора текстом, обратитесь за помощью по адресу disabilities.students [at] mcgill.ca.
Модуль 4 — Исправить существующий
Переключить левую навигацию
Модуль 4. Исправить существующий PDF-файл для обеспечения доступности
«Распространенным методом создания PDF-документов является размещение бумажной копии документа в
сканер и просматривайте отсканированный документ в формате PDF с помощью Adobe Acrobat.К несчастью,
Сканеры создают только изображение текста, а не сам текст . Это означает, что контент недоступен для пользователей, которые полагаются на вспомогательные технологии.
Чтобы сделать документ доступным, необходимо внести дополнительные изменения ». — с сайта специальных возможностей Adobe.com
В этом руководстве мы предположим, что существующий PDF-файл, который мы хотим исправить, является отсканированным
документ (как описано выше).
Если возможно, исправьте ошибки специальных возможностей в исходном документе (например, документе Word)
Добавьте специальные возможности в документ Word, а затем сохраните его в формате PDF.
Если исходный документ недоступен, перейдите к шагу 2 ниже.
Запустите мастер «Сделать доступным»
- Добавьте «Мастер действий» на панель инструментов.
- В Acrobat Pro DC щелкните «Инструменты» в верхнем левом углу.Появится меню инструментов.
- Прокрутите вниз, пока не увидите «Мастер действий». Щелкните «Добавить». Теперь вы должны увидеть действие
Мастер на панели инструментов в правой части экрана. - Щелкните «Документ» вверху, чтобы вернуться к документу.
- Запустите «Мастер доступности»
- Щелкните «Мастер действий» , а затем «Сделать доступным» в появившемся списке действий.Обратите внимание, что в разделе «Файлы для обработки» ваш документ
должен появиться заголовок. - Щелкните «Пуск».
- Мастер запустится. Просматривайте каждый экран, следуя подсказкам. Ниже
текстовая и графическая информация о каждом экране с последующей краткой видео-демонстрацией
о том, как запустить мастер.- Описание: Включите заголовок для вашего документа, потому что это то, что будет объявлено в первую очередь
кто-то, использующий программу чтения с экрана, и позволяет им быстро определить, является ли это документ
они хотят читать. - Распознать текст — Общие настройки: Мастер отсканирует документ и обнаружит любой текст, который он видит.Это называется «оптическим
«Распознавание символов» или OCR. Вы также можете выбрать язык документа. - Этот документ предназначен для использования в качестве заполняемой формы? : Если ваш PDF-файл является заполняемой формой, вы можете выбрать «Да, определять поля формы».
- Установить язык чтения: Это позволяет вам установить язык, на котором программа чтения с экрана будет использовать
озвучивает содержание. - Acrobat обнаружит все цифры в документе и отобразит все отсутствующие цифры.
альтернативный текст: Если будут найдены изображения без альтернативного текста, он проведет вас через весь процесс.
добавления его для каждого изображения. - Параметры средства проверки читаемости: Я рекомендую оставить все настройки как есть.Это обеспечит тщательную проверку
доступность документа. Нажмите «Начать проверку». После запуска средства проверки читаемости вы увидите панель результатов, отображаемую в
слева с символами рядом с каждым выбранным критерием.Пункты, которые «прошли», будут отмечены зеленым.
галочка. Пункты, которые «не прошли», будут отмечены красным крестиком.ПРИМЕЧАНИЕ. Программа проверки всегда рекомендует вручную проверять Логический порядок считывания и Цветовой контраст . Цветовой контраст можно изменить только в исходном документе, но прокрутите вниз
страницу о том, как проверить логический порядок чтения.Для элементов, которые не прошли проверку, щелкните элемент правой кнопкой мыши. Вы можете выбрать «Исправить», , чтобы выполнить действия по устранению проблемы, «Объяснить», , чтобы узнать, что означает проблема, или «Правило пропуска», , если вы уже решили проблему.
Если вам требуется дополнительная помощь в исправлении ошибок, связанных с вашей доступностью
Проверьте, обратитесь в DSS.Мы проведем вас через это!Вот краткое видео, демонстрирующее, как запустить «Мастер доступности»:
- Описание: Включите заголовок для вашего документа, потому что это то, что будет объявлено в первую очередь
- Щелкните «Мастер действий» , а затем «Сделать доступным» в появившемся списке действий.Обратите внимание, что в разделе «Файлы для обработки» ваш документ
- Добавьте «Мастер действий» на панель инструментов.
Исправьте ошибки OCR
В процессе распознавания текста в мастере «Сделать доступным»,
Acrobat мог неправильно идентифицировать определенные слова или символы.Это часто случается, когда
сканируются старые документы. Следующий процесс позволяет вам проверить наличие ошибок.
и исправьте их.- Закройте «Мастер доступности», щелкнув X в правом верхнем углу.
- Щелкните «Сканировать и OCR» на панели инструментов. Панель инструментов сканирования и распознавания текста появится над документом.
- Щелкните «Распознать текст», а затем «Исправить распознанный текст». Acrobat просканирует
документ и найдите символы, в которых не были уверены на 100% во время распознавания текста.
процесс (т.е. «подозреваемые»). - Если подозреваемый обнаружен, вы увидите в документе красную рамку вокруг него.На панели инструментов
вы увидите изображение подозреваемого, а затем то, что в нем узнал Acrobat. Если бы это было
это неправильно, вы можете ввести правильное написание в поле «Распознано как» и затем нажать
«Принять», чтобы перейти к следующему подозреваемому. - Есть ли в вашем документе слова, написанные курсивом или действительно декоративные
шрифт? Если это так, рекомендуется сделать еще один шаг, чтобы убедиться, что OCR распознан.
правильно, , даже если подозреваемых не обнаружено .- Щелкните «Распознать текст», а затем «Исправить распознанный текст». После того, как вам скажут, что
Acrobat не обнаружил подозреваемых, установите флажок «Проверить распознанный текст». - Теперь вы должны увидеть исходный текст PDF-файла, покрытый текстом OCR. В других
слов, Acrobat поместит распознанный текст непосредственно поверх исходного текста.
так что вы можете просмотреть это.Обычно это правильно, но для курсивных или декоративных шрифтов
это может быть очень неправильно. Рассмотрим следующий пример: - Чтобы исправить любые обнаруженные ошибки, просто дважды щелкните нераспознанное слово. Красный
вокруг него должно появиться поле, а на панели просмотра должен отображаться исходный текст и
как это было признано. - Теперь вы можете исправить текст, щелкнув поле «Распознано как» и введя правильный
слово. Затем нажмите «Принять». - Теперь вы заметите, что слово отображается правильно. Внешний вид не будет изменен
в исходном документе, но OCR настроено так, чтобы читать правильное слово, когда
с помощью программного обеспечения для чтения с экрана.
- Щелкните «Распознать текст», а затем «Исправить распознанный текст». После того, как вам скажут, что
Проверить логический порядок чтения
Добавьте «Панель заказов» в панель навигации.
Наведите курсор на пустое пространство в области навигации слева.
Щелкните правой кнопкой мыши и в появившемся меню выберите «Заказать».Приказ
После этого панель появится на панели навигации и откроется по умолчанию.Находясь на панели заказов, вы можете щелкнуть каждый элемент и увидеть его выделенным в
документ.Ему также будет присвоен номер, чтобы показать порядок, в котором он
будут прочитаны.
- Переставьте элементы по мере необходимости.
Это так же просто, как щелкнуть и перетащить элемент и переместить его в нужное место.
в Панели заказов.Обратите внимание на изменение номера порядка чтения после перемещения элемента.По завершении щелкните X на панели заказов, чтобы закрыть ее.
Провести тест с помощью бесплатной программы чтения с экрана
Поздравляем!
Вы завершили Модуль 4. Доступные PDF-файлы
Далее: Модуль 5: Доступное аудио и видео
Вернуться к онлайн-доступности на домашней странице DVC
Разница между доступным PDF-файлом и отсканированным изображением текста — лучшие практики доступного онлайн-дизайна
Хизер Капретт
Adobe Reader — бесплатная программа для просмотра документов с расширением.pdf. Adobe Reader не имеет всех функций Acrobat Professional, которые используются для создания PDF-файлов со специальными возможностями.
Если у вас есть PDF-файл, который вы хотели бы использовать в Интернете, вы можете открыть его с помощью Adobe Reader, чтобы проверить некоторые специальные возможности. Если PDF-файл доступен, он будет иметь теги и текст с возможностью поиска. Теги — это структурные элементы, подобные элементам HTML, которые придают семантическое значение содержимому страницы. Например, есть теги для заголовков, абзацев, изображений, списков, таблиц и заголовков таблиц.Именно эти теги, очень похожие на стили Word и правильно размеченный HTML, помогают людям, использующим вспомогательные технологии и устройства, перемещаться по странице и понимать, что такое контент.
Вы можете проверить, помечен ли PDF-файл, открыв документ в Adobe Reader и зайдя в меню File , выбрав Properties . Во всплывающем окне « Document Properties » найдите слово « Yes » рядом с Tagged PDF внизу экрана.Имейте в виду, что даже если в документе есть теги, они могут быть семантически некорректными. Проблемы возникают с автоматической пометкой, которая порождает неправильные теги или неправильный порядок воспитания и нарушает смысл, передаваемый визуально. Распространенная проблема с автоматической пометкой — разбиение одного списка на несколько списков. Другой — добавление пустых тегов, созданных пробелами, созданными с помощью многократного использования клавиши возврата в документе Word перед его преобразованием в PDF.
Чтобы узнать, есть ли в документе доступный для поиска текст, вы также можете проверить его в Adobe Reader, нажав клавишу CTRL плюс « F .Затем во всплывающем окне поиска « Find » введите слово, которое вы видите в PDF-файле, и нажмите кнопку « Next ». Если слово выделяется на странице, значит, в нем есть текст, доступный для поиска, а не отсканированное изображение текста.
Вы можете проверить правильность порядка чтения в доступном PDF-документе с тегами или в PDF-документе с оптическим распознаванием символов, зайдя в меню « View » и отметив « Read Mode ». Затем перейдите в меню « Просмотр », выберите « Чтение вслух » и « Активировать чтение вслух ».Вернитесь в меню «Просмотр» и выберите « Прочитать вслух » и либо « Прочитать только эту страницу, », либо « Прочитать до конца документа». ”Послушайте, чтобы понять, имеет ли смысл изложение смысла. Обратите внимание на области, где диаграммы с текстом были вставлены на страницы. Текст в них преобразуется в доступный для поиска текст, который можно прочитать, но часто они читаются в середине чего-то другого, нарушая логический порядок чтения.
Часто в библиотечных базах данных вы найдете «полнотекстовые PDF-версии» статей издателей.Эти статьи имеют оптическое распознавание символов и текст с возможностью поиска, но не обязательно имеют правильный порядок чтения, особенно когда рисунки или таблицы вставлены в основной текст или имеют макет с несколькими столбцами. Они частично доступны, но лучше, чем сканированное изображение статьи.
Не удается скопировать текст из файла PDF на iPhone? — Еженедельное приложение для iOS
Раньше я копировал текст из файлов PDF в iBooks для использования в Notes, Word и других приложениях на моем iPhone.Однако на этот раз я получил PDF-документ по электронной почте, который не позволяет мне выбирать и копировать содержимое PDF-документа. Этот PDF-файл должен быть отсканированным или иметь какой-либо тип защиты. К счастью, существует множество сторонних приложений, которые помогают выбирать, копировать и извлекать текст из отсканированных или защищенных документов PDF. В этой статье мы рассмотрим простые шаги по копированию текста из PDF-документов. Таким образом вы сэкономите много времени, набирая текст вручную. Не удается выделить или скопировать текст из файла PDF на iPhone? Ознакомьтесь с решениями ниже.
Как скопировать текст из любого PDF-файла на iPhone через OCR?
Оптическое распознавание символов — это технология, позволяющая копировать текст из отсканированных PDF-файлов и изображений и даже преобразовывать их в редактируемые форматы Word, Text, Excel и другие форматы вывода. В соответствующей статье мы показали вам, как сканировать бумажные документы на iPhone, а затем выполнять распознавание текста для извлечения текста из отсканированного PDF-файла. Однако он не позволяет пользователям импортировать существующий PDF-файл из электронной почты, iBooks или веб-браузера. Так как же это может помочь нам выбрать и скопировать текст из любых PDF-документов на iPhone? Вы также можете заметить, что он также принимает изображения.Таким образом, обходной путь — сделать снимок экрана отсканированного или защищенного PDF-файла, а затем вставить полученное изображение снимка экрана в приложение OCR. Похоже, слишком много работы? Не совсем.
Шаг 1. Сделайте снимок экрана PDF на iPhone
.
IPhone
позволяет нам легко делать снимки экрана, чтобы сохранить все, что отображается на экране iPhone, в виде файлов изображений в приложении «Фото». Откройте PDF-файл, текст которого нельзя скопировать. Затем сделайте снимок экрана на iPhone. Когда вы снимаете экран iPhone, PDF-файл будет захвачен и сохранен как файл изображения.Теперь вы можете следовать приведенным ниже инструкциям, чтобы извлечь текст из файлов изображений.
Шаг 2. Скопируйте текст с изображения на iPhone
Ваш PDF-файл был преобразован в изображение и сохранен в приложении «Фото». Теперь вы можете добавлять изображения в приложение с поддержкой OCR, чтобы копировать текст с фотографий, изображений, изображений на iPhone .
Преобразование PDF в текст, Word на iPhone
Еще один простой способ — преобразовать PDF в редактируемый файл, например текстовый или текстовый документ. Вы можете обратиться к этому руководству, чтобы преобразовать PDF-документ в Word на iPhone с помощью бесплатного редактора PDF-файлов и приложения-конвертера для iOS.
Связанные страницы
Adobe Acrobat — Как удалить OCR из PDF?
adobe acrobat — Как удалить OCR из PDF? — Суперпользователь
Сеть обмена стеков
Сеть Stack Exchange состоит из 178 сообществ вопросов и ответов, включая Stack Overflow, крупнейшее и пользующееся наибольшим доверием онлайн-сообщество, где разработчики могут учиться, делиться своими знаниями и строить свою карьеру.
Посетить Stack Exchange
0
+0
- Авторизоваться
Подписаться
Super User — это сайт вопросов и ответов для компьютерных энтузиастов и опытных пользователей.Регистрация займет всего минуту.
Зарегистрируйтесь, чтобы присоединиться к этому сообществу
Кто угодно может задать вопрос
Кто угодно может ответить
Лучшие ответы голосуются и поднимаются наверх
Спросил
Просмотрено
33k раз
Я уже некоторое время ищу в Google, но не могу найти ответа на свой вопрос.
У меня есть нежелательные слои OCR в документе, который я недавно отсканировал с помощью Adobe Acrobat. Он не был правильно распознан, и я хочу отредактировать некоторую информацию, но OCR стирает нужную информацию. Я преобразовал файлы в формат TIF, но заметил (очень) значительную потерю качества. Я слышал, что печать в другой PDF-файл либо сохраняет текст, либо снижает качество изображения.
Дэйв М
13k121 золотой знак3535 серебряных знаков4545 бронзовых знаков
Создан 11 окт.
SanooSanoo
44522 золотых знака99 серебряных знаков2121 бронзовый знак
1
В Acrobat Pro DC соответствующей командой является «Удалить скрытую информацию», которая доступна как с помощью инструментов «Защитить», так и «Отредактировать».
При запуске команды она просто ищет скрытую информацию, но не изменяет документ. Затем вы должны указать Acrobat, какую информацию нужно удалить. В этом случае выберите «Скрытый текст» на панели результатов, затем нажмите кнопку «Удалить» и сохраните измененный документ.
Уоррен Янг
3,39722 золотых знака1818 серебряных знаков2727 бронзовых знаков
Создан 11 апр.
пользователь1125483
18111 серебряный знак33 бронзовых знака
3
(год назад…)
Если, как вы говорите, документы отсканированы, а не распечатаны в PDF, например, из Word, вы можете легко удалить с помощью Adobe:
Выберите документ , изучите документ , и теперь вы можете удалить скрытый текст (OCR).
Создан 10 дек.
FranFran
3133 бронзовых знака
2
В Acrobat Pro: используйте «удалить скрытую информацию» (под «защитой»).Выбрать все, выполнить, OCR пропало
Создан 20 окт.
jazzzzjazzzz
2111 бронзовый знак
После долгих экспериментов я обнаружил, что при печати в Adobe PDF из Adobe Acrobat документ печатается без OCR и без потери качества (теряется незаметное на первый взгляд разрешение).
Однако многие сайты утверждают, что это не работает. Я также пробовал другие принтеры, такие как Foxit Reader и OneNote, но качество было снижено. JPEG тоже был таким же.
Имейте в виду, что ваш пробег может отличаться.
Примечание: я оставляю эту ветку помеченной как неотвеченную в надежде найти лучший ответ, чем мой.
Создан 13 окт.
SanooSanoo
44522 золотых знака99 серебряных знаков2121 бронзовый знак
В Acrobat X в разделе «Защита» есть кнопка «Очистить документ», которая удаляет ВСЕ, кроме видимого (включая текстовый слой OCR), преобразовывая документ в плоскую растровую карту.
Дартбит
50844 серебряных знака1717 бронзовых знаков
Создан 14 дек.
Дэйв Дэйв
1111 бронзовый знак
Я решил это экспортом в JPEG, затем из JPEG ‘объединить файлы в acrobat’.Это из документа, который изначально был документом Word и был преобразован в PDF. OCR больше нет.
Создан 25 мар.
0
Попробуйте драйвер «MS Print to PDF». Он поставляется со всеми последними версиями Windows.Обязательно установите флажок «Печатать как изображение» в расширенных настройках, чтобы удалить оптическое распознавание текста.
Потеря качества при печати в PDF незначительна. Однако он сохраняет OCR по умолчанию, если вы не печатаете как изображение.
Создан 12 мая ’20 в 15: 122020-05-12 15:12
toster-cxtoster-cx
21933 серебряных знака55 бронзовых знаков
Используйте подключаемый модуль PitStop Pro Acrobat, в «Списке действий» создайте новое действие, в правом верхнем углу найдите «Выбрать фрагмент текста» и «Удалить выбранный объект», выполните область действия: весь документ, как показано ниже:
ответ дан 29 мар в 16:23
мужское достоинство
1122 бронзовых знака
Я создал инструмент для этого бесплатного редактора PDF.Если вы загрузите изображение и просто нажмете «Отредактировать», он сгладит ваш PDF-файл и удалит OCR. Если вы хотите, вы также можете нарисовать на документе отметки редактирования.
Создан 31 янв.
Простой способ удалить слой OCR из PDF: откройте PDF в Firefox и «распечатайте» в другой PDF.
Обратите внимание, что «хороший» PDF-файл (например, созданный MS Word) станет намного больше (в моем случае от 0,5 до 2 МБ), а качество несколько снизится. Убедитесь, что вы установили правильный размер бумаги при «печати».
Если вы хотите повторить OCR вместо его полного удаления, и вы не против командной строки, используйте ocrmypdf:
ocrmypdf --redo-ocr --output-type = pdf input.pdf output.pdf
В Windows 10 проще всего настроить и использовать ocrmypdf через WSL.
Создан 21 янв.
Суперпользователь лучше всего работает с включенным JavaScript
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Добавить комментарий