Как перевести Pdf в Word?
Современные программы конвертеры форматов позволяют перевести графические форматы в текстовые, и наоборот. Эту возможность часто используют пользователи при создании своих документов. Например, можно найти в интернете pdf файл с необходимой оформленной информацией, и чтобы не набирать самому все заново, можно перевести Pdf в Word. Текстовый файл Word легко можно изменить или настроить, а также дополнить другой информацией. Далее мы как раз разберем вопрос, как перевести Pdf в Word наиболее удобным способом, и какие вообще способы есть.
Перед тем как перевести Pdf в Word воспользовавшись специальной программой или онлайн-сервисом, необходимо определить, как создан ваш pdf файл. В последнее время pdf файлы создаются на основе исходных текстовых или графических файлов, что позволяет перенести в pdf все шрифты и картинки без изменений, но pdf можно создать также из отсканированного документа, т.е. из картинок.
Для конвертирования таких разных pdf файлов необходимо применять совершенно разные программы и сервисы.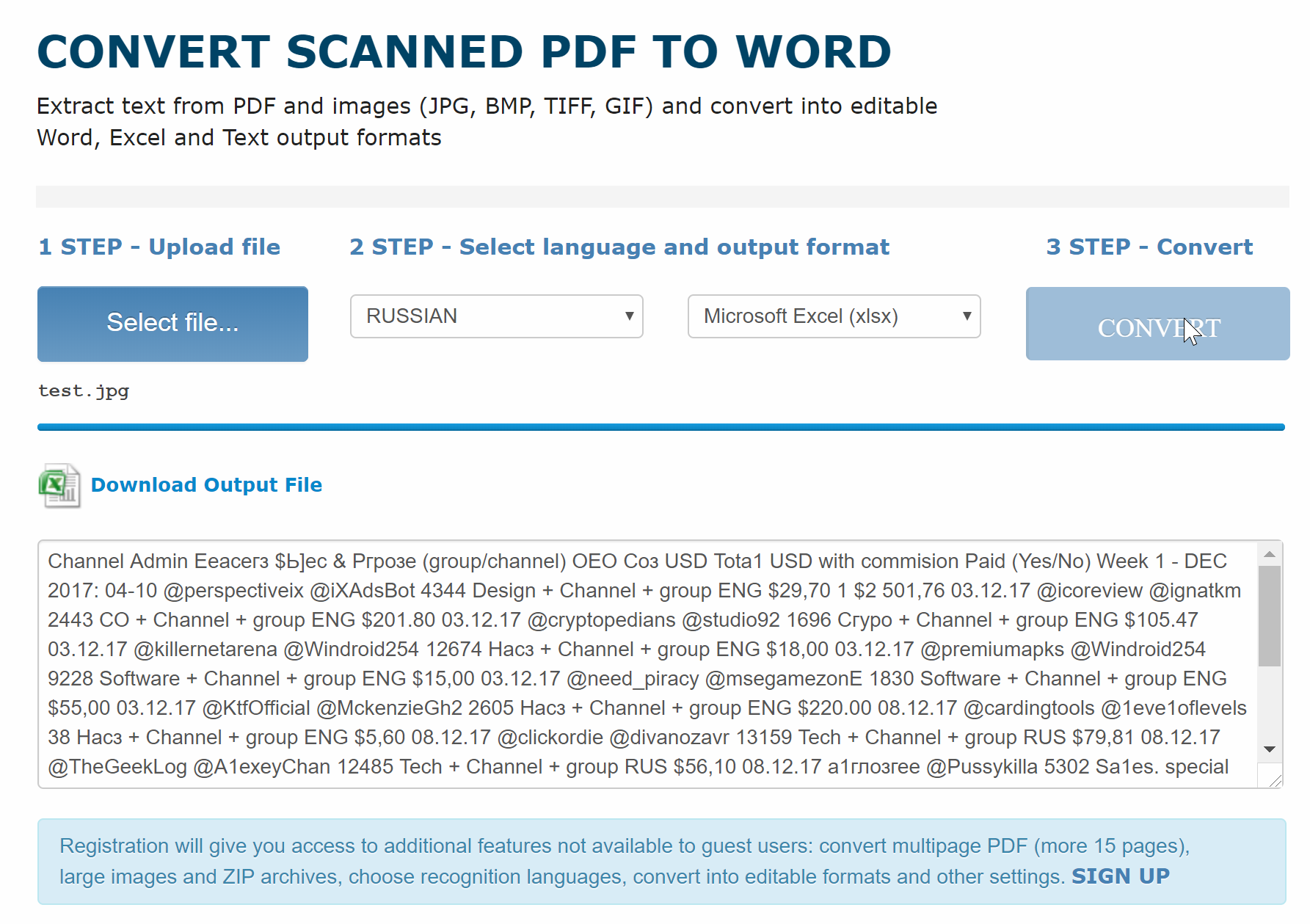 Определить, каким именно образом создан pdf файл, довольно просто. Достаточно его открыть любой программой для просмотра pdf файлов и попробовать воспользоваться инструментом выделения текста. Если текст выделяется, то файл создан на основе оригинального документа. Также можно определить визуально, если при значительном увеличении шрифт остается с ровными краями, то это качественных pdf на основе оригинала, а если шрифт становится с нечеткими краями, то документ создан на основе отсканированных картинок.
Определить, каким именно образом создан pdf файл, довольно просто. Достаточно его открыть любой программой для просмотра pdf файлов и попробовать воспользоваться инструментом выделения текста. Если текст выделяется, то файл создан на основе оригинального документа. Также можно определить визуально, если при значительном увеличении шрифт остается с ровными краями, то это качественных pdf на основе оригинала, а если шрифт становится с нечеткими краями, то документ создан на основе отсканированных картинок.
После того, как определились с качеством pdf файла, можно приступать к выбору соответствующей программы или сервиса. И так, если pdf создан из отсканированных картинок, то процедура конвертирования Pdf в Word становится гораздо сложнее. Вся проблема в том, что все эти программы и онлайн сервисы, которые предлагают перевести Pdf в Word, просто «вытаскивают» из качественного pdf файла текст и картинки, и переносят их в документ Word, а если в pdf файле содержаться только картинки, то и в Word будут перенесены только картинки. Для pdf файлов созданных из картинок необходимо рассматривать уже совершенно другой вопрос, а именно, как распознать текст? Кстати, текст распознать также можно и на онлайн-сервисах, подробнее об этом вопросе расписано в статье: Как распознать текст онлайн?
Теперь рассмотрим, какие неприятности нас могут ждать при переводе качественного Pdf в Word различными программами или сервисами. В интернете можно найти множество онлайн-сервисов, которые предлагают перевести Pdf в Word, но у всех у них есть ограничения на размер загружаемого pdf файла. Также не все сервисы могут качественно создать Word документ, перенося в него текст блоками, как в pdf файле, что делает редактирование текста очень затруднительным. Получить нормальный Word файл можно получить на онлайн-сервисе go4convert.com.
Программы, устанавливаемые на компьютер, могут перевести Pdf в Word уже без ограничения размера pdf файл, но некоторые из них также страдают созданием некачественного файла Word с текстом, расположенным блоками. Для примера можно попробовать программу PDF2Word, которая в демонстрационном режиме позволяет некоторое время переводить pdf в нормальный Word файл.
Также статьи на сайте chajnikam.ru связанные с программой Word:
Как сделать нестандартный размер шрифта в Ворде?
Как в Ворде установить линейку?
Делаем красную строку в Ворде
Как сделать перенос слов в Ворде?
Как перевести PDF документ в WORD?
В сегодняшнем видеоуроке я расскажу как распознать текст и конвертировать в Word с помощью бесплатной программы CuneiForm. В конце поста вы сможете скачать CuneiForm бесплатно…
После публикации поста PDF-Viewer vs Adobe Reader и Foxit Reader в комментариях появились вопросы о том, как редактировать сам текст документа, так как PDF-Viewer позволяет что-то вписывать в pdf документы, ставить штампы, заметки, но сам текст документа не изменяет…
Поэтому я пообещал, что сделаю видеоурок о программе распознавания текста, что и делаю сегодня! 🙂
Итак, вперед! 🙂
Как распознать текст и конвертировать в Word?
Если вы зададите поисковику найти «pdf в текст», «как распознать текст«, «конвертировать в word«, «перевести в ворд«, «распознавание текста со скана« или «скан в текст«, то найдете, в основном, только платные программы!
А в самом верху списка, конечно же будет ABBYY FineReader! 🙂
Действительно ABBYY FineReader — лидер среди программ распознавателей текста! Но его единственный недостаток — платность! Например, ABBYY FineReader 11 Professional Edition стоит 3590 р! ABBYY FineReader 10 Home Edition — 1340 р.
Вроде и недорого, но если мне раз в месяц нужно распознать документ, то нет смысла тратиться!
Хотя у меня есть бесплатная 6-я версия ABBYY FineReader! Она шла в программном обеспечении моего принтера EPSON. Но в лицензии написано, что я не имею права передавать ее кому-либо, более одного раза! 🙂
Можно, конечно, найти и пиратскую версию! Точнее взломанный FineReader с кряком или кейгеном или патчем, но это уже уголовное преступление!
Лучше все-таки распознать текст с CuneiForm?
Поэтому, хорошо поискав, я нашел совершенно бесплатную программу для распознавания текста и конвертирования в Word — CuneiForm!
CuneiForm, по качеству распознавания текста, ничем не уступает ABBYY FineReader! Единственный недостаток — CuneiForm не конвертирует pdf в текст!
Она делает распознавание текста со скана или фото!
Я в видеоуроке это не упомянул, но даже не обязательно сканировать документ! Можно воспользоваться программой для снятия скринов FSCapture! О том, как с ней работать, посмотрите видеоурок здесь…
Делаете скрин документа, сохраняете в JPG и распознаете в CuneiForm! Все очень просто! Кстати, FSCapture — очень полезная программа не только для снятия скринов! Очень рекомендую освоить!
Но, вернемся к CuneiForm!
Пользоваться программой очень легко! Перевести в Word текст можно всего одной кнопкой! Все делается пости на автопилоте! Уверен, что вы разберетесь даже без видеоурока! 🙂
Но все же можете посмотреть! И, если нужно скачать урок себе на компьютер, то здесь можете посмотреть, как это сделать!
Скачать CuneiForm, программу распознавания текста, можно здесь…
Теперь, собственно видеоурок —
Как конвертировать текст в Word из другого формата?
Как копировать страницу в word. Перемещение и копирование текста из документа в документ. Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Скачивая из Интернета различные документы, созданные в текстовом редакторе Microsoft Word, вам, возможно изредка попадаются такие, в которых нельзя скопировать защищенный текст и сам он запрещён к редактированию. В отдельных случаях на ресурсах, где размещены нужные вам файлы, указывается отдельно и пароль для снятия с них блокировки.
Но зачастую его нет, а угадать или подобрать его дело хлопотное. Обычно, документы Word защищаются владельцем от копирования и редактирования через функцию под названием «Защитить документ», расположенную в меню редактора «Рецензирование».
Поэтому, если владелец не хочет чтобы вы могли воспользоваться текстом в других своих целях, как кроме прочитать, это его право. Но что делать пользователю, если ему ну очень нужно скопировать текстовое содержимое, которое защищёно от копирования и редактирования или только определённую его часть?
Для этого существует очень простой способ, о котором я расскажу далее. Предупреждение — этот способ можно использовать только для извлечения текстового содержимого, а другие элементы, такие как картинки, мультимедиа-объекты, будут игнорироваться!
Демонстрация всего процесса будет проходить в операционной системе Windows 7 и офисном пакете Microsoft Word 2007. Вот так выглядит заблокированный для внесения изменений документ
ПОДГОТОВИТЕЛЬНАЯ РАБОТА
. Запускаем текстовый редактор Microsoft Word и создаём новый документ. По умолчанию он всегда запускается с пустым.
КАК СКОПИРОВАТЬ ЗАЩИЩЕННЫЙ ТЕКСТ
Переходим в раздел меню «Вставка», находим «Вставить объект», нажимаем на маленькую стрелочку возле него и кликаем по «Текст из файла…».
Выбираем нужный файл и нажимаем кнопку «Вставить».
После этой процедуры мы можем начинать работу с текстом. Редактировать, копировать и т.п.
После окончания работы с файлом переходим в меню «Сохранить как…» и сохраняем его под желаемым именем.
На этом пока всё! Вы узнали как скопировать защищенный текст. В следующей статье-инструкции я расскажу вам о способе, с помощью которого сможем снять защиту с запрещённого к редактированию документа. Советую не пропустить!
Если вам помогла инструкция или у вас возникли какие-либо трудности, то напишите об этом в комментариях. Также прошу ознакомиться с полным перечнем инструкций на моём ресурсе на отдельной странице — .
Довольно часто используется для публикации разного рода электронных документов. В PDF публикуются научные работы, рефераты, книги, журналы и многое другие.
Сталкиваясь с документом в PDF формате, пользователи часто не знают, как скопировать текст в Ворд. Если у вас также возникла подобная проблема, то наша статья должна вам помочь. Здесь вы узнаете 4 способа, как скопировать текст из PDF в Ворд.
Самый простой способ скопировать текст из PDF в Ворд это обычное копирование, которым вы пользуетесь постоянно. Откройте ваш PDF файл в любой программе для просмотра PDF файлов (например, можно использовать Adobe Reader), выделите нужную часть текста, кликните по ней правой кнопкой мышки и выберите пункт «Копировать».
Также вы можете скопировать текст с помощью комбинации клавиш CTRL-C. После копирования текст можно вставить в Ворд или любой другой текстовый редактор.
К сожалению, данный способ копирования текста далеко не всегда подходит. от копирования, тогда вам не удастся выполнить копирование текста. Также в PDF документе могут быть таблицы или картинки, которые нельзя просто так скопировать. Если вы столкнулись с подобной проблемой, то следующие способы копирования текста из ПДФ должны вам помочь.
Копируем текст из PDF файла в Word с помощью ABBYY FineReader
ABBYY FineReader это программа для распознавания текста. Обычно данную программу используют для распознавания текста на отсканированных изображениях. Но, с помощью ABBYY FineReader можно распознавать и PDF файлы. Для этого откройте ABBYY FineReader, нажмите на кнопку «Открыть» и выберите нужный вам PDF файл.
После того как программа закончит распознавание текста нажмите на кнопку «Передать в Word».
После этого перед вами должен открыться документ Ворд с текстом из вашего PDF файла.
Копируем текст из PDF файла в Word c помощью конвертера
Если у вас нет возможности воспользоваться программой ABBYY FineReader, то можно прибегнуть к программам-конвертерам. Такие программы позволят конвертировать PDF документ в Word файл. Например, можно использовать бесплатную программу .
Для того чтобы сконвертировать PDF документ в Word файл с помощью UniPDF вам нужно просто открыть программу, добавить в нее нужный PDF файл, выбрать конвертацию в Word и нажать на кнопку «Convert».
Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Также существуют онлайн конвертеры, которые позволяют сконвертировать PDF файл в Word файл. Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Использовать такие конвертеры довольно просто. Все что вам нужно сделать, это загрузить файл и нажать на кнопку «Конвертировать». А после завершения конвертации нужно будет скачать файл обратно.
Популярные онлайн конвертеры из PDF в Word.
Многим современным пользователям сейчас уже сложно в это поверить, но всеми функциями компьютера можно выполнять с клавиатуры, не используя для этого мышь. С непривычки это будет казать очень неудобным и нелогичным, но это так только на первый взгляд. Использование сочетаний клавиш для управления функциями компьютера вместо применения для этих целей мыши, позволяет выполнять многие операции гораздо быстрее. К использованию таких сочетаний, или как их еще принято называть «горячих клавиш» постепенно приходят все пользователи, у которых растет опыт работы в различных программах.
Когда вы работаете с текстовыми редакторами, пишите обзорные статьи, набираете или редактируете документы, то очень часто будете использовать операции копирования и вставки различных фрагментов текста. Освоив выполнение данных операций с помощью «горячих клавиш» вы будете приятно удивлены тем, насколько это эффективнее и удобнее.
Как скопировать текст с помощью клавиатуры
- Откройте любой текстовый документ. При этом совершенно не обязательно чтобы файл, из которого производится копирование, был открыт в таком же редакторе, что и документ в который этот текст будет вставлен.
Можно с одинаковым успехом копировать текст из Notepad и вставлять в Microsoft Word.
Главное, чтобы сам файл был текстового типа или содержал в себе информацию в данном виде.
- Выделите нужную часть текста мышью. Для этого установите ее курсор в начало нужного фрагмента, нажмите левую кнопку мыши и не отпуская кнопки проведите курсором до конца нужного участка текста. Отпустите кнопку. В результате данного действия выделенный фрагмент будет обозначен голубым фоновым цветом.
Если требуется выделить весь текст текущего документа, то для этого нажмите сочетание клавиш Ctrl + A (A — английское). Вначале нажимается клавиша Ctrl и не отпуская данной кнопки также нажимается клавиша A.
- После того, как текст выделен его можно скопировать в буфер обмена (оперативную память). Для этого нажмите сочетание клавиш Ctrl + C.
- Откройте документ, в которой необходимо вставить скопированный текст. Установите курсор на то место, в котором должна появиться данная ставка и нажмите сочетание клавиш Ctrl + V.
Гарантируем, что освоив методику копирования текста с помощью клавиатуры, вы будете удивлены насколько она быстрее и удобнее, чем регулярный вызов контекстного меню по правому клику мыши для копирования и вставки текста.
В заключении статьи приведем эти и некоторые другие полезные для работы в текстовых редакторах сочетания клавиш в виде небольшой таблицы.
Как глобальные, которые распространяются на все приложения, так и локальные, которые работают только в Word. Независимо от способа копирования теста, прежде всего, необходимо выделить ту его часть, которую планируете размножить. Поставьте курсор перед первым символом, который входит в копируемый текст. Нажмите один раз левую клавишу мыши. Удерживая клавишу нажатой, ведите указателем мыши до конечного символа, который необходимо копировать. Как только довели курсор до нужного места, отпустите кнопку мыши. Отмеченный текст будет отображаться белым шрифтом на черном фоне. Выделенную часть можно копировать.
Первый вариант копирования осуществляется с помощью выпадающего меню, которое появится, если кликнуть правой кнопкой мыши. На выделенном ранее , один раз кликните правой кнопкой мыши. Из открывшегося меню выберите пункт «Копировать». После нажатия на него ваш текст будет помещен в буфер обмена.
Следующий способ, который тоже относится к глобальным, заключается в использовании комбинации клавиш. После выделения необходимой части текста, нажмите комбинацию клавиш «Ctrl+C». После нажатия, выделенная часть текста будет скопирована в буфер.
Кроме указанных, есть способ копирования, который осуществляется с помощью нажатия внутренних комбинаций клавиш Microsoft Word. Выделите необходимую часть текста и нажмите сочетание «Ctrl+Ins». Выделенная част текста будет скопирована.
Помимо этого, после выделения текста, можно пройти в главном меню программы по адресу: «Правка» -> «Копировать». Текст также будет скопирован в буфер обмена.
Аналогичным образом осуществляется скопированного ранее текста. Поставьте курсор в ту часть текста, в которую хотите вставить фрагмент из буфера обмена. И по аналогии с копированием нажмите: «Ctrl+V» или «Shift+Ins» или правый клик мыши и «Вставить».
Источники:
- копируют текст
- Управление форматированием при вставке текста
MS Word – удобный редактор, с помощью которого можно создавать текстовые
документы, веб-страницы, графики и таблицы. Специальное меню «Правка» позволяет вносить изменения и исправления в готовые файлы.
Инструкция
Чтобы открыть документ, в меню «Файл» выбирайте команду «Открыть», укажите сетевой путь к файлу и нажмите кнопку «Открыть». Для выделения фрагмента текста, который нуждается в исправлении, наведите курсор на его начало, зажмите левую клавишу мыши и проведите до нужного места.
Этого же результата можно достичь, используя клавиатуру. Выделяйте мышкой начало фрагмента, зажмите клавишу Shift и кликайте в другом месте документа. Текст в этом промежутке будет выделен.Если использовать комбинацию Shift+Alt, выделение будет выглядеть как прямоугольный блок.
Если хотите отдельное слово, щелкните по нему дважды левой клавишей. Чтобы отметить предложение, зажмите на клавиатуре Ctrl и кликните любое слово из этого предложения. Для выделения всего документа в меню «Правка» выбирайте команду «Выделить все».
Чтобы выделенный текст заменялся новым, в меню «Сервис» выбирайте команду «Параметры» и переходите во вкладку «Правка». Поставьте флажок в чекбокс «Заменять выделенный текст при вводе». Если этот флажок снять, сначала придется удалить старый текст, а затем вводить новый.
Части текста можно перемещать внутри документа и переносить в другие документы. Выделяйте фрагмент, наведите на него курсор, зажмите левую клавишу мыши и, не отпуская, перетащите в другое место. Если использовать правую клавишу, то текст можно не только перемещать, но и копировать, и сделать . Выбирайте для этого нужные команды из выпадающего меню.
Перетаскивать мышкой текст удобно только на небольшие расстояния. Поместить его в другой документ таким образом уже не получится. Для этой цели используется буфер обмена – специальная область памяти редактора Word. Если вы хотите скопировать фрагмент текста, выделяйте его и нажмите на клавиатуре Ctrl+C. Затем переходите в новый документ, установите курсор в нужном месте и нажмите Ctrl+V. Возможно, вам нужно удалить фрагмент из одного документа и переместить его в другой, т.е. вырезать и вставить. В этом случае используйте сочетание Ctrl+X и Ctrl+V.
Если вы хотите запретить другим пользователям редактировать ваши документы, в меню «Сервис» выбирайте команду «Установить защиту». Можно разрешить посторонним вносить некоторые изменения:- запись исправлений;- вставка примечаний;- ввод данных в поля формы.Редактировать документ смогут только те, кому вы сообщите пароль. Пароль задается при установке защиты.
В Word 2007 есть возможность установить защиту только на часть текста. Выделяйте фрагмент, который будет доступен для редактирования другим пользователям. В меню «Сервис» выбирайте «Защитить документ». В правой части появляется окно настроек защиты. В разделе «2. Ограничение на редактирование» выбирайте тип ограничения. В разделе «3. Включить защиту» нажмите «Да, включить».
Видео по теме
Источники:
- выделить весь текст в ворде
При работе с документами, отсканированными книгами и пдф файлами часто возникает необходимость их редактирования. Для этого надо распознать текст в формате pdf и конвертировать его в обычный текстовой формат. Это можно сделать несколькими способами.
Распознать текст PDF
Электронные документы, созданные текстовым редактором, легко распознает бесплатная программа Adobе Rеadеr. Откройте в программе нужный PDF файл, зайдите в меню «редактировать», в выпадающем окне выберите строку «копировать в буфер обмена». Создайте в « » новый документ, вставьте в него из буфера обмена текс и редактируйте, затем сохраните в нужном формате.
Также конвертировать и редактировать пдф-файлы можете при помощи многофункциональной утилиты Acrobat Reader DC. Программный продукт располагает большим количеством инструментов для работы с электронными документами.
Это хорошие программы, но они не смогут распознать текст, если pdf-документы защищены от редактирования или отсканированы с бумажного носителя. В этом случае нужна специальная программа оптического распознавания символов.
Оптическое распознавание текста
Безусловным лидером является ABBYY FineReader, программа распознает и отдельные страницы, и работает в пакетном режиме. Обработанный текст можно сохранить в txt, doc, html и других форматах. Программа довольно качественно распознает текст pdf. Возможен небольшой процент неправильно распознаных символов и документу потребуется ручная доработка, результат зависит от качества сканов. У этой программы один недостаток – она платная.
Существуют и другие платные, а также бесплатные программы, позволяющие распознать и конвертировать текст из pdf в word: бесплатные – CuneiForm, Freemore OCR, FreeOCR; платные – Readiris Pro, Nitro PDF Professional.
Распознать текст онлайн
Если не каждый день преобразовываете электронные документы, просто возникла необходимость один раз поработать с форматом пдф, в этом случае нет смысла устанавливать на компьютер программу. Для таких эпизодов существуют сервисы. Также удобно пользоваться ими на работе, в путешествии, когда нет рядом компьютера с установленной программой. Онлайн сервисы позволяют распознать текст бесплатно и быстро. Вот некоторые:
Online OCR — www.onlineocr.net
NewOCR — www.newocr.com
Free-OCR — www.free-ocr.com
OCRConvert — www.ocrconvert.com
В распознавании много положительных моментов, но есть и минусы: на сервисе надо зарегистрироваться; не все сервисы имею функцию экспорта, надо самому распознанный текс копировать с веб-страницы; на некоторых сервисах установлен лимит на количество обрабатываемых документов; качество конечного результата зависит от скорости интернета.
Как выяснилось, распознать текст pdf несложно, существуют разные програмы, можите выбирать любую.
Любой пользователь с достаточным стажем работы с компьютером знает, что такое Copy и Paste (копировать, вставить). Копировать можно файлы и папки в Windows Explorer, копировать можно картинки, тексты в интернете
, в различных программах для работы с графикой, звуком, видео и текстом… Словом, работа с буфером обмена (clipboard), посредством которого осуществляются операции по копированию и вставке разнообразных объектов, является повседневной практически для каждого пользователя. Однако если вы впервые встречаете термины «копировать» и «вставить» применительно к компьютерным технологиям, рекомендуем срочно ознакомиться с таким методом работы.
Вам понадобится
- — компьютер
- — доступ в интернет
- — текстовый редактор
Инструкция
Необходимость сохранить часть какой-либо страницы в для последующего использования возникает довольно часто. Например, если вы пишете для , либо курсовую работу в институте. Работать с буфером обмена можно тремя способами: с помощью горячих клавиш, с помощью основного меню программы и с помощью контекстного меню.
Самый способ — первый — . Откройте интересующий вас сайт, выделите нужное слово, или абзац с помощью левой кнопки мыши (зажать левую кнопку в начале , «протащить» до конца предложения и отпустить). Если текст не помещается в экран, можно начать выделение, затем прерваться (выделить первую часть нужного текста), промотать до конца, зажать клавишу shift и кликнуть в конце текста. Затем используйте сочетание клавиш Ctrl + C для копирования, переключитесь в редактор (например, Microsoft Word) и нажмите Ctrl + V. Правильно нажимать горячие клавиши так: зажимается Ctrl, затем, не отпуская его, нажимается следующая кнопка (С или V), затем обе кнопки отпускаются.
Если вы не дружите с , для вас следующие два способа. С помощью контекстного меню копировать получается немного быстрее, чем меню файла. Выделите нужный текст (см. шаг №1), щелкните по нему правой кнопкой мыши, в контекстном меню выберите пункт «Копировать» (Copy). В разных браузерах этот пункт может формулироваться по-разному. Вставить в Word текст можно аналогичным образом — правый клик, в меню выбираем «Вставить» (Paste).
Третий способ самый верный, но самый долгий. После выделения нужного фрагмента текста вам следует обратиться к главному меню браузера. В любом браузере есть стандартный пункт «Правка» (Edit), он-то нам и . Не снимая выделения, нажмите Правка->Копировать (Edit -> Copy). Текст скопирован. Переключитесь в Word, в нем тоже есть главное меню и аналогичный пункт «Правка». Нажмите Правка -> Вставить.
Если перед вами стоит задача скопировать содержимое PDF файла и перенести его в документ Word, то сделать это обычным способом Copy – Paste скорее всего не удастся. Лучше использовать программу для конвертации.
Вам понадобится
- Программа PDF2Word или ABBYY PDF Transformer. Загрузка программ доступна на официальных сайтах: www.toppdf.com и www.pdftransformer.abbyy.com.
Инструкция
Как преобразовать DJVU в Word
DjVu – достаточно известный формат файла, который, как правило, используется для хранения учебников и часто художественной литературы в электронном виде (чаще где преобладают изображения). В том случае, если вам необходимо «вытащить» из DjVu текстовую часть и сохранить ее в документ Word, вам пригодится один из конвертеров, приведенных ниже.
Прежде нам доводилось подробнее рассказывать об особенностях файла DjVu и о том, какими программами данный файл можно открыть на компьютере. В том случае, если в текстовую составляющую файла DjVu вам необходимо вносить коррективы или требуется чтение документа практически на любом современном устройстве, то самым оптимальным решением будет выполнение процедуры конвертирование из DjVu в Docx.
Как конвертировать DjVu в Docx?
Вариант 1: конвертирование с помощью онлайн-сервиса Convertio
В том случае, если вам не требуется регулярное конвертирование DjVu-файлов, то лучше всего для процедуры преобразования файла в Word воспользоваться онлайн-конвертером, работа с которым будет выполняться прямо в окне браузера.
Для начала преобразования перейдите на страницу сервиса и щелкните по кнопке «С компьютера». На экране появится проводник Windows, в котором вам потребуется указать имеющийся DjVu-файл на компьютере.
При необходимости, вы можете добавить на страницу сервиса дополнительные DjVu-файлы. Теперь, чтобы приступить к конвертированию, вам потребуется щелкнуть по кнопке «Преобразовать».
Начнется процесс конвертирования, который займет некоторое время (продолжительность может растянуться в зависимости от размера и количества загруженных файлов). Как только процедура будет завершена, вам будет предложено скачать файл на компьютер.
К сожалению, сервису далеко не всегда удается распознать текст в файле, поэтому он внезапно может выдать ошибку работы.
Перейти на страницу сервиса Convertio
Вариант 2: конвертирование с помощью онлайн-сервиса NewOCR
Данный онлайн-сервис специализируется на распознавании текста различных форматов файлов. Суть в том, что с помощью данного онлайн-сервиса можно распознать текст в формат TXT, а затем лишь скопировать получившийся текст и вставить его в формат Doc.
Нюанс заключается в том, что в простеньком формате TXT будет полностью утеряно форматирование, но распознавание выполняется на очень высоком уровне.
Чтобы воспользоваться данным сервисом, вам потребуется загрузить в него DjVu-файл, а затем щелкнуть по кнопке «Preview».
Через некоторое время на экране отобразится окно настройки, в котором вам потребуется указать с какой страницы документа будет выполняться распознавание. Щелкните по кнопке «OCR».
Спустя мгновение, на экране отобразится текст документа, который можно скопировать и вставить в файл Docx и в последующем уже самостоятельно его отформатировать.
Перейти на страницу сервиса NewOCR
Вариант 3: конвертирование с помощью онлайн-сервиса PDF to DOCX
Формат DjVu по своей сути очень схож с форматом PDF, но в пользу второго стоит заметить, что он является самым популярным форматом документа в мире. К сожалению, найти онлайн-сервис или программу, которая бы позволила конвертировать DjVU в Docx практически невозможно, поэтому в данном случае мы пойдем обходным путем – конвертируем DjVu в PDF, а PDF, в свою очередь, в формат Docx.
Для начала пройдите на страницу сервиса DjVu to PDF по этой ссылке и щелкните по кнопке «Загрузить». На экране отобразится проводник Windows, в котором вам потребуется выбрать исходный DjVu-файл.
Сервис сразу начнет обработку загруженного файла. Как только обработка будет завершена, вам будет предложено загрузить результат на компьютер щелчком по кнопке «Скачать все».
На ваш компьютер будет загружен ZIP-архив, который для дальнейшей нашей работы потребуется распаковать. Теперь пройдите на страницу того же сервиса (ссылка ниже), который позволит перевести PDF в Docx. Точно таким же образом щелкните по кнопке «Загрузить», а затем укажите PDF-файл.
Сервис сразу начнет процедуру обработки. Снова ждем некоторое время, отслеживая процесс выполнения конвертирования. Данный тип конвертирования уже несколько сложнее, поскольку системе потребуется распознать весь текст документа, поэтому придется подождать несколько дольше.
Как только обработка будет завершена, щелкните по кнопке «Скачать все».
Собственно, на этом все. На ваш компьютер будет загружен ZIP-архив, который лишь остается разархивировать, «вытащив» требуемый файл Docx.
Перейти на страницу сервиса PDF to DOCX
Что в итоге
В данной статье были рассмотрены лишь онлайн-сервисы для конвертирования DjVu в Docx, но были упущены компьютерные программы. Если у вас есть на примете программы-конвертеры, идеально выполняющие поставленную в этой статье задачу, обязательно поделитесь ими в комментариях.
Бесплатное онлайн-распознавание текста — Часто задаваемые вопросы
Вы можете загружать любые файлы, содержащие текстовое изображение. Формат графического файла может быть любым из перечисленных ниже: TIF / TIFF (многостраничный TIFF), JPEG / JPG, BMP, PCX, PNG, GIF, PDF (многостраничный PDF) Единственное ограничение: размер файла не должен превышать 15 Мб в свободном доступе. гостевой режим и 200 мб для зарегистрированных пользователей. Для обеспечения хороших результатов распознавания разрешение изображения должно составлять 200 точек на дюйм или выше.
Вы можете загрузить более одного файла одновременно, поместив файлы в ZIP-архив (доступен только для зарегистрированного пользователя).
Если вам необходимо распознать изображение большего размера (более 200 Мб), обратитесь в службу поддержки.
Все документы, распознанные под учетной записью «Гость», автоматически удаляются после завершения процесса. Для зарегистрированных пользователей исходные документы и преобразованные файлы сохраняются в списке документов пользователя один месяц
После успешного распознавания текста в документах пользователя появляются ссылки на вновь созданные файлы вывода.Вы можете открыть файл для просмотра или загрузить его на свой компьютер.
Да, это возможно. В параметрах распознавания установите флаг «Многостраничный документ», а в поле для диапазона страниц укажите необходимые страницы через запятую (или диапазон страниц через дефис). Например, «14,26», будут распознаны только 14-я и 26-я страницы. Или будут распознаны «4,9-12», 4-я, 9-я, 10-я, 11-я и 12-я страницы.
Если в документе есть слова и предложения на разных языках, e.g., на английском и немецком языках, для достижения наиболее точного результата рекомендуется настроить необходимые языки при распознавании текста.
Да, если вы являетесь зарегистрированным пользователем, вы можете загрузить исходное изображение в своем рабочем пространстве.
Время распознавания текста зависит от множества факторов. Прежде всего, это качество изображения. Среднее время распознавания одного файла — несколько секунд.Второй важный фактор — текущая загруженность службы. Если запросы на распознавание поступают от разных пользователей одновременно, создается список ожидания.
Дополнительные страницы OnlineOCR.net можно приобрести в любое время, щелкнув ссылку «Купить страницы». Затем нажмите кнопку «КУПИТЬ», соответствующую количеству страниц, которые вы хотите купить. Все цены указаны в долларах США. OnlineOCR.net использует банковский сервис 2Checkout.com для обеспечения безопасных транзакций.После завершения транзакции вы вернетесь на страницу OnlineOCR.net с подтверждением вашего нового общего количества доступных страниц
Это может быть вызвано несколькими причинами.
1) Иногда возникает проблема со спам-фильтром. Пожалуйста, проверьте папку со спамом, так как она помогает в большинстве случаев. Это особенно актуально, если у вас есть учетная запись электронной почты hotmail, yahoo или gmail.
2) Проверьте, правильно ли вы ввели электронное письмо.
Преобразование отсканированного PDF в редактируемый Word
Используйте эту форму для загрузки отсканированного файла PDF и преобразования файла PDF в редактируемый файл Word. Макет будет сохранен в выходном файле Word.
1. Нажмите кнопку «Выбрать файл» (в разных браузерах может быть другое название кнопки, например «Обзор …»), откроется окно просмотра, выберите локальный файл Adobe PDF и нажмите кнопку «Открыть».
2.Выберите формат Word, нажмите «Конвертировать сейчас!» кнопку для преобразования. Подождите несколько секунд, пока не завершится преобразование файла. Эта онлайн-программа поддерживает:
- DOCX : Microsoft Office Word 2007/2010/2013/2016
- DOC : Microsoft Office Word 95 / 6.0 / 97/2000 / XP / 2003
- RTF : расширенный текстовый формат
3. Вы можете напрямую загрузить выходной файл Word в свой веб-браузер после преобразования.Для получения файлов не требуется адрес электронной почты.
Уведомление : Эта форма предназначена только для преобразования OCR. Щелкните здесь, если вы хотите преобразовать файл PDF с возможностью поиска в файл Word без обработки OCR.
Оптическое распознавание символов (OCR) : Оптическое распознавание символов (OCR) — это преобразование изображений в текст. Он широко используется в качестве формы ввода данных из печатных бумажных записей данных, будь то паспортные документы, счета-фактуры, банковские выписки, компьютеризированные квитанции, визитные карточки, почта, распечатки статических данных или любая подходящая документация.Это распространенный метод оцифровки печатных текстов, чтобы их можно было редактировать в электронном виде, искать, хранить более компактно, отображать в Интернете и использовать в машинных процессах, таких как машинный перевод, преобразование текста в речь, ключевые данные и интеллектуальный анализ текста. OCR — это область исследований в области распознавания образов, искусственного интеллекта и компьютерного зрения.
Как OCR с MS Office
На днях я получил задание от учительницы средней школы напечатать несколько прошлых экзаменов, которые она собирала в книгу.Контрольных работ было довольно много, если быть точным, файл того стоил.
Зная, что это будет проблемой с точки зрения времени и усилий, которые мне придется отложить, я решил найти гораздо более быстрое решение. Первое, что пришло мне в голову, это OCR (Optical Character Recognition) .
OCR — это в основном идентификация текста из файлов изображений. С точки зрения непрофессионала, можно представить себе как преобразование изображений в текст .
Таким образом,
OCR может сэкономить ваше время и деньги, которые в противном случае вы бы потратили на набор текста или передачу на аутсорсинг профессионалам.В моем случае мне удалось снизить нагрузку на эту конкретную работу примерно на 70-80%, и она была бы выше, если бы не несколько ошибочно идентифицированных символов и исправление некоторых диаграмм.
Для моих нужд OCR я выбрал MS Office. Я рассматривал другие варианты, прежде чем остановиться на нем, например, многофункциональный редактор PDF-XChange Editor, который связывает OCR со своим средством просмотра PDF. Однако в конечном итоге все они оказались менее способными по сравнению с механизмом распознавания текста в MS Office, который был более точным и быстрым.
Я полагаю, что это можно отнести к ним с использованием бесплатного движка Tesseract OCR, который, хотя и мощный сам по себе, имеет тенденцию уступать коммерческим альтернативам.
Начало работы: параметры оптического распознавания текста Microsoft Office
MS Office выполняет оптическое распознавание текста двумя способами:
- Использование OneNote
- Использование Microsoft Office Document Imaging (MODI)
Для этой цели подходят все версии OneNote 2007 и более поздних версий MS Office.Однако обратите внимание, что, начиная с Office 2019, приложение OneNote для Windows 10 заменило предыдущие версии Office, но не включает опцию распознавания текста.
Для MODI дела обстоят немного иначе, так как он давно снят с производства. MS Office 2007 был последней версией, в которой он был реализован. Однако вам не обязательно иметь MS Office 2007, поскольку его можно установить отдельно и использовать с более новыми версиями MS Office.
Что вам понадобится
- OneNote (любая версия Office 2007-2016)
- Для автономной функции распознавания текста вам потребуется SharePoint Designer 2007 для установки MODI.Вы можете получить его из двух источников:
- ,
- , автономный SharePoint Designer 2007, который предоставляется Microsoft для бесплатной загрузки. MS удалила ссылку из своего центра загрузки; вместо этого получите его из Softpedia.
- Если у вас уже есть лицензионная копия MS Office 2007, вы можете использовать ее вместо загрузки SharePoint Designer 2007.
- Изображение для OCR
- Сканер, если вы хотите использовать OCR во время процесса сканирования.
1.Как OCR с OneNote
- Запустите OneNote и начните с создания новой заметки .
- На ленте перейдите на вкладку Insert и вставьте изображение в OCR.
- Внутри заметки щелкните вставленное изображение правой кнопкой мыши и выберите Копировать текст с рисунка .
- Откройте MS Word или текстовый редактор и вставьте распознанный текст.
- Вы также можете найти текста в OneNote вместо того, чтобы копировать и вставлять его в другое место.Для этого щелкните вставленное изображение правой кнопкой мыши и выберите Сделать текст доступным для поиска по изображению, , затем выберите язык, на котором находится текст.
- Затем вы можете использовать Ctrl + F для поиска текста внутри изображения. Если он найдет совпадение, он будет выделен.
ПРИМЕЧАНИЕ: Если вам нужен другой язык, проверьте раздел языков, чтобы узнать, как установить дополнительные языковые пакеты.
2. Как OCR с Microsoft Office Document Imaging (MODI)
Шаг 1.Установка MODI
- Запустите установщик SharePoint Designer 2007 или MS Office 2007.
- Выберите вариант установки Customize .
- Установите для всех доступных параметров значение Недоступно , затем разверните Инструменты Office и установите для Microsoft Office Document Imaging значение Запускать все с моего компьютера .
- Теперь оставьте установку.
Шаг 2: OCR с MODI
MODI может запускать OCR одним из двух способов:
- Путем OCR для файлов изображений
- Путем подключения к сканеру и автоматического запуска OCR после завершения сканирования документа
i.OCR изображения
Только
MODI распознает изображения в формате TIFF (* .tif, * .tiff) . Если ваше изображение находится в другом формате (например, JPEG, PNG, GIF), вы можете использовать один из многих бесплатных редакторов изображений, доступных в Интернете (XnView, IrfanView и т. Д.), Чтобы преобразовать их в TIFF.
Вы даже можете использовать Paint для преобразования. Просто откройте изображение с помощью Paint, выберите Сохранить как , затем выберите Другие форматы . В диалоговом окне сохранения выберите тип TIFF и сохраните изображение.
Когда у вас есть изображения в этом формате, сделайте следующее:
- Перейдите в меню «Пуск» и внутри Microsoft Office Tools откройте Microsoft Office Document Imaging .
- Внутри MODI щелкните значок Открыть и выберите изображение TIFF в диалоговом окне.
- После загрузки изображения в MODI нажмите кнопку «Распознать текст с помощью OCR ».
- Дайте время для распознавания текста. Когда это будет сделано, нажмите кнопку «Отправить текст в Word ».
- Появится диалоговое окно с вариантами отправки текста. Если в TIFF было несколько страниц, обязательно выберите параметр Все страницы . Если в изображении есть изображения / диаграммы, которые вы также хотите экспортировать, установите флажок Сохранять изображения в выводе . Нажмите кнопку OK .
- Распознанный текст и любые изображения, которые он мог найти, будут экспортированы в файл HTML, открытый любой установленной версией Word.
ii.OCR прямо со сканера
- Подключите сканер и загрузите объект для сканирования.
- Перейдите в меню «Пуск» и в инструментах Microsoft Office откройте Сканирование документов Microsoft Office .
- В окне сканирования нажмите кнопку Сканер и выберите свой сканер.
- В зависимости от характера сканируемого объекта вы можете выбрать для него подходящую цветовую предустановку, которая включает Color, Grayscale или Black and White .
- Щелкните кнопку Сканирование. Ваш объект будет отсканирован, и после этого автоматически запустится распознавание текста.
- Распознанный текст будет открыт в MODI. В завершение нажмите кнопку «Отправить текст в Word» , чтобы передать распознанный текст и любые изображения в Word.
ПРИМЕЧАНИЕ:
В папке для сохранения по умолчанию вы найдете файл HTML, содержащий информацию OCR. Проверьте внутри соответствующей папки HTML любые изображения, такие как диаграммы, которые будет экспортирован MODI.
Поддержка языков для MODI и OneNote
Функция распознавания текста в OneNote и MODI встроена с поддержкой только трех языков: английский , французский и испанский . По умолчанию он будет использовать язык, который использует ваш установленный MS Office.
Вы можете изменить язык, который MODI использует для OCR, выполнив следующие действия:
- Откройте Microsoft Office Document Imaging.
- Перейдите к Инструменты> Параметры…
- Выберите вкладку OCR , а затем выберите раскрывающийся список Язык OCR.
Выбрать ИЛИ Langauge
Для других языков, особенно тех, которые используют совершенно другой алфавит, чем тот, который используется в английском, например греческий, корейский, китайский, японский, арабский, кириллица (славянские языки — русский, болгарский, сербский, украинский) и т. Д., Вам придется установите соответствующий языковой пакет, чтобы он работал с OneNote или MODI.
1. Установка языковых пакетов OCR для OneNote
Чтобы установить языковой пакет для OneNote в OCR, выполните следующие действия:
- Откройте OneNote и перейдите по ссылке: Параметры> Язык .
- Добавьте язык из раскрывающегося меню, затем, когда он появится в поле языков, щелкните ссылку Не установлен в столбце Проверка.
После этого вы перейдете на сайт поддержки Microsoft Office, где сможете загрузить бесплатные языковые пакеты.
Убедитесь, что вы загрузили правильный языковой пакет для той версии MS Office, которую вы используете, то есть пакет 32 или 64-бит вашей версии MS Office.
2.Установка языковых пакетов OCR для MODI
Для MODI процесс немного сложен, но здесь есть отличное руководство по установке языковых пакетов.
Если все это кажется большим трудом, вы можете выбрать использование Tesseract, которое имеет широкую поддержку разных языков. Однако Tesseract использует командную строку, но вы можете найти пару графических интерфейсов (версии с пользовательским интерфейсом) для него в Интернете.
Центр инвалидности учащихся — Советы и хитрости преобразования
Качество преобразования зависит от качества исходного документа.Кроме того, преобразованный файл может включать улучшения для навигации, если исходный файл помечен соответствующим образом. В следующих советах описаны простые способы подготовки файлов перед их преобразованием для получения высококачественного вывода.
PDF-файлы и файлы изображений
PDF-файлы и файлы на основе изображений будут обработаны с использованием оптического распознавания символов (OCR) для создания текстовой версии документа.
- При сканировании документа убедитесь, что на отсканированном изображении нет пятен, темных отметок, выделенного текста или артефактов.Это повлияет на точность процесса распознавания текста.
- Минимизируйте любые эффекты перекоса. Если изображение представлено «под углом», точность процесса распознавания будет ниже, что приведет к более низкому качеству текстовой версии.
- Если вы начинаете с формата на основе изображений и хотите преобразовать в текстовый формат, вы можете добиться лучших результатов, сначала преобразовав в PDF с тегами, а затем скопировав / вставив текст в документ MS Word. Хотя вы можете конвертировать непосредственно из файла изображения в текстовый файл, вы можете найти лучшие результаты для некоторых графических документов, если конвертируете в PDF с тегами, а затем в текстовый файл (см. Раздел «Преобразование в MS Word и текстовые файлы»).
Преобразование в MS Word и текстовые файлы
SDC преобразует документы на основе изображений в файлы MS Word, RTF и текстовые файлы. Для некоторых документов на основе изображений может оказаться полезным сначала преобразовать в PDF с тегами, а затем скопировать и вставить текст из PDF с тегами в MS Word. Это может улучшить качество чтения и удалить ненужный контент.
Версия документа для MS Word позволяет более точно «очистить» содержимое для преобразования в аудиофайл MP3 или для использования со вспомогательными технологиями.Большинство преобразований в MS Word занимают всего несколько секунд и включают использование инструментов «Найти и заменить». Для получения дополнительной информации об использовании инструментов «Найти» и «Заменить» см. Использование «Найти и заменить» в MS Word для удаления специальных символов из документа.
Примечание. В приведенных ниже примерах поиска и замены замените значение одним пробелом и не включайте кавычки.
Файл изображения в PDF с тегами в документ MS Word
- Отправьте документ на основе изображения в SDC и выберите PDF с тегами в качестве параметра вывода.п • «.
- Найдите «-» и замените без значения.
- Сохраните документ в предпочитаемом текстовом формате.
Файл изображения в документ MS Word
Чтобы очистить файл MS Word для использования со вспомогательными технологиями или для создания файлов MP3, выполните «поиск и замену», чтобы удалить дополнительные дефисы и разрывы разделов. Определите специальный символ, который вы хотите найти, в поле «Найти:» и оставьте поле «Заменить на:» пустым. Дополнительную информацию об удалении специальных символов из документа см. В разделе Использование поиска и замены в MS Word.п «.
Создание MS Word, RTF, текстовых файлов
- Используйте стили Word для определения заголовков документа. Например, стиль «Заголовок 1» можно использовать для идентификации заголовка документа, а стиль «Заголовок 2» можно использовать для идентификации информации о главе. Лучше использовать только один «Заголовок 1», чтобы облегчить точное преобразование в другие форматы документов (например, DAISY, ePub, шрифт Брайля и т. Д.)
- Обеспечьте краткое описание изображений, относящихся к содержанию, в документе MS Word.
- Избегайте использования текстовых полей в вашем документе. Если вы хотите настроить макет, используйте инструмент «Столбец» или «Разрыв раздела».
- При преобразовании в DAISY номера страниц будут определяться на основе разбивки на страницы MS Word. Чтобы получить настраиваемую разбивку на страницы, используйте стиль PageNumber из подключаемого модуля «Сохранить как DAISY» для Microsoft Office для настраиваемых номеров страниц.
Создание файлов HTML
- Использовать разметку заголовка HTML (например,g.,
,
и т. д.) для обозначения заголовков в документе. Например, стиль «Заголовок 1» можно использовать для идентификации заголовка документа, а стиль «Заголовок 2» можно использовать для идентификации информации о главе.
- Обеспечьте краткое описание изображений, связанных с содержимым, в документе HTML.
Использование оптического распознавания текста в Microsoft Office
Обработка изображений документов Microsoft Office была функцией, установленной по умолчанию в Windows 2003 и ранее. Он преобразовал текст отсканированного изображения в документ Word.Однако Редмонд удалил его в Office 2010, а в Office 2016 еще не вернул.
Хорошей новостью является то, что вы можете переустановить его самостоятельно, а не покупать OmniPage или другую относительно дорогую коммерческую программу оптического распознавания символов (OCR). Переустановка Microsoft Office Document Imaging относительно безболезненна.
После этого вы можете сканировать текст документа в Word. Вот как.
Откройте Microsoft Office Document Imaging
Нажмите Пуск > Все программы > Microsoft Office .Вы найдете Document Imaging в этой группе приложений.
Запустите сканер
Загрузите документ, который хотите отсканировать, в сканер и включите устройство. В разделе Файл выберите Сканировать новый документ .
Выберите предустановку
Выберите правильную предустановку для сканируемого документа.
Выберите источник бумаги и отсканируйте
Lifewire
По умолчанию программа вытягивает бумагу из автоподатчика документов.Если это не то, откуда вы хотите, нажмите Scanner и снимите этот флажок. Затем нажмите кнопку Сканировать , чтобы начать сканирование.
Отправить текст в Word
После завершения сканирования нажмите Инструменты и выберите Отправить текст в Word . Откроется окно, в котором вы можете выбрать сохранение фотографий в версии Word.
Редактировать документ в Word
Документ откроется в Word. OCR не идеально, и вам, вероятно, придется немного отредактировать, но подумайте обо всех наборах, которые вы сохранили!
Спасибо, что сообщили нам!
Расскажите, почему!
Другой
Недостаточно подробностей
Трудно понять
Image to Word Converter (2021)
Image to Word Converter (2021) — онлайн и 100% бесплатно
На каком языке написан текст? (Для лучших результатов)
Все загруженные файлы навсегда удаляются с наших серверов в течение 1 часа.
Загружая документ, вы соглашаетесь с нашими условиями.
Оригинальный макет и формат сохранятся как по волшебству!
Чтение текста.Это может занять некоторое время …
На основе технологии оптического распознавания символов (OCR)
сообщить об этом объявлении
Как работает этот инструмент
Этот онлайн-инструмент преобразует отсканированные изображения или изображения текстовых документов в редактируемые документы Word с помощью технологии оптического распознавания символов (OCR).Все документы Word преобразуются с сохранением исходного макета документа и столбцов. Чем крупнее и четче отсканированный текст, тем лучше будут результаты. В большинстве случаев мы можем достичь точности более 99% при обнаружении текста на ваших изображениях.
Этот инструмент можно использовать бесплатно, регистрация не требуется.
Использование
Этот инструмент идеально подходит для преобразования неотредактируемых отсканированных документов (таких как отсканированные контракты, счета-фактуры, квитанции или текстовые архивы) обратно в оцифрованный текст, который можно редактировать, искать или индексировать.
Поддерживаемые файлы
Просто перетащите любой файл PNG, JPG или многостраничный PDF-документ, содержащий изображения текста, в форму, и ваш файл будет мгновенно преобразован в документ Word, который вы можете редактировать.
Ограничения
Вы можете использовать этот инструмент без ограничений. Инструмент принимает файлы размером до 10 МБ и отсканированные PDF-файлы объемом до 30 страниц. Если вам нужно разделить PDF-файл на файлы меньшего размера, вы можете сделать это здесь.Нет никаких ограничений на то, как часто вы можете использовать этот инструмент.
Конфиденциальность
Мы серьезно относимся к вашей конфиденциальности; ваши данные в безопасности. Все загруженные файлы навсегда удаляются с наших серверов в течение 1 часа. Если вы хотите узнать больше, ознакомьтесь с нашей политикой конфиденциальности.
Удалите тексты из ваших PDF-документов с помощью онлайн-инструментов AvePDF
Давайте возьмем два PDF-файла: один, созданный с помощью текстового редактора, например, MS Word, и один отсканированный документ.Оба файла имеют расширение .pdf. Однако эти файлы не совпадают. Если вы откроете файл PDF, созданный с помощью вашего текстового процессора, вы можете нажать CTRL + F, ввести слова, которые вы ищете, и программа просмотра PDF выделит результаты документа.
Но попробуйте выбрать или выполнить поиск текста в PDF-файле, созданном с помощью программного обеспечения сканера, когда вы сканировали бумажные документы, это невозможно. Это потому, что отсканированный документ PDF не является текстовым; он основан на изображении. Этот тип PDF-файла называется растром PDF, и вскоре он станет стандартным форматом для хранения, транспортировки и обмена отсканированными документами. .Текст — это независимый элемент в исходных PDF-файлах. Вы можете видеть текстовые символы в PDF, но эти символы не обязательно являются текстовыми элементами PDF. Как отличить?
Как мы только что видели, текст может быть растровым изображением текста или векторным изображением текста. Во всех случаях он выглядит как текст, но компьютер не распознает его как таковой и не может выделить или выполнить поиск.
Текст, созданный текстовым процессором, не является ни растровым, ни векторным изображением, он (адекватно) называется реальным текстом или текстовым элементом PDF.Реальный текст доступен для поиска и выбора. Он выглядит резким даже при масштабировании, в отличие от векторного текста, который выглядит бугристым, и растрового текста, который пикселирован.
Как и в знаменитой картине Магритта, в мире PDF изображение текста — это не то же самое, что сам текст.
Чтобы сделать текст отсканированного документа доступным для поиска, необходимо запустить его с помощью OCR. Этот процесс добавляет слой невидимого текста в PDF, поэтому механизм распознавания текста может распознавать символы и «читать» текст. Этот текст не используется во время печати или просмотра PDF-документа и невидим для пользователя.
Зачем нужно удалять скрытый текст из PDF? Иногда отсканированный текст, который был распознан, плохо отображается в средстве просмотра. В некоторых случаях хитрость заключается в том, чтобы удалить скрытый текст и повторно обработать документ с помощью другого инструмента (например, AvePDF OCR PDF).
Также возможно, что используемый вами механизм OCR нуждается в обновлении, и вы захотите повторно обработать свои документы или переключиться на другой инструмент с более высокой производительностью. И последнее соображение: если вы сохраните в формате PDF / OCR пакет документов, который включает уже распознанные файлы, результат будет тяжелее.
Добавить комментарий