Rhasspy — опенсорсный и полностью офлайновый речевой тулкит. Распознавание русского языка. Никаких утечек в облако
Фото из сравнения микрофонных массивов для DIY-устройств типа самодельной умной колонки
Системы вроде Amazon Echo передают в облако для хранения ваши конфиденциальные разговоры (даже записанные случайно). В некоторых случаях записи прослушиваются живыми операторами. Это не просто потеря конфиденциальности. Это как добровольно впустить в свою квартиру «товарища майора», который стоит рядом 24 часа в сутки, слушает и внимательно записывает, притворяясь услужливым ассистентом.
Вместо покупки коммерческой системы у корпораций типа Google, Amazon или «Яндекс», вы можете собрать аналогичную опенсорсную систему на базе Raspberry Pi 2-3 B/B+, персонального компьютера или ноутбука.
Rhasspy — безопасный голосовой помощник, который работает автономно. Он ничего не передаёт на удалённые сервисы, при этом успешно справлятся с распознаванием речи и голосовых команд.
У Rhasspy очень простая интеграция в любую программную или аппаратную систему, куда вы хотите добавить голосовое управление. Автор поясняет, что инструмент изначально писался для проекта Home Assistant, но теперь совместим и с большинством других систем домашней автоматизации (Hass.io, Node-RED, OpenHAB, Jeedom).
Rhasspy оптимизирован для работы с внешними сервисами по MQTT, HTTP или Websockets. Оптимизирован именно для голосовых команд с чётко определённой грамматической структурой (включить/выключить свет, сделать музыку громче/тише и т. д.)
Поддерживается 14 языков, в том числе русский.
Модель работы описана в документации. В её основе — распознавание голосовых команд через специфический язык шаблонов, специально приспособленный для данной области. Эти команды классифицируются по намерению (intent) и могут содержать слоты или теги, такие как цвет для освещения или название конкретного светильника, которому подаётся команда.
Чтобы начать работу, перечислите намерения (в квадратных скобках) и возможные способы их вызова. Шаблон выглядит примерно так:
Шаблон выглядит примерно так:
[LightState]
states = (on | off)
turn (<states>){state} [the] lightПо такому шаблону Rhasspy сгенерирует JSON-код, который может использовать система домашней автоматизации, внешнее приложение или аппаратное устройство (через Node-RED, веб-сокеты):
{
"text": "turn on the light",
"intent": {
"name": "LightState"
},
"slots": {
"state": "on"
}
}Непосредственно распознавание речи выполняет pocketsphinx: легковесный опенсорсный движок с поддержкой русского языка. Он отлично подходит для мобильных устройств или одноплатных компьютеров типа Raspberry Pi.
Обработка звука происходит автономно на вашем устройстве. Сам звук может поступать с микрофонного массива Raspberry Pi (типа ReSpeaker 4 Mic Array или ReSpeaker 2 Mics pHAT) или из аудиопотока по сети.
Rhasspy — просто очень удобный инструмент, чтобы связать движок распознавания речи с системой автоматизации дома или какой-то другой системой, которая требует голосового управления. В принципе, его можно использовать где угодно: например, в мобильных приложениях. Или в каком-то домашнем роботе типа пылесоса или бармена.
В принципе, его можно использовать где угодно: например, в мобильных приложениях. Или в каком-то домашнем роботе типа пылесоса или бармена.
Приятно, когда робот выполняет все те же действия, что и раньше, но теперь по голосовой команде.
Автор Rhasspy также является автором проекта voice2json: это консольная программа примерно для той же задачи, чтобы легко преобразовать человеческую речь в список компьютерных команд (или наоборот).
Кажется, будущее за голосовыми интерфейсами. В этом случае очень важно, чтобы обработка звуковых потоков проходила локально и не требовала доступа в интернет.
Как легко и просто сделать транскрибацию аудио или видео в текст
Здравствуйте, друзья. Сегодня последняя статья из серии про профессию транскрибатор, в которой я расскажу, как новичку сделать транскрибацию максимально просто и быстро.
Показывать буду на примере одной из программ для транскрибации, о которых мы вчера разговаривали. Также приведу интересный способ, как можно делать расшифровку записей в текст с помощью распознавания речи.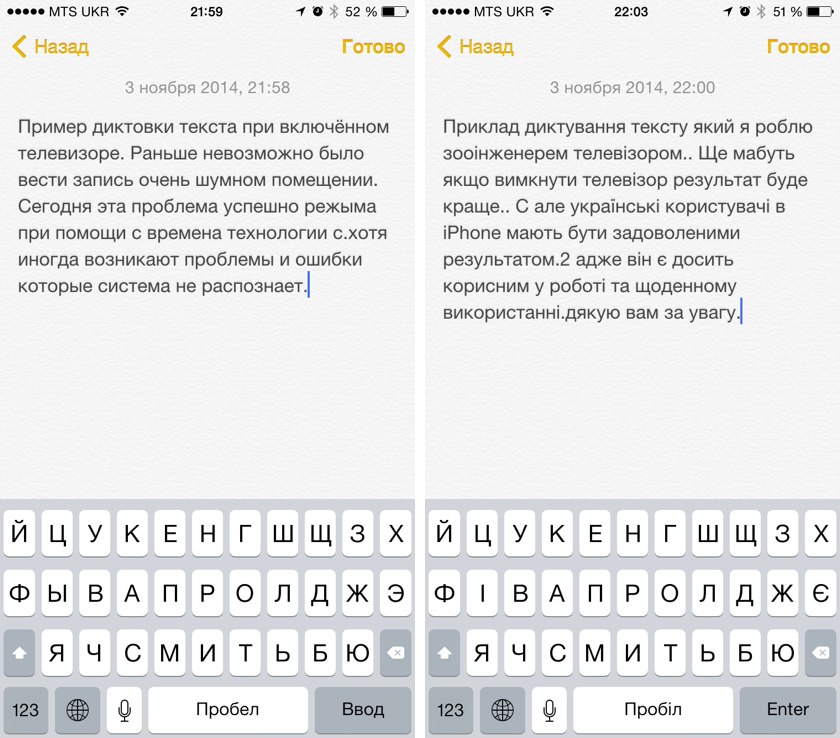
Способ 1
Express Scribe — это профессиональная программа, которой пользуются практически все, кто занимается переводом аудио- и видеозаписей. Она имеет все необходимые функции, которые требуются.
После установки данной программы и запуска, вы увидите такое окно.
Она, к сожалению, не имеет интерфейса на русском языке, но в ней и так всё понятно и настроек особых не требуется. Просто установите её и работайте.
Удобство этой программы заключается в том, что не нужно переключаться между окнами проигрывателя и текстовым документом, прослушивать запись и набирать текст можно сразу в одном месте.
Шаг 1. Чтобы загрузить свои файлы, которые нужно транскрибировать, нажмите кнопку «Load» или просто перетащите их из вашей папки, где они лежат, в самое верхнее окно.
Шаг 2. Изучите или напишите себе шпаргалку, какие горячие клавиши вам потребуются в работе.
Стандартные настройки горячих клавиш:
- F9 — воспроизведение записи.

- F4 — пауза.
- F10 — воспроизведение с обычной скоростью.
- F2 — воспроизведение на низкой скорости (50%).
- F3 — воспроизведение на высокой скорости (150%).
- F7 — перемотка назад.
- F8 — перемотка вперёд.
Удобно, что клавиши воспроизведения и паузы настроены под разные руки, и через некоторое время мышечная память их легко запомнит.
Шаг 3. В нижнем правом углу программы установите комфортную для вас скорость проигрывания записи. Можно замедлить до такого состояния, чтобы успевать печатать, не делая паузу.
Шаг 4. Можно начинать делать транскрибацию.
Также для записи вы можете отрегулировать каналы аудио, чтобы звук был лучше и понятнее, просто включите запись и подвигайте шкалы до лучшего качества.
Шаг 5. После того, как вы сделали перевод из аудио в текст, скопируйте получившийся текст в документ Word для сохранения и последующего его редактирования.
Способ 2
Второй способ заключается в том, чтобы не набирать текст на клавиатуре самостоятельно, а чтобы он набирался автоматически с помощью сервисов распознавания голоса.
То есть вы слушаете отрывки записи и голосом их пересказываете или ещё проще, включаете запись на колонках, если качество хорошее, и запускаете функцию голосового ввода.
Я рекомендую использовать сервис Speechpad или обычные Google документы.
В Гугл документах эта функция находится во вкладке «Инструменты» -> «Голосовой ввод…» или запускается сочетанием клавиш CTRL+SHIFT+S.
Заключение
Вот такие два совершенно простых способа, которые помогут вам сделать транскрибацию и заработать (для кого-то первые) деньги через интернет.
Профессия «транскрибатор» очень простая и с ней может справиться каждый, поэтому здесь не так много можно зарабатывать. Я рекомендую вам ознакомиться с другими интересными специальностями в книге «7 профессий в интернете», на которую я недавно делал обзор.
Если у вас возникли ко мне какие-то вопросы или пожелания, то всегда можете написать их мне ниже в комментариях к этой статье. Желаю удачи в освоении данного направления и хороших доходов в удалённой работе!
Речевые технологии. Часть 2. Speech-to-Text: как работает распознавание речи
Мы постоянно взаимодействуем с поисковыми системами и различными устройствами: ищем маршруты до определенных мест, заказываем еду, проверяем почту, отправляем файлы и пр. Голосовое управление позволяет нам тратить на это минимум времени. В его основе лежит технология распознавания речи. Как же она работает?
Мы уже рассказывали о синтезе речи, сегодня поделимся принципами работы технологии Speech-to-Text и способами ее использования в бизнесе.
Что такое распознавание речи
Распознавание речи или Speech-to-Text (STT) — технология преобразования речи в текст. Это многоуровневый процесс анализа акустических сигналов, их структурирования в слова, фразы, предложения и преобразования в текстовый формат. Технологию распознавания речи можно также называть технологией распознавания голоса.
Технологию распознавания речи можно также называть технологией распознавания голоса.
Speech-to-Text используется, когда необходимо создавать много письменного контента, но при этом не использовать ручной набор текста. Также распознавание речи помогает людям с ограниченными возможностями, которым сложно печатать текст вручную.
Технология распознавания голоса существует уже около 70 лет. Раньше это все сводилось к распознаванию простых слов и построению акустической модели. Речь представлялась статично и сравнивалась с готовыми шаблонами в словарях, что часто вело к ошибкам. Сейчас уровень точности и использование Speech-to-Text в повседневной жизни вышли на новый уровень. Благодаря машинному обучению системы распознавания постоянно совершенствуются. Каждое новое распознавание определяет точность следующего.
Как работает Speech-to-Text
Когда голосовой запрос поступает в систему, она воспринимает это как сигналы, которые плавно переходят друг в друга без четких границ. Распознавание речи — это процесс восстановления того, что было сказано, по этим сигналам.
Распознавание речи — это процесс восстановления того, что было сказано, по этим сигналам.
Обычно этот процесс делится на несколько этапов:
- Анализ сигнала. Компьютер отправляет полученный запрос на сервер, где он очищается от шумов и помех. После этого запись сжимается: делится на фрагменты длиной 25 миллисекунд. Каждый фрагмент пропускается через акустическую модель, которая определяет, какие именно звуки были произнесены, для последующего распознавания.
- Распознавание сигнала. Эталонные произношения, которые хранятся в акустической модели, сравниваются с каждым речевым фрагментом записи. Система с помощью машинного обучения подбирает варианты произнесенных слов и их контекст и собирает из звуков предполагаемые слова.
- Преобразование сигнала в текст. После этого, используя языковую модель, система определяет порядок слов и подбирает нераспознанные слова по контексту. Полученная информация поступает декодер, который объединяет данные от акустической и языковой моделей и преобразует их в текст с наиболее вероятной последовательностью слов.
Как распознавание речи используется в бизнесе
Использование распознавания речи сегодня помогает бизнесу развиваться в следующих направлениях:
- Интерактивные голосовые системы (IVR). Голосовые роботы позволяют автоматизировать общение с клиентами, снижают нагрузку на операторов и экономят средства компании на расширение контакт-центров.
СБЕР использует решения Voximplant для автоматизации работы колл-центра: робот самостоятельно отвечает на простые вопросы клиентов или помогает оператору найти нужную информацию. В процессе диалога оператора с клиентом происходит онлайн-транскрибация (распознавание речи) речи клиента и поиск подходящих ответов.
- Аналитика телефонных звонков. Аналитика телефонных разговоров развита хуже других каналов коммуникаций с клиентами. Это связано с тем, что звонки нужно записывать, прослушивать и после этого анализировать. С помощью технологии распознавания речи звонки можно анализировать автоматически.
- Проведение маркетинговых исследований. Система может самостоятельно обзванивать клиентов и узнавать их мнение о товарах или услугах. Для человека это не является трудной задачей, но автоматизация освобождает сотрудников от незначительных рутинных дел, а компании помогает сократить возможность человеческого фактора.
Например, проект «Совесть» модернизировал систему голосового взаимодействия в контактном центре с помощью Voximplant. Технологии синтеза и распознавания речи позволяют боту без оператора общаться с клиентами в двух направлениях: реагировать на обращения и помогать в решении проблем на входящей линии; проводить опросы при исходящих звонках. Благодаря боту проект контролирует качество обслуживания, оценивает уровень лояльности и удовлетворенности клиентов продуктом (NPS и CSI). Так, регулярно проводятся опросы по определенной выборке потребителей для сбора обратной связи.
- Персонализация предложений. С помощью технологий распознавания речи система может определить пол, возраст и другие данные о клиенте. Анализ этих данных позволяет выявить его потребности и предоставить соответствующие уникальные предложения о товарах или услугах.
- Сбор информации. Когда оператор получает информацию от клиента, ему необходимо занести ее в базу данных. Это действие можно автоматизировать, если настроить систему распознавания речи.
 С помощью технологий распознавания речи система может определить пол, возраст и другие данные о клиенте. Анализ этих данных позволяет выявить его потребности и предоставить соответствующие уникальные предложения о товарах или услугах.
С помощью технологий распознавания речи система может определить пол, возраст и другие данные о клиенте. Анализ этих данных позволяет выявить его потребности и предоставить соответствующие уникальные предложения о товарах или услугах.Проект «Совесть» с помощью технологий распознавания и синтеза речи также настроил голосовые уведомления и автоматизировал сбор информации. Бот совершает исходящие звонки, чтобы напомнить о необходимости внесения ежемесячного платежа или уточнить детали доставки карты. При этом количество исходящих звонков может достигать 2 тысяч в минуту, а режим работы позволяет задействовать его при необходимости 24/7.
- Найм сотрудников. Однообразный процесс в виде первичного отбора кандидатов технологии распознавания речи позволяют проводить без участия сотрудников HR-отдела. Система может задать кандидатам простые вопросы, проанализировать их ответы и оценить удовлетворенность. кандидата условиями работы. Мы уже писали о том, как компания KFC настроила автоматическую верификацию заявок, в статье о технологиях синтеза речи.
 Система может задать кандидатам простые вопросы, проанализировать их ответы и оценить удовлетворенность. кандидата условиями работы. Мы уже писали о том, как компания KFC настроила автоматическую верификацию заявок, в статье о технологиях синтеза речи.
Система может задать кандидатам простые вопросы, проанализировать их ответы и оценить удовлетворенность. кандидата условиями работы. Мы уже писали о том, как компания KFC настроила автоматическую верификацию заявок, в статье о технологиях синтеза речи.Помимо этого технологии распознавания речи активно используются и в других сферах:
- Голосовая почта. Позволяет диктовать и отправлять сообщения.
- Голосовой интерфейс. «Умный дом», голосовое управление бытовой техникой, навигацией в автомобиле и т. д.
- Социальные сервисы. Сервисы для людей с ограниченными возможностями.
Решение от Voximplant
Voximplant позволяет настраивать распознавание речи для автоматизированной обработки входящих звонков. Благодаря распознаванию речи и обработке естественного языка абоненты могут общаться с системой, как с живым человеком. Это избавляет от необходимости использовать ввод в тональном режиме и чрезмерно сложные подсказки меню. А передовая технология Voximplant способна понимать, что имеет в виду говорящий, ориентируясь не только на точные формулировки и ключевые слова, но и на контекст. Так, многие обращения могут обрабатываться без участия живого оператора.
А передовая технология Voximplant способна понимать, что имеет в виду говорящий, ориентируясь не только на точные формулировки и ключевые слова, но и на контекст. Так, многие обращения могут обрабатываться без участия живого оператора.
Первая система распознавания речи появилась в 1952 году. Она преобразовывала названные числа в текст. Сейчас система распознавания речи есть почти у каждого в руках, так как установлена на многих смартфонах. Голосом мы можем управлять различными приложениями и девайсами, упрощающими нашу жизнь. Технологии распознавания речи вышли на новый уровень, и сейчас продолжают активно развиваться, являясь одним из самых важных направлений в сфере ИИ.
расшифровщик аудио в текст… через облако Яндекса!
Мы уже использовали нейросети Яндекса, когда делали свой орфонейрокорректор — он автоматически исправляет все ошибки и опечатки, когда вы набираете текст. Теперь перейдём на уровень выше — используем искусственный интеллект для распознавания голоса в аудиозаписях. И для этого мы воспользуемся облачным сервисом Яндекса, потому что можем. Вы тоже.
И для этого мы воспользуемся облачным сервисом Яндекса, потому что можем. Вы тоже.
Для чего это нужно
Смысл такой: если нужно перевести аудиозапись в текст, можно это сделать очень быстро с помощью нейросетей. Яндекс в этом всяко преуспел, и мы теперь можем этим воспользоваться в своё удовольствие.
Если вы редактор или автор, вам нужно часто общаться с экспертами, чтобы получить необходимую информацию для своей работы. Можно всё конспектировать на ходу, а можно записать на диктофон и потом перевести в текст за 10 минут.
Если коллега вам оставил длинное голосовое сообщение, текст которого нужно разместить на сайте, то можно набрать всё руками или отдать эту задачу компьютеру.
Если вы студент и не хотите конспектировать лекции по гуманитарным наукам, запишите их на телефон, и нейронка переведёт их в текст. У вас будут самые полные лекции, и вся группа будет бегать за вами перед экзаменом.
В некоторых вебинарах или видео на YouTube есть классная информация, но каждый раз приходится их смотреть и перематывать, чтобы найти нужное. Выход простой: берём видео, вырезаем оттуда звук, отправляем в сервис распознавания и получаем готовый текст, с которым работать гораздо проще.
Что будем использовать
Возьмём сервис Yandex SpeechKit — он позволяет распознать или озвучить любой текст на нескольких языках. Именно на этом движке работает голосовой помощник «Алиса»: она использует его, чтобы понимать, что вы говорите, и говорить что-то в ответ.
SpeechKit — часть «Яндекс.Облака», большого ресурса, который умеет решать много задач. Например, кроме работы с текстом и голосом «Облако» может предоставить виртуальную вычислительную машину и хранилище данных, работать с Docker-образами, защищать от хакерских атак, управлять базами данных и много чего ещё.
Так как всё это — серьёзные технологии для программистов и IT-спецов, многое нужно будет делать в командной строке. Для этого мы сейчас покажем каждый шаг и объясним, для чего именно мы это делаем. В результате научимся отправлять файлы в «Облако» и получать оттуда готовый текст.
Для этого мы сейчас покажем каждый шаг и объясним, для чего именно мы это делаем. В результате научимся отправлять файлы в «Облако» и получать оттуда готовый текст.
Вся первая часть проекта у нас как раз и будет про настройку «Яндекс.Облака» и подготовку к работе.
Условия и ограничения
Распознавание речи — платная услуга, но Яндекс даёт 60 дней и 3000 ₽ для тестирования. За эти деньги можно распознать 83 часа аудио — больше трёх суток непрерывного разговора. Это очень много: за время подготовки этой статьи и тестирования технологии мы потратили 4 рубля за 3 дня.
Если отправлять файлы с записью больше минуты, то одна секунда аудио стоит одну копейку. Чтобы распознать запись длиной в час, нужно 36 рублей. Это примерно в 20 раз дешевле, чем берут транскрибаторы — люди, которые сами набирают текст на слух, прослушивая запись.
Нейросеть часто понимает, когда текст нужно разбить на абзацы, но делает это не всегда правильно.
Ещё она не ставит запятые, тире и двоеточия. Максимум, что она делает — ставит точку в конце предложения и начинает новое с большой буквы. Но при этом почти все слова распознаются правильно, и отредактировать такой текст намного проще, чем набирать его с нуля.
Последнее — из-за особенностей нашей речи и произношения SpeechKit может путать слова, которые звучат одинаково (код — кот) или ставить неправильное окончание («слава обрушилось на него неожиданно»). Решение простое: прогоняем такой текст через орфонейрокорректор и всё в порядке. Одна нейронка исправляет другую — реальность XXI века 🙂
Всё, приступаем.
Иногда результат получается вот таким, но на понимание текста это не сильно влияет.
Регистрация в «Облаке»
Для этого нам понадобится Яндекс-аккаунт: заведите новый, если его у вас нет, или войдите в него под своим логином.
Если аккаунт уже есть — переходим на страницу сервиса cloud. yandex.ru и нажимаем «Подключиться»:
yandex.ru и нажимаем «Подключиться»:
На следующем шаге подтверждаем согласие с условиями, и мы у цели:
На главной странице «Облака» активируем пробный период, чтобы бесплатно использовать все возможности сервиса, в том числе и SpeechKit:
Единственное, что нам осталось из формальностей, — заполнить данные о себе и привязать банковскую карту. С неё спишут два рубля и сразу вернут их, чтобы убедиться, что карта активна. Она нужна для того, чтобы пользоваться сервисами после окончания пробного периода. Если вам это будет не нужно — просто удалите карту, когда закончите проект.
Когда подключите карту — нажмите «Активировать».
Когда всё будет готово, вы попадёте на главную страницу сервиса, где увидите что-то подобное:
Вместо статуса Active вы увидите статус «Пробный период» и баланс в 3000 ₽ без кредитного лимита.
Командная строка Яндекса
С её помощью мы сможем получать нужные ключи доступа, чтобы отправлять файлы с записями на сервер для обработки.
Весь процесс установки мы опишем для Windows. Если у вас Mac OS или Linux, то всё будет то же самое, но с поправкой на операционную систему. Поэтому если что — читайте инструкцию.
Для установки и дальнейшей работы нам понадобится PowerShell — это программа для работы с командной строкой, но с расширенными возможностями. Запускаем PowerShell и пишем там такую команду:
iex (New-Object System.Net.WebClient).DownloadString(‘https://storage.yandexcloud.net/yandexcloud-yc/install.ps1’)
Она скачает и запустит установщик командной строки Яндекса. В середине скрипт спросит нас, добавить ли путь в системную переменную PATH, — в ответ пишем Y и нажимаем Enter:
Командная строка Яндекса установлена в системе, закрываем PowerShell и запускаем его заново. Теперь нам нужно получить токен авторизации — это такая последовательность символов, которая покажет «Облаку», что мы — это мы, а не кто-то другой.
Теперь нам нужно получить токен авторизации — это такая последовательность символов, которая покажет «Облаку», что мы — это мы, а не кто-то другой.
Переходим по специальной ссылке, которая даст нам нужный токен. Сервис спросит у нас, разрешаем ли мы доступ «Облака» к нашим данным на Яндексе — нажимаем «Разрешить». В итоге видим страницу с токеном:
Теперь нужно закончить настройку командной строки Яндекса, чтобы можно было с ней полноценно работать. Для этого в PowerShell пишем команду:
yc init
Когда скрипт попросит — вводим токен, который мы только что получили:
Сначала отвечаем «1», затем «Y» и «4».
Настраиваем доступ
Есть два способа работать с сервисом SpeechKit: через IAM-токен, который нужно запрашивать заново каждые 12 часов, или через API-ключ, который постоянный и менять его не нужно. Мы будем работать через ключ, потому что так удобнее.
Чтобы его получить, нам нужен сервисный аккаунт в «Облаке». Создадим его так.
1. Заходим в консоль управления и нажимаем на единственную папку в нашем облаке:
2. Выбираем «Сервисные аккаунты» → «Создать»:
3. Вводим имя (какое понравится), затем нажимаем «Добавить роль» и выбираем «editor»:
4. Заходим в сервисный аккаунт, который только что создали:
5. Нажимаем на кнопку «Создать новый ключ» и выбираем пункт «Создать API-ключ»:
Сервис спросит про описание — можно ничего не заполнять.
6. Сохраняем отдельно секретный ключ — он выдаётся только один раз и восстановить его нельзя. Выделяем, копируем и сохраняем в безопасное место:
Что дальше
Поздравляем — самое сложное позади. Дальше будет проще: мы напишем программу на Python, которая будет отправлять на сервер запрос на расшифровку и получать в ответ готовый текст. Ту би континьюд.
Ту би континьюд.
Обзор технологий распознавания голоса и способы его применения
«Хотелось бы сразу сказать, что с сервисами распознавания имею дело впервые. И поэтому расскажу о сервисах, с обывательской точки зрения» — отметил наш эксперт – «для тестирования распознавания я использовал пользовался тремя инструкциями: Google, Yandex и Azure».
Небезызвестная IT-корпорация предлагает протестировать свой продукт Google Cloud Platform в режиме онлайн. Опробовать работу сервиса может бесплатно любой желающий. Сам продукт удобен и понятен в работе.
Плюсы:
- поддержка более чем 80 языков;
- быстрая обработка имен;
- качественное распознавание в условиях плохой связи и при наличии посторонних звуков.
Минусы:
- есть трудности при распознавании сообщений с акцентом и плохим произношением, что делает систему трудной в использовании кем-то кроме носителей языка;
- отсутствие внятной технической поддержки сервиса.
Yandex
Распознавание речи от Yandex предоставляется в нескольких вариантах:
- Облако
- Библиотека для доступа с мобильных приложений
- «Коробочная» версия
- JavaScript API
Но будем объективными. Нас, в первую очередь, интересует не разнообразие возможностей использования, а качество распознавания речи. Поэтому, мы воспользовались пробной версией SpeechKit.
Плюсы:
- простота в использовании и настройке;
- хорошее распознавание текста на Русском языке;
- система выдаёт несколько вариантов ответов и через нейронные сети пытается найти самый похожий на правду вариант.
Минусы:
- при потоковой обработке некоторые слова могут определяться некорректно.
Azure
Система Azure разработана компанией Microsoft. На фоне аналогов она сильно выделяется за счёт цены. Но, будьте готовы столкнуться с некоторыми трудностями. Инструкция, представленная на официальном сайте то ли неполная, то ли устаревшая. Адекватно запустить сервис нам так и не удалось, поэтому пришлось воспользоваться сторонним окном запуска. Однако, даже здесь для тестирования вам понадобится ключ от сервиса Azure.
Адекватно запустить сервис нам так и не удалось, поэтому пришлось воспользоваться сторонним окном запуска. Однако, даже здесь для тестирования вам понадобится ключ от сервиса Azure.
Плюсы:
- относительно других сервисов, Azure очень быстро обрабатывает сообщения в режиме реального времени.
Минусы:
- система очень чувствительна к акценту, с трудом распознает речь не от носителей языка;
- система работает только на английском языке.
Итоги обзора:
Взвесив все плюсы и минусы мы остановились на Яндексе. SpeechKit дороже чем Azure, но дешевле чем Google Cloud Platform. В программе от Google было замечено постоянное улучшение качества и точности распознавания. Сервис самосовершенствуется за счет технологий машинного обучения. Однако, распознавание русскоязычных слов и фраз у Яндекса на уровень выше.
Как использовать распознавание голоса в бизнесе?
Вариантов использования распознавания масса, но мы остановим ваше внимание на том, который, в первую очередь, повлияет на продажи вашей компании. Для наглядности разберём процесс работы распознавания на реальном примере.
Для наглядности разберём процесс работы распознавания на реальном примере.
Не так давно, нашим клиентом стал один, известный всем SaaS сервис (по просьбе компании, имя сервиса не разглашается). С помощью F1Golos они записали два аудиоролика, один из которых был нацелен на продление жизни тёплых клиентов, другой – на обработку запросов клиентов.
Как продлить жизнь клиентов с помощью распознавания голоса?
Зачастую, SaaS сервисы работают по ежемесячной абонентской плате. Рано или поздно, период пробного пользования или оплаченного трафика — заканчивается. Тогда появляется необходимость продления услуги. Компанией было принято решение предупреждать пользователей об окончании трафика за 2 дня до истечения срока пользования. Оповещение пользователей происходило через голосовую рассылку. Ролик звучал так: «Добрый день, напоминаем, что у вас заканчивается период оплаченного пользования сервисом ХХХ. Для продления работы сервиса скажите — да, для отказа от предоставляемых услуг скажите нет».
Звонки пользователей, которые произнесли кодовые слова: ДА, ПРОДЛИТЬ, ХОЧУ, ПОДРОБНЕЕ; были автоматически переведены на операторов компании. Так, порядка 18% пользователей продлили регистрацию благодаря лишь одному звонку.
Как упростить систему обработки данных с помощью распознавание речи?
Второй аудиоролик, запущенный той же компанией, носил другой характер. Они использовали голосовую рассылку для того, чтобы снизить издержки на верификацию номеров телефона. Ранее они проверяли номера пользователей с помощью звонка-роботом. Робот просил пользователей нажать определенные клавиши на телефоне. Однако с появлением технологий распознавания, компания сменила тактику. Текст нового ролика звучал следующим образом: «Вы зарегистрировались на портале ХХХ, если вы подтверждаете свою регистрацию, скажите да. Если вы не направляли запрос на регистрацию, скажите нет». Если клиент произносил слова: ДА, ПОДТВЕРЖДАЮ, АГА или КОНЕЧНО, данные об этом моментально переводились в CRM-систему компании. И запрос на регистрацию подтверждался автоматически за пару минут. Внедрение технологий распознавания снизило время одного звонка с 30 до 17 секунд. Тем самым, компания снизила издержки почти в 2 раза.
Если вам интересны другие способы использования распознавания голоса, или вы хотите узнать подробнее о голосовых рассылках, переходите по ссылке. На F1Golos вы сможете оформить первую рассылку бесплатно и узнать на себе, как работают новые технологии распознавания.
Введение в распознавание речи с Python
Распознавание речи, как следует из названия, относится к автоматическому распознаванию человеческой речи. Распознавание речи является одной из важнейших задач в области взаимодействия человека с компьютером. Если вы когда-либо общались с Alexa или когда-либо приказывали Сири выполнить задание, вы уже испытали силу распознавания речи.
Распознавание речи имеет различные приложения — от автоматической транскрипции речевых данных (например, голосовой почты) до взаимодействия с роботами посредством речи.
В этом руководстве вы увидите, как мы можем разработать очень простое приложение для распознавания речи, способное распознавать речь как из аудиофайлов, так и в режиме реального времени с микрофона. Итак, начнем без дальнейших церемоний.
В Python было разработано несколько библиотек распознавания речи. Однако мы будем использовать библиотеку SpeechRecognition, которая является самой простой из всех библиотек.
Установка библиотеки SpeechRecognition
Выполните следующую команду для установки библиотеки:
pip install SpeechRecognitionРаспознавание речи из аудио файлов
В этом разделе вы увидите, как мы можем переводить речь из аудиофайла в текст. Аудиофайл, который мы будем использовать в качестве входных данных, можно скачать по этой ссылке. Загрузите файл в вашу локальную файловую систему.
Первым шагом, как всегда, является импорт необходимых библиотек. В этом случае нам нужно импортировать только что загруженную библиотеку speech_recognition.
import speech_recognition as speech_recog
Для преобразования речи в текст нам нужен единственный класс — это класс Recognizer из модуля speech_recognition. В зависимости от базового API, используемого для преобразования речи в текст, класс Recognizer имеет следующие методы:
recognize_bing(): Использует Microsoft Bing Speech APIrecognize_google(): Использует Google Speech APIrecognize_google_cloud(): Использует Google Cloud Speech APIrecognize_houndify(): Использует Houndify API от SoundHoundrecognize_ibm(): Использует IBM Speech to Text APIrecognize_sphinx(): Использует PocketSphinx API
Среди всех вышеперечисленных способов метод recognize_sphinx() можно использовать в автономном режиме для перевода речи в текст.
Чтобы распознать речь из аудиофайла, мы должны создать объект класса AudioFile модуля speech_recognition. Путь аудиофайла, который вы хотите перевести в текст, передается в конструктор класса AudioFile. Выполните следующий скрипт:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
В приведенном выше коде обновите путь к аудиофайлу, который вы хотите расшифровать.
Мы будем использовать метод recognize_google() для расшифровки наших аудио файлов. Тем не менее, метод recognize_google() требует объект AudioData модуля speech_recognition в качестве параметра. Чтобы преобразовать наш аудиофайл в объект AudioData, мы можем использовать метод record() класса Recognizer. Нам нужно передать объект AudioFile методу record(), как показано ниже:
with sample_audio as audio_file:
audio_content = recog.record(audio_file)
Теперь, если вы проверите тип переменной audio_content, вы увидите, что она имеет тип speech_recognition.AudioData.
Результат:
speech_recognition.AudioData
Теперь мы можем просто передать объект audio_content методу recognize_google() объекта класса Recognizer(), и аудиофайл будет преобразован в текст. Выполните следующий скрипт:
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas tank degrees office 30 face before you go out the race was badly strained and hung them the stray cat gave birth to kittens the young girl gave no clear response the meal was called before the bells ring what weather is in living'
Приведенный выше результат показывает текст аудиофайла. Вы можете видеть, что файл не был на 100% правильно транскрибирован, но точность довольно разумная.
Установка длительности и значений смещения
Вместо того, чтобы транскрибировать полную речь, вы также можете транскрибировать определенный сегмент аудиофайла. Например, если вы хотите транскрибировать только первые 10 секунд аудиофайла, вам нужно передать 10 в качестве значения параметра duration метода record(). Посмотрите на следующий скрипт:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
audio_content = recog.record(audio_file, duration=10)
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas'
Таким же образом вы можете пропустить некоторую часть аудиофайла с самого начала, используя параметр offset. Например, если вы не хотите транскрибировать первые 4 секунды звука, передайте 4 в качестве значения для атрибута offset. Например, следующий скрипт пропускает первые 4 секунды аудиофайла, а затем транскрибирует аудиофайл в течение 10 секунд.
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
audio_content = recog.record(audio_file, offset=4, duration=10)
recog.recognize_google(audio_content)
Результат:
'take the winding path to reach the lake no closely the size of the gas tank web degrees office dirty face'
Обработка шума
Аудио файл может содержать шум по разным причинам. Шум действительно может повлиять на качество перевода речи в текст. Чтобы уменьшить шум, класс Recognizer содержит метод adjust_for_ambient_noise(), который принимает объект AudioData в качестве параметра. Следующий скрипт показывает, как можно улучшить качество транскрипции, удалив шум из аудиофайла:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
recog.adjust_for_ambient_noise(audio_file)
audio_content = recog.record(audio_file)
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas tank web degrees office 30 face before you go out the race was badly strained and hung them the stray cat gave birth to kittens the younger again no clear response the mail was called before the bells ring what weather is in living'
Вывод очень похож на то, что мы получили ранее; это связано с тем, что в аудиофайле уже было очень мало шума.
Распознавание речи с живого микрофона
В этом разделе вы увидите, как вы можете транслировать живое аудио, полученное через микрофон в вашей системе.
Существует несколько способов обработки аудиовхода, полученного через микрофон, и для этого были разработаны различные библиотеки. Одной из таких библиотек является PyAudio. Выполните следующий скрипт для установки библиотеки PyAudio:
Теперь источником транскрибируемого звука является микрофон. Чтобы захватить звук с микрофона, нам нужно сначала создать объект класса Microphone модуля Speach_Recogniton, как показано ниже:
mic = speech_recog.Microphone()
Чтобы увидеть список всех микрофонов в вашей системе, вы можете использовать метод list_microphone_names():
speech_recog.Microphone.list_microphone_names()
Результат:
['Microsoft Sound Mapper - Input',
'Microphone (Realtek High Defini',
'Microsoft Sound Mapper - Output',
'Speakers (Realtek High Definiti',
'Microphone Array (Realtek HD Audio Mic input)',
'Speakers (Realtek HD Audio output)',
'Stereo Mix (Realtek HD Audio Stereo input)']
Это список микрофонов, доступных в моей системе. Имейте в виду, что ваш список, скорее всего, будет выглядеть иначе.
Следующим шагом является захват звука с микрофона. Для этого вам нужно вызвать метод listen() класса Recognizer(). Как и метод record(), метод listen() также возвращает объект speech_recognition.AudioData, который затем может быть передан методу recognize_google().
Следующий скрипт предлагает пользователю что-то сказать в микрофон, а затем печатает все, что сказал пользователь:
with mic as audio_file:
print("Speak Please")
recog.adjust_for_ambient_noise(audio_file)
audio = recog.listen(audio_file)
print("Converting Speech to Text...")
print("You said: " + recog.recognize_google(audio))
Как только вы выполните приведенный выше скрипт, вы увидите следующее сообщение:
В этот момент произнесите все, что хотите, и сделайте паузу. Как только вы сделали паузу, вы увидите транскрипцию всего, что вы сказали. Вот результат, который я получил:
Converting Speech to Text...
You said: hello this is normally from stack abuse abuse this is an article on speech recognition I hope you will like it and this is just a test speech and when I will stop speaking are you in today thank you for Reading
Важно отметить, что если метод recognize_google() не может сопоставить слова, которые вы говорите, с любым из слов в своем хранилище, выдается исключение. Вы можете проверить это, сказав несколько непонятных слов. Вы должны увидеть следующее исключение:
Speak Please
Converting Speech to Text...
---------------------------------------------------------------------------
UnknownValueError Traceback (most recent call last)
in
8 print("Converting Speech to Text...")
9
---> 10 print("You said: " + recog.recognize_google(audio))
11
12
~\Anaconda3\lib\site-packages\speech_recognition\__init__.py in recognize_google(self, audio_data, key, language, show_all)
856 # return results
857 if show_all: return actual_result
--> 858 if not isinstance(actual_result, dict) or len(actual_result.get("alternative", [])) == 0: raise UnknownValueError()
859
860 if "confidence" in actual_result["alternative"]:
UnknownValueError:
Лучшим подходом является использование блока try при вызове метода recognize_google(), как показано ниже:
with mic as audio_file:
print("Speak Please")
recog.adjust_for_ambient_noise(audio_file)
audio = recog.listen(audio_file)
print("Converting Speech to Text...")
try:
print("You said: " + recog.recognize_google(audio))
except Exception as e:
print("Error: " + str(e))
Вывод
Распознавание речи имеет различные полезные приложения в области взаимодействия человека с компьютером и автоматической транскрипции речи. В этой статье кратко объясняется процесс транскрипции речи в Python через библиотеку speech_recognition и объясняется, как переводить речь в текст, когда источником звука является аудиофайл или живой микрофон.
Диктуйте текст с помощью функции распознавания речи
Есть несколько способов исправить ошибки, допущенные во время диктовки. Вы можете сказать «исправьте это», чтобы исправить последнее сказанное вами. Чтобы исправить одно слово, произнесите «правильно» и затем слово, которое вы хотите исправить. Если слово встречается более одного раза, будут выделены все экземпляры, и вы сможете выбрать тот, который хотите исправить. Вы также можете добавлять слова, которые часто не слышны или не распознаются, с помощью Речевого словаря.
Использование диалогового окна панели «Альтернативы»
Откройте распознавание речи, нажав кнопку Пуск , нажав Все программы , щелкнув Стандартные , щелкнув Специальные возможности , а затем щелкнув Распознавание речи Windows .
Скажите «начать прослушивание» или нажмите кнопку « Микрофон », чтобы перейти в режим прослушивания.
Выполните одно из следующих действий:
Чтобы исправить последнее, что вы сказали, скажите «исправь».
Чтобы исправить одно слово, произнесите «правильно», а затем слово, которое вы хотите исправить.
В диалоговом окне панели «Альтернативы » произнесите число рядом с нужным элементом и нажмите «ОК.«
Примечание: Чтобы изменить выбор, в диалоговом окне панели «Альтернативы» произнесите «по буквам», затем номер элемента, который вы хотите изменить, а затем «ОК».
Использование речевого словаря
Откройте распознавание речи, нажав кнопку Пуск , нажав Все программы , щелкнув Стандартные , щелкнув Специальные возможности , а затем щелкнув Распознавание речи Windows .
Скажите «начать прослушивание» или нажмите кнопку « Микрофон », чтобы перейти в режим прослушивания.
Скажите «открыть речевой словарь».
Выполните одно из следующих действий:
Чтобы добавить слово в словарь, нажмите или произнесите Добавить новое слово , а затем следуйте инструкциям мастера.
Чтобы запретить диктовку определенного слова, щелкните или произнесите Запретить диктовку слова , а затем следуйте инструкциям мастера.
Чтобы исправить или удалить слово, которое уже есть в словаре, щелкните или произнесите Изменить существующие слова , а затем следуйте инструкциям мастера.
Примечание. Распознавание речи доступно только на английском, французском, испанском, немецком, японском, упрощенном китайском и традиционном китайском языках.
Что такое распознавание голоса?
Обновлено: 16.05.2020, Computer Hope
Также называется распознавание речи. , распознавание голоса. — это компьютерная программа или аппаратное устройство с возможностью декодирования человеческого голоса.Распознавание голоса обычно используется для управления устройством, выполнения команд или записи без использования клавиатуры, мыши или нажатия каких-либо кнопок. Сегодня это делается на компьютере с программным обеспечением ASR ( автоматического распознавания речи ). Многие программы ASR требуют, чтобы пользователь «обучил» программу ASR распознавать их голос, чтобы она могла более точно преобразовывать речь в текст. Например, вы можете сказать «открытый Интернет», и компьютер откроет Интернет-браузер.
Первое устройство ASR было использовано в 1952 году и распознавало однозначные цифры, произносимые пользователем (оно не было управляемым компьютером). Сегодня программы ASR используются во многих отраслях, включая здравоохранение, военную промышленность (например, истребители F-16), телекоммуникации и персональные компьютеры (например, вычисления без помощи рук).
Что требуется для распознавания голоса?
Чтобы распознавание голоса работало, у вас должен быть компьютер со звуковой картой и микрофоном или гарнитурой. Другие устройства, такие как смартфоны, имеют все необходимое оборудование, встроенное в устройство.Кроме того, используемое вами программное обеспечение требует поддержки распознавания голоса, или, если вы хотите использовать распознавание голоса повсюду, вам потребуется установить такую программу, как Nuance Naturally Speaking.
Если вы используете Microsoft Windows Vista, 7, 8 или 10, вы также можете использовать прилагаемую программу распознавания речи Windows.
Наконечник
Хотя для распознавания речи можно использовать любой микрофон, вы получите гораздо лучшие результаты, если используете гарнитуру.
Примеры использования распознавания голоса
По мере того, как распознавание голоса улучшается, оно внедряется во многих местах, и, скорее всего, вы уже использовали его.Ниже приведены примеры того, где вы можете столкнуться с распознаванием голоса.
- Автоматические телефонные системы — Сегодня многие компании используют телефонные системы, которые помогают направить звонящего в нужный отдел. Если вас когда-либо просили что-то вроде «Скажи или нажмите номер 2 для поддержки», и вы говорите «два», вы использовали распознавание голоса.
- Google Voice — Google voice — это служба, которая позволяет искать и задавать вопросы на вашем компьютере, планшете и телефоне.
- Цифровой помощник — Amazon Echo, Apple Siri и Google Assistant используют распознавание голоса для взаимодействия с цифровыми помощниками, которые помогают отвечать на вопросы.
- Car Bluetooth — В автомобилях с Bluetooth или подключением к телефону Handsfree вы можете использовать распознавание голоса для выполнения команд, таких как «позвонить жене», чтобы звонить, не отрывая глаз от дороги.
Типы систем распознавания голоса
Автоматическое распознавание речи — один из примеров распознавания голоса. Ниже приведены другие примеры систем распознавания голоса.
- Система, зависящая от громкоговорителя — Распознавание голоса требует обучения, прежде чем его можно будет использовать, что требует от вас чтения ряда слов и фраз.
- Система, не зависящая от динамика — Программа распознавания голоса распознает голоса большинства пользователей без обучения.
- Распознавание дискретной речи — Пользователь должен делать паузу между каждым словом, чтобы распознавание речи могло идентифицировать каждое отдельное слово.
- Распознавание непрерывной речи — Распознавание голоса позволяет понимать нормальную скорость речи.
- Естественный язык — Система распознавания речи не только понимает голос, но также может возвращать ответы на вопросы или другие задаваемые вопросы.
AVR, биометрия, громкая связь, сетка для мыши, фонема, программа чтения с экрана, звуковые термины, синтез речи, голос, VoIP
AI для распознавания речи — современные компании, технологии и тенденции
Распознавание речи — это технология, которая может распознавать произносимые слова, которые затем могут быть преобразованы в текст. Подмножество распознавания речи — это распознавание голоса, которое представляет собой технологию для идентификации человека на основе его голоса.
Facebook, Amazon, Microsoft, Google и Apple — пять ведущих технологических компаний мира — уже предлагают эту функцию на различных устройствах через такие сервисы, как Google Home, Amazon Echo и Siri.
Имея на рынке ряд продуктов для распознавания голоса, мы решили изучить влияние распознавания голоса на бизнес. Изучая технологии распознавания речи этих компаний, мы пытаемся ответить на следующие вопросы наших читателей:
- Каким образом распознавание речи повышает ценность бизнеса для этих компаний?
- Почему они вкладывают средства в распознавание речи?
- Как эта технология может выглядеть через несколько лет?
Мы начнем с некоторого контекста о том, как и почему технические гиганты разрабатывают технологию распознавания голоса.за ним следует краткое изложение технологий распознавания голоса от Facebook, Amazon, Microsoft, Google и Apple.
Возможные причины для развития технологии распознавания речи
Технологические компании осознают интерес к технологиям распознавания речи и работают над тем, чтобы сделать распознавание голоса стандартом для большинства продуктов. Одна из целей этих компаний может заключаться в том, чтобы голосовые помощники говорили и отвечали с большей точностью в зависимости от контекста и содержания.
Исследования показывают, что использование виртуальных помощников с возможностями распознавания речи, по прогнозам, продолжит расти в следующем году с 60.5 миллионов человек в США в 2017 году до 62,4 миллиона в 2018 году. По прогнозам, к 2019 году 66,6 миллиона американцев будут использовать технологию распознавания речи или голоса.
Чтобы создать надежную систему распознавания речи, искусственный интеллект, стоящий за ним, должен лучше справляться с такими проблемами, как акценты и фоновый шум. Сегодня разработки в области обработки естественного языка и технологии нейронных сетей настолько улучшили речевые и голосовые технологии, что сегодня они, как сообщается, находятся на одном уровне с людьми.В 2017 году. Например, процент ошибок по словам для голосовой технологии Microsoft был зафиксирован компанией на уровне 5,1 процента, в то время как Google сообщает, что оно снизилось до 4,9 процента.
Исследовательская фирма Research and Markets сообщила, что к 2023 году рынок распознавания речи будет стоить 18 миллиардов долларов. По мере того, как технология распознавания голоса становится все больше и лучше, исследования показывают, что ее можно будет внедрить во все, от телефонов до холодильников и автомобилей. Проблеск этого был замечен на ежегодной выставке CES 2017 в Лас-Вегасе, где были либо запущены, либо анонсированы новые устройства с голосом.
Стремясь показать, как сравниваются лидеры в области распознавания голоса, мы создали список, выделив каждый из них, а также его особенности.
Несмотря на то, что все приложения имеют очень похожие функции и возможности интеграции, мы сгруппировали их на основе того, на что указывают наши исследования как на основные направления каждого из них. В этой статье мы отметим две основные области:
- Умный динамик и Умный дом: Выделение Amazon, Google и Microsoft
- Приложения для мобильных устройств: Выделение интеграции Siri от Apple и распознавания речи Facebook.
Умный динамик и умный дом
Amazon Echo и Alexa
До недавнего времени голосовой виртуальный помощник Amazon, Alexa, был доступен только в коммерческих продуктах Amazon. Однако Amazon Web Services сделал голосового помощника доступным для других компаний. Amazon в партнерстве с Intel выпустила комплект для разработки программного обеспечения для устройств голосовой службы Alexa Voice, который может позволить сторонним компаниям встраивать возможности Alexa в свои устройства.Это партнерство является результатом стратегии Amazon «Alexa Everywhere», цель которой, по словам компании, сделать технологию, лежащую в основе Alexa, повсеместно доступной для производителей различных умных и носимых устройств.
На выставке CES 2018 в Лас-Вегасе Sony, TiVo и Hisense представили навыки умного дома, которые интегрировали Alexa, что позволяет клиентам управлять телевизором с помощью голоса. Производители бытовой техники, такие как Whirlpool, Delta, LG и Haier, также добавили навыки распознавания голоса Alexa, чтобы помочь людям контролировать все аспекты своего дома, от телевизоров и микроволновых печей до кондиционеров и смесителей.По данным сайта Amazon Alexa, с помощью Alexa можно управлять более чем 13000 умных домашних устройств от более чем 2500 брендов.
С учетом дополнений других компаний, Alexa теперь имеет 30 000 навыков. В то время как у Apple есть Siri, а у Google — безымянные виртуальные помощники, встроенные в смартфоны и динамики, Amazon интегрировала Alexa в свой интеллектуальный динамик Echo. Amazon не раскрывает окончательные данные о продажах, Forrester прогнозирует, что к концу 2017 года было бы продано 22 миллиона единиц Echo.Согласно Forrester, достижение этого числа продаж сделает Echo самым продаваемым голосовым помощником в США.
Чтобы активировать навык Alexa для новичков, пользователи могут перейти в раздел «Навыки» приложения Alexa, чтобы просмотреть каталог доступных возможностей. После того, как пользователь выбрал навык, нажмите «Включить навык». пользователь также может активировать навыки голосом.
В качестве виртуального помощника Amazon утверждает, что Amazon предлагает Alexa for Business, которая может помочь профессионалам управлять своим расписанием, отслеживать задачи и устанавливать напоминания.При интеграции в такие устройства, как консоли для совещаний, приложение может управлять настройками конференц-зала с помощью голоса говорящего. Устройства с поддержкой Alexa также могут действовать как устройства для аудиоконференций в небольших конференц-залах или управлять оборудованием в больших комнатах.
Компания Logitech встроила Alexa в свои пульты дистанционного управления Harmony для управления домашними развлекательными системами и устройствами умного дома. Дистанционные устройства активируются, когда клиенты говорят простые команды, такие как «Alexa, включи телевизор» или «Alexa, воспроизведи DVD».Затем Alexa отправляет запрос в Harmony, которая ретранслирует запрос на домашние устройства через инфракрасный порт, Bluetooth или IP.
Согласно Amazon, команда прототипов состояла из одного старшего архитектора программного обеспечения в Logitech, которому потребовалось два часа, чтобы интегрировать Alexa в Harmony. Как только прототип был готов, команды со всего Logitech подготовили навык к запуску. Amazon сообщает, что по данным Logitech, от прототипа до уровня производства потребовалось менее двух недель. Никаких других деталей или цифр в этом тематическом исследовании не было.
Другие продукты, которые интегрируют Alexa, включают Alarm.com, Ecobee и Haiku Home.
На более простом уровне Amazon также предлагает Transcribe, службу автоматического распознавания речи (ASR), которая позволяет разработчикам добавлять в свои приложения возможность преобразования речи в текст. После интеграции голосовых функций в приложение конечные пользователи могут анализировать аудиофайлы и получать в ответ текстовый файл с записанной речью.
Хасан Саваф — директор по искусственному интеллекту в Amazon Web Services, где он руководит созданием сервисных и технологических инициатив, связанных с технологиями естественного языка и машинным обучением.Он получил докторскую степень в области компьютерных наук, специализируясь на обработке речи и языка, в RWTH Ахенском университете в Германии.
Google Home и Ассистент
Google Assistant — это голосовой виртуальный помощник Google, чьи навыки включают такие задачи, как отправка и запрос платежей через Google Pay или устранение неполадок в телефоне Pixel 2 XL.
Assistant доступен на таких устройствах, как телефоны Android или iOS, смарт-часы, ноутбуки Pixelbook, смарт-телевизоры / дисплеи Android и автомобили с автоматической поддержкой Android.Пользователи также могут вводить команды в Ассистент, когда требуется тишина в таких местах, как библиотеки.
Для детей и семей Google Ассистент предлагает 50 голосовых игр. Например, дети могут приказать Ассистенту поиграть с ними в космические мелочи.
Google и Target также объединились, чтобы позволить покупателям покупать товары через Assistant.
Спектр интеллектуальных динамиков Google с функцией Assistant включает в себя Home. Google утверждает, что динамик работает с более чем 5000 устройствами умного дома, такими как кофемашины, лампы и термостаты, от более чем 150 брендов, включая Sony, Philips, LG и Toshiba.
По сообщениям, в первом квартале 2018 года Google продала 3,2 миллиона своих устройств Home и Home Mini, что превосходит устройства Echo на базе Alexa на 2,5 миллиона. Обе компании не опубликовали официальных данных.
Чтобы сделать Ассистента более повсеместным, Google открыл набор средств разработки программного обеспечения через Actions, который позволяет разработчикам встраивать голос в свои собственные продукты, поддерживающие искусственный интеллект.
В трехминутном видео ниже показано, как разработчики могут создавать настраиваемые действия с устройствами с помощью интерфейса Google Assistant и позволять пользователям взаимодействовать с устройствами с помощью своего голоса.
Google также недавно запустил программу Assistant Investments, которая инвестирует в стартапы, работающие над продвижением голосовых и вспомогательных технологий, будь то аппаратное или программное обеспечение, и ориентированная на путешествия, игры и гостиничный бизнес.
В рамках программы Google будет оказывать поддержку в технических аспектах, а также в вопросах развития бизнеса и потенциальных клиентов. Стартапы также получат первый доступ к новым функциям и программам Ассистента; кредиты на продукты Google, включая Google Cloud; и потенциальные возможности совместного маркетинга, согласно Google.
Одной из компаний, присоединившихся к этой программе, является Botsociety, которая разрабатывает приложения для чата с использованием Google Assistant, Facebook Messenger и Slack.
Botsociety не публикует тематические исследования на своем веб-сайте, но публикует отзывы от Microsoft, Hubspot, Finn.ai, Convrg и Black Ops, которых компания называет своими клиентами.
Botsociety также утверждает, что обслуживает AXA, Accenture и PWC.
Помимо Botsociety, другие стартапы в этой программе — Go Moment, Edwin и Pulse Labs.
Еще один продукт Google для распознавания речи — это управляемый искусственным интеллектом облачный инструмент преобразования речи в текст, который позволяет разработчикам преобразовывать звук в текст с помощью алгоритмов нейронной сети глубокого обучения. Работая на 120 языках, инструмент позволяет управлять голосом, транскрибировать аудио из колл-центров, обрабатывать потоковую передачу в реальном времени или предварительно записанный звук.
В трехминутном видео ниже показано, как разработчики могут создавать голосовые команды. Первым шагом является запись звука и создание запроса в интерфейсе прикладного программирования (API) преобразования речи в текст в формате JavaScript Object Notation (JSON).Затем разработчик отправляет запрос JSON в речевой API и ожидает ответа.
Эшвин Рам — технический директор по искусственному интеллекту в Google. До Google он шесть лет работал адъюнкт-профессором в вычислительном колледже Технологического института Джорджии. Он также был старшим менеджером Alexa AI в Amazon в течение двух лет. Эшвин имеет докторскую степень по информатике в Йельском университете.
Cortana от Microsoft
Microsoft дебютировала и выпустила собственного голосового виртуального помощника Cortana в октябре 2017 года.
Приложение Cortana для домашних динамиков и мобильных устройств дает пользователю напоминания; ведет заметки и списки; и может помочь в управлении календарем, согласно Microsoft. Его можно загрузить из Apple Store и Google Play и запустить на персональных компьютерах, интеллектуальных колонках и мобильных телефонах.
В домашней колонке Microsoft под названием Invoke Кортана запрограммирована, чтобы помочь пользователям управлять музыкой голосом, ставить плейлисты в очередь, увеличивать или уменьшать громкость; и остановить или запустить треки. Однако он не поддерживает основные сервисы потоковой передачи музыки за пределами Spotify.Microsoft утверждает, что умный динамик также отвечает на различные вопросы; совершает и принимает звонки по Skype; и проверяет последние новости и погоду.
Microsoft утверждает, что на ПК Кортана может управлять электронной почтой пользователей через учетные записи Office 365, Outlook.com и Gmail. По данным Microsoft, клиентами или партнерами Cortana являются Domino’s, Spotify, Capital One, Philips и FitBit.
В качестве примера умения пользователи могут использовать Кортану для подключения к Domino’s Pizza, чтобы разместить заказ, изменить порядок своего последнего заказа Domino и отслеживать свои заказы с помощью Domino’s Tracker.Пользователи могут авторизовать навык, войдя в профиль Domino или зарегистрировавшись в нем.
Capital One сообщает, что его пользователи также могут управлять своей учетной записью с помощью динамика Cortana. Чтобы использовать эту функцию, клиенты Capital One должны подключить свои учетные записи, нажав «Подключить» в интерфейсе приложения Capital One на веб-платформе или мобильной платформе Cortana. Как только они примут условия, им будет предложено ввести ваше имя пользователя и пароль Capital One.
Как объясняется в 55-минутном видео ниже, разработчики, которые хотят создать новые навыки Кортаны для бизнеса, должны сначала настроить среду разработки, такую как облачные ресурсы, инструменты разработки на своих компьютерах, мобильном устройстве Android или iOS или спикере Harman Kardon Invoke, и само приложение Cortana.
Сотрудничество между Cortana и Alexa продолжается, что позволяет интеллектуальным динамикам Amazon получать доступ к Microsoft Office Suite с помощью Cortana. И наоборот, Microsoft заявляет, что пользователи получат доступ к обширным навыкам и интеллекту Alexa, а также смогут делать покупки на Amazon. Дата запуска проекта пока не объявлена.
4-минутное видео ниже демонстрирует интеграцию Cortana и Alexa в одном устройстве. Чтобы переключаться между двумя технологиями, говорящий должен произнести имя виртуального помощника и озвучить навык.Alexa можно попросить активировать Кортану, и наоборот.
В основе технологии распознавания речи Microsoft лежит интерфейс преобразования речи в текст, который преобразует аудиопотоки в текст. Это та же технология, которая использовалась для создания Cortana, Office и других продуктов Microsoft. Microsoft сообщает, что служба распознает конец речи и предлагает варианты форматирования, включая использование заглавных букв и знаков препинания, а также языковой перевод.
Гарри Шам, исполнительный вице-президент по искусственному интеллекту и исследованиям в Microsoft, возглавляет общую стратегию компании в области ИИ и инициативы для Cortana и Bing.Он получил докторскую степень в области робототехники на факультете компьютерных наук Университета Карнеги-Меллона.
Приложения для мобильных устройств
Siri от Apple
Когда Apple впервые интегрировала Siri в iPhone 4 в 2011 году, виртуальный помощник подключился к множеству веб-сервисов и предлагал голосовые возможности, такие как заказ такси через TaxiMagic, извлечение узнавайте подробности концертов на StubHub, ищите обзоры фильмов на Rotten Tomatoes или просматривайте данные о ресторанах на Yelp.
Сегодня возможности Siri включают перевод, воспроизведение песен, бронирование поездок и перевод средств между банковскими счетами. По словам Apple, благодаря возможностям машинного обучения его можно программировать с помощью новых команд.
Хотя Siri была запущена раньше, чем Google Assistant и Amazon Alexa, по-прежнему существуют опасения по поводу ее точности при ответах на команды или вопросы по сравнению с другими технологиями на рынке.
В 2-х минутном видео Cnet.com протестировал Siri против Google Assistant и Amazon Alexa. В какой-то момент Alexa более точно и конкретно реагирует на команду. В нашем исследовании мы также обнаружили гораздо более длинные видеообзоры, которые показывают отставание Siri с точными ответами на вопросы, заданные всем трем голосовым технологиям.
В июне 2018 года Apple выпустила изменения в Siri, запустив новое специальное приложение «Ярлыки», которое пользователи могут загрузить. Apple утверждает, что благодаря этим изменениям пользователи могут приказывать Siri выполнять больше действий с помощью голосовой команды, текста или касания.В настоящее время он доступен на iPhone, iPad, Apple Watch и HomePod. Действия включают подключение и активацию функций сторонних приложений, таких как приложение Tile для поиска ключей, или получение информации о поездках из приложения Kayak.
Apple сообщает, что пользователи также могут использовать ярлыки для удаленной активации или управления гаджетами умного дома, такими как термостаты и вентиляторы, а также для сохранения подкаста или радиостанции. Пользователь также может попросить Siri сообщить членам семьи, когда они путешествуют и сколько времени займет поездка, согласно Apple.
В двухминутном видео ниже показано, как пользователь может создать ярлык для списка воспроизведения с помощью Siri.
Судя по видео, Siri просит пользователя настроить параметры ярлыка плейлиста. Это может включать просьбу Siri включить недавно проигранную музыку или жанр. Приложение также просит пользователя дополнительно настроить другие параметры, такие как значок, который будет отображаться на главном экране. Пользователь начинает создание этого ярлыка, давая Siri словесную команду, например: «Сделайте мне список воспроизведения.
Siri Shortcuts может считывать контекстные данные пользователя, такие как события календаря и местоположения по GPS, чтобы предлагать новые ярлыки. Например, одним ярлыком. Siri можно попросить перейти в режим «Не беспокоить», если пользователь назначит время для просмотра фильма на определенный день. Время пользователя и данные локатора определяют, что пользователь действительно находится внутри театра. Другой пример — это ярлык, о котором сообщается, который может уведомить другой контакт о том, что пользователь опаздывает, на основе календарного события и местоположения устройства.
Сторонние разработчики могут создавать и интегрировать ярлыки в свои собственные приложения с помощью SiriKit. Некоторые уже создали веб-сайт, на котором созданными ими ярлыками можно поделиться с другими пользователями.
Другие компании использовали Siri в своем бизнесе. Одна из них — ClaraLabs, которая заплатила Apple за Clara, обновленную версию технологии виртуального помощника Siri.
Руководство ClaraLabs осознало, что им потребовалось более 9 часов, и в среднем 135 разослали электронные письма, чтобы запланировать и перенести 27 встреч между собой и их рекрутерами, в общей сложности 18 графиков сотрудников.Они говорят, что обратились за помощью к Apple, чтобы создать своего виртуального помощника, который мог бы планировать собеседования для рекрутеров и встречи с заинтересованными сторонами с помощью простой голосовой команды.
В сообщении блога ClaraLabs руководитель отдела доходов ClaraLabs Бриана Берджесс утверждает, что Клара помогла ее компании организовать 27 встреч с 14 компаниями, что почти устранило 9 часов написания и отправки электронных писем.
Другие компании, использующие Siri, включают Kasisto и DigitalGenius.
Джон Джаннандреа (John Giannandrea) — руководитель отдела машинного обучения и стратегии искусственного интеллекта в Apple, где он руководит развитием технологий Core ML и Siri. До этого он восемь лет был старшим вице-президентом Google, где возглавлял группы машинного интеллекта, исследований и поиска. Он получил степень бакалавра наук с отличием в области компьютерных наук в Университете Стратклайда в Шотландии, где ему была присуждена почетная докторская степень.
Facebook Проекты распознавания речи
Хотя Facebook расширил и усовершенствовал свои возможности распознавания лиц, он также приобрел Wit.ai, компания, предлагающая средства разработки на естественном языке, в 2015 году.
На момент приобретения Wit.ai была стартапом, созданным 16 месяцев назад. С момента приобретения Wit.ai утверждает, что ее технологию распознавания речи использовали 160 000 разработчиков и интегрировали в мобильные приложения, роботов, носимые устройства и умную бытовую технику, такую как термостаты, холодильники и освещение.
Видео ниже демонстрирует, как распознавание речи Wit.ai интегрировано в робота Nao с использованием в сотрудничестве с программой Choregraphe, которая позволяет разработчикам создавать анимацию, поведение и диалоги.Согласно видео, Wit.ai позволяет роботу Nao выполнять такие задачи, как ходьба, рукопожатие и планирование с помощью голосовых команд.
Компания заявляет в своем блоге, что платформа останется открытой, что потенциально указывает на стремление Facebook к широкому распространению.
Facebook сегодня имеет возможность автоматически добавлять субтитры к видеообъявлениям с помощью распознавания речи. В видео ниже объясняется, что добавление субтитров к видеорекламе позволяет пользователям Facebook видеть тему рекламы при прокрутке ленты новостей.Рекламодатели Facebook могут добавить субтитры, перейдя в Power Editor и выбрав «генерировать автоматически» в соответствии с инструкциями.
Facebook также приобрела Oculus, производителя гарнитур виртуальной реальности, за 2 миллиарда долларов в 2014 году. В марте 2017 года Oculus объявила, что интегрировала распознавание голоса и речи в свои гарнитуры, чтобы пользователи могли легко перемещаться в виртуальной реальности. Приложение, доступное на английском языке для гарнитур Rift и Gear VR, позволяет пользователям выполнять голосовой поиск из Oculus Home для навигации по играм, приложениям и опыту.
На видео ниже показано, как пользователь гарнитуры Oculus произносит голосовые команды, начиная с «Привет, Окулус» и произнося простые инструкции, такие как «найти», «отменить», «запустить» и т. Д.
Facebook нанял Янна ЛеКун из Нью-Йоркского университета в 2013 году возглавил группу исследований искусственного интеллекта Facebook. В Нью-Йоркском университете ЛеКун исследовал и преподавал машинное обучение, искусственный интеллект, науку о данных, компьютерное зрение, робототехнику, вычислительную нейробиологию и извлечение знаний из данных в течение 15 лет.
Заключительные мысли
Согласно прогнозам, с 2016 по 2024 год отрасль распознавания голоса с оборотом в 55 миллиардов долларов вырастет на 11 процентов.
Эта технология нашла хорошее применение в других отраслях среди небольших и менее известных фирм. , в виде приложений для транскрипции. В настоящее время в сфере здравоохранения медицинские работники используют приложения для преобразования речи в текст, такие как Dolbey, для создания электронных медицинских записей для пациентов.
В правоохранительных и юридических секторах такие компании, как Nuance, предоставляют приложения для транскрипции для точного и быстрого документирования, что является критической потребностью. Транскрипция также используется для документирования отчетов об инцидентах.В средствах массовой информации журналисты используют приложения для транскрипции, такие как Recordly, в качестве инструмента для записи и расшифровки информации для более точного выпуска новостей. В сфере образования Sonix помогает исследователям записывать качественные интервью.
Среди пяти ведущих технологических компаний, предлагающих возможности распознавания речи и голоса — Google, Amazon, Microsoft, Apple и Facebook — аналогичные возможности вращаются вокруг планирования, напоминаний, управления списками воспроизведения, связи с розничными продавцами, управления электронной почтой, выполнения заказов на еду и онлайн-поиск.
Все они предлагаются на мобильных, персональных компьютерах и в большинстве случаев в домашних колонках их собственных брендов. Amazon Alexa находится на Echo, Apple Siri — на HomePod, Google Assistant — на Google Home, Microsoft Cortana — на Invoke. Только Facebook отклонился от этой тенденции, предложив функцию распознавания речи через гарнитуру виртуальной реальности Oculus и субтитры в видеорекламе.
Хотя Apple была первопроходцем в этой области, Siri оказалась менее умной, чем Amazon Alexa и Google Assistant, с ограниченными функциями по сравнению с другими.Что касается общих знаний, исследование, состоящее из почти 5000 вопросов, показало, что Google Assistant является самым умным среди четырех приложений.
Однако с точки зрения навыков, отдельный отчет показал, что Alexa имеет наибольшее количество навыков — 25 785, Google Assistant — 1719, а Кортана — 235. Siri не была включена в этот отчет. Рост числа навыков можно объяснить тем, что компании предлагают бизнес-версии этих приложений. Наборы для разработки программного обеспечения (SDK) стали доступны разработчикам, что позволяет стартапам и малым предприятиям развивать индивидуальные навыки для своих клиентов.
Вот краткое изложение того, как, по нашему мнению, компании конкурируют в отрасли, на основе нашего исследования:
- Google учредила программу Assistant Investments для финансирования стартапов с целью развития технологий распознавания речи и голоса.
- Facebook нанял эксперта по индустрии искусственного интеллекта и приобрел несколько стартапов по распознаванию речи.
- Microsoft заключила партнерское соглашение с Amazon, чтобы потенциально повысить шансы Кортаны на выживание.
Изображение заголовка предоставлено: Szifon
Все, что вам нужно знать о технологии распознавания голоса
Сегодня, с появлением новых технологий, связь изменилась.Например, когда мы звоним в крупное предприятие, физический человек никогда не отвечает на наш звонок. Вместо этого отвечает автоматическая запись голоса и предлагает вам нажимать кнопки для навигации по встроенному меню. Многие компании, занимающиеся разработкой мобильных приложений, выдвинули идеи, выходящие за рамки простого нажатия кнопок; клиентам просто нужно сказать несколько слов, чтобы ответить на их запросы.
Как это возможно?
Это все из-за программ распознавания речи, которые работают с использованием алгоритмов акустического и лингвистического моделирования.Акустическое моделирование означает связь между языковыми единицами речи и звуковыми сигналами, а языковое моделирование сопоставляет звуки с последовательностями слов, чтобы различать слова, которые звучат одинаково.
Это программное обеспечение можно использовать дома и на предприятии, что позволяет пользователям разговаривать со своими компьютерами и преобразовывать их слова в текст с помощью обработки текста и распознавания голоса. Вы можете получить доступ к функциональным командам, таким как установка будильника, открытие файлов, бронирование столика в любимом ресторане и многое другое.С другой стороны, некоторые мобильные приложения предназначены для точных бизнес-настроек, таких как медицинские или юридические записи.
Распознавание речи не становится доминирующим из-за своей ненадежности. Иногда платформы распознавания слов не воспринимают акценты или затруднения речи. И просто распознавать звук недостаточно — программа также должна распознавать новые слова и имена собственные.
Как работает эта технология
Мир наводнен смартфонами, умными автомобилями и умной техникой, но мы не всегда учитываем роль голоса в этих устройствах.Распознавание речи невероятно сложно! Например, представьте, как ребенок изучает язык. Со дня рождения ребенка его окружают звуки. Хотя очень маленькие дети не понимают слов, они усваивают все реплики и произношения, а их мозг формирует паттерны и связи в зависимости от того, как общаются их родители.
Технология распознавания речи работает практически так же:
- Пользователь произносит несколько слов, вызывая распознавание голоса в мобильном приложении.
- Произнесенные слова обрабатываются программой распознавания и преобразуются в текст.
- Преобразованный текст затем предоставляется в качестве входных данных для механизма поиска, который возвращает результаты.
Алгоритмы машинного обучения Google теперь обеспечивают точность слов на 95% для английского языка.
Преимущества голосовых мобильных приложений
- Проще и быстрее : Изначально единственным вариантом доставки команды была клавиатура.Благодаря распознаванию голоса общение с устройствами стало быстрее и естественнее.
- Работает точно : ошибок можно избежать, и пользователи могут сосредоточиться на том, что они делают, вместо того, чтобы смотреть на свой телефон.
- Повышенная производительность : Мобильные приложения на основе голосовой связи обеспечивают оптимизированные операции, повышающие производительность труда.
- Повышение безопасности : Голосовая технология позволяет быстро и безопасно интерпретировать и отслеживать, и требует меньшего обучения.
- Многократное использование : Голосовые заказы через мобильные устройства помогают выполнять задачи.
Почему это важно
Интегрируя навыки распознавания голоса в свое мобильное приложение, вы можете сделать гораздо больше, не используя клавиатуру телефона. Когда вы пишете кому-то текстовые сообщения, ввод длинных утверждений может привести к ошибкам и всегда утомителен, но с голосовыми возможностями вы можете общаться без помощи рук. С помощью голосовых технологий разработчики мобильных приложений могут улучшить взаимодействие с пользователем и повысить удобство работы, поскольку команды мобильного приложения предоставляют уникальный способ решения проблем UX.Если вы хотите избежать отвлекающих факторов или просто не можете управлять сенсорным экраном, голосовой помощник может оказаться самым простым решением.
Проблемы, с которыми сталкиваются при интеграции голосовых возможностей
Поскольку голосовая интеграция — относительно новая технология, неизбежно возникнут проблемы.
- Реакция в реальном времени : Реакция в реальном времени зависит от возможностей сети, сетевого подключения и микрофона устройства. Когда пользователь дает голосовую команду, мобильное приложение должно взаимодействовать с сервером для преобразования речевых данных в текст.Как только текст преобразован и отправлен обратно на устройство, он становится исполняемым. Процесс отправки и получения поведения приложения называется поведением ответа в реальном времени. Если определенным действием является поиск, устройство отправляет серверу еще один запрос для получения результатов. В таких случаях задержка в сети может быть самой сложной задачей. Чтобы преодолеть это, разработчики должны убедиться, что исходный код приложения оптимизирован должным образом. Более того, они могут перенести функции распознавания голоса и поиска на серверную часть.
- Языки и акценты : Не все программы поддерживают все языки, и разработчикам необходимо определять регионы своей целевой аудитории, чтобы принимать стратегические решения относительно распознаваемых языков или акцентов. Акценты — это проблема языка, потому что бывает трудно определить и распознать каждый акцент и язык, связанный с ним. API Google поддерживает различные акценты и является лучшим способом заставить ваше мобильное приложение поддерживать множество различных акцентов.
- Пунктуация : Это одна из самых больших проблем, с которыми приходится сталкиваться, когда дело касается голосового программного обеспечения.К сожалению, даже самые лучшие улучшения и алгоритмы могут не работать, потому что существует практически бесконечное количество предложений с разными типами пунктуации.
Одни из лучших технологий распознавания голоса
- Baidu : Китайская технология, Baidu специализируется на услугах, связанных с Интернетом, и ИИ. Эта технология распознавания голоса представляет собой сочетание глубокого обучения, компьютерного зрения, распознавания и синтеза речи, понимания естественного языка, интеллектуального анализа данных и бизнес-аналитики.Он основан на алгоритмах глубокого обучения, которые включают обучение многослойных виртуальных сетей нейронов распознаванию закономерностей для огромных данных. Мобильное приложение Baidu позволяет пользователям выполнять голосовой поиск и поставляется с голосовым помощником Duer. Голосовые запросы более популярны в Китае, потому что ввод текста требует больше времени, а некоторые люди не знают, как использовать пиньинь.
- Siri : Функция «Привет, Siri» позволяет пользователям использовать режимы громкой связи.Siri в iOS7 работает намного лучше, чем в более ранних версиях. Siri быстрее реагирует, понимает больше и говорит естественнее. Если вы посмотрите веб-страницу или приложение, вы можете сказать: «Напомнить мне об этом», и Siri узнает, на что вы смотрите, и добавит напоминание. Вы даже можете добавить время или место, и вам больше не нужно что-то копировать / вставлять или точно описывать то, что вы хотите.
- Microsoft Cortana : Cortana — это виртуальный помощник, созданный Microsoft для нескольких продуктов.Это бесплатный цифровой помощник, который может отправлять напоминания, вести заметки и списки, решать задачи и помогать вам управлять своим календарем. Это приложение может предоставлять уведомления в зависимости от местоположения, планировать встречу, прикреплять фотографии к напоминанию и многое другое. Когда используется Office 365 или Outlook, Кортана может напоминать вам об обязательствах, изложенных в электронном письме. Как и другие помощники для смартфонов, Кортана быстро найдет ответы на ваши поисковые запросы и даже может помочь найти то, что вам нравится, например, ваш любимый ресторан, и предоставить другие подходящие рекомендации.
- Amazon Alexa : Использовать Alexa так же просто, как задать вопрос — просто попросите воспроизвести музыку, отрегулировать свет или прочитать рецепт, и он мгновенно ответит, не требуя экрана или какой-либо ручной активации. Неважно, находитесь ли вы дома или в пути, Alexa призвана упростить вашу жизнь, позволяя вашему голосу управлять вашим миром. Чем больше вы разговариваете с Alexa, тем больше она принимает ваш речевой образ, произношение и личные предпочтения. С помощью приложения Alexa вы можете позвонить или написать кому угодно, просто подключив домашнюю сеть Wi-Fi.Когда вы привыкнете к особенностям использования Alexa, вы будете чувствовать себя более естественно и отзывчиво, чем разговаривать с голосовым помощником на телефоне, таким как Siri. В конце концов, вы будете реже пользоваться телефоном, когда будете дома.
Заключение
Технология распознавания голоса действительно прошла долгий путь, и в условиях жесткой конкуренции между компаниями-разработчиками мобильных приложений, продвижение технологий распознавания голоса — это долгий путь впереди.
Добавление возможностей распознавания речи в приложение NativeScript
Распознавание речи все еще отстой?
Это не так. Посмотрите это 24-секундное видео, чтобы поверить мне на слово:
Вау, распознавание речи iOS действительно впечатляет!
Знаю, да ?! Приятно то, что он одинаково хорошо работает на Android, и ни один из них не требует внешнего SDK — в настоящее время все это встроено в мобильные операционные системы.
Убежден, давайте заменим весь ввод текста речевым!
Конечно, выбей себя! Добавьте плагин, как и любой другой, и читайте дальше:
Плагин $ tns добавить nativescript-распознавание речи
Проверка доступности
Установив плагин, давайте убедитесь, что на устройстве есть возможности распознавания речи, прежде чем пытаться его использовать (некоторые старые устройства Android могут не использовать):
проверка доступности распознавания речи nativescript.ts
Запуск 👂 и остановка 🙉 прослушивание
Теперь, когда мы убедились, что устройство поддерживает распознавание речи, мы можем начать прослушивание голосового ввода. Чтобы помочь устройству распознать, что говорит пользователь, нам нужно указать ему, на каком языке оно может ожидать. По умолчанию мы ожидаем язык устройства.
Мы также передаем обратный вызов, который вызывается всякий раз, когда устройство интерпретирует одно или несколько произнесенных слов.
Этот пример основан на предыдущем и показывает, как начать и прекратить прослушивание:
nativescript-распознавание речи-прослушивание.ts
Согласие пользователя iOS
В iOS функция startListening вызовет два запроса: один для запроса разрешения Apple на анализ голосового ввода, а другой для запроса разрешения на использование микрофона.
Содержимое этих «всплывающих окон согласия» можно изменить, добавив подобные фрагменты в app / App_Resources / iOS / Info.plist:
nativescript-распознавание речи-ios-plist.xml
Есть отзывы?
Как обычно, в комментарии можно добавлять комплименты и предложения руки и сердца. Проблемы, связанные с плагином, могут попасть в репозиторий GitHub.Наслаждайтесь!
.
Добавить комментарий