Как полностью скрыть сайт от индексации?
Про то, как закрыть от индексации отдельную страницу и для чего это нужно мы уже писали. Но могут возникнуть случаи, когда от индексации надо закрыть весь сайт или зеркало, что проблематичнее. Существует несколько способов. О них мы сегодня и расскажем.
Существует несколько способов закрыть сайт от индексации.
Запрет в файле robots.txt
Файл robots.txt отвечает за индексацию сайта поисковыми роботами. Найти его можно в корневой папке сайта. Если же его не существует, то его необходимо создать в любом текстовом редакторе и перенести в нужную директорию. В файле должны находиться всего лишь две строчки:
User-agent: *
Disallow: /
Остальные правила должны быть удалены.
Этот метод самый простой для скрытия сайта от индексации.
С помощью мета-тега robots
Прописав в шаблоне страниц сайта следующее правило <meta name=»robots» content=»noindex, nofollow»/> или <meta name=»robots» content=»none»/> в теге <head>, вы запретите его индексацию.
Как закрыть зеркало сайта от индексации
Зеркало — точная копия сайта, доступная по другому домену. Т.е. два разных домена настроены на одну и ту же папку с сайтом. Цели создания зеркал могут быть разные, но в любом случае мы получаем полную копию сайта, которую рекомендуется закрыть от индексации.
Сделать это стандартными способами невозможно, т.к. по адресам domen1.ru/robots.txt и domen2.ru/robots.txt открывается один и тот же файл robots.txt с одинаковым содержанием. В таком случае необходимо провести специальные настройки на сервере, которые позволят одному из доменов отдавать запрещающий robots.txt.
#104
Февраль’19
1071
21
#94
Декабрь’18
2493
28
#60
Февраль’18
3353
19
Как закрыть контент от индексации — пошаговое руководство
Иногда возникают такие ситуации, когда нужно Закрыть от индексации часть контента.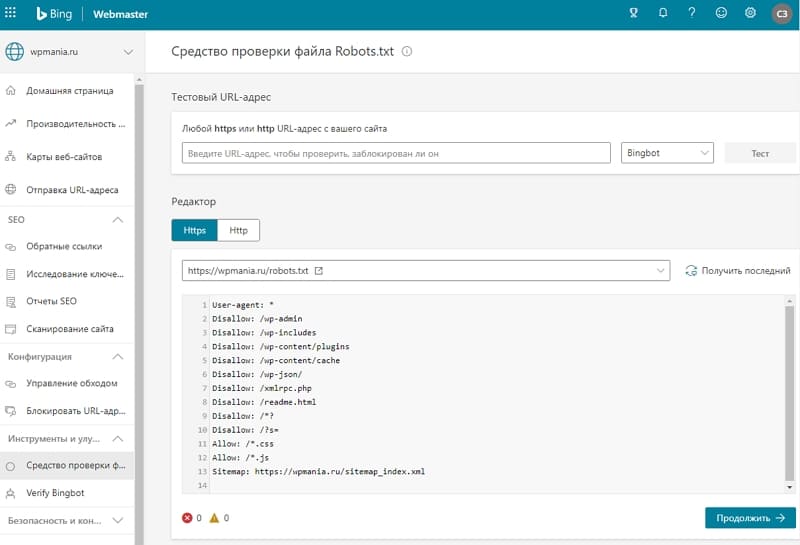 Пример такой ситуации мы рассматривали здесь.
Пример такой ситуации мы рассматривали здесь.
Также, иногда нужно:
- Скрыть от поиска техническую информацию
- Закрыть от индекса не уникальный контент
- Скрыть сквозной,повторяющийся внутри сайта, контент
- Закрыть мусорные страницы, которые нужны пользователям, но для робота выглядят как дубль
Постараемся в данной статье максимально подробно расписать инструменты при помощи которых можно закрывать контент от индексации.
Закрываем от индексации домен/поддомен:
Для того, чтобы закрыть от индексации домен, можно использовать:
1. Robots.txt
В котором прописываем такие строки.
User-agent: *
Disallow: /
При помощи данной манипуляции мы закрываем сайт от индексации всеми поисковыми системами.
При необходимости Закрыть от индексации конкретной поисковой системой, можно добавить аналогичный код, но с указанием Юзерагента.
User-agent: yandex
Disallow: /
Иногда, же бывает нужно наоборот открыть для индексации только какой-то конкретной ПС.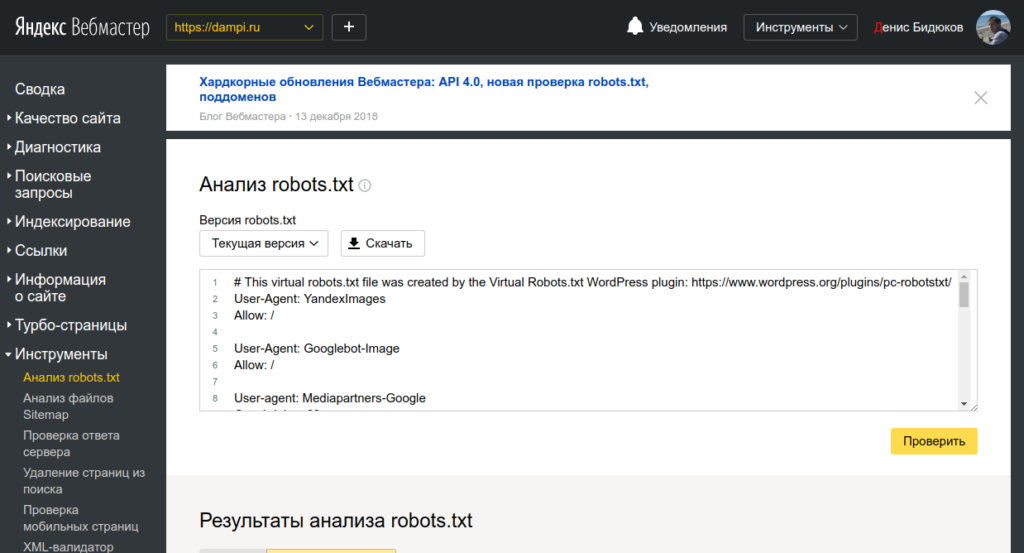 В таком случае нужно составить файл Robots.txt в таком виде:
В таком случае нужно составить файл Robots.txt в таком виде:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Таким образом мы позволяем индексировать сайт только однайо ПС. Однако минусом есть то, что при использовании такого метода, все-таки 100% гарантии не индексации нет. Однако, попадание закрытого таким образом сайта в индекс, носит скорее характер исключения.
Для того, чтобы проверить корректность вашего файла Robots.txt можно воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots.xml.
Статья в тему: Robots.txt — инструкция для SEO
2. Добавление Мета-тега Robots
Также можно закрыть домен от индексации при помощи Добавления к Код каждой страницы Тега:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Куда писать META-тег “Robots”
Как и любой META-тег он должен быть помещен в область HEAD HTML страницы:
Данный метод работает лучше чем Предыдущий, темболее его легче использовать точечно нежели Вариант с Роботсом. Хотя применение его ко всему сайту также не составит особого труда.
Хотя применение его ко всему сайту также не составит особого труда.
3. Закрытие сайта при помощи .htaccess
Для Того, чтобы открыть доступ к сайту только по паролю, нужно добавить в файл .htaccess, добавляем такой код:
После этого доступ к сайту будет возможен только после ввода пароля.
Защита от Индексации при таком методе является стопроцентной, однако есть нюанс, со сложностью просканить сайт на наличие ошибок. Не все парсеры могут проходить через процедуру Логина.
Закрываем от индексации часть текста
Очень часто случается такая ситуация, что необходимо закрыть от индексации Определенные части контента:
- меню
- текст
- часть кода.
- ссылку
Скажу сразу, что распространенный в свое время метод при помощи тега <noindex> не работает.
<noindex>Тут мог находится любой контент, который нужно было закрыть</noindex>
Однако существует альтернативный метод закрытия от индексации, который очень похож по своему принципу, а именно метод закрытия от индексации при помощи Javascript.
Закрытие контента от индексации при помощи Javacascript
При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее Данный скрипт закрывается от индексации при помощи Robots.txt
Такой Метод можно использовать для того, чтобы скрыть например Меню от индексации, для лучшего контроля над распределением ссылочного веса. К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.
Данный метод гугл не очень то одобряет, так-как он всегда говорил, что нужно отдавать одинаковый контент роботам и пользователям. И даже рассылал письма в средине прошлого года о том, что нужно открыть для индексации CSS и JS файлы.
Подробнее об этом можно почитать тут.
Однако в данный момент это один из самых действенных методов по борьбе с индексацией нежелательного контента.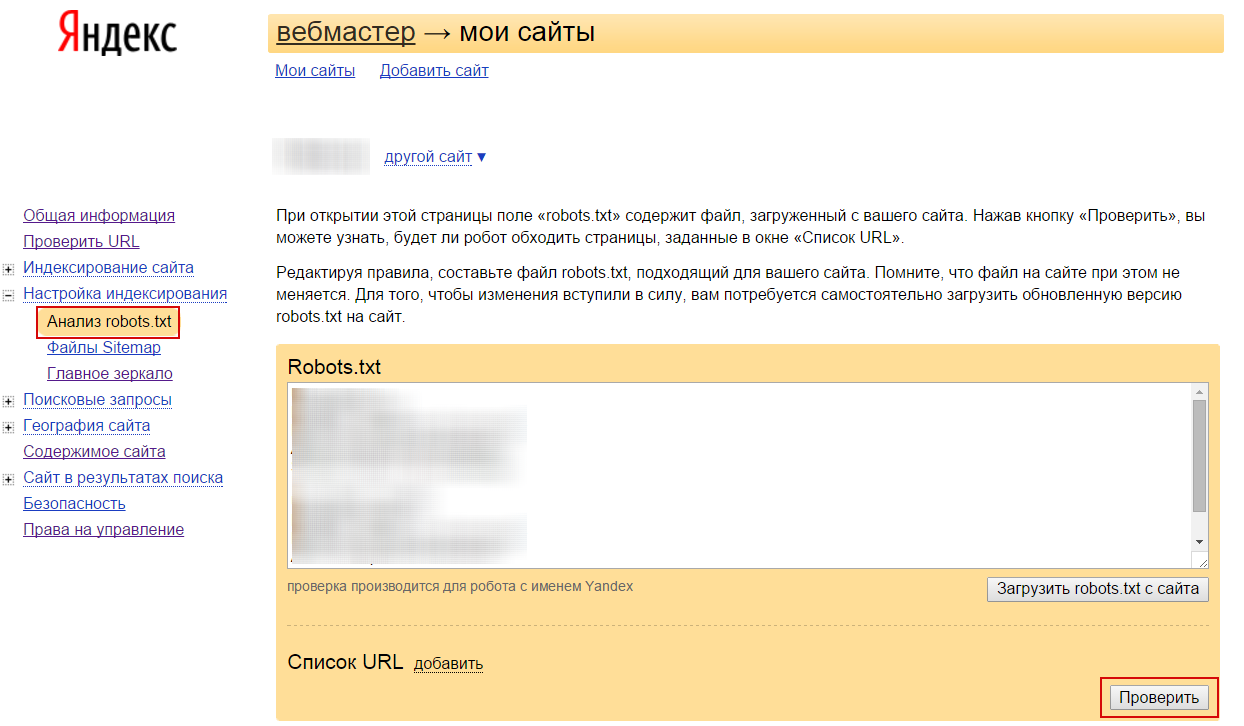
Точно также можно скрывать обычный текст, исходящие ссылки, картинки, видео материалы, счетчики, коды. И все то, что вы не хотите показывать Роботам, или что является не уникальным.
Как закрыть от индексации конкретную страницу:
Для того, чтобы закрыть от индекса конкретную страницу чаще всего используются такие методы:
- Роботс txt
- Мета robots noindex
В случае первого варианта закрытия страницы в данный файл нужно добавить такой текст:
User-agent: ag
Disallow: http://site.com/page
Таким образом данная страница не будет индексироваться с большой долей вероятности. Однако использование данного метода для точечной борьбы со страницами, которые мы не хотим отдавать на индексацию не есть оптимальным.
Так, для закрытия одной страницы от индекса лучше воспользоваться тегом
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Для этого просто нужно добавить в область HEAD HTML страницы. Данный метод позволяет не перегружать файл robots.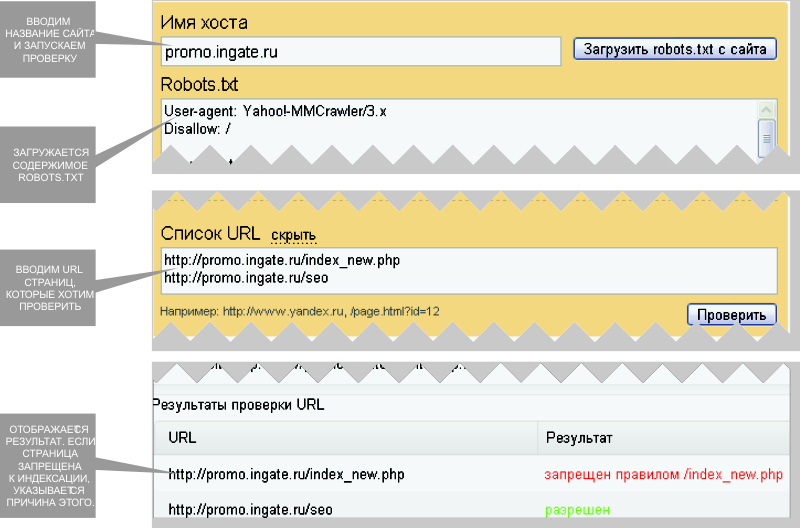 txt лишними строчками.
txt лишними строчками.
Ведь если Вам нужно будет закрыть от индекса не 1 страницу, а к примеру 100 или 200 , то нужно будет добавить 200 строк в этот файл. Но это в том случае, если все эти страницы не имеют общего параметра по которому их можно идентифицировать. Если же такой параметр есть, то их можно закрыть следующим образом.
Закрытие от индексации Раздела по параметру в URL
Для этого можно использовать 2 метода:
Рассмотрим 1 вариант
К примеру, у нас на сайте есть раздел, в котором находится неуникальная информация или Та информация, которую мы не хотим отдавать на индексацию и вся эта информация находится в 1 папке или 1 разделе сайта.
Тогда для закрытия данной ветки достаточно добавить в Robots.txt такие строки:
Если закрываем папку, то:
Disallow: /папка/
Если закрываем раздел, то:
Disallow: /Раздел/*
Также можно закрыть определенное расшерение файла:
User-agent: *
Disallow: /*.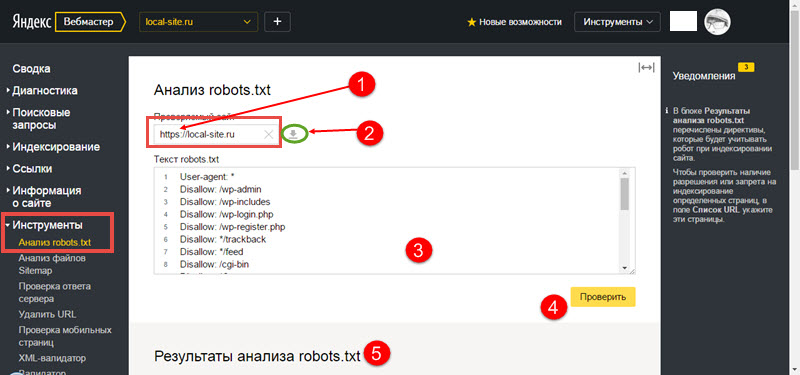 js
js
Данный метод достаточно прост в использовании, однако как всегда не гарантирует 100% неиндексации.
Потому лучше в добавок делать еще закрытие при помощи
META NAME=»ROBOTS» CONTENT=»NOINDEX”
Который должен быть добавлен в секцию Хед на каждой странице, которую нужно закрыть от индекса.
Точно также можно закрывать от индекса любые параметры Ваших УРЛ, например:
?sort
?price
?”любой повторяющийся параметр”
Однозначно самым простым вариантом является закрытие от индексации при помощи Роботс.тхт, однако, как показывает практика — это не всегда действенный метод.
Методы, с которыми нужно работать осторожно:
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.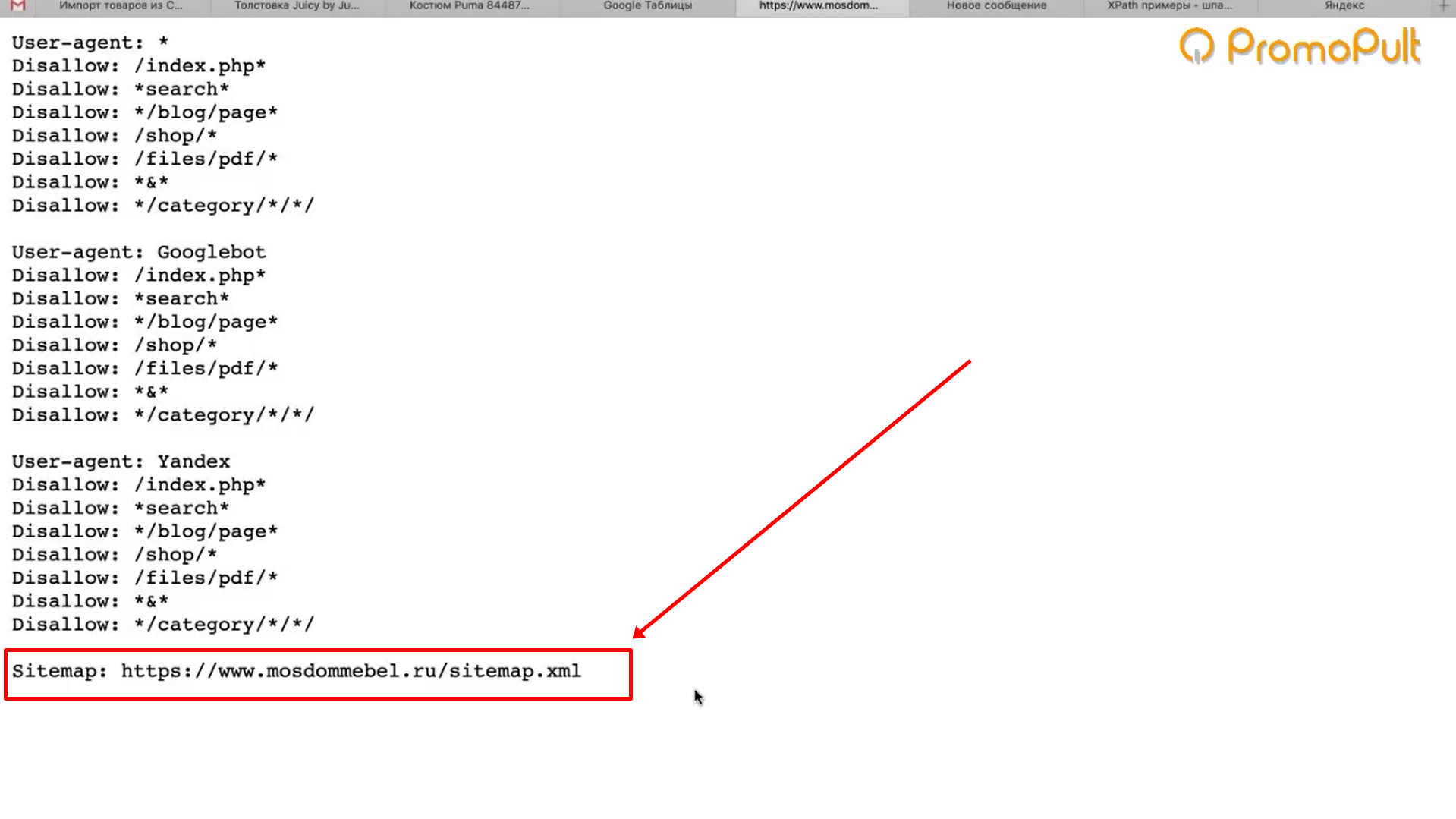
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем:
В заключение
Ситуации, когда необходимо закрыть контент от индексации случаются довольно часто, иногда нужно почистить индекс, иногда нужно скрыть какой-то нежелательный материал, иногда нужно взломать чужой сайт и в роботсе указать disalow all, чтобы выбросить сайт зеркало из индекса.
Основные и самые действенные методы мы рассмотрели, как же их применять — дело вашей фантазии и целей, которые вы преследуете.
Хорошие статьи в продолжение:
— Стоит ли открывать рубрики для индексации, если в разных рубриках выводятся одни и те же посты?
— Как открывать страницы поиска в интернет магазине — руководство
А что вы думаете по этому поводу? Давайте обсудим в комментариях!)
Оцените статью
Загрузка…
Какие страницы сайта следует закрывать от индексации поисковых систем
Индексирование сайта – это процесс, с помощью которого поисковые системы, подобные Google и Yandex, анализируют страницы веб-ресурса и вносят их в свою базу данных. Индексация выполняется специальным ботом, который заносит всю необходимую информацию о сайте в систему – веб-страницы, картинки, видеофайлы, текстовый контент и прочее. Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
В сегодняшней статье я рассмотрю, как правильно настроить индексацию, какие страницы нужно открывать для роботов, а какие нет.
Почему важно ограничивать индексацию страниц
Заинтересованность в индексации есть не только у собственника веб-ресурса, но и у поисковой системы – ей необходимо предоставить релевантную и, главное, ценную информацию для пользователя. Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Прежде чем переходить к списку ненужных страниц для индексации, давайте рассмотрим причины, из-за которых стоит запрещать их выдачу. Вот некоторые из них:
- Уникальность контента – важно, чтобы вся информация, передаваемая поисковой системе, была неповторима. При соблюдении данного критерия выдача может заметно вырасти.
 В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие. - Краулинговый бюджет – лимит, выделяемый сайту на сканирование. Другими словами, это количество страниц, которое выделяется каждому ресурсу для индексации. Такое число обычно определяется для каждого сайта индивидуально. Для лучшей выдачи рекомендуется избавиться от ненужных страниц.
 В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.В краулинговый бюджет входят: взломанные страницы, файлы CSS и JS, дубли, цепочки редиректов, страницы со спамом и прочее.
Что нужно скрывать от поисковиков
В первую очередь стоит ограничить индексирование всего сайта, который еще находится на стадии разработки. Именно так можно уберечь базу данных поисковых систем от некорректной информации. Если ваш веб-ресурс давно функционирует, но вы не знаете, какой контент стоит исключить из поисковой выдачи, то рекомендуем ознакомиться с нижеуказанными инструкциями.
PDF и прочие документы
Часто на сайтах выкладываются различные документы, относящиеся к контенту определенной страницы (такие файлы могут содержать и важную информацию, например, политику конфиденциальности).
Рекомендуется отслеживать поисковую выдачу: если заголовки PDF-файлов отображаются выше в рейтинге, чем страницы со схожим запросом, то их лучше скрыть, чтобы открыть доступ к наиболее релевантной информации. Отключить индексацию PDF и других документов вы можете в файле robots.txt.
Разрабатываемые страницы
Стоит всегда избегать индексации разрабатываемых страниц, чтобы рейтинг сайта не снизился. Используйте только те страницы, которые оптимизированы и наполнены уникальным контентом. Настроить их отображение можно в файле robots.txt.
Копии сайта
Если вам потребовалось создать копию веб-ресурса, то в этом случае также необходимо все правильно настроить. В первую очередь укажите корректное зеркало с помощью 301 редиректа. Это позволит оставить прежний рейтинг у исходного сайта: поисковая система будет понимать, где оригинал, а где копия. Если же вы решитесь использовать копию как оригинал, то делать это не рекомендуется, так как возраст сайта будет обнулен, а вместе с ним и вся репутация.
Веб-страницы для печати
Иногда контент сайта требует уникальных функций, которые могут быть полезны для клиентов. Одной из таких является «Печать», позволяющая распечатать необходимые страницы на принтере. Создание такой версии страницы выполняется через дублирование, поэтому поисковые роботы могут с легкостью установить копию как приоритетную. Чтобы правильно оптимизировать такой контент, необходимо отключить индексацию веб-страниц для печати. Сделать это можно с использованием AJAX, метатегом <meta name=»robots» content=»noindex, follow»/> либо в файле robots.txt.
Формы и прочие элементы сайта
Большинство сайтов сейчас невозможно представить без таких элементов, как личный кабинет, корзина пользователя, форма обратной связи или регистрации. Несомненно, это важная часть структуры веб-ресурса, но в то же время она совсем бесполезна для поисковых запросов. Подобные типы страниц необходимо скрывать от любых поисковиков.
Страницы служебного пользования
Формы авторизации в панель управления и другие страницы, используемые администратором сайта, не несут никакой важной информации для обычного пользователя. Поэтому все служебные страницы следует исключить из индексации.
Личные данные пользователя
Вся персональная информация должна быть надежно защищена – позаботиться о ее исключении из поисковой выдачи нужно незамедлительно. Это относится к данным о платежах, контактам и прочей информации, идентифицирующей конкретного пользователя.
Страницы с результатами поиска по сайту
Как и в случае со страницами, содержащими личные данные пользователей, индексация такого контента не нужна: веб-страницы результатов полезны для клиента, но не для поисковых систем, так как содержат неуникальное содержание.
Сортировочные страницы
Контент на таких веб-страницах обычно дублируется, хоть и частично. Однако индексация таких страниц посчитается поисковыми системами как дублирование. Чтобы снизить риск возникновения таких проблем, рекомендуется отказаться от подобного контента в поисковой выдаче.
Однако индексация таких страниц посчитается поисковыми системами как дублирование. Чтобы снизить риск возникновения таких проблем, рекомендуется отказаться от подобного контента в поисковой выдаче.
Пагинация на сайте
Пагинация – без нее сложно представить существование любого крупного веб-сайта. Чтобы понять ее назначение, приведу небольшой пример: до появления типичных книг использовались свитки, на которых прописывался текст. Прочитать его можно было путем развертывания (что не очень удобно). На таком длинном холсте сложно найти нужную информацию, нежели в обычной книге. Без использования пагинации отыскать подходящий раздел или товар также проблематично.
Пагинация позволяет разделить большой массив данных на отдельные страницы для удобства использования. Отключать индексирование для такого типа контента нежелательно, требуется только настроить атрибуты rel=»canonical», rel=»prev» и rel=»next». Для Google нужно указать, какие параметры разбивают страницы – сделать это можно в Google Search Console в разделе «Параметры URL».
Помимо всего вышесказанного, рекомендуется закрывать такие типы страниц, как лендинги для контекстной рекламы, страницы с результатами поиска по сайту и поиск по сайту в целом, страницы с UTM-метками.
Какие страницы нужно индексировать
Ограничение страниц для поисковых систем зачастую становится проблемой – владельцы сайтов начинают с этим затягивать или случайно перекрывают важный контент. Чтобы избежать таких ошибок, рекомендуем ознакомиться с нижеуказанным списком страниц, которые нужно оставлять во время настройки индексации сайта.
- В некоторых случаях могут появляться страницы-дубликаты. Часто это связано со случайным созданием дублирующих категорий, привязкой товаров к нескольким категориям и их доступность по различным ссылкам. Для такого контента не нужно сразу же бежать и отключать индексацию: сначала проанализируйте каждую страницу и посмотрите, какой объем трафика был получен. И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
- Страницы смарт-фильтра – благодаря им можно увеличить трафик за счет низкочастотных запросов. Важно, чтобы были правильно настроены мета-теги, 404 ошибки для пустых веб-страниц и карта сайта.

Соблюдение индексации таких страниц может значительно улучшить поисковую выдачу, если ранее оптимизация не проводилась.
Как закрыть страницы от индексации
Мы детально рассмотрели список всех страниц, которые следует закрывать от поисковых роботов, но о том, как это сделать, прошлись лишь вскользь – давайте это исправлять. Выполнить это можно несколькими способами: с помощью файла robots.txt, добавления специальных метатегов, кода, сервисов для вебмастеров, а также с использованием дополнительных плагинов. Рассмотрим каждый метод более детально.
Способ 1: Файл robots.txt
Данный текстовый документ – это файл, который первым делом посещают поисковики. Он предоставляет им информацию о том, какие страницы и файлы на сайте можно обрабатывать, а какие нет.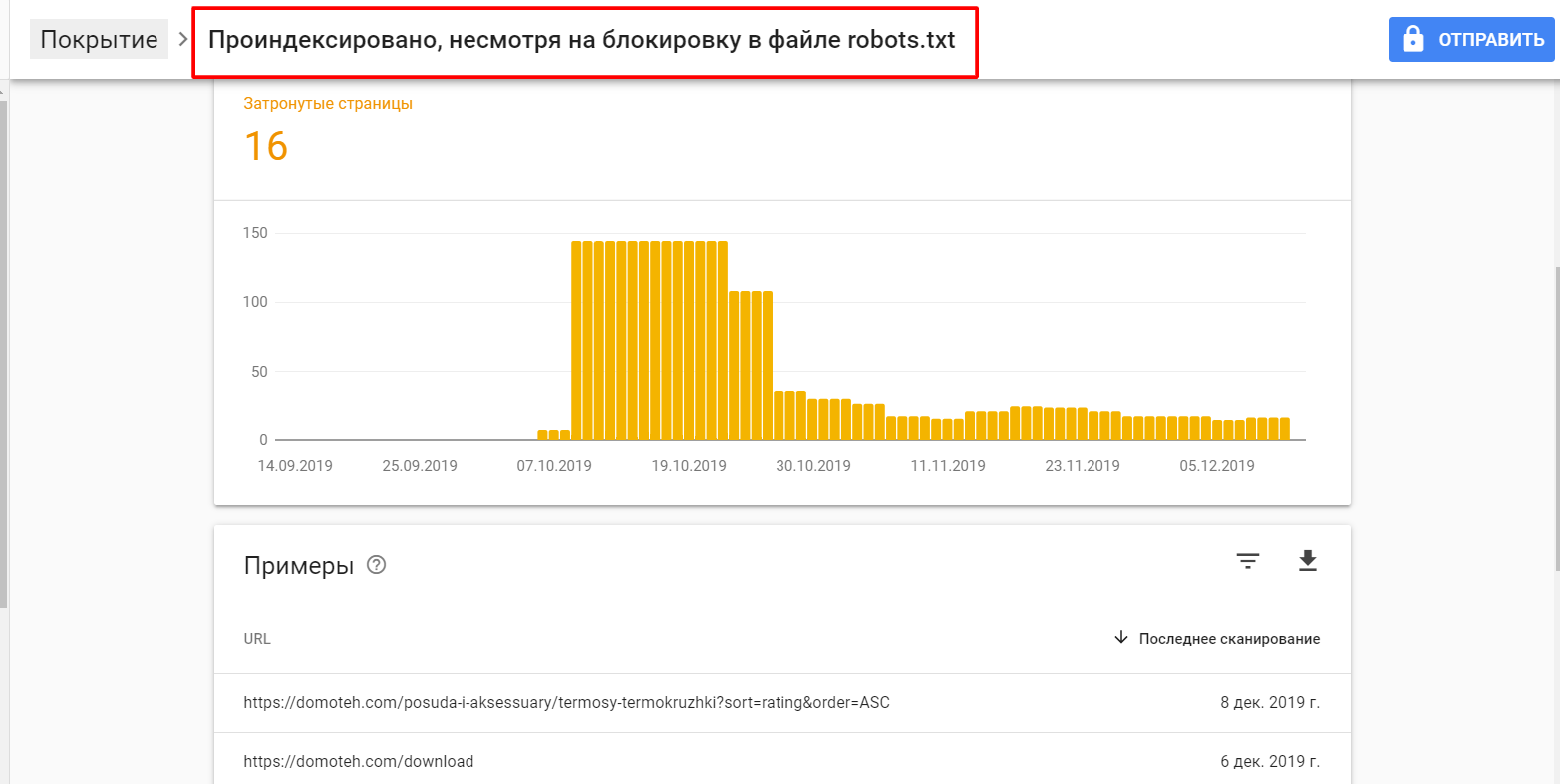 Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
- наименование прописано в нижнем регистре;
- формат указан как .txt;
- размер не должен превышать 500 Кб;
- местоположение – корень сайта;
- находится по адресу URL/robots.txt, при запросе сервер отправляет в ответ код 200.
Прежде чем переходить к редактированию файла, рекомендую обратить внимание на ограничивающие факторы.
- Директивы robots.txt поддерживаются не всеми поисковыми системами. Большинство поисковых роботов следуют тому, что написано в данном файле, но не всегда придерживаются правил. Чтобы полностью скрыть информацию от поисковиков, рекомендуется воспользоваться другими способами.
- Синтаксис может интерпретироваться по-разному в зависимости от поисковой системы. Потребуется узнать о синтаксисе в правилах конкретного поисковика.
- Запрещенные страницы в файле могут быть проиндексированы при наличии ссылок из прочих источников. По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.
 По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.
По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.Файл robots.txt включает в себя такие параметры, как:
- User-agent – создает указание конкретному роботу.
- Disallow – дает рекомендацию, какую именно информацию не стоит сканировать.
- Allow – аналогичен предыдущему параметру, но в обратную сторону.
- Sitemap – позволяет указать расположение карты сайта sitemap.xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.
- Clean-param – позволяет убрать из индекса страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
- Crawl-delay – снижает нагрузку на сервер в том случае, если посещаемость поисковых ботов слишком велика. Обычно используется на сайтах с большим количеством страниц.
 Обычно используется на сайтах с большим количеством страниц.
Обычно используется на сайтах с большим количеством страниц.Теперь давайте рассмотрим, как можно отключить индексацию определенных страниц или всего сайта. Все пути в примерах – условные.
Пропишите, чтобы исключить индексацию сайта для всех роботов:
User-agent: * Disallow: /
Закрывает все поисковики, кроме одного:
User-agent: * Disallow: / User-agent: Google Allow: /
Запрет на индексацию одной страницы:
User-agent: * Disallow: /page.html
Закрыть раздел:
User-agent: * Disallow: /category
Все разделы, кроме одного:
User-agent: * Disallow: / Allow: /category
Все директории, кроме нужной поддиректории:
User-agent: * Disallow: /direct Allow: /direct/subdirect
Скрыть директорию, кроме указанного файла:
User-agent: * Disallow: /category Allow: photo.png
Заблокировать UTM-метки:
User-agent: * Disallow: *utm=
Заблокировать скрипты:
User-agent: * Disallow: /scripts/*.
 js
jsЯ рассмотрел один из главных файлов, просматриваемых поисковыми роботами. Он использует лишь рекомендации, и не все правила могут быть корректно восприняты.
Способ 2: HTML-код
Отключение индексации можно осуществить также с помощью метатегов в блоке <head>. Обратите внимание на атрибут «content», он позволяет:
- активировать индексацию всей страницы;
- деактивировать индексацию всей страницы, кроме ссылок;
- разрешить индексацию ссылок;
- индексировать страницу, но запрещать ссылки;
- полностью индексировать веб-страницу.
Чтобы указать поискового робота, необходимо изменить атрибут «name», где устанавливается значение yandex для Яндекса и googlebot – для Гугла.
Пример запрета индексации всей страницы и ссылок для Google:
<html>
<head>
<meta name="googlebot" content="noindex, nofollow" />
</head>
<body>... Yandex" search_bot Yandex" search_bot
Yandex" search_botСпособ 4: Для WordPress
На CMS запретить индексирование всего сайта или страницы гораздо проще. Рассмотрим, как это можно сделать.
Как скрыть весь сайт
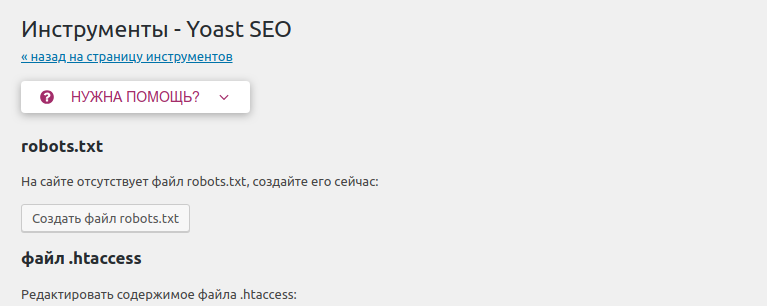
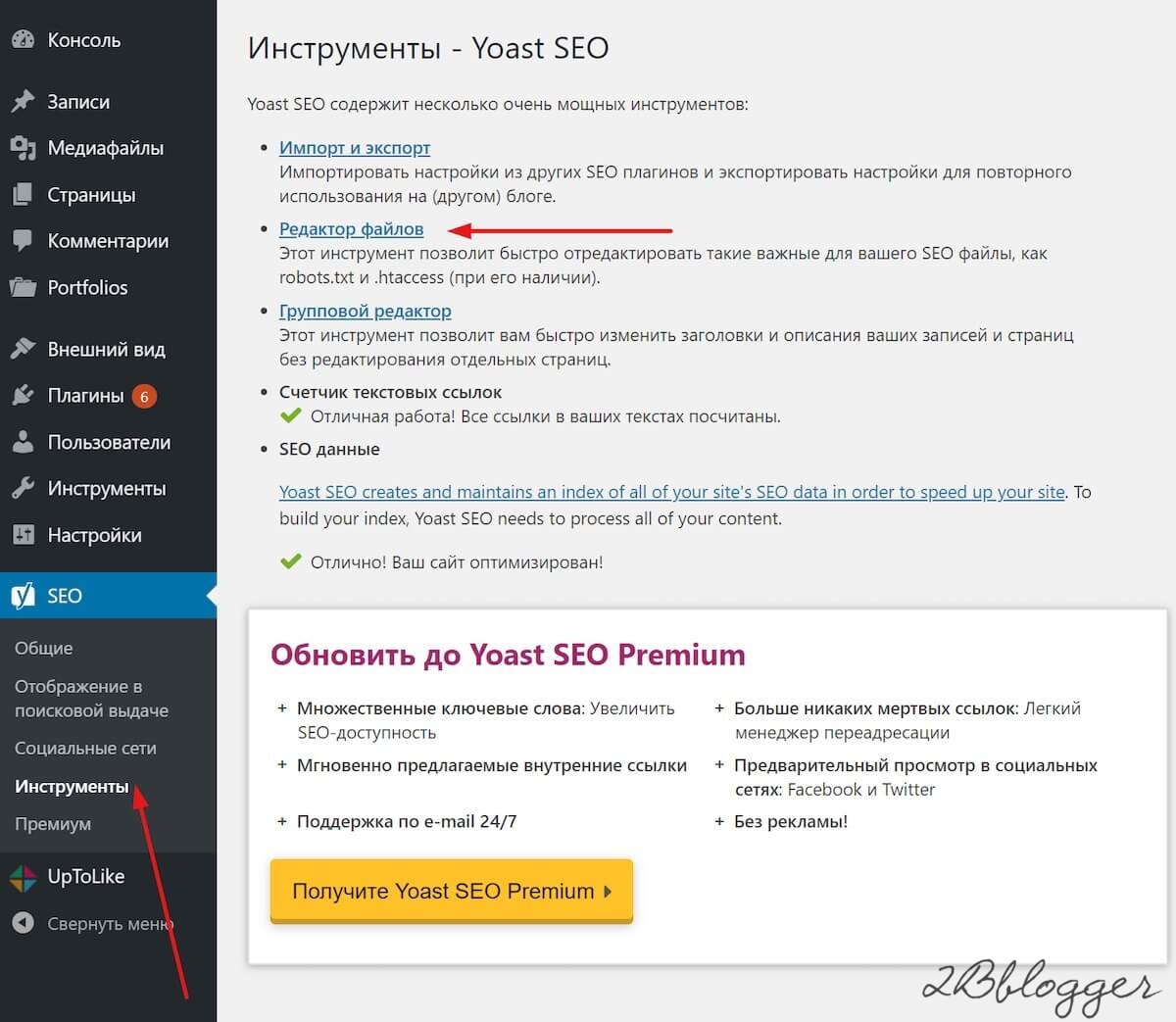
Открываем административную панель WordPress и переходим в раздел «Настройки» через левое меню. Затем перемещаемся в «Чтение» – там находим пункт «Попросить поисковые системы не индексировать сайт» и отмечаем его галочкой.
В завершение кликаем по кнопке «Сохранить изменения» – после этого система автоматически отредактирует файл robots.txt.
Как скрыть отдельную страницу
Для этого необходимо установить плагин Yoast SEO. После этого открыть страницу для редактирования и промотать в самый низ – там во вкладке «Дополнительно» указать значение «Нет».
Способ 5: Сервисы для вебмастеров
В Google Search Console мы можем убрать определенную страницу из поисковика. Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Процедура запрета на индексацию выбранной страницы может занять некоторое время. Аналогичные действия можно совершить в Яндекс.Вебмастере.
На этом статья подходит к концу. Надеюсь, что она была полезной. Теперь вы знаете, что такое индексация сайта и как ее правильно настроить. Удачи!
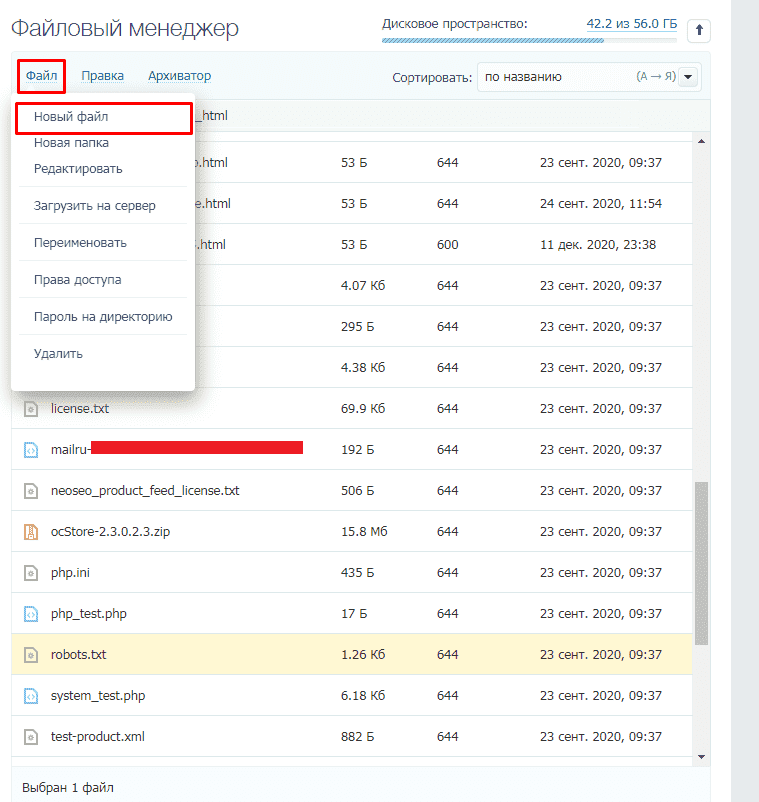
Запрет индексации страниц/директорий через robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов.
Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx. txt нет в каталоге вашего сайта, тогда вы можете его создать.
txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
- User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
- Disallow: / # будет запрещено индексирование всего сайта
- Disallow: /page/ # будет запрещено индексирование директории /page/
Примеры:
Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots. txt):
txt):
User-agent: *
Disallow:
Пример:
Разрешить индексировать сайт только ботам Yandex, Google, Rambler с задержкой 4сек между опросами страниц.
User-agent: *
Disallow: /
User-agent: Yandex
Crawl-delay: 4
Disallow:
User-agent: Googlebot
Crawl-delay: 4
Disallow:
User-agent: StackRambler
Crawl-delay: 4
Disallow:
Закрыть сайт от индексации ᐈ Способы запретить индексацию
Содержание:
Индексация и способы закрыть информацию сайта
Индексация. Закрыть домен (или поддомен)
Индексация. Закрыть информацию по частям
Индексация. Закрыть отдельные страницы ресурса
Индексация и использование URL
Индексация и сомнительные способы закрытия контента
Индексация. Итоги
Индексация очень полезная вещь, однако бывают случаи, когда владельцам сайтов или вебмастерам нужно закрыть часть информации от индексации поисковых систем. Или же запретить обращение к ней. Часть из таких ситуаций можно перечислить:
Или же запретить обращение к ней. Часть из таких ситуаций можно перечислить:
- Необходимость закрыть техническую информацию.
- Запрещение индексации неуникальной информации.
- Закрыть страницы, которые для поискового робота выглядят как дубль другой страницы. При этом такие адреса могут быть полезны рядовому пользователю.
- Часто сайт может использовать на разных страницах повторяющуюся информацию. Для лучшей оптимизации сайта ее нужно закрыть от постороннего взгляда.
Есть несколько способов закрыть сайт от взгляда поисковика.
Используем robots.txt
В этом файле нужно прописать такие ряды:
User-agent: *
Disallow: /
От этого закрывается отображение домена для абсолютно всех поисковиков. Но если есть желание исключить лишь одну систему, следует указать ее название. Пример:
User-agent: Yahoo
Disallow: /
Также существует возможность запретить доступ всем поисковикам, кроме одного. Тогда оставляем строки без изменений, как в первом примере и ниже добавляем еще два ряда:
Тогда оставляем строки без изменений, как в первом примере и ниже добавляем еще два ряда:
User-agent: Yahoo
Allow: /
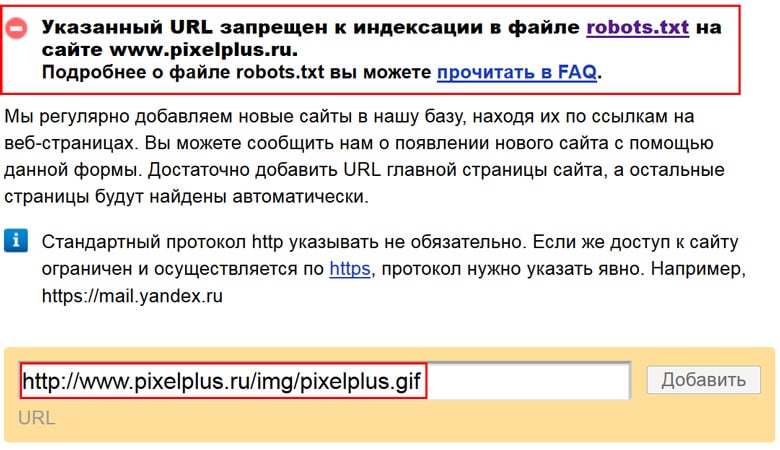
Минусом такого способа является не стопроцентная гарантия отсутствия индексации. Это маловероятно, но все же возможно. Для правильной корректировки роботс.txt используем онлайн-инструмент от Yandex. Держите ссылку http://webmaster.yandex.ru/robots.xml. Загружаем свой файл и сканируем его.
Использование мета-тега
Это очень легкий, но довольно затратный по времени метод. Особенно, если на вашем сайте существует большое количество страниц. Для его реализации необходимо в head нужных адресов указать ряды:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Такой способ абсолютно защищает ваш сайт от взгляда поисковиков. Его плюсом является отсутствия необходимости лезть роботс.
Индексация. Изменение атрибутов файла .htaccess
Этот способ позволяет закрыть доступ к ресурсу за паролем. В htaccess указываем ряды:
Такой способ также полностью закрывает доступ поисковикам к контенту сайта.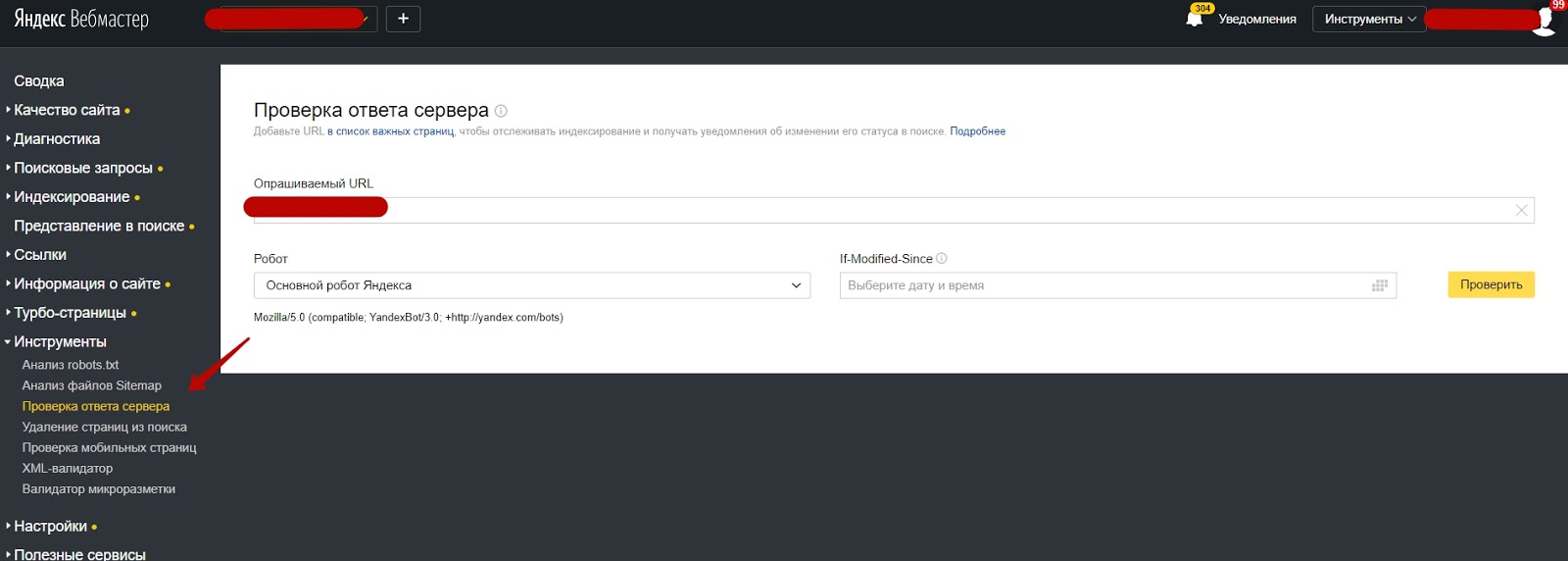 Однако из-за наличия пароля сайт становится очень тяжело просканировать на наличие ошибок. Поскольку не все сервисы имеют возможность вводить пароль.
Однако из-за наличия пароля сайт становится очень тяжело просканировать на наличие ошибок. Поскольку не все сервисы имеют возможность вводить пароль.
Есть множество вещей, доступ к которым следует закрыть (код, отдельный текст, ссылку на другие сайты, элементы меню), не закрывая при этом сам адрес. Сейчас очень популярный ранее метод с помощью noindex уже не используется. Его суть состояла в том, что в отдельный тег существовала возможность скопировать всю информацию, которую нужно было закрыть. Теперь мегапопулярным стал другой способ.
Использование JavaScript
В этом способе снова нужно использовать файл роботс. Его суть предполагает, что вся нужная информация кодируется с помощью яваскрипт, а после копируется в роботс и скрывается от индексации с помощью нужных тегов. Этот метод уменьшает «вес» ресурса, при его использовании быстродействие сайта увеличивается. Поэтому возможно улучшение ранжирования. Но есть один существенный минус. Google не одобряет данный способ и регулярно отсылает владельцам сайтов письма с просьбой открыть для индексации сокрытую информацию. По его заверениям информация должна быть идентичной и для пользователя, и для поискового робота.
По его заверениям информация должна быть идентичной и для пользователя, и для поискового робота.
Но несмотря на все усилия корпорации, этот способ остается достаточно популярным из-за эффективности.
Есть два способа, которые используются, чтобы закрыть ссылку на страницу от индексации.
Robots.txt
Для реализации первого способа добавляем в файл robots.txt такие строки:
User-agent: ag
Disallow: http://example.com/main
Это простой способ, но он не отличается надежностью. Страницы могут продолжать индексироваться. Но чтобы запретить их отображение, можно использовать еще один способ:
Мета-тег noindex
Второй способ является лучшим вариантом, поскольку в нем исключается воздействие роботс. Для его реализации в head всеx адресов, которые нужно закрыть от взгляда поисковых систем, вставляем тег:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Такой способ намного эффективнее использовать большим ресурсам, которым нужно закрывать больше сотни страниц. Однако, тогда у них отсутствует общий параметр.
Однако, тогда у них отсутствует общий параметр.
Robots.txt
И снова вмешательство в этот файл поможет нам избежать индексации страниц. Добавляя в тег Disallow названия разделов и папок, мы можем исключать их из индексации. Примеры:
Disallow: /название папки/
Disallow: /название раздела/
Такой способ удобный, быстрый и простой в применении. Но он также полностью не гарантирует отсутствие индексирования нужных страниц. Поэтому мы рекомендуем использование мета-тега noidex в способе, описанном выше.
Редактирование файла robots.txt однозначно остается самым легким способом закрытия контента от индексации. Но в любом случае он больше нагружает файл, что скажется на быстродействии ресурса и его ранжировании. Тем более, чаще всего эти способы не гарантируют стопроцентную эффективность.
Есть возможность закрыть доступ для поисковых систем на уровне сервера.
Добавляем в бан отдельных User Agents
Такой способ позволяет заблокировать пользователя или робота, указав его нежелательным или опасным. Это позволяет запретить доступ к контенту своим конкурентам.
Это позволяет запретить доступ к контенту своим конкурентам.
Способ используется для того, чтобы закрыть информацию от роботов онлайн-сервисов, которые анализируют источники трафика сайта, а также сео-оптимизации.
Это очень опасный метод, который часто приводит к нежелательным последствиям. Поэтому если вы не уверены в своих силах, следует обратиться к профессионалу.
Изменение HTTP-заголовка
Существует возможность прописать тег X-Robots как заголовок отдельной страницы. Такие методы идентичны тем, которые мы использовали при редактировании файла robots.txt. Нужно только указать имя пользователя (название поисковой системы).
Конкуренция в интернете с каждым днем вырастает все выше и напоминает промышленное шпионство больших корпораций. Поэтому владельцы сайтов и вебмастера вынуждены использовать любые способы, чтобы закрыть от посторонних глаз свою стратегию продвижения и способы сео-оптимизации.
Однако подобные методы используются и в банальных целях.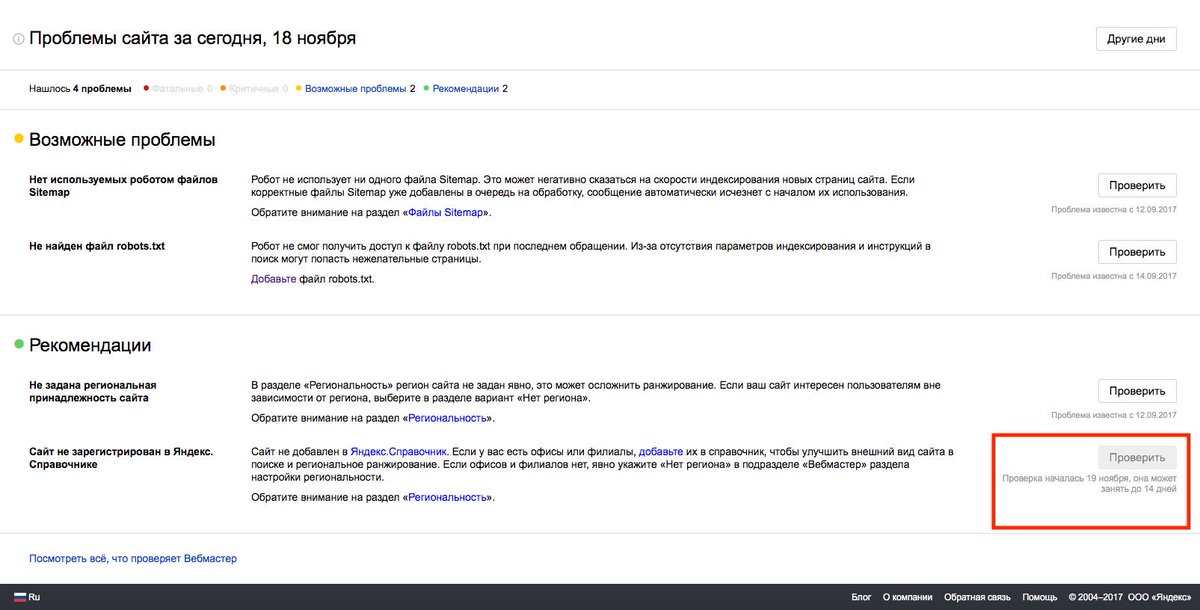 Например, чтобы закрыть от индексации «мусор» на страницах ресурса. Как видим, индексация имеет две стороны.
Например, чтобы закрыть от индексации «мусор» на страницах ресурса. Как видим, индексация имеет две стороны.
Перечисленные выше методы не панацея, поэтому при недостаточных знаниях лучше обращаться к профессионалу.
Запрет индексации сайта поисковыми системами. Самостоятельно проверяем и меняем файл robots.txt. Зачем закрывать сайт от индексации?
Зачем закрывать сайт от индексации? Проверяем и меняем файл robots.txt самостоятельно.
Ответ
Для закрытия всего сайта от индексации во всех поисковых системах необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
Далее, подробнее разберемся в вопросе подробнее и ответим на
другие вопросы:
- Процесс индексации что это?
- Зачем закрывать сайт от индексации?
- Инструкции по изменению файла robots.txt
- Проверка корректности закрытия сайта от
индексации - Альтернативные способы закрыть сайт от поисковых
систем
 youtube.com/embed/HfSJlKnGZ6o» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/HfSJlKnGZ6o» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Оглавление
Процесс индексации
Индексация сайта – это процесс добавления данных вашего ресурса в индексную базу поисковых систем. Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Именно в этой базе и происходит поиск информации в тот
момент, когда вы вводите любой запрос в строку поиска:
Именно из индексной базы поисковая система в момент ввода запроса производит поиск информации.
Если сайта нет в индексной базе поисковой системе = тогда
сайте нет и в поисковой выдаче. Его невозможно будет найти по поисковым
запросам.
В каких случаях может потребоваться исключать сайт из баз поисковых систем?
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых
систем может быть множество.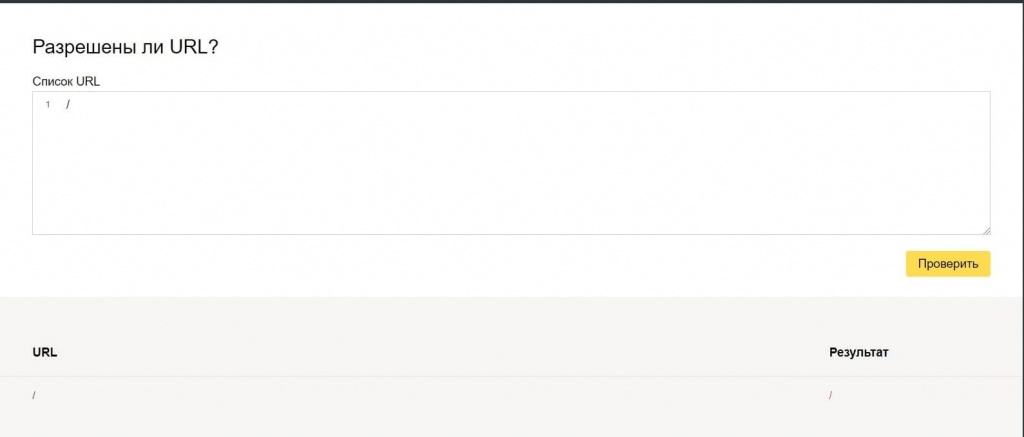 Мы не можем знать личных мотивов всех вебмастеров.
Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.
Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы
находитесь в стадии разработки (или доработки) ресурса. В таком случае его
лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в
индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной
готовности и наполненности контентом.
Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.
Другие мотивы
Может быть целый ряд других личных причин закрытия сайта от индексации поисковыми системами. Можете написать в комментариях Вашу причину закрытия сайта от индексации.
Закрываем сайт от индексации в robots.txt
Обращение к Вашему сайту поисковой системой начинается с
прочтения содержимого файла robots.txt. Это служебный файл со специальными
правилами для поисковых роботов.
Подробнее о директивах robots.txt:
Самый простой и быстрый способ это при первом обращении к
вашему ресурсу со стороны поисковых систем (к файлу robots. txt) сообщить
txt) сообщить
поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от
задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
| Закрыть во всех системах | Закрыть только в Яндекс | Закрыть только в Google |
| User-agent: * Disallow: / | User-agent: Yandex Disallow: / | User-agent: Googlebot Disallow: / |
Инструкция по изменению файла robots.txt
Мы не ставим целью дать подробную инструкцию по всем
способам подключения к хостингу или серверу, укажем самый простой способ на наш
взгляд.
Файл robots.txt всегда находится в корне Вашего сайта.
Например, robots.txt сайта iqad.ru будет
находится по адресу:
https://iqad.ru/robots.txt
Для подключения к сайту, мы должны в административной панели
нашего хостинг провайдера получить FTP (специальный протокол передачи файлов
по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
Авторизуемся в панели управления вашим хостингом и\или сервером, находим раздел FTP и создаем ( получаем ) уникальную пару логин \ пароль.
В описании
раздела или в разделе помощь, необходимо
найти и сохранить необходимую информацию для подключения по FTP к серверу,
на котором размещены файлы Вашего сайта. Данные отражают информацию, которую
нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно
воспользоваться бесплатной программой filezilla (https://filezilla.ru/).
Вводим данные в соответствующие поля и нажимаем подключиться.
FTP-клиент filezilla интуитивно прост и понятен: вводим cервер (host) + логин (имя пользователя) + пароль + порт и кнопка {быстрое соединение}.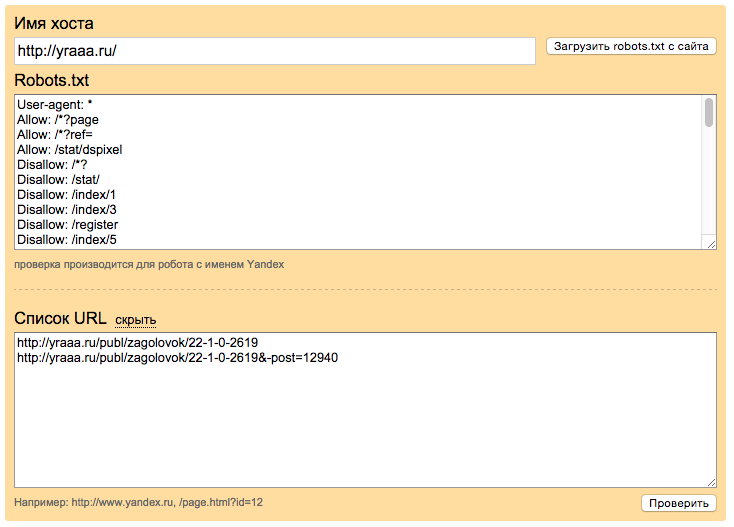 В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
После подключения прописываем необходимые директивы. См.
раздел:
Закрываем сайт от индексации в robots.txt
Проверка корректности закрытия сайта от индексации
После того, как вы внесли все необходимые коррективы в файл robots.txt
необходимо убедится в том, что все сделано верно. Для этого открываем файл
robots.txt
на вашем сайте.
Инструменты iqad
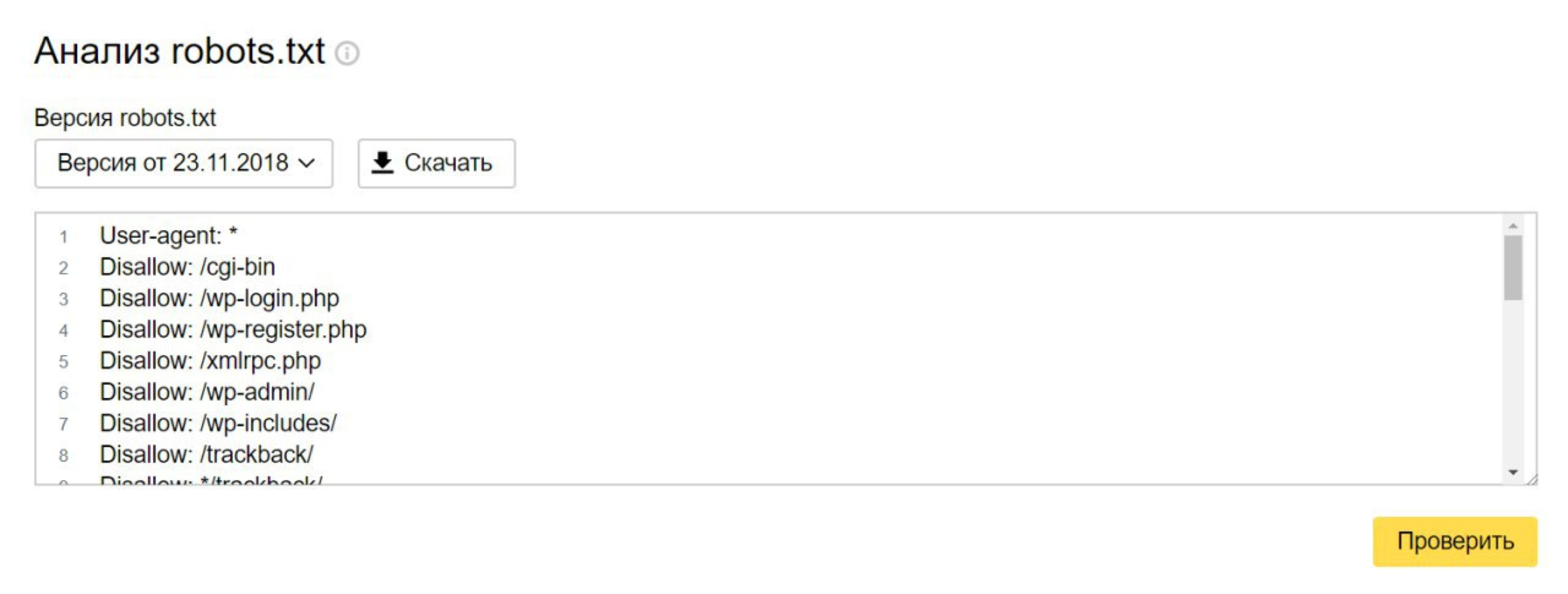
В арсенале команды IQAD есть набор бесплатных инструментов для SEO-оптимизаторов. Вы можете воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Самостоятельно
Открыть самостоятельно, файл находится корне Вашего сайта, по адресу:
www.site.ru/robots.txt
Где www.site.ru – адрес Вашего сайта.
Сервис Я.ВЕБМАСТЕР
Бесплатный сервис Я.ВЕБМАСТЕР – анализ robots.txt.
Бесплатный сервис ЯНДЕКС.ВЕБМАСТЕР проверит ваш robots.txt, покажет какими секциями Вашего файла пользуется поисковая система Яндекс:
Так же, в сервисе можно проверить запрещена ли та или иная страница вашего сайта к индексации:
Достаточно в специальное поле внести интересующие Вас страницы и ниже отобразится результат.
Альтернативные способы закрыть сайт от поисковых систем
Помимо классического
способа с использованием файла robots.txt можно прибегнуть и к другим, не
стандартным, подходам. Однако у них есть ряд недостатков.
- Вы можете
отдавать поисковым роботам отличный от 200 код ответа сервера. Но это не
гарантирует 100% исключения сайта из индекса. Какое-то время робот может
хранить копию Ваших страниц и отдавать именно их. - С помощью специального
meta тега: <meta name=”robots”>
<meta name=”robots” content=”noindex, nofollow”>
Но
так как метатег размещается и его действие относиться только к 1 странице, то
для полного закрытия сайта от индексации Вам придется разместить такой тег на
каждой странице Вашего сайта.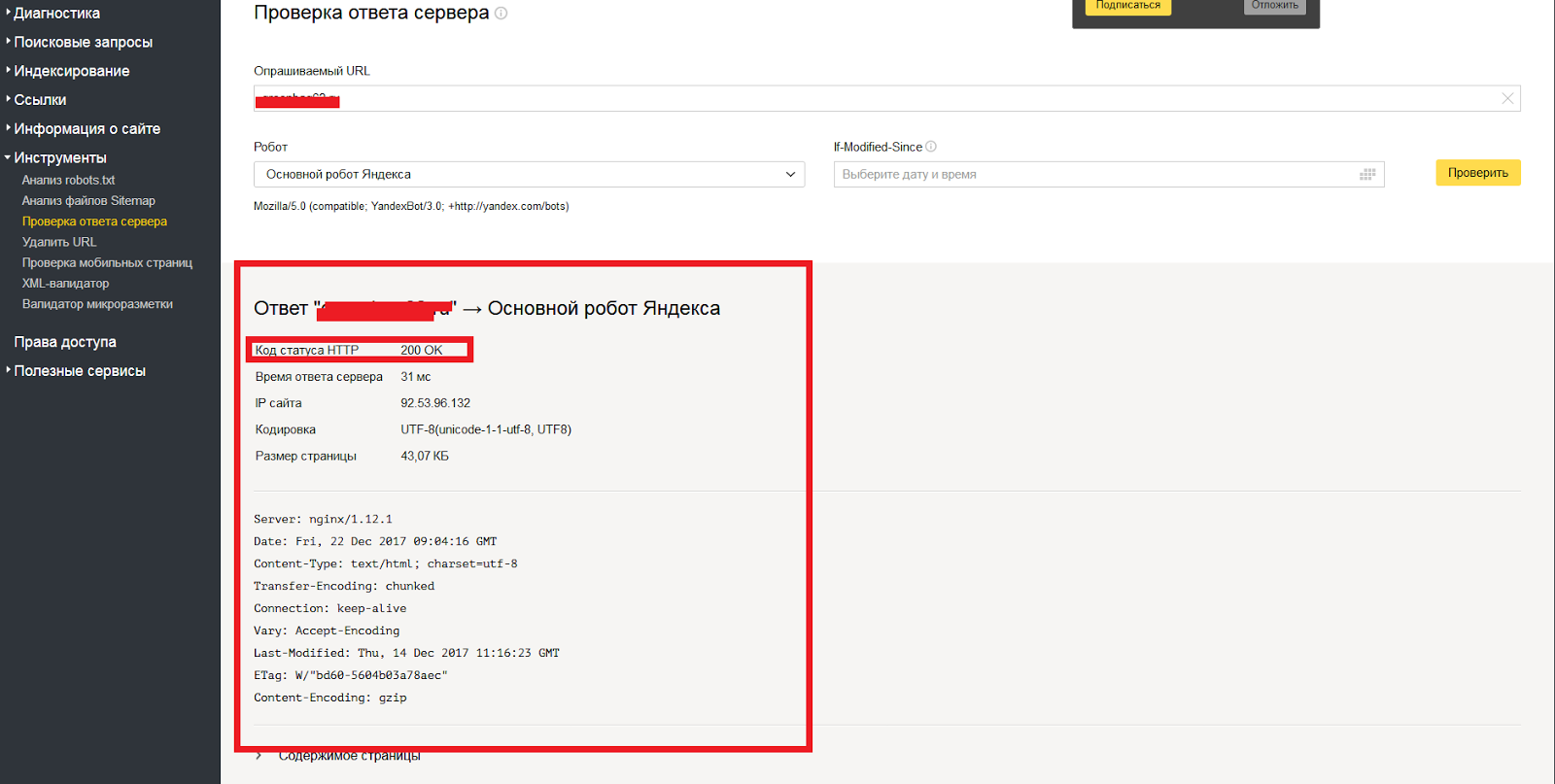
Недостатком
этого может быть несовершенство поисковых систем и проблемы с индексацией
ресурса. Пока робот не переиндексирует весь сайт, а на это может потребоваться
много времени, иногда несколько месяцев, часть страниц будет присутствовать в
поиске.
- Использование
технологий, усложняющих индексацию Вашего сайта. Вы можете спрятать контент
Вашего сайта под AJAX или скриптами. Таким образом поисковая система не сможет
увидеть контент сайта. При этом по названию сайта или по открытой части в
индексе поисковиков может что-то хранится. Более того, уже завра новое
обновление поисковых роботов может научится индексировать такой контент. - Скрыть все
данные Вашего сайта за регистрационной формой. При этом стартовая страница в
любом случае будет доступна поисковым роботам.
Заключение
Самым простым способом закрыть сайт от индексации, во всех поисковых системах, необходимо в файле
robots.txt прописать следующую директиву:
Disallow: /
«robots. txt» это служебный файл со специальными правилами для поисковых роботов.
txt» это служебный файл со специальными правилами для поисковых роботов.
Файл robots.txt всегда находится в корне Вашего сайта. Для изменения
директив файла Вам потребуется любой FTP-клиент.
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков. Для проверки текущих директив Вашего сайта предлагаем воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Управление robots.txt
Общие правила
Данная вкладка служит для указания общих правил для индексирования сайта поисковыми системами. В поле отображается текущий набор инструкций. Любая из инструкций (кроме User-Agent: *) может быть удалена, если навести на нее курсор мыши и нажать на «крестик». Для генерации инструкций необходимо воспользоваться кнопками, расположенными рядом с полем.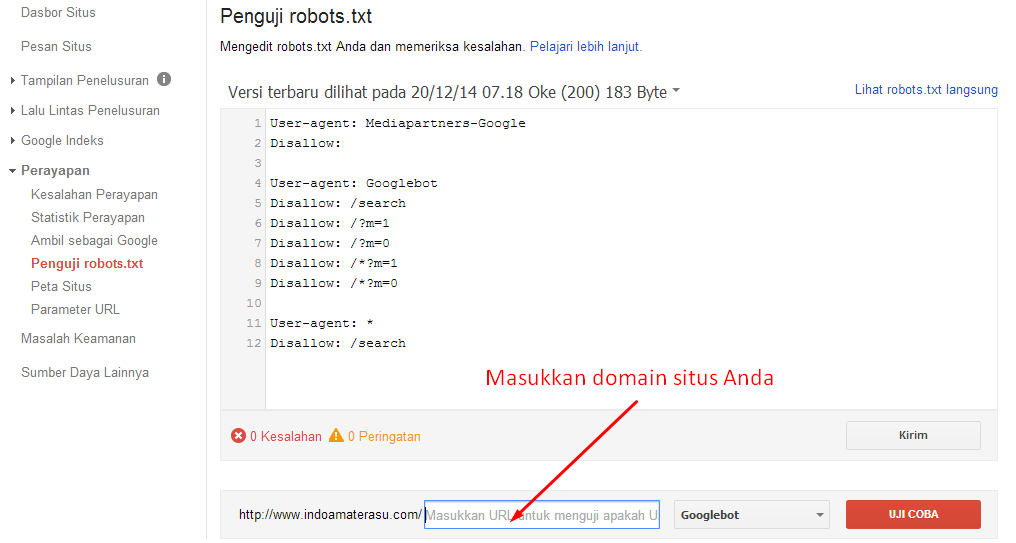.png)
| Кнопка | Описание |
|---|---|
| Стартовый набор | Позволяет задать набор стандартных правил и ограничений (закрываются от индексации административные страницы, личные данные пользователя, отладочная информация).
Если часть стандартного набора уже задана, то будут добавлены только необходимые отсутствующие инструкции. |
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации.  В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы.
|
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами. |
| Интервал между запросами (Crawl-delay) | Служит для указания минимального временного интервала (в сек.) между запросами поискового робота. |
| Карта сайта | Позволяет задать ссылку к файлу карты сайта sitemap.xml. |
Яндекс
Настройка правил и ограничений для роботов Яндекса. Настройку можно выполнить как сразу для всех роботов Яндекса (вкладка «Yandex»), так и каждого в отдельности (на вкладке с соответствующим названием робота). Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
| Кнопка | Описание |
|---|---|
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. |
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами.
Важно! Для каждого файла robots.txt обрабатывается только одна директива Host. |
| Интервал между запросами (Crawl-delay) | Служит для указания минимального временного интервала (в сек. ) между запросами поискового робота. ) между запросами поискового робота. |
Настройка правил и ограничений для роботов Google. Настройка выполняется для каждого робота в отдельности (на вкладке с соответствующим названием робота). Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
| Кнопка | Описание |
|---|---|
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации.  В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы.
|
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами.
Важно! Для каждого файла robots.txt обрабатывается только одна директива Host. |
Редактировать
На данной вкладке представлено текстовое поле, в котором можно вручную отредактировать содержимое файла robots.txt.
Смотрите также
© «Битрикс»,
2001-2021,
«1С-Битрикс», 2021
Наверх
Robots.txt Введение и руководство | Центр поиска Google
 txt file?»> Что такое файл robots.txt?
txt file?»> Что такое файл robots.txt? Файл robots.txt сообщает сканерам поисковых систем, какие страницы или файлы он может или
не могу запросить с вашего сайта. Это используется в основном для того, чтобы не перегружать ваш сайт
Запросы; , это не механизм для защиты веб-страницы от Google.
Чтобы веб-страница не попала в Google, вы должны использовать
директив noindex ,
или защитите свою страницу паролем.
Для чего используется файл robots.txt?
Файл robots.txt используется в основном для управления трафиком сканера на ваш сайт, а обычно для хранения файла вне Google, в зависимости от типа файла:
| Тип файла | Управление движением | Скрыть от Google | Описание |
|---|---|---|---|
| Интернет-страница | Для веб-страниц (HTML, PDF или другие форматы, не относящиеся к мультимедиа, которые может читать Google), файл robots. Вы не должны использовать файл robots.txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Это связано с тем, что, если другие страницы указывают на вашу страницу с описательным текстом, ваша страница все равно может быть проиндексирована без посещения страницы. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или директиву Если ваша веб-страница заблокирована файлом robots.txt , она все равно может отображаться в результатах поиска, но результат поиска не будет иметь описания и будет выглядеть примерно так. Файлы изображений, видеофайлы, PDF-файлы и другие файлы, отличные от HTML, будут исключены. | ||
| Медиа-файл | Используйте robots.txt для управления трафиком сканирования, а также для предотвращения появления файлов изображений, видео и аудио в результатах поиска Google. (Обратите внимание, что это не помешает другим страницам или пользователям ссылаться на ваш файл изображения / видео / аудио.) | ||
| Файл ресурсов | Вы можете использовать файл robots.txt для блокировки файлов ресурсов, таких как неважные изображения, скрипты или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не пострадают от потери .Однако, если отсутствие этих ресурсов затрудняет понимание страницы поисковым роботом Google, вы не должны блокировать их, иначе Google не сможет хорошо проанализировать страницы, зависящие от этих ресурсов. |
 txt можно использовать для управления сканирующим трафиком, если вы считаете, что ваш сервер будет перегружен запросами от поискового робота Google, или чтобы избежать сканирования неважных или похожих страниц на вашем сайте.
txt можно использовать для управления сканирующим трафиком, если вы считаете, что ваш сервер будет перегружен запросами от поискового робота Google, или чтобы избежать сканирования неважных или похожих страниц на вашем сайте. Если вы видите этот результат поиска для своей страницы и хотите его исправить, удалите запись robots.txt, блокирующую страницу. Если вы хотите полностью скрыть страницу от поиска, воспользуйтесь другим методом.
Если вы видите этот результат поиска для своей страницы и хотите его исправить, удалите запись robots.txt, блокирующую страницу. Если вы хотите полностью скрыть страницу от поиска, воспользуйтесь другим методом.Пользуюсь услугами хостинга сайтов
Если вы используете службу хостинга веб-сайтов, такую как Wix, Drupal или Blogger, вам может не потребоваться (или у вас будет возможность) напрямую редактировать файл robots.txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
Чтобы узнать, просканировала ли ваша страница Google, найдите URL-адрес страницы в Google.
Если вы хотите скрыть (или показать) свою страницу от поисковых систем, добавьте (или удалите) любую страницу входа в систему.
требования, которые могут существовать, и поиск инструкций по изменению вашей страницы
видимость в поисковых системах на вашем хостинге, например:
wix скрыть страницу от поисковых систем
Ознакомьтесь с ограничениями файла robots.
 txt
txt
Прежде чем создавать или редактировать файл robots.txt, вы должны знать ограничения этого метода блокировки URL. Иногда вам может потребоваться рассмотреть другие механизмы, чтобы гарантировать, что ваши URL-адреса не будут найдены в Интернете.
- Директивы Robots.txt могут поддерживаться не всеми поисковыми системами
Инструкции в файлах robots.txt не могут принудить сканер к вашему сайту; гусеничный робот должен им подчиняться. В то время как робот Googlebot и другие известные поисковые роботы подчиняются инструкциям в файле robots.txt, другие поисковые роботы могут этого не делать.Поэтому, если вы хотите защитить информацию от веб-сканеров, лучше использовать другие методы блокировки, такие как защита паролем личных файлов на вашем сервере. - Различные поисковые роботы по-разному интерпретируют синтаксис
Хотя уважаемые веб-сканеры следуют директивам в файле robots.txt, каждый поисковый робот может интерпретировать директивы по-разному. Вы должны знать правильный синтаксис для обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции. - Роботизированная страница все еще может быть проиндексирована, если на нее ссылаются с других сайтов
Хотя Google не будет сканировать или индексировать контент, заблокированный файлом robots.txt, мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылка с другого места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, все еще может отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатегnoindexили заголовок ответа (или полностью удалить страницу).
 Вы должны знать правильный синтаксис для обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции.
Вы должны знать правильный синтаксис для обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции.Примечание : Объединение нескольких директив сканирования и индексирования может привести к тому, что некоторые директивы будут противодействовать другим директивам. Узнайте, как совместить сканирование с директивами индексирования / обслуживания.
Тестирование страницы на наличие блоков robots.txt
Вы можете проверить, заблокирована ли страница или ресурс правилом robots.txt.
Для проверки директив noindex используйте инструмент проверки URL.
Индексирование поиска блоков
с помощью noindex
Вы можете запретить отображение страницы в поиске Google, указав noindex
метатег в HTML-коде страницы или путем возврата заголовка noindex в HTTP
отклик.Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он сбросит
эта страница полностью из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
Важно : Чтобы директива noindex вступила в силу, страница
не должен блокировать файлом robots.txt, иначе это должно быть
доступный для краулера. Если страница заблокирована
robots.txt или он не может получить доступ к странице, поисковый робот никогда не увидит
noindex , и страница по-прежнему может отображаться в результатах поиска, например
если на него ссылаются другие страницы.
Использование noindex полезно, если у вас нет root-доступа к вашему серверу, так как он
позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация
noindex
Есть два способа реализовать noindex : как метатег и как HTTP-ответ.
заголовок. У них такой же эффект; выберите способ, который удобнее для вашего сайта.
Тег
Чтобы запретить большинству поисковых роботов индексировать страницу вашего сайта, поместите
следующий метатег в раздел вашей страницы:
Чтобы запретить только веб-сканерам Google индексировать страницу:
Вы должны знать, что некоторые веб-сканеры поисковых систем могут интерпретировать
noindex иначе.В результате возможно, что ваша страница
по-прежнему появляются в результатах других поисковых систем.
Узнайте больше о метатеге noindex .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением
либо noindex , либо none в вашем ответе. Вот пример
HTTP-ответ с X-Robots-Tag , инструктирующий сканеры не индексировать страницу:
HTTP / 1.1 200 ОК (…) X-Robots-Tag: noindex (…)
Узнайте больше о заголовке ответа noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть метатеги и заголовки HTTP. Если страница все еще
появляется в результатах, вероятно, потому, что мы не сканировали страницу с тех пор, как вы добавили
тег. Вы можете запросить у Google повторное сканирование страницы с помощью
Инструмент проверки URL.Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из сети Google.
сканеры, поэтому они не могут видеть тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать свой
файл robots.txt. Вы можете редактировать и тестировать свой robots.txt, используя
Тестер robots.txt
инструмент.
Файл Robots.txt [Примеры 2021] — Moz
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем), как сканировать страницы на своем веб-сайте.Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта.Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Базовый формат:
User-agent: [user-agent name] Disallow: [URL-строка не должна сканироваться]
Вместе эти две строки считаются полным файлом robots.txt, хотя один файл robots может содержат несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задерживает сканирование и т. д.).
В файле robots.txt каждый набор директив пользовательского агента отображается как дискретный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами пользовательского агента, каждое запрещающее или разрешающее правило , только применяется к агенту (агентам), указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот будет только обратить внимание (и следовать директивам в) наиболее конкретной группе инструкций .
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому только пользовательские агенты будут обращать внимание на директивы в своих разделах роботов.txt файл. Все остальные пользовательские агенты будут следовать директивам в группе user-agent: *.
Пример robots.txt:
Вот несколько примеров использования robots.txt для сайта www.example.com:
URL файла Robots.txt: www.example.com/robots.txt
Блокирование всего контента для всех поисковых роботов
User-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt укажет всем поисковым роботам не сканировать никакие страницы www.example.com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контенту
User-agent: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам сканировать все страницы на www.example.com, включая домашнюю страницу.
Блокировка определенного поискового робота из определенной папки
User-agent: Googlebot Disallow: / example-subfolder /
Этот синтаксис сообщает только поисковому роботу Google (имя агента пользователя Googlebot) не сканировать страницы, которые содержат строку URL-адреса www.example.com/example-subfolder/.
Блокировка определенного поискового робота с определенной веб-страницы
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Этот синтаксис сообщает только поисковому роботу Bing (имя агента пользователя Bing) избегать сканирование конкретной страницы по адресу www.example.com/example-subfolder/blocked-page.html.
Как работает robots.txt?
Поисковые системы выполняют две основные задачи:
- Сканирование Интернета для обнаружения контента;
- Индексирование этого контента, чтобы его могли обслуживать искатели, ищущие информацию.
Чтобы сканировать сайты, поисковые системы переходят по ссылкам с одного сайта на другой — в конечном итоге просматривая многие миллиарды ссылок и веб-сайтов. Такое ползание иногда называют «пауками».
После перехода на веб-сайт, но перед его сканированием поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать дальнейшие действия поискового робота на этом конкретном сайте.Если файл robots.txt не содержит , а не директив, запрещающих действия агента пользователя (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Другой быстрый файл robots.txt, который необходимо знать:
(более подробно обсуждается ниже)
Чтобы его можно было найти, файл robots.txt должен быть помещен в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен иметь имя «robots.txt »(не Robots.txt, robots.TXT и т. д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваш файл robots.txt. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или парсеры адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого веб-сайта (если на этом сайте есть файл robots.txt!). Это означает, что любой может видеть, какие страницы вы хотите или не хотите сканировать, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельные файлы robots.txt. Это означает, что и blog.example.com, и example.com должны иметь свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать расположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
Технический синтаксис robots.txt
Robots.txt можно рассматривать как «язык» файлов robots.txt. Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. К ним относятся:
User-agent: Конкретный поисковый робот, которому вы даете инструкции для сканирования (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
Разрешить (Применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что робот Googlebot не подтверждает эту команду, но скорость сканирования можно установить в консоли поиска Google.
Sitemap: Используется для вызова местоположения любых XML-файлов Sitemap, связанных с этим URL.Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов, которые нужно заблокировать или разрешить, файлы robots.txt могут стать довольно сложными, поскольку они позволяют использовать сопоставление с образцом для охвата диапазона возможных вариантов URL. И Google, и Bing уважают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые оптимизатор поисковых систем хочет исключить. Эти два символа — звездочка (*) и знак доллара ($).
- * — это подстановочный знак, который представляет любую последовательность символов.
- $ соответствует концу URL-адреса
Google предлагает здесь большой список возможных синтаксисов и примеров сопоставления с образцом.
Где находится файл robots.txt на сайте?
Когда бы они ни заходили на сайт, поисковые системы и другие роботы, сканирующие Интернет (например, сканер Facebook Facebot), знают, что нужно искать файл robots.txt. Но они будут искать этот файл только в в одном конкретном месте : в основном каталоге (обычно в корневом домене или на домашней странице). Если пользовательский агент посещает www.example.com/robots.txt, а не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ).Даже если страница robots.txt и существует ли , скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами и, следовательно, сайт будет обрабатываться так, как если бы в нем вообще не было файла robots.
Чтобы гарантировать, что ваш файл robots.txt найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем нужен robots.txt?
Файлы Robots.txt управляют доступом поискового робота к определенным областям вашего сайта.Хотя это может быть очень опасным, если вы случайно запретите роботу Google сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Вот некоторые распространенные варианты использования:
- Предотвращение появления дублированного контента в результатах поиска (обратите внимание, что мета-роботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей группы инженеров)
- Предотвращение показа страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (ов) сайта
- Запрет поисковым системам индексировать определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т. Д.))
- Указание задержки сканирования для предотвращения перегрузки ваших серверов, когда сканеры загружают сразу несколько частей контента
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, вы не можете вообще нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
Если страница .txt не отображается, значит, у вас нет (активной) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создание файла — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов роботов? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Рекомендации по поисковой оптимизации
Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно просканировать.
Ссылки на страницах, заблокированных файлом robots.txt, переходить не будут. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и индексироваться. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Не используйте robots.txt для предотвращения появления конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность делать это позволяет вам точно настроить способ сканирования содержания вашего сайта.
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день.Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить URL-адрес robots.txt в Google.
Robots.txt против мета-роботов против x-роботов
Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это фактический текстовый файл, тогда как мета и x-роботы — это метадирективы. Помимо того, что они есть на самом деле, все три выполняют разные функции. Файл robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
Приложите свои навыки к работе
Moz Pro может определить, блокирует ли ваш файл robots.txt наш доступ к вашему веб-сайту. Попробовать >>
Отключить индексацию поисковой системой | Webflow University
В этом видео показан старый интерфейс. Скоро появится обновленная версия!
Вы можете указать поисковым системам, какие страницы сканировать, а какие нет на вашем сайте, написав файл robots.txt. Вы можете запретить сканирование страниц, папок, всего вашего сайта.Или просто отключите индексацию своего поддомена webflow.io. Это полезно, чтобы скрыть такие страницы, как ваша страница 404, от индексации и включения в результаты поиска.
В этом уроке
Отключение индексации субдомена Webflow
Вы можете запретить Google и другим поисковым системам индексировать субдомен webflow.io, просто отключив индексирование в настройках вашего проекта.
- Перейдите в Project Settings → SEO → Indexing
- Установите Disable Subdomain Indexing на «Yes»
- Сохраните изменений и опубликуйте свой сайт
A unique robots.txt будет опубликовано только на поддомене, указав поисковым системам игнорировать домен.
Создание файла robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов на сайте, которые вы не хотите, чтобы поисковые системы сканировали. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы сообщить сканерам поисковых систем, какой контент они должны сканировать.
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена.Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы заполните его в настройках своего проекта.
- Перейдите в Project Settings → SEO → Indexing
- Добавьте robots.txt правил, которые вы хотите (см. Ниже)
- Сохраните изменения и опубликуйте свой сайт
Создайте роботов .txt для вашего сайта, добавив правила для роботов, сохранив изменения и опубликовав свой сайт.
Robots.txt rules
Вы можете использовать любое из этих правил для заполнения роботов.txt файл.
- User-agent: * означает, что этот раздел применим ко всем роботам.
- Disallow: запрещает роботу посещать сайт, страницу или папку.
Чтобы скрыть весь сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: / page-name
Чтобы скрыть всю папку страниц
User-agent: *
Disallow: / folder-name /
Чтобы включить карту сайта
Sitemap: https: // your-site.com / sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt
Необходимо знать
- Содержимое вашего сайта может индексироваться, даже если оно не было просканировано. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент в другом онлайн-контенте. Чтобы страница не проиндексировалась, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex.
- Кто угодно может получить доступ к robots вашего сайта.txt, чтобы они могли идентифицировать ваш личный контент и получить к нему доступ.
Лучшие практики
Если вы не хотите, чтобы кто-либо мог найти определенную страницу или URL на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL. Вместо этого используйте любой из следующих вариантов:
Попробуйте Webflow — это бесплатно
В этом видео используется старый интерфейс. Скоро появится обновленная версия!
seo — Как деиндексировать страницы из Google с помощью robots.txt
Предполагается, что эти страницы все еще существуют, но вы просто хотите, чтобы они были удалены из результатов поиска…
Как правильно деиндексировать страницы с помощью robots.txt?
Необязательно использовать robots.txt с по деиндексировать страниц. т.е. удалить уже проиндексированные страницы из результатов поиска Google. Вместо этого может быть предпочтительнее использовать метатег noindex robots на самой странице (или заголовок HTTP-ответа X-Robots-Tag ) в сочетании с инструментом удаления URL в Google Search Console (GSC) для ускорения процесса.
роботов.txt , в частности, блокирует сканирование (не обязательно «индексацию»). Если запретить сканирование этих страниц , эти страницы должны естественно со временем выпадать из поискового индекса, но это может занять значительное время. Однако, если на эти страницы по-прежнему есть ссылки, они могут не исчезнуть полностью из результатов поиска, если эти URL-адреса заблокированы файлом robots.txt (вы можете получить ссылку только для URL-адреса в поисковой выдаче без описания). .
Используя роботов.txt , чтобы удалить каталог https://www.example.com/getridofthis/ ...
Агент пользователя: *
Запретить: / getridofthis /
Чтобы полностью удалить страницы из поисковой выдачи, рассмотрите возможность использования метатега noindex (или X-Robots-tag: noindex HTTP-заголовка ответа) вместо robots.txt . (Похоже, вы уже это делаете.) Не блокируйте сканирование в файле robots.txt , так как это не позволит сканеру увидеть метатег noindex .
Чтобы ускорить процесс деиндексации URL-адресов в поиске Google, вы можете использовать инструмент удаления URL-адресов в GSC (ранее называвшийся Инструменты для веб-мастеров). Чтобы этот инструмент был эффективным в долгосрочной перспективе, вам необходимо использовать метатег noindex на самих страницах. (В исходной статье в блоге говорилось, что robots.txt может использоваться в качестве механизма блокировки с помощью инструмента удаления URL-адресов, однако недавние справочные документы специально предупреждают об использовании robots.txt для «окончательного удаления».)
Артикул:
Как эффективно удалить страницу из Google (2020)
Во-первых, давайте разберемся, что все на самом деле делает. (Если вы уже знаете все это, перейдите к последнему разделу «Но как мне на самом деле удалить страницу?»).
Robots.txt
Что такое Robots.txt?
Файл robots.txt позволяет вам контролировать, куда будут заходить поисковые роботы на вашем сайте. Причудливое название для этого - «Протокол исключения роботов», и оно позволяет указать, какие части вашего сайта не должны просматриваться или обрабатываться.
Несмотря на то, что существуют директивы, позволяющие не индексировать страницу в файле robots, от Google поступают неоднозначные сообщения о том, хотят ли они, чтобы вы это сделали.
Вердикт : Не используйте файл robots.txt для удаления страницы. Это неэффективный способ удалить существующую страницу из индекса.
Инструмент для удаления URL в Инструментах для веб-мастеров (Search Console)
Что такое инструмент для удаления URL?
Консоль поиска Google - это кладезь полезных инструментов и информации о вашем веб-сайте, она должна быть у всех, кто владеет сайтом.Инструмент удаления позволяет временно удалить страницу из индекса.
Вердикт : Действует в краткосрочной перспективе - однако, чтобы страница не переиндексировалась… продолжайте читать.
Мета Роботы Noindex
Что такое метатег name = ”robots” content = ”noindex”?
Это HTML-тег, который вы можете добавить на любую страницу, чтобы Google не индексировал страницу. И записывается так: meta name = "robots" content = "noindex" (не забывайте открывающие и закрывающие теги, которые WP удалил в моем примере).Ознакомьтесь со спецификациями Google здесь.
Вердикт : Действует в долгосрочной перспективе. Это предотвратит индексирование вашей страницы поисковыми системами при правильном применении.
Nofollow
Что такое nofollow?
В зависимости от контекста и места добавления директивы nofollow. Это может означать две вещи. Он либо применяется к отдельным ссылкам с атрибутом rel = ”nofollow”, либо может применяться в мета-директиве robots, которая сообщает Google не переходить ни по одной из ссылок на странице, на которую вы его добавили.
Вердикт : нет, не использовать это для удаления существующей страницы из индекса.
Но как мне удалить страницу?
Итак, теперь у нас есть вся эта информация.
Во-первых, если у вас нет проверенных Инструментов для веб-мастеров, сделайте это, а затем вернитесь. Во-вторых, вам необходимо иметь доступ к HTML отдельных страниц вашего сайта. Если вы используете CMS, например WordPress, установите плагин Yoast и следуйте этим инструкциям.
Если вы используете другую систему управления контентом, выполните поиск «* ваша CMS * noindex a page».например 'Drupal noindex a page'. Если вы не используете WordPress или другую систему управления контентом и у вас есть доступ к HTML-кодам своих страниц, добавьте следующий код между тегами HEAD страницы-нарушителя: meta name = "robots" content = "noindex" (опять же, обратите внимание на открывающие и закрывающие теги, которые здесь были удалены WP).
В-третьих, перейдите в свой подтвержденный ресурс в Инструментах для веб-мастеров (Search Console) и перейдите к раскрывающемуся списку «Индекс Google», а затем к разделу «Удалить URL-адреса».Вставьте URL, который вы хотите удалить, туда (который, надеюсь, должен иметь недавно добавленный метатег robots) и имя Роберта, брата вашего отца. Ваша страница должна быть удалена навсегда!
* Бандиты
Убедитесь, что не заблокировали (не запретили) страницу с файлом robots.txt, так как Google не сможет «увидеть» директиву noindex, и вы получите следующее сообщение в результатах поиска, где должно быть ваше метаописание: Описание этого результата недоступно из-за robots.текст'. Затем вы можете крикнуть своему разработчику и сказать: «Смотри, я сказал тебе, Саймон».
Подробнее о robots.txt
Если у вас возникли проблемы с этим или у вас есть более сложная проблема с индексированием, с которой вам нужна помощь. Свяжитесь с нами, и мы сможем вам помочь.
Блокировать страницы или сообщения блога от индексации поисковыми системами
Есть несколько способов запретить поисковым системам индексировать определенные страницы вашего сайта.Рекомендуется тщательно изучить каждый из этих методов, прежде чем вносить какие-либо изменения, чтобы гарантировать, что только нужные страницы заблокированы для поисковых систем.
Обратите внимание: : эти инструкции блокируют индексирование URL страницы для поиска. Узнайте, как настроить URL-адрес файла в инструменте файлов, чтобы заблокировать его от поисковых систем.
Файл Robots.txt
Ваш файл robots.txt - это файл на вашем веб-сайте, который сканеры поисковых систем читают, чтобы узнать, какие страницы они должны и не должны индексировать.Узнайте, как настроить файл robots.txt в HubSpot.
Google и другие поисковые системы не могут задним числом удалять страницы из результатов после реализации метода файла robots.txt. Хотя это говорит ботам не сканировать страницу, поисковые системы все равно могут индексировать ваш контент (например, если на вашу страницу есть входящие ссылки с других веб-сайтов). Если ваша страница уже проиндексирована и вы хотите удалить ее из поисковых систем задним числом, рекомендуется вместо этого использовать метод метатега «Без индекса».
Мета-тег «Без индекса»
Обратите внимание: : , если вы решите использовать метод метатега «Без индекса», имейте в виду, что его не следует комбинировать с методом файла robots.txt. Поисковым системам необходимо начать сканирование страницы, чтобы увидеть метатег «Без индекса», а файл robots.txt полностью предотвращает сканирование.
Мета-тег "без индекса" - это строка кода, введенная в раздел заголовка HTML-кода страницы, который сообщает поисковым системам не индексировать страницу.
Консоль поиска Google
Если у вас есть учетная запись Google Search Console , вы можете отправить URL-адрес для удаления из результатов поиска Google. Обратите внимание, что это будет применяться только к результатам поиска Google.
Если вы хотите заблокировать файлы в файловом менеджере HubSpot (например, документ PDF) от индексации поисковыми системами, вы должны выбрать подключенный поддомен для файла (ов) и использовать URL-адрес файла для блокировки веб-сканеров.
Как HubSpot обрабатывает запросы от пользовательского агента
Если вы устанавливаете строку пользовательского агента для проверки сканирования вашего веб-сайта и видите сообщение об отказе в доступе, это ожидаемое поведение. Google все еще сканирует и индексирует ваш сайт.
Причина, по которой вы видите это сообщение, заключается в том, что HubSpot разрешает запросы от пользовательского агента googlebot только с IP-адресов, принадлежащих Google. Чтобы защитить сайты, размещенные на HubSpot, от злоумышленников или спуферов, запросы с других IP-адресов будут отклонены.HubSpot делает это и для других сканеров поисковых систем, таких как BingBot, MSNBot и Baiduspider.
SEO
Целевые страницы
Блог
Настройки аккаунта
Страницы веб-сайта
.
Добавить комментарий