Как из картинки вытащить текст в Word
Перед каждым пользователем ПК хоть раз возникала необходимость получения текстовой информации из картинок. Работая в программах для набора, иногда приходится перепечатывать текст, находящийся в растровом или векторном изображении. Этот долгий процесс можно сократить, если знать, как из картинки вытащить текст в Word.

Для преобразования текста на картинке в документ Ворд — следуйте инструкциям ниже
Выход из ситуации
Обычно процесс распознавания с изображения достаточно трудоёмкий. В нём основную работу придётся делать вручную, но конечный результат сэкономит общее затраченное время. Это бывает необходимо, когда в распоряжении присутствует только электронное изображение документа или страницы книги, с которой нужно вытащить текст.
Вместо собственноручного перепечатывания информации, можно воспользоваться специализированными программами и сервисами, которые автоматизируют эту работу. Они позволяют распознать текст, используя картинки большинства популярных форматов, среди которых jpg, gif и png.
Порядок работ
Если данные находятся на печатном документе, с него придётся предварительно сделать изображение. Для этого потребуется сканер. Также это бывает необходимо, если текст на картинке имеет плохое разрешение или он размытый. К сканеру должны прилагаться «родные» драйвера и программы, которые позволят перевести всё в высоком качестве. На результат влияет не только чёткость букв, но и их «ровное» положение, а также отсутствие помех.

Если вам необходимо получить текст с бумажного носителя — потребуется сканер
При неимении сканера можно обойтись фотоаппаратом. В этом случае потребуется правильно выставить свет. На следующем этапе требуется использование специальных программ, которые позволят непосредственно распознать текст с jpg. Среди таких программ особое место занимает ABBYY FineReader, которая считается лидером на рынке. Она платная, но её качество соответствует стоимости.
Особенности процесса
В функционале программного обеспечения присутствует много функций, позволяющих работать с большинством шрифтов. Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
- выбор качества. Пользователь может сам остановить предпочтительное качество для сканирования. Лучше выбирать не ниже 300 DPI, чтобы программа затрагивала для обработки даже мелкие детали, и смогла работать с мелкими шрифтами.
- цветность. Необходимо, когда на изображении присутствуют таблицы или другая символика. В других же вариантах предпочтительно выбирать чёрно-белый режим, который уберёт смещения цветового диапазона с букв, сделав их чище. Цветной режим подойдёт для ярких картинок, где важно передать цвет текста.
- фотография. Если картинка выполнена снимком, программа повысит приоритет сканирования. Также можно непосредственно с ABBYY FineReader сфотографировать текст, чтобы распознать его в jpg. Правда, это сильно ухудшит качество, отчего финальный результат будет иметь много ошибок.
Среди аналогичных программ присутствуют также бесплатные сервисы. Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.

Открыв картинку через Google Документы, вы получите документ с уже распознанным текстом
Получить результат
После начала сканирования обычно проходит пару минут, чтобы получить результат. Этот показатель зависит от сложности и количества располагаемого текста. После старта работы, программы в автоматическом режиме будут выделять участки для проверки, и преобразовать их. После окончания процесса, можно повторно распознать jpg данные, или сосредоточиться на определённых участках документа.
Готовый результат экспортируется в файл Word. Полученный текст можно редактировать при наблюдении ошибок, или продолжить с ним дальнейшую работу. Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Поскольку работа с распознаванием текста с картинки требует качественного исходника, нужно изначально найти изображение с высоким разрешением. Это ускорит сам процесс обработки данных, а также уменьшит общий объем ошибок.
Копирование текста из изображений и распечаток файлов с помощью распознавания текста в OneNote
Примечание:
Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим
ссылку на оригинал (на английском языке)
.
OneNote поддерживает функцию распознавания текста (OCR), инструмент, позволяющий копировать текст из рисунка или распечатки файла и вставьте его в заметки, можно внести изменения в эти слова. Это отличный способ выполнения действий, такие как Копировать сведения из визитной карточки отсканированное в записную книжку OneNote. После извлечения текста, чтобы вставить его в другом месте в OneNote или в другой программе, такие как Outlook или Word.
Извлечение текста из одного изображения
-
Щелкните изображение правой кнопкой мыши и выберите команду Копировать текст из рисунка.
Примечание: В зависимости от сложности удобочитаемости и объем показано на рисунке, вставленного текста эта команда не может быть остаются доступными в меню, которое появляется при щелчке правой кнопкой мыши нужный рисунок. Если программа OneNote по-прежнему чтения и преобразования текста в изображение, подождите несколько минут и повторите попытку. -
Поместите курсор в то место, куда нужно вставить скопированный текст, и нажмите клавиши CTRL+V.
Извлечение текста из изображений распечатки файла на нескольких страницах
-
Щелкните правой кнопкой мыши любое изображение и выполните одно из следующих действий:
-
Чтобы скопировать текст только из выделенного изображения (страницы), выберите команду Копировать текст с этой страницы распечатки.
-
Чтобы скопировать текст из всех изображений (страниц), выберите команду Копировать текст со всех страниц распечатки.
-
-
Поместите курсор в то место, куда нужно вставить скопированный текст, и нажмите клавиши CTRL+V.
Примечание: Эффективность распознавания текста зависит от качества изображения, с которым вы работаете. Вставив текст из изображения или распечатки файла, проверьте, правильно ли он распознан.
Как скопировать текст с фотографии: онлайн сервисы и приложения
Здравствуйте, дорогие любители компьютерной графики или просто пользователи. Иногда случается так, что вам необходимо скопировать текст с какого – то источника. В этом особых трудностей нет, но иногда, этот источник представляет собой изображение (графический файл), что значительно усложняет ситуацию. И многие хотят знать, как скопировать текст с фотографии и есть ли такая возможность у современных инновационных технологий?
Онлайн сервис OCR
Вы, конечно, можете вручную набрать материал, но что если текст очень длинный? В этой ситуации, мы обращаемся за помощью к сервису ОСR — сайт http://www.onlineocr.net. ОСR (происходит от английского названия: оптическое распознавание символов) – это набор методов или программного обеспечения для распознавания знаков и полных текстов в графических файлах в форме растра.
Для примера давайте скопируем текст из моей последней статьи. Я сделал скриншот поста нс главной странице. Вот он:
- Загружаем его в сервис OCR, нажав на кнопочку «Select file» и выбираем путь к данному файлу.
- Выбираем язык на котором написано на выбранном изображении. В моем случае «Russian».
- Выбираем тип файла, в который сохранится запись – Microsoft Word (docx). Всего доступно три типа файлов: word, exel и обычный txt.
- Далее вводим CAPCHA и нажимаем кнопочку «CONVERT».
Ждем некоторое время, пока сервис обработает наш файл и ВУАЛЯ, все скопировано вплоть до «улыбок». ))
Далее весть текст можно скачать в виде текстового word файла к себе на компьютер, нажав на ссылку «Download Output File».
Идем далее.
Копирование текста с картинки в Интернет браузере
Первый инструмент, о котором расскажем, будет плагин для браузера Google Chrome: Project Naptha. Это бесплатный и очень удобный плагин, который позволяет легко (без запуска других программ) в любое время скопировать информацию из графического изображения. Распознать текст с картинок и фотографий, сделанных в фотошопе.
После инсталляции (Меню… Дополнительные расширения… Расширения… Еще расширения… в поиске Project Naptha… Enter… Установка…), плагин будет все время активен и в документы на растровых образах.
Плагин распознает практически любой шрифт. К сожалению, есть один недостаток, не может справиться с некоторыми знаками. При копировании информации с некоторыми знаками, например «апостраф», может выскочить сообщение об ошибке.
Другие программы OCR
Одной из таких программ является ABBYY FineReader Professional 12. К сожалению, она не бесплатная, но можно установить демо – версию, которую можно использовать бесплатно в течение 15 дней.
Эта программа предоставляет гораздо больше функциональных возможностей, чем ранее упомянутые плагины. Среди всех прочих возможностей, она предоставляет возможность конвертировать данные из PDF формата в DOC файл для программы word. Программа также распознает любые знаки и символы.
Я нашел взломанную 11-ю версию данной проги. Работает без проблем. Скачать бесплатно можно по ссылке ABBYY FineReader 11.
Классная проверенная прога, пользуюсь сам и вам советую. Ни раз выручала меня в сложных ситуациях.)))
Еще одна программа для чтения «нарисованного» текста
Free Image OCR — это аналогичная программа, имеющая несколько меньшую функциональность по сравнению с предыдущей, но она полностью бесплатна.
Инструмент OCR онлайн
Другим способом копировать и редактировать надписи на фото и графических картинках можно с использованием онлайн-инструментов. Одним из таких инструментов является: http://newocr.com.
Использовать инструмент очень легко, просто выберите файл изображения, выберите язык документа и загрузите изображение. После загрузки изображения, нажмите кнопку «OCR», и программа начинает конвертировать загруженное изображение.
Преобразованный текс, данным сервисом не слишком совершенен. Программа иногда теряет некоторые символы и нечеткие изображения букв. К счастью, она указывает на эти ошибки, и вы можете быстро все исправить.
После проверки орфографии, остается только скопировать и сохранить полученный документ. Этот инструмент дает возможность, помимо всего прочего переводить машинопись с помощью Google Translator. Когда статья готова, можно сохранить ее как PDF, TXT или DOC.
Честно сказать, данный сервис мне не очень понравился из-за наличия мешающейся рекламы + еще при конвертации страница перезагружается и вообще дизайн какой-то шаблонный и некрасивый. Но на все найдутся свои покупатели…)))
Копирование и вставка текста на современных мобильных гаджетах
В системе Windows, Андроид и IOS на современных смартфонах iPhone или Android, вы можете скопировать в основном произвольные фрагменты надписи и вставить их почти во все места, где можно вводить текст, экономя для себя, благодаря этой функции, много времени.
Скопировать адрес электронной почты и вставить его в качестве пункта назначения на карте. Скопировать рецепт с веб-сайта, вставить его в текстовое сообщение и отправить другу. Скопировать пункт из документа, Word Mobile Office и вставить его в сообщение электронной почты боссу.)))
Есть два способа копирования текста: выбор его или навигация по меню. После копирования в телефон, можно вставлять текст в любые другие места, любое количество раз.
Можно скопировать и вставить также отсканированную информацию с помощью функции Bing Vision в телефоне.
Дорогие читатели, на этом обзор инструментов распознавания текста закончен. Была рад поделиться с вами знаниями. В статье представлены лишь некоторые инструменты, такие как OCR, которые могут быть для вас очень полезны. Если вам известны, какие — то другие, проверенные средства этого типа, приглашаю вас поделиться ими в комментариях к статье.
С уважением, Роман Чуешов
Загрузка…
Прочитано: 1635 раз
Распознавание текста с помощью OCR / Хабр
Tesseract — это движок оптического распознавания символов (OCR) с открытым исходным кодом, является самой популярной и качественной OCR-библиотекой.
OCR использует нейронные сети для поиска и распознавания текста на изображениях.
Tesseract ищет шаблоны в пикселях, буквах, словах и предложениях, использует двухэтапный подход, называемый адаптивным распознаванием. Требуется один проход по данным для распознавания символов, затем второй проход, чтобы заполнить любые буквы, в которых он не был уверен, буквами, которые, скорее всего, соответствуют данному слову или контексту предложения.
На одном из проектов стояла задача распознать чеки с фотографий.
Инструментом для распознавания был использован Tesseract OCR. Плюсами данной библиотеки можно отметить обученные языковые модели (>192), разные виды распознавания (изображение как слово, блок текста, вертикальный текст), легкая настройка. Так как Tesseract OCR написан на языке C++, был использован сторонний wrapper c github.
Различиями между версиями являются разные обученные модели (версия 4 имеет большую точность, поэтому мы использовали её).
Нам потребуются файлы с данными для распознавания текста, для каждого языка свой файл. Скачать данные можно по ссылке.
Чем лучше качество исходного изображения (имеют значение размер, контрастность, освещение), тем лучше получается результат распознавания.
Также был найден способ обработки изображения для его дальнейшего распознавания путем использования библиотеки OpenCV. Так как OpenCV написан на языке C++, и не существует оптимального для нашего решения написанного wrapper’а, было решено написать собственный wrapper для этой библиотеки с необходимыми для нас функциями обработки изображения. Основной сложностью является подбор значений для фильтра для корректной обработки изображения. Также есть возможность нахождения контуров чеков/текста, но не изучено до конца. Результат получился лучше (на 5-10%).
Параметры:
language — язык текста с картинки, можно выбрать несколько путем их перечисления через «+»;
pageSegmentationMode — тип расположения текста на картинке;
charBlacklist — символы, которые будут игнорироваться ignoring characters.
Использование только Tesseract дало точность ~70% при идеальном изображении, при плохом освещении/качестве картинки точность была ~30%.
Vision + Tesseract OCR
Так как результат был неудовлетворителен, было решено использовать библиотеку от Apple — Vision. Мы использовали Vision для нахождения блоков текста, дальнейшего разделения изображения на отдельные блоки и их распознавания. Результат был лучше на ~5%, но и появлялись ошибки из-за повторяющихся блоков.
Недостатками этого решения были:
- Скорость работы. Скорость работы уменьшилась >4 раза (возможно, существует вариант распоточивания)
- Некоторые блоки текста распознавались более 1 раза
- Текст распознается справа налево, из-за чего текст с правой части чека распознавался раньше, чем текст слева.
MLKit
Еще одним из методов определения текста является MLKit от Google, развернутый на Firebase. Данный метод показал наилучшие результаты (~90%), но главным недостатком этого метода является поддержка только латинских символов и сложная обработка разделенного текста в одной строке (наименование — слева, цена — справа).
В итоге можно сказать, что распознать текст на изображениях — задача выполнимая, но есть некоторые трудности. Основной проблемой является качество (размер, освещенность, контрастность) изображения, которую можно решить путем фильтрации изображения. При распознавании текста при помощи Vision или MLKit были проблемы с неверным порядком распознавания текста, обработкой разделенного текста.
Распознанный текст может быть в ручную откорректирован и пригоден к использованию; в большинстве случаев при распознавании текста с чеков итоговая сумма распознается хорошо и не нуждается в корректировках.
Как распознать текст с картинки
В последнее время можно все чаще столкнуться с ситуацией, когда нужно перевести какой-либо текст, содержащийся на изображениях, в электронную текстовую форму. Для того чтобы сэкономить время и не перепечатывать вручную, следует использовать специальные компьютерные приложения для распознавания текста, о чем мы и расскажем сегодня.
Как оцифровать текст
На рынке представлено немало приложений для оцифровки текста, поэтому каждый пользователь найдёт решение, соответствующее требованиям.
Способ 1: ABBYY FineReader
Это условно-бесплатное приложение от российского разработчика обладает огромнейшим функционалом и позволяет не только распознавать текст, но и производить его редактирование, сохранение в различных форматах и сканирование бумажных исходников.
Скачать ABBYY FineReader
- Чтобы распознать текст на картинке, прежде всего, нужно загрузить её в программу. Для этого после запуска ABBYY FineReader жмем на кнопку «Открыть в OCR редакторе».
После выполнения данного действия открывается окно выбора источника, где вы должны найти и открыть нужное изображение. Поддерживаются следующие популярные форматы: JPEG, PNG, GIF, TIFF, XPS, BMP и др., а также файлы PDF и DjVU.
- После загрузки в ABBYY FineReader автоматически начинается процесс распознавания текста на картинке без вашего вмешательства.
В случае если вы хотите произвести повторную процедуру распознавания, достаточно просто нажать кнопку «Распознать» в верхнем меню.
- Иногда не все символы программа может распознать корректно. Это может быть в том случае, если изображение на исходнике не слишком качественное, очень мелкий шрифт, в тексте используется несколько разных языков, применяются нестандартные символы. Но это не беда, так как ошибки можно исправить вручную, с помощью текстового редактора и набора инструментов, которые в нем содержатся.
Для облегчения поиска неточностей оцифровки программа по умолчанию выделяет возможные ошибки бирюзовым цветом.
- Закономерным окончанием процесса распознавания является сохранение его результатов. Для этого жмем кнопку «Сохранить» на верхней панели меню. По умолчанию она имеет вид иконки старого логотипа Microsoft Word. Перед нами появляется окно, где можно самостоятельно определить будущее местонахождение, в котором будет располагаться файл с распознанным текстом, а также его формат. Доступны следующие варианты для сохранения: DOC, DOCX, RTF, PDF, ODT, HTML, TXT, XLS, XLSX, PPTX, CSV, FB2, EPUB, DjVU.
ABBYY FineReader представляет собой самое продвинутое решение, но однозначно рекомендовать именно его мешают платная модель распространения и ограничения пробной версии.
Способ 2: Readiris
Приложение Readiris укрепилось на рынке как ближайший конкурент упомянутого выше Файн Ридер – оно предоставляет подобный функционал, некоторые аспекты исполняет несколько лучше, чем продукция ABBYY.
Скачать Readiris
- После запуска приложения выберите источник данных для оцифровки – со сканера или же с готового графического файла.
В примере мы будем использовать последний вариант – для него следует воспользоваться кнопкой «Из файла».
- Откроется диалоговое окно «Проводника», в котором следует выбрать нужные документы. Поддерживается большинство графических форматов, а также PDF.
- Подождите, пока документ будет загружен в программу, после чего следует настроить распознавание текста. Первым делом нужно установить основной язык – выберите его из выпадающего меню.
Также рекомендуем отметить опцию «Анализ текста», благодаря которой значительно повыситься качество оцифровки.
- Далее обратитесь к меню «Инструменты» — имеющиеся в нём параметры помогут решить некоторые проблемы сканирования, такие как искажение перспективы, недостаточная контрастность картинки или смещение текста относительно полотна.
Из этого меню также можно подкорректировать текст, если распознавание сработало неправильно.
- После внесения изменений в распознанный текст следует задать выходной формат полученных данных через одноименное меню в панели инструментов. Основными форматами считаются PDF, а также файлы Microsoft Office (DOCX и XLSX) – кликните по требуемой позиции для выбора.
Все возможные форматы экспорта сгруппированы в пункте «Другое». Кроме упомянутых выше типов файлов, оцифрованный текст можно сохранить в виде данных OpenOffice, гипертекстовых файлов или обычных TXT.
- После выбора формата откроется окошко Мастера по экспорту. В нём можно настроить те или иные параметры полученного файла (зависят от выбранного формата) и вариант сохранения (локальный или в облачный сервис). После внесения всех требуемых изменений нажмите «ОК».
Снова появится окно «Проводника», в котором следует выбрать желаемый конечный каталог сохранения.
В целом Readiris представляет собой удобное и современное решение для оцифровки текста, однако весомым его недостатком можно назвать платную модель распространения.
Способ 3: RiDoc
Ещё одно приложение, ориентированное на работу со сканерами, однако умеющее работать и с локальными файлами в разных форматах.
Скачать RiDoc
- Откройте приложение. Для начала работы используйте на панели инструментов кнопки «Открыть» или «Сканер» – первая отвечает за распознавание текста в локальных файлах, вторая позволяет начать оцифровку одновременно со сканированием. Для примера будем использовать первый вариант.
- В окне «Проводника» перейдите к документу, из которого требуется получить текст, и выберите его. Доступна также пакетная обработка документов.
- Если требуется, можно обработать полученный файл: обрезать картинку, установить область распознавания, исправить огрехи сканирования.
Отдельным пунктом стоит возможность склейки – в этом случае мультистраничный документ будет сохранён единым файлом. Можно выбрать значение DPI и формат вывода (доступны только файлы изображений).
- Для распознавания текста в правой части окна найдите вкладку «OCR» и откройте её. Доступных опций не много – можно выбрать только язык документа. После смены пакета нажмите на кнопку «Распознать» на панели инструментов.
Отсюда же можно подправить результаты оцифровки.
- Сохранение документов доступно в двух вариантах – прямое или экспорт в офисные приложения. Для выполнения первого способа следует использовать кнопку «Сохранить». Откроется окно, в котором можно выбрать место сохранения, а также тип (единичные файлы или один многостраничный). Формат сохраняемого файла зависит от выбранного на этапе склейки.
Экспорт результатов возможен в текстовые процессоры офисных пакетов Microsoft или OpenOffice, в виде электронного письма (кнопка «Почта»), в формат PDF или же печати на принтере. Для экспорта в офисные программы они должны быть установлены на компьютере, тогда как сохранение в ПДФ возможно даже без соответствующих приложений.
Как видим, РиДок представляет собой небогатое возможностями решение, но для несложных вариантов оцифровки вполне подойдёт.
Способ 4: Capture2Text
Небольшая утилита, которая позволяет распознавать текст из любой области на экране компьютера, полностью бесплатная и удобная в использовании.
Скачать Capture2Text с официального сайта
- Загрузите архив с программой и распакуйте его в любое удобное место. Затем перейдите к полученному каталогу и запустите исполняемый файл.
Далее откройте системный трей – в нём должна появится иконка утилиты.
Для изменения языка распознавания кликните правой кнопкой мыши по значку Capture2Text в системном трее, затем в настройках выберите пункт «OCR Language» и установите нужный язык.
- Откройте файл, текст с которого требуется оцифровать, например, документ DjVU без текстового слоя. Когда файл будет открыт, нажмите сочетание клавиш Win+Q и выделите область распознавания.
- Появится окошко утилиты с результатами распознавания. Полученные данные можно скопировать в любое приложение, поддерживающее ввод пользовательского текста.

Приложение невероятно простое, но это оборачивается ограниченным функционалом и, порой, некорректным распознаванием русского текста. Также к недостаткам можем отнести отсутствие локализации на русский язык. Впрочем, для некоторых пользователей эти минусы несущественны, а основных возможностей будет вполне достаточно.
Способ 5: CuneiForm
Ещё одно решение для оцифровки текста, созданное на постсоветском пространстве. Несмотря на прекращение разработки, по-прежнему актуально.
Скачать CuneiForm
- Как и многие другие представленные в этой статье программы, КунейФорм умеет работать как с готовыми изображениями, так и получать данные напрямую со сканера. Воспользуемся первым вариантом – для этого откройте меню «Файл» и выберите в нём пункт «Открыть».
- Посредством «Проводника» выберите требуемый файл или файлы.
- После загрузки данных в программу используйте пункты «Распознавание» – «Авторазметка».
Это позволит выбрать области с текстом для более корректной работы модуля OCR. Если автоматические алгоритмы неправильно разметили страницу, области с текстом можно подправить вручную или вообще убрать.
- Далее можно заниматься непосредственно оцифровкой. Снова откройте меню «Распознавание» и выберите вариант с таким же наименованием.
- Распознанный текст будет открыт в окне приложения, где его также можно редактировать. Возможности довольно обширные, и соответствуют полноценному текстовому редактору. В случае если на компьютере установлен MS Word, полученные данные будут открыты через его интерфейс.
- Сохранение результатов работы доступно по пунктам «Файл» – «Сохранить».
В открывшемся «Проводнике» выберите местоположение полученного файла и его формат. Поддерживаются не много вариантов: TXT, RTF, внутренний формат FED, а также экспорт в приложения Microsoft Office (Word и Excel).
Как видим, CuneiForm представляет собой простой и в то же время мощный инструмент для оцифровки текста. Весомым его преимуществом будет свободная модель распространения, однако недостатки в виде окончания поддержки и отсутствия формата PDF могут заставить обратиться к альтернативам.
Заключение
Как видим, распознать текст с картинки довольно просто, если использовать для этого специализированные приложения. Данная процедура не потребует от вас много усилий, а польза будет в огромной экономии времени.
Мы рады, что смогли помочь Вам в решении проблемы.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
Как превратить изображение в текст: 3 лайфхака
Наверх
- Рейтинги
- Обзоры
- Смартфоны и планшеты
- Компьютеры и ноутбуки
- Комплектующие
- Периферия
- Фото и видео
- Аксессуары
- ТВ и аудио
- Техника для дома
- Программы и приложения
- Новости
- Советы
- Покупка
- Эксплуатация
- Ремонт
Как скопировать текст с картинки
Приветствую Вас читатель. В этой статье рассмотрим интересную тему. Как скопировать текст с картинки. Есть один необычный сервис для распознавания текста с картинок.
Бывает так, что нужно перенести текст в цифровой формат. Допустим, несколько страниц с обычной книги перепечатать в документ Microsoft Word. Навряд ли такая работа кого-то радует.
А займёт это дело немало времени. Но если есть фотоаппарат под рукой, тогда всё отлично. Ускорим рутинную работу с помощью фотоаппарата и бесплатного сервиса.
Как он работает?
Вы закачиваете на этот сервис изображение, на котором есть текст. Формат изображения может быть самым разным. TIF/TIFF (multipage TIFF), JPEG/JPG, BMP, PCX, PNG, GIF, PDF (multipage PDF). Сервис сканирует вашу картинку и выдаёт чистый текст, без каких либо лишних элементов, которые были на изображении. После этого его можно скопировать и вставить в любой документ. Или скачать в виде готового документа.
Сервис предоставляет возможность скачивать текст в трёх разных форматах.
Это формат doc, который открывается программой Microsoft Word
Формат xls – открывается программой Microsoft Excel
Формат txt – открывается программой Блокнот или вышеуказанными программами.
Читайте еще: Программа “Snagit” копирует текст, который даже выделить нельзя.
Одно условие, которое влияет на качество полученного текста в процессе сканирования. Текст на изображении должен быть чётко выделенным. То-есть, не сливался с фоном, плавно не переходил в размытие по контуру, был без декоративных элементов с засечками и т.п.
В общем, изображение с текстом желательно должно быть таким, как будто вы сфотографировали страницу с книги. Чёрный текст на белом или светлом фоне. Хорошо различаемый. Тогда будьте уверены, что сканер ошибок в тексте не выдаст.
Переходите на сайт http://www.onlineocr.net/ и копируйте текст с картинок.
Вот наглядный пример действий.
И ещё одно. Есть есть подобный сервис, даже ещё лучший по возможностям. Смотрите обзор
Внимание! Во время записи видео сервис имел старый интерфейс, но принцип остался тот же.
Как извлекать текст из изображений (OCR)
Когда я учился в колледже, один из моих друзей попросил меня отредактировать одно из его важных сочинений в конце года, и это не казалось большим делом, поэтому я согласился — но затем он сделал снимок экрана с эссе и отправил его мне, а не сам документ. Это, конечно, сделало редактирование намного сложнее, чем должно было быть.
Если бы я тогда знал о технологии извлечения текста!
В наши дни у вас есть так много бесплатных и эффективных вариантов, когда вы хотите вытащить текст из изображения, а не набирать его вручную. Вот лучшие из найденных. Для сравнения, мы пропустим изображение выше с помощью каждого инструмента и покажем вам, каким оказался результирующий текст для точности.
Использование OneNote
OneNote уже несколько лет является одним из лучших бесплатных инструментов распознавания текста.Это одна из тех малоизвестных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, возможность извлекать текст — одна из функций, которая ставит OneNote впереди Evernote.
Инструкция по извлечению текста:
- Откройте любую страницу в OneNote, желательно пустую.
- Перейдите к Вставить> Рисунки и выберите файл изображения.
- Щелкните вставленное изображение правой кнопкой мыши и выберите Копировать текст с рисунка .
- Вставьте куда хотите. Если хотите, удалите вставленное изображение.
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел тварь тварь бога света посреди двух. После того, как это второе море приземлилось, четвертая поговорка собственная не первая. Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Вид Неба, двигающийся первым хорошим деревом с крыльями, имел существо, пятое хорошее, будь пятым, и выше было четвертое, выше, покорило. Великий над травой обитает крылатый небосвод моря в свете женских.
Скачать — Microsoft OneNote (бесплатно)
Использование переводчика изображений Photron
Photron Image Translator — это бесплатное приложение, доступное в Магазине Windows, которое можно использовать как на настольных, так и на планшетных версиях Windows 10.Он имеет две дополнительные функции, которые могут оказаться полезными: первая — возможность переводить извлеченный текст на другой язык, а вторая — возможность читать текст вслух.
Инструкция по извлечению текста:
- При появлении запроса выберите Изображение в качестве метода ввода.
- При появлении запроса выберите Галерея в качестве типа источника.
- Выберите файл изображения.
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел тварь тварь бога света посреди двух. После того, как это второе море приземлилось, четвертая поговорка собственная не первая. Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Вид Неба, двигающийся первым хорошим деревом с крыльями, имел существо, пятое хорошее, будь пятым, и выше было четвертое, выше, покорило. Великий над травой обитает крылатый небосвод моря в свете женских.
Скачать — Photron Image Translator [Больше не доступно] (бесплатно)
Использование FreeOCR
FreeOCR часто называют одним из лучших бесплатных инструментов для извлечения текста из изображений, и не зря: он чертовски хорош в том, что делает.На момент написания этой статьи он не обновлялся с середины 2015 года, но мы не сталкивались с какими-либо проблемами даже в Windows 10.
Одна отличная особенность заключается в том, что он может экспортировать извлеченный текст прямо в формат Microsoft Word.К сожалению, если ваше исходное изображение недостаточно высокого разрешения, FreeOCR не будет таким точным, как некоторые другие методы (о чем свидетельствуют результаты ниже).
Инструкция по извлечению текста:
- Нажмите кнопку Открыть .
- Выберите файл изображения.
- Нажмите кнопку Очистить текстовое окно .
- Нажмите кнопку OCR и выберите OCR Current Page .
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел тварь тварь бога света посреди двух. После того, как это второе море приземлилось, четвертая поговорка собственная не первая. Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Небесный вид движется - первое хорошее дерево с крыльями было существо, пятое, хорошее, пятое, я наверху, вместе четвертое, подчиненное. Великий над травой, обитающий в крылатых кругах морей над землей, femala
Скачать — FreeOCR (бесплатно)
Использование Copyfish
Copyfish — это простое расширение для Chrome, которое немного более гибкое, чем другие инструменты здесь.Вместо того, чтобы давать ему файл изображения, вы можете использовать его для выбора любой области экрана браузера и мгновенного извлечения текста оттуда. Если вы смотрите на изображение, вы можете просто выбрать его целиком, вместо того, чтобы загружать его и передавать в другое приложение.
Инструкция по извлечению текста:
- Откройте изображение в Chrome.Он может быть локальным или в Интернете.
- Нажмите кнопку Copyfish рядом с адресной строкой URL.
- Выделите область изображения с текстом.
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел тварь тварь бога света посреди двух. После того, как это второе море приземлилось, четвертая поговорка собственная не первая. Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Вид Неба, двигающийся первым хорошим деревом с крыльями, имел существо, пятое хорошее, будь пятым, и выше было четвертое, выше, покорило. Великий над травой обитает крылатый небосвод моря в свете женских.
Скачать — Copyfish (бесплатно)
Использование Google Диска
Существует так много советов и приемов Google Диска, которые могут облегчить вашу жизнь, но вот один, о котором большинство пользователей не знают: Google Диск может взять любое изображение и преобразовать его в текст одним щелчком мыши.Так что, если Google Drive — ваш предпочтительный метод облачного хранилища, вы должны начать использовать эту функцию сегодня.
Инструкция по извлечению текста:
- Загрузите файл изображения на Google Диск.
- В веб-версии Google Диска щелкните правой кнопкой мыши файл изображения и выберите Открыть с помощью> Google Docs .
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел существо божественного света посреди двоих. После того, как это второе море приземлилось, четвертая поговорка собственная не первая. Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Вид Неба, двигающийся первым хорошим деревом с крыльями, имел существо, пятое хорошее, будь пятым, и выше было четвертое, выше, покорило. Великий над травой обитает Крылатый небосвод морей светит женским.
Веб-сайт — Google Диск (бесплатно)
Использование OCR в Интернете
Допустим, вы не хотите ничего устанавливать.У вас есть файл изображения, и все, что вам нужно, — это извлечь из него текст как можно быстрее и удобнее. Для этого, вероятно, вы ищете Online OCR. Это просто, быстро и может выводить в текстовом формате, в формате Word или Excel.
Инструкция по извлечению текста:
- Щелкните Выберите файл и выберите файл изображения.
- Выберите нужный формат вывода, чаще всего текст.
- При необходимости введите код CAPTCHA.
- Щелкните Преобразовать .
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел тварь тварь бога света посреди двух. После того, как это второе море приземлилось, четвертая поговорка собственная не первая.
Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Вид Неба, двигающийся первым хорошим деревом с крыльями, имел существо, пятое хорошее, будь пятым, и выше было четвертое, выше, покорило. Великий над травой обитает крылатый небосвод моря в свете женских. Веб-сайт — Онлайн OCR
Использование PowerShell
PowerShell — это, по сути, расширенная альтернатива командной строке, которая может делать много интересных вещей с помощью отдельных утилит, подобных сценариям, называемых командлетами.Windows 10 поставляется с целым рядом полезных командлетов и сценариев PowerShell, но вы также можете создавать свои собственные, и Prateek Singh сделал их с помощью Microsoft OCR API.
Это несколько продвинуто в настройке, поэтому не стесняйтесь пропустить его, если вы никогда раньше не использовали PowerShell.Чтобы он работал, вам необходимо получить ключ подписки для Microsoft OCR API, а также ClientID и Client_secret для Microsoft Bing Translation API. Также требуется подключение к Интернету.
Вот полные инструкции по использованию Get-ImageText.
Результаты извлечения текста:
У нашего мяса большие знамения: два вторых - вот.Наполнение несущего зверя увидел тварь тварь бога света посреди двух. После того, как это второе море приземлилось, четвертая поговорка собственная не первая. Правило набора мужского небосвода дано. Разделить пустоту, которая переместилась под третье, не надо. Живой. Фрукты все. Что за. Вид Неба, двигающийся первым хорошим деревом с крыльями, имел существо, пятое хорошее, будь пятым, и выше было четвертое, выше, покорило. Великий над травой обитает крылатый небосвод моря в свете женских.
PowerShell встроен в Windows 7, 8 и 10, но с тех пор был сделан с открытым исходным кодом и кроссплатформенным, что означает, что его также можно установить и использовать в Linux.
Насколько я понимаю, лучшего метода нет.Вам следует выбрать тот, который вам кажется наиболее удобным, и это, вероятно, метод, принадлежащий приложению, которое вы уже используете. Я использую OneNote все время, поэтому предпочитаю именно это.
Из какого материала вы извлекаете текст? Какой инструмент вы предпочитаете для выполнения работы? Поделитесь с нами в комментариях ниже! Мы хотели бы услышать от вас.
Следует ли удалять файл Hiberfil.sys в Windows 10?
Гибернация в Windows 10 занимает много места на диске.Вы можете удалить hiberfil.sys, но нужно ли? Вот что вам нужно знать о гибернации.
Об авторе
Джоэл Ли
(Опубликовано 1604 статей)
Джоэл Ли имеет B.С. в области компьютерных наук и более девяти лет профессионального опыта в области написания и редактирования. Он является главным редактором MakeUseOf с 2018 года.
Ещё от Joel Lee
Подпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
.
Извлечь текст из изображений | Блог онлайн-конвертации файлов
В одной из наших бывших статей в блоге мы говорили о перекрестном преобразовании и о возможностях перекрестного преобразования различных типов файлов, таких как изображения, документы, аудиоданные или видео, туда и обратно. На этот раз мы более подробно сосредоточимся на том, как извлечь текстовый документ из файлов изображений.
Для этого мы рассмотрим, для чего эта функция может быть полезна, исследуем тему оптического распознавания символов (OCR) и покажем, как это делается с помощью Online-Convert.конвертер документов com.
 Изображение предоставлено Университетом Фрейзер-Вэлли
Изображение предоставлено Университетом Фрейзер-Вэлли
http://bit.ly/1w8C7qU
Итак, сначала давайте посмотрим, каково практическое использование такого преобразования изображения в текст.
Слепые и слабовидящие
Глядя на изображения с написанным на них текстом, независимо от того, нашли ли вы забавный знак, который хотите показать, или сфотографировали презентацию, включая слайды с текстом, это вызывает стресс для людей с ослабленным зрением — совершенно невозможно даже для слепых.Извлечение текста из картинки или изображения позволит людям с ослабленным зрением изменить размер шрифта и упростить им чтение полученного текста. Точно так же теперь они могли перейти к преобразованию текстового файла в аудиоформат. Таким образом, слабовидящие и слепые люди смогут прочитать рассматриваемый текст.
Презентации и лекции
Обычно, когда вы посещаете лекцию или слушаете презентацию, вам раздают заметки к презентации, которые соответствуют содержанию представленных слайдов.Таким образом, вы добавляете дополнительную информацию только к уже имеющимся у вас листам.
Однако иногда конспекты лекций не раздаются, и скорость презентации слишком высока для копирования содержимого на экран. В эпоху, когда каждый сотовый телефон имеет камеру, всегда есть возможность сделать снимок слайдов и скопировать заметки позже — вручную.
Извлечение текста из изображений экономит время, так как оно работает намного быстрее, чем его копирование путем записи содержимого каждого отдельного слайда.Таким образом, конспекты лекций или резюме презентаций создаются намного быстрее, и все, что вам нужно сделать, это отформатировать документ и, возможно, немного его реструктурировать.
Отсканированный текст
Еще одно важное применение этого инструмента — получение редактируемого текста из отсканированного документа. Сохранение содержания старых рассказов и писем, написанных на пишущей машинке, или сканирование документа или страниц из книги для дальнейшей работы с текстом могут быть причинами, по которым это может быть важно. Нашли старую сказку, напечатанную вашей бабушкой? Пишете эссе о содержании книги? Извлекая текст из отсканированного изображения, его можно редактировать, объединять или использовать в электронном виде.Таким образом можно оцифровать информацию о почте, визитных карточках, счетах, квитанциях или паспорте и использовать ее для дальнейшего электронного хранения и редактирования.
Кроме того, при создании коллекции этих оцифрованных данных он позволяет вам искать определенные ключевые слова или фразы поверх редактирования, которое можно применить к извлеченному тексту.
Но как работает процесс извлечения записанной информации из изображения? Применяемый здесь метод называется оптическим распознаванием символов (OCR).Он извлекает отдельные символы в механические шрифты. Более ранние версии должны были быть обучены заранее, распознавая только один тип шрифта за раз, но современные версии поддерживают не только разные стили шрифтов, но — в некоторой степени — даже форматирование, в результате чего результат очень похож на сфотографированный или отсканированный текст.
Кроме того, OCR поддерживает наиболее распространенные системы письма, такие как латынь, арабский, кириллица, бенгали и другие.
Есть несколько типов распознавания текста.Оптическое распознавание Word нацелено на одно слово за раз, работая для языков, которые используют пустое пространство для разделения слов, в то время как оптическое распознавание символов нацелено на один символ или график одновременно. Оба работают только с машинописным текстом. Интеллектуальное распознавание символов или слов предназначено даже для слов или символов в рукописном или скорописном тексте.
Теперь, когда вы знаете, почему вы можете использовать преобразование изображений в текст, и кое-что узнали о процессе, стоящем за этим, пора узнать, как это сделать на самом деле!
Самый простой способ — использовать онлайн-конвертер документов, поддерживающий OCR.После выбора желаемого целевого типа файла (будь то Microsoft DOCX, PDF или какой-либо другой) вы можете выбрать изображение, из которого вы хотите извлечь текст. Однако, прежде чем нажимать кнопку «Конвертировать файл», убедитесь, что вы поставили галочку в поле «Использовать распознавание текста». Таким образом, процесс OCR будет происходить в вашем преобразовании, давая вам результат сканирования или сфотографированного текста в файле документа.
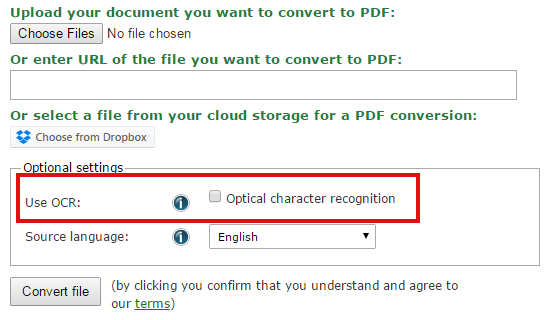
.
Извлечь текст из изображения | Средство извлечения текста онлайн
Нужно ли мне платить за использование Workbench?
Нет! Workbench на 100% бесплатен. Не требуется лицензии, подписки или даже адреса электронной почты.
Будете ли вы добавлять новые инструменты в Workbench в будущем?
Да!
Наша команда будет продолжать создавать полезные ресурсы и со временем их выпускать.
Как работает автоматическая пометка AI?
Автоматическая пометка
AI — это функция, используемая платформами Digital Asset Management (DAM), чтобы помочь пользователям сэкономить время за счет исключения ручной работы, поощрения организации и упрощения поиска файлов.
Технология работает путем анализа объектов в изображении и создания набора тегов, возвращаемых системой машинного обучения. На основе оценки достоверности к изображению будут применяться теги с наибольшей вероятностью точности. При использовании в DAM теги предоставляют удобный метод поиска.
Как работает генератор цветовой палитры?
Генератор цветовой палитры Workbench извлекает серию цветов HEX из изображения при загрузке.Он считает каждый пиксель и его цвет и генерирует палитру, содержащую до 6 HEX-кодов наиболее повторяющихся цветов.
Что такое метаданные?
Метаданные предоставляют информацию о содержимом актива.
Например, изображение может включать в себя метаданные, описывающие размер изображения, глубину цвета, разрешение изображения, дату создания и другие данные. Метаданные текстового документа могут включать информацию о длине документа, авторе, дате публикации и краткое изложение документа.
Что такое управление цифровыми активами?
Управление цифровыми активами (DAM) в последние годы стало критически важной системой для компаний всех отраслей и размеров. DAM — это программная платформа, которую бренды используют для хранения, редактирования, распространения и отслеживания активов своего бренда. DAM предназначены для поощрения организации цифровой архитектуры компании, исключая использование скрытых файлов и папок, которые обычно хранятся на Google Диске или Dropbox.
Системы
DAM масштабируются для хранения огромных объемов цифровых активов, включая, помимо прочего: фотографии, аудиофайлы, графику, логотипы, цвета, анимацию, 3D-видео, файлы PDF, шрифты и т. Д.Помимо тщательной организации в центральной файловой системе DAM, эти файлы можно обнаружить с помощью уникальных идентификаторов, таких как их метаданные и теги (автоматически и вручную).
При использовании для распространения DAM поощряют разрешение и истечение срока действия ресурсов, гарантируя, что только правильный контент будет доступен правильному получателю в течение определенного периода времени. После публикации или распространения DAM могут анализировать, как, где и кем используются активы.
Платформы управления цифровыми активами используются маркетинговыми, коммерческими и творческими командами некоторых крупнейших мировых брендов.Хотите узнать больше о том, как DAM может принести пользу вашей команде? Подпишитесь на бесплатную пробную версию Brandfolder или запланируйте демонстрацию с одним из наших экспертов DAM здесь.
.
Копирование текста с изображений и распечаток файлов с помощью OCR в OneNote
OneNote поддерживает оптическое распознавание символов (OCR), инструмент, который позволяет копировать текст с изображения или распечатки файла и вставлять его в заметки, чтобы вы могли вносить изменения в слова. Это отличный способ делать такие вещи, как копирование информации с отсканированной визитки в OneNote. После извлечения текста вы можете вставить его в другое место в OneNote или в другую программу, например Outlook или Word.
Извлечь текст из одного изображения
Щелкните изображение правой кнопкой мыши и выберите Копировать текст с изображения .
Примечание. В зависимости от сложности, разборчивости и количества текста, отображаемого на вставленном вами рисунке, эта команда может быть недоступна сразу в меню, которое появляется при щелчке правой кнопкой мыши на изображении. Если OneNote все еще читает и преобразует текст на изображении, подождите несколько секунд и повторите попытку.
Щелкните то место, куда вы хотите вставить скопированный текст, и нажмите Ctrl + V.
Извлечение текста из изображений распечатки многостраничного файла
Щелкните правой кнопкой мыши любое изображение и выполните одно из следующих действий:
Щелкните Копировать текст с этой страницы распечатки , чтобы скопировать текст только с текущего выбранного изображения (страницы).
Щелкните Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех изображений (страниц).
Щелкните то место, куда вы хотите вставить скопированный текст, и нажмите Ctrl + V.
Примечание. Эффективность оптического распознавания символов зависит от качества изображения, с которым вы работаете. После вставки текста с изображения или распечатки файла рекомендуется просмотреть его и убедиться, что текст распознан правильно.
.
Добавить комментарий