Вырезать текст из фото
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:
В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания
Загрузите файл
Выберите язык содержимого текста в файле
После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных.
 Данные между серверами передаются по SSL + автоматически будут удалены
Данные между серверами передаются по SSL + автоматически будут удалены - Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 5.1M+ запросов
 Данные между серверами передаются по SSL + автоматически будут удалены
Данные между серверами передаются по SSL + автоматически будут удаленыОсновные возможности
Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Сегодня (3.08.2018) мы обновили наш сайт.
Обновления коснулись интерфейса и добавления нового функционала:
• загрузка файлов перетаскиванием;
• в результатах возможность экспорта документа в Doc, Google Docs, pdf;
• перевод текста;
• проверка орфографии;
Сайт стал лучше и удобнее для пользователей. Но ещё много функций и дополнений мы запланировали реализовать в будущем.
0.5.2 (26.11.2018): Добавлен функционал для удаления запросов из истории
Если Вы нашли какие-то баги, пожалуйста, сообщите нам, отправив письмо на email: web(собака)img2txt.com
Спасибо.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani – Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese – Simplified, Chinese – Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian – Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian – Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek – Cyrillic, Vietnamese
© 2014-2019 img2txt Сервис распознавания изображений / v.0.6.4.1
Работая с различными графическими файлами, нам может понадобиться извлечь текст из нужного нам изображения. Разумеется, это можно сделать вручную, просто набрав в каком-либо текстовом редакторе текст с имеющейся картинки. Но если объём такого текста огромен, тогда сам процесс набора может затянуться на неопределённое время. Предлагаем читателю существенно упростить процедуру, и использовать для копирования текста специальные сервисы. Ниже разберём, каким образом можно скопировать текст с любой картинки в режиме онлайн. А также какие инструменты нам в этом помогут.
Разумеется, это можно сделать вручную, просто набрав в каком-либо текстовом редакторе текст с имеющейся картинки. Но если объём такого текста огромен, тогда сам процесс набора может затянуться на неопределённое время. Предлагаем читателю существенно упростить процедуру, и использовать для копирования текста специальные сервисы. Ниже разберём, каким образом можно скопировать текст с любой картинки в режиме онлайн. А также какие инструменты нам в этом помогут.
Как при помощи онлайн-сервисом можно скопировать текст с изображения
Технология, которая поможет нам перекопировать надпись с картинки, носит название «OCR» («Optical Character Recognition – оптическое распознавание символов) . Первый патент на оптическое распознавание текста был выдан в Германии ещё в далёком 1929 году. С тех пор наука шагнула далеко вперёд, и качество распознавания текстов существенно выросло. К примеру, в случае латинских символов качество распознавания может достигать 99% всего текста. В случае же кириллицы этот процент несколько меньше, что поясняется «латинским» акцентом большинства современных сервисов и программ.
Эффективное распознавание текста возможно при наличии чёткого изображения, где все буквы визуально отделены одна от другой. В случае «замыленного» изображения, в котором буквы связаны друг с другом, имеют витиеватый характер, распознавание будет некачественным. В некоторых случаях вы и вовсе получите отсутствие какого-либо результата.
Работа с такими сервисами проста:
- Вы переходите на такой ресурс, и загружаете на него изображение с текстом.
- Указываете язык, на котором написан имеющийся на изображении текст.
- При наличии на ресурсе возможности, выбираете ту часть изображения, на которой расположен нужный текст.
- Затем запускаете процедуру распознавания онлайн, и обычно через пару секунд получаете результат.
Давайте разберём сервисы, позволяющие выделить текст с графического изображения online.
Jinapdf.com – сервис для качественного распознавания текста
Американский ресурс jinapdf.com от «Convert Daily LLC» – это один из наиболее эффективных ресурсов для распознавания текста онлайн. Его предназначение – быстрая и эффективная конвертация файлов из одного формата в другой. При этом ресурс умеет распознавать текст с изображения, хорошо распознаёт латиницу и кириллицу, поддерживает русскоязычный интерфейс, бесплатен и быстр. Для копирования текста с изображения online этот ресурс станет хорошим выбором.
- Перейдите на jinapdf.com;
- Кликните на «Выберите язык», и укажите язык, на котором написан текст на картинке;
- Нажмите на «Выберите файл», и загрузите файл с изображением на ресурс;
Нажмите на «Выберите файл» для загрузки изображения на ресурс
Newocr.com – поможет скопировать надпись с любой картинки
Другой качественный ресурс, о котором мы хотим рассказать – это newocr.com. Его возможности позволяют распознать текст с 106 языков, он бесплатен и не требует регистрации. Количество загрузок пользовательских фотографий на ресурс неограниченно, сервис хорошо распознаёт изображение с несколькими слоями. Полученный результат можно скачать на ПК, отредактировать в Гугл Докс, перевести через Google или Bing Переводчик.
Для работы с сервисом выполните следующее:
- Запустите newocr.com;
- В графе «Recognition language» (языки распознавания) выберите языки, на которых написан текст в изображении;
- Нажмите на «Обзор», и укажите сервису путь к нужному изображению;
- Для загрузки картинки на ресурс и её распознавания кликните на кнопку «Upload+OCR»;
Нажмите на «Upload + OCR» для загрузки и распознавания текста

Для сохранения результата нажмите на «Download»
I2ocr.com – бесплатная идентификация текста онлайн
I2OCR – это бесплатный OCR-сервис, позволяющий выполнить идентификацию текста с изображения online. Его возможности позволяют извлечь текст с изображения онлайн для его последующего редактирования, форматирования, индексирования, поиска или перевода. Сервис распознаёт более 60 языков, поддерживает распознавание нескольких языков на одном изображении, многоколонный анализ документов, бесплатную загрузку неограниченного количества изображений.
Для работы с сервисом выполните следующее:
- Выполните вход на i2ocr.com;
- В графе «Select language» выберите язык распознавания;
- Нажмите на кнопку «Select image» в центре, и загрузите изображение на ресурс;
- Поставьте галочку рядом с надписью «Я не робот»;
- Нажмите на «Extract Text» для получения результата (будет отображён внизу).
Convertio.co – ресурс для копирования надписей с изображений
Ресурс convertio.co – это популярный онлайн-конвертер, имеющий интернациональный характер. С его помощью можно провести конвертацию шрифтов, видео и аудио, презентации и архивы, изображений, документов. Доступна здесь и функция OCR, которой мы и воспользуемся. Бесплатно можно распознать 10 страниц (изображений), за большее количество придётся доплачивать.
- Запустите convertio.co;
- Нажмите на «С компьютера» для загрузки изображения на ресурс;
- Чуть ниже выберите язык для распознавания (при необходимости активируйте дополнительные языки). Также выберите тип документа, в который будет трансформирован распознаваемый текст;
- Нажмите внизу на «Распознать»;
Настройки распознавания на convertio.co
Img2txt.com – русскоязычный сервис для распознавания текста
И последний сервис, о котором я хочу рассказать – это img2txt. com . Сервис был запущен в 2014 году, прошёл несколько стадий улучшения своего функционала, и ныне обладает довольно неплохим качеством распознавания. Здесь имеется русскоязычный интерфейс, что придётся по вкусу отечественному пользователю.
com . Сервис был запущен в 2014 году, прошёл несколько стадий улучшения своего функционала, и ныне обладает довольно неплохим качеством распознавания. Здесь имеется русскоязычный интерфейс, что придётся по вкусу отечественному пользователю.
- Перейдите на img2txt.com;
- Кликните на «Выберите файл с изображением» и загрузите изображение с текстом на ресурс;
- Выберите язык текста для распознавания;
- Поставьте галочку рядом с надписью «Я не робот» (капча), и нажмите на «Загрузить»;
Загрузите файл на ресурс
Как распознать текст из картинки. 4 бесплатных решения.
Если вам необходимо извлечь текст из изображения, то, вероятно, наилучшим решением будет покупка приложения ABBY Finereader. Однако у него есть и бесплатные аналоги, которых может оказаться вполне достаточно.
Используйте OneNote
Электронный блокнот от Microsoft умеет распознавать текст из картинок уже много лет, хотя эта его возможность до сих пор мало известна. Распознавание происходит быстро и качественно.
Для работы необходимо вставить в программу соответствующее изображение. Как вариант, для этого можно создать новую пустую страницу. Для добавления изображения используйте пункт меню «Вставка» и команду «Рисунки», либо же «Вырезку экрана», если надо сделать скриншот из интернета.
Далее кликните на самой картинке правой клавишей мыши и из контекстного меню выберите пункт «Поиск текста в рисунках» и укажите на каком языке приведен текст в изображении. После этого еще раз вызовите контекстное меню и выберите пункт «Копировать текст из рисунка». После этого просто вставьте его в любое свободное место страницы – Ctrl+V.
Скрытая возможность Диска Google
Если в OneNote опция извлечения текста из картинки редко используемая, а потому и малоизвестная, то в облачном хранилище от Google данная возможность столь неочевидна, что догадаться о ее существовании не так-то просто. Вместе с тем, Диск Google также позволяет быстро переконвертировать изображение в текст.
Вместе с тем, Диск Google также позволяет быстро переконвертировать изображение в текст.
Для этого загрузите картинку в онлайн-хранилище. Затем, используя веб-интерфейс, кликните правой клавишей мыши на файле с картинкой и выберите команду «Открыть с помощью» – «Google Документы». У вас автоматически создастся текстовый файл и в нем откроется само изображение и извлеченный текст под ним. Традиционно для офисных файлов Google полученный результат распознанного текста с картинки можно скачать в одном из удобных форматов, в том числе Microsoft Word.
Через интернет-сайт
Ресурс onlineocr.net позволяет бесплатно в режиме онлайн распознать текст из картинки. Загрузите изображение с текстом, выберите язык текста (помимо русского и английского предлагается еще около 20-ти вариантов языков) и один из трех вариантов формата для скачиваемого файла. Впрочем, скачивать файл вам не обязательно, транскрипция текста с изображения будет доступна и в браузере для копирования.
Всё это доступно без регистрации на сайте. При этом для зарегистрированных пользователей предлагаются более широкие возможности, вроде использования дополнительных форматов для вывода текста и больший размер изображений для загрузки (ограничение для незарегистрированных пользователей – 5Мб для картинки).
Попробуйте Photron Image Translator
Бесплатное приложение доступно в Windows Store для обладателей 10-й версии операционной системы от Microsoft и подойдет как для обладателей ПК, так и планшетов. Помимо распознавания текста из картинок Photron Image Translator умеет переводить этот текст на другие языки и даже озвучивать полученное сообщение. А чтение текста с картинки с каждым годом становится всё актуальнее.
После установки приложения, выберите изображение (Image) как метод ввода и пункт галереи (Gallery) для загрузки файла с жесткого диска. После выбора картинки перейдите во вкладку «Извлеченный текст» (Extracted text). Результат даже лучше, чему у OneNote. Возможно, это лучшая среди бесплатных программа для распознавания текста с картинки.
Возможно, это лучшая среди бесплатных программа для распознавания текста с картинки.
Распознать текст правильно: бесплатные программы и приложения на смартфонах Android и стационарных компьютерах
Ещё несколько лет назад распознавание текста на изображении казалось сложной операцией. Сегодня же это можно сделать даже с помощью бесплатного приложения для телефона.
Подпишись на Знай в Google News! Только самые яркие новости!
Подписаться
Сейчас благодаря специализированным программам можно распознать и извлечь текст из фотографии или документа, чтобы сделать его редактируемым и правильно отформатированным в редакторе, таком как Word. Поэтому каждый раз, когда у вас возникает необходимость извлечь текст, написанный на листе бумаги, или из каких-либо картинок в интернете, или же со сканера, используйте OCR-считыватель , то есть технологию оптического распознавания символов.
В данной статье представлены лучшие программы и бесплатные приложения OCR (Оптическое Распознавание Текста) для распознавания текста на изображениях и фотографиях.
Как распознать текст, скрин
Хотя некоторые из этих приложений также доступны для iPhone и iPad, примеры будут приведены для работы на смартфонах Android (в том числе Samsung Galaxy, Huawei, LG, HTC и т.д.), а также для работы на стационарном компьютере.
Популярные статьи сейчас
Показать еще
ABBYY FineReader
Это самая распостранённая программа для распознавания текста, которая переводит изображения документов и любые типы PDF-файлов в электронные редактируемые форматы. Она определяет и точно восстанавливает логическую структуру документа в его электронной копии, позволяя забыть о перепечатывании текстов.
Основные возможности программы:
- Преобразование бумажных документов (отсканированный или сфотографированный документ) и PDF-файлов любого типа в редактируемые форматы, включая Microsoft Word и Excel.
- Сканирование и распознавание документов с помощью мобильного приложения ABBYY FineReader, доступного в любое время и в любом месте.
- Распознавание скана фотографий и текстов на более чем 190 языках.
- Создание, редактирование, комментирование, заполнение форм, защита документов и другие возможности для работы с PDF в программе ABBYY FineReader.
- Хранение документов для скачивания и отправки в облачные хранилища в течение 14 дней.
- Верификация результатов, а также автоматизация однотипных или повторяющихся задач по обработке документов в программе ABBYY FineReader.

Как распознать текст, скрин
Как распознать текст, скрин
Google Keep
Это отличное приложение, включающее технологию распознавания текста. Программа позволяет распознавать текст и символы на фотографиях. Keep может сохранять форматирование текста в том виде, в котором оно сфотографировано и присутствует в изображении, даже если оно достаточно сложное.
Чтобы использовать Google Keep:
- Коснитесь +.
- Добавьте новую заметку.
- Выберите добавить её с помощью фотографии.
- Сфотографируйте лист бумаги или выберите изображение из галереи телефона.
Текст извлекается за считанные секунды и доступен для редактирования.
По сравнению с другими приложениями, преимущество Keep в том, что оно является разработкой Google и, следовательно, интегрируется с Google Drive. Заметки синхронизируются через учётную запись Google и доступны с любого компьютера и мобильного телефона (включая iPhone и iPad).
Также Google Keep является наиболее удобным приложением для оцифровки печатных документов.
Text Fairy
Это бесплатное приложение-распознавалка для Android, выпущенное в 2017 году. Благодаря этой программе производится считывание и извлечение текста из зображений. Распознаются слова, написанных на более чем 50 языках, включая китайский, японский, голландский, французский, английский и многие другие.
Приложение отлично сканирует книги и журналы с простым чёрно-белым текстом, но в распознавании цветных слов могут возникнуть трудности.
Чтобы использовать сервис Text Fairy:
- коснитесь значка камеры, чтобы сделать фото,
- или значка галереи, чтобы импортировать изображение.
Далее нужно настроить часть изображения для сканирования, указав, находится текст в одном или двух столбцах. Затем выберите язык.
Извлеченный текст можно редактировать или копировать в редакторе, например, в App Office для Android.
Как распознать текст, скрин
Как распознать текст, скрин
Office Lens
Это лучший вариант среди приложений для распознавания текста, которые Microsoft когда-либо выпускала для Android (а также для iPhone).
Хотя его основная функция — возможность сканировать и оцифровывать документы, приложение также имеет опцию OCR, которую можно использовать бесплатно. Для этого вы должны подключить учётную запись Microsoft.
Office Lens распознаёт как сканированные картинки, так и фотографии текста. Программа без каких-либо проблем может считать даже цветные символы.
Это также лучшее приложение для Android OCR по распознанию рукописного текста.
Кроме того, при выборе приложений для извлечения текса учтите, что Office Lens работает лучше, чем другие при оцифровке рукописных заметок.
И конечно, данный распознаватель тесно интегрируется с другими продуктами Microsoft, такими как OneNote и Office 365.
Чтобы использовать приложение, после его установки и открытия необходимо навести камеру на документ, который вы хотите извлечь. Затем сделайте снимок, сохраните его. И далее откройте распознанный текст с помощью Ворд.
Как распознать текст, скрин
Text Scanner (OCR)
Если вам нужно приложение по распознаванию и сохранению текста, взятого из фотографий, то хорошим универсальным вариантом станет Text Scanner.
Скан текста поддерживает переводчик для болем чем 50 языков, включая китайский, японский, французский, итальянский и английский. Он также поддерживает извлечение рукописного текста (хотя и не идеально) и имеет инструменты для увеличения и изменения яркости для лучшего захвата текста.
Чтобы использовать Text Scanner, после его открытия возьмите и отсканируйте бумажный документ или импортируйте изображение из галереи, чтобы можно было сразу увидеть распознанный текст, который можно скопировать в любое место.
img2txt
Задаваясь вопросом, какая бесплатная прога является наилучшей для распознавания текста из изображений, стоит обратить внимание на img2txt.
Для работы с этим приложение вам необходимо:
- Отсканировать или сфотографировать текст для распознавания.
- Загрузить файл.
- Выбрать язык содержимого текста в файле.
- После обработки файла ожидайте результат (длительность обработки файла может составлять до 60 секунд).
Программа позваляет перевести текст в такие форматы jpg, jpeg, png и pdf.
Результаты сохраняются в виде:
- Чистого текста (txt),
- Adobe Acrobat (pdf),
- Microsoft Word (docx),
- OpenOffice (odf).
Преимущества img2txt:
- Лёгкий и удобный інтерфейс.
- Мультиязычность — сайт переведён на 9 языков.
- Быстрое распознавание текста.
- Неограниченное количество запросив.
- Отсутствие регистрации.
- Защита информации. Данные между серверами передаются по SSL. Плюс ко всему, они автоматически удаляются.
- Переводчик поддерживает 35 языков по тексту, который необходимо распознать.
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке).
- Обработка более чем 6,8 млн запросов.
CamScanner
Это приложение, доступное в бесплатной и платной версиях. Является отличной альтернативой другим приложениям OCR для Android. Это отличная считывающая и распознающая программа для различных текстов (в том числе и сканированного) на фотографиях и различных изображениях.
Лучшая особенность приложения в том, что оно способно обрабатывать несколько документов одновременно.
Это также одно из лучших приложений для сканирования документов.
Как распознать текст, скрин
Smart OCR
Очень быстрое приложение для распознания текста OCR. Оно мгновенно распознает слова на картинке, затем моментально копирует и извлекает их в качестве текста.
LightPDF
Это отличная онлайн-программа, которая предлагает различные инструменты управления PDF. Программа имеет функцию OCR, которая очень проста в использовании.
LightPDF поддерживает широкий спектр считывания языков. Среди них — английский, французский, итальянский, японский и прочие. Есть возможность также обрабатывать картинку формата jpeg JPG, PNG или PDF.
Пошаговое руководство по извлечению текста:
- Откройте главную страницу LightPDF.
- Загрузите изображение, которым нужно управлять, перетащив его или нажав «Выбрать файл».
- Когда страница завершит загрузку, вы можете выбрать «Язык» документа. Затем начните извлекать текст из изображения, нажав «Конвертировать».
- Чтобы сохранить файл на локальном диске, просто нажмите кнопку загрузки.
Преимущества LightPDF:
- Программа безплатна и работает без регистрации.
- Простой интерфейс: нет рекламы на странице. Вам просто нужно открыть файл изображения, сделать ещё несколько кликов — и файл готов к использованию.
- Что касается конфиденциальности загруженных файлов, страница автоматически удаляет изображения и другие файлы после того, как вы закончили её использовать.
i2OCR
Считается отличным инструментом для извлечения текста из online-изображений. Как следует из названия, i2OCR предназначен для управления услугами, связанными с OCR. Несмотря на то, что это онлайн-приложение, оно работает так же, как и любой другой инструмент для фиксированного распознавания текста. Эта программа поддерживает форматы JPG, PNG, PGM, TIF, PPM и PBM.
Когда дело доходит до языков, инструмент считывает и распознаёт до 60 языков. Сервис также имеет чистый, простой в использовании интерфейс и обеспечивает пользователям конфиденциальность (удаляет файлы сразу после выхода из него).
Чтобы копировка текста прошла успешно, следуйте руководству:
- Перейдите на главную страницу инструмента.
- На странице выберите язык текста, который нужно извлечь.
- Выберите, откуда вы хотите загрузить изображения. У вас есть два варианта: загрузить их со своего ПК или получить по URL-ссылке.
- Чтобы начать процесс, установите флажок для проверки, а затем нажмите «Извлечь текст».
- После завершения вы можете скачать файл.
Почему мы рекомендуем эту программу:
- Она бесплатная.
- Предлагает два способа загрузки изображения. Поэтому, если вы хотите извлечь текст из изображения, найденного в интернете, вам не нужно его загружать.
- Есть несколько методов извлечения, что позволяет предварительно просмотреть извлечённое изображение и слова перед загрузкой.
- Поддерживает переход на страницы перевода и позволяет редактировать в Google Docs.
Как распознать текст, скрин
OCR.Space
Последняя простая программа, которую мы рекомендуем для преобразования изображений в текст, это OCR.Space. Данный онлайн-инструмент специализируется на услугах, связанных с распознаванием текста. В настоящее время программа поддерживает около 20 языков, и умеет считывать такие форматы файлов как PNG, JPG и PDF.
Для извлечения слов из изображений следуйте инструкции:
- Посетите официальный сайт OCR.Space.
- Нажмите «Выбрать файл» или вставьте URL изображения. Затем выберите язык файла, с которым вы работаете.
- Выберите необходимый режим извлечения и нажмите «Начать распознание».
- Когда процесс завершится, нажмите «Загрузить», чтобы сохранить извлечённый текст на жёстком диске вашего компьютера.
Преимущества сервиса:
- Это бесплатный онлайн инструмент.
- Прост в использовании и имеет чистый интерфейс (без рекламы и спамов) для работы.
- Можно просмотреть изображение или файл после загрузки.
Если ваше изображение содержит цифры, рекомендуется выбрать корейский или китайский язык перед началом процесса извлечения.
Итак, вашему вниманию были приведены простые и понятные программы, которые вы можете использовать для извлечения и копирования текста из онлайн-изображения. В заключение хотелось бы предупредить, что, несмотря на технологические достижения, ни один инструмент OCR не является на 100% надёжным для распознавания текста, написанного на листе.
Результаты во многом зависят от языка, яркости, качества отсканированного листа, а также от используемой камеры.
Рекомендуется всегда проверять конечный перевод и результат после обработки, а также правильность распознания сканированных документов. В конце всегда проводите сравнение с отсканированным оригиналом документа.
Как отредактировать PDF на Mac и распознать текст на изображении
Вскоре после того, как я купил свой первый Mac, встал вопрос о приложении для редактирования PDF. Возможность открывать такие файлы для чтения с помощью встроенной утилиты «Просмотр» была приятным сюрпризом, но когда нужно было отредактировать текст, изображение или добавить подпись, приходилось искать сторонние решения. Apple вроде могла бы добавить мощный редактор PDF в macOS, но, увы, его там нет — и, скорее всего, появится он не раньше, чем приложение «Калькулятор» на iPad.
Годных редакторов PDF для Mac не так много
На ум сразу приходит решение от Adobe, и действительно оно весьма неплохое, но после пробного периода встает вопрос об оформлении подписки. А она стоит совсем недешево. Но скачивать какие-то непонятные программы тоже не хочется, поэтому оптимальный выход — найти альтернативу в Mac App Store. Все приложения, которые туда попадают, проходят тщательный отбор модераторами, так что в их качестве можно быть уверенным.
В итоге выбор остановился на PDFelement 7. Это приложение выполняет все задачи, которые требуются от редактора PDF: позволяет изменять текст и изображения, добавлять аннотации и водяные знаки, объединять несколько PDF-файлов в один и даже извлекать данные из PDF, который сделаны в виде изображения (как большинство сканов, например).
Интерфейс приложения напоминает продукты Microsoft Office, но основные элементы управления размещены слева и справа. Среди них быстрый доступ к редактированию текста, изображений, ссылок, форм и другим инструментам. Справа можно посмотреть оставленные закладки и, например, комментарии других пользователей.
Минималистичный интерфейс, похожий на Microsoft Word
Разобраться в приложении можно за несколько секунд, все довольно интуитивно
После недавнего обновления редактировать PDF стало еще удобнее — за пару кликов выделяем цветом интересующий текст, создаем пометки в виде всплывающего или встроенного текста, добавляем аннотации в виде геометрических фигур, линий или стрелок. Либо же вносим изменения в сам текст документа, воспользовавшись клавиатурой. Приложение также позволяет добавлять колонтитулы, номера страниц, водяные знаки и другие элементы оформления.
А вот это прям круто — распознавание картинок в любом PDF
Есть совместное редактирование, так что аннотации увидят все ваши коллеги с доступом к документу
Готовый файл можно экспортировать в один из популярных форматов (не только PDF, но и MS Office, текстовые документы или графические файлы).
Помимо этого, приложение умеет конвертировать файлы в PDF и обратно, создавать PDF из отсканированных изображений, распознавать текст для последующего редактирования. Например, если у вас отсканированная таблица в PDF, вы хотите ее немного подкорректировать и распечатать. Заходите в «Инструменты» и выбираете «Оптическое распознавания текста». И на выходе получаете документ, полностью готовый для редактирования.
Оптическое распознавание текста позволяет перевести любой скан в формат для редактирования
Позаботились разработчики и о конфиденциальности. Для обеспечения дополнительной защиты вы можете внести необходимые настройки доступа. Например, вы можете сами определять границы свободы для пользователей, у которых на компьютере окажется ваш файл, и запретить им редактировать или даже просматривать его при отсутствии необходимого пароля.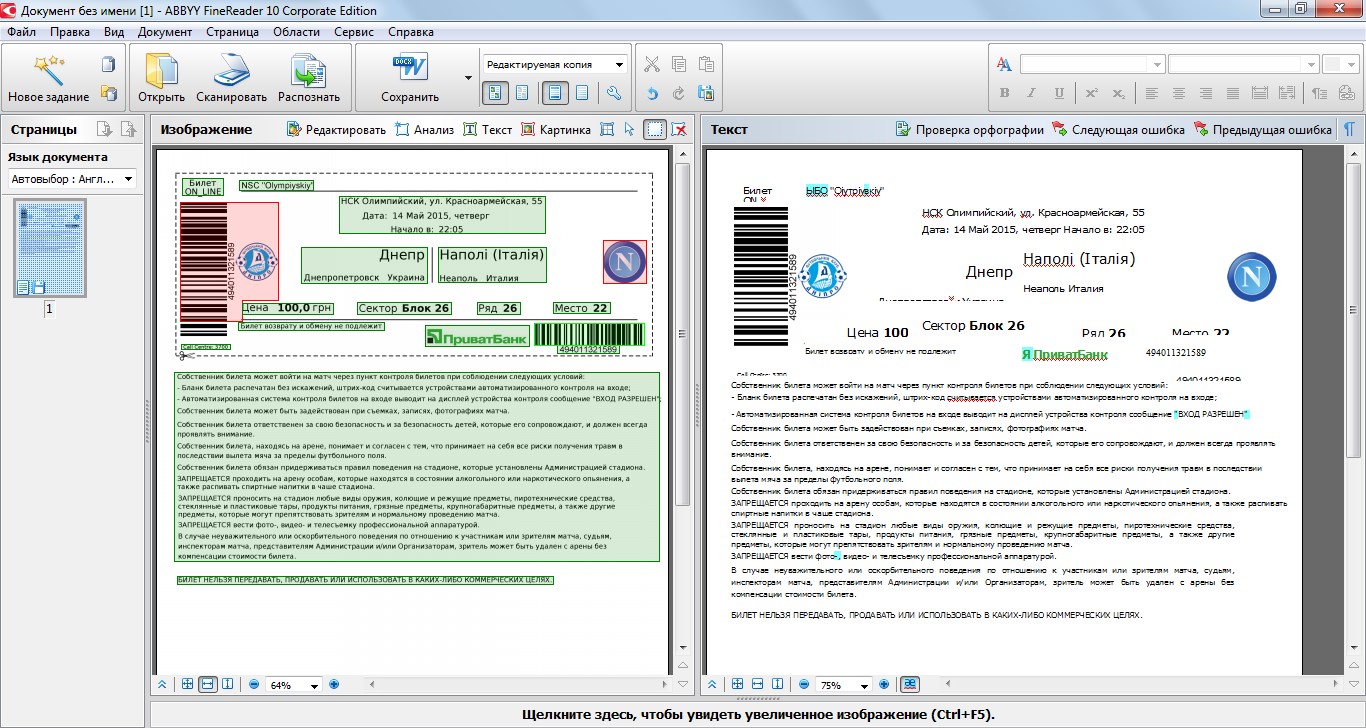 Все это в дополнение к возможности оставить водяной знак. Инструменты защиты выделены в отдельное меню для удобства.
Все это в дополнение к возможности оставить водяной знак. Инструменты защиты выделены в отдельное меню для удобства.
Защитить документ водяным знаком? Нет ничего проще
В специальном меню доступны опции для защиты и объединения PDF
Кстати, помимо настольной версии у PDFelement имеется и версия для iPhone и iPad, в которой тоже можно аннотировать PDF-документы, хотя и не поддерживается оптическое распознавание текста.
Чем удобно еще такое приложение, как PDFelement 7, так это гибкой системой подписок. Если вам нужны только основные функции, можно оформить стандартную подписку, а для доступа к профессиональным возможностям вроде распознавания текста предусмотрена профессиональная подписка. Но даже в простой подписке вы сможете добавлять аннотации и пометки к документам, объединять файлы в PDF, а также перемещать, удалять и добавлять страницы. Тем же, кто желает максимально близко подружиться с форматом PDF, лучше оформить профессиональную подписку. Поскольку приложение доступно в Mac App Store, есть различные варианты доступа к программе — от подписки на 1, 3 или 12 месяцев до бессрочной лицензии. А если вы не уверены в покупке, вы всегда можете воспользоваться демо-версией, доступной по ссылке ниже.
Название: PDFelement 7
Издатель/разработчик: Wondershare
Цена: Бесплатно / Подписка
Совместимость: Windows, Mac
Ссылка: Установить
Переводчик по фото онлайн — 2 способа
Пользователи сталкиваются с необходимостью перевода текста с фото онлайн. Ситуации могут быть разными: на фотографии есть текст, который необходимо извлечь из изображения и перевести на другой язык, есть изображение документа на иностранном языке, нужно перевести текст с картинки и т. п.
Можно воспользоваться программами для распознавания текста, которые с помощью технологии OCR (Optical Character Recognition) извлекают текст из изображений. Затем, извлеченный их фото текст, можно перевести с помощью переводчика. Если исходное изображение хорошего качества, то в большинстве случаев подойдут бесплатные онлайн сервисы для распознавания текста.
Затем, извлеченный их фото текст, можно перевести с помощью переводчика. Если исходное изображение хорошего качества, то в большинстве случаев подойдут бесплатные онлайн сервисы для распознавания текста.
В этом случае, вся операция проходит в два этапа: сначала происходит распознавание текста в программе или на онлайн сервисе, а затем осуществляется перевод текста, с помощью переводчика онлайн или приложения, установленного на компьютере. Можно, конечно, скопировать текст из фото вручную, но это не всегда оправданно.
Есть ли способ совместить две технологии в одном месте: сразу распознать и перевести тест с фотографии онлайн? В отличие от мобильных приложений, выбора для пользователей настольных компьютеров практически нет. Но, все же я нашел два варианта, как перевести текст с изображения онлайн в одном месте, без помощи программ и других сервисов.
Переводчик с фотографии онлайн распознает текст на изображении, а затем переведет его на нужный язык.
При переводе с изображений онлайн, обратите внимание на некоторые моменты:
- качество распознавания текста зависит от качества исходной картинки
- для того, чтобы сервис без проблем открыл картинку, изображение должно быть сохранено в распространенном формате (JPEG, PNG, GIF, BMP и т. п.)
- если есть возможность, проверьте извлеченный текст, для устранения ошибок распознавания
- текст переводится с помощью машинного перевода, поэтому перевод может быть не идеальным
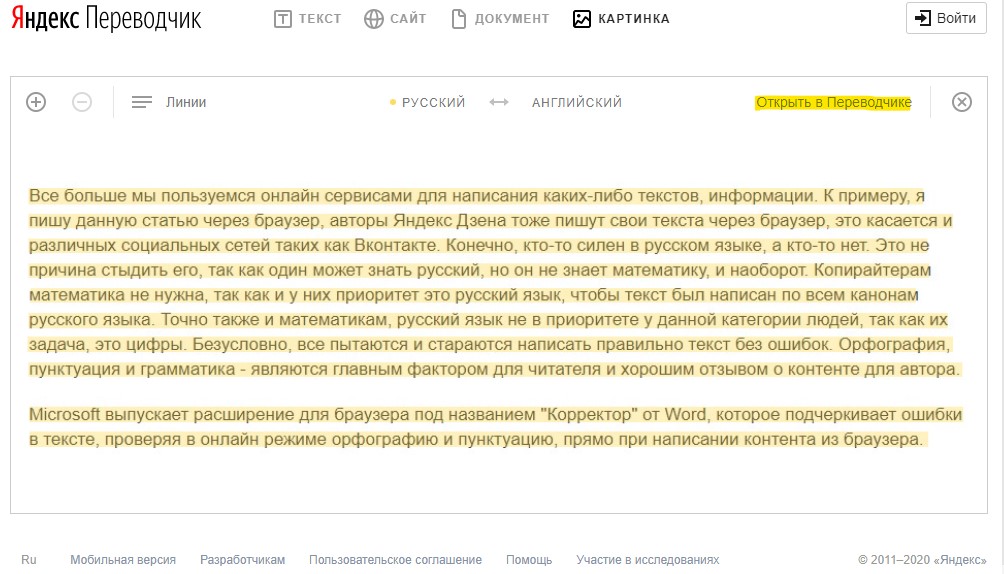
Мы будем использовать Яндекс Переводчик и онлайн сервис Free Online OCR, на котором присутствует функциональная возможность для перевода для извлеченного из фотошрафии текста. Вы можете использовать эти сервисы для перевода с английского на русский язык, или использовать другие языковые пары поддерживаемых языков.
Яндекс Переводчик для перевода с картинок
В Яндекс.Переводчик интегрирована технология оптического распознавания символов OCR, с помощью которой из фотографий извлекается текст. Затем, используя технологии Яндекс Переводчика, происходит перевод извлеченного текста на выбранный язык.
Затем, используя технологии Яндекс Переводчика, происходит перевод извлеченного текста на выбранный язык.
Последовательно пройдите следующие шаги:
- Войдите в Яндекс Переводчик во вкладку «Картинки».
- Выберите язык исходного текста. Для этого кликните по названию языка (по умолчанию отображается английский язык). Если вы не знаете, какой язык на изображении, переводчик запустит автоопределение языка.
- Выберите язык для перевода. По умолчанию, выбран русский язык. Для смены языка кликните по названию языка, выберите другой поддерживаемый язык.
- Выберите файл на компьютере или перетащите картинку в окно онлайн переводчика.
- После того, как Яндекс Переводчик распознает текст с фотографии, нажмите «Открыть в Переводчике».
В окне переводчика откроются два поля: одно с текстом на иностранном языке (в данном случае на английском), другое с переводом на русский язык (или другой поддерживаемый язык).
- Если у фото было плохое качество, имеет смысл проверить качество распознавания. Сравните переводимый текст с оригиналом на картинке, исправьте найденные ошибки.
- В Яндекс Переводчике можно изменить перевод. Для этого включите переключатель «Новая технология перевода». Перевод осуществляют одновременно нейронная сеть и статистическая модель. Алгоритм автоматически выбирает лучший вариант перевода.
- Скопируйте переведенный текст в текстовый редактор. При необходимости, отредактируйте машинный перевод, исправьте ошибки.
Перевод с фотографии онлайн в Free Online OCR
Бесплатный онлайн сервис Free Online OCR предназначен для распознавания символов из файлов поддерживаемых форматов. Сервис подойдет для перевода, так как на нем опционально имеется возможности для перевода распознанного текста.
В отличие от Яндекс Переводчика, на Free Online OCR приемлемое качество распознавания получается только на достаточно простых изображениях, без присутствия на картинке посторонних элементов.
Выполните следующие действия:
- Войдите на Free Online OCR.
- В опции «Select your file» нажмите на кнопку «Обзор», выберите файл на компьютере.
- В опции «Recognition language(s) (you can select multiple)» выберите необходимый язык, с которого нужно перевести (можно выбрать несколько языков). Кликните мышью по полю, добавьте из списка нужный язык.
- Нажмите на кнопку «Upload + OCR».
После распознавания, в специальном поле отобразится текст с изображения. Проверьте распознанный текст на наличие ошибок.
Для перевода текста нажмите на ссылку «Google Translator» или «Bing Translator» для того, чтобы использовать одну из служб перевода онлайн. Оба перевода можно сравнить и выбрать лучший вариант.
Скопируйте текст в текстовый редактор. Если нужно, отредактируйте, исправьте ошибки.
Заключение
С помощью Яндекс Переводчика и онлайн сервиса Free Online OCR можно перевести текст на нужный язык из фотографий или картинок в режиме онлайн. Текст из изображения будет извлечен и переведен на русский или другой поддерживаемый язык.
Источник
Распознавание текста с картинки. Python Tesseract ORC + OpenCV
Сегодня мы с вами поговорим на тему языка Python и рассмотрим пример создания крутого приложения. Наша программа будет способна считывать текст из любой фотографии.
Что сделаем за урок?
Мы с вами рассмотрим пример работы с библиотекой Tesseract ORC и на её основе построим приложение для распознавания текста с фото.
Что забавно, так это возраст библиотеки. Tesseract — является программой, разрабатывавшейся компанией Hewlett-Packard с середины 1980-х по середину 1990-х годов. Затем программа около 10 лет «пролежала на полке» и в августе 2006 года её купила Google. Google открыл исходный код под лицензией Apache 2.0 для продолжения разработки.
На сегодняшний день библиотека является наиболее крутым решением, если вам требуется считать данные из какого-либо фото.
Установка библиотеки
Первое, что необходимо сделать, то это выполнить установку Tesseract ORC. Установка Tesseract удобна на Маке и Линукс. Если вы на Windows, то придется выполнить на одно движение больше.
Если вы на Маке, то скачайте HomeBrew и далее в терминале пропишите brew install tesseract. Если вы на Линукс, тогда в зависимости от операционной системы вам нужно прописать соответствующую команду в терминале.
И если вы на Windows, то вам нужно скачать приложение на ПК. Вам нужно скачать файл Windows Installer. После скачивания выполните установку данной программы.
С самой программой вам никак не придется взаимодействовать, а лишь скопировать её расположение. Обычно оно устанавливается на диск С в Program files. Найдите вашу программу и скопируйте путь к этой папке.
Разработка проекта
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Полезные ссылки:
Код для реализации проекта из видео:
import cv2
import pytesseract
# Путь для подключения tesseract
# pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
# Подключение фото
img = cv2.imread('yourPhoto.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Будет выведен весь текст с картинки
config = r'--oem 3 --psm 6'
# print(pytesseract.image_to_string(img, config=config))
# Делаем нечто более крутое!!!
data = pytesseract.image_to_data(img, config=config)
# Перебираем данные про текстовые надписи
for i, el in enumerate(data.splitlines()):
if i == 0:
continue
el = el.split()
try:
# Создаем подписи на картинке
x, y, w, h = int(el[6]), int(el[7]), int(el[8]), int(el[9])
cv2.rectangle(img, (x, y), (w + x, h + y), (0, 0, 255), 1)
cv2.putText(img, el[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 1)
except IndexError:
print("Операция была пропущена")
# Отображаем фото
cv2. imshow('Result', img)
cv2.waitKey(0) imshow('Result', img)
cv2.waitKey(0)
imshow('Result', img)
cv2.waitKey(0)Распознавайте текст на фотографиях и других изображениях с помощью Google Keep
Google Keep — это приложение для создания заметок, к которому можно получить доступ в браузере в Интернете или с помощью приложения на телефоне или планшете, и оно работает везде. Это удобное место для хранения текста, изображений, списков и других элементов.
Теперь он может превращать изображения в редактируемый текст с помощью OCR (оптического распознавания символов).
Чтобы опробовать эту функцию, сфотографируйте квитанцию на свой мобильный телефон. Вы можете передать его на компьютер и загрузить, но лучший способ — запустить приложение Google Keep на телефоне и создать новую заметку с изображением из фотографии.
После этого перейдите на keep.google.com, чтобы войти в Google Keep на компьютере. Выберите фотографию квитанции, и она будет выглядеть примерно так:
Внизу изображения находится панель инструментов, и при нажатии на три точки отображается меню. Выберите Расшифровать текст . Он заканчивается почти сразу, и вы увидите уведомление вверху страницы. Щелкните изображение, чтобы просмотреть его.
Справа от этой всплывающей программы просмотра изображений есть полоса прокрутки, а при прокрутке вниз отображается текст, распознанный на изображении.На изображении также есть кнопка удаления.
Ужасная цветовая гамма — светло-серый на белом — кнопки трудно разглядеть, но она есть, если внимательно присмотреться. Нажмите кнопку удаления, если изображение вам больше не нужно.
Вот созданная записка. Это началось с фотографии квитанции, сделанной на мобильный телефон, а затем она была загружена и преобразована в текст с помощью средства распознавания текста Keep. Исходное изображение было удалено, и теперь есть простая заметка, содержащая редактируемый текст.
На самом деле это всего лишь тест, и вы, вероятно, не захотите превращать свои квитанции в Starbucks в редактируемый текст.
Он действительно показывает, как работает система, и может быть много случаев, когда у вас есть бумажный документ, который вы хотите превратить в редактируемый текст на вашем компьютере.
Вы можете сфотографировать его на свой телефон, чтобы создать заметку Keep image, а затем распознать ее, превратив в документ.
Это приятная функция, и Keep продолжает улучшаться.
Получите G Suite — это сервисы Google для предприятий
Gmail, Документы, Таблицы, Формы, Презентации, Календарь, Диск и многое другое. Управляйте пользователями, настраивайте устройства, безопасность и многое другое с помощью G Suite Admin. ( Партнерская ссылка ) Попробовать G Suite
Извлечь и перевести текст на изображение для iPhone, Android | TextGrabber
Повысьте продуктивность Скачать электронную книгу ›
Распознавать текст на 60+ языках в реальном времени
Мгновенно захватите текст из живого видеопотока или фото.Результат превращается в действие: ссылки, номера телефонов, адреса электронной почты, почтовые адреса, время и даты становятся интерактивными. Вы можете подписаться, позвонить, написать по электронной почте, найти на картах и создать события. Распознавание выполняется на устройстве, подключение к Интернету не требуется.
Перевод текста на экране камеры
Перевод в реальном времени прямо на экране камеры без фотографирования на 100+ языков онлайн (полнотекстовый перевод) и 10 языков офлайн (пословный перевод). С TextGrabber вы можете оцифровывать и переводить книги, руководства, рекламу, экран компьютера или телевизора — практически любой текст!
С TextGrabber вы можете оцифровывать и переводить книги, руководства, рекламу, экран компьютера или телевизора — практически любой текст!
Перевод текста на экране камеры
Перевод в реальном времени прямо на экране камеры без фотографирования на 100+ языков онлайн (полнотекстовый перевод) и 10 языков офлайн (пословный перевод).С TextGrabber вы можете оцифровывать и переводить книги, руководства, рекламу, экран компьютера или телевизора — практически любой текст!
Считайте QR-коды и поделитесь результатами
Выберите режим считывания QR-кодов и легко сканируйте QR-коды. Все собранные данные можно редактировать, копировать, читать с помощью VoiceOver, использовать в качестве поискового запроса и публиковать любым удобным для вас способом.
Ваш архив всегда под рукой
Никогда не теряйте распознанные и переведенные тексты и QR-коды — все ваши результаты сохраняются в истории, где вы можете легко их прочитать, объединить или удалить.
Ваш архив всегда под рукой
 5s and move 200px wait 0.3s»> Никогда не теряйте распознанные тексты и QR-коды — все ваши результаты сохраняются в истории, где вы можете легко их прочитать, объединить или удалить.
5s and move 200px wait 0.3s»> Никогда не теряйте распознанные тексты и QR-коды — все ваши результаты сохраняются в истории, где вы можете легко их прочитать, объединить или удалить.Что о нас говорят
Отлично.
Только что начал использовать текстовый захват. Пока все работает отлично.
Необходимая вещь
Один щелчок, и ваша фотография станет редактируемым текстом, который можно будет перенести в Twitter или около того. Отличный зверь.
Языки распознавания
Признание
Полнотекстовый перевод онлайн
Дословный перевод офлайн
Африкаанс
албанский
Амхарский
Арабский
Армянский
Азербайджанский
Баскский
Бенгальский
Боснийский
Бретонский
Болгарский
Белорусский
Каталонский
Себуано
чеченский
Chichewa
Китайский (упрощенный)
Китайский (традиционный)
Корсиканский
Крымскотатарский
Хорватский
Чешский
Датский
Голландский
Английский
Эсперанто
Эстонский
Фиджийцы
Филиппинский
Финский
Французский
Фризский
Галицкий
Грузинский
Немецкий
Греческий
Гуджарати
Гаитян К.
Хауса
Гавайский
Еврейский
Хинди
Хмонг
Венгерский
Исландский
Игбо
Индонезийский
Ирландский
Итальянский
Японский
Яванский
Кабардинец
каннада
Казах
кхмерский
Корейский
Курдский Курманджи
Кыргызская
Лаос
Латиница
латышский
Литовский
люксембургский
Македонский
Малагасийский
Малайский (Малайзийский)
Малаялам
Мальтийский
Маори
Маратхи
Молдавский
Монгол
Мьянма Б.
Непальский
Норвежский
Осетинская
пушту
Персидский
Польский
Португальский (Бразилия)
Португальский (Португалия)
Провансальский
Пенджаби
Рето-романский
Румынский
Русский
Самоа
Шотландский гэльский
сербский (кириллица)
Сесото
Шона
Синдхи
Сингальский
Словацкий
словенский
Сомали
Испанский
Суданский
Суахили
Шведский
Тагальский
Таджикский
Тамил
Татарский
телугу
Тайский
Турецкий
Украинский
Урду
Узбекский
Вьетнамский
Валлийский
Коса
Идиш
Йоруда
Зулу
Африкаанс
албанский
Амхарский
Арабский
Армянский
Азербайджанский
Баскский
Бенгальский
Боснийский
Бретонский
Болгарский
Белорусский
Каталонский
Себуано
чеченский
Chichewa
Китайский (упрощенный)
Китайский (традиционный)
Корсиканский
Крымскотатарский
Хорватский
Чешский
Датский
Голландский
Английский
Эсперанто
Эстонский
Фиджийцы
Филиппинский
Финский
Французский
Фризский
Галицкий
Немецкий
Греческий
Гуджарати
Гаитян К.
Хауса
Гавайский
Еврейский
Хинди
Хмонг
Венгерский
Исландский
Игбо
Индонезийский
Ирландский
Итальянский
Японский
Яванский
Кабардинец
каннада
Казах
кхмерский
Корейский
Курдский Курманджи
Кыргызская
Лаос
Латиница
латышский
Литовский
люксембургский
Македонский
Малагасийский
Малайский (Малайзийский)
Малаялам
Мальтийский
Маори
Маратхи
Молдавский
Монгол
Мьянма Б.
Норвежский
Осетинская
пушту
Персидский
Польский
Португальский (Бразилия)
Португальский (Португалия)
Провансальский
Пенджаби
Рето-романский
Румынский
Русский
Самоа
Шотландский гэльский
сербский
Сесото
Шона
Синдхи
Сингальский
Словацкий
словенский
Сомали
Испанский
Суданский
Суахили
Шведский
Тагальский
Таджикский
Тамил
Татарский
телугу
Тайский
Турецкий
Украинский
Урду
Узбекский
Вьетнамский
Валлийский
Коса
Идиш
Йоруда
Зулу
Скачайте ABBYY TextGrabber прямо сейчас
Дополнительные инструменты для повышения производительности
Top 5 OCR (оптическое распознавание символов) API и программное обеспечение
Что такое OCR?
OCR — Оптическое распознавание символов — полезная функция машинного зрения. OCR позволяет распознавать и извлекать текст из изображений для дальнейшей обработки / сохранения. Это очень полезно для обработки сканированных изображений / изображений текста — например, при работе со счетами, отсканированными формами и вывесками.
OCR позволяет распознавать и извлекать текст из изображений для дальнейшей обработки / сохранения. Это очень полезно для обработки сканированных изображений / изображений текста — например, при работе со счетами, отсканированными формами и вывесками.
Мы рассмотрели несколько API-интерфейсов для распознавания текста и оценили их по следующим критериям:
- Точность — мы перепробовали их все с изображением ниже, чтобы убедиться, что они четко распознают текст.
- Цена — мы указываем цену за вызов различных API.
- Специальные возможности — некоторые из рассмотренных нами API обладают особыми возможностями, что делает их более подходящими для конкретных задач, таких как сканирование счетов / распознавание логотипов.
Мы использовали следующее изображение, чтобы опробовать API, поскольку оно содержит много текста в разных стилях и размерах, а также некоторую графику, которая может сбить с толку API.
Лучшие API-интерфейсы OCR
1. Microsoft Computer Vision
Microsoft Computer Vision API — это полный набор инструментов компьютерного зрения, охватывающий такие возможности, как создание интеллектуальных миниатюр изображений, распознавание знаменитостей на изображениях и описание содержание изображений с использованием ИИ.
Точность
Microsoft API предлагает две конечные точки OCR: OCR из файла изображения и OCR из URL-адреса изображения. Обе конечные точки работают одинаково с разными источниками.
Распознавание текста работает хорошо и возвращает текст, разделенный на области текста. В каждой области есть строки, и в каждой строке есть слова, которые содержат фактический текст. Разделение удобно для понимания структуры содержимого изображения, хотя, если вам просто нужен текст в виде одной большой строки и вас не волнует позиционирование, потребуется дополнительный код.
Цена
Уровень бесплатного пользования API Microsoft предоставит вам 5 000 запросов в месяц. У API есть 3 платных плана:
У API есть 3 платных плана:
- 19,90 долларов -> 15000 запросов в месяц
- 74,90 долларов -> 70000 запросов в месяц
- 199,90 долларов -> 200000 запросов в месяц
По теме: Как использовать Computer Vision API с Python
2. SemaMediaData
Этот API представляет собой выделенную платформу OCR с единственной функцией — Image OCR.У него также есть «родственный» API — Video OCR, который оптимизирован для извлечения текста из видео (подробнее об этом позже).
SemaMedia API также требует ручной настройки языка для каждого запроса (с помощью параметра lang). В сценариях, где язык известен, это должно фактически повысить точность, поскольку позволяет API сравнивать распознанные слова со словарем (при использовании параметра df = True).
Точность
API очень хорошо обработал предоставленное изображение.Он возвращает массив результатов, каждая область текста с позицией на изображении, а также текстовый результат.
Специальные функции
Платформа SemaMedia также поддерживает видео OCR с Video OCR API. Согласно документам, OCR видео — это каскад анализа, который включает в себя сегментацию видео (жесткую вырезку), обнаружение / распознавание видеотекста и распознавание именованных объектов из видеотекста (NER — это бесплатная надстройка). Результат анализа этого метода обеспечивает автоматический поиск и индексирование видео, а также поиск видео по содержанию в видеоархивах.Подробный пример можно найти на нашем демонстрационном сайте.
Цена
Уровень бесплатного пользования API SemaMedia дает вам 100 запросов в месяц. У API 3 платных плана:
- 50,00 долларов -> 2200 запросов в месяц
- 200,00 долларов -> 13,500 запросов в месяц
- 500,00 долларов -> 40,000 запросов в месяц
3. Taggun
API Taggun — это уникальный OCR API, предназначенный непосредственно для сканирования счетов-фактур и квитанций. Это может быть полезно, поскольку API не только распознает текст на изображении, но также распознает структуру счета и возвращает проанализированные данные, такие как totalAmount , taxAmoumt , merchantName и т. Д.…
Это может быть полезно, поскольку API не только распознает текст на изображении, но также распознает структуру счета и возвращает проанализированные данные, такие как totalAmount , taxAmoumt , merchantName и т. Д.…
Accuracy
Вызывая конечную точку обработки простых квитанций, API возвращает оценку точности для каждого возвращенного фрагмента информации. Иногда это будет 0, и информация будет отсутствовать. Однако когда информация есть, она обычно точна.
Метка по точности метки может использоваться, чтобы запрашивать у пользователей поля, которые не распознаются должным образом в отсканированном счете.
Цена
Taggun API имеет бесплатный план, который включает 50 запросов в месяц, и платный план стоимостью 90 долларов, который включает 1000 ежемесячных запросов.
4. Cloudmersive
Cloudmersive OCR API — отличный инструмент для простого извлечения текста из изображений. Он имеет только одну конечную точку — изображение в текст, и возвращает весь текст изображения в виде одной строки, а не по регионам.Это может быть полезно при расшифровке большого куска текста (из книги / статьи), и нужен только сам текст.
Точность
API был довольно точным и успешно транскрибировал большинство слов в документе.
Цена
На уровне бесплатного пользования Cloudmersive API вы получите 50 000 запросов в месяц. У API есть 3 платных плана:
- 19,99 долларов -> 100 000 запросов в месяц
- 49,99 долларов -> 250 000 запросов в месяц
- 99 долларов.90 -> 500 000 запросов в месяц
5. Google Cloud Vision
Google Cloud Vision API — это комплексная платформа машинного зрения с возможностями, выходящими за рамки OCR, такими как распознавание лиц, маркировка изображений и обнаружение ориентиров (обнаружение естественных / рукотворный ориентир в изображениях).
Точность
Используя конечную точку / detectText с предоставленным изображением, API хорошо идентифицировал текст. Ответ содержит поле textAnnotation , которое содержит различные сегменты слова в изображении с их текстом и расположением.Это может быть очень удобно для выделения определенных слов на изображении (например, выделения названий брендов / слов из списка).
API также возвращает поле fullTextAnnotation , которое содержит весь текст изображения в виде одной строки, а также обнаруженный язык документа.
Цена
API включает 1000 бесплатных вызовов API в месяц и плату в размере 1,5 доллара США за каждую последующую 1000 запросов (по состоянию на апрель 2018 г.).
Специальные функции
API Google Cloud Vision также имеет связанную с OCR конечную точку / detectLogos.Учитывая изображение, содержащее логотипы брендов, эта конечная точка может идентифицировать бренды, которым они принадлежат. Во время нашего тестирования эта конечная точка легко идентифицировала логотипы ведущих брендов.
Сводка: Лучшие OCR API
| OCR API | Автоопределение языка | Текст по регионам | Текстовая аннотация (весь текст одной строкой) | Запросы на уровне бесплатного пользования | Приблиз.цена за звонок | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Google Cloud Vision | Да | Да | Да | Да | 0 | ||||||||||||||
Sema Media Data | Нет | Да | Нет | 100 | .013 | ||||||||||||||
Taggun | Да | Нет | Да (счета) | Cloudmersive | Да | Нет | Да | 50,000 | $ 0.0002 | ||||||||||
Microsoft Computer Vision | Да | Да | Нет | 5,000 | 5,000 Допустим, вам поручили оцифровывать ежемесячные счета от поставщиков. Вы можете пойти по старинке и вводить их вручную, исправляя орфографические ошибки.Вы также можете использовать сканер или популярное программное обеспечение для оптического распознавания символов, чтобы преобразовать всю информацию в счетах в цифровые файлы. Хотя все параметры, упомянутые выше, выполнимы, только оптическое распознавание символов (OCR) гарантирует эффективность, точность и внимание к деталям. Однако, прежде чем мы засыпаем вас более подробной информацией, давайте перейдем к сути и расскажем, что такое OCR и где оно используется. Что такое OCR?OCR — это аббревиатура от оптического распознавания символов, технологии, которая позволяет электронным или механическим способом преобразовывать тексты в печатных, рукописных, печатных, отсканированных и графических документах в машиночитаемый цифровой формат данных.Технология распознает и извлекает символы, такие как буквы, цифры и знаки препинания, из текстов изображений, а также печатных и письменных документов и преобразует их в электронный формат, который легко читается программами и компьютерами. Ранние версии OCR были обучены с изображениями каждого символа, и они могли работать только с одним шрифтом за раз. Однако сегодня можно найти передовые системы, которые могут обеспечить высокую степень точности распознавания. Кроме того, современные системы могут работать с разными шрифтами на ходу и предоставлять результаты в виде множества входных цифровых файловых форматов. Однако технология OCR не учитывает характер документа или элемента, содержащего символы. Он только ищет в элементе тексты, которые необходимо преобразовать. Тем, кто хочет узнать как природу предмета, так и его персонажей, необходимо объединить различные технологии. Как работает OCRОптическое распознавание символов позволяет преобразовывать символы в три основных этапа; предварительная обработка изображений, распознавание символов и постобработка. Предварительная обработка изображения Этот шаг включает в себя ряд процессов, предназначенных для улучшения четкости изображения для лучшего и успешного распознавания. Основная цель предварительной обработки — подавить искажения и улучшить важные функции сканируемого документа или изображения. Распознавание символов Этот шаг включает в себя два основных алгоритма OCR, которые позволяют использовать устройство для обнаружения только намеченных частей или форм оцифрованного изображения.Если входные данные слишком велики, будет обработана только их небольшая часть. Этот шаг гарантирует, что важные части документа или изображения сохранены, а повторяющиеся части отсортированы — это гарантирует лучшую производительность, когда дело доходит до распознавания текста. Постобработка Постобработка шаг, направленный на исправление ошибок и обеспечение повышенной точности OCR. Точность можно повысить за счет использования словаря — списка допустимых слов, чисел или кодов.Таким образом, алгоритм может вернуться только к списку требуемых чисел, слов и кодов. Этот шаг может также включать другие методы, направленные на повышение точности. К ним относятся такие вещи, как использование стандартных цветов и бизнес-правил. Для чего используется OCR? С момента своего создания оптическое распознавание символов применялось в различных областях, от банковского дела до истории. И теперь, когда технология претерпела колоссальный прогресс, вы обнаружите это сегодня в нескольких областях.К ним относятся:
Что такое OCR API? Как и многие другие технологии, большинство компаний ищут способы интегрировать OCR в свои приложения и системы. И один из лучших способов сделать это — использовать API. В настоящее время существует несколько API-интерфейсов OCR, которые люди могут использовать для распознавания различных символов из огромного массива изображений и документов. Вместо того, чтобы тратить целое состояние на устройства OCR, частные лица и предприятия могут воспользоваться API-интерфейсами OCR, которые также могут помочь извлекать печатный или рукописный текст из изображений. Статьи по темеЧасто задаваемые вопросыЧто такое OCR API?OCR — оптическое распознавание символов — полезная функция машинного зрения. OCR позволяет распознавать и извлекать текст из изображений для дальнейшей обработки / сохранения. Это очень полезно для обработки сканированных изображений / изображений текста — например, при работе со счетами, отсканированными формами и вывесками. Какие известные API-интерфейсы OCR доступны в виде веб-служб?Вот несколько лучших OCR API: Google Cloud Vision, Sema Media Data, Taggun, Cloudmersive и Microsoft Computer Vision Сколько стоит использование OCR API?Стоимость использования этих API может варьироваться от 0 долларов США.От 0015 до 0,09 доллара США за запрос API в зависимости от API и плана подписки. OCR изображения в текст с Tesseract.js | Бенсон РуанВы только что почувствовали, что обнаружили сокровище? Мы могли бы получить отсканированное изображение книги и использовать технологию оптического распознавания текста, чтобы прочитать изображение и вывести текст в формате, который мы можем использовать на машине. Это могло бы значительно повысить нашу продуктивность и избежать дублирования ручного ввода. В этом руководстве я покажу вам, как использовать Tesseract.js для создания веб-приложения OCR.Давайте сразу перейдем к коду. # Шаг 1. Включите tesseract.js Прежде всего, нам нужно включить библиотеку JavaScript tesseract.js. Самый простой способ включить Tesseract.js на страницу HTML5 — использовать CDN. Итак, добавьте следующее к
Если вы используете npm, вы также можете установить его, выполнив команду ниже npm install tesseract.js @ next В конце включите основной файл javascript tesseract-ocr.js# Шаг 2. Настройка элемента htmlСледующее, что нам нужно сделать, это добавить элементы html ниже
# Шаг 3: Инициализация и запуск Tesseract Кроме того, мы инициализируем Вы можете получить текстовый результат внутри функции обратного вызова, которую можно добавить с помощью метода # Шаг 4. Отображение хода выполнения и результата Наконец, давайте исследуем возвращаемый объект После возврата результата он содержит уровень достоверности , , текст , извлеченный из изображения. В массив слов он также включает местоположение слова внутри изображения. Теперь мы используем приведенную ниже функцию Вот и все для кода! Выберите свои собственные изображения с текстом и наблюдайте за результатами! OCR — Оптическое распознавание символовПоиск инструмента OCR — Распознавание символов Инструменты для распознавания текста.Оптическое распознавание символов (OCR) позволяет извлекать текстовое содержимое из изображений. Он в основном используется для нумерации документов, для расшифровки писем, написанных от руки или нет. Результаты OCR — Распознавание символов — dCode Тэги: Обработка изображений Поделиться dCode и другие dCode является бесплатным, а его инструменты являются ценным подспорьем в играх, математике, геокешинге, головоломках и задачах, которые нужно решать каждый день! Распознавание символовdCode не позволяет распознавать символы из файла.Однако вот список онлайн-инструментов, которые могут помочь. Инструменты для распознавания текста. Оптическое распознавание символов (OCR) позволяет извлекать текстовое содержимое из изображений. Он в основном используется для нумерации документов, для расшифровки писем, написанных от руки или нет. Ответы на вопросы (FAQ)Какие самые лучшие бесплатные онлайн-распознавания текста?Free- OCR .com здесь (ссылка): онлайн, бесплатно и быстро, с ограничением до 6 месяцев. I2OCR здесь (ссылка): онлайн, быстро и бесплатно, ограничено 200dpi и 10Mo Бесплатно онлайн OCR здесь (ссылка): онлайн, бесплатно, немного медленно DevTools360 здесь (ссылка): онлайн, много языков Новый OCR здесь (ссылка): онлайн, быстро, бесплатно, с выбором кадрирования. Онлайн OCR здесь (ссылка): онлайн, бесплатно, ограничено 4 месяцами. Google Docs здесь (ссылка): требуется учетная запись Google, открыв изображение или PDF-файл в Docs. Какие самые лучшие бесплатные программы для распознавания текста?GOCR здесь (ссылка): ПО с открытым исходным кодом для Windows или Linux. Tesseract здесь (ссылка): блок с открытым исходным кодом, используемый в Google Docs. Какие коммерческие программы для оптического распознавания текста являются лучшими?OmniPage здесь (ссылка): возможно, самое продвинутое программное обеспечение, но очень дорогое Abbyy FineReader здесь (ссылка): еще одно продвинутое программное обеспечение, немного дешевле. Как распознать шрифт, использованный в картинке?Чтобы определить конкретный шрифт, используемый в документе, изображении или PDF, вот несколько веб-сайтов: Какой шрифт здесь (ссылка): бесплатно, изображения Идентификатор здесь (ссылка): бесплатно, разработан MIT. Какой шрифт здесь (ссылка): бесплатно, онлайн, изображения Пример: dCode использует шрифт Courier Как распознать рукописный текст?На сегодняшний день (2016 г.) надежного программного обеспечения для распознавания рукописного ввода нет. Тем не менее, возможно распознавание рукописных символов в реальном времени (например, письмо подключенным пером) Задайте новый вопрос Исходный кодdCode сохраняет за собой право собственности на исходный код онлайн-инструмента «OCR — распознавание символов». За исключением явной лицензии с открытым исходным кодом (обозначенной CC / Creative Commons / free), любой алгоритм, апплет или фрагмент (конвертер, решатель, шифрование / дешифрование, кодирование / декодирование, шифрование / дешифрование, переводчик) или любая функция (преобразование, решение, дешифрование / encrypt, decipher / cipher, decode / encode, translate), написанные на любом информатическом языке (PHP, Java, C #, Python, Javascript, Matlab и т. д.)) никакие данные, скрипт, копипаст или доступ к API не будут бесплатными, то же самое для OCR — загрузка распознавания символов для автономного использования на ПК, планшете, iPhone или Android! Нужна помощь?Пожалуйста, заходите в наше сообщество в Discord для получения помощи! Вопросы / комментарииСводка Инструменты аналогичные Поддержка Форум / Справка Ключевые слова ocr, распознавание, оптика, символ, шрифт Ссылки Источник: https: // www.dcode.fr/ocr-optical-character-recognition-text © 2021 dCode — Идеальный «инструментарий» для решения любых игр / загадок / геокэшинга / CTF. 10 лучших API для OCROCR означает оптическое распознавание символов и обеспечивает способ чтения букв и цифр на изображениях, рукописных заметках, счетах и квитанциях, видео или любых других визуальных носителях и преобразовании их в машиночитаемый текст. Очевидно, что это полезная технология для разработчиков всех видов приложений, включая бухгалтерский учет, электронную коммерцию и розничную торговлю, юриспруденцию, идентификацию транспортных средств, здравоохранение, банковское дело, перевод и множество других применений.А способ интеграции служб OCR с приложениями — использование интерфейсов управления прикладными программами или API. Лучшее место для поиска подходящих API, которые могут позволить приложениям расшифровывать текст, находится в категории ProgrammableWeb OCR. В этой статье мы подробно рассмотрим десять самых популярных API-интерфейсов OCR на основе просмотров страниц читателя на ProgrammableWeb . 1. Free OCR APIFree OCR APITrack этот API анализирует изображения и многостраничные документы PDF (PDF OCR) и возвращает извлеченный текст в формате JSON.API можно использовать с любого устройства, подключенного к Интернету, включая мобильные устройства Android и iOS, а также устройства IoT. 2. Intento APIIntento (Inten.to) предоставляет единый интерфейс для нескольких моделей когнитивного ИИ и поставщиков. Этот API-интерфейс Intento APITrack предоставляет ответы в формате JSON для перевода текста, добавления тегов к изображениям, анализа тональности, оптического распознавания символов (OCR) и транскрипции речи. Что касается OCR, он охватывает технологии из ABBYY, API Google Cloud Vision и API Microsoft Computer Vison. 3. CAPTCHAS.io APICAPTCHAs.IO — это служба автоматического распознавания капчи, которая поддерживает более 30 000 кодов изображений, звуковых кодов и reCAPTCHA v2 и v3, включая невидимую reCAPTCHA. CAPTCHAs.IO APITrack этот API обеспечивает RESTful доступ ко всем методам решения капчи CAPTCHAs.io. Разработчики могут выбрать ПОЛУЧЕНИЕ ответов API в формате JSON или в виде обычного текста. 4. API поиска российских автомобильных номеровAPITrack поиска российских автомобильных номеров. Этот API позволяет пользователям использовать камеру смартфона для захвата номерных знаков (Госномер) российского автомобиля и получения информации о марке и модели, году выпуска, ориентировочное изображение автомобиля, частичный номер VIN, и если автомобиль разыскивается российской полицией (Gibdd).Он предназначен для использования на автомобильных сайтах, ориентированных на российский рынок. 5. Google Cloud Vision APIGoogle Cloud Vision APITrack этот API предоставляет разработчикам доступ к инструментам распознавания, обработки и анализа изображений. Служба классифицирует изображения по тысячам категорий (например, «грузовик», «тигр», «Эмпайр-стейт-билдинг») и обнаруживает отдельные объекты и лица на изображениях. Его компонент OCR может обнаруживать более 50 различных языков, включая смешанный текст.Также он распознает почерк. Он может распознавать текст в нескольких форматах изображений, включая TIFF, GIF, PDF, JPG и Animated GIF. 6. Cloudmersive API оптического распознавания символовCloudmersive предоставляет масштабируемые API для компьютерного зрения и естественного языка. Cloudmersive Optical Character Recognition APITrack этот API позволяет пользователям преобразовывать отсканированные изображения страниц в распознанный текст. API использует машинное обучение для автоматической предварительной обработки и последующего распознавания текста на более чем 90 языках.Он также раскручивает и поворачивает изображения и может автоматически сегментировать документы и квитанции из фотографий. Cloudmersive OCR API позволяет приложениям определять товары по отсканированным квитанциям. Изображение: Cloudmersive 7. Mathpix APIЭтот API-интерфейс Mathpix APITrack позволяет пользователям решать математические уравнения с помощью технологии OCR. С помощью API разработчики могут реализовывать обработку изображений, системы уравнений, матрицы, длинные деления, номера задач, графики и геометрические диаграммы.Приложение можно скачать для Android и iOS. Этот API поддерживает научную нотацию, используемую в химии, математике, физике, информатике, экономике и других предметах STEM. 8. Captcha Solutions APICaptcha Solutions — это веб-служба декодирования CAPTCHA, предлагающая решения на основе фиксированной ставки за каждую решенную CAPTCHA. Этот RESTful APITrack этот API предназначен для решения большого количества задач CAPTCHA для широкого спектра приложений. Он на 90% основан на системе распознавания текста и на 10% человеческом коллективе. 9. NewOCR APINewOCR APITrack Этот API может преобразовывать текст в файлах JPG, PNG, GIF, BMP, TIFF, PDF и DjVu в текст. API предлагает бесплатные и платные службы OCR для 122 языков распознавания и шрифтов, выбор области на странице для OCR, автоповорот, несколько способов отображения и обработки результирующего текста, включая копирование в буфер обмена и редактирование в Документах Google, несколько форматов ввода, включая многостраничный PDF или несколько изображений в ZIP-архиве, анализ макета страницы, распознавание математических уравнений, а также поддержка плохого сканирования и изображений с низким разрешением. 10. API Den OCRAPI Den предоставляет API для услуг B2B. API Den OCR APITrack этот API позволяет приложениям иметь возможности OCR, включая поддержку более 120 языков. OCR преобразует изображения печатного, рукописного или напечатанного текста в машинно-кодированный текст. Сервис считывает фотографии, документы, фотографии с места событий, паспорта, банковские выписки и все остальное и может отображать в обычном текстовом формате или в формате XHTML. Дополнительные API-интерфейсы, а также SDK и образцы исходного кода можно найти в категории OCR. Распознать текст | Справка — Zoho DelugeОписаниеЗадача zoho.ai.recognizeText выполняет OCR (оптическое распознавание символов) для указанного файла. Другими словами, он извлекает текст из изображения или файла PDF. Примечание:
Синтаксис<ответ> = zoho.ai.recognizeText (<файл>, [<тип_модели>], [<язык>]); где:
Примечание: Здесь вы можете найти разрешенные типы моделей и поддерживаемые языки. ПримерСледующий скрипт извлекает и возвращает текст, присутствующий в данном изображении. // Получить файл изображения из Интернета изображение = invokeurl [ URL: "http://www.thenonlinearpath.com/wp-content/uploads/2016/05/GoodVibesOnly.png" тип: GET ]; // Для извлечения текста из файла изображения response = zoho.ai.recognizeText (изображение); где: Ответ KEY-VALUE, представляющий текст, извлеченный из файла изображения. ФАЙЛ, представляющий изображение, из которого необходимо извлечь текст. Формат ответаУспешный ответ
Реакция на сбой
|
Добавить комментарий