Распознавание текста онлайн
Набирать текст на клавиатуре мало кто любит, особенно если знаешь, что до тебя его уже кто-то набирал и можно взять готовое. Так студенты уже давно научились брать необходимый текст из печатных изданий, отсканировав его и распознав.
Но что делать, если уже имеется отсканированный документ, но нет возможности установить необходимую программу распознавания текста? Оказывается, у пользователей появилась возможность распознать текст онлайн.
В интернете появилось множество различных сервисов, которые предоставляют услуги распознания текста онлайн. Качество распознавания текста на абсолютно бесплатных сервисах оставляет желать лучшего, поэтому мы рассмотрим два самых достойных платных сервиса, которые позволяют распознать текст онлайн.
Начнем мы с сервиса Online OCR, который можно найти по адресу onlineocr.ru. Для начала работы с сервисом распознавания текста онлайн, необходимо пройти регистрацию, но даже после этого в бесплатном режиме он будет распознавать только часть текста.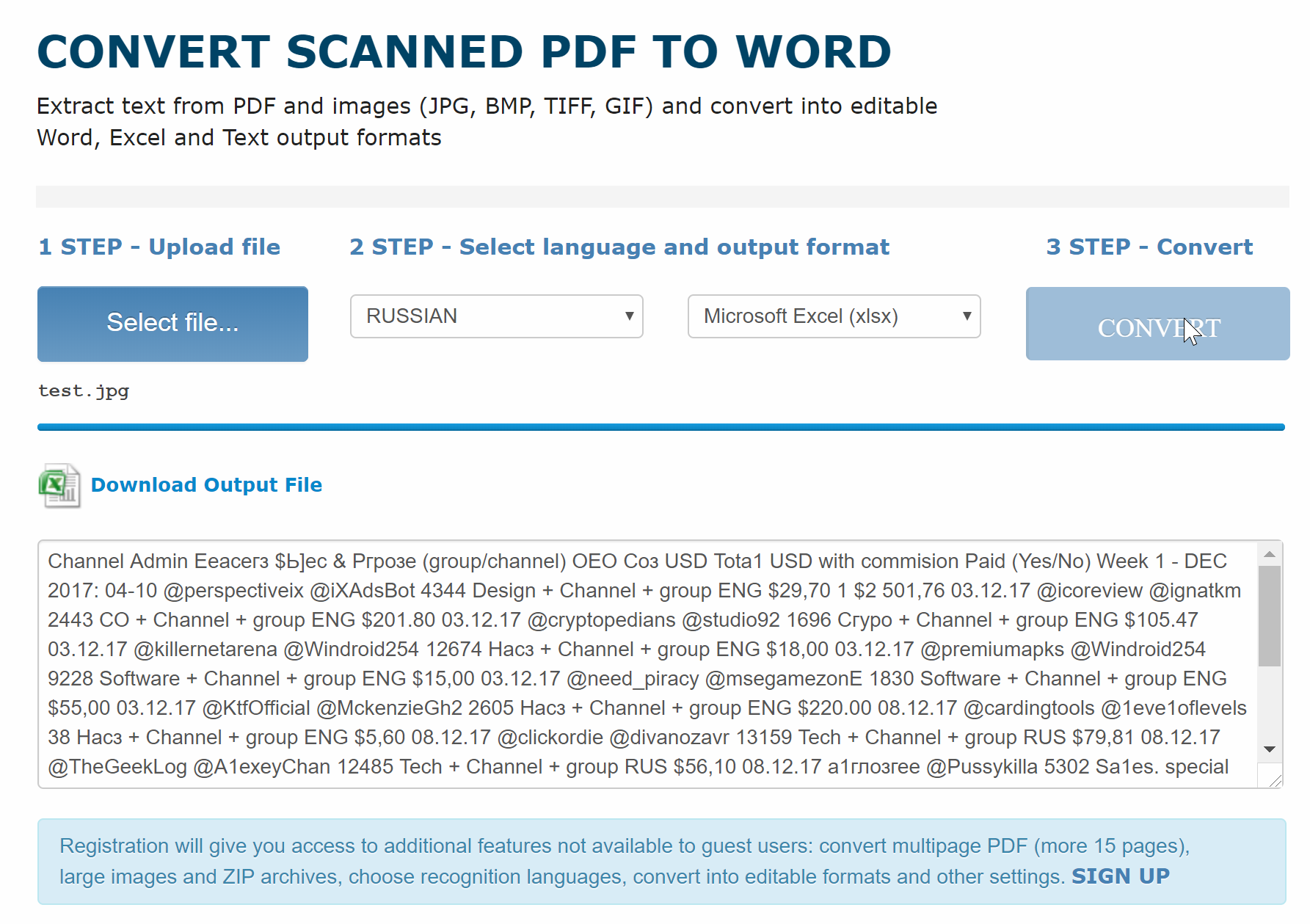 Для распознавания можно загружать картинки различных форматов, а также TIFF и PDF. Полученный результат можно будет сохранить в одном из шести форматов: Adobe PDF, MS Word, Excel, Html, Rtf, Txt.
Для распознавания можно загружать картинки различных форматов, а также TIFF и PDF. Полученный результат можно будет сохранить в одном из шести форматов: Adobe PDF, MS Word, Excel, Html, Rtf, Txt.
Для полноценной работы с сервисом необходимо произвести оплату, которая в принципе не так уж и велика.
Распознавание текста онлайн начинается с загрузки своего файла на сервер, для этого на главной странице нажимаем на хорошо заметную кнопку «Распознать текст», после чего мы попадаем в настройки. Необходимо выбрать языки, которые присутствуют в документе и формат выходного файла. После выбора и загрузки файла можно приступать к распознаванию.
Результат распознавания можно сразу загрузить на компьютер в необходимом формате.
Следующий известный сервис распознавания текста онлайн Abbyy Fine reader Onlaine, который находится по адресу finereader.abbyyonline.com. После регистрации на сайте появляется возможность бесплатно распознать текст онлайн в демонстрационном режиме.
Для начала работы необходимо загрузить файл, сделать настройку языков и формат выходного файла, затем нажать «Распознать». После некоторого времени обработки результат распознавания готов к скачиванию в виде файла.
По завершению демонстрационного режима распознавания текста онлайн необходимо произвести оплату.
Современные технологии и достижения науки периодически удивляют и радуют нас, но ничто так не завораживает, как Планета Земля из космоса. Этот голубой шар с большой высоты кажется совершенно безобидным, и благодаря нашим астронавтам мы можем рассматривать красивейшие фотографии нашей Планеты Земля.
Также статьи на сайте chajnikam.ru связанные с интернетом:
Google Panda
Как искать сайты в интернете?
Мир социальных отношений
Зачем нужен сайт?
Как распознать текст с картинки в Word – инструкция
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.
Как распознать текст с картинки в Word
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.
Открываем любую страницу в OneNote
- Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.
Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.
Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей. Он не распознает русский текст.
Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.
Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»
Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.
Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.
Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Извлекаем текст
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Как распознать текст на изображении. Самый простой способ
Бывают случаи, когда вам нужно распознать текст на изображении, чтобы в итоге у вас была не картинка, а то, что можно распечатать или отредактировать. Можно, конечно, перепечатать текст самостоятельно, но зачем это делать, если в век цифровых технологий есть куда более доступные, а главное — быстрые способы. И о них мы сейчас вам и расскажем.
Распознать текст можно в два счета. Главное — иметь доступ к сети
Немного теории. Как программа распознает изображение
Извлечение текста из изображения осуществляется с помощью программного обеспечения, которое называется OCR (сокращенно от optical character recognition). Программа считывает файл изображения (формат тут не важен, будь то jpg, png, pdf и так далее). Выявляет там то, что потенциально может быть текстом и затем «сравнивает» с базой шрифтов. В итоге на выходе мы получаем текстовый файл. При этом чем лучше качество исходного файла и чем более распространенный там используется шрифт — тем лучше произойдет распознавание текста.
В то время, как нет недостатка в OCR-приложениях для смартфонов на Android и даже расширений браузера Сhrome не наблюдается, они не всегда могут оказаться у вас под рукой. О самых лучших программах в самых разных категориях мы регулярно, так что подписывайтесь на нас в Телеграм, чтобы ничего не пропустить. Однако если под рукой нет нужны программ, можно использовать более простой, а главное — всегда доступный метод.
Как распознать текст на картинке
Распознаем текст онлайн без СМС и регистрации
Для начала рассмотрим ситуацию, когда вы работаете на ПК. Откройте веб-версию Google Keep по этой ссылке и загрузите свое изображение в виде заметки в этот сервис, нажмите на три вертикальные точки под вашим изображением и выберите опцию «Распознать текст изображения». Сервис в максимально короткий срок сделает все необходимое, после чего вы сможете работать с получившимся текстом.
Да, популярное приложение для создания заметок Google Кeep обладает, как вы догадались, возможностью по распознаванию текста. Конечно, вы можете держать его на своем смартфоне для подобных ситуаций и мы рекомендуем вам скачать его из магазина Google Play. Но мы рассматриваем простой способ без лишних загрузок, верно? В этом случае вам опять же поможет веб-интерфейс Google Кeep, который отлично работает и при загрузке со смартфона.
Читайте также: Лучшие приложения для преобразования голоса в текст
Однако стоит заметить, что если у вас установлено приложение Google Кeep, то вы получите некоторые дополнительные опции. Например, вы можете создать новую заметку в приложении и после этого нажать на кнопку камеры в углу интерфейса программы. Теперь у вас есть два варианта: вы можете либо сделать снимок документа или какой-то надписи, либо же выбрать изображение из памяти устройства.
Google Keep способен на многое
При любом исходе приложение загрузит фото в память и после нажатия на меню опции вы увидите заветную надпись «Распознать текст изображения». После этого вы можете сохранить результат в эту же заметку, либо же сформировать из него отдельный текстовый документ. Ах да, если у вас включена синхронизация с аккаунтом Google, то вы можете тут же «расшарить» заметку на Google Диск и иметь к ней доступ с любого устройства, подключенного к сети.
Как распознать текст с картинки
Бывают ситуации, когда нужная информация хранится на бумажном носителе или в файле PDF, а вам нужно срочно перевести её в электронный документ. Если текст небольшой, его можно быстро перепечатать. Но что делать с большими документами? Как распознать текст с картинки, чтобы не тратить время на ручной перенос информации?
Google Drive
Есть у вас есть аккаунт Google (почта Gmail), то воспользуйтесь для распознавания текста возможностями сервиса Google Документы.
- Откройте Google Диск.
- Нажмите «Мой диск» и выберите «Загрузить файлы».
- Выберите картинку (PDF-файл), который нужно распознать.
После загрузки файла кликните по нему правой кнопкой и выберите открытие через Google Документы. Появится окно, в котором будет ваша картинка.Под ней – распознанный текст, который вы можете спокойно скопировать в Word.
Важно: проверьте текст на соответствие оригиналу. Если на снимке были какие-то дефекты, то распознавание может пройти с ошибками.
Однако у этого способа есть ряд ограничений:
- Размер файла не должен превышать 2 Мб.
- Поддерживаются только форматы JPG, GIF, PNG и PDF.
- В PDF распознается не более 10 страниц.
- Текст должен быть расположен ровно. Если есть какое-то смещение, то необходимо предварительно его устранить через графический редактор.
Если вы сделаете четкий снимок без размытостей и с равномерным освещением, то Google Документы без проблем распознает текст. Технология поддерживает письмо справа налево, слева направо и вертикальное (японский и китайский языки).
Онлайн-сервисы
Если аккаунта Google нет, или вам не понравилось качество распознавания текста, то попробуйте использовать специальные онлайн-сервисы. Сайтов-конвертеров, предоставляющих подобный функционал, достаточно много, поэтому остановимся на самых известных площадках.
FineReader Online
Признанный лидер рынка, отлично распознающий текст из файлов разного формата. Единственный минус – сервис этот платный. Бесплатно в месяц можно распознать не более 5 страниц. Если вы постоянно нуждаетесь в переводе из JPG в Word – покупайте пакет страниц.
Для разового же распознавания сервис подходит идеально. Поэтому если нужно перевести в Word меньше 5 страниц, воспользуйтесь приведенной ниже инструкцией:
- Перейдите на сайт https://finereaderonline.com/ru-ru. Создайте учетную запись (простая регистрация – e-mail и пароль).
- Нажмите кнопку «Распознать».
- Загрузите файл.
- Выберите язык (можно выбрать одновременно 3 языка).
- Укажите формат сохраняемого документа.
- Нажмите «Распознать».
После завершения конвертации откроется страница с распознанным текстом. Чтобы сохранить документ, просто нажмите на него.
OCR Convert
Если вы не хотите регистрироваться и вам не хватает тех возможностей, что бесплатно предоставляет сервис FineReader Online, то попробуйте альтернативные варианты. Например, используйте OCR Convert:
- Загрузите файл.
- Выберите язык.
- Укажите, что вы не робот.
- Нажмите «Process».
Из недостатков сервиса можно выделить ограниченный выбор форматов на выходе – текст переводится только в TXT. Еще один минус – слабое, по сравнению с FineReader, распознавание.
Некоторые буквы перепутаны, иногда внутри слов встречаются цифры. Поэтому обязательно перечитывайте текст после конвертации.
Есть и некоторые ограничения: в частности, размер исходника не должен превышать 5 Мб, работает сервис с форматами PDF, GIF, BMP и JPEG. Зато OCR Convert поддерживает низкое разрешение изображения, так что даже если снимок не очень хорошего качества, с него можно попытаться «снять» текст.
Схожим образом работает сервис Free Online OCR. Но, в отличие от OCR Convert, здесь чуть больше возможностей для конвертирования – готовый документ можно получить в трех форматах (DOCX, TXT, XLCX).
Ограничение на вес стандартное – 5 Мб. Без регистрации в час можно распознать 15 изображений. Если заведете учетную запись, ограничение снимается.
i2OCR
Еще один удобный сервис, поддерживающий более 60 языков и все основные форматы изображений. Главное отличие от предыдущих конвертеров – наличие возможности загрузить снимок из URL.
Порядок работы тот же: указываете язык, выбираете файл, вводите капчу и нажимаете «Extract Text».
Полученный текст можно загрузить на компьютер, перевести или редактировать в Google Документах.
Есть и другие подобные сервисы – Newocr, Free-OCR и другие OCR, позволяющие распознать текст с изображений. Однако нужно понимать, что машинный алгоритм не является безошибочным. Поэтому внимательно вычитывайте тексты после конвертации, чтобы не попасть в неловкую ситуацию.
Конвертер изображения в текст [изображение в текст]
Picture to Text Converter Online — это бесплатный инструмент распознавания текста от SEO Tools Center, который поможет вам извлекать текст из рукописных заметок или цифровых изображений. Этот инструмент использует передовую технологию программного обеспечения оптического распознавания символов (OCR) для извлечения текста из изображения, которое можно загрузить в виде текстового файла.
Извлечь текст из изображения в Интернете
У вас есть текст на изображении, и вы хотите использовать его в новом документе? Если нет редактируемого текста, вы не сможете просто скопировать текст и использовать его в другом месте.Функция копирования текста не работает с изображениями. Итак, если вам нужен текст, вам придется вручную ввести его в новый файл. Это займет у вас много времени и сил.
Здесь на помощь приходит наш онлайн-конвертер изображений в текст!
Этот инструмент использовал новейшую технологию оптического распознавания символов OCR для анализа текста, распознавания символов на изображении, которое вы добавляете в этот инструмент. Он переводит символы в цифровой текст, который выдает вам в текстовом файле.
Самостоятельный набор текста с изображений временами может сильно утомлять. Здесь мы представляем вам этот инструмент, который вы можете использовать для извлечения текста из отсканированных изображений в Интернете.
Просто добавьте изображение, содержащее текст, который вы хотите в этом инструменте, позвольте ему выполнить свою обработку, и он предоставит вам извлеченный текст за короткий промежуток времени.
В качестве альтернативы, если вы хотите сгенерировать изображение из текста, вы можете использовать Генератор текста в изображение от Центра инструментов SEO.
Какие приложения изображения к тексту?
Технология OCR стала довольно распространенной за последние несколько лет. Не только правоохранительные органы и государственные учреждения имеют доступ к онлайн-распознаванию текста. Учитывая его применение в повседневной жизни для извлечения текстовой информации из отсканированных документов, становится очевидным, почему эта технология стала популярной во всем мире.
Вот некоторые из наиболее распространенных приложений для извлечения текста из файла изображения в Интернете.
Интерактивная оцифровка ручного документооборота
Неважно, к какой сфере жизни вы принадлежите, независимо от вашей профессии, задачи, связанные с оформлением документов на каждую работу, переводятся в цифровую форму. Старые записи конвертируются в цифровые файлы для лучшего хранения.
И эта оцифровка оказывает большое давление на людей, которым приходится заниматься набором данных. Они могут использовать технологию OCR для преобразования документов в цифровой формат за короткое время.Кстати, если у вас есть PDF-файл, и вы хотите извлечь из него изображения, вы можете использовать для этой цели инструмент «Извлечь изображения из PDF-документа».
Преимущества OCR в секторе здравоохранения
OCR оказался весьма полезным для легкого и удобного хранения истории болезни пациента. Больницы используют OCR для получения информации о своих пациентах и хранят их для лучшего диагноза.
Это значительно упрощает процесс получения и обмена информацией в разных доменах.Наш инструмент OCR поможет больницам упростить процесс оцифровки информации о здоровье пациентов.
Изображение в текст для студентов
Для учащихся, которые не хотят печатать рукописные заметки в текстовом документе, они могут использовать этот инструмент для извлечения текста из своих заметок, а затем использовать этот текст для создания слова или файла PDF за короткий промежуток времени. Это поможет сэкономить время и энергию, которые они могут потратить на изучение большего, вместо того, чтобы тратить время на ручной ввод заметок в классе.
Студенты и учителя могут использовать этот инструмент, чтобы избавиться от ручного ввода информации с изображения на цифровую платформу, такую как Word или Excel. Учащиеся также могут использовать инструмент «Обрезать изображение в Интернете», чтобы обрезать изображение перед извлечением из него текста.
Простое преобразование рукописных заметок в цифровой текст
Рукописные заметки — самый надежный способ хранения информации. Но опять же, когда вам нужно хранить эти рукописные заметки на своем компьютере, все может стать довольно беспокойным.Вы можете использовать онлайн-конвертер изображений в текст в Центре инструментов SEO для легкого извлечения текста из рукописных заметок.
Полученный цифровой текст можно будет легко использовать на любой цифровой платформе по вашему выбору. Цифровые маркетологи могут комбинировать этот инструмент с Image Optimizer, чтобы улучшить свои изображения с точки зрения SEO.
Как извлечь текст из изображений в Интернете с помощью инструмента SEO Center Picture To Text Converter?
- Загрузите изображение в этот инструмент [только.jpg extension].
- Вы также можете добавить URL-адрес изображения, из которого хотите извлечь текст, и нажать кнопку преобразования .
- После этого вы нажимаете «Преобразовать», чтобы запустить инструмент OCR, и он покажет успешно преобразованный файл .
- Подождите, пока инструмент закончит обработку, нажмите кнопку загрузки файла .
- Скачать извлеченный текст [откроется в новой вкладке].
Примечание : Вы также можете загрузить файл изображения с Google Диска или Dropbox.
Возможности конвертера изображения в текст
Бесплатный онлайн-инструмент
Благодаря нашему бесплатному инструменту распознавания текста вам не придется беспокоиться о настройке планов платежей и вообще ничего не платить ежемесячно. В отличие от большинства онлайн-инструментов для преобразования изображений в текст, наш инструмент полностью бесплатен. Также нет небольшого ограничения на размер файла.
Извлечение текстовой информации из цифровых изображений
Если вы хотите быстро извлечь важную информацию из изображений, этот инструмент для вас.Вместо того, чтобы писать информацию вручную, вы можете использовать наш инструмент, чтобы извлечь эту информацию и использовать ее так, как вы хотите.
Быстрое и эффективное извлечение текста
Мы оптимизировали этот инструмент, чтобы он работал максимально быстро и эффективно. OCR работает на наших веб-серверах и обеспечивает удивительно высокую производительность за короткое время. Наш инструмент поможет вам быстро и точно извлекать текст из изображений.
Возможности Поддержка нескольких языков
Этот инструмент не только поддерживает английский язык, но и позволяет извлекать текст из изображений, содержащих текст на испанском, французском или даже итальянском языках.Мы постоянно совершенствуем этот инструмент, добавляя поддержку большего количества языков, чтобы вы могли получить лучший опыт преобразования изображений в текст.
Функции загрузки файла
После извлечения текста из изображения пользователи этого инструмента смогут использовать текст так, как захотят. Текст будет предоставлен пользователям в виде текстового файла, который можно будет легко загрузить.
Часто задаваемые вопросы о преобразователе изображения в текст
Зачем нужен конвертер изображений в текст Центра инструментов SEO?
Наш конвертер изображений в текст быстрый, эффективный и, что самое главное, совершенно бесплатный.Вам не нужно регистрироваться или создавать учетную запись для использования этого инструмента распознавания текста.
Как скопировать текст с картинки?
Если вы хотите скопировать текст с изображения, вы можете использовать для этого наш бесплатный инструмент преобразования изображения в текст. Этот инструмент — ваш лучший выбор для извлечения текста из изображений.
Как скопировать текст с изображения?
Чтобы скопировать текст с изображения, добавьте изображение в наш инструмент. Позвольте инструменту обработать изображение, и он выдаст вам текст.
Как превратить картинку в pdf?
Чтобы превратить изображение в PDF, воспользуйтесь нашим инструментом для извлечения текста. После извлечения текста вы сможете загрузить его в виде файла PDF или простого текстового файла.
Используйте конвертер изображения в текст — Почему это важно?
Конвертеры изображения в текст
используют технологию OCR для извлечения текста из изображений. У этого есть огромное количество пользователей в правоохранительных органах, секторе здравоохранения, образования и других государственных и частных учреждениях для оцифровки и хранения информации.
Как мне извлечь текст из PNG?
Загрузите файл PNG в наш инструмент преобразования изображений в текст. Нажмите кнопку конвертировать, чтобы начать обработку, и оставьте все инструменту. Он будет автоматически извлекать текст из файлов PNG.
Распознаватель JPEG в TXT OCR
Распознаватель JPEG в TXT OCR
Распознаватель JPEG в TXT OCR — это приложение, предназначенное для распознавания текста в изображениях JPEG с помощью технологии оптического распознавания символов (OCR).Он может распознавать символы в изображениях, таких как JPEG, и сохранять символы в Microsoft Word или обычных текстовых файлах.
Распознаватель JPEG в TXT OCR бесплатен для ознакомления. Вы можете попробовать перед покупкой в течение ограниченного времени. После установки и запуска вы можете увидеть основной интерфейс приложения, как показано на рисунке 1. Открытое изображение JPG отобразится в левой части интерфейса. Слева кнопки на боковой панели предназначены для изменения параметров просмотра. Вы можете использовать и для увеличения и уменьшения изображения.Кнопки и предназначены для поворота изображения и приведения изображения в правильную ориентацию. Если изображение имеет неправильную ориентацию, приложение не распознает символы правильно.
Рисунок 1
На панели инструментов выберите Файл -> Открыть , чтобы открыть изображение JPEG, а затем выберите команду -> OCR . Приложение начнет распознавать символы на изображении. Распознанные символы будут отображаться в текстовом поле справа.В текстовом поле вы можете редактировать текст как редактируемый текст в других текстовых редакторах. Если вы хотите очистить текстовое поле и повторить распознавание, просто нажмите кнопку. После редактирования текста выберите Файл -> Сохранить или Сохранить как , а затем выберите целевой формат, например txt. Распознанный текст будет сохранен в виде обычного текстового файла и его можно будет редактировать позже.
Помимо распознавания символов в изображении JPEG, распознаватель JPEG to TXT OCR поддерживает такие форматы ввода, как BMP, GIF, PNG, TIFF и PDF.Вы также можете сохранить распознанный текст в формате Microsoft Word.
Есть больше поддерживаемых функций, и вы можете щелкнуть и просмотреть больше функций распознавателя JPEG в TXT OCR .
Как исправить ошибки распознавания текста с помощью Adobe Acrobat
Оптическое распознавание символов, обычно сокращенно OCR, — это процесс преобразования файлов изображений, содержащих буквы и слова (например, отсканированные изображения или фотографии), в доступные для поиска текстовые документы.
Теперь, когда правила электронной подачи во многих штатах, например в Калифорнии и Техасе, требуют, чтобы документы, поданные в электронном виде (, включая экспонаты ), были доступны для поиска по тексту, важно понимать процесс распознавания текста и то, как выявлять и исправлять ошибки.
Подробнее: Как сделать PDF-текст доступным для поиска >>
Самая большая проблема с процессом распознавания текста? Это очень редко бывает идеально. Хотя оригиналы хорошего качества (например, снимки экрана или сканирование набранных букв с высоким разрешением) могут быть распознаны со 100% точностью, изображения более низкого качества будут распознаваться менее точно.
Таким образом, сканированные изображения с низким разрешением или нечеткие факсы могут плохо воспроизводиться. Точно так же почерк почти никогда не будет точно распознан как текст.
Поэтому, когда вы сканируете изображения, чтобы включить их в документы в суд, очень важно провести аудит результатов OCR и исправить любые явные и существенные ошибки, прежде чем рассматривать документ как окончательный и готовый к подаче в суд.
Как проверить качество распознавания текста
Acrobat предлагает функцию, называемую «предварительная проверка», часть которой позволяет сделать видимым текст OCR (то есть скрытый текст, помещенный под изображением и отражающий символы, которые программа распознала при применении OCR).
Вот как сделать этот скрытый текстовый слой видимым, чтобы вы могли проверить его точность:
Шаг первый
Откройте документ с оптическим распознаванием текста в Adobe Acrobat. Теперь на правой панели инструментов введите «предварительная проверка» в поле поиска. Выберите Preflight под Optimize PDF.
Шаг второй
Откроется диалоговое окно Preflight . В поле поиска введите «Сделать OCR». Из появившихся опций выберите Сделать текст OCR видимым , а затем щелкните Анализировать и исправить.
Acrobat попросит вас переименовать файл. Рекомендуется добавить примечание, например «_Review» к имени файла, чтобы вы могли легко идентифицировать эту версию позже.
Шаг третий
Теперь, чтобы проверить качество примененного OCR, вам необходимо просмотреть слой OCR. Чтобы просмотреть этот слой, откройте панель Layers , щелкнув значок слоев в левом меню.
Четвертая ступень
Откроется панель Layers .Вы увидите два доступных слоя, которые можно просмотреть. По умолчанию отображаются как отсканированное изображение, так и невидимый текст. Чтобы проверить качество OCR, вам нужно отключить изображение, чтобы вы могли видеть только слой OCR. Снимите отметку с глазного яблока рядом со значком Visible page content , чтобы выключить его.
Теперь на экране виден только текст OCR. Как видно из примера, качество OCR — особенно для рукописных разделов — часто, мягко говоря, довольно низкое.
Бесплатная загрузка: узнайте больше о навыках работы с Adobe Acrobat, которые жизненно важны для успешного электронного хранения, в нашей бесплатной электронной книге >>
Как исправить ошибки распознавания текста
Если текст, который не был правильно опознан, особенно уместен, вы можете улучшить качество поиска документа, исправив невидимый текст вручную. В Acrobat:
это делается в два этапа.
Шаг первый
Откройте документ с оптическим распознаванием текста в Acrobat.На правой панели инструментов «» найдите «Правильно» и выберите параметр « Корректировать распознанный текст » под Улучшить сканирование .
Шаг второй
Функция Correct Text появится в верхней части экрана. Проверить Просмотрите распознанный текст. Подозреваемые ошибки будут выделены красным цветом. Просто выберите ошибку, введите правильный текст и нажмите Принять .
Как видите, это довольно трудоемкий и трудоемкий процесс.Таким образом, вы можете принять решение, основываясь как на важности подаваемого документа, так и на вашем лучшем представлении о качестве оригинала, к которому вы применили OCR, при принятии решения о том, сколько усилий вы хотите приложить для аудита вашего PDF-файла.
***
Бесплатная электронная книга: основные навыки работы с Adobe Acrobat для успешной электронной подачи >>
Как использовать Live Text в iOS 15 и iPadOS 15
Apple внесла в iOS 15 несколько интересных и замечательных улучшений.Но среди всех функций Live Text привлек мое внимание. В конце концов, встроенная функция OCR может помочь вам распознавать, копировать и использовать текст из изображений или живых сценариев.
Итак, что такое Live Text и как его можно использовать на iPhone и iPad. Присоединяйтесь ко мне, когда я углублюсь в эту новую функцию iOS и сравню ее с Google Lens.
Что такое Live Text в iOS 15?
Live Text — это интеллектуальная интегрированная функция распознавания текста в iOS 15; он распознает и оцифровывает текст на фотографиях.Отсканированный текст можно использовать несколькими способами: от копирования и вставки до поиска в Интернете.
Кроме того, Live Text может похвастаться следующими особенностями:
Теперь все это открывает двери для множества вариантов использования, от оцифровки рукописных заметок до сканирования номера / адреса на ходу и записи рецептов или квитанций до получения дополнительной информации о ресторане на картинке.
Live Text iOS 15 поддерживаемых устройств
Хотя это очень удобная функция, не все пользователи iOS, iPadOS или macOS могут ею воспользоваться.Для запуска функции Live Text на вашем устройстве у вас должно быть:
- iPhone и iPad с A12 Bionic или новее и под управлением iOS 15 / iPadOS 15 или новее
- iPhone XS и новее
- iPad Pro 2020 и новее
- iPad Mini 5-го поколения
- iPad Air 2019 или новее
- iPad 2020
- Mac с процессором M1 и macOS Monterey.
Как распознать текст с помощью камеры iPhone в iOS 15
- Запустите приложение Camera и направьте его на текст, который вы хотите захватить.
- Коснитесь общей области текста . Вы увидите, как вокруг него образуется желтая скобка.
- Теперь коснитесь значка Live Text (с желтыми скобками и текстом внутри) в правом нижнем углу страницы.
- Выберите нужный текст, и вы можете
- Скопируйте текст в буфер обмена и вставьте его при необходимости.
- Выбрать все , чтобы выделить весь текст и символы на изображении.
- Look Up для поиска выделенного текста в Интернете.
- Переведите , чтобы преобразовать текст на поддерживаемый язык.
- Поделиться … для отправки текста через Сообщения, электронную почту, WhatsApp или любое другое приложение.
Как скопировать текст с изображений в iOS 15
- Откройте приложение « Фото» и выберите фотографию.
- Коснитесь значка Live Text в правом нижнем углу страницы.
- Проведите пальцами по тексту, чтобы выделить его.
- Теперь скопируйте и вставьте, найдите, переведите или поделитесь текстом.
Как скопировать текст с камеры iPhone в любое приложение
- Запустите приложение по вашему выбору; Я, например, делал заметки.
- Нажмите и удерживайте экран, чтобы вызвать плавающее окно параметров.
- Выбрать текст из камеры ; экран разделится на две части с камерой внизу.
- Перенести объект с текстом в поле зрения камеры; Live View автоматически начнет распознавать текст и вставлять его в приложение.
- При необходимости выделите текст и нажмите Вставить , чтобы завершить процесс.
Как позвонить или написать по электронной почте напрямую с помощью Live Text в iOS 15 и iPadOS 15
- Запустите приложение камеры и направьте его на номер телефона / адрес электронной почты или откройте приложение «Фото» и выберите изображение.
- Коснитесь значка Live View .
- Выберите
- Телефонный номер: вы можете позвонить, отправить сообщение, FaceTime или скопировать номер.
- Идентификатор электронной почты: Открывает почтовое приложение по умолчанию, чтобы вы могли быстро составлять и отправлять почту.
Примечание : Это также работает с адресами; просто отсканируйте изображение с помощью Live View и коснитесь адреса. он откроется в приложении «Карты».
Вы уже тестировали функцию Live Text? Поделитесь с нами своим мнением в разделе комментариев ниже.
Подробнее:
Как воспользоваться преимуществами оптического распознавания символов в Google Keep
Если вы ищете самый быстрый способ ввести текст в Google Keep, запустите приложение камеры Android и сделайте снимок нужного текста.Джек Уоллен покажет вам, как это сделать.
Изображение: Джек Уоллен
Google Keep — одно из лучших облачных приложений для ведения заметок на рынке, и Google постоянно добавляет новые способы сделать этот инструмент еще более полезным. Одним из таких дополнений является возможность сделать снимок, а затем быстро скопировать текст в цифровой формат. Это означает, что вы можете сфотографировать чью-то визитную карточку и почти мгновенно получить ее данные в текстовом формате…все без ввода единой строки текста.
Как вы это делаете? Простой. Позвольте мне показать вам, как это сделать.
Во-первых, в отличие от извлечения текста из изображений, уже сохраненных на вашем локальном компьютере или в Google Фото, оптическое распознавание символов с помощью камеры работает только с мобильным приложением (по понятным причинам). Но когда вы сделали фотографию и извлекли текст, он автоматически синхронизируется с каждым экземпляром Google Keep, который вы связали с вашей учетной записью Google.
Для этого выполните следующие действия:
- Откройте Keep на своем мобильном устройстве.
- Коснитесь значка камеры в правом нижнем углу.
- Нажмите «Сделать фото».
- Сделайте снимок изображения.
- Нажмите на галочку, когда будете довольны фотографией.
- В появившемся окне коснитесь кнопки меню (три вертикальные точки).
- Нажмите «Захватить текст изображения» (, рис. A, ).
- Заголовок примечания.
- При необходимости отредактируйте заметку.
- По завершении нажмите кнопку «Назад».
Рисунок A
Изображение: Джек Уоллен
Работа с Google Keep на Nexus 6 под брендом Verizon
Вскоре после того, как вы присвоите заметке заголовок, она синхронизируется с вашей учетной записью (и со всеми вашими устройствами). Вы можете снова редактировать заметку, добавлять теги и делать с ней все, что вам нужно.
Одна удобная функция, которую добавил Google, — это возможность удалить связанную фотографию из заметки.Для этого откройте заметку, а затем нажмите значок корзины, связанный с изображением (, рис. B, ).
Рисунок B
Изображение: Джек Уоллен
Удаление исходного изображения из заметки в настольном клиенте.
Я протестировал этот метод на нескольких источниках и обнаружил, что способность Keep правильно извлекать текст весьма впечатляет; даже с более длинными абзацами, не теряйте из виду.
Попробуйте эту функцию Google Keep
Вам не нужно тратить время на ввод слов в Google Keep — не тогда, когда изображение стоит тысячи этих слов. Попробуйте эту функцию Keep и посмотрите, не превратится ли она в ваш любимый способ быстро получить информацию на ходу и отправить ее прямо в облако Google.
См. Также
10 лучших API для OCR
OCR означает оптическое распознавание символов и обеспечивает способ чтения букв и цифр с изображений, рукописных заметок, счетов-фактур и квитанций, видео или любых других визуальных носителей и преобразования их в машиночитаемый текст.
Очевидно, что это полезная технология для разработчиков всех видов приложений, включая бухгалтерский учет, электронную коммерцию и розничную торговлю, юриспруденцию, идентификацию транспортных средств, здравоохранение, банковское дело, перевод и множество других применений. А способ интеграции служб OCR с приложениями — использование интерфейсов управления прикладными программами или API.
Лучшее место для поиска подходящих API, которые могут позволить приложениям расшифровывать текст, находится в категории ProgrammableWeb OCR.
В этой статье мы подробно рассмотрим десять самых популярных API-интерфейсов OCR на основе просмотров страниц читателя на ProgrammableWeb .
1. Free OCR API
Free OCR APITrack этот API анализирует изображения и многостраничные документы PDF (PDF OCR) и возвращает извлеченный текст в формате JSON. API можно использовать с любого устройства, подключенного к Интернету, включая мобильные устройства Android и iOS, а также устройства IoT.
2. Intento API
Intento (Inten.to) предоставляет единый интерфейс для нескольких моделей когнитивного ИИ и поставщиков. Этот API-интерфейс Intento APITrack предоставляет ответы JSON для перевода текста, добавления тегов к изображениям, анализа тональности, оптического распознавания символов (OCR) и транскрипции речи.Что касается OCR, он охватывает технологии из ABBYY, API Google Cloud Vision и API Microsoft Computer Vison.
3. API CAPTCHAS.io
CAPTCHAs.IO — это служба автоматического распознавания капчи, которая поддерживает более 30 000 кодов изображений, звуковых кодов и reCAPTCHA v2 и v3, включая невидимую reCAPTCHA. CAPTCHAs.IO APITrack этот API обеспечивает RESTful доступ ко всем методам решения капчи CAPTCHAs.io. Разработчики могут выбрать получение ответов API в формате JSON или в виде обычного текста.
4. API поиска российских автомобильных номеров
APITrack поиска российских автомобильных номеров. Этот API позволяет пользователям использовать камеру смартфона для захвата номерных знаков (Госномер) российского автомобиля и получения информации о марке и модели, году выпуска, ориентировочное изображение автомобиля, частичный номер VIN, и если автомобиль разыскивается российской полицией (Gibdd). Он предназначен для использования на автомобильных сайтах, ориентированных на российский рынок.
5. Google Cloud Vision API
Google Cloud Vision APITrack этот API предоставляет разработчикам доступ к инструментам распознавания, обработки и анализа изображений.Служба классифицирует изображения по тысячам категорий (например, «грузовик», «тигр», «Эмпайр-стейт-билдинг») и обнаруживает отдельные объекты и лица на изображениях. Его компонент OCR может обнаруживать более 50 различных языков, включая смешанный текст. Также он распознает почерк. Он может распознавать текст в нескольких форматах изображений, включая TIFF, GIF, PDF, JPG и Animated GIF.
6. Cloudmersive API оптического распознавания символов
Cloudmersive предоставляет масштабируемые API компьютерного зрения и естественного языка.Cloudmersive Optical Character Recognition APITrack этот API позволяет пользователям преобразовывать отсканированные изображения страниц в распознанный текст. API использует машинное обучение для автоматической предварительной обработки и последующего распознавания текста на более чем 90 языках. Он также расшивает и поворачивает изображения, а также может автоматически сегментировать документы и квитанции из фотографий.
Cloudmersive OCR API позволяет приложениям определять товары по отсканированным квитанциям. Изображение: Cloudmersive
7. Mathpix API
Этот API-интерфейс Mathpix APITrack позволяет пользователям решать математические уравнения с помощью технологии OCR.С помощью API разработчики могут реализовывать обработку изображений, системы уравнений, матрицы, длинные деления, номера задач, графики и геометрические диаграммы. Приложение можно скачать для Android и iOS. Этот API поддерживает научную нотацию, используемую в химии, математике, физике, информатике, экономике и других предметах STEM.
8. Captcha Solutions API
Captcha Solutions — это веб-служба декодирования CAPTCHA, предлагающая решения на основе фиксированной ставки за каждую решенную CAPTCHA. Этот RESTful APITrack этот API предназначен для решения большого количества задач CAPTCHA для широкого спектра приложений.Он на 90% основан на системе распознавания текста и на 10% состоит из людей.
9. NewOCR API
NewOCR APITrack этот API может преобразовывать текст в файлах JPG, PNG, GIF, BMP, TIFF, PDF и DjVu в текст. API предлагает бесплатные и платные службы OCR для 122 языков распознавания и шрифтов, выбор области на странице для OCR, автоповорот, несколько способов отображения и обработки результирующего текста, включая копирование в буфер обмена и редактирование в Документах Google, несколько форматов ввода, включая многостраничный PDF или несколько изображений в ZIP-архиве, анализ макета страницы, распознавание математических уравнений, а также поддержка плохого сканирования и изображений с низким разрешением.
10. API Den OCR
API Den предоставляет API для услуг B2B. API Den OCR APITrack этот API позволяет приложениям иметь возможности OCR, включая поддержку более 120 языков. OCR преобразует изображения печатного, рукописного или напечатанного текста в машинно-кодированный текст. Сервис считывает фотографии, документы, фотографии с места событий, паспорта, банковские выписки и все остальное и может отображать в обычном текстовом формате или в формате XHTML.
Дополнительные API-интерфейсы, а также SDK и образцы исходного кода можно найти в категории OCR.
Оптическое распознавание символов | Распознавание текста OCR
Обзор
- Оптическое распознавание символов (OCR) — широко используемая система в области компьютерного зрения
- Узнайте, как создать собственное распознавание текста для различных задач
- Мы будем использовать библиотеку OpenCV и Tesseract для создания системы распознавания текста.
Введение
Вы помните дни, когда во время экзамена вам приходилось ставить точки над правильным ответом? Или как насчет теста на способности, который вы дали перед первой работой? Я хорошо помню олимпиады и тесты с множественным выбором, когда университеты и организации использовали систему оптического распознавания символов (OCR) для массового оценивания листов ответов.
Честно говоря, OCR находит применение в широком спектре отраслей и функций. Таким образом, все, от сканирования документов — банковских выписок, квитанций, рукописных документов, купонов и т. Д., До чтения уличных указателей в автономных транспортных средствах — все это подпадает под действие системы распознавания текста.
Системы оптического распознавания текста
были довольно дорогими и громоздкими пару десятилетий назад. Но достижения в области компьютерного зрения и глубокого обучения означают, что мы можем создать нашу собственную систему распознавания текста прямо сейчас!
Но создание системы распознавания текста — непростая задача.Во-первых, он наполнен проблемами, такими как разные шрифты в изображениях, плохой контраст, несколько объектов на изображении и т. Д.
Итак, в этой статье мы рассмотрим некоторые очень известные и эффективные подходы к задаче распознавания текста и то, как вы можете реализовать их самостоятельно.
Если вы новичок в обнаружении объектов и компьютерном зрении, я предлагаю просмотреть следующие ресурсы:
Содержание
- Что такое оптическое распознавание символов (OCR)?
- Популярные приложения для оптического распознавания текста в реальном мире
- Распознавание текста с помощью Tesseract OCR
- Различные способы обнаружения текста
Что такое оптическое распознавание символов (OCR)?
Давайте сначала разберемся, что такое OCR, если вы раньше не сталкивались с этой концепцией.
OCR, или оптическое распознавание символов, — это процесс распознавания текста внутри изображений и преобразования его в электронную форму. Эти изображения могут представлять собой рукописный текст, печатный текст, например документы, квитанции, визитки и т. Д., Или даже фотографию естественной сцены.
OCR состоит из двух частей. Первая часть — это обнаружение текста , где определяется текстовая часть в изображении. Эта локализация текста внутри изображения важна для второй части OCR, распознавания текста , где текст извлекается из изображения.Используя эти методы вместе, вы можете извлечь текст из любого изображения.
Но нет ничего идеального, и OCR не исключение. Однако с появлением глубокого обучения стало возможным получить лучшие и более общие решения этой проблемы.
Прежде чем мы погрузимся в создание собственного OCR, давайте взглянем на некоторые из популярных приложений OCR.
Популярные приложения для оптического распознавания текста в реальном мире
OCR широко применяется в различных отраслях промышленности (в первую очередь с целью сокращения ручного труда человека).Он вошел в нашу повседневную жизнь до такой степени, что мы почти никогда этого не замечаем! Но они, безусловно, стремятся улучшить взаимодействие с пользователем.
OCR используется для задач распознавания рукописного ввода для извлечения информации. В этой области ведется большая работа, и мы добились действительно значительных успехов. Microsoft придумала потрясающее математическое приложение, которое принимает на вход написанное от руки математическое уравнение и генерирует решение вместе с пошаговым объяснением работы.
OCR все чаще используется для оцифровки в различных отраслях промышленности, чтобы сократить объем ручной работы. Это позволяет очень легко и эффективно извлекать и хранить информацию из деловых документов, квитанций, счетов-фактур, паспортов и т. Д. Кроме того, когда вы загружаете свои документы для KYC (Знай своего клиента), OCR используется для извлечения информации из этих документов и хранения их для дальнейшего использования.
OCR также используется для сканирования книг , где необработанные изображения преобразуются в цифровой текстовый формат.Многие крупномасштабные проекты, такие как проект Гутенберга, проект «Миллион книг» и Google Книги, используют OCR для сканирования и оцифровки книг и хранения произведений в виде архива.
Банковская отрасль также все чаще использует оптическое распознавание текста для архивирования документов, связанных с клиентами, например, вступительных материалов, чтобы легко создать клиентский репозиторий. Это значительно сокращает время адаптации и, таким образом, улучшает взаимодействие с пользователем. Кроме того, банки используют OCR для извлечения из чеков такой информации, как номер счета, сумма, номер чека, для более быстрой обработки.
Приложения OCR неполны, если не упомянуть об их использовании в беспилотных автомобилях . Автономные автомобили широко используют OCR для считывания указателей и дорожных знаков. Эффективное понимание этих знаков делает автономные автомобили безопасными для пешеходов и других транспортных средств, которые едут по дорогам.
Определенно существует множество других приложений OCR, таких как распознавание автомобильных номеров, преобразование отсканированных документов в редактируемые текстовые документы и многие другие.Я хотел бы услышать ваш опыт использования OCR — дайте мне знать в разделе комментариев ниже.
Оцифровка с использованием OCR, очевидно, имеет широкие преимущества, такие как простота хранения и обработки текста, не говоря уже о непостижимом объеме аналитики, которую вы можете применить к этим данным! OCR, безусловно, является одной из важнейших областей компьютерного зрения.
Теперь давайте посмотрим на один из самых известных и широко используемых методов распознавания текста — Tesseract.
Распознавание текста с помощью Tesseract OCR
Tesseract — это движок OCR с открытым исходным кодом, первоначально разработанный как проприетарное программное обеспечение HP (Hewlett-Packard), но позже открытый в 2005 году.С тех пор Google принял проект и спонсировал его разработку.
На сегодняшний день Tesseract может определять более 100 языков и обрабатывать даже текст с письмом справа налево, например на арабском или иврите! Неудивительно, что он используется Google для обнаружения текста на мобильных устройствах, в видео и в алгоритме обнаружения спама в изображениях Gmail.
Начиная с версии 4, Google значительно продвинул этот механизм распознавания текста. Tesseract 4.0 добавил новый движок OCR, который использует систему нейронной сети, основанную на LSTM (Long Short-term Memory), одном из наиболее эффективных решений проблем предсказания последовательности.Хотя его предыдущий механизм распознавания текста, использующий сопоставление с образцом, по-прежнему доступен как устаревший код.
После того, как вы загрузили Tesseract в свою систему, вы легко запустите его из командной строки, используя следующую команду:
tesseract-l --oem --psm
Вы можете изменить конфигурацию Tesseract для получения результатов, наиболее подходящих для вашего изображения:
- Langue (-l) — Вы можете определить один или несколько языков с помощью Tesseract
- Режим движка OCR (–oem) — Как вы уже знаете, Tesseract 4 имеет механизмы LSTM и Legacy OCR.Однако существует 4 режима допустимых режимов работы на основе их комбинации
3. Сегментация страниц (–psm) — Можно настроить в соответствии с текстом на изображении для получения лучших результатов
Pyteseract
Однако вместо метода командной строки вы также можете использовать Pytesseract — оболочку Python для Tesseract. Используя это, вы можете легко реализовать свой собственный распознаватель текста с помощью Tesseract OCR, написав простой скрипт Python.
Вы можете загрузить Pytesseract с помощью команды pip install pytesseract .
Основная функция в Pytesseract — это image_to_text () , которая принимает в качестве аргументов изображение и параметры командной строки:
Какие проблемы возникают с Tesseract?
Не секрет, что Tesseract несовершенен. Он плохо работает, когда изображение имеет много шума или когда шрифт языка тот, на котором Tesseract OCR не обучен.Другие условия, такие как яркость или перекос текста, также влияют на производительность Tesseract. Тем не менее, это хорошая отправная точка для распознавания текста с небольшими усилиями и высокой производительностью.
Различные способы обнаружения текста
Tesseract предполагает, что входное текстовое изображение довольно чистое. К сожалению, многие входные изображения будут содержать множество объектов, а не только чистый предварительно обработанный текст. Следовательно, становится крайне необходимо иметь хорошую систему обнаружения текста, которая может обнаруживать текст, который затем может быть легко извлечен.
Есть несколько способов обнаружения текста:
- Традиционный способ использования OpenCV
- Современный способ использования моделей глубокого обучения и
- Создание вашей собственной нестандартной модели
Обнаружение текста
с использованием OpenCV
Обнаружение текста с использованием OpenCV — классический способ решения задач. Вы можете применять различные манипуляции, такие как изменение размера изображения, размытие, пороговое значение, морфологические операции и т. Д., Чтобы очистить изображение.
Здесь у нас есть изображения в градациях серого, размытые и пороговые изображения в указанном порядке.
После того, как вы это сделаете, вы можете использовать обнаружение контуров OpenCV для обнаружения контуров для извлечения фрагментов данных:
Наконец, вы можете применить распознавание текста к контурам, которые вы должны предсказать текст:
Результаты на изображении выше были достигнуты с минимальной предварительной обработкой и обнаружением контуров с последующим распознаванием текста с помощью Pytesseract.Очевидно, не каждый раз контуры определяли текст.
Но, тем не менее, обнаружение текста с помощью OpenCV — утомительная задача, требующая много экспериментов с параметрами. Кроме того, это не очень хорошо с точки зрения обобщения. Лучший способ сделать это — использовать модель обнаружения текста EAST.
Современная модель глубокого обучения — EAST
EAST, или «Эффективный и точный детектор текста сцены», представляет собой модель глубокого обучения для обнаружения текста на естественных изображениях сцены.Он довольно быстрый и точный, так как способен обнаруживать изображения 720p со скоростью 13,2 кадра в секунду с F-оценкой 0,7820.
Модель состоит из полностью сверточной сети и стадии подавления без максимума для предсказания строки слова или текста. Модель, однако, не включает некоторые промежуточные шаги, такие как предложение кандидата, формирование текстовой области и разделение слов, которые использовались в других предыдущих моделях, что позволяет оптимизировать модель.
Вы можете посмотреть на изображение ниже, предоставленное авторами в их статье, сравнивая модель EAST с другими предыдущими моделями:
EAST имеет U-образную сеть.Первая часть сети состоит из сверточных слоев, обученных на наборе данных ImageNet. Следующая часть — это ветвь слияния функций, которая объединяет текущую карту функций с картой объектов без пула из предыдущего этапа.
За ним следуют сверточные слои для сокращения вычислений и создания выходных карт характеристик. Наконец, при использовании сверточного слоя на выходе получается карта оценок, показывающая наличие текста, и геометрическая карта, которая представляет собой либо повернутую рамку, либо четырехугольник, покрывающий текст.Это можно визуально понять по изображению архитектуры, которое было включено в исследовательскую работу:
Я настоятельно рекомендую вам самостоятельно просмотреть статью , чтобы получить хорошее представление о модели EAST.
OpenCV включает модель детектора текста EAST начиная с версии 3.4. Благодаря этому очень удобно реализовать собственный детектор текста. Полученные локализованные текстовые поля можно передать через Tesseract OCR для извлечения текста, и у вас будет полная сквозная модель для OCR.
Пользовательская модель
с использованием API объекта TensorFlow для обнаружения текста
Последний метод построения детектора текста — использование специально созданной модели детектора текста с использованием API объектов TensorFlow. Это платформа с открытым исходным кодом, используемая для создания моделей глубокого обучения для задач обнаружения объектов. Чтобы разобраться в этом подробнее, я предлагаю сначала прочитать эту подробную статью.
Чтобы создать собственный детектор текста, вам, очевидно, потребуется набор данных из нескольких изображений, по крайней мере, более 100.Затем вам нужно аннотировать эти изображения, чтобы модель могла знать, где находится целевой объект, и узнать о нем все. Наконец, вы можете выбрать одну из предварительно обученных моделей, в зависимости от компромисса между производительностью и скоростью, из зоопарка моделей обнаружения TensorFlow. Вы можете обратиться к этому всеобъемлющему блогу, чтобы создать свою собственную модель.
Сейчас. Обучение может потребовать некоторых вычислений, но если вам их на самом деле недостаточно, не волнуйтесь! Вы можете использовать Google Colaboratory для любых ваших требований! В этой статье вы узнаете, как эффективно его использовать.
Наконец, если вы хотите сделать шаг вперед и создать ультрасовременную модель детектора текста YOLO, эта статья станет ступенькой к пониманию всех ее мельчайших деталей, и вы получите отличный результат. Начните!
Конечные ноты
В этой статье мы рассмотрели проблемы распознавания текста и различные подходы, которые можно использовать для решения этой задачи. Мы также обсудили различные недостатки подходов и почему OCR не так просто, как кажется!
Работали ли вы раньше с каким-либо приложением OCR? Какие варианты использования OCR вы планируете создать после этого? Сообщите мне свои идеи и отзывы ниже.
.
Добавить комментарий