16 сервисов для работы с семантическим ядром — SEO на vc.ru
Сделал подборку из 16 сервисов для сбора и работы с семантическим ядром.
У сервиса большой инструментарий для работы с семантикой.
SemRush покажет вам, на какие ключевые слова следует обратить внимание, чтобы обойти конкурентов. Поможет узнать общие и уникальные ключевые слова доменов. Есть базы ключевых слов для 26 стран.
Всем известный сервис для анализа поисковых запросов в Яндексе. Есть возможность смотреть статистику поисковой фразы по регионам, похожие поисковые запросы и историю запросов в разрезе года.
Расширение для браузеров, которое позволяет значительно ускорить ручной сбор слов из Яндекс Wordstat. С помощью расширения вы сможете одним кликом выбрать все ключевые слова на странице и копировать в буфер обмена.
Бесплатная версия Keyword Tool генерирует до 750 + ключевых слов для каждого поискового запроса. Собирает поисковые подсказки, частотность и может анализировать домены конкурентов. Сервис позиционирует себя, как лучшая альтернатива планировщику ключевых слов Google.
Как бесплатно парсить ключевые слова и объявления конкурентов в «Яндексе» и Google
Перед запуском рекламной кампании полезно посмотреть, как с контекстной рекламой работают конкуренты: какие ключи используют, на какие регионы таргетируются, как составляют тексты объявлений. Так вы пополните семантику, почерпнете идеи для объявлений и получите представление о масштабах рекламной активности конкурентов.
Для анализа конкурентов в контекстной рекламе есть разные сервисы: Semrush, SpyFu, Serpstat и др. Однако для работы в них потребуется платная подписка. Если хотите провести анализ бесплатно, обратитесь к альтернативе — бесплатному инструменту «Слова и объявления конкурентов» от Click.ru.
Этот инструмент покажет, сколько активных объявлений, в каких регионах и по каким ключевикам запускали конкуренты за последние 3 года. Инструмент работает для Яндекса и Google, в нем есть возможность сужать поиск так, как это вам необходимо.
Для примера возьмем онлайн-магазин подарков и рассмотрим, как парсить ключевые слова и объявления конкурентов для решения различных задач.
Готовимся к анализу конкурентов: собираем домены
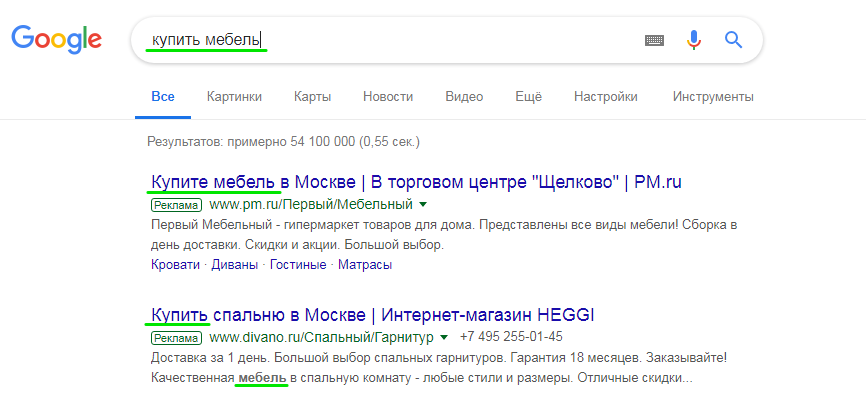
Перед началом анализа нужно понять, кто, собственно, наши конкуренты в поисковой выдаче. Для этого открываем поисковик (Яндекс или Google) и вбиваем основной запрос, по которому планируем рекламироваться. Вот результаты выдачи:
Нам нужны домены из платной выдачи, поэтому копируем URL первых четырех объявлений, указанных на скрине выше.
Как парсить ключевые слова для контекстной рекламы: краткое руководство
Яндекс.Директ, Яндекс Маркет, Google Adwords, Google Merchant, Ремаркетинг

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Для запуска поисковой контекстной рекламы необходимо создать объявления, интересные потенциальным клиентам. Чтобы вызвать интерес, нужно знать по каким запросам аудитория ищет ваш товар или услугу. Если вы указываете ключевые слова наугад, то рискуете «слить» бюджет впустую. На ручной подбор вы потратите недели и месяцы упорного труда. Оптимальным вариантом является использование парсеров и вспомогательных SEO-инструментов. Поговорим о том, как парсить ключевые фразы для контекстной рекламы.
Как работает контекстная реклама
Контекстная реклама направлена непосредственно на людей, которые искали/ищут ваш товар/услугу. Пользователь вводит запрос в поисковую строку и в первых строках выдачи видит релевантное рекламное объявление.
Объявления контекстной рекламы содержат фразы, соответствующие конкретным запросам потенциальных клиентов. Следовательно, для их создания нужно собрать ключевые слова, которые может использовать ваша целевая аудитория.
Как парсеры помогают в подборе коммерческих запросов
Парсеры – это программы или скрипты, которые автоматически собирают необходимые данные с указанных источников. Они изучают содержимое веб-страниц, выбирают нужную информацию и сохраняют в виде готового отчета.
При подборе ключевых фраз парсеры анализируют запросы пользователей в поисковых системах, тематические сайты и статистические данные. На основе анализа формируется список заданных и похожих фраз с указанием частотности показа. Из полученного перечня рекламодатель может выбрать наиболее релевантные словосочетания для создания объявлений. Рассмотрим все этапы сбора ключевых запросов.
Пошаговое руководство: как парсить ключевые слова для контекстной рекламы
Подготовку к запуску рекламной кампании в поиске начать следует с анализа вашего предложения: что вы предлагаете, почему клиентам это может быть интересно, чем вы отличаетесь от конкурентов и прочее. Эта информация поможет понять, что могут искать ваши потенциальные клиенты. Начинаем парсить.
# 1 Подбираем основные ключевые фразы
В первую очередь определяем базовые запросы. Это популярные ключевые слова, которые характеризуют ваш товар/услугу.
Для подбора базовых фраз используйте:
- «мозговой штурм» – соберите все идеи и ассоциации, связанные с тематикой вашего предложения;
- анализ топ-выдачи – посмотрите результаты, которые поисковики выдают по вашим запросам, и соберите ключевые слова из сниппетов;
- Яндекс.Метрика/Google Search Console – при наличии сайта посмотрите данные статистики и выберите ключи, по которым больше всего переходов с поиска.
Учтите, что базовых запросов может быть много. Старайтесь максимально их конкретизировать и сузить. Преимущественно выбирайте ключи из 1-2 слов. Длинные фразы чаще всего используют для редких товаров, брендированных запросов или как дополнение к основным. Вместе с тем отсеивайте короткие ключи слишком общего характера, чтобы не спарсить кучу нерелевантных фраз.
Итогом этого этапа станут 5-10-20 базовых словосочетаний. Они станут «каркасом» будущего списка ключей.
# 2 Дополняем базу ключевых запросов
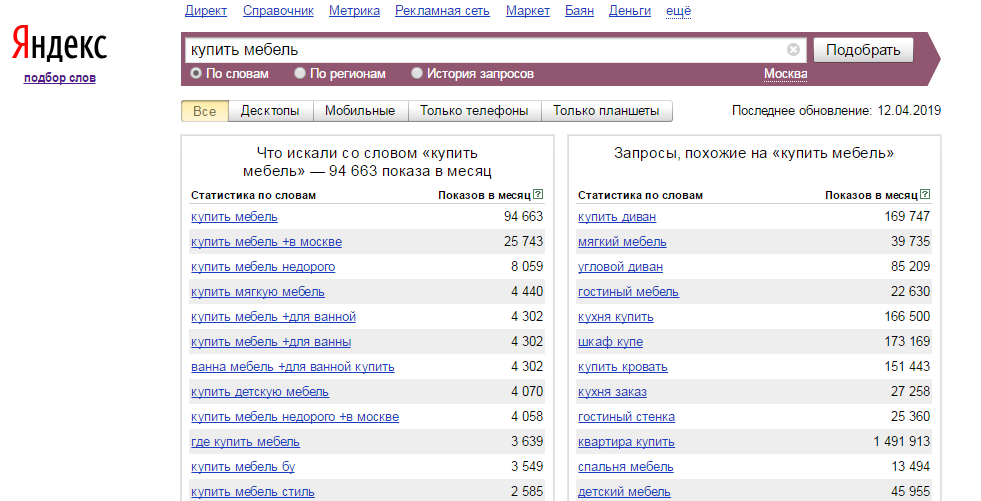
Для Рунета основным источником ключевых слов выступает поисковая система Яндекс и бесплатный сервис подбора слов Wordstat Yandex. Он показывает количество и частоту запросов по заданной фразе в Яндексе. Ключи отображаются в разных падежах. Дополнительно показаны похожие фразы. Фразы можно искать по регионам и типам устройств. Есть возможность просмотреть историю запроса за 2 года. При помощи специальных операторов можно максимально точно сформулировать проверяемый запрос и исключить лишние фразы.
Введите в строку ввода Яндекс.Вордстат базовый запрос из ранее созданного списка. Система выдаст все запросы за последние 30 дней. Выберите подходящие фразы. Аналогично поработайте со всеми базовыми ключами. При необходимости укажите регион поиска, тип устройства, точность словосочетания и минус-слова.
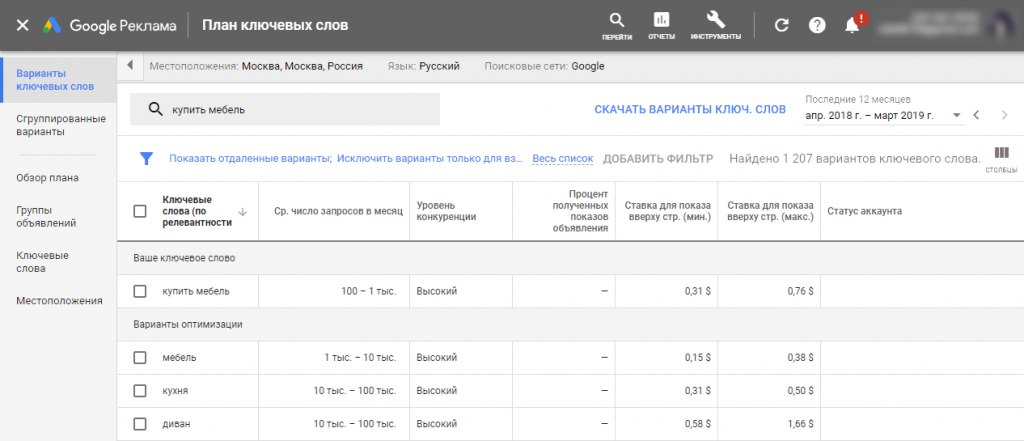
Если ниша узкая или нужно собрать максимально широкую базу ключей, дополнительно примените бесплатный Планировщик ключевых слов Google. Он показывает статистику по словам и прогнозирует эффективность ключей по заданной ставке.
Откройте Планировщик и выберите раздел «Найдите новые ключевые слова». Введите базовый запрос. Система выдаст список релевантных фраз с указанием частотности, уровня конкуренции и вариации ставок для показа. Проработайте весь список базовых ключей и выберите самые подходящие фразы.
Все собранные ключевые слова добавьте в общий Excel-файл. Однако учтите, что на этом этапе в базе могут присутствовать дубли, нерелевантные фразы, ключи с нулевой частотностью. Их нужно удалить.
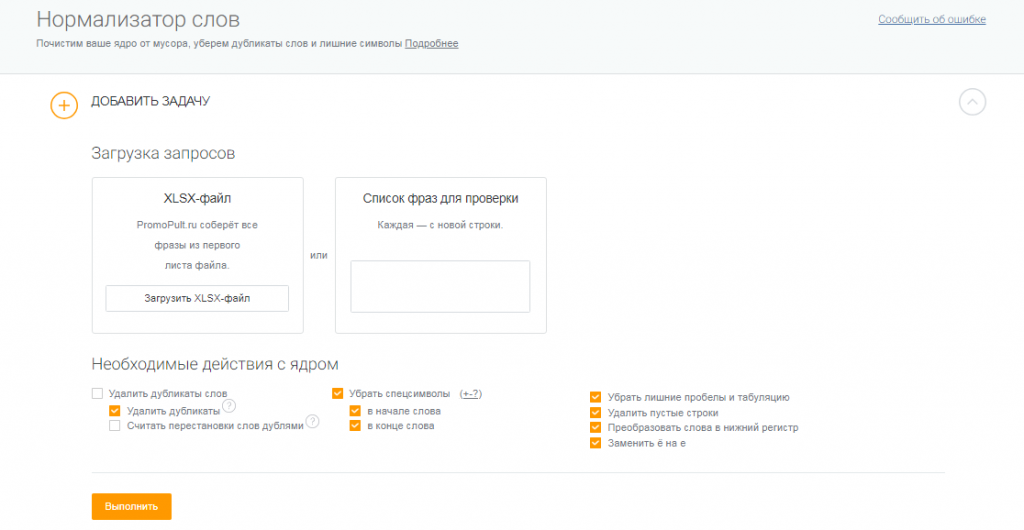
Нерелевантные запросы придется удалять вручную. Для очистки семантического ядра от мусорных фраз и дублей используйте специальные инструменты. Например, бесплатный сервис от PromoPult «Нормализатор слов» автоматически чистит базу и не ограничен количеством запросов.
Собранное ядро желательно расширить дополнительными фразами. Для этого используем сторонние парсеры.
# 3 Расширяем семантику
Для расширения ядра потребуется собрать поисковые подсказки, а также «длиннохвостые» ключи. В работе пригодятся такие инструменты, как:
- Key Collector – платная десктоп-программа. Собирает данные с популярных ресурсов. Учитывает региональность и глубину поиска. Можно применять для чистки семантического ядра.
- СловоЁБ – бесплатный парсер, практически аналогичный Key Collector. Отличием выступает некоторое ограничение в источниках.
- Keyword Tool – частично бесплатный парсер, собирающий поисковые подсказки из Google, YouTube и англоязычных ресурсов.
- Букварикс – бесплатный онлайн-инструмент с платным вариантом для десктопа. Собирает ключи по запросам и доменам сайтов.

Выбираем подходящий сервис и проверяем фразы, собранные с помощью Вордстата и Планировщика. Изучаем ключи, полученные в результате парсинга, и наиболее релевантные добавляем в общий список.
На данном этапе у нас получится довольно большой перечень ключей. Он может содержать дубликаты фраз, словосочетания с переставленными словами и схожие словоформы. Некоторые парсеры позволяют проанализировать базу. Например, Букварикс поможет убрать из загруженного списка слов морфологические дубликаты и дубликаты-перестановки.
После завершения работы целесообразно будет проанализировать конкурентов, чтобы знать, как продвигаются они.
# 4 Парсим запросы конкурентов
По поводу парсинга ключей конкурентов для контекстной рекламы мнения специалистов противоречивы. Кто-то считает, что этот способ позволяет собрать самые оптимальные фразы для Яндекс Директ и Google Ads. Другие обоснованно полагают, что использование чужих ключевиков не всегда целесообразно.
Во-первых, вы не знаете маркетинговых целей конкурентов. Их задачи могут отличаться от ваших и не соответствовать вашей стратегии. Возможно, что цель конкурента заключается в продвижении бренда и максимальном охвате аудитории, а вам нужны реальные продажи. К тому же, вы не знаете рекламный бюджет конкурента, который может в разы отличаться от вашего.
Во-вторых, рекламу конкурента мог настроить начинающий специалист. При копировании вы можете повторить все совершенные ошибки кампании. Поэтому логично использовать запросы конкурентов для проверки своего семантического ядра.
Для анализа конкурентов пригодятся следующие инструменты:
- Serpstat – анализирует домены конкурентов, объявления, посадочные страницы. Также ищет страницы с высокими показателями видимости в выдаче, показывает фразы ранжирования конкурентов из топ-10, отображает частотность фраз и проверяет уровень конкуренции. Есть ограниченная бесплатная версия.
- SpyWords – собирает ключевые слова конкурентов, тексты объявлений, трафик, бюджет, рекламные позиции. Платный инструмент.

- AdvSpider – находит объявления в РСЯ по ключевым запросам с учетом региональности показов и типа устройств. Есть демо-версия.
Выберите одного или нескольких конкурентов с максимальной схожестью. Спарсите ключи, по которым они запускают контекстную рекламу. Затем сравните собранные фразы со своими ключевыми словами. Может быть, вы упустили некоторые словосочетания и сможете дополнить ими собственную семантику.
После завершения всех вышеуказанных этапов у вас будет готовая база ключевых слов для создания объявлений контекстной рекламы. Однако в ней перемешаны разные типы запросов, отличающиеся по намерениям, степени схожести и т. д. Потому заключительным этапом подбора ключей выступает создание сегментов.
# 5 Сегментируем ключевые слова для контекстной рекламы
Сегментация базы ключевых слов для контекстной рекламы подразумевает осуществление кластеризации – разбивку семантического ядра на кластеры и группирование схожих фраз. Каждый кластер объединяет похожие ключевые слова.
Для кластеризации можно использовать сервис Rush Analytics. Для его использования нужно просто загрузить собранные ключи в одну колонку Excel, а в другой колонке документа – указать частотность . Далее вы отправляете ядро на кластеризацию, а сервис сортирует данные, создавая набор кластеров.
После сегментации собранных баз определите, какие предложения можно составить на основе каждого кластера . На основании своих выводов создайте объявления, релевантные запросам потенциальных клиентов, и запустите рекламу.
Используя парсеры, собрать ключевые запросы для контекстной рекламы сможет даже новичок. Чем точнее будут ваши ключи, тем эффективнее пройдет кампания. Но помните, что «волшебных» фраз не существует. Анализируйте результаты показов, выбирайте лучшие объявления и определяйте наиболее эффективные фразы для вашего бизнеса.
Парсеры вордстата яндекса онлайн бесплатно ключевых слов и фраз
Автор author На чтение 5 мин. Просмотров 2.8k. Опубликовано
Обновлено
WordStat от Яндекс используется для анализа поисковых запросов, количества просмотров по регионам, сезонности. Но интерфейс и ограниченная функциональность делают сервис неудобным для обработки большого числа ключевых слов. Выход – использование парсеров.
Какие есть парсеры для Вордстата?
Обработка запросов в ВордСтат возможна только в ручном режиме. Это увеличивает время формирования семантического ядра (СЯ) даже для небольшого проекта. Для автоматизации разрабатывают программы и онлайн-сервисы – парсеры. Они собирают данные статистики Яндекс, используя технологию API и другие программные комплексы. В итоге пользователь может обрабатывать большой объем информации.
Цель работы парсеров – актуальная статистика ключевых фраз с возможностью углубленного анализа по параметрам. Это реализуется следующими способами:
- Программы. Сбор актуальной статистики WordStat, анализ по критериям пользователя. Условия использования – условно-бесплатное или платное.
- Онлайн-сервисы. По сравнению с программами обладают меньшим функционалом. Преимущества – экономия времени, не нужно устанавливать ПО.
- Специализированные программы. Разрабатываются для решения узконаправленных задач.
Выбор зависит от объема запросов и точности результатов. Онлайн-сервисы скачивают данные из Яндекса, чтобы уменьшить время формирования отчета. Поэтому информация не объективная. На это влияет частота обновления баз конкретного парсера.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор

Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб

Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан

Программный комплекс «Магадан» по возможностям схож с Кей Коллектором, в том числе – по цене. Отличия – интерфейс и наличие бесплатной версии. Последняя с ограниченным функционалом, что делает ее аналогичной «Словоёбу». Есть полноценная информационная и техническая поддержка как для версии Lite, так и для Pro.
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия

Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия

Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
Бесплатные парсеры
В Сети можно найти бесплатные версии парсеров, которые по заверениям разработчиков ничем не уступают вышеописанным программам и сервисам. Однако в большинстве случаев это «сырой» продукт с рядом недостатков – отсутствие обновлений, неудобный интерфейс, ограниченные функции. Низкая точность выборки, часто возникают ошибки. Причина – Яндекс.Вордстат постоянно изменяется, за этим нужно следить и вносить корректировки в ПО.
Если бесплатное использование является обязательным условием, можно скачать актуальные версии «Словоёб» или «Магадан». Альтернатива – воспользоваться возможностями «Букварикса» после регистрации.
Выбор парсеров зависит от поставленной задачи – объема ключевых фраз, точности выборки и дальнейшей обработки результатов. Для больших проектов рекомендуются платные версии, для ознакомления с возможностями и для составления СЯ для 1-3 сайтов – бесплатные.
Что такое Яндекс Вордстат и как им правильно пользоваться
Как производится подбор статистики по запросам и парсинг ключевых слов в Яндекс Вордстат (Wordstat)? Как с ним работать? Как собрать семантическое ядро сайта через данный парсер? И что такое операторы: плюс, минус, восклицательный знак, кавычки и скобки? Давайте сегодня разберем все эти вопросы.
Онлайн Парсер Wordstat — что это и зачем он нужен
Вордстат — это сервис, рассчитанный для сбора статистики ключевых запросов по заданным городам и техническим устройствам, которые пользователи вбивают в поисковой строке Яндекса. Иными словами, с помощью данного парсера вы получаете сведения о базовой или точной частности, а также количестве слов по необходимой теме.
На сегодняшний день Wordstat является очень полезным инструментом в услугах по SEO-оптимизации сайта или его конкретной страницы. Помимо этого, с помощью данного сервиса вы сможете провести анализ любой интересующей вас отрасли и более детально понять насколько она популярна среди других пользователей. Разумеется, SEO-специалисты пользуются множеством других сервисов помимо него, но, в большинстве случаев, первичный анализ по предоставленной информации от клиента, начинается именно с этого парсера. Конечно Вордстат — это не совсем парсер, так как, он является внутренним сервисом Яндекса, который предоставляет сведения о количестве запросов пользователей в самой поисковой системе.
Базовая частотность — это общая информация, которую вы получаете, когда пишите запрос в Вордстате без синтаксиса, склонения и точной словоформы. Она демонстрирует общее число всех слов или словосочетаний, в которых присутствуют фразы, входящие в данный запрос в любых словоформах и очереди.
Точная частотность — это число обращений человека с определенным словом или словосочетанием к поисковой системе в период 30 дней.
Помимо этого, используя Вордстат, вы можете без труда определить сезонность и региональность ключевых слов. В принципе, вот такой незамысловатый сервис. Давайте теперь рассмотрим детали того, как пользоваться Wordstat.
Как работать с Вордстатом
Как же осуществляется проверка частотности ключевых слов в Вордстате? Для начала давайте начнем с простого и понятного примера.
Перед тем, как начать работу в данном сервисе вам необходимо в нем зарегистрироваться (то есть иметь аккаунт в Яндексе).
Регистрация в Вордстате
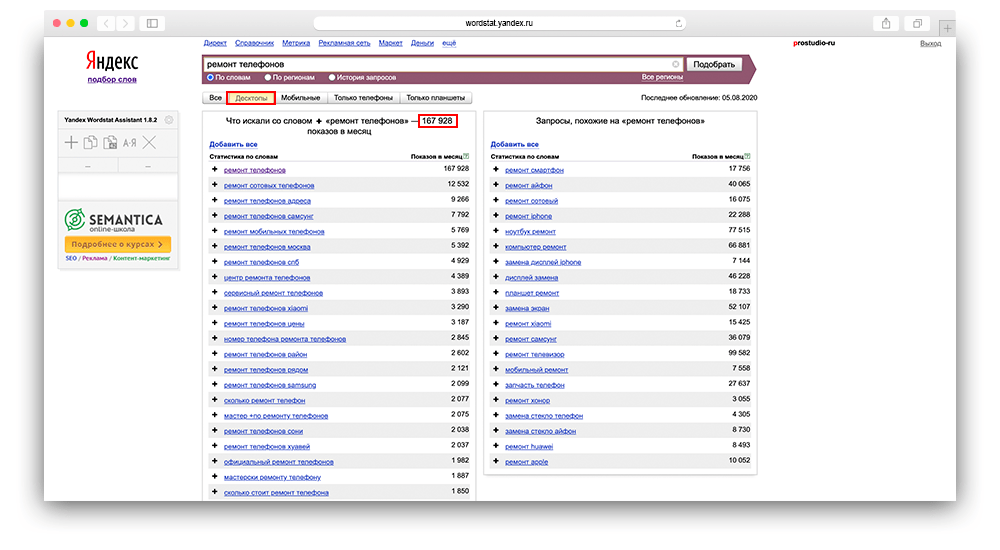
Затем можете «вбивать» запрос, который вас интересует в поисковую строку. Для того, чтобы рассмотреть функционал сервиса, давайте возьмем часто задаваемый вопрос пользователей: «ремонт телефонов».
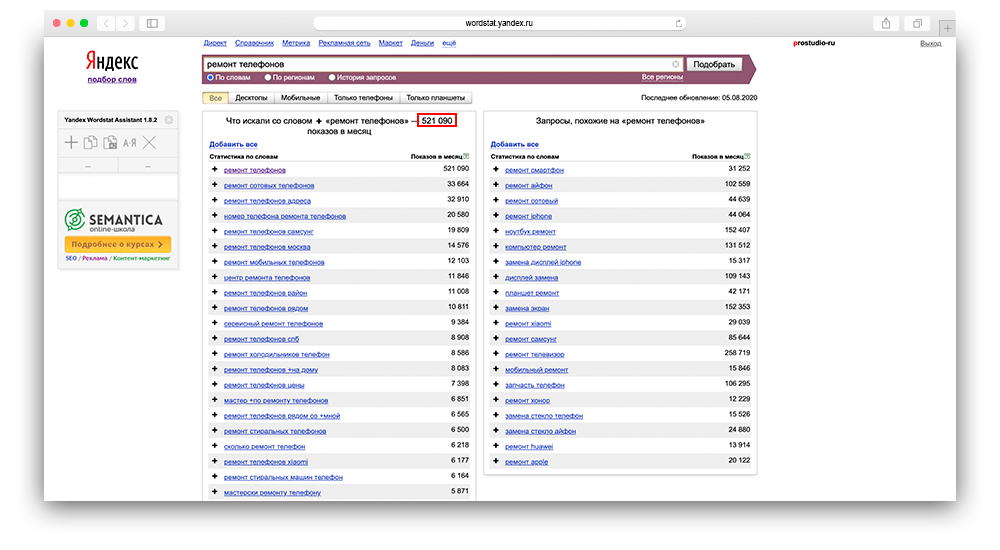
Как работать с Вордстатом
Как вы могли заметить, выдача разделяется на 2 колонки:
- Левая колонка — демонстрируется вся статистика по словам, которые вбивают в связке с «ремонт телефонов». Следовательно, цифра, которая показывает частотность запроса, не относится непосредственно к двум искомым словам, а демонстрирует общее количество запросов, подсчитывая все нижеуказанные словоформы, расположенные под данным словосочетанием. Для сбора точной частотности необходимо использовать вспомогательные операторы.
- Правая колонка — отображаются схожие смысловые запросы с указанной тематикой. У вас может возникнуть вполне логичный вопрос: «Каким образом система определяет аналогичность запросов?». Не вдаваясь в подробности, выглядит это так: Wordstat собирает всю информацию о каждом пользователе: какие запросы он вбивал и в какой период времени, а затем, проводит некий анализ, сопоставляя схожие запросы друг с другом у большинства пользователей за последние 30 дней. Пример: в период 30-и дней 100 человек запросило: «разработка интернет магазина». Из них 40 человек запросило: «продвижение сайта». В следствии чего, система отслеживает одинаковые запросы у одних и тех же пользователей и генерирует готовое решение в правую колонку подсказок.
Как выгрузить слова из Вордстата в Эксель
Здесь все очень просто. Вам необходимо:
- Установить специальное расширение для браузера.
- На странице Wordstat, в левом углу у вас появится окно.
- Затем вводите необходимый запрос.
- Напротив каждого слова или словосочетания, полученных в выдаче, вы увидите иконку «+».
- Вам нужно нажимать на «+», расположенный около каждого интересующего вас запроса, таким образом данные слова будут попадать в окно.
- В верху окна находятся две иконки — скопировать с частотностью и без нее.
- Выберите нужный вам способ копирования, затем вставьте в Эксель.
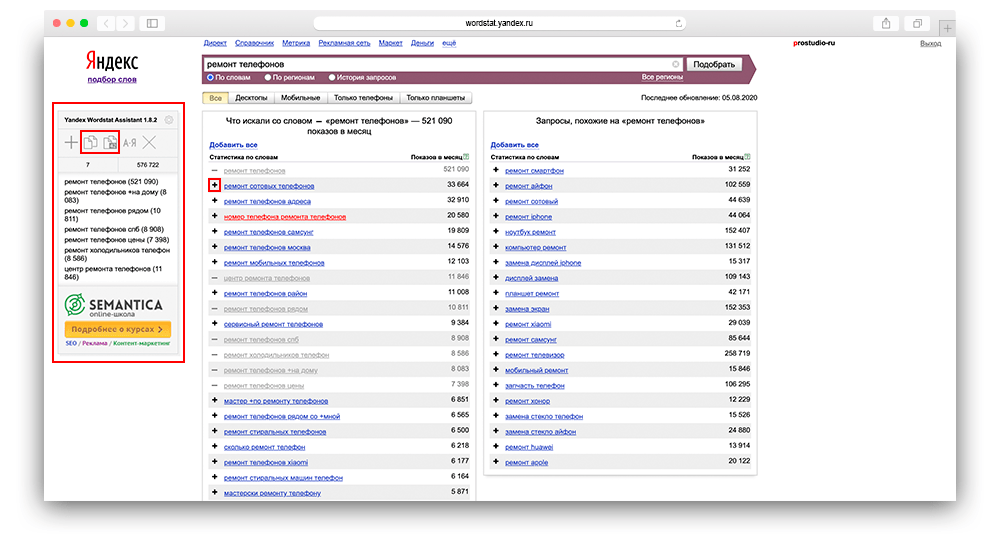
Как выгрузить слова из Водстата в Эксель
Разумеется, вы можете просто их копировать без вспомогательных сервисов, однако у вас уйдет на это чуть больше времени. Разобравшись с базовым функционалом данного сервиса, давайте рассмотрим, как правильно осуществлять подбор ключевых слов для точного вхождения по поисковой фразе.
Что такое операторы
Для уточнения информации по результатам выдачи ключевых слов, необходимо понять, что такое операторы.
Операторы — это специализированные символы, являющие вспомогательным инструментом для определения точной частотности искомого запроса. Перечень операторов:
- кавычки;
- плюс;
- минус;
- восклицательный знак;
- круглые скобочки;
- квадратные скобки.
Кавычки
« » — с помощью данного оператора, вы получите сведения именно о том количестве слов, сколько вписывали в запрос без дополнительных словоформ. То есть, если вы написали: «ремонт телефонов», то информации по: «ремонт мобильных телефонов» не будет. Но данный оператор не фиксирует словосочетание, от склонений, множественной и единственной формы. То есть, вам будут демонстрироваться сведения по: «ремонту телефонов»; «телефонов ремонт» и так далее.
Пример использования: «ремонт телефонов».
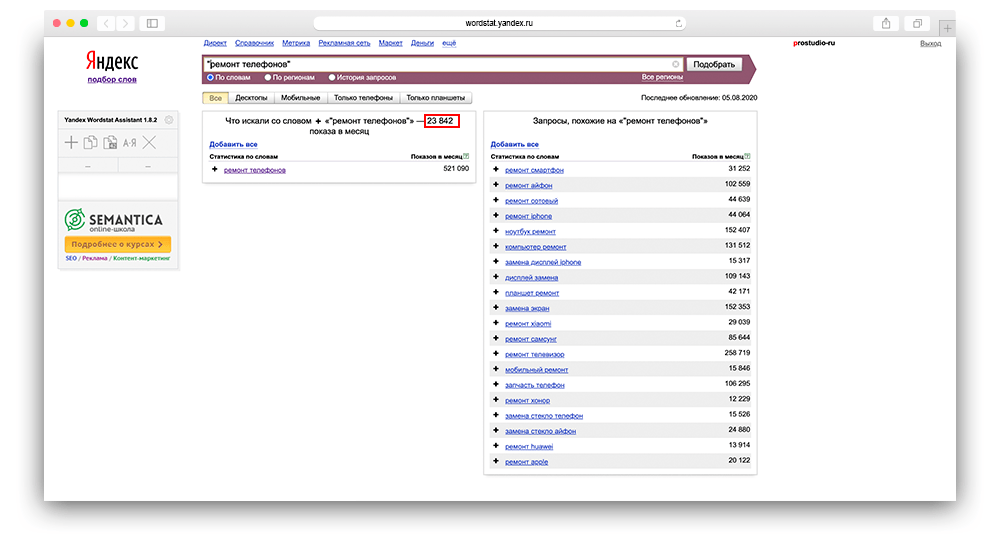
Вордстат — слова в кавычках
Восклицательный знак
! — определяет форму запроса. Другими словами, вы получите точную информацию именно о словосочетании: «ремонт телефонов», без склонения, падежа, числа и времени, таких как: «ремонту телефонов»; «ремонта телефонам» и так далее. Также нельзя забывать о том, что восклицательный знак должен ставиться перед каждым словом, без отступов.
Пример использования: !ремонт !телефонов.
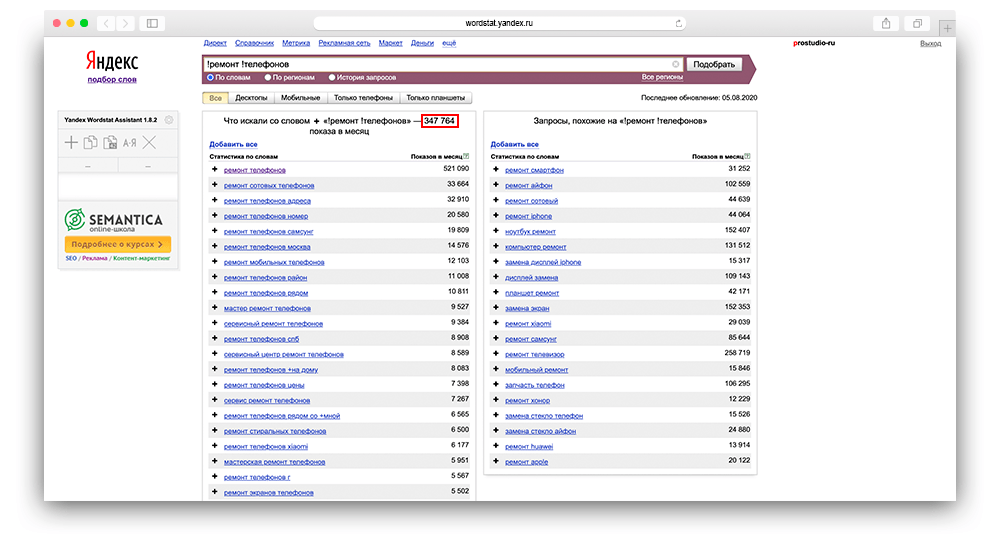
Вордстат — восклицательный знак перед словом
Квадратные скобки
[ ] — показывает порядок слов в запросе. Этот оператор актуально использовать для изучения запросов в отношении билетов из одного города в другой. Например, если вы хотите узнать количество людей, которым интересно путешествие из Санкт-Петербурга в Москву, а не наоборот, то данный оператор вам окажет помощь в этом. Так как, количество запросов «билеты Санкт-Петербург — Москва» составляет 5 916 за последние 30 дней, а: «билеты Москва — Санкт-Петербург» составляет 14 528 за последние 30 дней. Следовательно, как вы сами могли заметить показатели сильно разнятся и без данного уточнения, вы получили бы в корне не верные цифры по искомому запросу. Возвращаясь к примеру: «ремонт телефонов», с помощью этого оператора, вы сможете понять порядок слов и более детально провести анализ запросов в данной области, для дальнейшего формирования рекламного объявления или составления заголовков на продающей странице.
Пример использования: [ремонт телефонов].
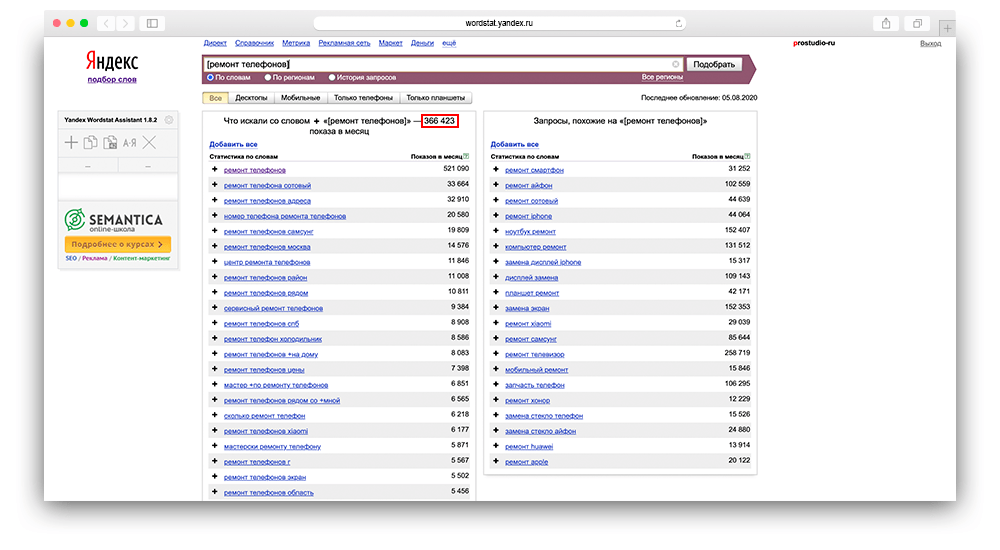
Вордстат — слова в квадратных скобках
Плюс
«+» — существуют некоторые слова и предлоги, которые Wordstat не учитывает. Данный оператор принудительно делает такие слова видимыми для сервиса.
Пример использования: ремонт телефонов +это.
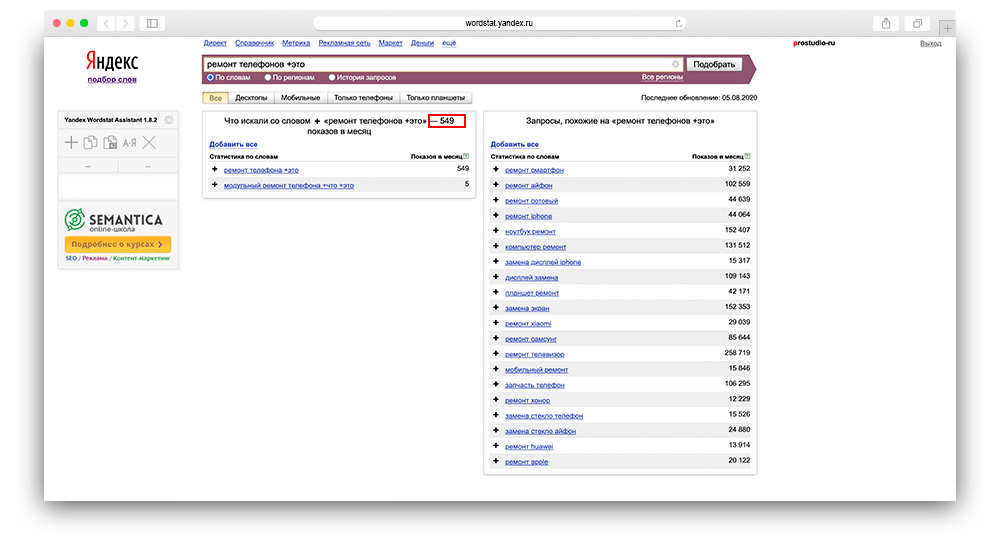
Вордстат — плюс перед словом
Минус
«-» — в свою очередь, убирает не нужные слова, находящиеся в списке выдачи.
Пример использования: ремонт телефонов -дешево -центр — цена.
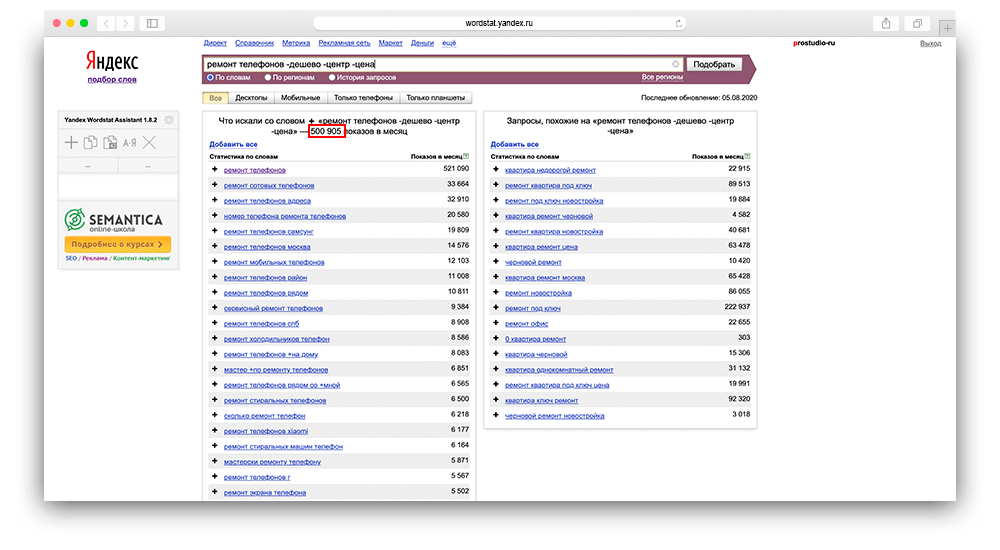
Вордстат — минус перед словом
Круглые скобочки
«( | )» — позволяют сгруппировать поисковые фразы.
Пример использования: ремонт (телефонов | компьютеров).
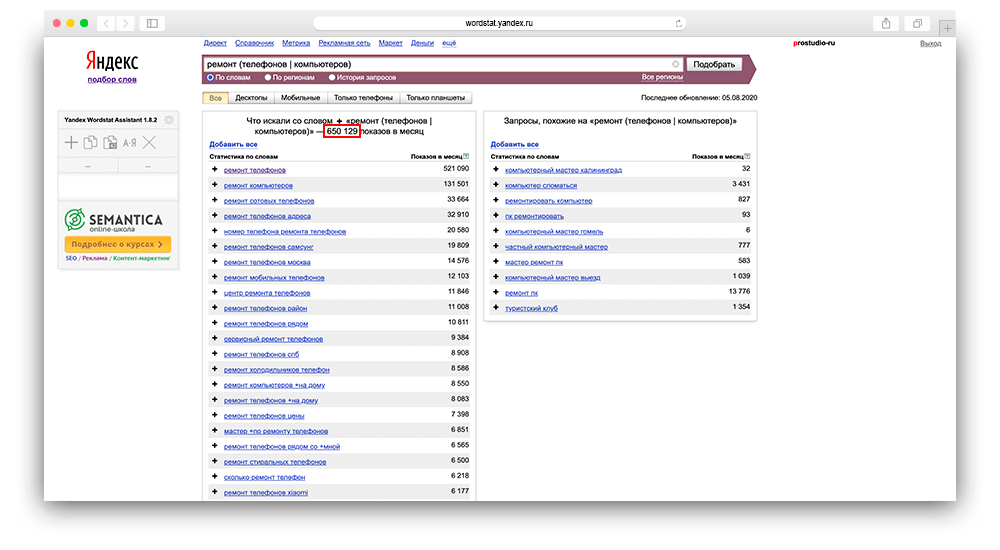
Вордстат — слова в круглых скобках
Ответы на часто задаваемые вопросы
Очень часто мы слышим нижеуказанные вопросы от начинающих SEO-оптимизаторов и маркетологов. Поэтому решили сформировать перечень кратких ответов на них.
Что такое десктопы
Выбирая раздел «десктопы», вы даете команду сервису — показывать только сведения о поисковых запросах с ноутбуков и компьютеров.
Что такое десктопы в Вордстате
Как производится массовая проверка частотности запросов
Здесь все зависит от тематики и объема базовой частоты запросов. Другими словами, совершая данную процедуру, вы проводите детальный анализ каждого слова. Тем самым, вам необходимо собрать все классы частотностей запросов:
- высокочастотные — больше 10 000 запросов за 30 дней;
- среднечастотные — от 1000 до 10 000 запросов за 30 дней;
- низкочастотные — меньше 1 000 запросов за 30 дней.
Однако, данные разделения условные, все зависит от тематики запросов. Поэтому, в некоторых случаях, с помощью вышеуказанного расширения, вы производите подбор необходимых запросов и переносите их в Excel. Иногда количество слов по интересующей вас тематике слишком большое и лучше воспользоваться вспомогательными программами для составления семантического ядра, такими как, Key Collector.
Как убрать капчу
Если вы хотите отключить капчу вам нужно:
- Установить adblock.
- Зайти на сервис Wordstat.
- Нажать кнопку adblock, расположенную в верхнем правом углу.
- И выключить adblock находясь на странице Вордстата.
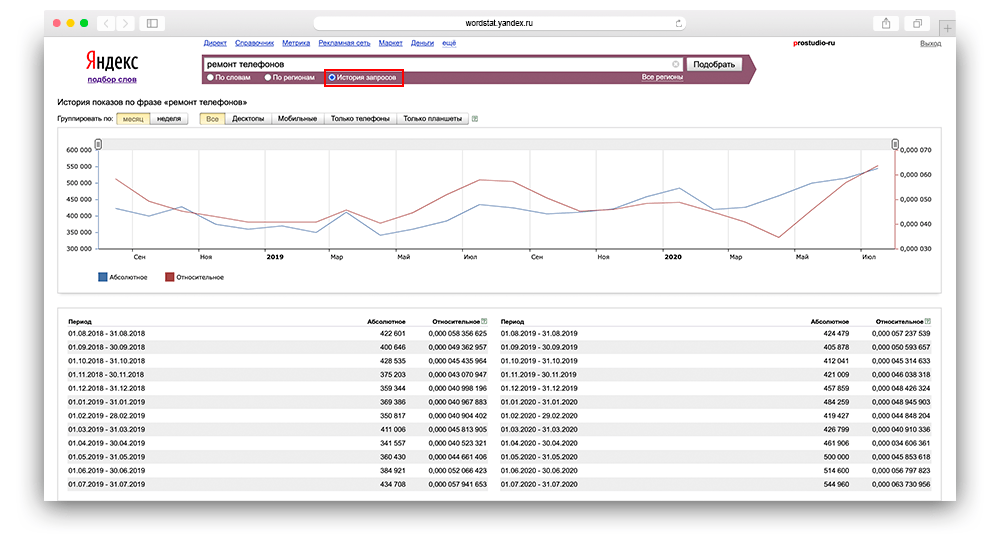
Как посмотреть историю запросов
Если вы хотите посмотреть историю запросов, вам требуется кликнуть на белый кружек, расположенный справа от словосочетания «История запросов», которое находится под поисковой строкой Вордстата.
Как посмотреть история запросов в Вордстате
Как вы могли заметить, диаграмма демонстрирует сведения по месяцам, при этом вы можете узнать выдачу по неделям.
Абсолютное значение — это практическое определение запросов в разное время.
Относительное значение — это соотношение запросов по выбранным ключевым словам к общему количеству запросов в Яндексе. Простыми словами, на этой диаграмме демонстрируется популярность ключевого слова по отношению ко всем остальным.
История запросов может сильно помочь при продаже сезонных товаров, к примеру аренде водных видов транспорта, так как, выдача летом и зимой может кардинально отличаться.
Заключительный результат
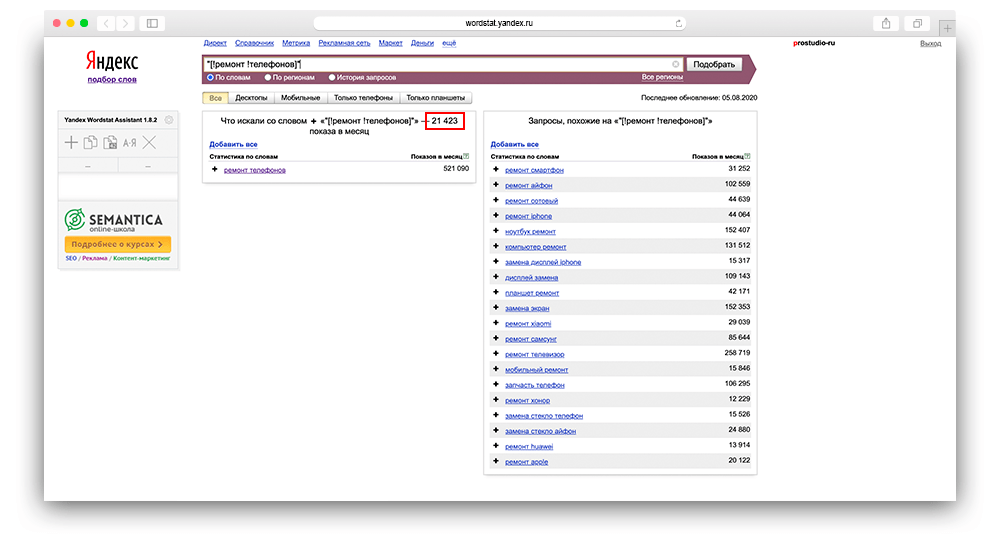
В заключении давайте посмотрим, как целиком выглядит точная частотность запроса в Вордстате.
Пример использования: «[!ремонт !телефонов +это]».
Вордстат — заключительный результат
Таким образом, вы получайте наиболее точную информацию по искомому запросу. То есть фиксируйте запрос в отношении числа, времени, склонения, количества дополнительных слов и последовательности. Если у вас остались вопросы по прочитанному материалу — напишите нам в комментариях и мы вам ответим.
Parser — парсер для профессионалов SEO
A-Parser — многопоточный парсер поисковых систем,
сервисов оценки сайтов,
ключевых слов,
контента(текст, ссылки, произвольные данные) и других различных сервисов(youtube, картинки, переводчик…),
всего A-Parser содержит более 70 парсеров
На сегодняшний день A-Parser развился в невероятный SEO комбаин,
позволяющий покрыть огромное число задач для SEO-специалистов и вебмастеров любого уровня подготовки:
- Используйте встроенные парсеры чтобы с легкостью получать и анализировать любые данные
- Воспользуйтесь нашим каталогом парсеров и пресетов
для расширения возможностей A-Parser и решения нестандартных задач - Если вы продвинутый пользователь — создавайте свои собственные парсеры на основе
регулярных выражений или XPath - Владеете JavaScript? Тогда A-Parser предлагает вам беспрецедентную возможность программировать
свои собственные парсеры, используя всю мощь возможностей A-Parser! - Для автоматизации мы предлагаем API позволяющий легко встроить A-Parser в ваши бизнес процессы,
а также для создания сервисов любого уровня сложности на базе нашего парсера
Кроме этого мы предоставляем услуги по составлению заданий и написанию парсеров под ваши задачи,
в кратчайшие сроки и по демократичной цене.
Хотите спарсить целиком интернет магазин(Ozon, Amazon, AliExpress)?
Проверить 100 миллионов сайтов по вашим признакам?
Получить данные с любого сайта в структурированном виде(CSV, JSON, XML, SQL)?
В решении этих задач поможет наша дополнительная платная поддержка
A-Parser полностью решает рутинные задачи по получению, обработке и систематизации данных, необходимых для работы в следующих областях:
- SEO-оптимизация сайтов и Web-аналитика
- Сбор баз ссылок для XRumer, A-Poster, AllSubmitter, ZennoPoster…
- Оценка сайтов и доменов по множеству параметров
- Мониторинг позиции любых сайтов в поисковых системах
- Сбор контента(текст, картинки, ролики) для генерации сайтов(дорвеев)
- Отслеживание обратных ссылок
- Сбор произвольной информации с любых сайтов(например телефоны/e-mails, сообщения с форумов, объявления…)
- Сбор и оценка ключевых слов
- Сбор списка обратных ссылок
- И многое другое
- Web-безопасность
- Сбор и фильтрация баз ссылок по признакам
- Определение CMS сайтов
- Формирование произвольных GET, POST запросов с одновременной фильтрацией ответа
- Сетевое администрирование
- Работа с DNS службой — резолвинг доменов в IP адреса
- Работа с Whois — дата регистрации и окончания регистрации доменов, name-cервера
Данный список включает лишь частые варианты применения парсера, A-Parser позволяет решать самые нестандартные задачи комбинируя его возможности, такие как:
A-Parser создавался и продолжает развиваться учитывая более чем 10 летний опыт разработки парсеров и многопоточных сетевых приложений, разработка ведется исключительно по следующим принципам:
- Быстродействие и производительность, прежде всего за счет многопоточной обработки запросов
- Максимальная эффективность использования ресурсов компьютера или сервера
- Функциональность и удобство использования, наш продукт ориентирован на пользователя
- Для каждой задачи выбирается лучший инструмент или алгоритм, предварительно прошедший тщательное тестирование
Для дальнейшего знакомства с A-Parser‘ом рекомендуется полноценно оценить его преимущества,
ознакомится с отзывами пользователей,
выбрать необходимую версию
и перейти к оплате лицензии
50 лучших инструментов для работы с семантическим ядром — Devaka SEO Блог
180К
просмотров
Составление и обработка семантического ядра – одна из ключевых задач в SEO. Ниже представлен список инструментов и сервисов для работы с семантикой: подбор, группировка, фильтрация, кластеризация ключевых слов и другое.
Собственные системы аналитики

Собственные счетчики и системы аналитики позволяют собирать списки ключевых слов, по которым люди уже заходили на сайт. Самые популярные из них, и бесплатные:
— Google Analytics
Не покажет зашифрованные запросы Яндекса, а также скроет многие ключи, по которым люди переходили из Google, но какой-то полезный список ключевых слов все же можно получить. При связи с панелью для вебмастеров можно получить больше информации по запросам.
— Яндекс.Метрика
Статистика переходов и ключевых слов из Яндекса и других поисковиков, в том числе из Яндекс.Картинок.
— LiveInternet
Полезно использовать вместе с другими системами аналитики, чтобы собирать как можно больше данных.
Сервисы поисковых систем

Поисковики предоставляют собственные бесплатные сервисы для анализа и подбора ключевых слов.
— Яндекс Вордстат
Подбор ключевых слов от Яндекса. Можно задавать регион и искать связанные слова, смотреть популярность запросов.
— Рамблер Вордстат
Статистика по запросам от Рамблера. Можно выбирать период и проверять сезонность запросов. Также позволяет узнать популярность запроса в разных странах и российских регионах.
— Keyword Planner от Google
Подбор запросов от Google. Можно настроить поиск не только слов из органики, но и видео-запросов с YouTube.
— Статистика запросов от Mail.ru
Реальные запросы в Mail с демографической статистикой. Хорошо показывает, что некоторые высокочастотные фразы не такие уж высокочастотные.
— Тренды Google
Поиск трендовых (быстрорастущих) запросов, текущих, за период или в разных странах.
— Google Correlate
Поиск слов, коррелирующих с заданным. Производится на основе поведенческих данных (одинаковой активности пользователей по разным запросам).
Готовые оффлайн и онлайн базы

Готовая база ключевых слов – также хороший источник семантики. Все базы обычно платные.
— База Пастухова [платная]
База русскоязычных ключевых слов с данными по количеству запросов в Яндексе и цене кликов в Бегуне. Автоматизированные фильтры и разные функции для работы со списками ключевиков через программный интерфейс.
— UP Base [платная]
Русская и английская базы ключевых слов из различных доступных источников, очищенные от мусора. Программа имеет ряд требований и ограничений.
— Мутаген [платная]
Онлайн-база, где можно подобрать эффективные ключевики. Показывает для запросов уровень конкуренции, имеет API.
— KeyBooster [платная]
Хранит запросы, которые люди парсили из вордстата сервисом «Магадан».
— RooStat [платная]
База запросов из Рунета для интеграции в свой софт. Ежемесячные обновления.
Сервисы анализа конкурентов

Эти сервисы предназначены для анализа конкурентов и имеют широкий функционал, в том числе здесь можно быстро составить семантическое ядро, основываясь на семантике заданных сайтов.
— АДВСЁ [платная]
Статистика поисковой рекламы в Яндексе и Google. Подбор семантики, исходя из конкретных сайтов (поиск запросов, по которым эти сайты размещают контекстную рекламу).
— advODKA [платная]
Анализ ключевых слов, по которым показываются объявления сайта, видимость домена в ТОП20 Яндекса и Google (регионы «Москва» и «Питер») с различной статистикой.
— SpyWords [платная]
Анализ семантики сайтов-конкурентов, поиск уникальных запросов видимости домена в поиске (по московскому региону), по сравнению с другими заданными доменами.
— SemRush [платная]
Собирает ТОП20 Google и Bing по 100 млн. запросов. Удобный инструмент для тех, кто продвигает сайт под русскоязычный или зарубежный Google.
— Prodvigator [платная]
Анализ украинского, российского, болгарского и казахстанского Google, а также поисковой выдачи Яндекса (Мск) по базе реальных запросов. Быстрая выборка не только поисковых запросов, но и подсказок.
— TopVisor [платная]
Парсинг контекста (Яндекс, Гугл), поисковых подсказок (в т.ч. из Mail и Спутника) или выгрузка ключевиков из панели для вебмастеров или системы аналитики для анализируемых проектов.
— Spy Fu [платная]
Подбор англоязычных запросов для зарубежных проектов. Итоговая статистика имеет параметр сложности продвижения запросов.
— Keyword Eye [платная]
Просмотр конкурентости заданных англоязычных ключевых слов в виде облака. Формирование предложений (выгрузка из готовой базы по заданной фразе).
— SimilarWeb [условно бесплатно]
Отображает разные параметры сайта, в том числе, по каким запросам он получает трафик из органического поиска или контекста.
— Alexa [условно бесплатно]
Подобный сервису SimilarWeb. В бесплатной версии можно узнать лишь 5 трафиковых запросов сайта. Берет данные из своего тулбара.
Специализированные сервисы подбора семантики

— keywordtool.io [бесплатно]
Удобная альтернатива AdWords Planner. 750 предложений для каждого ключевого слова, основанные на подсказках Google для разных языков (83 доступных языка) и регионов (192 домена Google). Подбор семантики из YouTube, AppStore и Bing.
— fastkeywords.biz [условно бесплатно]
Поиск по базе ключевых слов. Имеет возможность задавать маску, чтобы находить слова с разными окончаниями. Неизвестно, как часто обновляется.
— actualkeywords.com [платная]
Поиск по готовой базе англоязычных ключевых слов, готовые тематические подборки.
— keywords.megaindex.ru [бесплатно]
Подбор ключевых слов для сайта от MegaIndex. Неудобно, но бесплатно.
—wordtracker.com [платная]
Популярный зарубежный инструмент анализа ключевых слов.
—ubersuggest.org [бесплатно]
Парсер поисковых подсказок Google. Можно задать язык и вертикаль поиска – например, спарсить семантику из поиска по изображениям или новостям.
—wordpot.com [бесплатно]
Бесплатный подбор англоязычных запросов.
—words.elama.ru [бесплатно]
Удобный подбор поисковых запросов. Правда нет возможности экспортировать список.
—keywordtooldominator.com/k/amazon-keyword-tool/ [бесплатно]
Семантика из интернет-магазина Амазон. Очень удобный инструмент для сбора коммерческих (транзакционных) запросов.
Программы для работы с семантическим ядром

— Key Collector [платная]
Многофункциональная программа под Windows для работы с семантическим ядром.
— Yandex Wordstat Helper [бесплатно]
Расширение для Mozilla Firefox и Google Chrome, ускоряющее сбор ключевых слов в Яндекс.Вордстате.
— export.yandex.ru/inflect.xml [бесплатно]
Склонятор ключевых слов от Яндекса.
— Mystem [бесплатно]
Программа от Яндекса для морфологического анализа текста на русском языке. Можно использовать для приведения ключевых слов в нормальную форму.
— Магадан [платная]
Парсер ключевых слов Яндекс.Директа (Вордстата). Помогает составлять семантическое ядро и подготавливать рекламные кампании.
— tools.k50project.ru/lemma/ [бесплатно]
Лемматизатор для лингвистических экспериментов. Приведение ключевых слов к нормальной форме.
— kg.ppc-panel.ru [бесплатно]
Создание групп запросов по общим вхождениям. Удобный и простой инструмент.
— Макрос от Devaka [бесплатно]
Макрос для OpenOffice, упрощающий классификацию поисковых запросов.
Другие инструменты для работы с семантическим ядром

— Keyword Organizer [платно]
Удобный инструмент для группировки ключевых слов, создания контента под определенные группы.
— Just Magic [платно]
Авто-подбор семантики для SEO и контекста, подбор релевантных страниц под запросы.
— Key Assistant [бесплатно]
Ручная группировка ключевых слов по страницам.
— МегаЛемма [платно]
Очистка семантического ядра от мусора, группировка ключевых слов, экспорт результатов в удобном формате.
— Rush Analytics [платно]
Парсинг вордстата и поисковых подсказок, кластеризация поисковых запросов на основе подобия ТОПа. На выходе – практически готовая структура сайта.
— s:toolz [платно]
Кластеризация поисковых запросов на основе поисковой выдачи. Ещё один сервис по автоматизации подбора семантического ядра для сайта.
— Кейса [платно]
Фильтрация ключевых слов, быстрое распределение по группам, возможности внесения дополнительных данных. Ускоряет работу с большими списками запросов.
Если этот список инструментов оказался для вас полезным, поделитесь ссылкой на него с друзьями.
Как парсить ключевые слова для контекстной рекламы: краткое руководство
Яндекс.Директ, Яндекс Маркет, Google Adwords, Google Merchant, Ремаркетинг
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Для запуска поисковой контекстной рекламы необходимо создать объявления, интересные потенциальным клиентам.Чтобы вызвать интерес, нужно знать по каким запросам аудитория ищет ваш товар или услугу. Если вы указываете ключевые слова наугад, то рискуете «слить» бюджет впустую. На ручном подборе вы потратите недели и месяцы упорного труда. Оптимальным является использование парсеров и вспомогательных SEO-инструментов. Поговорим о том, как парсить ключевые слова для контекстной.
Как работает контекстная реклама
Контекстная реклама направлена непосредственно на людей, которые искали / ищут ваш товар / услугу.Пользователь вводит запрос в поисковую строку и в первых строках выдачи видит релевантное рекламное объявление.
Объявления контекстной рекламы содержат фразы, соответствующие конкретным запросам клиентов. Следовательно, для их создания нужно выбрать ключевые слова, которые могут использовать ваша целевая аудитория.
Как парсеры помогают в подборе коммерческих запросов
Парсеры — это программы или скрипты, которые автоматически собирают необходимые данные с источников.Они изучают содержимое веб-страниц, выбирают нужную информацию и сохраняют в виде готового отчета.
При подборе ключевых слов парсеры анализируют пользователей в поисковых системах, тематические сайты и статистические данные. На основе анализа формируется список заданных и похожих фраз с указанием частотности показа. Из полученного перечня рекламодатель может выбрать наиболее релевантные словосочетания для создания объявлений. Рассмотрим все этапы сбора ключевых запросов.
Пошаговое руководство: как парсить ключевые слова для контекстной рекламы
Подготовку к запуску рекламной кампании в поиске начать с вашего анализа предложений: что вы предлагаете, почему клиентам это может быть интересно, чем вы отличаетесь от конкурентов и прочее.Эта информация поможет понять, что могут искать ваши потенциальные клиенты. Начинаем парсить.
# 1 Подбираем основные ключевые фразы
В первую очередь определяем базовые запросы. Это популярные ключевые слова, которые характеризуют ваш товар / услугу.
Для подбора базовых фраз використов:
- «мозговой штурм» — соберите все идеи и ассоциации, связанные с тематикой вашего предложения;
- анализ топ-выдачи — посмотрите результаты, которые поисковики выдают по вашим запросам, и соберите ключевые слова из сниппетов;
- Яндекс.Метрика / Google Search Console — при наличии сайта посмотрите данные по поиску ключей, по которому больше всего переходов с поиска.
Учтите, что базовых запросов может быть много. Старайтесь максимально их конкретизировать и сузить. Преимущественно выбирайте ключи из 1-2 слов. Длинные фразы чаще всего используют для редких товаров, брендированных запросов или как дополнение к основным. Вместе с тем отсе содержат короткие ключи слишком общего характера, чтобы не спарсить кучу нерелевантных фраз.
Итогом этого обновления 5-10-20 базовых словосочетаний. Они станут «каркасом» будущего спи
.
Parser — парсер для профессионалов SEO
A-Parser — многопоточный парсер поисковых систем ,
сервисов оценки сайтов ,
ключевых слов ,
контента (текст, ссылки, произвольные данные) и других различных сервисов (youtube, картинки, переводчик …),
всего A-Parser содержит более 70 парсеров
На сегодняшний день A-Parser развился в невероятный SEO комбаин,
позволяющий покрыть огромное число задач для SEO-специалистов и вебмастеров любого уровня подготовки:
- Используйте встроенные парсеры, чтобы с легкостью получать и анализировать любые данные
- Воспользуйтесь нашим каталогом парсеров и пресетов.
для расширения возможностей A-Parser и решения нестандартных задач - Если вы продвинутый пользователь — создавайте свои собственные парсеры на основе
регулярных выражений или XPath - Владеете JavaScript ? Тогда A-Parser предлагает вам беспрецедентную возможность программирования
свои собственные парсеры, используя все мощь возможности A-Parser! - Для использования предлагаем API позволяющий легко встроить A-Parser в ваши бизнес-процессы,
а также для создания сервисов любого уровня сложности на базе нашего парсера
Кроме этого мы предоставляем услуги по составлению заданий и написанию парсеров под ваши задачи,
в кратчайшие сроки и по демократичной цене.Хотите спарсить целиком интернет магазин ( Ozon, Amazon, AliExpress )?
Проверить 100 миллионов сайтов по вашим признакам?
Получить данные с любого сайта в структурированном виде ( CSV, JSON, XML, SQL )?
В решении этих задач поможет наша дополнительная платная поддержка
A-Parser полностью решает рутинные задачи по получению , обработка и систематизации данных, необходимых для работы в следующих областях:
- SEO-оптимизация сайтов и веб-аналитика
- Сбор баз ссылок для XRumer, A-Poster, AllSubmitter, ZennoPoster…
- Оценка сайтов и доменов по множеству параметров
- Мониторинг позиции любых сайтов в поисковых системах
- Сбор контента (текст, картинки, ролики) для генерации сайтов (дорвеев)
- Отслеживание обратных ссылок
- Сбор произвольной информации с любых сайтов (например, телефоны / e-mails, сообщения с форумов, объявления …)
- Сбор и оценка ключевых слов
- Сбор списка обратных ссылок
- И многое другое
- Web-безопасность
- Сбор и фильтрация баз ссылок по признакам
- Определение CMS сайтов
- Формирование произвольных GET, POST-запросов с одновременной фильтрацией ответа
- Сетевое администрирование
- Работа с DNS-службой — резолвинг доменов в IP-адресе
- Работа с Whois — дата регистрации и окончания регистрации доменов, имя-cервера
Данный список включает лишь частые варианты применения парсера, A-Parser позволяет решать самые нестандартные задачи комбинируя его возможности, такие как:
A-Parser создавался и продолжает развиваться более чем 10 летний опыт разработки парсеров и многопоточных сетевых приложений, разработка ведется исключительно по следующему принципу:
- Быстродействие и , прежде всего за счет многопоточной обработки запросов
- Максимальная эффективность использования ресурсов компьютера или сервера
- Функциональность и удобство использования , наш продукт ориентирован на пользователя
- Для каждой задачи выбирается лучший инструмент или алгоритм , ранее прошедшее тщательное тестирование
Для дальнейшего знакомства с A-Parser ‘рекомендуется полноценно оценить его преимущества,
ознакомится с отзывами пользователей,
выбрать другую версию
и перейти к оплате лицензии
.
Добавить комментарий