Распознавание японского текста с картинки
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:
В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.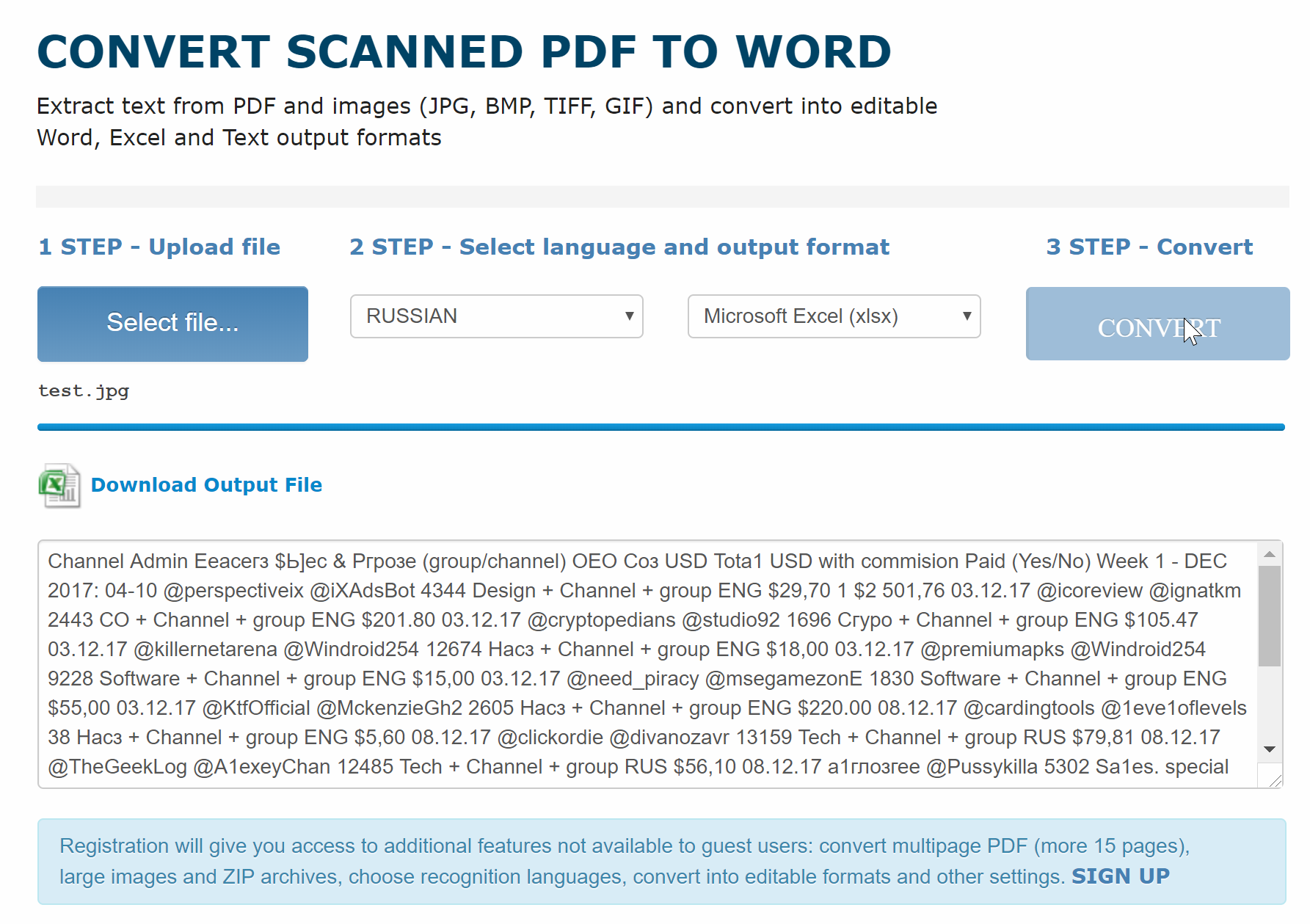
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
Мы уже рассматривали с Вами программу для распознавания текста с картинки. Но распознавать текст можно не только с помощью программы. Это можно делать с помощью онлайн сервисов, не имея никаких программ на своем компьютере.
И действительно, зачем устанавливать какие-то программы, если Вам нужно распознать текст один раз, и в дальнейшем Вы не собираетесь эту программу использовать? Или Вам нужно делать это раз в месяц? В этом случае лишняя программа на компьютере не нужна.
Давайте рассмотрим несколько сервисов, при помощи которых можно распознавать текст с картинки бесплатно, легко и быстро.
Free Online OCR
Очень хорошим сервисом для распознавания текста с картинки онлайн является сервис Free Online OCR. Он не требует регистрации, распознает текст с картинки практически любого формата. работает с 58 языками. Распознаваемость текста у него отличная.
Пользоваться этим сервисом просто. Когда Вы на него зайдете, перед Вами будет всего два варианта: загрузить файл с компьютера, или вставить URL-адрес картинки, если она находится в Интернете.
Если Ваше изображение находится на компьютере, нажимаете на кнопку Выберите файл , затем выбираете свой файл, и нажимаете на кнопку Upload . Вы увидите свой графический файл ниже, а над ним кнопку OCR . Жмете эту кнопку, и получаете текст, который Вы можете найти в нижней части страницы.
Online OCR Net
Также довольно неплохой сервис, который позволяет распознавать тексты с картинок онлайн бесплатно, и без регистрации. Поддерживает он 48 языков, включая русский, китайский, корейский и японский. Чтобы начать с ним работать, заходите на Online OCR, нажимаете кнопку Select file , и выбираете файл на своем компьютере. Существуют ограничения по размеру — файл не должен весить больше 5 Мбайт.
В соседних полях выбираете язык и расширение текстового документа, в котором будет полученный из картинки текст. После этого вводите капчу внизу, и нажимаете на кнопку Convert справа.
Внизу появится текст, который Вы можете скопировать, а выше текста — ссылка на загрузку файла с этим текстом.
ABBYY FineReader Online
Очень хороший сервис в плане своей многофункциональности. На ABBYY FineReader Online можно не только распознавать текст с картинки, но также и переводит документы из формата PDF в формат Word, переводить таблицы из картинок в Excel, и создавать документы PDF из сканов.
На этом сервисе есть регистрация, но можно обойтись и входом с помощью социальной сети Facebook, сервисов Google+, или Microsoft Account.
Преимущество такого подхода в том, что созданные документы будут храниться в Вашем аккаунте в течении 14 дней, и даже если Вы их удалите из компьютера, можно будет вернуться на сервис, и опять их скачать.
Online OCR Ru
Сервис, похожий на предыдущий, с информацией на русском языке. Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.
Кроме распознавания текста из картинок, сервис предоставляет возможность перевода изображений в форматы PDF, Excel, HTML и другие, причем структура и разметка документа будет соответствовать той, которая была на картинке.
На этом сервисе также есть регистрация, и файлы, созданные Вами с его помощью, будут храниться в Вашем личном кабинете.
Данные сервисы распознавания текста с картинок, на мой взгляд, самые лучшие. Надеюсь, они и Вам принесут пользу. Также, возможно, я не все хорошие сервисы осветил. Жду Ваших комментариев, насколько эти сервисы Вам понравились, какими сервисами пользуетесь Вы, и какие из них являются, на Ваш взгляд, самыми удобными.
Более подробные сведения Вы можете получить в разделах «Все курсы» и «Полезности», в которые можно перейти через верхнее меню сайта. В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
Также Вы можете подписаться на блог, и узнавать о всех новых статьях.
Это не займет много времени. Просто нажмите на ссылку ниже:
Подписаться на блог: Дорога к Бизнесу за Компьютером
Вам понравилась статья? Поделитесь, буду весьма признателен:
Также приглашаю добавиться в друзья в социальных сетях:
Еще по теме.
13 комментариев »
Попробовал сейчас сервис распознавания текста Free Online OCR — супер! Не знал, что такие есть. Про программы давно слышал, а онлайн не знал. Осталось только сканер купить и в библиотеке можно старые газеты сканировать и легко наполнять какие нибудь сайты. Или продавать тексты.
Это действительно классный сервис! Легок в работе и все понятно. Спасибо!
Насчет идеи для копирайтинга, это не ново. Особенно перепечатывание с бумаги в электронный вид было распространено когда вебмастера создавали сайты-сателлиты, чтобы продвинуть свои основные. Уникальный и грамотный текст хорошо индексировался и давал хороший вес для продвигаемого сайта.
Читал я уже про распознавание текста с отсканированных документов, только там через программу на компьютере, а не онлайн.
Тоже классная возможность:) Будем знать где такой сервис искать:)
Сегодня конкретно помог мне онлайн сервис по распознаванию текста. Пришлось искать эту статью. Теперь занес в закладки. Хочу сайт купить, а на одно продающемся стоит плагин от копирования. Не проверить было на копипаст. С помощью Online OCR сделанный скриншот перевел в электронный вид, проверил и передумал покупать.
Александр, сам пишешь тексты или покупаешь? Так часто публикуешь.
Так я смотрю по 2 статьи в день все в основном идет последние время. План под конец года нагоняешь?
А попробуйте еще сервис img2txt.com
Не знал, что есть подобные сервисы, обычно для этого использовал программы, отлично.
Пригодится, взял на заметку.
Спасибо ! Free Online OCR — реально работающая система. Перевёл с корейского, другие сайты не справились.
У «Free Online OCR» даже API есть с бесплатным лимитом.
Жаль, что услуга платная по конвертации файлов
Описание
Допустимые форматы: pdf (в т.ч. многостраничные), jpg, gif, jp2, jpeg, png, tiff (в т.ч. многостраничные), webp
Сервис позволяет бесплатно распознать текст онлайн с картинок и pdf файлов. После распознавания можно проверить текст на уникальность и орфографические ошибки. Результаты распознавания доступны по секретной ссылке, которой можно поделиться. Ссылка на результаты OCR хранится 7 дней.
Рекомендации
Для лучшего распознавания используйте картинки с разрешением не менее 300 dpi.
Старайтесь, чтобы строки текста располагались горизонтально, поправьте предварительно картинки в графическом редакторе, если строки слишком завалены.
Желательно обрезать ненужные края, особенно если там есть элементы, похожие на текст.
Оптимальным для распознавания являются картинки, сканированные планшетным сканером.
Http www onlineocr net — Вэб-шпаргалка для интернет предпринимателей!
Распознавание текста с картинки, OCR (optical character recognition), то есть превращение картинки в текст доступно бесплатно на многих сайтах в режиме онлайн. Но везде свое качество и свои ограничения на количество распознаваемых картинок.
Я проверила с десяток онлайн-сервисов и составила рейтинг лучших.
Для примера распознавала фотографию документа, который есть у каждого – свидетельство ИНН физического лица (разрешением 1275×1750 пикселей).
| Сервис | Нужна регистрация | Рейтинг | Адрес |
|---|---|---|---|
| да | 3 | https://drive.google.com/drive | |
| Abbyy Finereader | да | 5 | https://finereaderonline.com/ru-ru |
| Online OCR2 | — | 5 | http://www.onlineocr.net |
| Free Online OCR | — | 2 | https://www.newocr.com |
| OCR Convert | — | 4 | http://www.ocrconvert.com |
| Free OCR | — | 1 | www.free-ocr.com |
| I2OCR | — | 4 | http://www.i2ocr.com |
| Яндекс ОCR | Распознает и переводит. | 5 | https://translate.yandex.ru/ocr |
| Convertio | Работает своеобразно | 3 | https://convertio.co/ru/ocr/ |
В Google можно распознавать неограниченное количество картинок, лишь бы они поместились на Google Drive. Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
| Входные форматы | PDF , JPEG, PNG, GIF |
| Выходные форматы | Word, Open Document, RTF, Adobe PDF, HTML, Text Plain, Epub (но форматирование исчезает – нарушается компоновка картинок с текстом) |
| Размер файла | До 2 Мб |
| Ограничения | Ограничено только размером хранилищ Google. |
Качество исходника рекоменовано не меньше 10 пикселей по высоте для строки.
Как пользоваться
- Загрузите файл на страницу drive.google.com или выберите там уже загруженную картинку
- Нажмите правой кнопкой мыши на нужный файл.
- Выберите “Открыть с помощью” –> “Google Документы”.
- Картинка преобразуется в документ Google и откроется на вкладке https://docs.google.com
Abbyy Finereader
В Abbyy Finereader Online самый удобный интерфейс, хорошее качество, но доступна только ознакомительная версия – можно распознать не более 10 страниц за две недели. (200 страниц в месяц стоят 299р). Для использования сервиса нужно зарегистрироваться (можно войти через аккаунты социальных сетей). Кроме того, полученный текст можно там же перевести на другой язык с помощью машинного перевода.
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG |
| Выходные форматы | Word, Excel, Power Point, Open Document, RTF, Adobe PDF, Text Plain, Fb2, Epub |
| Размер файла | До 100Мб |
| Ограничения | 10 картинок на две недели |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Online OCR – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)
Как пользоваться
- Загрузите файлы
- Выберите язык
- Выберите выходной формат
- Щелкните кнопку «Распознать»
Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Как пользоваться
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Можно распознавать как все целиком, так и выделить часть изображения для распознавания.
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера Не забудьте правильно указать язык.
- Выберите область сканирования (можно оставить целиком как есть)
- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
- Внизу появится окно с текстом
OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Как пользоваться
- Загрузите файл, выберите язык и щелкните кнопку «Process»
Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
Как пользоваться
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”
I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert. |
Замечено, что сервис временами не работает.
Как пользоваться
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.
Перетащите картинку Результат распознавания
Convertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
| Входные форматы | pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp, webp |
| Выходные форматы | Text Plain, PDF, Word , Excel, Pptx, Djvu, Epub, Fb2, Csv |
| Размер файла | ?, зависит от тарифа |
| Ограничения | 10 страниц бесплатно, дальше тарифы от 7 долларов. |
| Качество | Сложно оценить – файл с картинками (ИНН) не распознал совсем, отдельно вырезанный кусок текста распознал. |
Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе.
Как пользоваться
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите капчу
- Щелкните “Преобразовать”
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.
Интерфейс Convertio
Вырезанный и распознанный кусок (целиком не распознается):
Результат работы Convertio
Заключение
Лучше всего документ распознал Abbyy Finereader и Online OCR. Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Хуже всего сработал Free OCR – он распознал всего три слова.
Распознавание текста онлайн — ТОП-9 сервисов: 3 комментария
СПАСИБО! И меня очень выручили… по поиску в яндексе мои попытки тоже были безуспешные, а статья помогла и выбрала отличный ресурс, который преобразовал все 30 страниц) к слову, нужно было очень быстро и срочно!)))
если есть такая возможность то напишите пожалуйста
есть страничка
на ней картинки с текстом
конкретно адреса электронной почты
https://www.math.fsu.edu/People/faculty.php
вопрос можно ли вытащить каким то средствами текст этих адресов
согласен что это не хорошо но увы нужно
сделайте скриншот, да распознайте картинку. Правда, качество там не очень
Описание
Допустимые форматы: pdf (в т.ч. многостраничные), jpg, gif, jp2, jpeg, png, tiff (в т.ч. многостраничные), webp
Сервис позволяет бесплатно распознать текст онлайн с картинок и pdf файлов. После распознавания можно проверить текст на уникальность и орфографические ошибки. Результаты распознавания доступны по секретной ссылке, которой можно поделиться. Ссылка на результаты OCR хранится 7 дней.
Рекомендации
Для лучшего распознавания используйте картинки с разрешением не менее 300 dpi.
Старайтесь, чтобы строки текста располагались горизонтально, поправьте предварительно картинки в графическом редакторе, если строки слишком завалены.
Желательно обрезать ненужные края, особенно если там есть элементы, похожие на текст.
Оптимальным для распознавания являются картинки, сканированные планшетным сканером.
В процессе написания реферата, дипломной работы или подготавливая доклад на заданную тему учащийся (абитуриент) использует довольно большие массивы информации. Именно в такие моменты пользователю может потребоваться услуга онлайн распознавание текста с картинки. Ведь зачастую необходимый для работы документ имеет не совсем приемлемый формат, а также может быть в виде скана, картинки или скриншота. В следствии чего, полноценное использование текстового материала с последующим применением основных элементов редактирования просто невозможно без программной поддержки онлайн инструментов, о которых и пойдет речь в этой статье.
Наиболее корректный распознаватель текста — Finereaderonline
Безусловным лидером представленного обзора является именно этот онлайн сервис. И все же, сразу оговоримся, среди бесконечного списка преимуществ данного текстового агрегатора нашлось и место для недостатков.
Существенный минус — это отсутствие бесплатной формы использования. Ограниченный вариант ознакомления с возможностями сервиса все же доступен, если вы пройдете весьма простой процесс регистрации.
В течении 15-ти дней вам дается право «распознать» десять документов. По истечении этого срока, а также исчерпав лимит на обработку данных необходимо купить один из аккаунтов доступа.
Совершенно бесплатные сервисы распознавания текста
[adsense2]
Таковых во Всемирной паутине невероятное множество. Однако наш выбор должен отвечать следующим критериям:
- Простота и неограниченность в использовании.
- Инструмент обязательно должен поддерживать русский язык.
- Высокий уровень функциональности.
Несмотря на соответствие ниже представленных сервисов упомянутым условиям, все же велика вероятность того, что в результате распознавания вы получите не совсем читабельный текст.
В некоторых случаях придется подкорректировать полученный контент, так сказать вручную. Тем не менее, это все же лучше, нежели руками перепечатывать большие объемы сканированного текста.
Free Online OCR — очень мощный инструмент распознавания
Без регистрации и каких-либо ограничений вы можете производить операции OCR преобразования с файлами следующих форматов: JPEG, PNG, GIF, JFIF, BMP, PBM, PPM, PGM, PCX, а также документов с расширением — TIFF, PDF, DjVu, DOCX, ODT и даже загружать на обработку некоторые ZIP архивы.
Сервис способен распознать 106 языков. Что немаловажно Free Online OCR поддерживает пакетную обработку данных. То есть загрузив многостраничный PDF файл вам останется лишь немного подождать, пока не будет завершен процесс распознавания. Сохранить на ПК полученный результат можно в виде: TXT, DOC, ODT, RTF, PDF или HTML документа.
Хотите попробовать Free Online OCR в действии, вам сюда — https://www.newocr.com/.
i2OCR — самый «объемный» обработчик
Используя данный веб инструмент, вы сможете загружать картинки и документы размером до 10 МБ. Незначительные неудобства в работе сервиса — это периодический ввод капчи.
Помимо основной функции распознавания i2OCR оснащен несколькими специальными кнопками навигации, посредством которых можно осуществить комфортный переход в определенную область редактирования.
Что касается поддерживаемых форматов графических файлов, то здесь воспринимаются основные и широко применяемые, все те же — JPG — PNG — BMP — TIF — РВМ — PGM – PPM. Вывод итогового документа можно произвести в виде DOC, PDF или TXT файла.
Воспользоваться данным сервисом можно здесь — http://www.i2ocr.com/.
OnlineOcr
Достаточно быстро функционирующий сервис позволяет в течении одного часа провести распознание 15-ти документов. Размер каждого из них (по отдельности) не должен превышать 5 МБ.
OnlineOcr поддерживает следующие графические форматы: JPEG, TIFF, BMP и GIF.
По завершению операции перевода текста из графического состояния в символьный формат, полученный результат можно сохранить в виде MS Word (DOC) или MS Excel (XLS) документа, а также с расширением TXT.
Попробовать инструмент в работе — http://www.onlineocr.net/
В заключение
Что ж, возможно какой-либо из сервисов вам действительно понравиться и, надеемся, окажется невероятно полезным. Ну а напоследок хочется дать вам, уважаемый читатель, несколько полезных советов. Во-первых, чтобы получить действительно качественный результат — первичный документ должен быть в высоком разрешении. Второе, всегда обращайте внимание на кнопку, где выбирается язык распознавания. Ну и третье, если первая «попытка» не принесла ожидаемого результата, то стоит попробовать другой вариант и даже следующий. В любом случае, знайте — безвыходных ситуаций не бывает!
Попробовал «Free online OCR» ввода капчи ни разу не обнаружил, убило только то, что за раз распознаётся всего одна страница, и с 415-ю страницами нужной мне книги пришлось потратить весьма изрядное количество времени. На «AABBYY online Fine Reader» программа тоже книгу распознать не смогла но прочла 5 страниц за раз, однако при цене 25 руб/страница распознавание выйдет дороже повторной покупки той же книги в нужном формате. На «Online — OCR» порадовала возможность загружать распознанные страницы последовательно в один файл и автоматический переход от страницы к странице, недостаток тот же, что и у её тёзки «Free» распознавание за раз только одной страницы.
Рекомендуем к прочтению
3 способа преобразования надписей на экране в печатный текст
Для преобразования текста, присутствующего на изображении, в текст печатный на рынке софта сегодня представлено достаточно многого программных продуктов. Это и известный Abbyy FineReader, и Scanitto Pro, и Ocr Cuneiform. Для разовых же задач можно использовать онлайн-технологии OCR – оптического распознавания текста. Загружаешь в такой сервис картинку, получаешь распознанный текст. Таких сервисов в сети много, достаточно ввести в поисковик запрос «текст распознать».
Многие из них бесплатны, ну или как минимум условно-бесплатны. Но как быть, если нужно активно работать с распознаванием текста на экране монитора? К примеру, при изучении интерфейса англоязычных программ, если его познания оставляют желать лучшего, или при необходимости извлечения текста со слайдов, электронных книг и подобного рода форматов некопируемого контента.
Для этих целей существуют программы по типу скриншотеров со встроенной технологией OCR. Рассмотрим ниже две таких для Windows, а также поговорим о способе преобразования нарисованного текста в печатный с помощью продукта Office Lens.
1. Easy Screen OCR
https://easyscreenocr.com/
Программа Easy Screen OCR – это минималистичный инструмент для захвата изображения на экране монитора со встроенной технологией Google OCR. Программа работает из системного трея, где можно вызвать её опции. Для захвата текста на экране жмём «Capture».
Запустится режим захвата экрана, мышью указываем область распознавания. Скриншот отобразится в программном окошке, во вкладке «Screenshot». Здесь жмём кнопку «OCR» для старта процедуры распознавания.
Далее переключаемся на вкладку «Text». Здесь увидим преобразованный текст и можем его скопировать.
У Easy Screen OCR есть и иной режим работы – распознавание текста с файлов изображений. В опциях в системном трее выбираем «Image OCR» и перетаскиваем во вкладку «Image» картинку.
Easy Screen OCR поддерживает множество языков распознавания, в частности, английский и русский. Но программа не определяет язык сама. Язык распознавания каждый раз при его смене необходимо задавать в настройках (Preferences).
Программа платная, распространяется по платной подписке за $9 в месяц. Есть полнофункциональная триал-версия.
2. Abbyy Screenshot Reader
https://www.abbyy.com/ru-ru/download/screenshot_reader/
Abbyy Screenshot Reader – производный продукт от Abbyy FineReader, работающий, соответственно, на базе технологии OCR от компании Abbyy. Это скриншотер с различными областями захвата экрана и возможностью выбора дальнейших действий – распознавание с копированием в буфер, с сохранением в текстовый файл, в документы Word и Excel, сохранение в снимок, копирование снимка в буфер и т.п. Поддерживает множество языков распознавания, языки распознаёт автоматически.
Работает программа из системного трея, здесь запускается окно захвата. Выставляем нужные параметры захвата – область экрана и тип выгрузки распознанного текста.
Жмём кнопку захвата, указываем область, если выбран захват области экрана. И далее получаем результат в зависимости от выбранного типа выгрузки.
Abbyy Screenshot Reader – платная программа, стоит $149. Есть триалка с 15-дневным тестовым периодом.
3. Office Lens в Windows 10
Обе рассмотренные программы, как видим, являются платными. В среде Windows 10 осуществить процедуру преобразования текста на картинке в текст печатный можно бесплатно, не прибегая при этом к помощи онлайновых OCR-сервисов. Для этого потребуется установить в Microsoft Store UWP-приложение Office Lens. Это сканер и редактор документов с выгрузкой изображения в различные форматы файлов, форматы продуктов Microsoft в частности.
Запускаем приложение и делаем фото надписи на экране. Либо же делаем скриншот, например, штатными «Ножницами» или новым приложением «Фрагмент и набросок», затем импортируем его в Office Lens.
Применяем к изображению фильтр «Документ», сохраняем.
Сохраняем его как файл PDF.
Открываем.
Копируем текст.
Вот, собственно, и всё.
6 лучших бесплатных онлайн-программ для оптического распознавания текста
Теперь вам не нужно такое приложение, как Adobe Acrobat, для извлечения текста из изображений или PDF-файлов. В Интернете есть множество программ OCR (оптического распознавания символов), которые выполняют аналогичную или лучшую работу без проблем с установкой приложения на ваш компьютер. Они также не зависят от платформы, так как все, что вам нужно, — это браузер. Самое приятное то, что с этим бесплатным онлайн-программным обеспечением OCR легко работать.
Лучшее бесплатное программное обеспечение для распознавания текста в Интернете
У каждого веб-приложения есть свои плюсы и минусы, которые мы четко перечислим.Обратите внимание, что вам необходимо загрузить файл в Интернете, что может представлять угрозу безопасности и конфиденциальности, хотя большинство веб-приложений заявляют, что удаляют файлы по истечении заданного периода времени.
1. Google Документы
Google Docs имеет скрытую функцию распознавания текста, о которой большинство пользователей не знает. Вы можете получить к нему доступ, загрузив файл PDF на Google Диск и открыв его с помощью Google Docs. Щелкните файл правой кнопкой мыши, наведите указатель мыши на Открыть с помощью, и щелкните Google Docs . Google Docs теперь автоматически конвертирует PDF в редактируемый формат.Вы можете отредактировать и сохранить файл обратно в формате PDF или скопировать из него любой текст.
Но вы не можете извлекать текст из изображений с помощью Google Документов.
Плюсы
- Возможность редактирования
- Возможность сохранения извлеченного текста в нескольких форматах, включая Microsoft Word
Минусы
- Не удается извлечь текст из изображений
Откройте Документы Google
2. Google Keep
В то время как Google имеет функцию распознавания текста для извлечения текста из PDF-файлов, Google Keep делает то же самое для изображений.Все, что вам нужно сделать, это открыть Google Keep, создать новую заметку и загрузить изображение с текстом, используя значок изображения. После добавления изображения к заметке щелкните значок меню с тремя точками и выберите Захватить текстовое изображение . Вот и все. Google Keep захватит весь текст с изображения и добавит его в саму заметку, чтобы вы могли редактировать или копировать.
Единственная проблема с Google Keep заключается в том, что он иногда портит форматирование, добавляя новую строку в середине предложения или не оставляя пробелов между абзацами.Тем не менее, он точно извлекает текст, но не работает с PDF-файлами.
Плюсы
- Простота использования и редактирования
- Возможность копировать извлеченный текст в Google Docs изнутри
Минусы
- Не удается извлечь текст из PDF-файлов
- Есть несколько проблем с форматированием
Откройте Google Keep
Также читайте: 16 Google Keep Notes Советы и уловки, чтобы оставаться организованными (2020)
3.Верстак
Google Docs и Google Keep помогают извлекать и редактировать текст из PDF-файлов и изображений соответственно. Workbench — это простая бесплатная онлайн-программа для распознавания текста, которая извлекает текст как из изображений, так и из документов. После загрузки он извлечет текст и поможет вам легко скопировать его с помощью простой кнопки Копировать текст . Помимо компьютера, вы также можете загружать изображения и документы из популярных облачных хранилищ, таких как Google Drive, Dropbox, Box и т. Д.
Хотя пользовательский интерфейс понятен и прост в работе, ему не хватает мелких функций, таких как возможность редактировать извлеченный текст.Хотя точность достаточно высока, было бы удобно внести изменения перед копированием текста. Может в будущем обновлении?
Плюсы
- Простой и минимальный пользовательский интерфейс
- Возможность загрузки из основных облачных сервисов хранения данных
Минусы
- Невозможно редактировать извлеченный текст
Open Workbench
4. OnlineOCR
В то время как большинство бесплатных программ онлайн-оптического распознавания текста поддерживает изображения и документы, онлайн-оптическое распознавание текста также поддерживает файлы GIF.Это также одно из редких программ оптического распознавания текста, которое позволяет загружать извлеченный текст в документ Microsoft Word. OnlineOCR сохранит макеты, форматирование, таблицы, столбцы и графику из исходного файла в преобразованный документ. В отличие от Workbench, вы можете редактировать текст перед его копированием.
У
Online OCR не очень хороший интерфейс с множеством объявлений на странице.
Плюсы
- Поддерживает множество форматов файлов, включая GIF.
- Возможность сохранения текста как Microsoft Word
Минусы
- Не очень хороший интерфейс с множеством объявлений на странице
Открыть OnlineOCR
5.Преобразование
В то время как все службы позволяют загружать только одно изображение или документ, Convertio позволяет загружать до 10 изображений одновременно. Вы можете выбрать платный план, который начинается с 4,99 доллара, чтобы загружать еще больше изображений и поддерживать неограниченный размер для каждого файла. Он также поддерживает несколько форматов файлов, таких как текстовые файлы, текстовые документы, CSV и epub. Вы можете добавить документ из облачного хранилища, такого как Диск, Dropbox и т. Д., И после этого загрузить его обратно.
Единственная проблема с расширением заключается в том, что оно не поддерживает такие типы файлов, как webp и GIF.
Плюсы
- Возможность загрузки нескольких фотографий или PDF-файлов одновременно
- Поддержка облачного хранилища
- Поддерживает Microsoft Word
Минусы
- Не поддерживает многие форматы файлов, такие как Webp
Open Convertio
6. Копировальная рыба
Это не веб-приложение, а расширение Chrome, которое может извлекать текст из любого места в браузере, будь то изображение, видео, документ или даже веб-сайт, который не позволяет копировать правой кнопкой мыши.Расширенные функции начинаются от 19,92 долларов в месяц, включая автоматическое определение языка и поддержку рукописного ввода.
У расширения нет серьезных недостатков, но тарифные планы Pro довольно дороги.
Плюсы
- Может извлекать текст из любого места в Интернете
- Версия Pro также поддерживает рукописный текст
Минусы
- Pro планы основаны на подписке и дороги
Скачать Copyfish Extension
Подведение итогов: лучшее бесплатное программное обеспечение для оптического распознавания текста Onlinr
Хотя Документы Google и Google Keep извлекают текст из PDF-файлов и изображений соответственно, вы также можете редактировать текст перед его копированием.В то время как Workbench и Online OCR — простые инструменты для всех, позволяющие быстро извлекать текст из многих поддерживаемых форматов файлов. Convertio — это инструмент OCR, который поддерживает извлечение текста из нескольких файлов одновременно, а Copyfish может извлекать текст из чего угодно в браузере независимо от формата файла.
Если вы сочтете это полезным, мы рассмотрели приложения OCR для Android, iOS и Windows.
Топ-5 лучших онлайн-инструментов OCR для извлечения текста из изображения
Вам надоело писать или у вас проблемы с копированием? У вас есть проблемы с вводом текста, который был ранее опубликован? Например, OCR — это технологический прогресс, который облегчил нашу рабочую жизнь.Лучшая электронная технология для преобразования письменного текста или документов в легкодоступные текстовые данные — это оптическое распознавание символов.
Он помог пользователям повысить эффективность их рабочих процессов. С помощью OCR можно идентифицировать текст в изображениях, отсканированных документах и фотографиях, что экономит время и предоставляет вам новый полезный документ.
Оптическое распознавание символов (OCR) было впервые представлено в начале 1990-х годов и теперь предлагается в виде облачной службы в Интернете.С тех пор было внесено много улучшений, и теперь это наиболее широко используемый инструмент для распознавания фотографий, документов и простого извлечения идентифицируемых данных. Использование оптического распознавания символов (OCR) значительно выросло с годами. Отофон, например, был разработан в 1940 году и в конечном итоге позволил слепым людям читать текст.
Многие приложения OCR, такие как распознавание данных, рукописный ввод и извлечение информации из печатных текстов, сделали его более доступным, чем когда-либо прежде.Также возможно использование этого программного обеспечения в качестве словаря; он просто обнаруживает термин, уменьшает количество ошибок, а затем продолжает сканировать текст на наличие ошибок.
OCR эволюционировало до такой степени, что теперь оно может читать более сложный текст, рукописный текст и печатные материалы.
1) Онлайн OCR
Сканеры, факсы, снимки, PDF-файлы и электронные книги могут быть преобразованы в текст с помощью этой программы. Вы можете загружать неограниченное количество файлов, хранить свои данные в безопасности, редактировать файл в Google Документах, а затем переводить и размещать его в Интернете на веб-сайтах после того, как вы его загрузили.
Можно использовать различные типы файлов ввода и вывода, такие как JPEG и JFIF, а также обычный текст (TXT) и Microsoft Word (DOC), а также Adobe Acrobat (PDF).
2) Газировка PDF OCR
OCR в настоящее время широко используется, и можно создавать PDF-файлы как онлайн, так и офлайн с помощью настольного приложения Soda Pdf, которое можно загрузить на ПК. Используя содовый PDF-файл, вы можете распознать текст во многих файлах. Если вы используете OCR, вы можете копировать, вставлять и изменять текст в PDF-документе.
Когда вы закончите, вы сможете получить доступ к своему PDF-файлу на своем компьютере, загрузив его. Существует множество возможностей, включая преобразование текста в PDF, преобразование PDF из текста, преобразование изображения в текст и управление файлами PDF.
3) OCR Space
OCR позволяет превращать отсканированные фотографии со смартфона или текстовые документы в файлы с возможностью поиска. Его можно использовать совершенно бесплатно, но он защищает ваши данные, как ничто другое. Загрузите файл, запустите OCR, получите результаты и изучите наложение определенных изображений / текстов — все это простые процессы, которым нужно следовать.
Если вы используете бесплатный тарифный план, вы можете загружать не более 1 МБ фотографий и PDF-файлов. Если вы обновитесь до премиум-версии, ваш лимит загрузки не ограничен. Поддерживается множество различных языков OCR, включая китайский, японский, немецкий и английский. Однако он ограничивается работой с напечатанными файлами.
4) Отсканированный PDF-файл в Word Online
Один из способов сэкономить время — загрузить отсканированные файлы PDF и преобразовать их в редактируемые файлы Word. Преимущества использования механизма распознавания текста включают облегчение вашей жизни.Это упрощает извлечение текста из отсканированных файлов PDF и делает их доступными для поиска.
Пока вы не указываете им свой адрес электронной почты при регистрации, ограничений нет. Они удаляют ваши файлы после преобразования, поэтому они в безопасности. Поскольку его можно использовать на любом компьютере, установка инструмента преобразования не требуется.
5) Преобразование
Оптическое распознавание символов (OCR) так же просто, как и сам термин convertio.Отсканируйте документы и фотографии в удобочитаемый формат файла, а затем загрузите их. Вы можете выбирать из множества типов файлов, включая PDF, JPG и PBM.
Языки и параметры вывода можно настроить в соответствии с вашими потребностями. Если в конце нажать кнопку распознавания, ваш файл будет преобразован, загружен и готов к использованию.
Кнопка оптического распознавания символов (OCR). В этот момент текст будет извлечен из изображения.
Этот сайт позволяет вам публиковать текстовые изображения в любое время, и он предоставит вам необработанный текст этих изображений, который вы можете легко скопировать и вставить в другие документы.JPEG, PNG, GIF, BMP, TIFF, PDF можно преобразовать в текст.
Capture2Text
Capture2Text
Содержание
Что такое Capture2Text?
Capture2Text позволяет пользователям быстро распознавать часть экрана с помощью
Сочетание клавиш. Полученный текст по умолчанию будет сохранен в буфер обмена.
Концептуальная иллюстрация:
Capture2Text распространяется бесплатно и под лицензией GNU General Public License.
Скачать
Последнюю версию можно найти на странице загрузки Capture2Text, размещенной на SourceForge.
Системные требования
Поддерживаемые операционные системы:
- Окна 7
- Windows 8 / 8.1
- Окна 10
Примечание. Поддержка Windows XP была прекращена в Capture2Text v4.0.
Как запустить Capture2Text (установка не требуется)
- Распакуйте содержимое zip-файла.
- Дважды щелкните файл Capture2Text.exe. Вы должны увидеть значок Capture2Text на
в правом нижнем углу экрана (хотя он может быть скрыт, и в этом случае вы
нужно будет нажать на стрелку «Показать скрытые значки»).
Установка дополнительных языков OCR
По умолчанию Capture2Text поставляется со следующими языками: английский, французский, немецкий, японский, корейский, русский и испанский.
Если вы хотите установить дополнительные языки OCR, выполните следующие действия:
- Загрузите словарь соответствующего языка OCR.
- Откройте файл .zip, который вы только что загрузили, с помощью 7-Zip или аналогичной программы для распаковки.
- Перетащите все файлы, содержащиеся в zip-файле, в папку tessdata:
- Перезапустите Capture2Text.
Поддерживаются следующие языки распознавания текста:
| африкаанс (африкаанс) | греческий (элл) | одия (ори) | ||
| албанский (sqi) | гуджарати (гудж) | панджаби (амхарский) | гаитянский (шляпа) | персидский (fas) |
| древнегреческий (grc) | иврит (heb) | польский (pol) | ||
| арабский (ara) | хинди (хин португальский) | por) | ||
| Ассамский (asm) | Венгерский (hun) | Пушту (pus) | ||
| Азербайджанский (aze) | Исландский (isl) | Румынский (ron) | ||
| Баскский (eus) | Индийский (inc) | Русский (rus) | ||
| Белорусский (bel) | Индонезийский (ind) | Санскрит (san) | ||
| Бенгальский (ben) | сербский (srp) | |||
| боснийский (bos) | ирландский (gle) | сингальский (sin) | ||
| болгарский (bul) | итальянский (ita) | словацкий (sl) | ||
| бирманский (mya) | японский (jpn) | словенский (slv) | ||
| каталонский (cat) | яванский (jav) | испанский (спа) | ||
| Себуано (ceb) | Каннада (кан) | Суахили (swa) | ||
| Центральный кхмерский (khm) | Казахский (kaz) | Шведский (swe) | ||
| Чероки (chrokeghiz8) kir) | Сирийский (syr) | |||
| Китайский — упрощенный (chi_sim) | Корейский (kor) | Тагальский (tgl) | ||
| Китайский традиционный (chi_tra) | Курух ( | |||
| Хорватский (hrv) | Лаосский (lao) | Тамильский (tam) | ||
| Чешский (ces) | Latin (lat) | Telugu (tel) | латышский (lav) | тайский (tha) |
| голландский (nld) | литовский (lit) | тибетский (bod) | ||
| дзонгха (dzo) | македонский | Тигринья (tir) | ||
| Английский (eng) | Малайский (msa) | Турецкий (tur) | ||
| Эсперанто (epo) | Малаялам (mal) | |||
| Мальтийский (mlt) | Украинский (ukr) | |||
| Финский (fin) | Marathi (mar) | Urdu (urd) | ||
| Frankish (frk) | Математика / уравнения (equ) | Узбекский (uzb) | ||
| Французский (fra) | Среднеанглийский (1100-1500) (enm) | Вьетнамский (vie) | ||
| Галисийский (glg) | Среднефранцузский (1400-1600) (frm) | валлийский (cym) | ||
| грузинский (kat) | непальский (nep) | идиш (yid) | ||
| немецкий (deu) | норвежский (норвежский) |
Как выполнить стандартное распознавание текста
Выполните следующие действия, чтобы выполнить стандартный захват OCR с помощью блока захвата:
- Поместите указатель мыши в верхний левый угол текста, который нужно распознать.
- Нажмите горячую клавишу OCR (Windows Key + Q), чтобы начать захват OCR.
- Переместите указатель мыши, чтобы изменить размер синего поля захвата над текстом, который нужно распознать. Вы можете удерживать правую кнопку мыши и перетаскивать, чтобы переместить весь блок захвата.
- Нажмите горячую клавишу OCR еще раз (или щелкните левой кнопкой мыши или нажмите ENTER), чтобы завершить захват OCR.
Текст OCR будет помещен в буфер обмена, и появится всплывающее окно, показывающее захваченный текст (всплывающее окно может быть отключено в настройках).
Как и для всех снимков OCR, вы должны вручную выбрать язык, который вы хотите OCR, в настройках.
Чтобы изменить язык оптического распознавания текста, щелкните правой кнопкой мыши значок Capture2Text на панели задач, выберите параметр «Язык оптического распознавания текста», а затем выберите нужный язык.
Для быстрого переключения между 3 языками используйте клавиши быстрого доступа к языку OCR: Клавиша Windows + 1, Клавиша Windows + 2 и Клавиша Windows + 3. Языки быстрого доступа можно указать в настройках.
Если выбран китайский или японский язык, необходимо указать текст
направление (вертикальное / горизонтальное / авто) с использованием направления текста
горячая клавиша: Windows Key + O. Если выбрано авто, горизонтальное будет использоваться, когда
ширина захвата более чем вдвое превышает высоту, в противном случае вертикальная будет
использовал. Направление текста также влияет на то, как фуригана удаляется из японского текста.
(для японского) Capture2Text попытается автоматически удалить фуригану.
Как выполнить оптическое распознавание текста строки
Capture2Text может автоматически захватывать строку текста, ближайшую к указателю мыши.
Выполните следующие действия, чтобы выполнить оптическое распознавание текста строки:
- Наведите указатель мыши на строку текста, которую нужно захватить, или рядом с ней.
- Нажмите горячую клавишу Text Line OCR Capture (Windows Key + E).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR прямой текстовой строки
Capture2Text может автоматически захватывать строку текста, начиная с символа, ближайшего к указателю мыши, и продвигаясь вперед.
Выполните следующие действия, чтобы выполнить захват OCR прямой текстовой строки:
- Наведите указатель мыши на символ, с которого нужно начать, или рядом с ним.
- Нажмите горячую клавишу Захват прямого текста OCR (Клавиша Windows + W).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR пузырьков
Capture2Text может автоматически захватывать текст, содержащийся в пузыре речи / мысли комиксов, если пузырек полностью закрыт.
Выполните следующие действия, чтобы выполнить захват OCR в виде пузырьков:
- Поместите указатель мыши в пустую часть пузыря (не на текст).
- Нажмите горячую клавишу «Захват OCR» (Клавиша Windows + S).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как указать активный язык OCR
Чтобы указать активный язык OCR, щелкните правой кнопкой мыши значок в области уведомлений, выберите Язык OCR и выберите языки OCR из списка:
Перевод
Чтобы включить функцию перевода, сначала откройте диалоговое окно настроек (щелкните правой кнопкой мыши значок в области уведомлений и выберите «Настройки… «) и щелкнув вкладку» Перевести «.
Установите флажок «Добавить перевод в буфер обмена», чтобы добавить переведенный текст в буфер обмена с помощью предоставленного разделителя.
Установите флажок «Показать перевод во всплывающем окне», чтобы отображать переведенный текст рядом с текстом OCR во всплывающем окне. Например:.
Каждый установленный язык OCR может быть переведен на другой язык.
Примечание 1. Некоторые языки OCR не поддерживают перевод.Неподдерживаемые языки отображаться не будут.
Примечание 2: Для перевода требуется доступ в Интернет.
Настройки
Щелкните правой кнопкой мыши значок Capture2Text на панели задач в правом нижнем углу экрана, а затем выберите параметр «Настройки …», чтобы открыть диалоговое окно «Настройки». Вы можете навести указатель мыши на многие метки параметров, чтобы отобразить полезную подсказку, объясняющую этот параметр.
Вкладка «Горячие клавиши» позволяет указать, какие клавиши и модификаторы использовать для каждой горячей клавиши.Чтобы отключить горячую клавишу, выберите «
Текущий язык OCR: укажите используемый активный язык OCR. Вы также можете указать активный язык OCR в меню значка на панели задач.
Quick-Access Languages: языки, используемые для каждой из горячих клавиш быстрого доступа.
Белый список: Сообщите механизму распознавания текста, что захваченный текст будет содержать только указанные символы.
Черный список: Сообщите механизму OCR, что захваченный текст никогда не будет содержать указанные символы.
Ориентация текста: ориентация текста, который будет захвачен. Этот параметр используется только в том случае, если в качестве активного языка распознавания задан китайский или японский. Если выбрано «Авто», будет использоваться горизонтальное, если ширина захвата более чем в два раза превышает высоту, в противном случае будет использоваться вертикальное. Направление текста также влияет на то, как фуригана удаляется из японского текста. Вы также можете указать ориентацию текста в меню значка на панели задач или с помощью горячей клавиши «Ориентация текста».
Файл конфигурации Tesseract: расширенная функция, позволяющая указать файл конфигурации Tesseract.
Trim Capture: во время предварительной обработки OCR обрезайте захваченное изображение до пикселей переднего плана и добавьте тонкую границу. Точность распознавания текста будет более стабильной и даже может быть улучшена.
Deskew Capture: во время предварительной обработки OCR попытайтесь компенсировать наклон текста, обнаруженный при захвате OCR.
Содержит параметры для настройки автоматических захватов. Чтобы получить дополнительную информацию, наведите указатель мыши на метки параметров.
Позволяет указать цвета поля захвата OCR.Прозрачность можно изменить, настроив значение «Альфа-канал» в диалоговом окне выбора цвета.
Позволяет указать положение, цвет и шрифт предварительного просмотра. Вы можете отключить предварительный просмотр, сняв флажок «Показать окно предварительного просмотра».
Сохранить в буфер обмена: сохранить захваченный текст OCR в буфер обмена.
Показать всплывающее окно: показать захваченный текст OCR во всплывающем окне:
Сохранять разрывы строк: установите этот флажок, если вы не хотите, чтобы символы возврата каретки и перевода строки удалялись из захваченного текста.
Ведение журнала: позволяет сохранять все записи в указанный файл в указанном формате. В формате могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}, $ {linebreak}, $ {tab}. Формат по умолчанию: «$ {capture} $ {linebreak}».
Вызов исполняемого файла: расширенная функция, позволяющая вызывать исполняемый файл после завершения распознавания текста. Могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}. Пример:
C: \ Anaconda3 \ python.exe "C: \ Scripts \ test.py" "$ {capture}" "$ {translation}"
Позволяет выполнять замену текста. Поддерживает регулярные выражения. Текст слева будет заменен текстом справа. Для каждого языка OCR могут быть указаны разные замены.
См. Раздел перевода.
На этой странице можно включить функцию преобразования текста в речь, установить громкость и выбрать параметры (голос, скорость, высота тона) для использования для каждого языка OCR.
Включить преобразование текста в речь: включить преобразование текста в речь при захвате текста.
Если этот параметр отмечен и голос не установлен на «
Громкость: основная громкость функции преобразования текста в речь. Применимо ко всем языкам.
Язык OCR: укажите параметры речи для выбранного языка OCR.
- Скорость: Скорость преобразования текста в речь.
- Pitch: Высота голоса для преобразования текста в речь.
- Голос: Голос для преобразования текста в речь. Установите значение «
», чтобы отключить функцию преобразования текста в речь только для выбранного языка OCR.
Предварительный просмотр: предварительный просмотр текущей скорости, высоты тона и голоса.
Параметры командной строки
Использование: Capture2Text_CLI.exe [параметры]
Capture2Text может использоваться для распознавания файлов изображений или части экрана.Примеры:
Capture2Text_CLI.exe --screen-rect "400 200 600 300"
Capture2Text_CLI.exe --vertical -l "Китайский - упрощенный" -i img1.png
Capture2Text_CLI.exe -i img1.png -i img2.jpg -o result.txt
Capture2Text_CLI.exe -l японский -f "C: \ Temp \ image_files.txt"
Capture2Text_CLI.exe --show-languages
Параметры:
- ?, -h, --help Отображает эту справку.
-v, --version Отображает информацию о версии.
-b, --line-breaks Не удалять разрывы строк из текста OCR.-d, --debug Выводить захваченное изображение и предварительно обработанное
изображение для отладки.
--debug-timestamp Добавить метку времени для отладки изображений, когда
используя параметр -d.
-f, --images-file <файл> Файл, содержащий пути файлов изображений к
OCR. Один путь на строку.
-i, --image <файл> Файл изображения для OCR.Вы можете OCR несколько
файлы изображений, например: "-i -i
-i "
-l, --language <язык> используемый язык распознавания текста. Деликатный случай.
По умолчанию "английский". Использовать
опция --show-languages для вывода списка установленных
Языки OCR.
-o, --output-file <файл> Выводить текст OCR в этот файл.Если не
указано, будет использоваться стандартный вывод.
--output-file-append Добавить в файл при использовании параметра -o.
-s, --screen-rect <"x1 y1 x2 y2"> Координаты прямоугольника, определяющего область
экрана в OCR.
-t, --vertical OCR вертикальный текст. Если не указано,
предполагается горизонтальный текст.
-w, --show-languages Показать установленные языки, которые можно использовать
с опцией "--language".--output-format Формат для использования при выводе текста OCR.
Вы можете использовать эти токены:
$ {capture}: текст OCR.
$ {linebreak}: разрыв строки (\ r \ n).
$ {tab}: символ табуляции.
$ {timestamp}: время для этого экрана или каждого
файл был обработан.$ {file}: файл, который был обработан или
экран прямоугольник.
Формат по умолчанию - «$ {capture} $ {linebreak}».
--whitelist <символы> Распознавать только указанные символы.
Пример: «0123456789».
--blacklist <символы> Не распознавать указанные символы.
Пример: «0123456789».--clipboard Выводить текст OCR в буфер обмена.
--trim-capture Во время предварительной обработки OCR выполняется обрезка
изображение в пиксели переднего плана и добавьте тонкий
граница.
--deskew Во время предварительной обработки OCR попытаться
компенсировать наклон текста.
--scale-factor Коэффициент масштабирования для использования во время предварительной обработки.Диапазон: [0,71, 5,0]. По умолчанию - 3,5.
--tess-config-file <файл> (Дополнительно) Путь к конфигурации Tesseract
файл.
------
Для Capture2Text.exe (в отличие от Capture2Text_CLI.exe) вы можете указать дополнительную опцию:
--portable Хранить файл настроек .ini в том же каталоге
как.EXE файл.
Устранение неполадок и часто задаваемые вопросы
- Я получаю сообщение об отсутствии файла DLL, когда дважды щелкаю Capture2Text.exe.
Решение: установите распространяемый пакет Visual Studio 2015.
- Capture2Text вообще не работает. Что я могу сделать?
Возможные решения:
Убедитесь, что вы разархивировали Capture2Text.Поищите в Google, если не знаете, как
разархивировать файл.Убедитесь, что ваше антивирусное программное обеспечение не блокирует Capture2Text.
Обратитесь к документации, прилагаемой к вашему антивирусному программному обеспечению.Убедитесь, что вы скачали последнюю версию с
SourceForge.Перезагрузите компьютер.
Попросите внука помочь вам 🙂
- Я обнаружил ошибку!
Отлично! Создайте заявку и опишите ошибку.
- Я хочу сделать предложение.
Отлично! Создайте заявку и опишите свое предложение.
- Capture2Text выводит символы мусора.
Решение: укажите правильный язык OCR.
- Интересующий меня язык не отображается в меню языка распознавания текста.
Прочтите Установка дополнительных языков распознавания текста.
- Я не вижу значок Capture2Text на панели задач.персонаж).
- Я щелкнул значок Capture2Text в трее, но он ничего не сделал.
Вместо этого щелкните его правой кнопкой мыши.
- Capture2Text не работает на моем Mac.
Capture2Text — это программа только для Windows. Если у вас есть технический опыт,
не стесняйтесь портировать его (но не просите меня помочь). - Где деинсталлятор?
Нет ни одного. Capture2Text также не имеет установщика.Удалять
Capture2Text со своего компьютера, просто удалите каталог Capture2Text. - Где находится файл настроек .ini?
Введите «% appdata% \ Capture2Text» в проводнике Windows.
Вы можете удалить его, чтобы восстановить настройки по умолчанию.
- Как сделать Capture2Text портативным?
Вызовите Capture2Text.exe с параметром —portable. Вы можете создать для этого ярлык.Установка этого параметра заставит Capture2Text сохранить файл настроек .ini в том же каталоге, что и Capture2Text.exe (в отличие от «% appdata% \ Capture2Text», которое является обычным местом).
- Где находится исходный код?
Исходный код находится на SourceForge.
Сопутствующие инструменты для изучающих японский язык
- JGlossator (Windows)
Автоматический поиск японских слов, распознаваемых вами с помощью Capture2Text.Поддерживает искаженные выражения, чтения, звуковое произношение, примеры предложений,
акцент высоты тона, частота слов, информация о кандзи и грамматический анализ. Поддерживает словари EDICT и EPWING. - OCR манга для чтения (Android)
Бесплатное приложение для чтения манги для Android с открытым исходным кодом, которое позволяет быстро распознавать текст и выполнять поиск
Японские слова в реальном времени. Нет рекламы и никаких загадочных сетевых разрешений.
Поддерживает словари EDICT и EPWING.
10 лучших веб-сайтов для извлечения текста из изображений в Интернете бесплатно
Если вы ищете ответы на вопрос, например, какой веб-сайт лучше всего для извлечения текста из изображений в Интернете бесплатно ? Тогда мы рекомендуем вам ознакомиться с этой статьей, потому что мы собираемся поделиться с вами некоторыми из лучших доступных вариантов.
Всякий раз, когда возникает потребность в конкретном тексте из определенного изображения, вы обычно должны ввести весь текст.Давайте возьмем пример: иногда выполнение назначения становится трудным, потому что вам нужно самостоятельно вводить весь контент и информацию, а это происходит из-за того, что данные, которые мы получили, не в форме текста, а или доступны в виде изображений, таких как файлы pdf. . Теперь, если речь идет о наборе двух или трех строк, тогда все в порядке, но что, если вам нужно ввести несколько основных абзацев из файлов PDF. Я уверен, что от этого вас будет много времени тошнить.
Но больше не беспокойтесь, потому что с помощью программного обеспечения OCR вы можете легко извлекать текст из изображений и отсканированных страниц.Программное обеспечение OCR означает Оптическое распознавание символов, — это механическое или электронное преобразование сканированных изображений рукописного, машинописного или напечатанного текста в машинно-кодированный текст.
Давайте сократим этот чат и перейдем к теме, посвященной всей статье, то есть бесплатному онлайн-инструменту для извлечения текста из изображений. Для этого мы сократили список некоторых из лучших доступных веб-сервисов, чтобы включить их в этот список. И тут приходит первый:
1. Free OCR
Free-OCR.com — это бесплатный онлайн-инструмент OCR (оптического распознавания символов). Вы можете использовать эту службу для извлечения текста из любого изображения, которое вы предоставляете. Для использования этой услуги не требуется никакой регистрации. Все, что вам нужно сделать, это просто загрузить файлы изображений. Free-OCR принимает форматы JPG, GIF, TIFF BMP или PDF. Некоторые из ограничений, с которыми вы столкнетесь, заключаются в том, что изображения не должны быть больше 2 МБ, не шире или выше 5000 пикселей, и существует ограничение в 10 загрузок изображений в час.
2. Sciweaver– i2OCR
i2 OCR — еще один замечательный онлайн-инструмент, о котором я говорю здесь. Используя эту бесплатную службу OCR, вы можете конвертировать изображения отсканированных документов, факсы или снимки экрана в редактируемые текстовые документы.Одной из лучших особенностей i2OCR является то, что он поддерживает несколько форматов входных изображений, включая TIF, JPEG, BMP, PNG, PBM, GIF, PGM, PPM.
3. Online OCR
Это еще один отличный веб-инструмент, с помощью которого вы можете распознавать текст и символы из отсканированных документов PDF (включая многостраничные файлы), фотографий и изображений, снятых цифровой камерой. Что мне действительно нравится в этом инструменте, так это то, что его не нужно устанавливать на компьютер. Он поддерживает 32 языка распознавания.Одна вещь, в гостевом режиме вы можете конвертировать 15 изображений в час
4. Бесплатное онлайн-распознавание текста
Удивительный классный веб-сайт, который конвертирует отсканированные изображения в редактируемый текст. Free Online OCR — это бесплатная служба, которая позволяет легко конвертировать отсканированные документы, факсы, снимки экрана и фотографии в редактируемый текст с возможностью поиска, например DOC, TXT или PDF.
5. OCR Online
CR Online — это расширенное веб-приложение для оптического распознавания символов (OCR), способное превращать отсканированные бумажные документы и цифровые фотографии в текстовые файлы, которые вы можете редактировать и искать по тексту.
6. Новый OCR
NewOCR.com — это бесплатная онлайн-служба OCR (оптического распознавания символов), которая может анализировать текст в любом загружаемом вами файле изображения, а затем преобразовывать текст из изображения в текст, который вы можете легко редактировать на вашем компьютере.
7. To Text
To-Text Converter — это решение, которое позволяет конвертировать изображения, содержащие письменные символы, в текстовые документы без необходимости установки какого-либо программного обеспечения.
8.Извлечение OCR
Как и вышеупомянутые веб-службы OCR, извлечение OCR — это решение для извлечения текста из изображений. OCRextrACT поддерживает PDF, TIFF, PNG, JPG, BMP и PBM в качестве входных файлов. Размер загружаемого файла ограничен 5 МБ. Поддерживаются многостраничные форматы, такие как TIFF или PDF.
9. ABBYY FineReader Online
Еще одно онлайн-распознавание изображений и преобразование в редактируемые документы. FineReader Online позволяет конвертировать файлы в любой из следующих графических форматов BMP, PCX, DCX, JPEG / JPEG 2000, PNG, TIFF / TIF (включая многостраничные файлы), GIF и DjVu.
Добавить комментарий