Инструкция по функционалу «Учитывать порядок слов в запросе» сборщика Wordstat
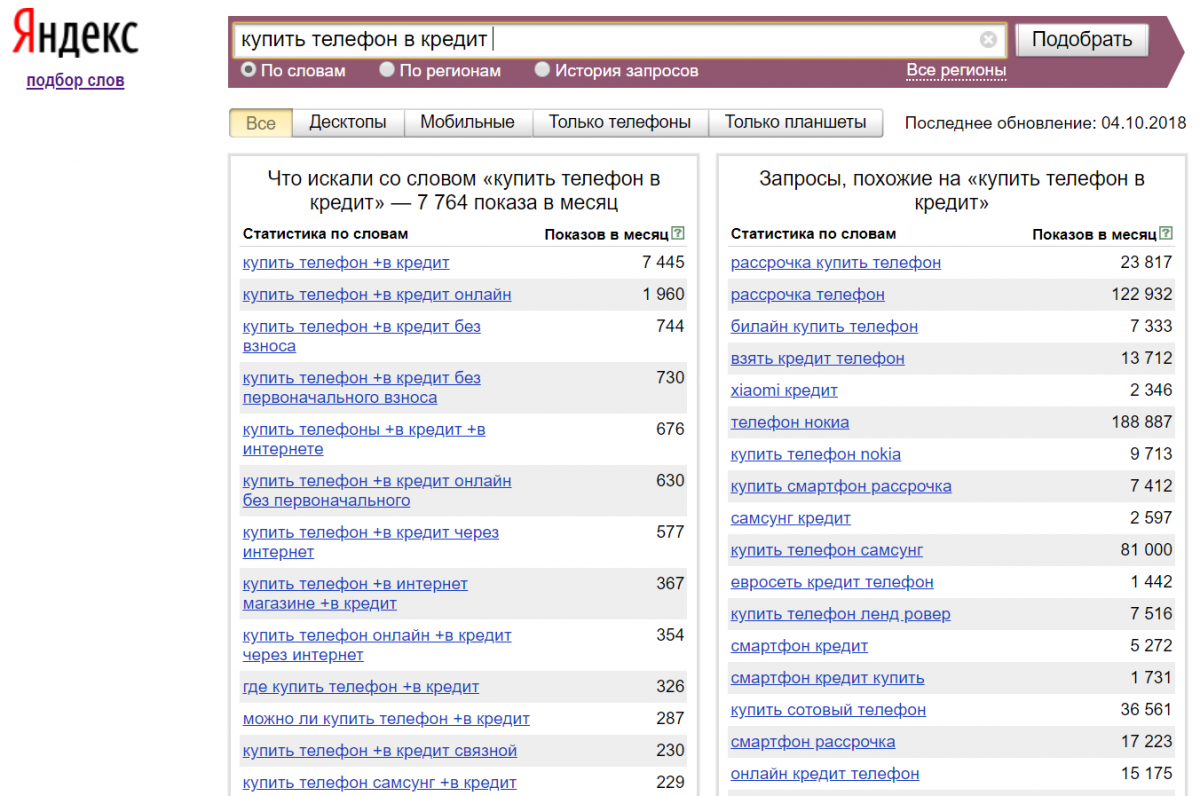
Многие SEO-специалисты знают, что метод сбора частотности из Yandex.Wordstat имеет один существенный недостаток — отсутствие разницы в частотности запросов, имеющих одни и те же слова, но в разном порядке. Например, даже оператор точного соответствия «!» выдаёт одну и ту же частотность по запросам «онлайн фильмы» и «фильмы онлайн»:
Но мы-то знаем, что на самом деле это не так. Есть некое определенное количество людей, которые искали «фильмы онлайн», и есть некое количество людей, которые искали «онлайн фильмы», и эти числа совсем не обязаны быть равными.
Как узнать «истинную» частотность поискового запроса в Яндексе?
До недавнего времени всё было непросто: оптимизаторам приходилось идти на ухищрения, чтобы понять, какой же порядок слов в запросе является более частотным. Тут на помощь приходила и частотность ключевых слов из Google AdWords, и самая частотная словоформа, отдаваемая в левой колонке Yandex. Wordstat, но все эти методы были крайне далеки от идеала.
Wordstat, но все эти методы были крайне далеки от идеала.
Но совсем недавно всё изменилось в лучшую сторону: Yandex.Wordstat начал поддерживать оператор «[]» (квадратные скобки), который ранее существовал только в Яндекс.Директе! Данный оператор, со слов Яндекса «Позволяет зафиксировать порядок слов в поисковом запросе».
Что это означает на практике? Теперь, применяя данный оператор, мы наконец-то можем узнать «истинную» частотность любого запроса в Яндексе!
Как видите, запрос «онлайн фильмы» на самом деле имеет частотность в 10 раз ниже, чем «фильмы онлайн»!
И конечно, данный оператор теперь поддерживается нашим сервисом RUSH ANALYTICS!
Читайте также: Сбор подсказок Яндекса
Как им воспользоваться?
Заходим в наш парсер Wordstat, выбираем что будем собирать — Сбор частотности, и видим там новую опцию «учитывать порядок слов []»:
Читайте также: Как собрать поисковые подсказки Youtube
Если данная опция активна, то все выбранные виды частотности (кроме общей) будут учитывать порядок слов. То есть, если Вы отметили только частотность «ключевое слово» (в кавычках), то будет собрана частотность по запросу «[ключевое слово]» (в кавычках). А если вы отметили 2 вида частотности: «в кавычках» и «с восклицательным знаком», то оба этих вида частотности будут собраны уже с новым оператором. Иными словами, при установленной галочке, стандартные частотности заменяются на аналогичные, но с учетом порядка слов.
То есть, если Вы отметили только частотность «ключевое слово» (в кавычках), то будет собрана частотность по запросу «[ключевое слово]» (в кавычках). А если вы отметили 2 вида частотности: «в кавычках» и «с восклицательным знаком», то оба этих вида частотности будут собраны уже с новым оператором. Иными словами, при установленной галочке, стандартные частотности заменяются на аналогичные, но с учетом порядка слов.
Внимание! «Общая» частотность (широкое соответствие без всех операторов) не поддерживается вместе с новой опцией «Учитывать порядок слов []»! Просьба при работе с новой опцией выбирать только частотности «» и «!».
Читайте также: Google Keyword Planner
Пример
Вы подали на вход запросы «онлайн фильмы» и «фильмы онлайн», отметили 2 вида частотности: «кавычки» и «восклицательный знак», и поставили чекбокс «Учитывать порядок слов []».
Будет собрана ТОЛЬКО такая частотность:
- «[онлайн фильмы]»
- «[фильмы онлайн]»
- «[!онлайн !фильмы]»
- «[!фильмы !онлайн]»
Если же вы хотите собрать ещё и «старую» частотность БЕЗ учета порядка слов в запросе, такую как:
- онлайн фильмы
- «онлайн фильмы»
- «!онлайн !фильмы»
То вам потребуется создать новый проект, и не отмечать галочку «Учитывать порядок слов []».
Попробовать новый функционал в Rush Analytics
Частотность ключевых запросов в Яндекс и Google: методы определения
Эта статья рассчитана на новичков в SEO, а также на владельцев сайтов, которые выбрали себе запросы для продвижения, но не знают, частотные ли это запросы.
Итак, начнём.
Частотность запроса — это количество запросов или фраз, набранных пользователем в поисковой системе в определённый промежуток времени. Способы определения частотности запроса в поисковых системах отличаются. В этой статье мы рассмотрим частотность запросов в самых популярных поисковых системах — в Google и Яндексе.
Из этой статьи мы узнаем следующее:
- Как определять частотность запросов в Яндексе
- Как определять частотность запросов в Google
- Программный сбор частоты запросов
- Онлайн-сбор частоты
1. Как определять частотность запросов в Яндексе
1. 1. Сервис подбора слов в Яндексе
1. Сервис подбора слов в Яндексе
Для определения частоты запросов в Яндексе есть простой и удобный «Сервис подбора слов в Яндексе» или, как его ещё называют, Яндекс Wordstat.
Вбивая запрос в строку подбора, мы получаем следующую картину:
Мы видим, что по запросу [пластиковые окна] было 1 006 660 показов в месяц — это и есть его частота. То, что находится ниже, — это «Статистика по запросу» + «Словосочетания с этим запросом, которые также искали люди». Эти данные необходимы при сборе семантического ядра. Об этом есть статья в нашем блоге «Семантическое ядро: как правильно подобрать ключевые фразы для продвижения сайта».
Примечательно, что сейчас мы видим общую картину по показам в месяц, но можно посмотреть частоту запроса отдельно по виду устройств (планшеты, мобильные телефоны, компьютеры), с которых пользователи искали запрос.
Так, мы видим, что 269 733 показа от общего количества пришлись на телефоны.
1. 2. Виды частотности в Яндексе
2. Виды частотности в Яндексе
Итак, мы узнали, что у запроса [пластиковые окна] было 1 006 660 показов в месяц — это будет базовая частота запроса.
Всего в Яндекс Wordstat выделяют три вида частоты:
- Базовая частота — обозначает число показов по всем запросам с нужным ключевым запросом. В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.
- Фразовая частота — для её определения нужно взять запрос в кавычки. Это позволит нам узнать частоту запроса по интересующей нас фразе.
Как видно по скриншоту, фразовая частота значительно ниже базовой, так как во фразовой частоте могут учитываться словоформы, падежи, разные окончания, но игнорируются добавочные слова (например, запрос [купить пластиковые окна] при сборе фразовой частоты не учитывается).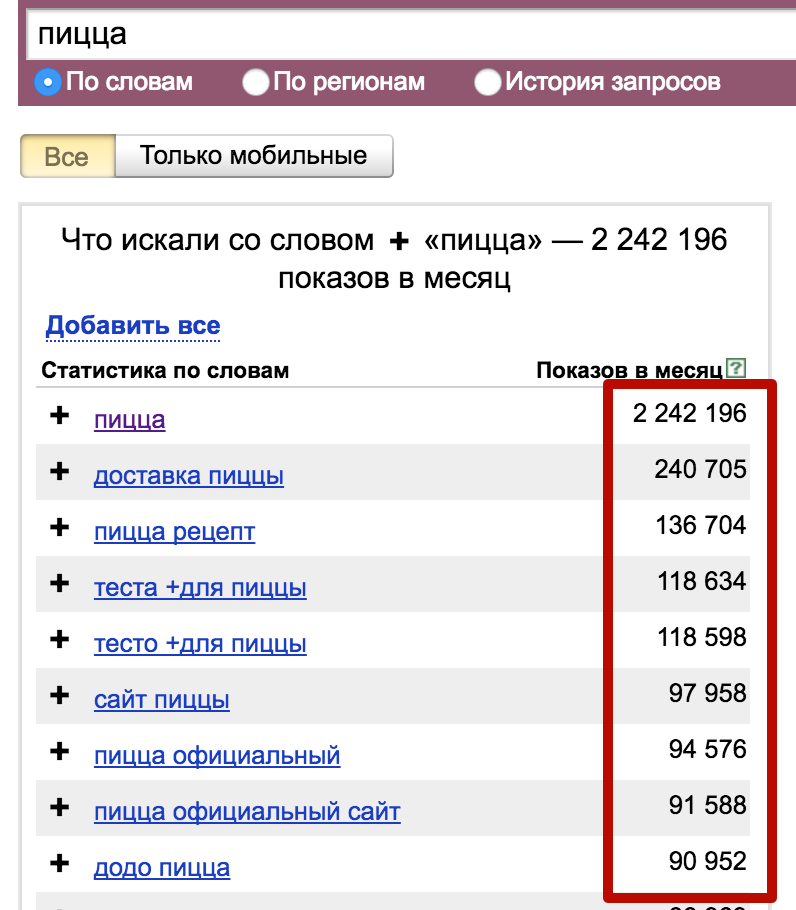
- Точная частота — для её определения нужно взять запрос в кавычки и перед каждым словом в запросе поставить восклицательный знак.
В таком виде мы узнаем количество показов в месяц конкретно по этому запросу.
1.3. Геозависимость
Помимо различной частоты запроса, мы можем узнать частоту по запросам в разных регионах. Для этого нужно вместо пункта «По словам» отметить пункт «По регионам».
На скриншоте видно общее число запросов, а также их количество конкретно по регионам. К примеру, в регионе «Москва» 13 847 показов, региональная популярность составляет 206%.
Что такое региональная популярность? Ответ Яндекса:
«Региональная популярность» — это доля, которую занимает регион в показах по данному слову, делённая на долю всех показов результатов поиска, пришедшихся на этот регион. Популярность слова/словосочетания, равная 100%, означает, что данное слово в данном регионе ничем не выделено. Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Также можно задать регион при сборе частоты. По умолчанию установлен сбор по всем регионам.
Выбираем регион.
Таким образом, при поиске точной частоты запроса по конкретному региону можно узнать, какое количество людей ищут интересующий вас запрос в указанном регионе.
1.4. Как определить сезонность запроса
В Яндекс Wordstat есть ещё одна интересующая нас функция. Для её использования нужно отметить пункт «История запросов».
Таким образом, мы видим, какой была частота запроса по месяцам в разные периоды. С помощью этой информации можно примерно спрогнозировать падения/подъёмы трафика на сайте.
1.5. Плагины для удобства пользования сервисом
Сервис Wordstat полезный, но не очень удобный, поэтому для того чтобы облегчить себе жизнь, при работе с ним я использую плагин Yandex Wordstat Assistant.
Вот так он выглядит в окне Вордстата:
Первое, что бросается в глаза, — это плюсы около запросов. Нажимая на них, мы добавляем запросы в колонку слева:
Это очень удобно, так как обычно нужно выделять каждый запрос и его частоту, чтобы его скопировать. Более того, можно спокойно переключаться на другие запросы, и список запросов, добавленных в колонку, сохранится.
Также этот плагин позволяет сортировать запросы прямо в колонке по частоте или алфавиту, а после — копировать эти запросы с частотой в нужный вам документ. Рекомендую использовать плагин для браузера Chrome, так как там более свежая версия, которая постоянно обновляется. Для FireFox тоже есть плагин, но он не обновлялся с апреля 2015 года, так что не все функции работают корректно.
2. Как определять частотность запросов в Google?
Если с Яндексом всё относительно просто, то узнать частоту запроса в Google будет сложнее. У Google нет сервиса вроде Яндекс Wordstat, поэтому приходится использовать сервис контекстной рекламы Google AdWords. Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Откройте вкладку меню «Инструменты» и в выпавшем меню найдите «Планировщик ключевых слов».
После этого откроется страница планировщика. На этой странице нужно выбрать «Получение статистики запросов и трендов». Там вбейте интересующий вас запрос и укажите регион.
Нажмите на кнопку «Узнать количество запросов». Вы получите такой результат:
Из-за ограничений AdWords у запроса среднее число запросов в месяц колеблется от 1000 до 10 000. Чтобы получить более подробную информацию, нужно создать и запустить кампанию.
При запущенной платной кампании частота запроса будет выглядеть следующим образом:
3. Программный сбор частоты запросов
Выше были описаны способы ручного сбора частоты запросов. При большом количестве запросов собирать их частоту вручную очень неудобно, поэтому я использую специальные программы.
3.1. Программа «Словоёб»
В статье в нашем блоге «Два подхода к подбору семантического ядра» подробно описано, как с помощью «Словоёба» парсить ключевые слова (скачать его можно бесплатно с сайта). Но программа будет полезна и в том случае, если у вас уже есть запросы и вам нужно только собрать частоту.
Обратите внимание: программа парсит данные из Яндекс Wordstat, следовательно, частоту запросов можно узнать только по Яндексу.
Чтобы собрать частоту по определённому списку запросов, нужно сделать следующее:
- Добавить запросы в программу, вызвать контекстное меню в окне программы и выбрать функцию «Добавить фразы»;
- В появившемся окне вставить списком запросы и нажать «Добавить в таблицу»;
- Указать «Регион» и в верхнем меню выбрать вид частоты.
Результат таков:
Как я уже говорил выше, программа парсит Яндекс Wordstat, так что в настройках меню Yandex. Direct нужно будет добавить любой аккаунт Яндекса. Также в настройках можно указать ключ для Антикапчи. Настроек немного, так что разобраться несложно. Программа бесплатная, потому воспользоваться ею может любой желающий.
3.2. Программа Key Collector
Ещё одна программа, которую я хочу упомянуть, — это знаменитый Key Collector. Этой программой я пользуюсь регулярно и рекомендую всем, кто связан с SEO и постоянно работает с запросами.
Чтобы собрать частоту, нужно для начала настроить программу. О настройке программы Key Collector написано в статье «Как составить ТЗ копирайтеру, чтобы статья попала в ТОП без ссылок?».
После настройки программы нужно запустить её и так же, как и в случае со «Словоёбом», добавить запросы, указать «Регион» и нажать на «Сбор статистики Yandex. Direct».
Key Collector, в отличие от «Словоёба», парсит данные, используя Яндекс. Директ, что значительно ускоряет процесс парсинга. Жмём «Получить данные» и получаем результат:
Программа позволяет собирать частоту и для Google, используя Google AdWords. Для этого нужно её настроить. Настройки можно посмотреть на официальном сайте Key Collector. Затем нужно будет нажать на кнопку «Сбор статистики Google. Adwords», которая находится рядом с кнопкой «Сбор статистики Yandex.Direct».
4. Онлайн-сбор частоты запросов
Иногда бывают ситуации, когда любимого инструмента нет под рукой, а частоту собрать нужно. В этом случае можно воспользоваться онлайн-сервисами для сбора частоты. Я рассмотрю 2 сервиса, которые использую сам. Один будет под Яндекс, другой — под Google.
4.1. Онлайн-инструмент для сбора частоты от SeoLib для Яндекса
У сервиса SeoLib есть множество удобных инструментов. Один из таких инструментов — «Подбор ключевых слов».
Всё, что нужно сделать, — это открыть вкладку «Анализ ключевых фраз» и скопировать в форму для запросов или прикрепить отдельным файлом список интересующих запросов. После этого нужно выбрать необходимую частоту и регион, при необходимости указать дополнительные параметры. После нажать на «Начать анализ».
Результат:
Инструмент платный, но цены демократичные. К примеру, список из этих 7 запросов по всем видам частотности обошёлся мне в 5,3 рубля.
4.2. Онлайн-инструмент для сбора частоты от Ahrefs для Google
Сервис Ahrefs популярен тем, что через него удобно анализировать ссылочную массу сайта. В нашем блоге сервису посвящена отдельная статья «Как проанализировать ссылочную массу сайта с помощью Ahrefs».
В сервисе есть инструмент «Анализ ключевых слов».
В форму нужно через запятую добавить ключевые слова и указать регион около кнопки «Пояса».
Результат:
Переходим во вкладку «Метрики»:
Отчёты содержат большое количество полезной информации для анализа. Сервис платный, но есть 2 недели пробного доступа для знакомства с функционалом.
Итоги
Работа с Яндексом:
- Если запросов несколько, можно смотреть их вручную через Яндекс Wordstat. В таком случае я настоятельно рекомендую поставить плагин Yandex Wordstat Assistant — он заметно облегчает процесс;
- Если у вас есть список запросов и вам необходима быстрая разовая проверка, используйте онлайн-инструмент «Подбора ключевых слов» от SeoLib;
- Если вы постоянно работаете с запросами, рекомендую купить Key Collector. «Словоёб» хоть и бесплатный, но парсит слишком медленно, а время, которое вы сэкономите на парсинге запросов в Key Collector, с лихвой отобьёт затраты. «Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.
Работа с Google:
- Если запросов несколько, используйте Google AdWords;
- Если у вас есть список запросов, то удобнее будет воспользоваться онлайн-сервисом Ahrefs или настроить Key Collector.
Я перечислил сервисы, которые сам использую для сбора частоты запросов. Возможно, вы пользуетесь другими сервисами? Тогда укажите их в комментариях, буду рад ознакомиться с ними!
На этом пока всё, желаю вам хороших позиций по частотным запросам!
Подписаться на рассылку
Еще по теме:
Андрей Д.
SEO-аналитик
Всегда знал, что моя работа будет связана с интернетом и компьютером. Начал самостоятельно учить HTML и пробовать себя в верстке. HTML давался легко, но верстать сайты было скучно. Тогда я и узнал о SEO.
С отличием завершил мастер-класс по обучению и управлению персоналом. Сдал письменный тест по английскому языку в Лондонской школе на 98%. Написал более десятка развивающих статей по SEО.
Работаю SEO-специалистом в компании SiteClinic, пишу статьи для блога. В свободное время хожу в походы.
Девиз: Just Do It
Оцените мою статью:
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
Новый! Уникальный способ сбора Яндекс.Вордстат
Команда проекта запустила новый экспертный инструмент: «Получение данных из Яндекс.Вордстат». Логика его работы — достаточно простая, доступно множество настроек, что позволяет собрать большое семантическое ядро для проекта в пару кликов, задав:
-
Регион сбора частот / фраз.
-
Глубину парсинга Wordstat в страницах.
-
Получение точной и общей частоты по запросам.
-
Сбор правой колонки (запросы, похожие на «фраза»).
-
Получение частот на мобильных устройствах.
-
Список стоп-слов (для исключения нецелевых запросов по маске).
-
Удаление НЧ-фраз (если требуется, отсечка — по частоте).
-
Дополнительная обработка: спецсимволы, запросы с нулевой точной или общей частотой, очень длинные/короткие фразы, условные дубли.
Итоговый файл будет сформирован в облаке (никаких КАПЧ (!) и банов по IP) за несколько минут, а скаченный CSV будет содержать и дополнительные колонки, удобные для дальнейшей работы с семантикой:
-
Отношение частот (Точная / Общая).
-
Доля мобильного спроса.
-
Колонка Wordstat: Левая / Правая.
-
Число слов в запросе.
-
Тип фразы (кириллическая, на латинице, с числами, смешанная и т.д.).
Один лимит «Пиксель Тулс» расходуется на парсинг двух страниц с запросами и/или двух точных частот. Истории проверок (парсинга) хранятся в облаке.
Данный инструмент очень хорошо гармонирует с другими источниками семантики:
Удачи в быстром сборе семантического ядра для проектов!
Как использовать инструмент «Детальный анализ запроса» для поисковых фраз и SEO?
Сервис анализа поисковых запросов помогает детально оценить все параметры фразы и поисковой выдачи с целью оценки уровня конкуренции по нему и тех параметров, которые наиболее важны SEO-специалисту при анализе выдачи сайта по запросам.
Какие параметры определяет инструмент?
Функционал инструмента не ограничивается анализом частотности запросов онлайн. Перечень определяемых критериев при анализе ключевых слов довольно объемен:
-
Геозависимость. Бинарный параметр, определяет зависимость результатов выдачи от региона пользователя.
-
Степень локализации. Количественный параметр, отражающий долю результатов в ТОП-50 выдачи с ярко выраженной географической принадлежностью.
-
Слова из подсветки (без СПЕКТРа). Слова, которые подсвечиваются в выдаче поисковой системы, исключая те слова, которые были подсвечены по технологии СПЕКТР.
-
Слова СПЕКТРа. Следует из названия — слова, которые подсвечены благодаря технологии СПЕКТР, например, «отзывы», «самостоятельно» и так далее.
-
Слова, задающие тематику. Слова, которые встречаются чаще других в сниппетах результатов выдачи, исключая запрос и его синонимы. То есть, наш сервис анализа ключевых слов можно использовать таким образом для расширения семантики.
-
Общая и точная частоты по WordStat. Онлайн проверка частотности запросов в Яндекс показывает две частоты по системе статистики Яндекс.Вордстат общую и точную, с учётом указанного пользователем региона. Общая — без операторов, точная — с операторами «кавычки» и «восклицательный знак», например, [«!мебель»].
-
Число главных страниц в ТОП. Параметр определяет число главных страниц в поисковой выдаче, чтобы пользователь мог определить, какой тип документа на сайте является приоритетным для продвижения по интересующему ключу.
-
Наличие витального ответа. Позволяет оценить наличие витального результата, которое чаще всего характерно при поиске бренда или имени сайта. Например, для сайта pixelplus.ru запрос [пиксель плюс] будет являться витальным.
-
Число найденных результатов. Отражает общее число релевантных документов в индексе поисковой системы.
-
Бюджет по MegaIndex. Численное значение, которое отражает уровень конкуренции в Яндексе по фразе. Как правило, чем выше число – тем конкурентней запрос.
-
Число объявлений в Яндекс.Директ. Отражает, какое число игроков на рынке дает контекстную рекламу по данной фразе.
-
Число точных вхождений в Title и сниппеты из ТОП-50. Позволяет оценить корректность фразы. Этот параметр также является одним из косвенных способов проверки конкурентности запросов.
-
Средний возраст документов. Название параметра говорит само за себя. Чем выше средний возраст документов в ТОП, тем, как правило, выше уровень конкуренции по нему. Для молодых сайтов рекомендуется уделять внимание оценке данного показателя при анализе поисковых фраз составлении семантического ядра.
Как видите, наш инструмент намного полезнее обычного сервиса проверки запросов на частотность.
Как пользоваться инструментом?
Интерфейс инструмента для анализа ключевых запросов максимально прост в использовании.
В поле «Запрос» вводится фраза, которую нужно проанализировать. В выпадающем меню выбирается регион, по которому будет проводиться анализ частотности ключевых слов и выдачи по ним. При желании можно сразу получить результат в формате CSV, отметив соответствующий чекбокс. Затем нажимаем кнопку «Проверить».
Результат выводится в течение нескольких секунд и представляет собой таблицу с перечнем параметров и значением. Каждый параметр снабжен всплывающей подсказкой, увидеть которую можно кликнув на символ вопросительного знака. Повторный клик по значку скрывает подсказку.
Пример использования
Как уже сказано выше, наш инструмент не просто сервис для анализа частотности запросов. С его помощью можно решать более сложные и глобальные задачи. Покажем на примере.
Допустим, возникает вопрос:
«Можем ли мы продвинуть сайт, на котором представлены исключительно металлические кованые лестницы, по запросу [лестницы]?»
Ответ — в таблице.
Мы видим, что данный запрос является геозависимым и у него достаточная степень локализации, чтобы считать его коммерческим. При этом в словах, задающих тематику, встречаются «деревянный» и «этаж», а слова «металлический» и «кованый» &mdash наоборот, отсутствуют.
Это значит, что в выдаче по фразе «лестницы» присутствуют сайты, предлагающие межэтажные лестницы из дерева, и именно такие сайты поисковая система считает релевантным ответом на данный запрос. Проверка частоты запросов поисковых слов показывает большую разность точной и общей частоты. Иначе говоря &mdash плохую полноту. То есть, эта фраза слишком общая и многозначная. Показатель «Бюджет по MegaIndex» говорит об очень высокой конкуренции.
Еще одним важным показателем является «Средний возраст документов в ТОП-10». Если речь идет о продвижении нового сайта, а средний возраст документов &mdash более трех лет, продвижение еще более осложняется.
Видео: всё о поисковых запросах и анализе фраз
А как проверить больше запросов?
Проводить массовую проверку частотности запросов и других параметров позволяет специальный API-метод, доступный для пользователей на тарифах «Эксперт» и «Гуру». Провести детальный анализ запросов в поисковых системах позволяют и другие инструменты «Пиксель Тулс»:
Удачи в применении!
Задайте вопрос или оставьте комментарий
Перейти к инструменту «Детальный анализ запроса»
Другие вопросы нашего FAQ
Массовая проверка частотности запросов: 20 сервисов +12 лайфхаков
Занять топовые позиции в поисковой выдаче получится, если seo-специалист предвидит объем трафика на сайт. Для этого нужна информация о частотности запросов.
Искать вручную частотность у нескольких десятков, а то и сотней ключевиков – обесценивать время и свой труд. К решению можно подойти комплексно и проверить частоту запросов массово. В статье расскажу, как это сделать, какие инструменты использовать и поделюсь лайфхаками.
ТОП-20 сервисов
Если уже владеете терминами и знаниями о частотности и знаете, как ей пользоваться в работе, то просто ловите сервисы, в которых Вы сможете массово проверить частотность запросов. Почти во всех есть бесплатный доступ, пробуйте и выбирайте удобный для себя. Первые три – лидеры по нашему субъективному рейтингу.
| Сервис | Стоимость | Бесплатный доступ | Доступные поисковые системы | Глубина сбора позиций | Возможность снимать мобильную выдачу |
| Seranking | от 350 руб/мес | 14 дней | – Яндекс; – Mail; – Google; – Bing; – Yahoo; – Youtube. | до 200 | Есть |
| Serpstat По промокоду (“In_scale” скидка до -25%) | от 6 325 руб/мес | Нет | – Яндекс; – Google. | до 100 | Есть |
| Seoplane | от 225 руб/5 000 проверок | 500 проверок | – Яндекс; – Google. | до 100 | Нет |
| Rush-analytics | от 500 руб/мес | 14 дней | – Яндекс; – Google. | до 100 | Есть |
| Allpositions | 1 монета/проверка позиции сайта | 1 000 монет | – Яндекс; – Mail; – Google; – Rambler. | до 100 | Нет |
| pr-cy | 0,025 руб/проверка | 7 дней | – Яндекс; – Google. | до 100 | Есть |
| Seolib | от 0,05 руб/проверка | Нет | – Яндекс; – Mail; – Google; – Вконтакте. | до 500 | Есть |
| Megaindex | от 1 490 руб/мес | Бесплатный тариф | – Яндекс; – Google. | до 100 | Нет |
| Seobudget | 0,12 руб/проверка | 800 проверок | – Яндекс; – Google. | до 250 | Нет |
| Spyserp | от 490 руб/1 000 проверок | Бесплатный тариф | – Google; – Yandex; – Bing; – Yahoo; – Seznam. | до 100 | Есть |
| Tools.pixelplus | от 950 руб/мес | Нет | – Яндекс; – Google. | до 100 | Есть |
| Siteposition | от 0,35 руб/запрос | Нет | – Яндекс; – Mail; – Google; – Bing; – Yahoo; – Gogo; – Rambler. | до 300 | Нет |
| Serphunt | от 490 руб/мес | 500 позиций | – Яндекс; – Google. | до 100 | Есть |
| Topvisor | от 999 руб/мес | 200 запросов | – Яндекс; – Mail; – Google; – Bing; – Yahoo; – Sputnik; – Seznam. | до 1 000 | Есть |
| Ahrefs | 7 735 руб | Нет | – Google. | до 105 | Есть |
| Rankinity | от 0,78 руб за 2 позиции | Бесплатный тариф | – Google; – Yandex; – Bing. | до 100 | Есть |
| Semrush | от 7 735 руб/мес | Бесплатный тариф | – Google; – Baidu. | до 200 | Есть |
| Wincher | от 916 руб/мес | 14 дней | – Google. | до 100 | Есть |
| Lider-system | 240 руб/140 запросов | 80 запросов | – Яндекс; – Google; – Mail. | до 100 | Есть |
Кстати, все эти сервисы показывают частоту по запросу, так что если Вам эта функция важна, имейте в виду.
Как проверить частотность
Все упомянутые сервисы имеют похожий принцип работы. Чтобы понять его, мы рассмотрим функционал на примере проверенного сервиса – SE ranking.
Шаг 1. Опускаем стандартные моменты про регистрацию и переходим к главному. Для начала нажмите на вкладку “Еще”, далее “Инструменты” и выберите инструмент “Определение частотности”.
Шаг 2. Когда откроется вкладка, выберите базу данных с помощью чего будет определяться частотность: Google Keyword Planner или Яндекс Wordstat.
Помимо этого из выпадающего меню выберите страну для поиска частотности. Введите ключевые слова по одному на строку. Когда все данные введены, нажмите “Начать сбор”. Имейте в виду, что сбор информации может занять некоторое время. Это зависит от количества ключевиков и загруженности системы.
Шаг 3. Результаты поиска появятся в одноименной вкладке. Там можно ознакомиться с историей частотности по последним 100 запросам. Напротив каждой задачи есть значок, который позволит узнать число показов по ключевикам.
лайфхаки по проверке
Чтобы Ваша работа над массовой проверкой частоты запросов проходила эффективнее, собрала список лайфхаков, изучайте и пользуйтесь.
- Затраты. При формировании бюджета учитывайте частотность и конкурентность, нишу и регион продвижения. Цены на seo сильно варьируются по стране. Чем шире ниша продвижения, тем больше потребуется средств. Ведь нужно не только качественно составить семантику, но и обойти конкурентов;
- Пересечение. Следите, чтобы на landing page не пересекались коммерческие и информационные запросы. Совместить их – значит понизить конверсию, увеличить частотность, как правило, такие страницы не оптимизируются. Если цели у запросов противоположные, рациональнее сделать отдельные посадочные страницы и вести трафик на них;
- Геозависимость. В полном объеме укажите данные на странице “Контакты”, добавьте продвигаемый сайт в Яндекс.Вебмастер, в том числе и филиалы компании. Помните, что для каждого региона должна быть создана собственная страница;
- Смысл. Формируйте запросы, отталкиваясь от цели поиска у пользователя и ставьте на первое место смысл его запроса, а не удобное содержание для клиента или поисковика;
- Поиск. Используйте различные сочетания частотности запросов в работе. Готовых схем запросов по конкурентности и частотности не существует. Пробуйте и ищите те, которые дают трафик при минимальных затратах;
- Проверка. Периодически актуализируйте частотность ключевых фраз, лучше раз в полгода. В компаниях постоянно обновляются или убираются категории товаров, добавляются новые позиции, услуги, соответственно, часть семантики требует переброски. Кроме того, при редизайне или существенных внутренних изменениях сайта тоже нужно пересматривать частотность ключевиков;
- Глубина. Она имеет большое значение. Смотреть ключи нужно после 200 позиции, потому что так будет собрано максимум ключевых слов. А значит тщательнее будут оптимизированы тексты, от которых зависят позиции сайта в поисковиках;
- Формирование. Проверяйте все ключи, но отсеивайте их при помощи “стоп-слов”. Сформированный список – это и есть семантическое ядро – основа, которая будет продавать товар или услугу;
- Сезонность. Отслеживайте её, если у ниши имеется привязка ко времени года. Не переживайте из-за высокой амплитуды частотности запросов, но своевременно обновляйте весь список. Такие сезонные всплески можно спрогнозировать, а значить спланировать маркетинговую деятельность;
- Скачки. Проверяйте частотность запросов, если позиции сайта скачут. Скорее всего у высокочастотного запроса изменяется позиция, поэтому он то в топе и видимость высокая, то скатывается и это сразу отражается на падение позиций сайта;
- Информационные запросы. Не списывайте их со счетов. У образовательного контента не важна привязка к геопозиции, и если компания работает по всей стране, то полезная информация будет добавлять узнаваемости и работать на бренд;
- Варианты. Используйте частотность ключевых слов не только в текстах на сайте, а также в title, description, заголовках h2-h6 и анкорных ссылках, грамотно компануя между собой виды частотностей.
коротко о главном
Частотность запросов – основной показатель при составлении семантического ядра, который никак нельзя игнорировать. Определение числа запросов на ключевые фразы поможет сформировать интерес пользователей на товар или услугу и повысить посещаемость сайта.
Чтобы максимально автоматизировать работу по сбору данных, воспользуйтесь массовой проверкой запросов. Сервисов для этого много, но мы рекомендуем эту тройку:
По теме:
Комбинатор ключевых слов: 10 сервисов + алгоритм
ТОП-70 СЕО-инструментов (по категориям) + рейтинг от эксперта
SEO-продвижение лендинга: инструкция + 2 кейса
SEO маркетинг: 3 примера + тест на потенциал
SEO-копирайтинг: как писать + 9 примеров
Автор
Анна Пискун
Понравилось?
Расскажите друзьям:
Нашли ошибку в тексте? Выделите
фрагмент и нажмите ctrl+enter
Подбор ключевых слов с точной статистикой запросов
Анализируйте ключевые слова по основным параметрам
в Google и Yandex
Уровень сложности продвижения
Оцените сложность вывода ключа в ТОП. Рассчитывается исходя из качества доменов, ранжирующихся в ТОП-10: чем сильнее конкуренты в выдаче, тем выше показатель сложности.
Чаcтотность поисковых запросов
Посмотрите сколько раз в месяц пользователи запрашивают ключевое слово в Google или Яндексе. Для Google дополнительно выводится общий тренд сезонности за последний год.
Стоимость клика и уровень конкуренции
Проверьте среднюю стоимость клика в рекламных системах Google Ads или Яндекс.Директ. Для Google дополнительно выводятся цены за клик в других регионах и общий рейтинг конкуренции.
Подбирайте ключевые слова
Соберите семантику для нового проекта
Обновите или расширьте семантическое ядро вашего сайта
Настройте фильтрацию по параметрам
Экспортируйте любые данные
Альтернативные ключевые слова, похожие на выбранное ключевое слово или включающие его
Оцените процент совпадения страниц по ключевым словам в ТОП-100 Google
Релевантные ключи, по которым в ТОП-100 поисковой выдачи ранжируются те же страницы, что и по выбранному ключевому слову
Поисковые подсказки — популярные запросы, появляющиеся под строкой поиска, когда пользователь вводит выбранное ключевое слово
Оцените конкуренцию
Подбирая ключевые слова, вы будете сразу понимать, с кем придется соревноваться в органической и платной выдаче
Пакетный анализ ключевых слов
Ключевых слов много и просмотр всех по отдельности занимает целую вечность? А вот и нет! Вы можете сразу запустить анализ группы запросов и получить комплексный отчет по ним.
Используйте одну из самых больших баз на рынке
12
городов в Яндекс
3 млрд
ключевых слов
Гибкие тарифы для любого бизнеса
КОРПОРАТИВНЫЙ
₽9450/месяц
300 проверок домена/день
∞ сайтов
2,500 ключевых слов
250,000 страниц для аудита
ПЛЮС
₽4450/месяц
100 проверок домена/день
∞ сайтов
1,000 ключевых слов
150,000 страниц для аудита
ОПТИМУМ
₽1950/месяц
20 проверок домена/день
10 сайтов
250 ключевых слов
25,000 страниц для аудита
Посмотреть тарифные планы
Оплата за проверку
От $0,06
За один отчет
Вы можете управлять расходами и платить только за те инструменты, которые используете.
Хороший инструмент для специалиста
Плюсов достаточно много. В одном месте собраны, на мой взгляд, самые нужные и полезные инструменты для seo-специалиста, сервис закрывает большинство задач.
Из инструментов особенно нравятся:
— анализ сайта;
— подбор ключевых слов;
— кластеризатор запросов.
Палочка-выручалочка в маркетинге
SE Ranking особенно помогает мне в анализе конкурентов и в подборе ключевых слов. Работаю с инструментом второй год, за это время выработалось доверие к данным сервиса. Спасибо за работу!
SE Ranking – незаменимый SEO-комбайн для сеошника
SE Ranking — мой первый инструмент для мониторинга позиций сайтов. Этот сервис оказался многогранен, чем меня он и подкупил. Также он позволяет выполнить внутренний SEO аудит, произвести анализ конкурентов и бэклинков, подобрать ключевые слова.
Отличный сервис. Рекомендую
Больше всего мне нравиться, что это все инструменты в одном. Очень нравиться что сканируются сниппеты, сканируются ошибки сайта по каждому заголовку и по каждой странице — это очень удобно. Нравиться аналитика ключевых слов, ежедневно можно наблюдать за скачками позиций и делать прогнозы. Рекомендую, отличный сервис.
С нами уже 400,000+ пользователей
Вы в хорошей компании
Еще больше возможностей SE Ranking
Quickstart — Запросы документации 2.25.0
Хотите начать? Эта страница дает хорошее представление о том, как начать работу
с запросами.
Давайте начнем с нескольких простых примеров.
Отправить запрос
Сделать запрос с помощью запросов очень просто.
Начните с импорта модуля запросов:
А теперь давайте попробуем получить веб-страницу. В этом примере давайте возьмем общедоступный GitHub
график:
>>> r = запросы.получить ('https://api.github.com/events')
Теперь у нас есть объект Response с именем r . Мы можем
получить всю необходимую информацию из этого объекта.
Простой API
Requests означает, что все формы HTTP-запросов столь же очевидны. За
Например, вот как вы делаете запрос HTTP POST:
>>> r = requests.post ('https://httpbin.org/post', data = {'ключ': 'значение'})
Красиво, правда? А как насчет других типов HTTP-запросов: PUT, DELETE, HEAD и
ПАРАМЕТРЫ? Это все так же просто:
>>> r = запросы.put ('https://httpbin.org/put', data = {'ключ': 'значение'})
>>> r = requests.delete ('https://httpbin.org/delete')
>>> r = requests.head ('https://httpbin.org/get')
>>> r = requests.options ('https://httpbin.org/get')
Это все хорошо, но это только начало того, что запросы могут
делать.
Передача параметров в URL-адресах
Вы часто хотите отправить какие-то данные в строке запроса URL. Если
вы создавали URL вручную, эти данные будут представлены как ключ / значение
пары в URL-адресе после вопросительного знака, e.грамм. httpbin.org/get?key=val .
Запросы позволяют вам предоставить эти аргументы в виде словаря строк,
используя аргумент ключевого слова params . Например, если вы хотите пройти
ключ1 = значение1 и ключ2 = значение2 от до httpbin.org/get , вы должны использовать
следующий код:
>>> payload = {'ключ1': 'значение1', 'ключ2': 'значение2'}
>>> r = requests.get ('https://httpbin.org/get', params = полезная нагрузка)
Вы можете увидеть, что URL-адрес был правильно закодирован, напечатав URL-адрес:
>>> печать (г.URL) https://httpbin.org/get?key2=value2&key1=value1
Обратите внимание, что любой ключ словаря со значением None не будет добавлен в
Строка запроса URL.
Вы также можете передать список элементов как значение:
>>> payload = {'ключ1': 'значение1', 'ключ2': ['значение2', 'значение3']}
>>> r = requests.get ('https://httpbin.org/get', params = полезная нагрузка)
>>> печать (r.url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Содержание ответа
Мы можем прочитать содержимое ответа сервера.Рассмотрим график GitHub
снова:
>>> запросы на импорт
>>> r = requests.get ('https://api.github.com/events')
>>> r.text
'[{"репозиторий": {"open_issues": 0, "url": "https: //github.com / ...
Запросы будут автоматически декодировать контент с сервера. Самый юникод
кодировки легко декодируются.
Когда вы делаете запрос, Requests делает обоснованные предположения о кодировке
ответ основан на заголовках HTTP. Кодировка текста, угадываемая запросами
используется при доступе к р.текст . Вы можете узнать, что такое запросы на кодирование
используя, и измените его, используя свойство r.encoding :
>>> r. Кодирование 'utf-8' >>> r.encoding = 'ISO-8859-1'
Если вы измените кодировку, запросы будут использовать новое значение r.encoding
всякий раз, когда вы звоните по номеру r.text . Вы можете сделать это в любой ситуации, когда
вы можете применить специальную логику, чтобы выяснить, что кодирование контента будет
быть. Например, HTML и XML могут указывать свою кодировку в
их тело.В таких ситуациях вам следует использовать r.content , чтобы найти
кодирование, а затем установите r. кодирование . Это позволит вам использовать r.text с
правильная кодировка.
Запросы также будут использовать пользовательские кодировки, если они вам понадобятся. Если
вы создали свою собственную кодировку и зарегистрировали ее с помощью кодеков
модуль, вы можете просто использовать имя кодека как значение r.encoding и
Запросы будут обрабатывать расшифровку за вас.
Содержимое двоичного ответа
Вы также можете получить доступ к телу ответа в байтах, для нетекстовых запросов:
>>> г.содержание
b '[{"репозиторий": {"open_issues": 0, "url": "https: //github.com / ...
gzip и deflate кодирования передачи автоматически декодируются для вас.
Например, чтобы создать изображение из двоичных данных, возвращаемых запросом, вы можете
используйте следующий код:
>>> из PIL import Image >>> из io import BytesIO >>> i = Image.open (BytesIO (r.content))
Содержимое ответа JSON
Также имеется встроенный декодер JSON на случай, если вы имеете дело с данными JSON:
>>> запросы на импорт
>>> r = запросы.получить ('https://api.github.com/events')
>>> r.json ()
[{'репозиторий': {'open_issues': 0, 'url': 'https: //github.com / ...
В случае сбоя декодирования JSON r.json () вызывает исключение. Например, если
ответ получает 204 (нет содержимого), или, если ответ содержит недопустимый JSON,
попытка r.json () вызывает ValueError: объект JSON не может быть декодирован .
Следует отметить, что успешный вызов r.json () делает не
указывают на успех ответа.Некоторые серверы могут возвращать объект JSON в
неудачный ответ (например, сведения об ошибке с HTTP 500). Такой JSON будет декодирован
и вернулся. Чтобы проверить успешность запроса, используйте
r.raise_for_status () или проверьте r.status_code — это то, что вы ожидаете.
Frontiers | Понимание онлайн-поведения: изучение вероятности онлайн-личностных качеств с использованием подхода машинного обучения с учителем
Введение
Взаимодействие человека с компьютером (HCI) — это сложная дисциплина, объединяющая различные исследовательские дисциплины.Исследования HCI включают изучение более широких социальных последствий и взаимодействий, основанных на использовании компьютерных систем (Hooper and Dix, 2013). Интеграция психологических исследований человека в исследования HCI для понимания динамики человека в Интернете привлекла минимальное внимание (Hooper and Dix, 2013), при этом одним из основных аспектов является поведенческая идентичность в Интернете. Исследование поведенческой идентичности человека в Интернете объединяет HCI и веб-науку, так что традиционные механизмы идентификации (например, идентификаторы сетевого домена, токены безопасности и аутентификации) дополняются для обеспечения более надежной идентификации и создания профиля.Первоначальные поисковые исследования в Интернете выявили поведенческие тенденции, такие как тенденции компенсации одиночества (Amichai-Hamburger et al., 2002, 2004; Ross et al., 2009), разлука с семьей и депрессия (Amichai-Hamburger, 2002), ведение блогов и т. Д. модели использования средств массовой информации (Guadagno et al., 2008; Schrammel et al., 2009; de Oliveira et al., 2011; Quercia, Kosinski, 2011; Moore, McElroy, 2012) и даже склонности к привыканию (Samarein et al., 2013). Существование этих тенденций можно объяснить самой природой Интернета, который обеспечивает подходящую платформу для интеграции домашней, профессиональной и семейной жизни и социальных желаний, а также для проявления врожденных желаний.Такая платформа представляет собой парадоксального агента, способного раскрыть личность онлайн-пользователей. Другими словами, Интернет представляет собой интегрированную платформу для идентификации и упрощения сложной человеческой идентичности.
Идентификация — важный фактор в веб-науке и использовании компьютеров, которая концептуализируется в идентификации домена (Joiner et al., 2007), включая физиологическую биометрию, социальную идентичность, техническую идентичность и поведенческую биометрию. Черты личности человека представляют собой наиболее распространенную поведенческую биометрию, принятую для процесса идентификации пользователей Интернета (Amiel and Sargent, 2004; Guadagno et al., 2008; Correa et al., 2010). Черты личности — это переменные, которые координируют человеческие действия и опыт посредством динамической психологической организации, и они составляют главный дискриминант для определения поведенческих паттернов в сети (Amichai-Hamburger, 2002). Теория черт характеризуется двумя фундаментальными принципами: количественная оценка и кросс-ситуационная согласованность. Было обнаружено, что черты личности, измеренные с помощью пятифакторной модели (FFM) или моделей Большой тройки (Matthews et al., 2003), удовлетворительно соответствуют этим принципам.Кроме того, было замечено, что они адекватно отражают человеческое взаимодействие в Интернете.
Исследовательские вопросы, касающиеся частоты использования онлайн-СМИ, демографического состава онлайн-пользователей, взаимосвязи между индивидуальными различиями и использованием онлайн-медиа и мотивами для онлайн-взаимодействия, а также вероятной взаимосвязи между интернет-пользователями и их вероятными предпочтениями, были рассмотрены (Joiner et al., 2007; Guadagno et al., 2008; Correa et al., 2010; Davis, Yi, 2012; Moore, McElroy, 2012).Эти исследования оценили влияние различных личностных качеств на использование Интернета, основываясь на предположении, что Интернет не может заменить человеческое общение и развлечения. Хотя такое предположение верно в более широком аспекте, один ключевой компонент для понимания Интернета и человеческого взаимодействия — поведенческий образец онлайн среди людей, которые разделяют схожие личности, — в значительной степени игнорируется. Утверждалось, что Интернет прямо или косвенно связан с индивидуальными чертами личности (Amichai-Hamburger et al., 2002; Амиэль и Сарджент, 2004 г .; Ross et al., 2009) и в основном находится под контролем отдельного человека и является модерационной платформой для выражения анонимной идентичности (Young and Rodgers, 1998; Tan and Yang, 2012; Samarein et al., 2013), а также явный предиктор использования киберпространства (Guadagno et al., 2008; Golbeck et al., 2011; Davis and Yi, 2012). Однако вопрос о существовании сигнатур личностных черт в Интернете остается без ответа.
In de Oliveira et al.(2011) была исследована вероятность того, что личностные особенности пользователей мобильных телефонов могут быть выведены на основе среднего балла черты и характера звонков. Аналогичным образом, в работе Мюррея и Даррелла (2000) была исследована вероятность того, что демографические атрибуты онлайн-пользователей могут быть выведены. В Ross et al. (2009) было высказано предположение, что исследования, нацеленные на сайты социальных сетей, такие как Facebook, Twitter и LinkedIn, направлены на изучение представления личности в Интернете.Подтверждение наличия личностной сигнатуры в Интернете включает наблюдение дихотомизации личностных факторов (Ross et al., 2009; Amichai-Hamburger and Vinitzky, 2010; Moore and McElroy, 2012) для определения отличительных характеристик среди различных людей в континууме черт. . В этом исследовании делается попытка ответить на основной вопрос, лежащий в основе: «Могут ли личностные черты человека быть выведены из его / ее сетевого трафика?» Этот вопрос согласуется с логикой, согласно которой повторяющиеся повседневные поведенческие модели человека являются предметом врожденной личностной черты, которая регулирует синергию между поведением в сети и вне ее.Однако для надежного ответа на этот вопрос требуется сетевой источник данных, не зависящий от платформы или приложения. Существующие исследования в литературе ограничиваются интересующей платформой, такой как электронная почта, блоги или Facebook, что вызывает поведение, характерное для ее функций и применения. Различные утверждения о чертах личности, основанные на зависящих от платформы интернет-источниках, представлены в таблице 1.
Таблица 1. Резюме утверждений о личностных качествах .
Особенности личности и Интернет
Использование черты личности FFM в исследованиях веб-науки, которые заключаются в открытости новому опыту, добросовестности, экстраверсии, покладистости и невротизму, позволяет использовать общий словарь и метрики для исследования и понимания индивидуальной динамики. Исследование, представленное Golbeck et al. (2011) показали, что люди раскрывают свои черты личности в онлайн-общении посредством самоописания и онлайн-статистических обновлений на сайтах социальных сетей, с помощью которых FFM может обеспечить всестороннюю оценку отношений между человеком и компьютером.Исследование показало, что личностные качества пользователей можно оценить (в социальных сетях) с точностью ± 11% для каждого фактора на основе среднеквадратичной ошибки наблюдаемой онлайн-статистики. Это означает, что предсказание черт личности может быть достигнуто в пределах 1/10 его фактического значения. В Guadagno et al. (2008), аналогичный вывод, основанный на поведении блогов, наблюдался. В исследовании изучалась корреляция между ведением блогов и открытостью новому опыту, а также невротизмом. Аналогичным образом, в исследовании, опубликованном в Lim et al.(2006) показали, что временная изменчивость задержки и ответа на электронную почту может быть использована для вывода личностных черт человека. В Salleh et al. (2010a, b, 2014), было замечено, что личностные черты человека могут быть выведены из его / ее склонности к парному программированию.
Растущая тенденция к использованию индивидуальных черт личности в онлайн-исследованиях указывает на то, что личностные черты представляют собой онлайн-биометрический метод для понимания и идентификации онлайн-пользователей (Delgado-Gómez et al., 2010). Эта парадигма широко применяется для понимания личности человека и социальных сетей в Интернете. Социальные сети в этом контексте относятся к онлайн-платформам, на которых индивидуальное потребление цифровых медиа направлено на взаимодействие и / или расширение социального влияния через онлайн-медиа, независимо от намерения. Исследования взаимосвязи между личностью человека и потреблением средств массовой информации выявили корреляцию и регрессию, как показано в таблице 1. В Correa et al.(2013) утверждалось, что синтез индивидуального психологического склада дает возможность раскрыть использование Интернета. Это утверждение получило дальнейшее подтверждение в Amichai-Hamburger (2005), где утверждалось, что использование Интернета зависит от личностных качеств человека. Исследование показало, что влияние личностных качеств можно наблюдать по продолжительности периода просмотра человеком в Интернете и его склонности к использованию Интернета. Продолжительность периода просмотра веб-страниц отражает индивидуальный выбор, предпочтения и рефлексы в киберпространстве, которые в значительной степени контролируются его / ее уникальными и стабильными психологическими характеристиками (Correa et al., 2013). Следовательно, продолжительность просмотра может отражать тенденцию к одиночеству, поскольку крайне невротичные люди и интроверты, как правило, проводят больше времени в Интернете, чтобы компенсировать вероятное отсутствие физического взаимодействия, и в то же время он проецирует интерес «настоящего себя». ”Исследование интерактивного взаимодействия (Amichai-Hamburger, 2005; Schrammel et al., 2009). Тенденция к использованию Интернета определяется в контексте теории «богатые становятся богатыми» и «бедные становятся богатыми» (Amichai-Hamburger, 2002).Например, в Amichai-Hamburger and Vinitzky (2010) было замечено, что люди с высокими баллами по шкале экстраверсии склонны использовать социальные сети, чтобы расширить границы своих друзей и влияния, в то время как люди с высокими баллами по шкале невротизма, как правило, используют анонимные сети. СМИ для личного самовыражения. В Hamburger and Ben-Artzi (2000) было также высказано предположение, что Интернет можно описать как сложную платформу, которая представляет собой разнообразный парадоксальный лексикон. Исследование, однако, показало, что использование Интернета само по себе не объясняет причин индивидуального использования (несходства).Как показано в Таблице 1, по-видимому, существует общий консенсус в отношении положительной взаимосвязи между невротизмом и использованием Интернета, в частности, по анонимному каналу.
И наоборот, кажется, что были сделаны противоположные утверждения о связи между факторами личностных черт и использованием Интернет-услуг. Например, в исследовании, опубликованном Ross et al. (2009), который был основан на инструменте измерения самоотчета, было замечено, что добросовестность не является предиктором социальных сетей.Однако в исследовании, опубликованном в Amichai-Hamburger and Vinitzky (2010) и Moore and McElroy (2012), было замечено, что добросовестность является предиктором социальных сетей в Интернете. Важно отметить, что в работах Мура и МакЭлроя (2012) и Амичай-Гамбургер и Виницки (2010) в качестве инструмента измерения был принят профиль человека, в то время как Росс и др. (2009), был использован инструмент самоотчета. Интуитивно понятно, что степень наблюдаемой корреляции зависит от надежности измерительного прибора.Особенности, наблюдаемые в измерительном приборе, формируют основу для эффективного утверждения, основанного на пространственно-временных свойствах данных. В таблице 2 представлен синопсис атрибутов, рассмотренных в исследованиях в литературе о личности и Интернете. Однако функции, рассматриваемые в этих исследованиях, зависели от платформы или приложения. Наблюдение, представленное Schrammel et al. (2009) и Мур и МакЭлрой (2012) подтверждают важность надежности измерительного прибора, ориентированного на данные.Для изучения онлайн-моделей требуются пространственно-временные особенности, которые не зависят от платформы или приложения. В исследованиях по идентификации пользователей в Интернете (Herder, 2005; Padmanabhan and Yang, 2007; Kumar and Tomkins, 2010; Yang and Padmanabhan, 2010; Abramson, 2012; Herrmann et al., 2012; Abramson and Aha, 2013; Abramson and Gore, 2013), были приняты такие независимые от платформы функции, которые включают, помимо прочего, характеристики посещения веб-страницы, характеристики веб-запроса, характеристики веб-сеанса и характеристики веб-жанра.
Таблица 2. Сводка характеристик, использованных в исследованиях личностных качеств .
Интеграция этих приложений и независимых от платформы функций приводит к созданию надежного механизма для изучения поведения людей в Интернете. В этом исследовании наблюдалась вероятность существования цифровых черт личности на основе платформенно-независимых функций. Таким образом, он отличается от существующих исследований следующим образом.
• Рассматриваемые функции основаны исключительно на действиях человека и не зависят от платформы.Семантические структуры наблюдаемых признаков адаптированы для классификации паттернов.
• Сигнатура черт личности рассматривается на основе классификации дихотомии черт, в отличие от корреляции и регрессии среднего балла черты. Дихотомия определяется в этом контексте как обозначение категоризации непрерывной переменной, как это предусмотрено в работе Орен и Гасем-Агаи (2003).
• Измерение повторяемости и валидации экспериментов основано на стандартной перспективе измерения в дополнение к общему методу дихотомизации признаков (Oren and Ghasem-Aghaee, 2003).Это отличается от правила большого пальца n-сигма и метода равных третей, примененных Россом и др. (2009), Amichai-Hamburger и Vinitzky (2010) и Moore and McElroy (2012) или дихотомия 40:30:30, примененная в Salleh et al. (2010а, б, 2014). Интуиция, стоящая за общей дихотомией, основана на ограничениях, присущих дихотомии, ориентированной на данные. Дихотомия, ориентированная на данные, дает различные границы для каждого набора данных, как показано в дихотомии, наблюдаемой Россом и др. (2009) и Amichai-Hamburger и Vinitzky (2010).
В соответствии с этими наблюдаемыми различиями текущее исследование сосредоточено на ответе на вопрос: учитывая дихотомический континуум личностных черт, проявляют ли индивиды в дихотомии последовательную сигнатуру, отличную от индивидов в другой дихотомии? Чтобы ответить на этот исследовательский вопрос, были рассмотрены два ключевых предположения:
1. FFM инструмента самоотчета личностных черт достаточно для описания человека в континууме личностных черт.
2.Инструмент самоотчета отдельного человека не зависит от других людей.
Эти допущения обеспечивают особый состав индивидуума, для которого может быть проведена дихотомизация и последующий процесс классификации, как подробно описано в последующих разделах.
Метод
Чтобы изучить вероятность того, что различие черт личности, основанное на онлайн-взаимодействии, существует, были приняты данные о сети на стороне сервера (из фундаментального строительного блока Интернета, коммуникации клиент-сервер).Дополнительно использовался инструмент измерения черт личности FFM. Данные серверной сети собирались с действующих серверов в Центре управления исследованиями (RMC) в Universiti Teknologi, Малайзия, в течение 8 месяцев. Включение сетевых данных в это исследование было обусловлено двумя критериями.
• Наблюдаемый клиент (в данном случае компьютер) используется только одним человеком на протяжении всего периода сбора данных.
• Каждый клиент часто обменивался данными с сервером во время сбора данных.
Сервер RMC — это сервер информационной системы исследований и разработок, на котором проводятся исследования и повседневная деятельность академического и неакадемического персонала университета. Сетевые данные, собранные с сервера, представлены в виде журналов активности каждого выбранного пользователя, как описано в следующем подразделе.
Образец и процедура
Данные сервера были захвачены на сервере RMC с помощью сценария дампа URL-запроса, который записывает активность каждого клиента в организации.Чтобы привлечь пользователей к этому исследованию, предложение по исследованию было первоначально отправлено директору исследовательского центра, где комитет по этике рекомендовал его одобрить. Кроме того, формы согласия были розданы сотрудникам RMC. В этом исследовании вызвались добровольцами 64 сотрудника. Ежедневный мониторинг физического присутствия этих 64 сотрудников проводился для соответствия критериям сбора сетевых данных. Оценка личностных качеств, состоящая из 50 пунктов, была проведена 64 респондентам.Однако только 43 респондента соответствовали критериям сбора сетевых данных. Таким образом, в этом экспериментальном исследовании приняли участие 43 респондента, что составляет 67% добровольцев. Исследовательский анализ 43 ответов дал альфа-надежность Кронбаха, представленную в сравнительном анализе в таблице 3.
Таблица 3. Описательный анализ объектов измерения .
Альфа достоверности Кронбаха качественной добросовестности личности (0.734) оказалось ближе к эталонному значению IPIP (0,790). Кроме того, личностная черта сознательности чаще встречается у респондентов, что отражается в значении ее среднего значения и стандартного отклонения (2,61 ± 1,02). Таким образом, при анализе сетевых данных в данном исследовании респонденты рассматривались на основе их добросовестности (как выделено жирным шрифтом в таблице 3). Добросовестность — это непрерывное измерение личностной черты, которое описывает индивидуальную склонность к демонстрации тщательного и внимательного мыслительного процесса, эффективный и организованный метод решения задачи и систематические поведенческие тенденции.Выбор добросовестности черты личности в первую очередь ограничивается надежностью измеряемого инструмента, что отражено в альфе Кронбаха. По совпадению, выбор добросовестной черты личности также станет лучшей альтернативой корреляционным исследованиям, проведенным Россом и соавт. (2009) и Amichai-Hamburger и Vinitzky (2010) и Мур и МакЭлрой (2012). Сетевой трафик каждого респондента по качеству личности «Сознательность» собирался с 26 апреля 2014 г. по 31 декабря 2014 г.
Сетевая функция
Была разработана эвристическая методология для очистки необработанного файла журнала запрошенного URL-адреса и для извлечения соответствующих ориентированных на человека функций. Эвристика рассматривает веб-запросы, которые возникают в результате действий человека, в отличие от запросов, инициированных системой или сетевым объектом от имени человека. Эвристика применялась к индивидуальным запросам, и следующие ориентированные на человека особенности были извлечены на основе 30-минутной границы сеанса, которая является общепринятой продолжительностью сеанса (Kumar and Tomkins, 2010; Yang and Padmanabhan, 2010).Сетевые особенности, рассматриваемые в этом исследовании, основаны на характеристиках, ориентированных на человека, определенных в Adeyemi et al. (2014). Характеристики, которые представляют поведенческие характеристики, являются неотъемлемой частью повседневной жизни человека. Такое поведение коллективно применялось в исследованиях на людях (Adeyemi et al., 2014). Эти особенности разъясняются в следующих подразделах.
Характеристики веб-запроса
Индивидуальный шаблон веб-запроса отслеживался с помощью характеристик запросов, извлеченных из каждого сеанса.Время между запросами (также называемое интервалом) — это разница во времени между двумя последовательными запросами в рамках сеанса. Статистические свойства характеристик веб-запросов, определенные в Adeyemi et al. (2014), которые включают среднее значение, SD, дисперсию, эксцесс и асимметрию отдельных веб-запросов, были извлечены из каждого сеанса. Эти стандартные характеристики учитывались в отношении интервала и времени полета. Всего из характеристик веб-запроса было извлечено 10 ориентированных на человека функций.
Схема посещения
Университетский центр использует двухсерверную архитектуру связи клиент-сервер с балансировкой нагрузки. Это означает, что возможное количество возможных веб-страниц ограничено общим количеством веб-страниц на двух серверах, представленным числом
.
URLTotal = ∑i = 1s [∫j = 1NURLj] (1)
s = общее количество серверов и N = количество уникальных URL-адресов на каждом сервере.
В этом исследовании предполагалось, что отдельные шаблоны веб-запросов подчиняются степенному закону распределения, как утверждается в Barabasi (2005) и Zhou et al.(2008) на основе эмпирических экспериментов. Характеристики посещений, рассматриваемые в этом исследовании, включают агрегирование посещений в рамках сеанса, частоту повторных посещений за сеанс и продолжительность сеанса относительно агрегирования посещений, представленных в уравнениях 2–4, соответственно.
Vagg = ∑i = 1n (URL за сеанс) i∑jN (URL под наблюдением) j (2)
Rvs = ∑i = 1n (URL на сеанс) iSd, Sd⇒ Продолжительность сеанса = ∫j = 1ntj dt, ≤ 30 мин (3)
Sagg = ∑jN (наблюдаемый URL) jSd (4)
Логика скорости посещения соответствует формуле.1, исходя из того, что вероятные URL-адреса, которые может посетить человек, ограничены наблюдаемыми URL-адресами на сервере. Кроме того, это предполагает, что модель вероятных запросов, ориентированная на интересы, и модель очереди с приоритетами (Zhou et al., 2008) охватываются ограниченным распределением URL-адресов, так что все наблюдаемые пользователи имеют одинаковые условия работы и основное наблюдаемое различие можно выявить, наблюдая за составом поведения человека. Три характеристики были получены из модели посещения.Кроме того, были также получены продолжительность сеанса и общее количество запросов за сеанс. Всего из сетевого трафика было извлечено 15 функций, как показано в Таблице 4.
Таблица 4. Сводка функций, используемых в процессе классификации .
Продолжительность сбора данных на стороне сервера была разделена на этап наблюдения (обучения) шаблона и этап проверки шаблона. Для этапов обучения и проверки модели были приняты соответственно 21 и 15 недель.Чтобы исследовать различие между наблюдаемыми дихотомиями, были исследованы шесть контролируемых алгоритмов машинного обучения. Выбор шести классификаторов был основан на первоначальном исследовании применимых классификаторов с использованием извлеченных признаков. Первоначально были исследованы двадцать два контролируемых классификатора. Сюда входят базовый классификатор, дерево BF, пень решения, дерево Хёффдинга, J48, дерево логистической модели (LMT), дерево NB, случайный лес, случайное дерево, Наивный Байес, Сеть Байеса, Простая логистика, Скрытая модель Маркова, SMO, SVM, многослойность персептрон, таблица решений, JRip, дерево частичных решений (PART), k-NN, таблица решений Naïve Bayes (DTNB) и модель логистической регрессии.Шесть классификаторов работали значительно лучше, чем базовый классификатор. Шесть классификаторов включали модель логистической регрессии, LMT, дерево решений J48, дерево решений с сокращенным сокращением ошибок (REPTree), DTNB и PART. Обсуждение этих алгоритмов классификации можно найти в Kotsiantis et al. (2007), Othman et al. (2007) и Нгуен и Армитаж (2008).
Процесс, принятый в этом исследовании для изучения классификации, аналогичен процессу, определенному в Kotsiantis et al. (2007), как показано на рисунке 1.Тем не менее, процесс исследования, примененный в этом исследовании, включал метод исчерпывающего поиска для нахождения применимого классификатора. Это включает поиск всех применимых классификаторов, способных установить различительную границу между классами в наборе данных на основе информативной структуры пространства признаков. Процесс начинается с размещения и сортировки данных для достижения единообразия. Результат этого процесса затем вводится в секцию предварительной обработки. Предварительная обработка включает в себя очистку данных, извлечение последовательности запроса и создание сеанса запроса на основе принятого порога сеанса.Следующий этап включает разбиение набора данных на обучающую и тестовую выборки. Затем следует процесс исследования классификатора. Этот процесс включает в себя выбор алгоритма классификации, разделение набора данных на обучение и тестирование, а затем сравнение точности алгоритма с базовой точностью. Базовый план по умолчанию для процесса разведки основан на вероятности самого высокого класса, который может быть измерен с помощью алгоритма ZeroR из набора инструментов WEKA ® . Классификатор считается применимым, если достигнутая точность значительно лучше базовой точности.Некоторые классификаторы, такие как модель логистической регрессии, требуют оптимизации параметров посредством настройки параметров. Для такого классификатора выполняется настройка, чтобы проверить применимость классификатора к пространству признаков. Затем принимается классификатор, соответствующий этим критериям. Однако классификатор считается неприменимым, если он не способен установить различительную границу между классами в наборе данных, представленном в пространстве признаков, как показано на рисунке 1.
Рисунок 1.Порядок исследования классификатора .
Программное обеспечение
WEKA было адаптировано для процесса исследования классификатора в этом исследовании. Это связано с тем, что это программное обеспечение с открытым исходным кодом на основе Java, получившее широкое распространение для классификации шаблонов и процессов машинного обучения из-за его устойчивости к размеру функций, простоты интеграции (Othman et al., 2007) и автоматизации внутри сценария ( Ян, 2010). Экспериментальный процесс был основан на точности, полученной с помощью 10-кратной перекрестной проверки и 10-итерационного процесса для предотвращения переобучения.Настройки по умолчанию в наборе инструментов WEKA были приняты для всех параметров в выбранных классификаторах.
Для оценки производительности каждого классификатора были рассмотрены семь показателей оценки: точность, статистика Каппа, среднеквадратичная ошибка (RMSE), точность, отзыв, F-мера и площадь под кривой рабочих характеристик приемника (AUC). Точность каждого классификатора описывается степенью разницы между правильно классифицированным [истинно-положительным (TP) и истинно-отрицательным] экземпляром и фактическим экземпляром.RMSE измеряет увеличенную разницу между правильно классифицированными экземплярами и реальными экземплярами. RMSE (диапазон от 0 до 1) смещается в сторону больших ошибок, что делает его пригодным для оценки эффективности прогнозирования. Precision (0 → 1) вычисляет коэффициент правильности для классифицированных экземпляров. Он описывает последовательность классификатора. Отзыв (0 → 1) оценивает производительность на основе вероятности правильно классифицированного экземпляра. AUC (0 → 1) — это кумулятивная функция распределения (CDF) TP для CDF ложноположительных результатов (FP).F-мера (0 → 1) измеряет средний уровень точности и отзывчивости классификатора. Он уравновешивает компромисс между точностью и отзывчивостью. Статистика Каппа (коэффициент Каппа Коэна), однако, измеряет точность относительно значения p ; таким образом, каппа-статистика измеряет совпадение результатов работы классификатора и процесса генерации метки. Он компенсирует случайную точность в явлении нескольких классов. Его значения варьируются от -1 (полное несогласие) до 0 (случайное согласие) до 1 (полное согласие), что означает, что вычисленная точность зависит от эффективности и действенности классификатора для данного наблюдения.
Дихотомия объекта измерения
Чтобы определить принадлежность к классу на основе оценки области FFM каждого респондента, была принята дихотомия, показанная на рисунке 2. Дихотомия высокого, среднего и низкого классов была получена для 21, 12 и 10 респондентов соответственно. Статистический тест t выявил статистически значимую разницу между средним значением наблюдаемых дихотомий, что предполагает высокую межклассовую границу и низкую внутриклассовую границу. Чтобы предотвратить избыточность данных и повысить вычислительную эффективность, только люди, показавшие уникальные шаблоны запросов, рассматривались для включения в процесс наблюдения шаблонов.Наблюдался уникальный шаблон запроса, основанный на дискретизации и символьном преобразовании отдельных шаблонов между запросами. Было замечено, что общий экземпляр сеанса и размер респондентов для каждой дихотомии были уменьшены на 27,3, 8,33 и 5% для низкого, среднего и высокого классов соответственно для набора обучающих данных.
Рис. 2. Адаптированный порог для дихотомии оценки признаков / формирования класса .
Результаты
Чтобы изучить вероятность того, что цифровая личность существует в Интернете, черта сознательности была дихотомизирована, чтобы сформировать кластеры низкого, среднего и высокого классов, как показано на рисунке 2, на основе утверждения Орен и Гасем-Агаи (2003). ), которые выявили дихотомию пяти классов в континууме личностных черт.Принятый порог не зависит от распределения данных. Это сделано для предотвращения дихотомии, ориентированной на данные, в то время как только три дихотомии были извлечены из распределения оценок признаков. Шесть классификационных схем машинного обучения были применены к извлеченным признакам, чтобы наблюдать структурные отношения, способные выявить несходный паттерн взаимной дихотомии. Схемы включали дерево решений J48, модель логистической регрессии, LMT, DTNB, REPTree и PART. Деревья решений (DT) способны представлять высокоуровневые абстрактные отношения между наблюдаемыми переменными и упрощают вычисление.Первоначальные наблюдения показали, что наблюдаемые схемы демонстрируют более высокую точность классификации, чем другие типы схем классификации.
Наблюдение за подписью на основе данных обучения
Чтобы изучить вероятность различения людей на основе дихотомии сознательности и, следовательно, ответить на вопрос исследования, было рассмотрено восемь стандартизированных критериев оценки машинного обучения. Результаты экспериментального процесса представлены в таблице 5.Экспериментальный процесс был основан на 10 запусках 10-кратной перекрестной проверки. Выбор наблюдаемого классификатора был основан на предварительном исследовании, направленном на поиск подходящего классификатора, и на том предпочтении, чтобы полученные результаты были логически интерпретируемыми. Кроме того, древовидные классификаторы широко применялись при онлайн-идентификации пользователей (Yang and Padmanabhan, 2010). Результаты показали, что пять классификаторов, DTNB, PART, J48, LMT и REPTree, достигли статистически значимой точности классификации по сравнению с базовой точностью.Базовый классификатор в среднем достиг точности 48,81%. Однако DTNB, PART, J48, LMT и REPTree достигли средней точности 79,21, 76,66, 82,36, 84,96 и 80,74% соответственно. Классификатор LMT достиг более высокой точности в различении людей по континууму личностных черт сознательности с примечательно низким уровнем ошибок (Тип-I и Тип-II), что указывает на надежность достигнутых результатов. На исследовательский вопрос, поставленный в разделе «Особенности личности и Интернет» данной статьи, используется уровень статистической значимости p > 0.001. Полученная точность для каждого классификатора была измерена относительно ZeroR, базового классификатора, принятого в этом исследовании. В таблице 5 показана базовая точность (классификатор ZeroR) 48,81%, которая формирует нулевую гипотезу (вероятность получения уровня точности ниже или равного исходному уровню может быть объяснена случайной вариацией) для исследования. Точность, достигаемая с помощью модели логистической регрессии, статистически не значима. Это означает, что полученная точность с использованием модели логистической регрессии может быть объяснена случайной вариацией.Однако другие классификаторы, DTNB, PART, J48, LMT и REPTree, достигли статистически значимого уровня точности. Статистическая значимость результатов этих классификаторов подразумевает, что достигаемая точность является функцией структурного состава и эффективности классификаторов.
Таблица 5. Результат исследования образца сигнатуры .
Эффективность LMT значительно превосходит (как выделено жирным шрифтом в таблицах 5 и 6) производительность базового классификатора на основе значения AUC (график частоты ложноположительных результатов по сравнению с частотой истинных положительных результатов).Значение AUC варьируется от 0 до 1, где значение <0,5 указывает, что результат классификатора не лучше случайного предположения. Значения, близкие к 1, указывают на надежность и точность классификатора. AUC устойчив к несбалансированным данным, таким образом обеспечивая надежную метрику, которая указывает, насколько хорошо классификатор разделяет классы в наборе данных. Значение AUC (усредненное на уровне 0,94) показывает, что классификатор LMT может правильно разделить экземпляры (признак добросовестности) респондентов на их соответствующие дихотомии.Точно так же F-мера, усредненная на уровне 0,89, показывает, что LMT обеспечивает надежный дискриминационный детектор границ для различных классов в наборе данных. F-мера - это гармоническое среднее значение точности и отзыва, которое указывает свойство точности отзыва классификатора. Кроме того, оценка LMT с использованием статистики RMSE и Kappa показала довольно стабильную производительность. Среднее значение RMSE, равное 0,28, указывает, что классификатор LMT может надежно оценить апостериорные вероятности каждого класса.Значение RMSE находится в диапазоне от 0 до 1, где значение, близкое к 0, отражает способность классификатора надежно оценивать апостериорную вероятность каждого класса в экспериментальных данных.
Согласованность подписи на основе набора данных проверки
Чтобы установить и проверить наблюдаемую надежность результатов, представленных в таблице 5, был оценен отдельный набор данных валидации. Результаты, показанные в Таблице 6, были основаны на тех же экспериментальных условиях, что и обучающий набор данных, что выявило согласованность в вероятности различения людей в континууме личностных черт сознательности.Производительность J48 и LMT неизменно выше, чем у других классификаторов. Эти результаты указывают на очень высокую вероятность существования цифрового отпечатка пальца в континууме сознательности.
Таблица 6. Результат проверки шаблона подписи .
Анализ
Результаты в таблице 6 дополнительно подтверждают существование цифрового отпечатка пальца, о чем свидетельствуют результаты, представленные в таблице 5.LMT показал стабильно более высокие результаты, чем другие классификаторы. Средняя точность на этапе исследования и на этапе проверки показывает относительное сходство при значении> 80%, что предполагает статистически значимую вероятность существования отпечатка личности. Результаты, полученные с помощью пяти классификаторов, как показано в таблице 6, показывают очень высокую статистически значимую классификацию пространства данных набора данных проверки по сравнению с классификатором базовой точности (ZeroR).Результаты, представленные в таблице 6, основаны на априорной вероятности класса 35,6, 39,3 и 25,1% для дихотомии высокого, среднего и низкого класса соответственно. Наблюдаемая средняя точность LMT на уровне 80,50% для дихотомии сознательности, как показано на рисунке 3, указывает на то, что людей можно различить по континууму добросовестности с точностью 7,2, 7,0 и 6,9 из каждых 10 случаев для высокой, средней , и младшие классы соответственно. На рисунке 3 представлен сравнительный анализ точности для каждого класса в дихотомии сознательности.Рассматриваемые параметры включают априорную вероятность каждого класса, достигнутую точность каждого класса, разницу между априорной вероятностью класса и достигнутую точность. Результаты также указывают на надежную внутреннюю согласованность с F-мерой и значением AUC примерно на уровне 0,82 и 0,92 соответственно. Кроме того, чувствительность (отзыв) показывает, что идентификация личности надежна и составляет примерно 0,82. Это означает, что для каждого конкретного случая модель LMT может правильно различать людей по континууму добросовестности с надежностью 82%.Чтобы проверить производительность LMT по сравнению с другими классификаторами (с использованием парного теста t ), эксперимент был повторен со ссылкой на LMT в качестве базового классификатора. Результат теста представлен в Таблице 7.
Рисунок 3. Анализ результата валидации .
Таблица 7. Тест анализа значимости .
Тест статистической значимости был измерен на основе 10 повторений 10-кратного результата перекрестной проверки каждого классификатора (что дало 100 экземпляров точности для каждого классификатора).Каждый классификатор был спарен с LMT, и выборочное среднее для пар было проверено в предположении, что нет статистически значимой разницы между достигнутой точностью классификации LMT и каждым парным классификатором. Результат показал, что точность LMT была статистически значимой при доверительном интервале 95 и 99% по сравнению с другими классификаторами. Таким образом, этот тест повышает надежность LMT на наборах данных для обучения и проверки.
Первоначальное наблюдение за результатами процесса проверки предполагает более высокую точность классификации низкого класса.Однако детальный анализ силы точности показывает, что точность высокого класса немного лучше, чем у других классов.
Обсуждение
Вопрос исследования, сформулированный в форме гипотезы, утверждает, что людей можно различать в онлайн-взаимодействии на основе их положения в континууме личностных черт. Результаты, представленные в таблицах 5 и 6, подтверждают это утверждение, показывая высокую вероятность существования сигнатуры черты личности.Дихотомия, исследуемая в этом исследовании, отличается от принятой в Ross et al. (2009), Amichai-Hamburger и Vinitzky (2010), и Moore and McElroy (2012). Он также отличается от дихотомии, рассмотренной в Salleh et al. (2010a) и Salleh et al. (2014), а также из правил n-sigma. Определенная дихотомия, принятая в этом исследовании, считается общей и беспристрастной в отношении асимметрии данных. Такое общее масштабирование обеспечивает основу для экспериментальной повторяемости и соответствующего сравнения с последующими исследованиями.В более ранних исследованиях в литературе дихотомии определялись на основе распределения средних баллов по признакам (например, равные трети). Такая граница отсечения смещена в сторону распределения данных, что составляет различные границы отсечки для каждого набора данных [дихотомии, наблюдаемые у Росс и др. (2009) и Amichai-Hamburger and Vinitzky (2010), например] и, следовательно, зависят от контекста. Лица, отнесенные к высокому классу в одном контексте, могут быть классифицированы как умеренные в другом. Формирование результатов исследований на такой основе противоречит универсальности инструмента измерения черт личности.Кроме того, первоначальная экспериментальная оценка, основанная на правиле пяти сигм и равной третьей дихотомии, дала точность ниже 10% для априорной вероятности каждого класса. F-мера и чувствительность каждого классификатора на основе правила пяти сигм были ниже 0,60. Это говорит о том, что зависимая от контекста дихотомия [такая, как представленная в Ross et al. (2009)] не может служить надежной мерой для исследования признака «цифровой сознательности». Результаты, представленные в таблицах 5 и 6, последовательно демонстрируют возможности исследуемой дихотомии.
Результаты дополнительно демонстрируют превосходство классификатора LMT над другими классификаторами с точки зрения общей точности. Классификатор LMT — это гибридный классификатор, который объединяет модель линейной логистической регрессии в механизм классификации DT. Классификация достигается путем генерации решений с логистическими моделями на его конечных элементах, а прогнозная оценка получается с использованием апостериорной вероятности класса. Интеграция DT в LMT усиливает его превосходство над моделями линейной регрессии при применении к многомерному набору данных, который требует простоты интерпретируемости человеком.В этом исследовании эффективность классификатора DTNB была ниже, чем у LMT. DTNB представляет собой интеграцию наивного байесовского алгоритма в механизм таблицы решений. Первоначальный эксперимент, основанный на наивном методе Байеса, показал очень низкую эффективность классификации. Наивный байесовский классификатор предполагает, что все атрибуты в наборе данных независимы. Способность LMT выводить более обширные структурные сведения из набора данных большого размера может быть объяснена его превосходством над DTNB. PART — это основанный на правилах алгоритм индукции, который строит DT, избегая глобальной оптимизации, чтобы сократить время и сложность обработки.PART использует подход RIPPER «отделяй и властвуй» и объединяет его с механизмом DT C4.5, удаляя все экземпляры из обучающего набора данных, которые подпадают под это правило, и продолжает работу рекурсивно, пока в наборе данных не останется ни одного экземпляра. PART строит частичное ОУ для текущего набора экземпляров, выбирая в качестве нового правила листы с наибольшим покрытием. Однако LMT продемонстрировал более высокую классификационную способность, чем PART в этом исследовании.
REPTree применяет логику дерева регрессии и генерирует несколько деревьев в измененных итерациях путем однократной сортировки значений числовых атрибутов.Это достигается за счет принципа получения информации (который измеряет ожидаемое снижение энтропии), отсечения дерева на основе отсечения с уменьшением ошибок с помощью метода обратной подгонки и интеграции механизма C4.5 для пропущенных значений путем разделения каждого соответствующего экземпляра на дробные экземпляры. Однако LMT продемонстрировал более высокую точность классификации, чем REPTree, как в процессе обучения, так и в процессе тестирования. Классификатор J48 DT — это версия C4.5 DT с кодом Java, реализованная в рабочей среде WEKA.C4.5 — это алгоритм обучения на основе индукции, который использует коэффициент усиления информации, в отличие от обычного выигрыша информации, который смещен в сторону атрибутов большого значения, в качестве критерия разделения для рекурсивного разделения экземпляров атрибутов в пространство атрибутов. Экземпляры классифицируются путем создания узлов, которые образуют корень дерева, с использованием отдельных входящих ребер для связывания узлов, при этом поддерживая множественные исходящие ребра с помощью предопределенной дискретной функции значения входного атрибута.Производительность LMT показала более высокую точность классификации, чем у J48, с точки зрения измеренных параметров в Таблице 7. Это дополнительно показано в среднем количестве правильно и неправильно классифицированных экземпляров в Таблице 8. Детальное наблюдение полученной модели показывает что LMT создал меньший размер правил для классификации, чем J48. Однако время, необходимое для создания модели LMT, значительно больше, чем время, необходимое для создания модели J48 DT. Сравнительный анализ производительности каждого классификатора представлен в таблице 8.Учитываемые параметры включают время, затраченное на построение каждой модели (затраченное время), среднее количество правильно классифицированных экземпляров за 10 итераций (среднее количество правильных), среднее количество неправильно классифицированных экземпляров за 10 итераций (среднее количество неправильных) и количество правила или деревья, сгенерированные алгоритмом для изучения экземпляров атрибута для прогнозирования (количество деревьев / правил).
Таблица 8. Сравнительный анализ работы классификаторов .
Как показано в Таблице 8, количество правил, созданных для классификации, не является прямым показателем эффективности классификатора. Это очевидно по количеству правил, генерируемых LMT (903), J48 (1469), REPTree (779) и PART (181) в порядке убывания производительности. С точки зрения времени, затраченного на построение модели, REPtree превзошел все другие классификаторы со средним числом правильно классифицированных экземпляров 9019,3. Следующим в рейтинге производительности, основанном на времени, затраченном на сборку модели, является J48 DT.Производительность этого классификатора особенно интересна, потому что по среднему количеству правильно классифицированных экземпляров он ближе к LMT. Следовательно, если время рассматривается как фактор при выборе классификатора, J48 DT демонстрирует лучшие характеристики классификации, чем LMT. Процессы сетевого криминалистического анализа (такие как «поймай, пока можешь»), которые считают время важным фактором, являются примером приложений, которые отдают предпочтение времени, затраченному на построение модели. Однако в процессе анализа данных, где точность является критическим фактором независимо от затраченного времени, классификатор LMT обеспечивает лучшую производительность.Кроме того, прошедшее время (также называемое временем работы классификатора) зависит от таких факторов, как
.
и. ядро процессора; конфигурация одноядерной системы против многоядерной,
ii. поколение процессорного ядра по скорости чтения / записи памяти,
iii. архитектура: 32- или 64-битная и
iv. входные данные для алгоритма классификации.
Данные, вводимые классификатором, определяют его внутреннюю сложность классификации.WEKA измеряет прирост сложности классификатора на основе логарифмической функции потерь по основанию 2 прироста энтропии. Столбец улучшения сложности в таблице 8 показывает уровень увеличения сложности априорной энтропии класса для каждого наблюдаемого классификатора. Классификаторы LMT и DTNB продемонстрировали высокий выигрыш в сложности по сравнению с другими классификаторами. Это также свидетельствует об эффективности LMT с точки зрения точности, общей сложности и надежности разработанной модели.
Примером такого приложения является тип сетевого криминалистического процесса с остановкой и просмотром.Изображение DT, созданного классификатором J48, представлено на рисунке 4. DT из J48 представлено в сравнении с DT из модели LMT. Это связано с тем, что модель LMT генерирует правила, которые объединяют логистическую модель и дерево решений, которые относительно сложно интерпретировать, в отличие от правил, созданных из J48 и других классификаторов на основе правил. На рисунке показан набор правил, созданных с использованием процесса DT классификатора J48. Результаты для набора обучающих данных, как показано на частичном ОУ, представленном на рисунке 4, показывают, что люди в каждой дихотомии демонстрируют структурные паттерны, которые объединяют следующие комбинации сетевых функций по шкале сознательности.
Рисунок 4. Частичное дерево решений отпечатка личности .
Низкий класс
На рисунке 4 можно увидеть, что, когда частота посещений была ≤0,106557, скорость подсчета посещений за сеанс составляла ≤10,8684, частота посещений была <0,009975 и> 0,00, продолжительность сеанса составляла> 320 с, частота посещений за сеанс составляла> 7,655462, продолжительность сеанса составляла> 1227 с, а частота посещений за сеанс составляла ≤8.488285 в общей сложности было извлечено 142 структурных паттерна, и было обнаружено, что все паттерны принадлежат лицам, получившим низкие баллы по континууму черт сознательности.
Средний класс
На рисунке 4 можно увидеть, что, когда частота посещений была ≤0,106557, частота посещений за сеанс составляла ≤10,8684, частота посещений была ≤0,009975, а частота посещений была <0,00, всего из 47 структурных паттернов были извлечены, и все паттерны принадлежали индивидам умеренного класса континуума черт сознательности.
Высокий класс
Навигация сверху вниз на Рисунке 4, правый переход к узлу N185, показывает, что когда узел N185 был> 4,352697, а продолжительность сеанса была> 1615, было извлечено 100 структурных паттернов. Девяносто шесть из них принадлежали к людям высокого класса по континууму сознательности. Только четыре шаблона относятся к другому классу. Дальнейшая навигация по пространству DT показывает, что 18 структурных паттернов также были извлечены, и 17 из 18 структурных паттернов принадлежат людям в высшем классе континуума сознательности.Структуры показывают, что люди этого класса имеют одинаковую продолжительность сеанса, которая относительно выше, чем у людей других классов.
Эти правила демонстрируют способ использования DT для классификации человека в Интернете на низкий, средний или высокий классы по континууму сознательности. Правила также показывают взаимосвязь между личностными качествами онлайн-пользователей и наблюдаемой моделью использования Интернета. По сути, это показывает, что онлайн-пользователей, которые относятся к низшему, среднему или высокому классу по континууму личностных черт Сознательности, можно различить в Интернете в течение 30-минутного сеанса.Поскольку в этом исследовании не удалось выделить классы для очень низких и очень высоких дихотомий, логично предположить, что новые сигнатуры людей, которые принадлежат к таким дихотомиям по континууму черт сознательности, не отражены в настоящем исследовании. Однако этот результат особенно полезен, потому что он использует ОУ. DT предлагает несколько преимуществ по сравнению с другими типами классификаторов. К ним относятся простота интерпретации людьми и простота представления и применения. Более того, DT не требует предварительного предположения о структуре данных, но строит знания на основе структуры данных.
Последствия
Учитывая достижения современных технологий, Интернет по-прежнему предъявляет высокие требования к эффективным системам предоставления услуг, а также к надежной информационной безопасности и надежности. Идея существования отпечатка личности в Интернете представляет собой парадигму, которая способна объяснить и впоследствии понять сложности Интернет-технологий. Идея индивидуального отпечатка решает эту проблему и в конечном итоге развенчивает общее изречение «в Интернете никто не знает, что вы собака».«Персональная печать с точки зрения предоставления услуг, таких как электронная коммерция и электронное обучение, а также системы рекомендаций, представляет собой платформу для разработки интеллектуальной системы интернет-услуг, которая способна определять характеристики человека и, следовательно, прогнозировать или предлагая эффективные процессы персонализированного обслуживания. Соответствующее изучение личности конечного пользователя открывает перед исследователями более фундаментальный дискурс о лежащих в основе причинности скачков сети и вероятности создания сложных искусственных сетей, способных воспроизводить или имитировать человеческую динамику.Кроме того, это открывает исследователям возможность лучше понять эволюцию потребления Интернета. С точки зрения сетевой безопасности, отпечаток личности представляет собой дополнительную платформу для онлайн-идентификации, особенно в процессах аутентификации «один ко многим». Интеграция персонального отпечатка в процесс идентификации и аутентификации также предполагает наличие надежного и надежного механизма безопасности, сочетающегося с присущими человеку характеристиками. Наблюдаемая высокая вероятность существования отпечатков личности подтверждает утверждения в литературе, посвященной личности и Интернету (Ross et al., 2009; Correa et al., 2010; Moore and McElroy, 2012), так что можно объяснить общее описание отношений между онлайн-пользователем и наблюдаемым поведенческим паттерном сетевых функций.
Наблюдение в этом исследовании ограничено несколькими факторами. Во-первых, в этом исследовании наблюдался только один личностный фактор. Это связано с ограниченным размером выборки респондентов в исследовании. Наблюдаемая точность классификации LMT ниже 100%. Это означает, что полученные результаты не представляют собой идеальную классификацию, но предоставляют вероятностный анализ существования отпечатка личности.Кроме того, в этом исследовании были изучены только три класса из пяти дихотомических различий, определенных на рисунке 2. Это также можно объяснить размером выборки, принятой в данном исследовании. Интеграция данных клиентской сети в процесс наблюдения за образцами представляет собой более полный набор данных для исследования отпечатков личности. В настоящее время осуществляется процесс расширения этого предварительного расследования, чтобы можно было изучить более крупную выборку. Кроме того, исследуются другие факторы моделей личностных качеств Большой пятерки.
Авторские взносы
Все перечисленные авторы внесли существенный, прямой и интеллектуальный вклад в работу и одобрили ее для публикации.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось в отсутствие каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Это исследование было поддержано / частично поддержано Universiti Teknologi Malaysia и Министерством высшего образования Малайзии под номером голосования: R.J130000.7813.4F804.
Дополнительные материалы
Дополнительные материалы к этой статье можно найти в Интернете по адресу https://www.frontiersin.org/article/10.3389/fict.2016.00008
Список литературы
Абрамсон, М. (2012). «К атрибуции поведения в сети», в Симпозиум IEEE по вычислительному анализу для приложений безопасности и защиты (CISDA) , (Оттава: IEEE), 1–5.
Google Scholar
Абрамсон, М., и Аха, Д. (2013). «Аутентификация пользователя при просмотре веб-страниц», в FLAIRS Conference , (Пало-Альто, Калифорния: Цифровая библиотека AAAI), 268–273.
Google Scholar
Абрамсон, М., и Гор, С. (2013). Ассоциативные шаблоны поведения при просмотре веб-страниц (Пало-Альто, Калифорния: Цифровая библиотека AAAI).
Google Scholar
Адейеми, И. Р., Разак, А. С., и Салле, М. (2014). «Психографическая основа для онлайн-идентификации пользователей», в Международном симпозиуме по биометрии и технологиям безопасности (ISBAST) , , (Куала-Лумпур: IEEE), 198–203.
Google Scholar
Amichai-Hamburger, Y., Fine, A., and Goldstein, A. (2004). Влияние интерактивности в Интернете и необходимости закрытия на предпочтения потребителей. Comput. Человеческое поведение. 20, 103–117. DOI: 10.1016 / S0747-5632 (03) 00041-4
CrossRef Полный текст | Google Scholar
Amichai-Hamburger, Y., (ed.). (2005). «Личность и Интернет», в Социальная сеть: поведение человека в киберпространстве (Нью-Йорк, Нью-Йорк: Oxford University Press), 27–55.
Google Scholar
Amichai-Hamburger, Y., и Vinitzky, G. (2010). Использование социальных сетей и личность. Comput. Человеческое поведение. 26, 1289–1295. DOI: 10.1016 / j.chb.2010.03.018
CrossRef Полный текст | Google Scholar
Amichai-Hamburger, Y., Wainapel, G., and Fox, S. (2002). «В Интернете никто не знает, что я интроверт»: экстраверсия, невротизм и взаимодействие в Интернете. Cyberpsychol. Behav. 5, 125–128.DOI: 10.1089 / 109493102753770507
CrossRef Полный текст | Google Scholar
Amiel, T., и Sargent, S. (2004). Индивидуальные различия в мотивах использования Интернета. Comput. Человеческое поведение. 20, 711–726. DOI: 10.1016 / j.chb.2004.09.002
CrossRef Полный текст | Google Scholar
Корреа Т., Бахманн И., Хинсли А. В. и Хиль де Суньига Х. (2013). «Личность и использование социальных сетей» в журнале «Организации и социальные сети: использование социальных сетей для привлечения потребителей» , Vol.2013 г., редакторы Э. Ю. Ли, С. Ло, Э. Каин и Л. Фабиана (Херши, Пенсильвания: Справочник по бизнес-науке), 41–61.
Google Scholar
Корреа Т., Хинсли А. и Де Зунига Х. (2010). Кто взаимодействует в сети? Пересечение личности пользователей и использования социальных сетей. Comput. Человеческое поведение. 26, 247–253. DOI: 10.1016 / j.chb.2009.09.003
CrossRef Полный текст | Google Scholar
Дэвис, Дж. М., и Йи, М. Ю. (2012). Расположение пользователей и степень использования Интернета: подход иерархии черт. Внутр. J. Hum. Comput. Stud. 70, 346–363. DOI: 10.1016 / j.ijhcs.2011.12.003
CrossRef Полный текст | Google Scholar
де Оливейра Р., Керубини М. и Оливер Н. (2013). Влияние личности на удовлетворенность услугами мобильной связи. ACM Trans. Comput. Взаимодействовать. 20, 10. DOI: 10.1145 / 2463579.2463581
CrossRef Полный текст | Google Scholar
де Оливейра, Р., Карацоглу, А., Сересо, П. К., Армента Лопес де Викуа, А., и Оливер, Н. (2011). «К психографической модели пользователя при использовании мобильного телефона», в CHI’11 Extended Abstracts on Human Factors in Computing Systems , 2191–2196.
Google Scholar
Дельгадо-Гомес, Д., Сукно, Ф., Агуадо, Д., Сантакрус, К., и Артес-Родригес, А. (2010). Индивидуальная идентификация по личностным качествам. J. Netw. Comput. Заявление 33, 293–299. DOI: 10.1016 / j.jnca.2009.12.009
CrossRef Полный текст | Google Scholar
Голбек, Дж., Роблес, К., Тернер, К. (2011). «Предсказание личности с помощью социальных сетей», в CHI’11 Extended Abstracts on Human Factors in Computing Systems (New York: ACM), 253–262.
Google Scholar
Гуаданьо Р., Окди Б. и Ино К. (2008). Кто ведет блог? Предсказатели личности блоггинга. Comput. Человеческое поведение. 24, 1993–2004. DOI: 10.1016 / j.chb.2007.09.001
CrossRef Полный текст | Google Scholar
Гамбургер, Ю.А., и Бен-Арци, Э. (2000). Взаимосвязь между экстраверсией и невротизмом и различными способами использования Интернета. Pdf. Comput. Человеческое поведение. 16, 441–449. DOI: 10.1016 / S0747-5632 (00) 00017-0
CrossRef Полный текст | Google Scholar
Гердер, Э. (2005). «Характеристики поведения пользователей при повторном посещении сети», в Proceedings Workshop on Adaptive and User Modeling in Interactive Systems (Hershey: Idea Group Publishing), 1–6.
Google Scholar
Херрманн, Д., Гербер, К., Банс, К., и Федеррат, Х. (2012). «Анализ характерных шаблонов доступа к хосту для повторной идентификации сеансов веб-пользователей», в Технология информационной безопасности для приложений , ред. А. Туомас, Дж. Киммо и Н. Кайса (Эспоо, Финляндия: Springer), 136–154.
Google Scholar
Хупер, К. и Дикс, А. (2013). Веб-наука и взаимодействие человека и компьютера: формирование взаимовыгодных отношений. Взаимодействия 20, 52–57.DOI: 10.1145 / 2451856.2451868
CrossRef Полный текст | Google Scholar
Джойнер Р., Броснан М. и Даффилд Дж. (2007). Взаимосвязь между идентификацией в Интернете, беспокойством по поводу Интернета и использованием Интернета. Comput. Человеческое поведение. 23, 1408–1420. DOI: 10.1016 / j.chb.2005.03.002
CrossRef Полный текст | Google Scholar
Коциантис, С., Захаракис, И., и Пинтелас, П. (2007). Машинное обучение с учителем: обзор методов классификации. информатика 31, 249–268.
Google Scholar
Кумар Р., Томкинс А. (2010). «Характеристика поведения при просмотре веб-страниц в Интернете», в материалах Proceedings of the 19 International Conference World Wide Web (Северная Каролина: ACM), 561–570.
Google Scholar
Ландерс Р. и Лаунсбери Дж. (2006). Исследование большой пятерки и узких черт личности в связи с использованием Интернета. Comput. Человеческое поведение. 22, 283–293. DOI: 10.1016 / j.chb.2004.06.001
CrossRef Полный текст | Google Scholar
Лим, М. Дж.-Х., Негневицкий, М., и Хартнетт, Дж. (2006). Имитационная модель системы электронной почты на основе личностных качеств. Внутр. J. Netw. Secur. 3, 164–182.
Google Scholar
Мэтьюз Г., Дири И. Дж. И Уайтмен М. С. (2003). Черты характера . Цинциннати: Университет Цинциннати.
Google Scholar
Мур, К.и МакЭлрой Дж. (2012). Влияние личности на использование Facebook, публикации на стенах и сожаление. Comput. Человеческое поведение. 28, 267–274. DOI: 10.1016 / j.chb.2011.09.009
CrossRef Полный текст | Google Scholar
Мюррей Д. и Даррелл К. (2000). «Выведение демографических характеристик анонимных пользователей Интернета», в International WEBKDD’99 Workshop, Сан-Диего; CA; США; 15 августа; Пересмотренные документы 1999 г., , изд. М. С. Брий Масанд (Берлин, Гейдельберг: Springer), 7–20.
Google Scholar
Nguyen, T. T., and Armitage, G. (2008). «Обзор методов классификации интернет-трафика с использованием машинного обучения», в IEEE Communications Surveys & Tutorials , IEEE, 56–76.
Google Scholar
Орен, Т., и Гасем-Агаи, Н. (2003). «Представление личности, обрабатываемое в нечеткой логике для моделирования поведения человека», в Society for Computer Simulation International: In Summer Computer Simulation Conference , Society for Computer Simulation International, 11–18.
Google Scholar
Орен, Т. И., и Гасем-Агаи, Н. (2003). «К нечетким агентам с динамической индивидуальностью для моделирования человеческого поведения», в Proceedings of the 2003 Summer Computer Simulation Conference (San Diego: SCS), 11–18.
Google Scholar
Осман, Ф. М., Мох, Т., и Яу, С. (2007). «Сравнение различных методов классификации рака груди с использованием WEKA», 3-я Международная конференция по биомедицинской инженерии в Куала-Лумпуре, , Vol.15, 520–523.
Google Scholar
Quercia, D., и Kosinski, M. (2011). «Наши профили в Твиттере, мы сами: прогнозирование личности с помощью Твиттера», в Третьей международной конференции по конфиденциальности, безопасности, рискам и доверию (PASSAT) и третьей Международной конференции IEEE 2011 года по социальным вычислениям (SocialCom) (Бостон, Массачусетс: IEEE ), 180–185.
Google Scholar
Росс, К., Орр, Э. Э. С., Сисик, М., Арсено, Дж. М., Симмеринг, М. Г., и Орр, Р. Р. (2009). Личность и мотивы, связанные с использованием Facebook. Comput. Человеческое поведение. 25, 578–586. DOI: 10.1016 / j.chb.2008.12.024
CrossRef Полный текст | Google Scholar
Салле, Н., Мендес, Э., и Гранди, Дж. (2011). «Влияние открытости к опыту на парное программирование в контексте высшего образования», в материале Proceeding of the 24th IEEE-CS Conference on Software Engineering Education and Training (CSEE & T) , (Гонолулу, Гавайи: IEEE), 149–158.
Google Scholar
Салле, Н., Мендес, Э., и Гранди, Дж. (2014). Изучение влияния личностных качеств на парное программирование в условиях высшего образования с помощью серии экспериментов. Empir. Софтв. Англ. 19, 714–752. DOI: 10.1007 / s10664-012-9238-4
CrossRef Полный текст | Google Scholar
Салле, Н., Мендес, Э., Гранди, Дж., И Берч, Г. (2010a). «Эмпирическое исследование влияния добросовестности в парном программировании с использованием пятифакторной модели личности», Труды 32-й Международной конференции ACM / IEEE по программной инженерии , Vol.1 (Кейптаун: ACM), 577–586.
Google Scholar
Салле, Н., Мендес, Э., Гранди, Дж., И Берч, Г. (2010b). «Влияние невротизма на парное программирование: эмпирическое исследование в контексте высшего образования», в материалах Proceedings of the 2010 ACM-IEEE International Symposium on Empirical Software Engineering and Measurement (Bolzano: ACM), 22.
Google Scholar
Самареин, З.А., Фар, Н.С., Еклех, М., Тахмасеби, С., Рамезани Ю.В., Санди Л. (2013). Взаимосвязь личностных качеств и интернет-зависимости студентов Университета Харазми. Внутр. J. Psychol. Behav. Res. 2, 10–17.
Google Scholar
Шраммель, Дж., Кёффель, К. и Челиги, М. (2009). «Особенности личности, модели использования и раскрытие информации в онлайн-сообществах», в материалах Proceedings of the 23rd British HCI Group Annual Conference on People and Computers: Celebrating People and Technology , (Cambridge: ACM), 169–174.
Google Scholar
Свикерт Р., Гиттнер Дж., Харрис Дж. И Херринг Дж. (2002). Отношения между использованием Интернета, личностью и социальной поддержкой. Comput. Человеческое поведение. 18, 437–451. DOI: 10.1016 / S0747-5632 (01) 00054-1
CrossRef Полный текст | Google Scholar
Тан, В., и Ян, К. (2012). «Предикторы личностных характеристик использования Интернет-услуг», в Международная конференция по экономике и бизнес-инновациям (IIPEDR) , Vol.38 (Сингапур: ACSIT Press), 185–190.
Google Scholar
Тан, В., и Ян, К. (2014). Использование интернет-приложений и личность. Телематика Информ. 31, 27–38. DOI: 10.1016 / j.tele.2013.02.006
CrossRef Полный текст | Google Scholar
Янг Ю. и Падманабхан Б. (2010). К шаблонам пользователей для онлайн-безопасности: время наблюдения и онлайн-идентификация пользователей. Decis. Поддержка Syst. 48, 548–558.DOI: 10.1016 / j.dss.2009.11.005
CrossRef Полный текст | Google Scholar
Ян, Ю. К. (2010). Профилирование поведения веб-пользователей для идентификации пользователей. Decis. Поддержка Syst. 49, 261–271. DOI: 10.1016 / j.dss.2010.03.001
CrossRef Полный текст | Google Scholar
Янг, К. С. и Роджерс, Р. С. (1998). «Интернет-зависимость: черты личности, связанные с ее развитием», 69-е ежегодное собрание Восточной психологической ассоциации , Бостон, Массачусетс, 1–6.
Google Scholar
Юэ, К., Кан, С., Сяомэн, Х., и Чжэнь, Л. (2010). «Психологические влияния ведения блогов: использование блогов, личностные особенности и самооценка», в , 2010 г., Второй симпозиум IEEE Web Society , IEEE, 71–76.
Online Tone Generator — генерируйте чистые тона любой частоты
Инструкции
Чтобы воспроизвести постоянный тон, щелкните Play или нажмите Пробел .
Чтобы изменить частоту, перетащите ползунок или нажмите ← → (клавиши со стрелками).Чтобы отрегулировать частоту на 1 Гц, используйте
или нажмите Shift + ← и Shift + → .
Чтобы настроить частоту на 0,01 Гц, нажмите Ctrl + ← и Ctrl + → ;
чтобы отрегулировать его на 0,001 Гц, нажмите Ctrl + Shift + ← и Ctrl + Shift + →
Чтобы уменьшить / удвоить частоту (вниз / вверх на одну октаву), нажмите
× ½ и × 2.
Чтобы изменить тип волны с синусоидальной волны (чистый тон) на квадратную / треугольную / пилообразную волну, нажмите кнопку
кнопка.
Вы можете смешивать тона, открыв онлайн-генератор тона
в нескольких вкладках браузера.
Для чего я могу использовать этот тон-генератор?
Настройка инструментов, научные эксперименты ( какая резонансная частота этого бокала? ), тестирование аудиооборудования
(, как низко опускается мой сабвуфер? ), проверил свой слух ( какая самая высокая частота, которую вы можете слышать? Есть ли частоты
ты слышишь только одним ухом? ).
Согласование частоты тиннитуса.
Если у вас чистый тиннитус, этот онлайн-генератор частоты поможет вам определить его частоту.Знание частоты шума в ушах может помочь вам лучше нацеливать маскирующие звуки и
тренировка частотной дискриминации.
Когда вы найдете частоту, которая соответствует вашему шуму в ушах, обязательно проверьте частоты.
на октаву выше (частота × 2) и на октаву ниже (частота × ½), так как это легко спутать
тоны, разнесенные на одну октаву.
Болезнь Альцгеймера.
Есть некоторые ранние научные доказательства того, что прослушивание тона 40 Гц
может обратить вспять некоторые молекулярные изменения в мозге пациентов с болезнью Альцгеймера.Это одна из тех вещей, которые звучат слишком хорошо, чтобы быть правдой,
но первые результаты очень многообещающие. Вот
краткое изложение проведенного исследования и отчет пользователя, который
попробовал терапию 40 Гц на своей жене.
( Обратите внимание, что этот тон-генератор не является медицинским устройством — я ничего не гарантирую! )
Комментарии
Вы можете оставлять комментарии здесь.
Поддержите этот сайт
Если вы используете онлайн-генератор тональных сигналов и находите его полезным, пожалуйста, поддержите его немного деньгами.Вот сделка:
Моя цель — продолжать поддерживать этот сайт, чтобы он оставался совместимым с
текущие версии браузера. К сожалению, это занимает нетривиальное количество времени (например, вычисление
устранение неясной ошибки браузера может занять много часов), что является проблемой, потому что
Я должен зарабатывать на жизнь. Пожертвования от таких замечательных, красивых пользователей, как вы, дают мне время, чтобы все работало.
Добавить комментарий