Семантическое ядро сайта – как правильно его составить и не допустить ошибок?
Что такое семантическое ядро?
Семантическое ядро – это набор поисковых фраз и слов, по которым осуществляется продвижение сайта. Эти поисковые слова и фразы помогают роботам определить тематику страницы или всего сервиса, то есть узнать, чем занимается компания.
В русском языке семантикой называется раздел науки о языке, занимающийся изучением смыслового наполнения лексических единиц языка. Применительно к поисковой оптимизации это означает, что семантическое ядро – это смысловое наполнение ресурса. Оно помогает определиться, какую информацию доносить до пользователей и в каком ключе. Поэтому семантика – это фундамент, основа всего SEO.
Для чего нужно семантическое ядро сайта и как его использовать?
- Правильное семантическое ядро необходимо, чтобы точно рассчитать стоимость продвижения.

- Семантика – это вектор построения внутренней seo-оптимизации: подбираются наиболее релевантные запросы для каждой услуги или товара, чтобы пользователи и поисковые роботы лучше их находили.
- На его основе создаются структура сайта и тексты для тематических страниц.
- Ключи из семантики используются для написания сниппетов (кратких описаний страницы).

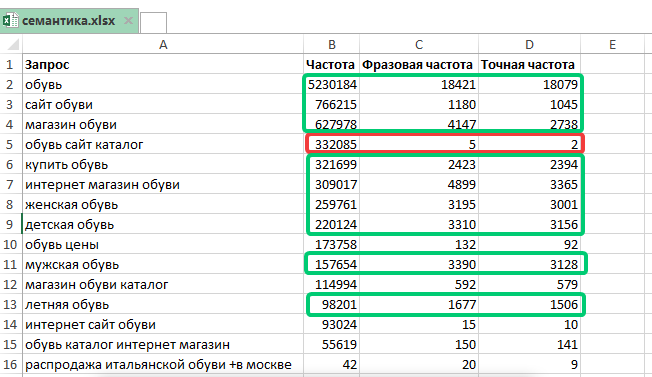
Вот семантическое ядро – пример его составления в компании SEO.RU для сайта строительной компании:
Оптимизатор собирает семантику, разбирает ее по логическим блокам, выясняет число их показов и на основе стоимости запросов в топе Яндекса и Google рассчитывает общую стоимость продвижения.
Разумеется, при подборе семантического ядра учитывается специфика работы компании: например, если бы компания не проектировала и не строила дома из клееного бруса, то соответствующие запросы мы бы удалили и не использовали в дальнейшем. Поэтому обязательный этап работы с семантикой – согласование его с заказчиком: лучше него никто не знает особенности работы компании.
Поэтому обязательный этап работы с семантикой – согласование его с заказчиком: лучше него никто не знает особенности работы компании.
Виды ключевых слов
Есть несколько параметров, по которым классифицируются ключевые запросы.
- По частотности
- высокочастотные – слова и фразы с частотой от 1000 показов в месяц;
- среднечастотные – до 1000 показов в месяц;
- низкочастотные – до 100 показов.
- По типу:
- геозависимые и негеозависимые – привязанные к региону продвижения и непривязанные;
- информационные – по ним пользователь получает какую-то информацию. Ключи такого типа обычно используются в статьях – например, обзорах или полезных советах;
- брендовые – содержат в себе название продвигаемого бренда;
- транзакционные – подразумевающие действие от пользователя (купить, скачать, заказать) и так далее.
- Другие виды – те, которые сложно отнести к какому-либо типу: допустим, ключ «профилированный брус». Вбивая такой запрос в поисковик, пользователь может подразумевать что угодно: покупку бруса, свойства, сравнения с другими материалами и прочее.
Из опыта работы нашей компании можем сказать, что по таким запросам продвигать любой сайт очень сложно – как правило, это высокочастотные и высококонкурентные, а это не только сложно в оптимизации, но и дорого для клиента.
Сбор частотности по ключевым словам помогает узнать, что чаще всего запрашивают пользователи. Но высокочастотный запрос – необязательно запрос с высокой конкурентностью, и составление семантики с высокой частотностью и низкой конкурентностью – один из главных аспектов в работе со смысловым ядром.
 Ключи такого типа обычно используются в статьях – например, обзорах или полезных советах;
Ключи такого типа обычно используются в статьях – например, обзорах или полезных советах;
Как собрать семантическое ядро для сайта?
Как собрать семантическое ядро для сайта?
Пример сбора семантики в KeyCollector
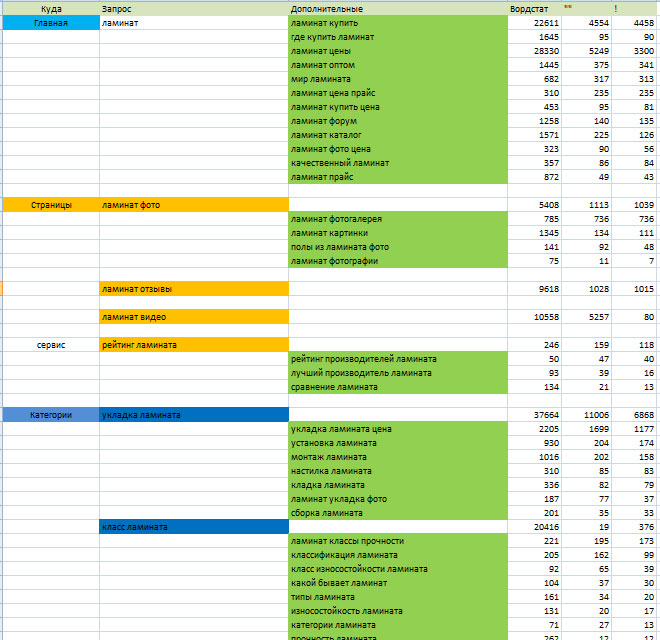
- Путем анализа сайтов-конкурентов (в SEMrush, SerpStat можно посмотреть семантическое ядро конкурентов):
Пример сбора семантики в SerpStat
Процесс составления семантического ядра
Собранные запросы – это еще не семантическое ядро, тут надо еще зерна от плевел отделить, чтобы все запросы были релевантны услугам клиента.
Чтобы составить семантическое ядро, запросы нужно кластеризовать (разбить на блоки по логике оказания услуги). Делать это можно с помощью программ (например, KeyAssort или TopSite) – особенно, если семантика объемная. Или вручную оценивать и перебирать весь список, удалять неподходящие запросы.
Затем отправить клиенту и уточнить, есть ли ошибки.
Готовое семантическое ядро – дорожка из желтого кирпича к контент-плану, к статьям в блоге, текстам для карточек товаров, новостям компании и так далее. Это таблица с потребностями аудитории, которые вы можете удовлетворить, используя свой сайт.
- Распределите ключи по страницам.
- Используйте ключевые запросы в метатегах <title>, <description>, <h> (особенно в заголовке первого уровня h2).
- Вставьте ключи в тексты для страниц. Это один из белых методов оптимизации, но тут важно не переборщить: за переспам можно попасть под фильтры поисковых систем.
- Оставшиеся поисковые запросы и те, которые не подходят ни под один раздел, сохраните под названием «О чем еще написать». В дальнейшем можно использовать их для информационных статей.
- И помните: ориентироваться надо на запросы и интересы пользователей, поэтому пытаться впихнуть все ключи в один текст бессмысленно
Сбор семантического ядра для сайта: основные ошибки
- Отказ от высококонкурентных ключей. Да, возможно, в топ по запросу «купить профилированный брус» вы не попадете (и это не помешает вам успешно продавать свои услуги), но включать в тексты его все равно нужно.
- Отказ от низкочастотки. Ошибочно это по той же причине, что и отказ от высококонкурентных запросов.
- Создание страниц под запросы и ради запросов. «Купить профилированный брус» и «заказать профилированный брус» – по сути одно и то же, разбивать их по отдельным страницам смысла нет.
- Абсолютное и безусловное доверие к софту. Без seo-программ не обойтись, но ручной анализ и проверка данных необходимы. И никакая программа пока не может оценить отрасль, уровень конкуренции и распределить ключи без ошибок.
- Ключи – наше всё. Нет, наше всё – удобный, понятный сайт и полезный контент. Ключи нужны любому тексту, но если текст плохой, то ключи не спасут.

Как собрать семантическое ядро: Пошаговая инструкция для начинающих — SEO Интеллект
Основой успешного продвижения сайта в поисковых системах, или запуска контекстной рекламы, всегда являлось правильно собранное семантическое ядро. В данной статье показан весь процесс сбора и группировки запросов.
Мы разделили работу на три основных этапа:
- Сбор вариаций написания продукта и маркеров
- Сбор и чистка семантического ядра в Key Collector
- Кластеризация (группировка) семантического ядра
Каждый этап мы разберем на примере группы товаров «Шлемы для мотоцикла», для которых и соберем семантическое ядро.
Чтение статьи займет у вас чуть больше 10 минут. Но если вы не очень любите читать, то можете потратить примерно то же время на просмотр ролика.
Этап 1: Сбор вариаций написания продукта и маркеров
Перед сбором запросов, необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекс: https://wordstat.yandex.ru/.
Методика:
- Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».
- Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.
- Переносим все найденные варианты названия продукта в отдельный файл.

- На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.
Для выявления маркеров есть два пути:
- Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
Плюс: Сбор всех существующих в спросе маркеров;
Минус: Долгий и трудозатратный процесс.
- Поиск и анализ страниц конкурентов в ТОП10, которые уже имеют страницы с нашим продуктом.
Плюс: Быстрый процесс;
Минус: Не полный сбор свойств, если они отсутствуют у конкурентов.
- Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП10. Это возможно сделать вводом основного запроса прямо в поисковую систему, или же воспользоваться инструментом полноценного поиска конкурентов, по видимости их сайтов, как было рассказано в 4 пункте, первого этапа, данной статьи:
- На странице конкурента, нужно обратить внимание на структуру категории, то есть, существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры.
- Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:
- Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы, для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в программе «Microsoft Excel». В результате получим таблицу, аналогичную представленной ниже:
- Для пакетной (разовой) загрузки всех ключевых слов в программу KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом, мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь, создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:
 Итоговый список запросов в необходимом формате:
Итоговый список запросов в необходимом формате:Этап 2: Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра, необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если Ваш магазин находится в Москве, то и запросы с их частотностью, нужно собирать по данному региону. Для этого, в нижней части окна, мы выбираем регион для сервисов: «Yandex.Wordstat» и «Яндекс Директ»:
После выбора региона можно приступать к сбору семантики.
Методика:
- В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:
- В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:
- После нажатия на кнопку в правой колонке групп, мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:
 Далее мы можем нажимать кнопку «Начать сбор»:
Далее мы можем нажимать кнопку «Начать сбор»:Запустив парсинг левой колонки «Yandex.Wordstat» мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
- Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса «Yandex.Wordstat», нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:
Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:
- Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточнённую» частотность, после чего нажимаем кнопку «Получить данные»:
- Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточнённой» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
 Мы рекомендуем удалять запросы с «Уточнённой» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Мы рекомендуем удалять запросы с «Уточнённой» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц. Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
- Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
- Инструмент фильтрации – позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
- Инструмент «Стоп-слова» — позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу, по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
- Инструмент «Анализ групп» — позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.

- Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находиться во вкладке «Данные»:
Во всплывающим окне, можно увидеть, несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице, и не случиться того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придётся искать позже, вручную, в общем списке запросов.
- Просматривая группы одну за другой, отмечаем их, или фразы внутри них, которые явно нам не подходят. В процессе, мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:
- После того, как мы отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».

После чего, следует перейти к выгрузке запросов в excel для последующей ручной чистки запросов и группировки семантики.
- Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Этап 3: Кластеризация (группировка) семантического ядра
Полученный список запросов, нам нужно разбить на кластеры, для последующей проработки посадочных страниц. Чтобы корректно выполнить эту задачу, нужно использовать сервисы кластеризации запросов, работающие на основе выдачи поисковых систем. Именно такой формат анализа, возможности продвижения тех или иных запросов на одной или разных страницах, дает 70% успеха при дальнейшем продвижении сайта.
Популярные программные продукты:
- KeyAssort – Программа для кластеризации и структуризации семантического ядра.
- Key Collector – Функционал «Анализ групп» с типом группировки «По поисковой выдаче»).
Популярные онлайн сервисы:
- Engine Seointellect – http://engine.seointellect.ru
- Tools PixelPlus – https://tools.pixelplus.ru/
- Rush Analytics – https://www.rush-analytics.ru/
Рассмотрим методику группировки запросов с помощью сервиса Engine Seointellect.
Методика:
- Полученный список запросов, который мы выгрузили из программы Key Collector, содержит столбец с названием «Группа». Нам необходимо по очереди добавлять все запросы из каждой группы в кластеризатор.
- Заходим в сервис и выбираем, в меню слева, пункт «Кластеризация запросов». В открывшимся блоке мы видим кнопку «Новая группировка».
- Нажимаем на данную кнопку. На экране появятся следующие поля для заполнения:
- Добавить запросы – в данный блок мы добавляем все запросы из первой анализируемой группы.
- Вид группировки – включает в себя три вида жесткости кластеризации:
«Hard» — жесткая группировка
«Balance» — группировка средней жесткости
«Soft» — группировка низкой жесткости

Подробнее про различие работы методов группировки можно посмотреть в данном видео:
При группировке коммерческих запросов, как в нашем случае, следует изначально выбирать метод группировки «Hard», если запросы информационные, то рекомендуем пользоваться только методом «Soft».
- Регион – выбираем соответствующий регион продвижения.
- Мой сайт – не нужно указывать, так как эта функция нужна для определения запросов по уже существующим посадочным страницам указанного сайта.

- Нажав «Запустить группировку», необходимо дождаться окончания процесса сбора данных. При завершении анализа, в правой части созданного задания, вместо отображения процесса, появиться иконка «Глаз», на которую необходимо нажать.
- Мы попадаем на страницу результата группировки, и можем проанализировать данные:
- Мы видим, что все наши запросы, кроме одного, попали в одну группу (отмечено зеленым), а значит их можно продвигать вместе на одной посадочной странице.
- Также присутствует нераспределенный запрос (отмечено синим), это значит, что по данному запросу результаты выдачи сильно отличаются от результатов других запросов. В таком случае, следует сделать вывод, что под этот запрос нужно создавать отдельную посадочную страницу бренда «Ataki».
- Справа от группы есть функционал «Показать список URL», нажав на который, откроется блок со ссылками, на страницы из ТОП10, по которым была проведена кластеризация.

- Если бы мы добавили большее количество запросов в кластеризатор, то в нераспределенных могли оказаться фразы, которые можно продвигать в готовых группах. Можно просто увидеть эти запросы и перенести в нужную группу, но если фраз много, то их следует отправить на группировку по методу «Soft». Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».
- Проведя данные действия с каждой группой из нашего файла, мы получим готовый список разделенных запросов, для последующей проработки страниц.
Финальная версия файла семантического ядра
Итоговый файл, с семантическим ядром, должен представлять собой таблицу, включающую следующие столбцы с данными:
- Запрос
- Группа
- Базовая частотность
- Уточненная частотность
- Посадочная страница
Все группы мы рекомендуем отделять чертой друг от друга, чтобы впоследствии, с таким файлом было легче работать:
Выводы:
Теперь Вы знаете на сколько трудозатратным является процесс сбора и группировки семантического ядра, для продвижения сайта или настройки контекстной рекламы.
Это лишь базовая инструкция, которая не охватывает многих нюансов, возникающих в процессе, но именно эта работа является основой успешного достижения целей продвижения, а значит выполнять ее некачественно равносильно бездействию, так как вы не добьетесь никаких результатов без «построенного фундамента».
Как правильно составить семантическое ядро?
26 Апреля 2019
SEO продвижение любого сайта начинается с правильно составленного семантического ядра. Не имеет значения продвигаете вы сайт услуг или интернет-магазин, наша статья поможет вам разобраться с тем, что такое семантическое ядро, как его правильно собрать и какие сервисы для этого можно использовать.
Содержание
Что такое семантическое ядро?
Семантическое ядро (СЯ) — перечень слов и их сочетаний, отражающих тематику и структуру сайта.
Оно также представляет собой список запросов, которые пользователи вводят в поисковую строку. Они хотят найти ресурс, который полностью решит их проблему, потратив на это минимум времени. Мы же хотим привести на сайт заинтересованных пользователей, которые совершают целевое действие: оформят покупку, оставят заявку, контактные данные и т.д. Поэтому очень важно правильно собрать ядро и оптимизировать страницы под поисковые фразы, которые приведут на сайт именно целевую аудиторию.
Они хотят найти ресурс, который полностью решит их проблему, потратив на это минимум времени. Мы же хотим привести на сайт заинтересованных пользователей, которые совершают целевое действие: оформят покупку, оставят заявку, контактные данные и т.д. Поэтому очень важно правильно собрать ядро и оптимизировать страницы под поисковые фразы, которые приведут на сайт именно целевую аудиторию.
Во время сбора семантического ядра происходит формирование списка ключевых слов и фраз. Чем больше синонимов, вариаций написания слов и терминов вы учтете, тем лучше можно будет продумать и сформировать структуру сайта, проработать контент, с учетом ключевых слов, к которому относятся заголовки страниц, описания и тексты. Таким образом, вы сможете предоставить интересную, понятную и актуальную информацию для пользователей вашего сайта.
Классификация ключевых слов
Все ключевые слова можно условно классифицировать на несколько видов, работа с каждым из которых имеет свои особенности.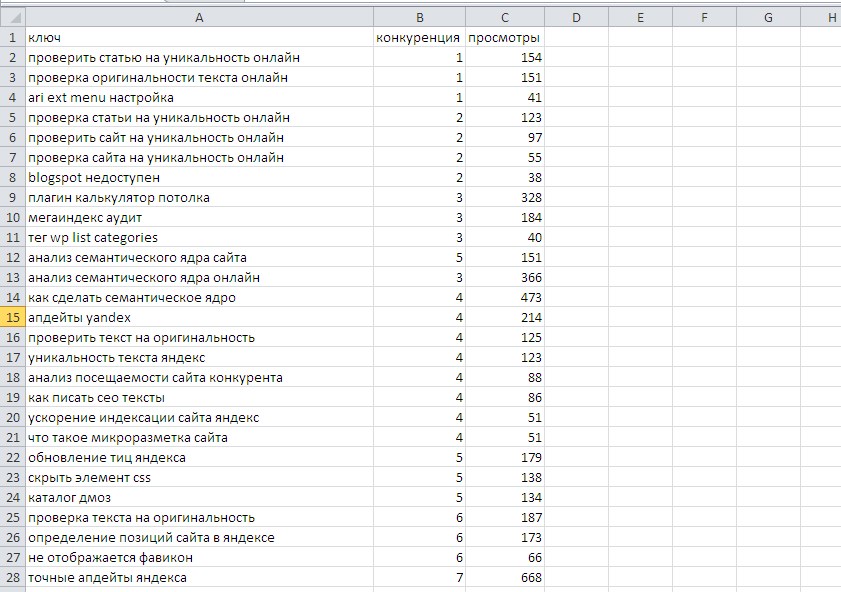 Мы рассмотрим 4 основных типа параметров, по которым разделяются поисковые фразы.
Мы рассмотрим 4 основных типа параметров, по которым разделяются поисковые фразы.
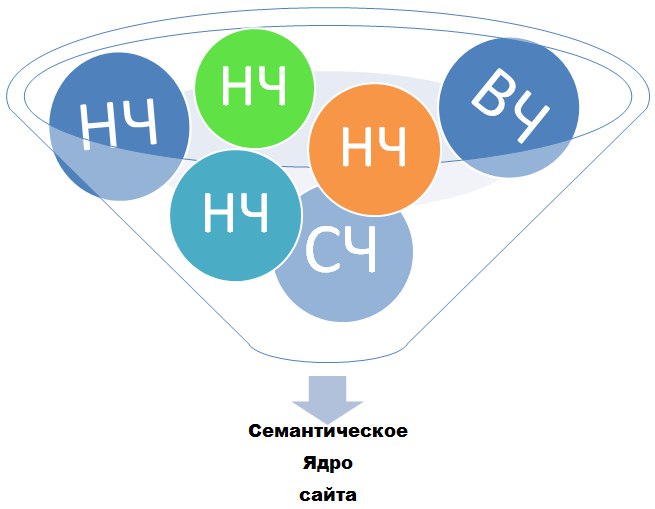
1. По частотности
- Высокочастотные (ВЧ) – фразы, описывающие общую тему. Чаще всего посадочной для них является главная страница.
- Среднечастотные (СЧ) – отдельные направления в теме. Подходят для продвижения разделов, подразделов и каталожных страниц коммерческого сайта, а также для крупных информационных статей.
- Низкочастотные (НЧ) – запросы нацеленные на поиск конкретного ответа на вопрос. Под такие фразы чаще всего оптимизируются карточки товаров или определенные статьи.
- Микронизкочастотные (МНЧ) – это фразы, которые спрашивают один раз в месяц (по данным Яндекс.Вордстат).
ВЧ запросы стоит включать в семантическое ядро в том случае, если ваш сайт уже уверенно стоит в ТОПе по низкочастотным и среднечастотным запросам.
С них часто начинается продвижение молодого сайта, у которого пока нет позиций и трафика.

Нет смысла включать такие запросы в семантическое ядро. По ним легко выйти в ТОП, но будучи на первых позициях вы не получите трафика.
2. По коммерческости
Коммерческий запрос — фраза, которую пользователь вводит в поисковую строку с целью совершить покупку (купить самокат, велопрокат прайс).
Некоммерческий запрос — фраза, с помощью которой пользователь ищет информацию без осуществления покупки (станок характеристики, микроволновка отзывы).
Семантическое ядро интернет-магазинов и прочих продающих сайтов обязательно должно включать в себя коммерческие запросы и составлять его основу. Это не значит, что нельзя включать в СЯ некоммерческие запросы: они могут вести на страницы со статьями, советами, обзорами. Однако вы должны понимать, что такие запросы не принесут продаж.
3. По геозависимости
Геозависимые — ключевые фразы, по которым результаты выдачи в поиске отличаются при смене региона. Например:
- мультфильм шрек в кино
- заказать пиццу
- ресторан морепродуктов
Если пользователь ищет «кинотеатры», находясь в Новосибирске, то ему не интересны кинотеатры в Москве, Санкт-Петербурге и других городах.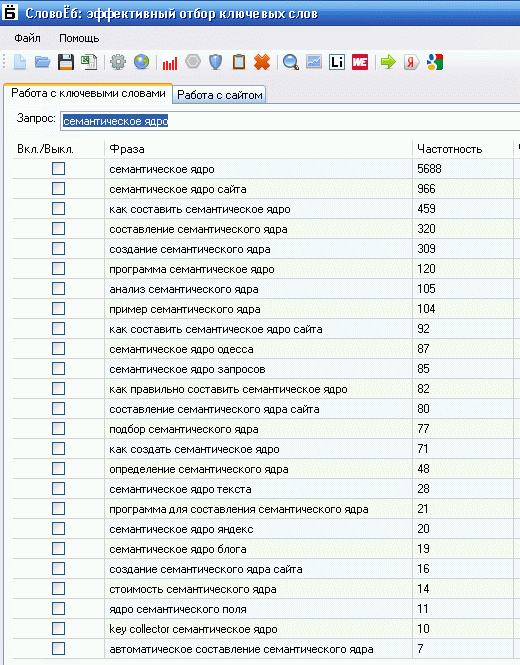
Геонезависимые — ключевые фразы, по которым результаты выдачи в поиске НЕ отличаются при смене региона. Например:
- мультфильм шрек оценки
- купить кровать в омске
- как приготовить кулич
Если в том же Новосибирске вводится запрос «кинотеатры в москве», то становится понятно, что нужны результаты по Москве, независимо от того, в каком городе пользователь находится.
По геонезависимым запросам намного тяжелее выйти в ТОП из-за большой конкуренции. Но коммерческие запросы редко бывают геонезависимыми — ведь чем ближе географически к пользователю расположена компания предлагающая услуги или товары, тем ему удобнее. Поэтому основная часть семантического ядра коммерческого сайта будет состоять из геозависимых запросов. Однако существуют исключения, все зависит от тематики сайта. Поэтому всегда проверяйте продвигаемые фразы на геозависимость.
4. По типу
- Информационные — запросы, с помощью которых осуществляется поиск полезной информации (как связать носки).
- Брендовые — запросы включающие в себя название определенной компании. Брендовыми также являются запросы с различными вариантами написания домена, в том числе на русском и с ошибками (алиэкспересс, али экспрес, ali express).
- Транзакционные — фразы, которые используют для поиска товаров и услуг с дальнейшим желанием покупки или заказа. Транзакционные аналогичны коммерческим.
- Навигационные — ключевые слова, по которым ищут какое-то место или событие (конференция сбербанк 2018).

Такие запросы можно брать в семантическое ядро, если только ваш бренд, марка или компания достаточно известны и пользователи ищут вас в сети.
По некоторым транзакционным запросам в ТОПе выдачи находится большое количество сайтов-агрегаторов. И для обычных интернет-магазинов остается 1-2 места, либо его вообще нет. Поэтому лучше подобрать более реальный запрос для продвижения.
Сервисы для составления семантического ядра
Есть большое количество онлайн сервисов, которые ускоряют и автоматизируют процесс сбора семантического ядра. Вы можете воспользоваться как платными, так и бесплатными программами. Рассмотрим несколько таких сервисов и их принцип работы.
Вы можете воспользоваться как платными, так и бесплатными программами. Рассмотрим несколько таких сервисов и их принцип работы.
Key Collector
Эта программа окажет вам непосильную помощь, если вы хотите собрать обширное ядро для большого сайта с достаточно разветвленной структурой. Список основных функций этого сервиса:
- Сбор ключевых слов через Яндекс.Вордстат.
- Парсинг подсказок поисковых систем.
- Удаление неподходящих слов с помощью стоп-слов.
- Определение базовой и точной частотности.
- Фильтрация запросов по различным показателям.
- Определение сезонности.
Сервис Key Collector платный. Все эти задачи можно выполнить и в бесплатных аналогах, но придется использовать несколько программ.
SlovoEB
Это бесплатный сервис от разработчиков Key Collector. Его основные функции — это сбор ключевиков через Wordstat, парсинг подсказок и определение частотности фраз.
Интерфейс будет достаточно понятен даже для людей, которые не имеют опыта работы с подобными сервисами. Для начала работы нужно создать новый проект, а затем на вкладке “Данные” перейти на “Добавить фразу”. Отметьте там предполагаемые фразы по которым пользователи могут найти ваш сайт, продукт или услуги на нем.
Сервис сам подберет ключевые фразы, а также поможет автоматизировать задачи для последующего анализа и очистки будущего ядра.
Wordstat Яндекса
Яндекс.Вордстат — сервис с помощью которого вы сможете бесплатно собрать и проанализировать семантическое ядро вашего сайта онлайн. Давайте немного подробнее рассмотрим функционал сервиса:
Предоставляет статистику показов в месяц по ключевому слову, а также поисковым фразам, которые включают указанное вами ключевое слово. Можно проанализировать общие данные или заострить внимание на запросах именно мобильной аудитории.
- Показывает данные по регионам
- Предоставляет историю показов фраз в динамике
- Предоставляет статистику запросов по определенным регионам
Этот сервис очень удобен для подборки ключевых фраз для семантического ядра, но дальше проводить анализ и группировать запросы придется вручную.
Системы аналитики
При сборе семантического ядра для уже существующего сайта можно воспользоваться такими системами аналитики, как Яндекс.Вебмастер, Яндекс.Метрика или Google Analytics. Там вы сможете найти с помощью каких фраз посетители находят ваш сайт и выбрать из них подходящие для продвижения.
Анализ семантического ядра конкурентов
Для сбора семантического ядра есть немного другой подход. Можно провести анализ семантического ядра конкурентов. В итоге вы получите список фраз, который можно использовать при продвижении сайта. В большинстве своем такие сервисы платные.
Принцип работы сервисов
Сервисы для анализа семантики конкурентов не имеют прямого доступа к статистике сайта. Алгоритм их работы основывается на периодическом сборе и анализе информации с поисковых систем. Информация записывается в базу и выдается пользователю инструмента по запросу. Следовательно, если база сервиса обновляется редко — есть шанс получить уже устаревшую, не актуальную и бесполезную информацию.
Megaindex Premium Analytics
Модуль «Видимость сайта» платформы Megaindex дает нам достаточно обширный набор инструментов для получения ключевых фраз конкурентов: можно посмотреть и выгрузить ключевые фразы по которым ранжируется сайт; найти схожие по семантике сайты, которые тоже могут быть использованы в качестве доноров. Сервис платный.
Keys.so
Был создан как инструмент для анализа семантики конкурентов. Необходимо ввести url интересующего нас сайта, отобрать доноров по количеству общих ключей, проанализировать их сайты и выгрузить ключи. Все делается быстро и без лишних телодвижений. Приятный, свежий интерфейс, только нужная информация.
Spywords.ru
Помимо анализа видимости предоставляет статистику по объявлениям в директе. Интерфейс немного перегружен, но если разобраться, то сервис свою задачу в целом решает. Можно проанализировать сайты конкурентов, посмотреть пересечения по семантическому ядру, выгрузить фразы по которым продвигаются конкуренты. К недостаткам можно отнести довольно слабую базу — всего 23 млн ключевых слов.
К недостаткам можно отнести довольно слабую базу — всего 23 млн ключевых слов.
Бесплатные сервисы
XTool – популярный сервис которым пользуется большое количество новичков. Он может показывать видимость сайтов в поисковых системах, их траст, а также некоторые другие данные. Количество проверок лимитировано. Стоимость каждой проверки, которая превышает этот лимит – 1 рубль.
Букварикс – бесплатно позволяет анализировать семантическое ядро чужих ресурсов, что в конечном итоге позволяет пользователям получать доступ к нужной информации, не заплатив ни копейки. Очень распространен среди фрилансеров на всевозможных биржах, т. к. даже бесплатный аккаунт позволяет пользоваться инструментом на достаточно приличном уровне.
Сбор семантического ядра пошагово
Разберем основные этапы через которые нужно пройти для составления будущего семантического ядра.
Шаг 1. Подбор основных фраз
Определитесь что именно будет продавать ваш сайт, наметьте основные разделы товаров.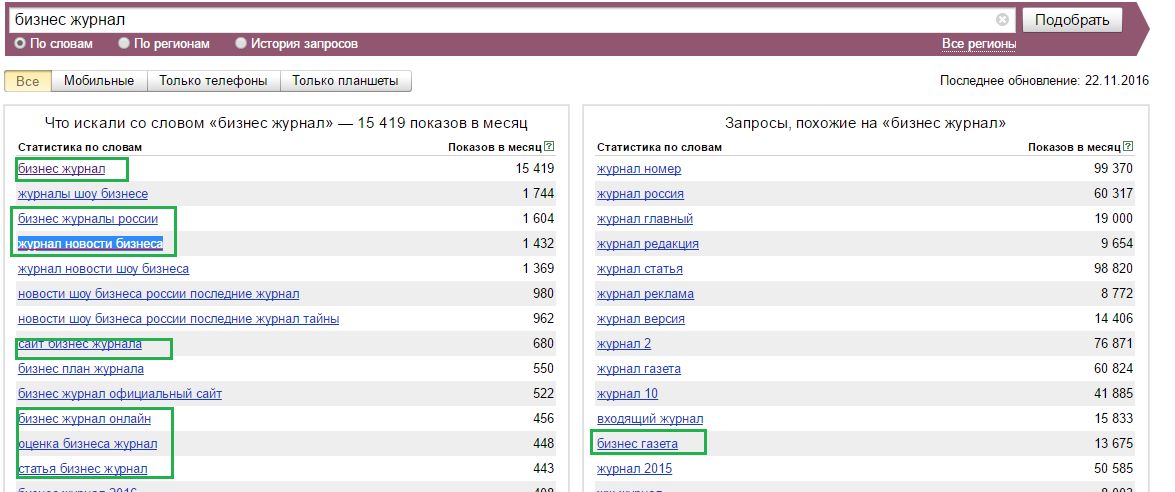
Для начала нужно собрать первичный список общих основных слов и словосочетаний, охватывающих тематику (ВЧ). Также такие запросы называются маркерами. Это могут быть названия направлений сайта (можно использовать названия разделов и подразделов).
При подборе маркерных фраз удобнее всего использовать Яндекс.Вордстат. Вбивая в него ключевую фразу, слева вы можете увидеть вариации этого словосочетания с использованием различных слов, а справа — похожие запросы, которые можно взять для дальнейшего расширения темы.
Также показывается базовая частотность фразы за месяц во всех словоформах и с добавлением любых слов. Но нам такая частотность в данный момент не нужна, ведь нас будет интересовать частота всех итоговых фраз ядра “в кавычках”, т. е. учитывается частота во всех словоформах, но без добавления дополнительных слов.
Представьте, что вы решили продвигать свой блог для сео, значит часть основных запросов будет примерно такая:
Для наглядности разберем как на каждом шагу происходит подбор фраз на основе маркерной фразы “семантическое ядро”, а для остальных тем всё можно сделать аналогично примеру.
Шаг 2. Поиск синонимов
Пользователи при написании запроса в поисковой строке могут использовать слова близкие по смыслу. Чтобы максимально охватить ядро тематики нам нужно найти все возможные синонимы и словоформы к основным словам. Для этого можно воспользоваться следующим:
- Мозговой штурм. Поставьте себя на место пользователя и подумайте какими другими словами вы могли бы сформулировать вопрос.
- Правая часть в Яндекс.Вордстат.
- Запросы сформулированные на кириллице (seo/сео, polaris/поларис).
- Аббревиатуры, сленговые фразы и различные термины, относящиеся к тематике.
- Подсказки в поисковой строке Яндекс и Google, а также фразы в блоке “Вместе с … ищут”.
После всех действий по выбранной теме получится подобный список фраз:
Шаг 3. Расширение ядра
Этот шаг удобно выполнять с помощью уже знакомого инструмента Wordstat. С помощью этого сервиса нужно провести анализ по всем фразам, которые были получены на прошлом этапе, и скопировать всё, что будет находиться в левой колонке в отдельный файл. Также иногда нужно поглядывать и на правую колонку, потому что иногда Яндекс будет предлагать вам и другие слова, которые вы могли пропустить ранее.
Также иногда нужно поглядывать и на правую колонку, потому что иногда Яндекс будет предлагать вам и другие слова, которые вы могли пропустить ранее.
В результате выполнения этого шага у вас должен получиться список фраз из Yandex.Wordstat для каждого ключа, полученного на втором этапе.
Шаг 4. Удаление лишних фраз
Этот этап для вас будет самым долгим и трудозатратным, т. к. выполняется он вручную. Нужно внимательно просмотреть каждую поисковую фразу и удалить неподходящие по смыслу.
Рассмотрим примеры запросов, которые нужно сразу убирать из будущего ядра:
- ключи с названиями брендов конкурентов;
- ключи с названиями товаров или услуг, которые вы не предоставляете и не собираетесь с ними работать в дальнейшем;
- ключи с использованием неподходящих регионов и адресов;
- фразы написанные с ошибками и опечатками.
После удаления лишних фраз получится перечень запросов для маркерного ключа “семантическое ядро”. Далее рассмотрим ещё несколько шагов, в процессе которых будут вноситься корректировки в полученный список.
Далее рассмотрим ещё несколько шагов, в процессе которых будут вноситься корректировки в полученный список.
Шаг 5. Определение точной частотности для фраз
Для массового определения точной частотности “в кавычках” нужно воспользоваться сервисами, например, Key Collector или SlovoEB. Подробнее о них мы разберем в этой статье позже.
После определения точной частотности всех фраз, нужно удалить все нулевики, т. к. такие запросы в точности никто не вводит, а значит трафик они вам не принесут.
Шаг 6. Проверка конкурентности
Здесь нужно анализировать выдачу в ТОП-10 по запросам. Обратите внимание на количество главных страниц (морд сайтов), тип контента конкурентов (статья, товар или каталожная страница), вложенность адресов страниц и их формат, а также тип сайтов конкурентов (информационные, коммерческие, агрегаторы). После анализа выдачи вы сможете понять, насколько жесткая борьба за позиции по определенному запросу и на сколько велика вероятность попадания в ТОП вашего сайта. Если становится понятным, что ваш сайт не сможет составить конкуренцию в выдаче, то такие запросы нужно убирать из ядра.
Если становится понятным, что ваш сайт не сможет составить конкуренцию в выдаче, то такие запросы нужно убирать из ядра.
После прохождения всех шагов, представленных выше, для каждой базовой поисковой фразы, вы получите готовое ядро для сайта.
Итоговый чек-лист
- Подбираем базовые запросы, которые описывают тематику. Берез за основу структуру сайта и типы предоставляемых товаров или услуг.
- Ищем синонимы ключевых слов с помощью Яндекс.Вордстат и парсинга подсказок поисковых систем.
- Расширяем ядро с помощью левой части в Wordstat.
- Очищаем список от лишних фраз.
- Определяем точную частотность для всех запросов и удаляем нулевики.
- Проверяем конкурентность запросов и проводим окончательную чистку семантического ядра.
Пример семантического ядра интернет-магазина
Здесь вы можете увидеть пример части семантического ядра интернет-магазина.
Такое представление помогает оценить всю ситуации продвижения, а также увидеть подобные проблемы:
- нет страницы, которая подходит для продвижения по данному запросу, нужно создать новую
- эффективность продвижения страниц сайта
- соответствуют ли посадочные и ранжируемые страницы
Что делать с семантическим ядром после составления?
Вы составили семантическое ядро для своего сайта, но затем возникают вопросы: “Что делать после сбора ядра?”, “Как размещать семантическое ядро на сайте?”. Давайте рассмотрим следующие шаги продвижения сайта:
Давайте рассмотрим следующие шаги продвижения сайта:
- Кластеризация запросов и распределение их по посадочным страницам. На данный момент ваше семантическое ядро является разрозненным списком фраз. Для дальнейшей работы вам необходимо провести их кластеризацию, т. е. объединить в группы по смыслу. А затем уже подобрать для каждой группы страницу продвижения (выбрать из существующих на сайте или создать новую).
- Составление оптимизированных заголовков и описаний для посадочных страниц. Используем самый высокочастотный запрос, описывающий содержимое страницы для заголовка h2. Менее частотные фразы добавляем в заголовок title и описание description с разбавлением дополнительными словами, не относящимися к тематике.
- Наполнение страницы контентом. Проанализируйте запросы, подобранные для продвигаемых страниц. Необходимо выявить потребности пользователей, которые вводят эти поисковые фразы. Какую информацию они хотят найти, перейдя на ваш сайт? Далее составляем план текста и пишем его сами, либо отправляем задание копирайтеру. Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.
 Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.
Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.
Теперь ваши посадочные страницы оптимизированы под фразы из семантического ядра.
Заключение
В этой статье мы рассмотрели все этапы по сбору качественного и полного семантического ядра для сайта, а также некоторые сервисы, которые помогут вам в этом деле. Выполняя каждый шаг в описанной выше инструкции вы сможете собрать ядро, которое будет максимально охватывать тематику вашего сайта, а это значит, что вы сможете составить правильную стратегию продвижения и быстро выбраться в ТОП выдачи поисковых систем.
как собрать самостоятельно семантическое ядро
Семантическое ядро сайта — это кластеры ключевых слов, сформированные на основании семантически релевантных групп. Другими словами, это ядро сайта (или группа ключей), которые после сбора и кластеризации распределяется по тематическим страницам сайта.
Как собрать семантическое ядро сайта? Можно ли сделать это в автоматическом режиме, или же сбор СЯ выполняется только в ручном режиме? Читайте далее нашу статью и используйте наиболее удобные для вас варианты.
Основы кластеризации и семантики сайта
Зачем нужно делать семантическое ядро сайта?
Представьте ситуацию: вы создаете онлайн-магазин по продаже электронных товаров. У вас не менее 50 категорий (ноутбуки, компьютеры, комплектующие, смартфоны, смарт-часы, периферийные устройства и т.д.).
В каждой категории — не менее нескольких сотен позиций товара. Например: смартфоны → Apple → iPhone → iPhone 8 → iPhone 8 256gb. Аналогично — со всеми другими товарами.
Аналогично — со всеми другими товарами.
Мы видим древовидную структуру, когда от категории товаров навигация переводит на конкретную модель или позицию товара.
Для каждого товара, категории или группы необходимо подобрать ключевые слова, по которым вы хотите, чтобы та или иная страница ранжировалась. И в данном случае сбор всех подходящих ключевых слов и их дальнейшая кластеризация и составляют семантическое ядро сайта.
Другими словами, семантическое ядро — это группа морфологически схожих словоформ и словосочетаний, которые наилучшим образом характеризуют страницу веб-сайта.
Как собрать семантическое ядро вручную?
Для ручного сбора семантического ядра необходимо выполнить следующие действия:
1.
 Определить центральное ключевое слово (слова)
Определить центральное ключевое слово (слова)
Центральное ключевое слово — это основа вашего будущего СЯ. Центральное КС должно отвечать следующим требованиям:
- Максимально точно характеризовать сайт в целом;
- Иметь высокую частотность;
- Быть коммерческим/информационным, в зависимости от типа сайта.
Приведем пример: ваш сайт — интернет-магазин техники. Вашими главными ключами будут: купить телефон, интернет магазин, купить ноутбук, купить смартфон и т.д.
Ключевое слово может быть не одним — их может быть несколько, в зависимости от размера сайта.
2. Определить основные группы ключевых слов
Основные группы ключевых слов — это следующий уровень после центральных ключевых слов в структуре семантического ядра.
Главные группы ключевых слов используются для категорий, разделов и прочих крупных семантических кластеров.
3. Определить ключевые слова для подгрупп и страниц
Следующим шагом необходимо собрать ключи для подгрупп и страниц, которые должны группироваться по тому же принципу, который описан выше.
Остался последний вопрос: как это всё выглядит на практике? Как собрать семантическое ядро сайта и какие инструменты нужно использовать для этого? Выглядит это всё следующим образом.
Сбор СЯ с помощью Планировщика ключевых слов Google
Перейдите в Google Keyword Planner (планировщик ключевых слов) и перейдите по внутренней ссылке.
Выберите меню с поиском ключевых слов:
Выберите категории и основные ключевые слова, которые наилучшим образом характеризуют ваш сайт.
Выберите локацию и нажмите кнопку “Получить варианты”.
Перейдите во вкладку “Варианты КС”…
…и выгрузите ключевые слова в документ:
Далее вы можете отсортировать ключевые слова по конкурентности, частотности и другим параметрам.
Аналогичным образом семантическое ядро собирается для каждой группы семантически релевантных запросов.
Что делать, если все ключевые слова относятся к разным категориям?
В таком случае возможны два варианта:
1. Ручная группировка запросов. Хороший метод, когда у вас не более 100 ключевых слов. Если же у вас тысячи ключей, группировка запросов может занять недели.
2. Автоматическая группировка (кластеризация). Выполняется с помощью SpySERP. Для этого необходимо зарегистрироваться на сайте, выбрать раздел “Кластеризация”, после чего все ваши ключевые слова автоматически сгруппируются по семантически релевантным кластерам.
Семантическое ядро сайта онлайн: сервисы для автоматического сбора
Итак, вы не хотите использовать планировщик ключевых слов по каким-либо причинам. Как собрать семантическое ядро другими способами?
Вы можете собрать семантическое ядро сайта онлайн — специально для этого существует ряд сервисов, которые помогут справиться с задачей не хуже, чем ПКС от Google или Яндекс Вордстат.
Key Collector
Программа для комплексной работы с семантическим ядром сайта. Позволяет выполнять все возможные операции, начиная от сбора ключей и заканчивая чисткой полученного списка.
Сервис платный — лицензия на использование стоит $50.
Ahrefs Keyword Explorer
Если вам нужно быстро и просто собрать ключевые слова, вы можете воспользоваться функционалом Ahrefs. Месячная подписка стоит $99, однако если и триал-версия на неделю стоимостью $7 — такого триала вам должно более чем хватить для решения задач небольшого объема.
Semrush
Наконец, для сбора семантического ядра вы можете воспользоваться Semrush — ещё одним онлайн-сервисом, который работает по принципу, описанному выше. В бесплатной версии вы можете собрать до 10 фраз в широком и фразовом соответствии, с учетом региона запросов.
В бесплатной версии вы можете собрать до 10 фраз в широком и фразовом соответствии, с учетом региона запросов.
Семантическое ядро — это “скелет” сайта и его основа, которая в дальнейшем послужит вам базисом для развития стратегии продвижения. Именно поэтому процессу сбора ядра необходимо уделять особое внимание и мы надеемся, что информация, описанная в статье, поможет вам сделать это максимально быстро и качественно.
Как составить семантическое ядро сайта
3124 Посещений
Прежде чем переходить к составлению семантического ядра, необходимо ознакомиться с видами поисковых запросов. Условно их можно разделить на три группы:
- Высокочастотные запросы (ВЧ).
- Среднечастотные запросы (CЧ).
- Низкочастотные запросы (НЧ).

В зависимости от того, как часто пользователь обращаются к тому или иному запросу, он “отравляется” в соответствующую группу. Подчеркнем, что речь идет об условных границах, разделяющих виды запроса, поскольку данный нюанс зависит от направленности веб-портала.
Помимо частотности существует еще один параметр — конкурентность запроса. Здесь имеется ввиду, насколько сложно буде продвинуться в ТОП выдачи поисковиков по тому или иному запросу. Существую следующие виды конкурентности запрсов:
- Высококонкурентные запросы (ВК).
- Среднеконкурентные запросы (СК).
- Низкоконкурентные запросы (НК).
При этом определить конкурентоность запросов сложнее, нежели их частотность. Кроме того, запросы бывают первичные (общая характеристика веб-портала), основные (составляют основу семантического ядра) и вспомогательные (близкие по духу запросы). Теперб, когда с терминологией мы разобрались, перейдем к пошаговому составлению семантического ядра.
Составление семантического ядра
В первую очередь выберите все возможные поисковые запросы, максимально охватывающие тематику вашего веб-портала. Для подбора поисковых запросов существуют специальные сервисы.
Второй шаг — отказ от лишних слов. Удалите запросы, которые подходят вам наименее. Не удивляйтесь, если на этом обычно этапе отсеивается порядка половины выбранных ключей.
Третий шаг — отсеивание запросов, по которым веб-портал вряд ли продвинется из-за высокой конкуренции.
Четвертый шаг — распределение оставшихся запросов по страницам сайта. Более конкурентные запросы “отдайте” главной странице и страницам, имеющим большой статический вес (внутренняя перелинковка и ссылки с других сайтов).
Ошибки, которых стоит избегать при составлении семантического ядра
Велика вероятность, что при составлении семантического ядра, вы включите в него слишком обобщающие фразы или же, наоборот, чересчур “узкие”. Не проконтролировав этот момент вы рискуете ухудшить пользовательские факторы и снизить рост посещаемости.
Как бы странно это ни звучало, но в семантическом ядре должны содержаться запросы с грамматическими ошибками (к примеру, пользователь ищет “котедж”, а не “коттедж”).
Не нужно злоупотреблять поисковыми запросами, если вы имеете дело с небольшим текстом. Кроме того, старайтесь включить в свой список ряд ассоциативных запросов. Так вы сделаете свои тексты более привлекательными для поисковиков.
Сервисы для составления семантического ядра
Рассмотрим основные онлайн-платформы, используемые для составления семантического ядра:
- Google.Adwords. Простой и понятный сервис для поиска ключевых запросов. Перейдите на страницу “Планировщик ключевых слов” и приступайте к работе. Обратите внимание на то, что на этой же страницы вы найдете полное руководство по работе с Google.Adwords:
- Яндекс.Вордстат. Платформа, напоминает Google.Adwords. На странице выводятся как основные, как и вспомогательные запросы. Для того, чтобы получить список ключей, просто введите интересующий вас запрос:
Составление семантического ядра — пошаговая инструкция
Один из этапов создания рекламной кампании — сбор семантического ядра. Оно включает в себя ключевые фразы пользователей, по которым будут показываться рекламные объявления. Релевантные ключевые слова и правильно написанный оффер — отличная возможность показать объявления целевой аудитории, привлечь клиентов и сэкономить бюджет. Как это сделать, читайте в инструкции по составлению семантического ядра от eLama.
Семантическое ядро для поисковых кампаний
1 этап. Сбор базовых ключевых слов
Прежде всего подумайте, какие слова характеризуют вашу нишу. Например, для интернет-магазина по продаже iPhone будут очевидны следующие слова: iPhone, айфон, купить, заказать и т. д. Для удобства записывайте слова в таблицу Excel.
Если у вас закончились идеи, то зайдите в yandex.wordstat.ru и посмотрите, что ищут при вводе, например, iPhone.
К собранному в Excel списку добавим слово «Цена».
Далее, найденные слова нужно скомпоновать. Это можно сделать через инструмент eLama «Комбинатор ключевых фраз»:
Полученные фразы мы будем использовать на следующем этапе.
Этап 2. Подбор семантического ядра
Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра.
Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее:
Итак, получился список и одна свободная колонка, которая нужна для списка минус-слов.
Этап 3. Чистка семантического ядра
Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы.
Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel.
Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов».
По сравнению с Wordstat он имеет больше функций, благодаря которым можно:
- узнать конкурентность ниши и процент показа объявлений;
- минимальные/максимальные ставки для показа объявлений внизу/вверху страницы.
В списке могут появиться фразы с минимальным различием, например, «iphone 8 в москве» и «iphone 8 купить спб». Для того, чтобы система показывала объявления, релевантные запросу, нужно провести кросс-минусацию, например, через eLama.
Для получения более точного результата попробуйте комбинировать все инструменты.
Этап 4. Заключительный
Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость.
Операторы и типы соответствия ключевых слов в Яндекс.Директе и Google Ads
Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление.
Для экономии времени используйте «Комбинатор ключевых фраз», который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор:
Если нужны типы соответствия/операторы, которых нет в «Комбинаторе ключевых фраз», то используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом. Полный список операторов Яндекс.Директа есть на странице помощи, а для типов соответствия Google Ads — здесь.
Подбор ключевых слов для КМС и РСЯ
Ключевые фразы для РСЯ и КМС не нужно уточнять. Достаточно создать семантическое ядро с широкими ключевыми фразами, которые взаимосвязаны между собой. Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, то воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ.
Заключение
Сбор семантики — интересный, но в то же время сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.
Хотите быть в курсе всех топовых digital-мероприятий?
Кликайте на изображение и подписывайтесь на нашу афишу!
Читать онлайн «Как составить семантическое ядро для сайта» — автор Сервис 1ps.ru
Введение
Пробиться в поисковой выдаче наверх и удержаться там — во все времена было целью владельцев сайтов, которые не собирались ограничиваться минимальным заработком и плохими результатами в ТОП-е.
Для того чтобы занять «место под солнцем», а именно улучшить позиции вашего интернет-ресурса, необходимо провести целый комплекс мер по его оптимизации и продвижению.
Если СЯ составлено некорректно, сколько бы средств вы ни тратили, желаемого успеха вряд ли добьетесь.
1. Составление семантического ядра
Семантическое ядро (СЯ) — это база поисковых слов, словосочетаний и морфологических форм, наиболее точно характеризующих вид деятельности, товары и услуги, которые предлагает сайт.
Как уже было сказано ранее, СЯ — это основа работы каждого seo-специалиста, фундамент в успешном поисковом продвижении сайта. Без подбора ключевых слов цели не будут достигнуты, будь то продажа товаров или услуг, предложение и реализация инфопродуктов или просто монетизация для получения прибыли за счёт рекламы.
Если семантическое ядро сайта составлено неправильно, посетителей из поисковых систем ждать не стоит. Они просто не найдут ваш интернет-ресурс, так как его не будет в приоритетной зоне выдачи по актуальным тематике сайта запросам.
Следовательно, отнестись к процессу составления СЯ следует очень серьёзно, ведь от этого зависит судьба вашего проекта!
1.1. Факторы, учитываемые при составлении СЯ
Подробнее о том, как правильно подбирать ключевые слова с учетом данных факторов мы поговорим в главе «1.2. Стратегия составления СЯ», поэтому если вы знакомы с основной терминологией (или просто станет скучно читать) — переходите к следующей главе.)
Перечислим основные факторы, которые вам нужно будет учитывать при подборе ключевых слов для продвижения сайта:
Количество показов или частотность.
По частоте и количеству показов все запросы можно поделить на высокочастотные, низкочастотные и среднечастотные.
Высокочастотные (ВЧ) — наиболее популярные поисковые фразы, которые часто ищут пользователи в сети Интернет. Частота такого запроса более 10 000 показов в месяц. Например, «ремонт квартир» — 484 110 показов в месяц по данным Yandex. Wordstat.
Ввиду большой востребованности продвижение по ВЧ считается наиболее финансово затратным, сложным и трудоёмким, при этом не всегда оправданным.
Среднечастотные (СЧ) — запросы, имеющие относительную популярность. Их нельзя отнести ни к ВЧ, ни к НЧ. Частота показов колеблется от 1000 до 10 000 в месяц. Например, «ремонт квартир в Иркутске» — 1342 показа в месяц по данным Yandex. Wordstat. Использование таких слов является самым популярным и оптимальным методом SEO продвижения.
Низкочастотные (НЧ) — тип ключевых слов, который запрашивается реже всего. Частота менее 1000. Например, «быстрый ремонт квартир» — 432 показа в месяц по данным Yandex. Wordstat. Несмотря на минимальную востребованность запроса, продвижение по НЧ достаточно эффективно.
Правильным шагом в начале раскрутки молодого сайта является наполнение интернет-ресурса контентом с низкочастотниками. Так, вы сможете заслужить доверие поисковиков (получить траст), что поможет в дальнейшем продвижении.
Чистый спрос — количество показов запроса без словосочетаний, в которые он входит.
Например, в количество показов запроса «обогреватели» входят все прочие запросы с этим словом: «инфракрасные обогреватели», «газовые обогреватели» и т. п. Важно учесть частоту именно основного запроса без учета других запросов, т. е. чистый спрос без шлейфа. Подробнее о том, как это сделать, разберем в следующей главе.
Количество показов без использования морфологических форм.
Следует учитывать морфологию запроса (склонение, спряжение и прочее) — т. е. сколько людей ищет именно словосочетание «ремонт квартиры», а не «услуги по ремонту квартиры».
Наличие релевантных поисковым запросам страницы.
Нужно не просто подбирать запросы, а подбирать так, чтобы ваш сайт был лучшим ответом на этот запрос. Т. е. если в интернет-магазине музыкальных инструментов фото гитар есть только в разделе каталог товаров, то не стоит использовать запрос «фото электрогитары».
Конкурентность запроса.
Чтобы определить, сколько денег потребуется для продвижения, необходимо оценивать конкуренцию по запросу, особенно, если ваш бюджет ограничен. По конкуренции запросы можно поделить на высококонкурентные, среднеконкурентные и низкоконкурентные.
Высококонкурентные запросы (ВК) — запросы, по которым в поисковой выдаче находится много оптимизированных под них сайтов. Например: «купить мультиварку».
Среднеконкурентные (СК) — запросы, характеризующиеся неплохим количеством трафика и средней конкуренцией. Продвижение такого запроса потребует меньших финансовых вложений, чем при раскрутке ВК, Например: «купить мультиварку в Минске».
Низкоконкурентные (НК) — ключевые запросы, не обладающие популярностью. Используя такой запрос попасть в ТОП можно только за счёт внутренних факторов оптимизации. Например: «купить мультиварку редмонд в Минске».
Что такое семантическое ядро (ядро запросов) для веб-сайта?
Администратор
Продвижение любого сайта в поисковый трафик всегда начинается с формирования семантического ядра. А что такое семантическое ядро, зачем оно нужно и зачем придумали такое сложное понятие, вы узнаете из этой статьи. И поверьте, после нашей статьи концепция станет намного проще.
Итак, начнем, семантическое ядро - это список всех запросов и ключевых слов, по которым пользователь может найти ваш сайт.Именно поэтому семантическое ядро служит основой для создания структуры и даже отдельных страниц самого сайта. Вы хотите, чтобы сайт находился в ТОПе выдачи поисковых систем, значит вы пришли по адресу.
Основные задачи формирования семантического ядра:
1. Определяет тематику ресурса;
2. Это основа для формирования структуры сайта;
3. Участвует в раздаче страниц в поисковых системах;
4.Отвечает на запросы пользователей.
Чтобы продвижение сайта принесло свои плоды, необходимо сформировать семантическое ядро - составить все ключевые слова, относящиеся к тематике сайта, причем разделенные по смысловой группе. Кстати, такое понятие как семантика используется не только при создании сайта, но и непосредственно при запуске рекламной кампании. Они формируют семантическое ядро как вручную, так и с помощью различных сервисов.
Подбирают ключевые слова (ключевые слова) путем анализа товаров и услуг, представленных на сайте, а также отслеживают семантическое ядро конкурентов.При этом особое внимание уделяется именно статистике использования поисковых запросов в зависимости от сезонов. Основная задача — создать на сайте страницы, максимально подходящие под все запросы и отвечающие запросам целевой аудитории.
Формирование семантического ядра делится на следующие этапы:
— набор ключевых слов, которые подробно описывают содержание сайта в зависимости от его тематики и назначения;
— разделение собранных ключевых слов на разделы / подразделы проекта;
— адаптация всех страниц по группам собранных ключевых слов.
При подборе ключевых слов их следует разделить на коммерческие и некоммерческие, для сервисных сайтов и интернет-магазинов.
Коммерческие запросы включают в себя все слова и фразы, используемые целевой аудиторией. Часто используются такие слова, как: «цена», «стоимость», «покупка», «заказ» и т. Д.
Слова и фразы, которые пользователи вводят, когда хотят найти определенную информацию, относятся к запросам некоммерческих организаций. Возможно, такие запросы с меньшей вероятностью приведут к целевой аудитории сайта, но среди этих посетителей могут быть потенциальные клиенты.
Одним из важных критериев группировки ключевых слов является их частота. Частота — это количество запросов, полученных за определенный период. Есть вопросы, которые можно задать один раз, а другие задают тысячу раз в неделю.
По частоте встречаются такие типы запросов:
высокочастотные (от 1000 показов) — это те типы запросов, которые наиболее часто используются при поиске сайтов определенной тематики, по ним наблюдается наибольшая конкуренция на рынке;
среднечастотных (до 1000 показов) — ключевые слова, которые не так популярны, как высокочастотные, но в то же время пользуются спросом;
низкочастотные (67-79% всех требований поиска) — такие ключевые слова часто состоят из нескольких слов и используются реже.Но в таких запросах есть заслуга — упрощенное продвижение в ТОП, а также возможность привлечь на сайт целевую аудиторию.
Как сформировать семантическое ядро?
1. Собрать семантическое ядро можно с помощью сервисов поисковых систем;
2. Для каждого раздела вашего сайта нужно записать слова и фразы с названиями товаров, услуг, основными характеристиками товара и т. Д.
3. Собрать и применить ключевые слова конкурентов
Вы можете построить семантическое ядро с помощью следующих программ:
1.Google Analytics https://marketingplatform.google.com/about/analytics/
2. Яндекс.Метрика http://metrika.yandex.ru/
3. Яндекс.Wordstat http://wordstat.yandex.ru/
4. Планировщик ключевых слов от Google https://adwords.google.com/select/KeywordToolExternal
5. SpyWords https://spywords.ru/
6.Коллекционер ключей http://www.key-collector.ru/
Далее в статье мы подробнее остановимся на одном из популярных ресурсов Яндекс.Wordstat.
Чтобы было понятнее, как пользоваться ресурсом, ниже приведен пример семантического ядра, скомпилированного в Яндекс.Wordstat. Чтобы лучше понять основные принципы формирования семантики, рассмотрим подбор ключевых слов для интернет-магазина по продаже кошельков. Для начала необходимо определить, по каким запросам посетители будут искать данные сайта.В нашем случае очевидным запросом будет слово «кошелек». Открываем сервис Яндекс.Wordstat, вводим наше слово в строку поиска, чтобы получить информацию о нашем запросе и дополнительную информацию:
Мы рекомендуем использовать расширение Google Yandex Wordstat Helper для удобства сбора ключевых слов. Это расширение позволяет выбрать из полученных данных необходимые ключевые слова для формирования семантического ядра, нажав на плюс:
После успешного добавления всех ключевых слов их можно перенести в файл Excel.При обычном вводе ключевого слова без служебных символов мы сможем видеть статистику по всем запросам в любой форме. Есть способ узнать точную частоту запросов в месяц по этому конкретному ключевому слову, для этого нужно его процитировать и поставить перед ключом восклицательный знак:
Чтобы узнать частоту фразы, берем кавычки, кстати этот показатель бывает в сотни, а то и в тысячи раз меньше базовой частоты:
Эта информация поможет вам найти самые популярные запросы, а также поможет найти редкие цепочки для ключей с высокой общей частотой.Именно на основе этих данных составляется структура сайта.
Другие службы также помогут вам собрать все данные, необходимые для успешной настройки вашего сайта.
В результате мы рекомендуем вам уделять особое внимание низкочастотным ключевым словам, если они, конечно, имеют отношение к вашей теме. Такие клавиатуры часто приводят к активным посетителям сайта.
После того, как вы сформировали семантическое ядро, приступайте к настройке сайта, наполняйте его ключами.Только не переусердствуйте, текст должен отвечать на поисковый запрос пользователя. Удачи вам в этом деле!
Если вдруг у вас нет возможности самостоятельно сформировать семантическое ядро, вы можете связаться с нами, и они вам помогут!
Разработка семантического ядра — цифровые коммуникации активов
Разработка семантического ядра ключевых слов SEO для вашего веб-сайта — это отправная точка для внутреннего SEO. Вы, вероятно, слышали много разговоров о ключевых словах, длинных ключевых словах и стратегии ключевых слов как основополагающих для стратегии поисковой оптимизации.
При разработке вашей стратегии SEO, и в частности оптимизации вашего веб-сайта на странице, мы начинаем со сбора семантического ядра. Семантическое ядро - это часто встречающиеся, качественные слова и фразы, которые наиболее точно описывают то, что вы делаете. Ядро — это список, предназначенный для привлечения вашей целевой аудитории на ваш сайт.
Когда мы называем их ключевыми словами, это значение связано с пониманием объема поиска, генерируемого ключевыми словами, и последующим выбором наиболее подходящих вариантов. Поскольку только время покажет, насколько вы успешны, ключевые слова и стратегия регулярно измеряются с течением времени.
Какое ключевое слово является эффективным для вашего бизнеса?
С точки зрения SEO, эффективное ключевое слово — это ключевое слово, по которому ваш бизнес может ранжироваться, релевантное для вашего бизнеса и имеющее большой объем органического трафика. По мере того, как вы улучшаете свою позицию в рейтинге для этого ключевого слова, вы увидите увеличение объема органического трафика на ваш веб-сайт, связанное с улучшением рейтинга.
Как только вы это поймете, вы сможете разработать свой план дальнейших действий по SEO, включая планирование контента, оптимизацию и структурирование, размещение веб-сайта на странице и т. Д.
Разработка семантического ядра для вашего веб-сайта
Ключевые слова, которые являются основой, которая позволит вашему веб-сайту утвердиться в качестве авторитета и лидера в вашем секторе. Эта работа ведется в конкурентной среде. И поэтому при разработке семантического кода для вашего веб-сайта необходимо учитывать ваших конкурентов.
Когда люди ищут ваши продукты или услуги в Интернете, они используют множество различных поисковых запросов.Первый шаг — понять, что это за условия поиска или популярные ключевые слова. Семантическое ядро - это те условия поиска или ключевые слова, которые позволят этим пользователям найти вас.
Ваши шаги по определению семантического ядра
- Используйте Google Analytics, Google Search Console или другой инструмент для определения наиболее частых запросов (условий поиска) на ваших веб-сайтах
- Проведите тот же анализ на веб-сайтах ваших конкурентов
- Составьте список этих запросов, содержащий ключевые слова и их синонимы
- Удалите бессмысленные ключевые слова
- Сгруппируйте ключевые слова по категориям
- Установите приоритет ключевых слов на основе каждой страницы вашего веб-сайта
- Организуйте страницы вашего веб-сайта в соответствии с целевыми страницами в структура сайта
- Эта работа должна учитывать рейтинг ваших конкурентов по ключевым словам.
Используйте онлайн-инструменты для исследования
Создание списка ключевых слов, выбор ключевых слов и создание семантического ядра требуют много времени. В этой работе используются как бесплатные, так и платные инструменты. Мы поделимся с вами некоторыми из тех, которые считаем важными.
Бесплатные инструменты SEO:
- Google Analytics — это важный набор инструментов, необходимых для анализа данных для вашего бизнеса, предоставляемый Google бесплатно.
- Search Console — Google предоставляет набор бесплатных инструментов и отчетов для измерения поискового трафика и эффективности вашего сайта, устранения проблем и повышения эффективности вашего сайта в результатах поиска.
- Планировщик ключевых слов — Еще один бесплатный инструмент от Google. Используется для исследования ключевых слов SEO, оптимизации контента и идей по темам.
- Плагин Yoast SEO для вашего веб-сайта. Yoast SEO — один из самых популярных плагинов WordPress. Это мощный инструмент, позволяющий сделать ваш сайт максимально удобным для поисковых систем.
- Google Page Insights — PageSpeed Insights (PSI) сообщает об эффективности страницы как на мобильных, так и на настольных устройствах, а также предоставляет предложения о том, как эта страница может быть улучшен.
Самые популярные инструменты:
- Semrush — Saas-компания (программное обеспечение как услуга), предоставляющая по подписке программное обеспечение для видимости и аналитики, которое поможет вам повысить вашу онлайн-конкурентоспособность.
- MOZ — Saas (программное обеспечение как услуга) компания, которая предоставляет подписки на программное обеспечение для входящего маркетинга и маркетинговой аналитики.
- Ahrefs — Saas (программное обеспечение как услуга) компания, которая предоставляет инструменты аудита сайта на основе подписки для анализа веб-сайтов на предмет распространенных проблем с поисковой оптимизацией и отслеживания состояния вашего SEO с течением времени.
Мы надеемся, что это руководство по развитию вашего семантического ядра окажется полезным. Поскольку сегодня поисковая оптимизация сложна и динамична, компании нанимают для этой работы SEO-агентства.
Как владельцу бизнеса вам не нужно становиться экспертом в области SEO, однако понимание рычагов, управляющих стратегией SEO, позволит вам лучше понять работу, которую ваше агентство SEO выполняет от вашего имени.
Ключевые слова SEO или семантическое ядро
Мы рады представить всем нашим клиентам и не только — результат нашей многолетней работы — новые онлайн-сервисы
Даем каждому по 150 $ на сбор любой семантики условий акции на официальном сервисе.Просто зарегистрируйтесь по ссылке .
Создание семантического ядра или seo-ключа с помощью WebCoreLab включает онлайн-сервисы сбора и группировки семантических запросов. Мы можем получить мета-ключевые слова с сотен веб-сайтов для использования в текстовом маркетинге.
Теперь продвигать сайты стало проще : просто воспользуйтесь нашими техническими условиями для написания контента (текстов) для своих сайтов. Вам не нужно быть профессиональным редактором или SEO-специалистом, просто возьмите техническое задание и с его помощью раскройте тему.И как только материал попадет в индекс Google, вы начнете получать тысячи, а может и десятки тысяч уникальных посетителей.
Мы занимаемся только ручным сбором семантического ядра и используем профессиональные семантические инструменты на основе нейронных сетей с привлечением семантических экспертов в конкретной сфере бизнеса клиента!
Почему выбирают нас:
- 10 лет на рынке.
- Обширный опыт работы в индустрии семантического ядра и построения профессиональной архитектуры сайта.
- Собственные сервисы по сбору и кластеризации семантических ядер под управлением нейронных сетей
- Собственные автоматические сервисы по формированию ТЗ на копирайтеров
- Вы платите только за результат.
- Вы можете контролировать и управлять всем процессом сбора и кластеризации семантического ядра в нашей уникальной системе.
- Онлайн-поддержка 24 \ 7 — в личном кабинете, индивидуальный чат на сайте, а также поддержка по телефону.
- Перед тем, как начать пользоваться сервисом, вы можете попробовать его бесплатно: https://home.webcorelab.com/test
- Любые способы оплаты — Visa, Mastercard, Pay Pal, Payoneer, банковский перевод.
Наши технические характеристики основаны на ключах LSI и 27 метриках префикса.
Мы готовим технические спецификации с использованием LSI Keywords.
Для более полного и качественного сбора ключевых слов бизнес-аккаунты используются в таких сервисах, как semrush.com, serpstat.com, советы Google, Moz, Google Реклама, Google Trends. Мы также используем наши собственные ключевые базы данных (900 миллионов в США и 4,2 миллиарда во всех других регионах).
Почему работать с нами выгодно и безопасно:
- Вы платите за семантическое ядро только в любом количестве и качестве, которое вы выберете, то есть платите только за одобренные вами ключевые слова и не более
- Фиксированная плата за готовое разгруппированное ключевое слово составляет всего 0 долларов.35 и без скрытых комиссий
- Бесплатные тестовые системы перед запуском
- Чтобы начать и получить результат через четыре дня, достаточно нескольких минут.
Начать сбор в 2 этапа:
Просто заполните бриф и внесите фиксированный залог в размере 150 долларов (на брифе должна быть кнопка)
После того, как мы сделаем за вас всю работу, вы сможете наблюдать и контролировать весь процесс сбора семантического ядра в личном кабинете сервиса.
Все работы проходят в несколько этапов:
- Перед тем, как приступить к любому проекту, мы детально выясняем сферу бизнеса, в которой работает клиент, и особенности его бизнеса. Первичный анализ бизнес-сферы занимает от 2-х дней, после чего к клиенту назначается профильный специалист, который ведет его до конца проекта.
Для выполнения этого анализа нам понадобится введение от клиента, которое клиент должен заполнить, после анализа деловой сферы вам может потребоваться личный контакт через мессенджеры или по телефону.
По завершении анализа клиент получит отдельный отчет «Competitive Intelligence».
- Второй этап — это первичный парсинг всей бизнес-сферы.
Сканируем всех ТОП конкурентов с детальным анализом качества ресурса в сфере бизнеса.
- Третий этап — это первичная чистка ядра, согласование окончательного списка ключевых слов для последующей группировки и подготовка технического задания для копирайтеров.
- Четвертый этап — согласование ключей для группировки; На этом этапе клиент выбирает оптимальное количество и качество ключевых слов для последней версии семантического ядра. Необязательно просматривать весь список ключевых запросов, достаточно указать нам направление, остальную работу мы сделаем за вас.
- Пятый этап — ручная группировка ключевых слов с учетом вводного клиента.На этом этапе мы окончательно согласовываем с клиентом окончательный список ключевых слов.
- Шестой этап — формирование технического задания на копирайтеров с учетом LSI. Каждое Техническое задание представляет собой отдельный документ с определенным набором ключей LSI для Заголовка — h2 — Body и оптимальной длиной текста в символах.
Нравится:
Нравится Загрузка …
(PDF) Выбор службы семантической паутины на уровне процесса: пример из практики eBay / Amazon / PayPal
отдельные рассуждения о процессах и рассуждения о он-
тологиях.В подходе, реализованном в
WSMO, процессы
представлены как абстрактные конечные автоматы, хорошо известный
и общий формализм для представления динамического поведения. Идея
, лежащая в основе
WSMO, заключается в том, что все переменные машин абстрактного состояния
определяются с помощью терминов онтологического языка
WSMO —
. Вместо этого наши процессы работают с собственными переменными состояния
, некоторые из которых могут быть отображены на отдельный тологический язык
, что позволяет применять минималистичный и практичный подход к семантическим аннотациям и эффективно обнаруживать
. , выбрать или создать службы автоматически.
Действительно, цель работы над
WSMO состоит в том, чтобы предложить общий язык и механизм представления для семантических
веб-сервисов, в то время как мы сосредоточимся на практической проблеме
, обеспечивающей эффективные методы выбора и составления
семантических веб-сервисов автоматически. Было бы интересно исследовать, как наш подход может быть применен к
WSMO
абстрактным конечным машинам, а не к процессам BPEL, и
, как идея минималистских семантических аннотаций может быть расширена с
, как правило, работать с остальная часть структуры
WSMO.Эта задача
входит в нашу программу исследований. В [2] автор предлагает
комбинацию SHIQ (D) DL и μ-исчисления. В нашем подходе
мы используем CTL для выражения временных характеристик.
CTL относится к μ-исчислению в соответствии с минималистской
природой нашего подхода.
Ссылки
[1] Структура моделирования веб-сервисов —
http://www.wsmo.org/.
[2] С. Агарвал. Язык задания целей для автоматического обнаружения и составления веб-сервисов
.In International
Conference on Web Intelligence (WI ’07), Silicon Valley,
USA, NOV 2007.
[3] Т. Эндрюс, Ф. Курбера, Х. Долакия, Дж. Голанд, Дж. Кляйн,
Ф. Лейманн, К. Лю, Д. Роллер, Д. Смит, С. Тэтт, И. Уловка —
ович и С. Веераварана. Язык выполнения бизнес-процессов
для веб-сервисов (версия 1.1), 2003.
[4] Д. Берарди, Д. Кальванезе, Г. Д. Джакомо, М. Лензерини и
М. Мечелла. Автоматическая композиция E-Services, которые ex-
порт их поведения.В Proc. ICSOC’03, 2003.
[5] П. Бертоли, А. Чиматти, М. Писторе, М. Ровери и
П. Траверсо. MBP: Планировщик на основе моделей. В IJCAI-2001
семинар
по планированию в условиях неопределенности и неполной информации
, 2001.
[6] Дж. Р. Берч, Э. М. Кларк, К. Л. Макмиллан, Д. Л. Дилл и
Л. Дж. Хван. Проверка символической модели: 10
20
состояний и
за пределами страны. Информация и вычисления, 98 (2), июнь 1992 г.
[7] A.Чиматти, Э. М. Кларк, Ф. Джунчилья и М. Ровери.
N
USMV: новая проверка символьных моделей. International
Journal on Software Tools for Transfer Technology, 2 (4),
2000.
[8] T. O. S. Coalition. OWL-S: семантическая разметка для веб-сервисов
пороков, 2003.
[9] У. Дал Лаго, М. Писторе и П. Траверсо. Планирование с использованием языка
для расширенных целей. В Proc. AAAI’02, 2002.
[10] Э. А. Эмерсон. Временная и модальная логика.В J. van
Leeuwen, редактор, Справочник по теоретическим компьютерным наукам
ence, том B: Формальные модели и семантика, глава 14,
страниц 996–1072. Elsevier Science Publishers B.V .: Амстердам-
,
плотина, Нидерланды, Нью-Йорк, Нью-Йорк, 1990.
[11] Р. Халл, М. Бенедикт, В. Кристофидес и Дж. Су. E-
Услуги: взгляд за занавес. В Proc. PODS’03,
2003.
[12] Д. Манделл и С. Макилрейт. Адаптация BPEL4WS для семантической сети
: восходящий подход к веб-сервису
Взаимодействие.В Proc. 2-й Международной конференции по семантическому вебу
(ISWC03), 2003.
[13] Д. Л. МакГиннесс и Э. Ф. ван Хармелен. OWL Web On-
Обзор языка тологии. Рекомендация W3C, 2004 г.
http://www.w3.org/TR/2004/REC-owl-features-20040210/.
[14] С. Нараянан и С. Макилрайт. Моделирование, проверка
и автоматизированная композиция веб-сервисов. В Proc.
WWW’02, 2002.
[15] М. Ортис, Д. Кальванезе и Т. Эйтер.Характеристика данных
Сложность ответа на конъюнктивный запрос на экспрессивном языке
Описание логики. AAAI, 2006.
[16] Ф. Пальяреччи, М. Писторе, Л. Спалацци и П. Траверсо. Обнаружение сервиса Web
на уровне процесса на основе семантической аннотации
. В материалах пятнадцатого итальянского симпозиума по
передовым системам баз данных, Торре Канне, Бразилия, Италия, 2007.
[17] А. Патил, С. Оундхакар, А. Шет и К. Верма. METEOR-
S Структура аннотаций веб-сервисов.В WWW04, 2004.
[18] I. D. Pietro, F. Pagliarecci, L. Spalazzi. Se-
мантическая аннотация веб-сервисов. Техническое перевооружение
порт, DIIGA — Universit
`
a Politecnica delle Marche,
2008. http://leibniz.diiga.univpm.it/∼spalazzi/reports/TR-
2008-01.pdf .
[19] М. Писторе, А. Маркони, П. Бертоли и П. Траверсо. Au-
модифицированная композиция веб-сервисов путем планирования на уровне знаний
.В Proc. IJCAI’05, 2005.
[20] М. Писторе, Л. Спалацци и П. Траверсо. Минималистский подход к семантическим аннотациям для составления веб-процессов
. В Proc. 3-й Европейской конференции по семантической паутине —
(ESWC 2006), Будва (Черногория), 11–14 июня 2006 г.
Springer – Verlag, Берлин, Германия.
[21] А. Шет, К. Верна, Дж. Миллер и П. Раджасекаран. Улучшение описаний веб-служб
с помощью WSDL-S. В EclipseCon,
2005.
[22] С. Тобис. Результаты сложности и практические алгоритмы для логики
в представлении знаний. Кандидатская диссертация, RWTH
Аахен, 2001.
[23] П. Траверсо и М. Писторе. Автоматизированная компоновка сервисов Mantic Web Se-
в исполняемые процессы. В Proc.
ISWC’04, 2004.
[24] К. Верма, А. Мокан, М. Зарембра, А. Шет и Дж. А.
Миллер. Объединение усилий служб семантической паутины: интеграция
WSMX и METEOR-S.В семантической и динамической сети
Процессы
(SDWP), 2005.
[25] Семантические аннотации W3C для описания веб-сервисов
Рабочая группа по языку
. Семантические аннотации для
WSDL и XML-схемы, 2007.
[26] Д. Ву, Б. Парсиа, Э. Сирин, Дж. Хендлер и Д. Нау. Автоматизация создания веб-сервисов DAML-S с использованием SHOP2. В
Proc. ISWC’03, 2003.
(PDF) Основанная на семантике композиция процессов автоматизации производства, инкапсулированная веб-службами
2358 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL.9, NO. 4, НОЯБРЬ 2013
Подход позволит инженерам предметной области моделировать системные
tems и веб-сервисы на вышеупомянутых выразительных и
широко поддерживаемых языках, сохраняя при этом эффективный
и автоматическую компоновку веб-сервисов.
Повторное использование ранее составленных процессов OWL-S повторно
требует, чтобы Service Monitor сохранял каждый составленный процесс
в сервисной модели, что может чрезмерно увеличить количество операторов
в модели и задержки доступа к знаниям
.Кроме того, модификации в наборе доступных семантических веб-служб
могут сделать ранее составленные составные процессы
OWL-S неоптимальными или неприменимыми. Однако после разработки более сложного алгоритма планирования
отпадет необходимость в
для хранения и повторного использования ранее составленных процессов com-
posite.
ССЫЛКИ
[1] T.Cucinotta, A.Mancina, G.F. Анастаси, Дж. Липари, Л. Мангерука,
Р. Чеккоццо и Ф.Русина, «Сервисно-ориентированная архитектура в реальном времени для промышленной автоматизации», IEEE Trans. Ind. Inf., Vol. 5, вып. 3, pp.
267–277, август 2009 г.
[2] Ф. Джеммс и Х. Смит, «Сервис-ориентированные парадигмы в промышленной автоматизации
», IEEE Trans. Ind. Inf., Vol. 1, вып. 1, pp. 62–70, февраль 2005 г.
[3] APKalogeras, JVGialelis, CEAlexakos, MJGeorgoudakis,
и SA Koubias, «Вертикальная интеграция корпоративных промышленных систем —
человек, использующих веб-сервисы. ”IEEE Trans.Ind. Inf., Vol. 2, вып. 2, стр.
120–128, май 2006 г., ID: 1.
[4] И. М. Деламер и Дж. Л. Мартинес Ластра, «Сервисно-ориентированная архитектура —
Структура для распределенного промежуточного программного обеспечения публикации / подписки в электронике. воздуховода », IEEE Trans. Ind. Inf., Vol. 2, вып. 4, pp. 281–294, May 2006.
[5] ТАКвалёй, Э. Ронген, А. Тирадо-Рамос и П. Слот, «Автоматическая композиция
и выбор семантических веб-сервисов», Лекционные заметки
Comput. Sci., т. 3470, pp. 266–271, 2005.
[6] А. Христоскова, Д. Моейерсон, С. В. Хёке, С. Верстичел, Дж.
Декрюенаер и Ф. Д. Турк, «Динамическая композиция медицинских служб поддержки
в ICU: Детали разработки платформы и алгоритма »,
Comput. Методы Программы Biomed., Vol. 100, нет. 3, стр. 248–264,
2010, 12.
[7] А. Саса, М. Б. Юрич и М. Криспер, «Сервисно-ориентированная структура для поддержки и автоматизации задач человека
», IEEE Trans.Ind. Inf., Vol. 4, вып.
4, стр. 292–302, ноябрь 2008 г.
[8] С.А. Макилрайт, Т.С. Сон, Х.Зенг, «Semanticwebservices»,
IEEE Intell. Syst., Т. 16, нет. 2, pp. 46–53, 2001.
[9] A.Alves, A.Arkin, S.Askary, C.Barreto, B.Bloch, F.Curbera, M.
Ford, Y. Goland, A. Guízar, N. Kartha, CK Liu, R. Khalaf, D. König ,,
M. Marin, V. Mehta, S. Thatte, der Rijn van, P. Yendluri, и A. Yiu,
Web Services Business Process Execution Language 2007 [Online].
Доступно: http://docs.oasis-open.org/wsbpel/2.0/OS/wsbpel-v2.0-OS.
html
[10] Дж. Путтонен, А. Лобов, М. А. Кавиа Сото и Дж. Л. Мартинес Ластра,
«Подход на основе семантических веб-сервисов для управления производственными системами
trol», Adv. Англ. Информ., Т. 24, вып. 3, pp. 285–299, AUG 2010.
[11] Э. Прюдоммо, А. Сиборн, Язык запросов SPARQL для
RDF 2008 [онлайн]. Доступно: http://www.w3.org/TR/rdf-sparql-
запрос /
[12] М.Л. Сбодио, Д. Мартин и К. Мулен, «Обнаружение семантических веб-сервисов
с использованием SPARQL и интеллектуальных агентов», Веб-семантика: наука,
Сервисы
, агенты World Wide Web, вып. 8, вып. 4, pp. 310–328, 2010, 11.
[13] Э. Кристенсен, Ф. Курбера, Г. Мередит и С. Вираварана, Web
Service Defnition Language (WSDL) 2001 [онлайн]. Доступно: http: //
www.w3.org/TR/wsdl
[14] Д. Мартин, М. Бурштейн, Д. МакДермотт, С. Макилрайт, М. Паолуччи, К.
Сикара, Д. Л. МакГиннесс, Э. Сирин и Н. Шринивасан, «Внедрение мантики se-
в веб-сервисы с помощью OWL-S», Wo r l d Wi d e We b, vol. 10, вып.
3, стр. 243–277, 2007, 07 /.
[15] Д. Роман, У. Келлер, Х. Лаузен, Дж. Де Брейн, Р. Лара, М. Столлберг, А.
Поллерес, К. Фелер, К. Басслер и Д. Фенсель, » Моделирование веб-сервисов
онтологии // Прикл. Онтол., Т. 1, вып. 1, pp. 77–106, 2005.
[16] Д. Л. МакГиннесс и Ф. ван Хармелен, Owl Web Ontology Language
Overview 2004 [Online].Доступно: http://www.w3.org/TR/2004/
REC-owl-features-20040210/
[17] Дж. Фаррелл и Х. Лаузен, Семантические аннотации для WSDL и XML
Schema 2007 [ Онлайн]. Доступно: http://www.w3.org/TR/sawsdl/
[18] Д. Мартин, М. Паолуччи и М. Вагнер, Использование семантических аннотаций
в веб-сервисах: OWL-S From the SAWSDL Perspective, ser.Lec-
Заметки по информатике, т. 4825, pp. 340–352, 2007.
[19] I.Horrocks, P.Ф. Патель-Шнайдер, Х. Болей, С. Табет, Б. Грософ,
и М. Дин, май 2004 г., SWRL: язык правил семантической сети
, объединяющий OWL и RuleML [Online]. Доступно: http: //www.w3.
org / Submission / SWRL /
[20] П. Мартинек, Б. Тотфалусси и Б. Шикора, «Внедрение мантических сервисов se-
в интеграцию корпоративных приложений», WSEAS Trans.
Вычисл., Т. 7, вып. 10, pp. 1658–1668, 2008.
[21] Дж. Рао и X. Су, «Обзор методов автоматизированной композиции веб-сервисов
», в Proc.1-й международный семинар Semantic Web Services
Web Process Composition (SWSWPC 2004), 2004, стр. 43–54.
[22] О. Хаци, Д. Вракас, Н. Бассилиадес, Д. Анагностопулос и И.
Влахавас, «Семантическая осведомленность в автоматизированной компоновке веб-сервисов через планирование», Конспект лекций Comput. Sci., Т. 6040, pp.
123–132, 2010.
[23] Д. Макдермотт, PDDL — язык определения предметной области планирования
Версия 1.2 Йельский центр вычислительного видения и управления, 1998,
, технический отчет.
[24] Б. Ян и З. Цинь, «Составление семантических веб-сервисов с помощью PDDL»,
Информ. Technol. J., т. 9, вып. 1, pp. 48–54, 2010.
[25] Э. Сирин, Б. Парсия, Д. Ву, Дж. Хендлер и Д. Нау, «Планирование HTN
для композиции веб-сервисов с использованием SHOP2», Мы b S e mant i cs: Sci., Ser-
vices, Agents World Wide Web, vol. 1, вып. 4, стр. 377–396, 2004, 10.
[26] С. Х. Еганех, Дж. Хабиби, Х. Ростами и Х. Аболхассани, «Стенд для тестирования состава веб-сервисов Semantic
», Comput.Электр. Англ., Т. 36, нет.
5, стр. 805–817, 2010, 9.
[27] Дж. Л. Мартинес Ластра, И. Деламер, Онтологии для производства Au-
tomation, сер. Успехи в веб-семантике I, LNCS, vol. 4891, pp.
276–289, 2008.
[28] L. Ferrarini, C. Veber, A. Людер, Дж. Пешке, А. Калогерас, Дж. Джалелис, Дж.
Роде, Д. Вюнш и В. Чапурлат, «Архитектура управления для реконфигурируемых производственных систем: подход PABADIS’PROMISE»,
in Proc.IEEE Symp. Emerg. Technol. и Factory Autom. (ETFA),
2006, стр. 545–552.
[29] М. К. Уддин, Дж. Путтонен, С. Шольце, А. Дворянчикова и Дж. Л.
Мартинес Ластра, «Контекстно-зависимое вычисление на основе онтологий для оптимизации fms
», Assembly Autom. 32, нет. 2, стр. 163–174, 2012.
[30] А. Сегев, К. Шенг, «Онтологии начальной загрузки для веб-сервисов»,
IEEE Trans. Услуги вычисл. , т. 5, вып. 1. С. 33–44, янв. / Мар.
2012.
[31] В. В. Вяткин, Дж. Х. Кристенсен и Дж. Л. Мартинес Ластра,
«OOONEIDA: открытая, объектно-ориентированная экономика знаний для интеллектуальной промышленной автоматизации
», IEEE Trans. Ind. Inf., Vol.1, no.1,
pp. 4–16, 2005.
[32] IEC 61499-1 Function Blocks — Architecture, 2005.
[33] JL Martine z Lastra and IM Деламер, «Сервисы семантической паутины в факсимильной автоматизации
: фундаментальные идеи и план исследований», IEEE
Trans.В д. И нф., Т. 2, вып. 1, pp. 1–11, 2006.
[34] Х. Тонг, Дж. Цао, С. Чжан и М. Ли, «Распределенный алгоритм для композиции веб-служб
на основе модели агента службы», IEEE Пер.
Параллельный распр. Syst., Т. 22, нет. 12, pp. 2008–2021, Dec. 2011.
[35] U. of Basel, «ON :: OWL-S API — Введение». [Онлайн]. Доступно:
http://on.cs.unibas.ch/owls-api/index.html
[36] Д. Мартин, М. Бурштейн, Дж. Хоббс, О. Лассила, Д. МакДермотт, С.
Макилрайт, С. Нараянан, М. Паолуччи, Б. Парсия, Т. Пейн, E.
Сирин, Н. Сринивасан и К. Сикара, OWL-S: семантическая разметка для веб-служб
[онлайн]. Доступно: http://www.ai.sri.com/daml/ser-
vices / owl-s / 1.2 / overview
[37] Проект Socrades [Online]. Доступно: http://wwww.socrades.eu
[38] В. Вильясеньор Эррера, А. Видалес Рамос и Дж. Л. Мартинес Ластра,
«Агентная система для поддержки оркестровки веб-службы — en-
устройства в дискретных производственных системах », Дж.Intell. Мануфактура,
с. 1–22, 2011, статья в Press.
[39] Набор инструментов DPWS4J от Schneider Electric [Онлайн]. Доступно:
https://forge.soa4d.org/projects/dpws4j/
[40] Профиль устройств OASIS для веб-служб (DPWS). [Онлайн]. Доступно:
http://docs.oasis-open.org/ws-dd/ns/dpws/2009/01
Как использовать LSI и семантические ключевые слова [Руководство]
Что делает ваш бизнес успешным? Больше доходов и больше клиентов. Но чтобы клиенты звонили вам или посещали ваш магазин в современном онлайн-мире, вы знаете, что вам нужно появиться в верхней части Google Поиска.Вы также, вероятно, понимаете, что ключевые слова имеют решающее значение, но знаете ли вы, какие ключевые слова использовать и как использовать семантические ключевые слова, чтобы больше людей находили ваш контент и вашу компанию в Интернете?
Продолжайте читать, чтобы узнать все, что вам нужно знать, чтобы эффективно использовать семантически связанные ключевые слова для более разумного маркетинга вашего веб-сайта и вашей организации. В этой статье вы узнаете:
Plus, мы проиллюстрируем эти идеи соответствующими примерами, которые помогут прояснить семантические ключевые слова и способы их добавления в свой арсенал контент-маркетинга.
1. Что такое семантические ключевые слова
Прежде чем вы сможете понять семантические ключевые слова, вам нужно немного узнать, что такое семантика.
Что такое семантика?
Согласно лексике Оксфордского университета, семантика — это раздел лингвистики и логики, изучающий значение. Существует множество ветвей семантики, в том числе:
- Формальная семантика — исследование логических аспектов значения
- Концептуальная семантика — исследование когнитивной структуры значения
- Лексическая семантика — изучение значения слов и отношения слов
С точки зрения семантических ключевых слов, ваша главная забота — лексическая семантика.Другими словами, как значения ваших ключевых слов, а также слов и фраз связаны с вашими основными ключевыми словами.
Примеры семантики
Легко увязнуть в сложности семантики, поэтому давайте рассмотрим три примера:
- Прилагательное «квадрат» может относиться к прямоугольнику, кубу, форме или старомодный сленг для среднего человека, придерживающегося правил и статус-кво.
- Существительное «растение» может быть кустом, цветком, травой, деревом или фабрикой.
- Термин «авария» может относиться к автомобильной аварии, внезапному падению уровня энергии, громкому шуму в результате падения чего-либо или резкому падению на фондовом рынке.
Проще говоря, значение слова часто зависит от контекста и значения других слов в том же предложении, абзаце или общем содержании. Когда слово или фраза может иметь несколько значений, мы сразу понимаем, какое из них есть, по его отношению к другим словам, включая семантически связанные термины и фразы.
Семантически связанные слова сами по себе не являются синонимами, а являются словами и фразами, которые передают контекст и значение отрывка, темы или темы.
Но что это означает, когда дело доходит до поисковой оптимизации и исследования ключевых слов? Продолжайте читать, чтобы узнать.
Что такое ключевые слова скрытого семантического индексирования?
Теперь, когда вы углубляетесь в значение ключевых слов и лингвистику, вы можете беспокоиться о том, что вы усложняете или неправильно понимаете, что вам нужно исследовать, анализировать и оптимизировать для вашего контента.Вам не нужно становиться лингвистом или философом, чтобы понимать, как применять семантику к вашим усилиям по поисковой оптимизации и созданию контента.
Но прежде чем мы перейдем к этому, что такое ключевые слова LSI ?
Скрытое семантическое индексирование — это математическая технология. Теперь он используется Google и другими для анализа текста и определения его значения.
Скрытое семантическое индексирование (LSI) в мире SEO относится к ключевым словам и фразам, которые семантически связаны с вашими основными ключевыми словами.Таким образом, термины ключевые слова LSI и семантические ключевые слова описывают одни и те же типы ключевых слов, и независимо от того, на какой термин вы ссылаетесь, они помогают повысить ваш контент из-за их высокой степени релевантности для основного ключевого слова вашего контента.
Примеры семантических ключевых слов
Когда вы хотите оптимизировать свой контент для LSI, важно понимать, что это не то же самое, что синонимы. Хотя использование синонимов полезно для SEO на странице и позволяет избежать случайного набивки ключевыми словами, эта тактика отличается от использования семантики для улучшения вашего онлайн-контента.Итак, каковы примеры семантики?
Пример 1: Пекарня
Если на вашем веб-сайте пекарни есть сообщение в блоге с основным ключевым словом «как испечь торт», ваши ключевые слова могут включать такие слова, как:
- Мука
- Противень
- Яйца
- Глазурь
- Марципан
- Шоколад
- Температура духовки
- Выпечка
- Десерты
Ни одно из приведенных выше терминов не является синонимом. Тем не менее, все они помогают вашему читателю и поисковым системам понять контекст и релевантность вашей статьи поисковому запросу.
Пример 2: Подрядчик по ОВК
Может быть, вы не пекарь, но владеете предприятием, занимающимся подрядом и ремонтом ОВК. Вместо этого у вас может быть основное ключевое слово вроде «ремонт кондиционера». В этом случае список ключевых слов может включать:
- Охлаждение
- Лето
- Горячий воздух
- Неприятный запах
- Горение
- Круглосуточное обслуживание
- Техническое обслуживание
- Профессиональная помощь
- Скорая помощь
Вы Вы заметите, что некоторые из приведенных выше фраз могут использоваться в разных контекстах, включая контент, который вообще не касается нагрева или охлаждения.Однако при использовании в контенте, который включает ваше основное ключевое слово, вашим клиентам и Google очевидно, что веб-страница или статья посвящены «ремонту кондиционера» и что слово LSI, такое как «горячий воздух», относится к блоку переменного тока, а не к чему-то как воздушный шар.
2. Почему ключевые слова LSI важны
Теперь, когда вы знаете, какая семантика связана с ключевыми словами, а какая нет, каково их значение с точки зрения помощи вашему веб-сайту и вашему контенту, появляющимся на первой странице результатов поиска Google? И, что более важно, привлечь клиентов к вашему бизнесу? Недостаточно основных ключевых слов?
Ранние дни SEO и ключевых слов
На заре SEO вы привыкли обходиться без всяких вещей, чтобы доминировать в поиске и быть найденным в Интернете.Нередко можно было увидеть веб-страницы со скрытым содержанием, состоящим только из ключевых слов, или с содержанием, которое почти не имело смысла, но было наполнено основным ключевым словом. Позже такая стратегия стала неодобрительной, потому что она не помогала поисковикам, но ключевые слова остались.
В то время Google, Bing и другие поисковые системы не могли точно определять цель поиска или контекст вашего контента, и использование основных ключевых слов несколько раз на странице контента было критически важным.
Перенесемся в сегодняшний день, и мы увидим многочисленные обновления алгоритмов Google, а также достижения в области машинного обучения и искусственного интеллекта, которые позволят поисковому гиганту расширить возможности ранжирования вашего сайта и вашего контента.Совсем недавно обновление Google BERT за октябрь 2019 года улучшило способность поисковой системы понимать «контекст неоднозначных, сложных и сбивающих с толку поисковых запросов».
Как Google определяет контекст для ранжирования контента
Согласно Google, они используют различные алгоритмы для определения значения фрагмента контента и намерений поисковика. Помимо основных ключевых слов, поисковая система просматривает или включает следующие элементы:
- Орфографические ошибки
- Понимание естественного языка
- Синонимы
- Скрытое семантическое индексирование
Эти и другие методы помогают им определить, где будет оцениваться ваш контент. конкретный поисковый запрос.Чем более релевантен ваш контент для пользователя, тем больше вероятность, что он появится на первой странице их поиска.
Как семантика усиливает ваши основные ключевые слова
Поскольку Google использует LSI и аналогичные методы для определения намерений поисковика и контекста контента, когда вы включаете семантически ориентированные ключевые слова в свою стратегию SEO, ваш контент с большей вероятностью будет найден в Интернете.
LSI помогает Google и вашим клиентам понять ваш веб-сайт, ваш бизнес, ваши услуги и ваши продукты.Во многих отношениях то, как они используются для определения того, что отображается в том или ином поисковом запросе, показывает, что тема данной веб-страницы более важна, чем то, сколько раз ваши основные ключевые слова появляются в копии.
Почему ключевые слова LSI важнее плотности ключевых слов в вашем содержании
Мы более подробно рассмотрим плотность ключевых слов в конце статьи. Хотя вы не можете игнорировать важность плотности ключевых слов, вам необходимо понимать, почему семантика имеет решающее значение для оптимизации вашего контента, чтобы он отображался на глазах у большего числа людей.
Если вы хотите получить больше трафика из обычных результатов поиска, вы должны понимать цель выбора ключевых слов, а не только плотность. Кроме того, как мы уже отмечали, поисковые алгоритмы Google эволюционировали, чтобы лучше понимать контекст, значение и намерения пользователя.
И хотя плотность ключевых слов по-прежнему является фактором ранжирования, Google использует больше сигналов, которые помогают им определять релевантность и контекст вашего содержания поисковому запросу пользователя. Правильное использование LSI помогает Google понять тему ваших страниц, и именно поэтому они важнее плотности ключевых слов, но не устраняет необходимости в первичном исследовании ключевых слов и использовании их в интернет-маркетинге.
Итак, как найти и использовать правильные ключевые слова?
3. Как семантические ключевые слова используются для SEO
При исследовании статьи или копии веб-страницы мне больше всего нравится использовать метод, подобный тому, который предложил Судан Патель в его статье в Search Engine Journal, с некоторыми вариациями. и не обязательно в таком порядке.
# 1 Определите ваше основное ключевое слово (а)
Вы все равно должны провести исследование темы и основного ключевого слова. Однако у вас, возможно, уже есть список основных ключевых слов, на которые ориентирован веб-сайт вашей компании.Используйте их, чтобы направлять выбор темы и семантику.
# 2 Определите ключевые ключевые слова
Затем составьте список слов, близких по смыслу к вашим основным ключевым словам. Это могут быть синонимы и фразы, которые передают ту же идею, что и ваше основное ключевое слово. Обратите внимание на предложения поиска и похожие запросы в Google.
# 3 Составьте список тематически связанных ключевых слов
Третий шаг включает поиск фраз, которые не имеют одинакового значения, но относятся к той же теме.Например, давайте вернемся к человеку, ищущему ремонт кондиционера, из предыдущего примера HVAC. Они могли начать с просмотра «Лучший ремонт кондиционера рядом со мной» или «Отзывы подрядчиков по ОВК», потому что у них возникла непосредственная проблема — их кондиционер сломался.
Таким образом, список тематически связанных ключевых слов «Лучший ремонт кондиционера рядом со мной» может включать:
- Разбитый кондиционер
- Как найти ремонт переменного тока
- Техническое обслуживание кондиционера
- Неисправный кондиционер
- Ремонт переменного тока
- Домашний кондиционер
# 4 Составьте список основных ключевых слов, отвечающих на вопросы поисковика
Этот шаг включает поиск ключевых слов, отвечающих на вопросы поисковиков, включая вопросы, которые могут возникнуть после того, как они начали поиск.Вы можете найти некоторые из них, используя функцию «люди также спрашивают» в поиске Google и анализируя проблему, которую человек пытается решить, чтобы вы могли предвидеть следующие шаги, которые он может предпринять.
В нашем примере с неисправным кондиционером вы также можете оптимизировать свой контент для следующего:
- Где я могу купить новый кондиционер?
- Как определить, нужен ли вам новый AC
- Следует ли мне отремонтировать или заменить неисправный кондиционер?
- Какие вопросы я должен задать своей ремонтной компании?
- Могу ли я самостоятельно отремонтировать свой кондиционер?
# 5 Обозначьте свои статьи ключевыми словами из всех четырех списков, которые вы создали.
После того, как вы создали списки ключевых слов и фраз LSI, вы готовы обрисовать свои статьи на основе четырех списков, которые вы создали.Кроме того, предварительное описание статей поможет направить любые необходимые исследования и упростит написание статьи для вас или для писателя-фрилансера.
Чтобы использовать созданные вами списки, начните с использования основного ключевого слова или основного ключевого слова LSI в заголовке, а затем выберите от одного до двух ключевых слов из тематических списков и списков основных / вопросных ключевых слов LSI. Давайте воспользуемся или объединим некоторые ключевые слова нашего вымышленного подрядчика по ОВК, чтобы обрисовать в общих чертах сообщение в блоге для их веб-сайта, которое поможет потенциальному клиенту, который борется с неисправным кондиционером в жаркий день в Фениксе, штат Аризона:
- Руководство по ремонту кондиционера
- Куда обратиться найти ремонт кондиционера
- Ремонт кондиционера vs.Замена переменного тока
- Могу ли я самостоятельно отремонтировать неисправный кондиционер?
Вы можете легко создать контент, охватывающий всю тему, оптимизированный на основе поискового намерения и помогающий Google понять, о чем ваше сообщение, и ранжировать его по релевантным запросам.
# 6 Пишите для людей, а не для поисковых систем
Теперь, когда мы поговорили о семантике и более продвинутом исследовании ключевых слов, в котором приоритет отдается ключевым словам LSI, самое важное, что вы можете сделать, чтобы создать контент, который будет отображаться в верхней части сети поиски, это писать для людей.
Фактически, как только вы найдете тему для создания полезного контента, который поможет вашим клиентам, вы можете вернуться и использовать инструменты во время редактирования, чтобы включить больше ключевых слов LSI и исключить любое случайное чрезмерное использование ключевых слов и других терминов.
Если вы знаете и понимаете свои целевые рынки и своих текущих клиентов, вы можете создавать контент, который отвечает на их вопросы, помогает им решать их проблемы и гарантирует, что они видят вашу организацию как лучшую компанию, к которой они могут обратиться, когда им понадобится помощь.
4. Инструменты, используемые для поиска семантики
Хотя LSI может быть для вас более новой концепцией, чем устаревшее исследование ключевых слов, хорошая новость заключается в том, что есть инструменты, которые вы можете использовать, чтобы помочь. Следующие из них являются одними из фаворитов SEO-команды BizIQ:
LSI Graph
LSI Graph бесплатно предоставит вам ограниченный список основных ключевых слов, а также ограниченный список статей по той же теме. Для более продвинутых функций и большего количества ключевых слов вы можете выбрать между базовой и премиальной версией, и есть даже подписка на уровне агентства.
Стоимость: от 27 долларов в месяц до 444 долларов в год
Ключевые слова LSI
Инструмент ключевых слов LSI позволяет вводить до 10 ключевых слов для бесплатного создания списка семантических ключевых слов. Это простой, но мощный инструмент, который неоценим, особенно если у вас ограниченный бюджет.
Стоимость: Бесплатно
Отвечайте обществу
Я люблю Отвечать общественности! Это один из первых инструментов SEO-копирайтинга, который я использовал помимо Google. Они заменили причудливого старичка, изображенного на их домашней странице, на парня, похожего на хипстера, но это нормально.Их инструмент генерирует список вопросов и список предлоговых фраз, которые позволяют создавать мощные списки многоуровневых ключевых слов LSI. Даже бесплатная версия дает вам много возможностей для оптимизации контента.
Стоимость: Бесплатно до 99 долларов в месяц
KWFinder
KeyWord Finder — это доступный инструмент SEO, который поможет вам проводить все виды исследований ключевых слов, от LSI до длинных, а также основных ключевых слов. Бесплатная версия отсутствует. Однако вы можете попробовать его бесплатно в течение 10 дней.
Стоимость: от 49 до 129 долларов в месяц (скидка 40% при оплате за год)
Google Autocomplete
Дедушка всех бесплатных инструментов LSI по ключевым словам — это функция автозаполнения в поиске Google. Это бесплатно. И им невероятно просто управлять. Просто выполните следующие действия:
Откройте страницу поиска Google
Введите часть запроса
Например, когда вы вводите «кондиционер», Google Autocomplete генерирует список ниже, в котором отображаются следующие термины:
- Кондиционер
- Воздух кондиционирование
- Услуги по кондиционированию воздуха
- Кондиционеры
- Воздушное охлаждение
- Кондиционер
Стоимость: Бесплатно
5.Взаимосвязь между ключевыми словами LSI и их плотностью
Теперь, когда вы имеете представление о том, на что похоже современное исследование ключевых слов, давайте вернемся назад и кратко рассмотрим взаимосвязь между ключевыми словами LSI и плотностью ключевых слов.
Что такое плотность ключевых слов?
Плотность ключевых слов — это процент случаев, когда определенное ключевое слово появляется в фрагменте содержания. В прошлом некоторые SEO рекомендовали плотность ключевых слов от 10% до 13%. Тем не менее, в настоящее время это будет считаться набиванием ключевых слов, и вы не хотите превышать плотность ключевых слов более 1.От 5% до 2%. В идеале лучше писать естественную копию и не беспокоиться о плотности ключевых слов, а затем редактировать, чтобы избежать чрезмерного использования терминов, а также вместо этого сосредоточиться на включении семантических ключевых слов и плотности ключевых слов LSI.
Как рассчитать плотность ключевых слов
Вы можете рассчитать плотность ключевых слов вручную. Для этого нужно разделить количество повторений определенного ключевого слова на общее количество слов на веб-странице или в статье, а затем умножить на 100 (NKR / TKN) * 100 = плотность ключевых слов.
Кроме того, вы можете использовать бесплатный инструмент для анализа плотности ваших ключевых слов, а также плотности ваших ключевых слов LSI.
Заключительные мысли
Как видите, органический поиск и SEO далеко вышли за рамки простых ключевых слов. Теперь Google больше фокусируется на поисковом намерении и контексте вашего контента по отношению к этому намерению, чем на простых ключевых словах и фразах.
И хотя основные ключевые слова по-прежнему актуальны, чтобы показываться большему количеству клиентов в Интернете и доминировать в результатах поиска, владельцы малого бизнеса и их сотрудники по маркетингу должны понимать важность ключевых слов LSI.Если меньше сосредоточиться на плотности ключевых слов и больше на оптимизации трех типов ключевых слов LSI для поддержки вашего основного ключевого слова и темы, ваш контент улучшится и получит более высокий рейтинг.
Нужна помощь в маркетинге вашего бизнеса, включая местное и органическое SEO? Свяжитесь с BizIQ сейчас, чтобы поговорить со специалистом по интернет-маркетингу.
Семантические службы, функциональная совместимость и веб-приложения: Новые концепции: 9781609605933: Книги по информатике и ИТ
Предисловие
Амит Шет
Государственный университет Райта, США
Санджай Чаудхари
DA-IICT, Индия 55
05 к семантическим службам, взаимодействию и веб-приложениям: новые концепции
Есть явные признаки того, что семантическая сеть, если рассматривать ее как технологию, прошла стадию раннего внедрения своего жизненного цикла принятия технологии (Wikipedia Contributors, 2010).Принятие семантической паутины обусловлено конвергенцией ряда факторов, включая следующие:
- ускорение роста информации и ресурсов в сети, а также увеличение неоднородности (как в технологических аспектах, таких как представление и медиа, так и в нетехнических аспектах). такие как социокультурные аспекты)
- признание со стороны не только исследователей, но и практиков и компаний, что синтаксические и статистические решения близки к пределу эффективности в борьбе с масштабом и неоднородностью, и будущие выгоды будут получены от использования семантики
- хорошая степень консенсуса и принятия языков представления и основных технологий, для которых инициатива W3C Semantic Web и ее рекомендации, такие как RDF, SPARQL и OWL, сыграли решающую роль
- доступность технологий с большим количеством инструментов с открытым исходным кодом и примером системы более чем 20 хранилищами RDF и системами запросов, а также более широкой экосистемой доступные поставщики коммерческих услуг и продуктов
- успешная демонстрация своего ценностного предложения рядом областей раннего внедрения, что продемонстрировано развернутыми приложениями (Sheth & Stevens, 2007; Браммер и Терзиян, 2008; Cardoso et al., 2008) в нескольких областях, включая здравоохранение (Sheth et al., 2006) и науки о жизни (Ruttenberg et al., 2009; Baker & Cheung, 2007), фармацевтику, финансовые услуги (Sheth, 2005), электронное правительство и оборону ( Mentzas, 2007).
О раннем коммерческом использовании подхода Semantic Web сообщила компания Taalee (впоследствии путем поглощения / слияния Voquette, Semagix, Fortent), основанная в 1999 году, в том же году, когда термин Semantic Web был придуман Тимом Бернерс-Ли. Основной доклад, сделанный в 2000 году, дает ясные примеры семантического поиска и других приложений, у которых есть платные клиенты (Sheth, 2000).Это включает в себя создание онтологий или фоновых знаний в различных областях, автоматическую семантическую аннотацию разнородного веб-контента и приложений, включая семантический поиск, семантический просмотр, семантическую персонализацию, семантический таргетинг / рекламу и семантический анализ (Sheth et al., 2001). Эти первые усилия охватывали сотни веб-сайтов и семантическую обработку со скоростью около миллиона документов в час на сервер и были в значительной степени ограничены доступной инфраструктурой.Продолжает расти количество коммерческих продуктов и услуг, которые составляют основу инноваций и раннего внедрения в жизненном цикле технологий.
Теперь давайте посмотрим, почему мы находимся на ранней стадии большинства жизненного цикла. Быстро растущее число компаний и организаций предлагают продукты и услуги с использованием технологий семантической паутины или используют их для критически важных приложений (Sheth & Stephens, 2007; [³] Herman, 2009). Примеры компаний, предоставляющих продукты и услуги (с примером одного из ключевых приложений семантической сети), включают Adobe (инструменты для работы в Интернете и для настольных ПК), Dow Jones (доставка контента), General Electric (энергоэффективность), Hakia (поиск), IBM (анализ контента) , Nokia (инструменты и службы портала), OpenLink и Oracle (СУБД), WolframAlpha (поиск) и Reuters (служба семантической аннотации).Ряд компаний и организаций используют технологии семантической паутины для критически важных приложений, включая Office of Management and Budget, Pfizer, Eli Lily, Novartis и Telefonica. Коммерческий интерес к технологии семантической паутины наиболее ярко проявился в форме приобретения нескольких стартапов и небольших компаний крупными интернет-компаниями и технологическими компаниями, что лучше всего иллюстрируется приобретением Microsoft Powerset (2008 г.), Apple Siri (апрель 2010 г.) и Google of Metaweb (июнь 2010 г.).
Хотя использование технологии семантической паутины в полном масштабе сети еще предстоит, мы видим конкретный прогресс в использовании и поддержке возможностей семантической сети в масштабе сети. Наиболее конкретный шаг, предпринятый этими системами веб-масштабирования, в первую очередь поисковыми и другими веб-приложениями, — это создание и / или повторное использование огромных объемов фоновых знаний, часто включающих набор доменов, и каждый из которых включает (зависящие от предметной области) наборы сущностей. (также называемые объектами, концепциями и т. д.).Известно, что все крупные поисковые компании — Microsoft Bing, Google и Yahoo! — работают над этой возможностью. Поддержка неоднозначности является лакмусовой бумажкой семантической способности (в отличие от ключевых слов / синтаксис ориентированных подходов), который большинство из этих систем работает над поддержкой. Не менее важным является принятие RDFa и открытый обмен метаданными (такими как Facebook’sOpenGraph).
Возможно, однако, что наиболее значительный прогресс в семантической сети был достигнут в области связанных данных. Международный журнал семантической паутины и информационных систем гордится тем, что в 2010 году выпустил свой первый всеобъемлющий специальный выпуск по этой теме.
Давайте теперь рассмотрим главы этой книги.
Совместимость — одна из самых сложных проблем для межорганизационных информационных систем. Функциональная совместимость становится очень важной и актуальной для информационных систем электронного правительства, которые способны поддерживать межорганизационную коммуникацию в трансграничной установке. В разделе «Разрешение конфликтов семантической совместимости в трансграничных услугах электронного правительства» Mocan, Loutas, Facca, Peristeras, Goudos и Tarabanis предлагают бесшовную интеграцию общеевропейских электронных услуг для граждан для разрешения семантической совместимости, и в нем используются общие государственные услуги. модель управленческой архитектуры предприятия и онтологии моделирования веб-сервисов.В этой главе обсуждаются конфликты семантической совместимости на уровне данных и на уровне схемы. Услуги и решения по передаче данных разработаны в рамках проекта SemanticGov, финансируемого ЕС, для разрешения конфликтов семантической совместимости. Решение использует отображение онтологий и включает создание согласований между онтологиями предметной области во время разработки и их использование во время выполнения.
Документы, содержащие слова, не определенные в словаре, такие как WordNet и такие неопределенные слова, называются «Неизвестное слово (UW)».Хван и Ким в своей работе «Новая мера подобия для автоматического построения лексического словаря неизвестных слов» предлагают новый метод построения лексического словаря UW путем ввода различных коллекций документов, разбросанных по сети. Чтобы достичь истинной семантической обработки информации, работа ищет UW и термины, относящиеся к UW. Байесовская вероятность используется для присвоения вероятностного веса, а семантический вес на основе WordNet рассчитывается для определения семантической взаимосвязи между UW и связанным термином (ами).В работе используется недавно разработанный метод устранения неоднозначности смысла слов (WSD), чтобы словарь мог иметь точную синхронизацию для связанных терминов. Предлагаемый алгоритм WSD предназначен для автоматического построения лексического словаря UW с точностью 81% и продемонстрировал эффективную производительность по сравнению с алгоритмом SSI. Результаты показывают улучшение производительности на 15% по сравнению с методом Dice Coefficient.
Запросы для любых приложений веб-поиска могут быть неоднозначными, поскольку слова в запросах обычно имеют несколько значений.В статье «Извлечение взаимосвязей понятий и пользовательских предпочтений для персонализации устранения неоднозначности запроса» Чен и Чжан представляют кластерный метод устранения неоднозначности слов (WSD), позволяющий найти все подходящие интерпретации для запроса. Любое двусмысленное слово, вероятно, будет иметь очень близкие семантические отношения; рабочие группируют такие похожие смыслы вместе, чтобы объяснить двусмысленное слово в одной интерпретации. В случае нескольких противоречащих друг другу интерпретаций для одного неоднозначного запроса предпочтения пользователей, полученные из данных переходов по ссылкам, получаются для определения подходящих концепций или группы концепций.Экспериментальный результат показывает лучшую производительность предложенного метода по сравнению с алгоритмами WSD и Adapt Lesk на основе случаев.
Платформы и системы Web 2.0 используют RDF и RDFS в качестве базовых стандартов для хранения, запроса, обновления и обмена данными. Обоснование данных RDF является критическим вопросом с точки зрения производительности и масштабируемости. Существует острая необходимость в улучшении алгоритмов рассуждений для реализации возможностей семантической паутины. Многие исследователи стремятся улучшить производительность алгоритмов рассуждений при работе с крупномасштабными онтологиями RDF / OWL.SPARQL широко используется для извлечения данных из хранилищ RDF. В «Берлинском эталонном тесте SPARQL» Байзер и Шульц предлагают новый тест для оценки эффективной производительности таких функций SPARQL, как OPTIONAL, ORDER BY, UNION, REGEX и CONSTRUCT. В работе сравнивается производительность трех популярных хранилищ RDF с двумя преобразователями SPARQL-to-SQL в разных архитектурах и используется вариант использования электронной коммерции, состоящий из 100 миллионов троек и одного клиента. В документе обсуждается конструкция Berlin SPARQL Benchmark (BSBM) и сравнивается производительность четырех популярных хранилищ RDF — Sesame, Virtuoso, Jena TDB и Jena SDB с производительностью двух программ преобразования SPARQL-to-SQL — D2R Server и Virtuoso RDF Views и производительность двух СУБД — MySQL и Virtuoso RDBMS.Он использует методы тестирования, такие как выполнение смешанных запросов, параметризация запросов, моделирование нескольких клиентов и наращивание мощности системы. Ни один из результатов эталонного тестирования не был признан лучшим для одного варианта использования клиента для всех запросов и размеров наборов данных, и это оправдывает необходимость улучшения алгоритмов перезаписи. Чтобы сделать оптимизаторы SPARQL устойчивыми, необходимо разработать сложные методы оптимизации.
Хеллманн, Леманн и Ауэр применяют методы машинного обучения для получения сложных описаний классов из объектов в очень большой базе знаний, такой как DBpedia, OpenCyc, GovTrack и т. Д.«Изучение выражений классов OWL на очень больших базах знаний и их приложениях» направлено на повышение масштабируемости алгоритмов обучения OWL за счет интеллектуальной предварительной обработки, а также разработки, внедрения и интеграции гибкого метода в структуру DL-Learner для извлечения соответствующих частей очень большие базы знаний для данной учебной задачи.
Рассмотрение на основе крупномасштабных наборов данных RDF на базе Интернета — очень сложная задача. В «Масштабируемом авторитетном обосновании OWL для Интернета» Хоган, Харт и Поллерес предлагают фрагмент OWL Тер-Хорста pD для создания основанной на правилах структуры для приложения, которая использует алгоритм рассуждений с прямой цепочкой, называемый масштабируемым авторитетным рассуждением OWL (SAOR).Форвард-рассуждение используется, чтобы избежать сложности переписывания запросов во время выполнения, связанной с подходами с обратной цепочкой. Предлагаемая система отделяет терминологические данные от данных утверждений, включает в себя облегченный индекс в памяти, сортировку на диске и сканирование файлов. Он поддерживает отдельный оптимизированный индекс T-box для анализа наборов данных OWL. Чтобы сохранить управляемую базу знаний, алгоритм SAOR рассматривает только положительный фрагмент рассуждений OWL, анализирует авторитет источников, чтобы избежать перехвата онтологии, и использует идентификаторы сводных данных вместо полной материализации равенства.Эксперименты проводятся с базой данных, собранной из Интернета с миллиардом утверждений.
Чтобы удовлетворить растущий спрос на услуги для смартфонов / мобильных устройств, мобильные и повсеместные услуги должны иметь возможность семантического мышления. В статье «Включение масштабируемого семантического обоснования для мобильных сервисов» Стеллер, Кришнасвами и Габер предлагают интересную стратегию оптимизации семантического обоснования для приложений и сервисов, предназначенных для мобильных устройств. Предлагаемый алгоритм mTableaux оптимизирует задачи логического обоснования описания, так что большие задачи рассуждений можно масштабировать для небольших мобильных устройств с ограниченными ресурсами.В работе представлен сравнительный анализ производительности предложенного алгоритма с семантическими рассуждениями — Pellet, RacerPro и FaCT ++, демонстрирующий значительное улучшение времени отклика. Точность результата оценивается с использованием значений отзыва и точности.
Перемещение связанных данных — это набор передовых методов для публикации и соединения структурированных данных через Интернет, и его можно рассматривать как одну из основ семантической сети. Количество связанных поставщиков данных значительно увеличилось за последние три года.В главе «Связанные данные — история на данный момент» Байзер, Хит и Бернерс-Ли публикуют связанные данные, а также описывается обзор приложений на основе связанных данных. Усилия, связанные со связанными данными, подразделяются на три категории: браузеры связанных данных, поисковые системы связанных данных и приложения связанных данных для конкретных предметных областей. Поисковые системы SWSE и Falcons — это поисковые системы на основе ключевых слов, но по сравнению с существующими популярными поисковыми системами, обе используют базовую структуру данных, предоставляют сводку объекта, выбранного пользователем, а также дополнительные структурированные данные, сканируемые из Интернета, и ссылки на связанные сущности.Разрабатывается ряд сервисов, предлагающих специфичные для домена функциональные возможности путем объединения данных из различных связанных источников данных. Revyu, DBpedia Mobile, Talis Aspire, BBC Programs and Music, DERI Pipes — лишь немногие из таких приложений связанных данных для конкретных областей. Чтобы использовать Интернет как единую глобальную базу данных, необходимо решить различные исследовательские задачи: пользовательские интерфейсы и парадигмы взаимодействия, архитектуры приложений, отображение схем и слияние данных, обслуживание каналов связи, лицензирование, доверие, качество и актуальность.
В разделе «Объединенные связанные данные, управляемые сообществом» Шакья, Такеда и Вувонгсе предлагают подход, позволяющий людям обмениваться различными данными с помощью простой в использовании социальной платформы. В работе реализовано социальное программное обеспечение под названием StYLiD. Он позволяет пользователям с множеством точек зрения обмениваться различными типами структурированных связанных данных и выводить онтологии, чтобы предоставить онлайн-социальную платформу для использования обычными людьми. Пользователи могут свободно определять свои собственные концепции. StYLiD объединяет несколько схем путем полуавтоматического сопоставления этих схем с помощью методов выравнивания схем.Концепции группируются полуавтоматически на основе предложенного алгоритма вычисления подобия схем. Он генерирует неформальные онтологии для объединения нескольких точек зрения и объединения общих элементов. StYLiD построен на Pligg — системе управления контентом Web 2.0, и эксперименты проводятся на основе всех определений или типов пользовательских схем, полученных из Freebase.
«Поиск связанных объектов с помощью соколов: подход, реализация и оценка» Ченга и Ку представляет поисковую систему на основе ключевых слов для связанных объектов, называемую поиском объектов Falcon.Для каждого объекта он создает исчерпывающий виртуальный документ, состоящий из текстовых описаний, извлеченных из описания объекта RDF. Он строит инвертированный индекс на основе терминов в виртуальных документах. Для выполнения запроса на основе ключевых слов система использует инвертированный индекс и сравнивает термины в запросе с виртуальными документами объектов для создания набора результатов. Объекты набора результатов ранжируются с учетом их релевантности запросу и их популярности. Для каждого результирующего объекта предоставляется релевантный для запроса структурированный фрагмент, чтобы показать связанные литералы и связанные объекты, соответствующие запросу с ключевым словом.Понятие PD-thread используется как базовая единица, сниппет. Разработана методика ранжирования PD-потоков в сниппет. Информация о типах объектов расширяется путем выполнения рассуждений о включении классов по описаниям классов для реализации уточнения запроса на основе классов. Система рекомендует подклассы, чтобы разрешить навигацию по иерархиям классов для выполнения возрастающей фильтрации результатов.
В статье «URI стоит тысячи тегов: от тегирования до связанных данных с помощью MOAT» Пассан, Лаубле, Бреслин и Декер демонстрируют, как Web 2.0 можно объединить принципы содержания и связанных данных, чтобы решить проблемы систем свободной маркировки, такие как неоднозначность и неоднородность тегов. Он предлагает онтологию MOAT, основанную на четырехсторонней модели тегов, в которой каждый тег может быть представлен четверкой (,,,). Это помогает назначать выбранные теги ресурсу, используя огромное количество авторитетных URI из сети данных, чтобы сузить предполагаемое значение.
В «Онтологии идей для управления инновациями» Ридл, Мэй, Финзен, Стател, Кауфман и Кркмар делают попытку представить идеи с помощью онтологии.Трудно получить точное и формальное определение идеи. Онтология основана на OWL и обеспечивает общий язык для поддержки взаимодействия между инновационными инструментами для поддержки полного жизненного цикла идеи в открытой инновационной среде. В этой работе дается собственное определение идеи, и на основе детального анализа области управления инновациями создается онтология. Онтология предназначена для отражения основной концепции идеи для поддержки совместной разработки идей, оценки, обсуждения, маркировки и группирования идей в открытой инновационной среде.
В «Индуктивной классификации семантически аннотированных ресурсов с помощью сокращенных кулоновских энергетических сетей» Фаницци, д’Амато и Эспозито предлагают интересный метод для побуждения классификаторов из онтологии к поиску концептов. Индуцированный классификатор может определять меру правдоподобия индуцированных утверждений о принадлежности к классу для выполнения приблизительного ответа на запросы и ранжирования. В работе предлагается использовать классификатор на основе экземпляров для ответа на запросы на основе непараметрической схемы обучения; Сеть пониженной кулоновской энергии (RCE).Работа расширяет алгоритм классификации с использованием сетей RCE на основе меры энтропийного подобия для OWL. Эксперименты проводятся для выполнения приближенного ответа на запросы для ряда онтологий из публичных репозиториев. Результаты показывают, что индукционная классификация конкурентоспособна по сравнению с дедуктивными методами и способна выявлять новые утверждения о знании, которые не выводятся логически.
В статье «Связь в онтологиях» Руотсало и Мякеля сравнивают эффективность корпусного и структурного подходов для определения семантического родства в легких онтологиях.В работе выявляются сильные и слабые стороны методов в различных сценариях применения. Результаты экспериментов показывают, что ни корпусный метод, ни структурные меры не являются эффективными и конкурентоспособными. Скрытый семантический анализ (LSA) обеспечивает наилучшую производительность для всего набора данных. Структурные меры обеспечивают лучшую производительность по сравнению с LSA при применении пороговых значений. Эффективность сравниваемых методов различается для разных рангов. Было обнаружено, что LSA эффективно отфильтровывает нерелевантные отношения и может находить отношения, в то время как структурные меры терпят неудачу.В работе предлагается использовать комбинацию основанных на корпусе методов и структурных методов и определить соответствующие пороговые значения на основе предполагаемого варианта (-ов) использования.
Ссылки
Baker, C.J. O., & Cheung, K.-H. (Ред.). (2007). Семантическая сеть: революционное открытие знаний в науках о жизни . Springer.
Браммер М. и Терзиян В. (ред.). (2008). Промышленные приложения семантической паутины . Нью-Йорк, штат Нью-Йорк: Springer-Verlag.
Cardoso, J., Hepp, M., & Miltiadis, D. (Eds.). (2008). Семантическая сеть, реальные приложения из индустрии . Springer.
Герман И. (2009). Что сегодня делается? Презентация сделана Deutsche Telekom, Дармштадт, Германия, 14 декабря 2009 г.
Менцас Г. (2007). Знания и семантические технологии для гибкого и адаптивного электронного правительства . 7-й Глобальный форум по обновлению правительства: укрепление доверия к правительству, 26-29 июня 2007 г.
Ruttenberg, A., Рис, Дж. А., Самвальд, М., и Маршалл, М. С. (2009). Науки о жизни в семантической сети: Neurocommons и не только. Брифинги по биоинформатике, 10 (2), 193–204. DOI: 10.1093 / bib / bbp004.
Шет, А. (2000). Семантическая паутина и информационное посредничество: возможности, коммерциализация и проблемы . Основной доклад на Международном семинаре по семантической паутине: модели, архитектура и управление, Лиссабон, Португалия, 21 сентября 2000 г.
Sheth, A. (2005).E Корпоративные приложения семантической паутины: золотая середина риска и соответствия . Международная конференция IFIP по промышленным приложениям семантической сети (IASW2005), Ювяскюля, Финляндия, 25–27 августа 2005 г.
Шет А., Авант Д. и Бертрам К. (2001). Система и метод создания семантической сети и ее приложений для просмотра, поиска, профилирования, персонализации и рекламы . (Номер патента США — 6311194), Taalee, Inc., 30 октября 2001 г.
Sheth, A.
Добавить комментарий